神經網路與深度學習入門必備知識|概論
神經網路與深度學習緒論
- 人工智慧的一個子領域
- 神經網路:一種以(人工)神經元為基本單元的模型
- 深度學習:一類機器學習問題,主要解決貢獻度分配問題
知識結構
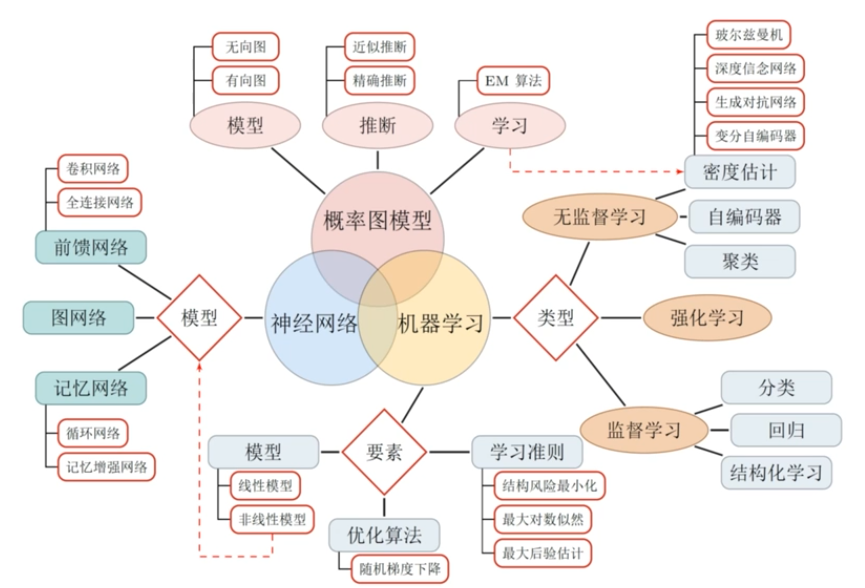
學習路線圖
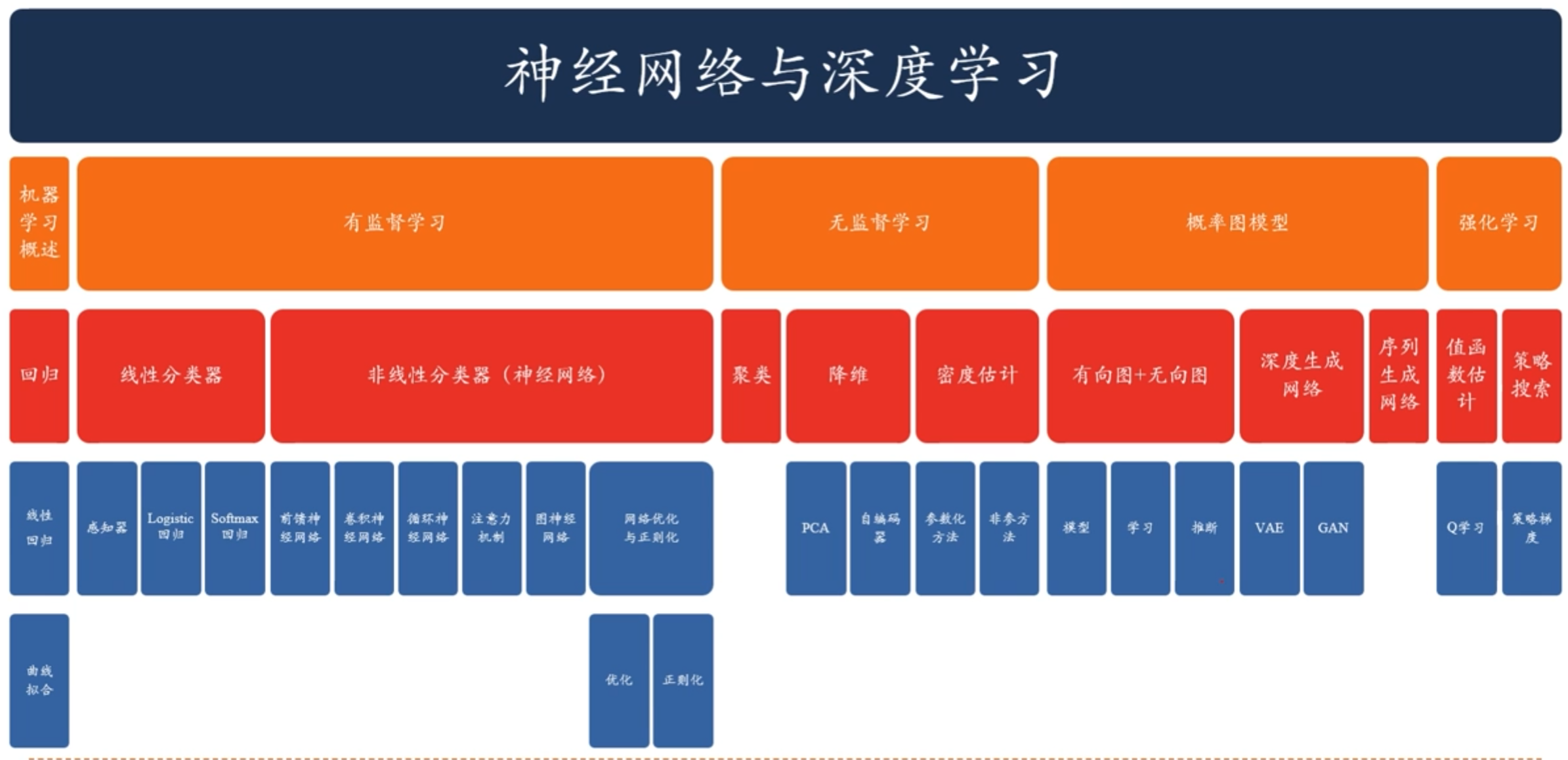
預備知識
- 線性代數
- 微積分
- 數學優化
- 概率論
- 資訊理論
推薦課程
斯坦福大學CS224n: Deep Learning for Natural Language Processing
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/
Chris Manning主要講解自然語言處理領域的各種深度學習模型
斯坦福大學CS23ln: Convolutional Neural Networks for Visual Recognition
http://cs231n.stanford.edu/
Fei-Fei Li Andrej Karpathy 主要講解CNN、RNN在影象領域的應用
加州大學伯克利分校CS294:Deep Reinforcement Learning
http://rail.eecs.berkeley.edu/deeprlcourse/
推薦材料
林軒田 「機器學習基石」 「機器學習技法」
https://www.csie.ntu.edu.tw/~htlin/mooc/
李宏毅 「1天搞懂深度學習」
http://speech.ee.ntu.edu.tw/~tlkagk/slide/Tutorial_HYLee_Deep.pptx
李宏毅 「機器學習2020」
https://www.bilibili.com/video/av94519857/
頂會論文
- NeurIPS、ICLR、ICML、AAAI、ICAI
- ACL、EMNLP
- CVPR、ICCV
- …
常用的深度學習框架
- 簡易和快速的原型設計
- 自動梯度計算
- 無縫CPU和GPU切換
- 分散式計算
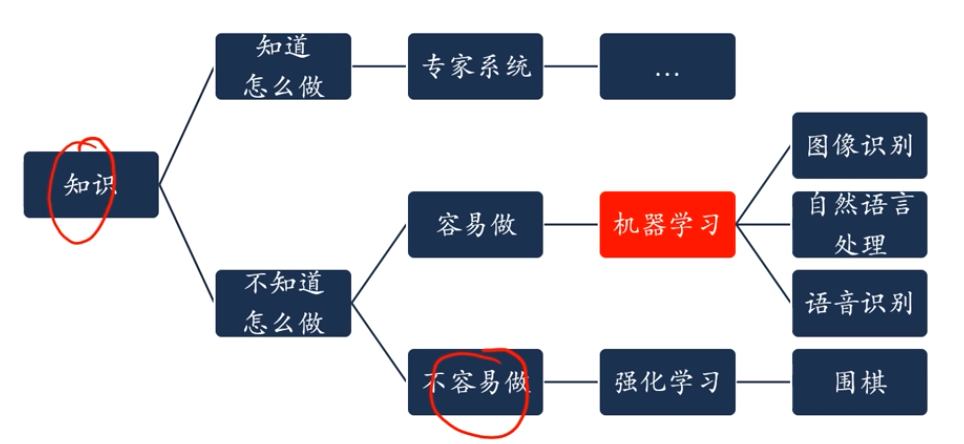
人工智慧
人工智慧的研究領域
圖靈測試是促使人工智慧從哲學探討到科學研究的一個重要因素,引導了人工智慧的很多研究方向。
因為要使得計算機能通過圖靈測試,計算機必須具備理解語言、學習、記憶、推理、決策等能力。
研究領域
- 機器感知(計算機視覺、語音資訊處理、圖形識別)
- 學習(機器學習、強化學習)
- 語言(自然語言處理)
- 記憶(知識表示)
- 決策(規劃、資料探勘)
如何開發人工智慧系統
規則是什麼?


表示學習
當我們用機器學習來解決一些圖形識別任務時,一般的流程包含以下幾個步驟:

- 淺層學習(Shallow Learning):不涉及特徵學習,其特徵主要靠人工經驗或特徵轉換方法來抽取。
- 特徵工程:需要藉助人類智慧,人自己處理
資料表示
語意鴻溝:人工智慧的挑戰之一
底層特徵VS高層語意
人們對文字、影象的理解無法從字串或者影象的底層特徵直接獲得

什麼是好的資料表示(Representation)?
「好的表示」是一個非常主觀的概念,沒有一個明確的標準。
但一般而言,一個好的表示具有以下幾個優點:
- 應該具有很強的表示能力。
- 應該使後續的學習任務變得簡單。
- 應該具有一般性,是任務或領域獨立的。
資料表示是機器學習的核心問題。
表示形式:如何在計算機中表示語意?
-
區域性表示
-
離散表示、符號表示
-
One-Hot向量
-
分散式(distributed)表示
-
壓縮、低維、稠密向量
-
用ON)個參數列示O(2)區間
-
k為非0引數,k<N
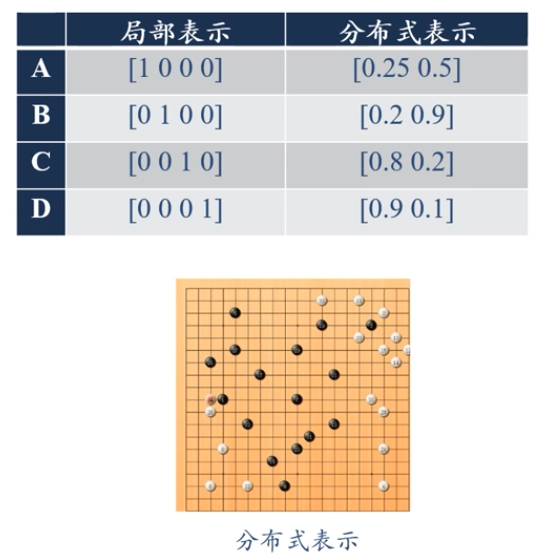
一個生活中的例子:顏色

詞嵌入(Word Embeddings)
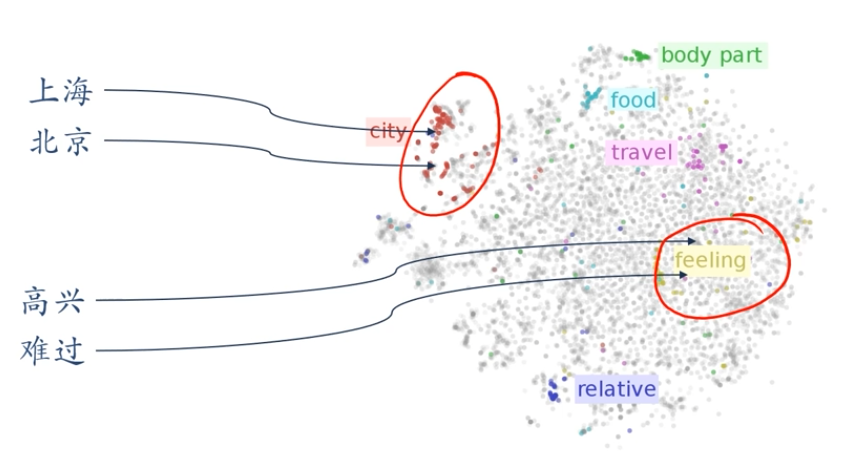
表示學習
- 表示學習:如何自動從資料中學習好的表示
- 通過構建具有一定「深度」的模型,可以讓模型來自動學習好的特徵表示(從底層特徵,到中層特徵,再到高層特徵),從而最終提升預測或識別的準確性。

傳統的特徵提取VS表示學習
特徵提取
- 線性投影(子空間)
- PCA、LDA
- 非線性嵌入
- LLE、Isomap、譜方法
- 自編碼器
特徵提取VS表示學習
特徵提取:基於任務或先驗對去除無用特徵
表示學習:通過深度模型學習高層語意特徵【難點:沒有明確的目標,將輸入和輸出連線,是端到端的學習】
深度學習
表示學習與深度學習
一個好的表示學習策略必須具備一定的深度
- 特徵重用:指數級的表示能力
- 抽象表示與不變性:抽象表示需要多步的構造
深度學習概述
深度學習=表示學習+決策(預測)學習[淺層學習]

深度學習的關鍵問題是貢獻度分配問題,也就是底層特徵還是中高層特徵的建構函式誰更重要。
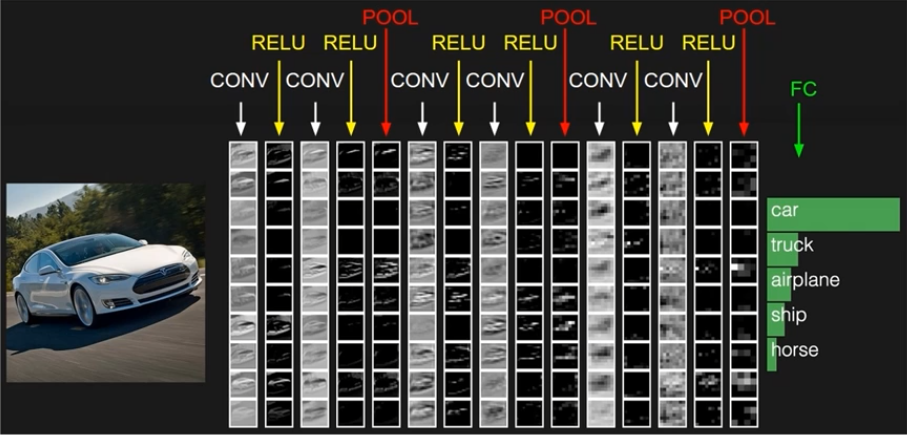
上面這種學習屬於端到端學習(end-to-end)沒有人為干預。
深度學習的數學描述
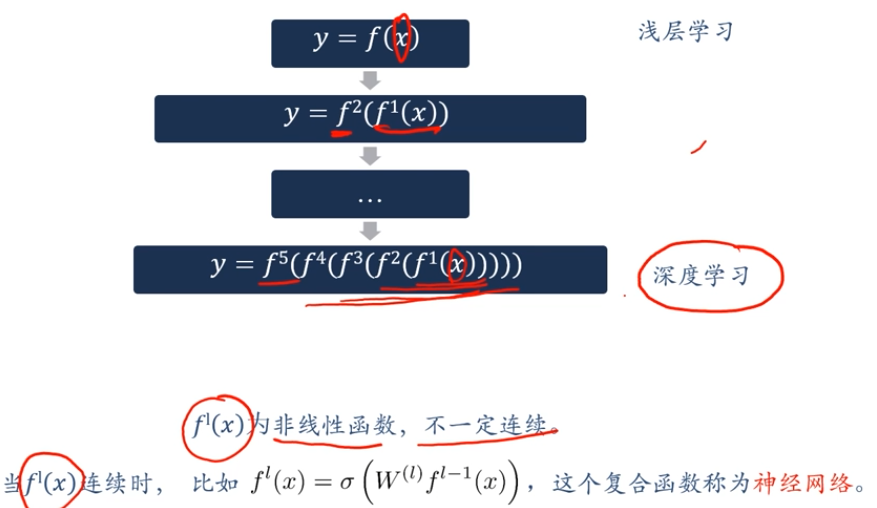
神經網路
生物神經元
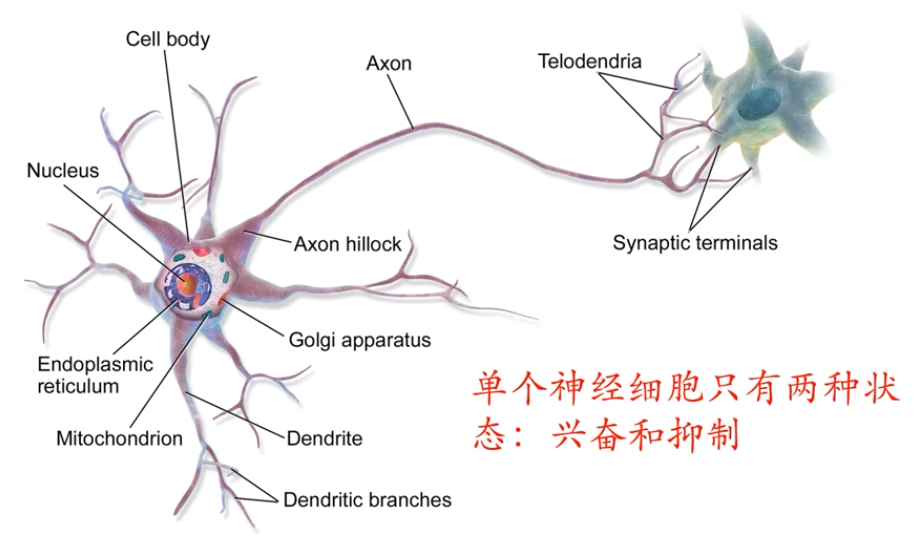
神經網路如何學習?
赫布法則Hebb's Rule
「當神經元A的一個軸突和神經元B很近,足以對它產生影響,並且持續地、重複地參與了對神經元B的興奮,那麼在這兩個神經元或其中之一會發生某種生長過程或新陳代謝變化,以致於神經元A作為能使神經元B興奮的細胞之一,它的效能加強了。」
——加拿大心理學家 Donald Hebb,《行為的組織》,1949
- 人腦有兩種記憶:長期記憶和短期記憶。短期記憶持續時間不超過一分鐘。如果一個經驗重複足夠的次數,此經驗就可儲存在長期記憶中。
- 短期記憶轉化為長期記憶的過程就稱為凝固作用。
- 人腦中的海馬區為大腦結構凝固作用的核心區域。
人工神經網路
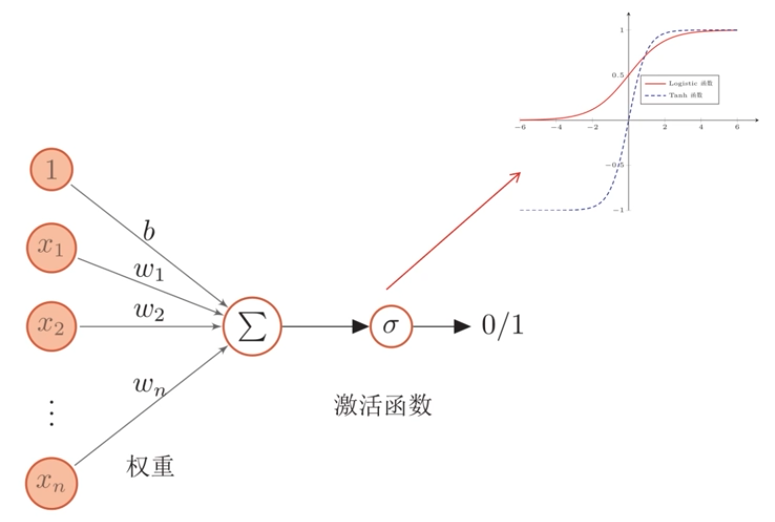
人工神經元
-
人工神經網路主要由大量的神經元以及它們之間的有向連線構成。因此考慮三方面:
- 神經元的啟用規則:主要是指神經元輸入到輸出之間的對映關係,一般為非線性函數。
- 網路的拓撲結構:不同神經元之間的連線關係。
- 學習演演算法:通過訓練資料來學習神經網路的引數。
-
人工神經網路由神經元模型構成,這種由許多神經元組成的資訊處理網路具有並行分佈結構。
-
雖然這裡將神經網路結構大體上分為三種型別,但是大多數網路都是複合型結構,即一個神經網路中包括多種網路結構。
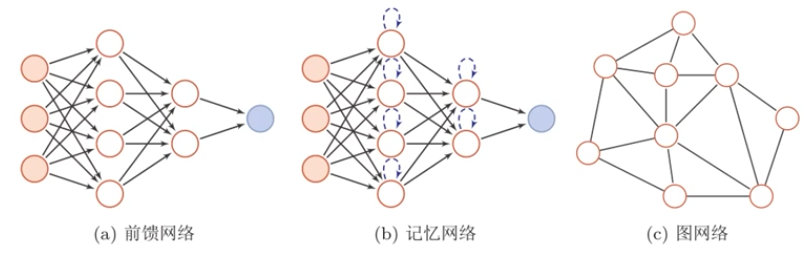
神經網路
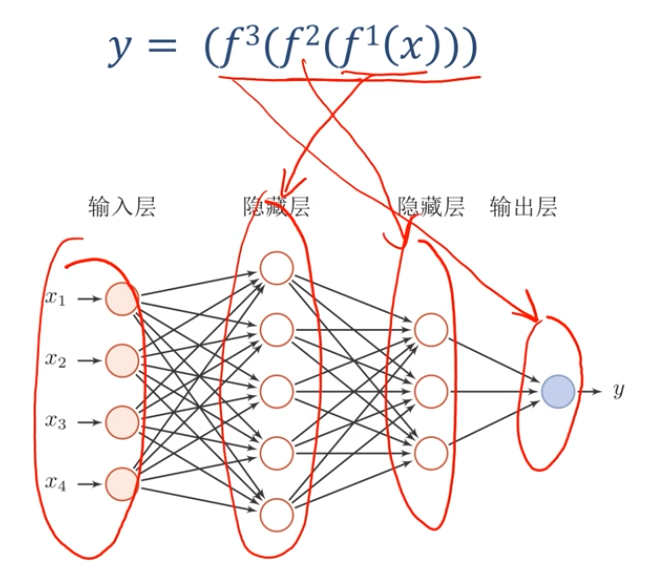
如何解決貢獻度分配問題?
偏導數
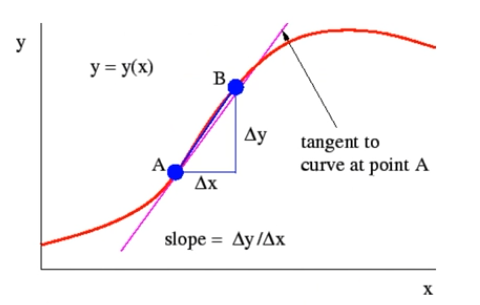
貢獻度
神經網路天然不是深度學習,但深度學習天然是神經網路。
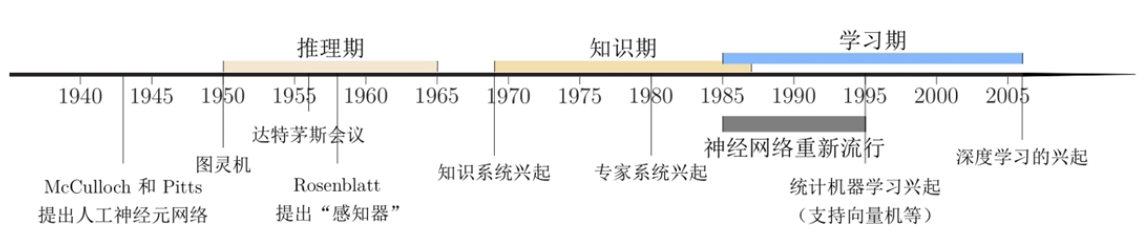
神經網路發展史
神經網路的發展大致經過五個階段。
第一階段:模型提出
- 在1943年,心理學家Warren McCulloch和數學家Walter Pitts和最早描述了一種理想化的人工神經網路,並構建了一種基於簡單邏輯運算的計算機制。他們提出的神經網路模型稱為MP模型
- 阿蘭·圖靈在1948年的論文中描述了一種「B型圖靈機」。(赫布型學習)
- 1951年,McCulloch和Pitts的學生Marvin Minsky建造了第一臺神經網路機,稱為SNARCO
- Rosenblatt[l958]最早提出可以模擬人類感知能力的神經網路模型,並稱之為感知器(Perceptron),並提出了一種接近於人類學習過程(迭代、試錯)的學習演演算法。
第二階段:冰河期
- 1969年,Marvin Minsky出版《感知器》一書,書中論斷直接將神經網路打入冷宮,導致神經網路十多年的「冰河期」。他們發現了神經網路的兩個關鍵問題:
- 1)基本感知器無法處理互斥或迴路。
- 2)電腦沒有足夠的算力來處理大型神經網路所需要的很長的計算時間。
- 1974年,哈佛大學的Paul Webos發明反向傳播演演算法,但當時未受到應有的重視。
- 1980年,Kunihiko Fukushima(福島邦彥)提出了一種帶折積和子取樣操作的多層神經網路:新知機(Neocognitron)[折積神經網路前身]
第三階段:反向傳播演演算法引起的復興
- 1983年,物理學家John Hopfield對神經網路引入能量函數的概念,並提出了用於聯想記憶和優化計算的網路(稱為Hopfield網路),在旅行商問題上獲得當時最好結果,引起轟動。
- 1984年,Geoffrey Hinton提出一種隨機化版本的Hopfield網路,即玻爾茲曼機。
- 1986年,David Rumelhart和James McClelland對於聯結主義在計算機模擬神經活動中的應用提供了全面的論述,並重新發明了反向傳播演演算法。
- 1986年,Geoffrey Hinton等人將引入反向傳播演演算法到多層感知器。[前饋神經網路]
- 1989年,LeCun等人將反向傳播演演算法引入了折積神經網路,並在手寫體數位識別上取得了很大的成功。
第四階段:流行度降低
- 在20世紀90年代中期,統計學習理論和以支援向量機為代表的機器學習模型開始興起。
- 相比之下,神經網路的理論基礎不清晰、優化困難、可解釋性差等缺點更加凸顯,神經網路的研究又一次陷入低潮。
第五階段:深度學習的崛起
- 2006年,Hinton等人發現多層前饋神經網路可以先通過逐層預訓練,再用反向傳播演演算法進行精調的方式進行有效學習。
- 深度神經網路在語音識別和影象分類等任務上的巨大成功。
- 2013年,AlexNet:第一個現代深度折積網路模型,是深度學習技術
- 在影象分類上取得真正突破的開端。[第一個真正意義現代神經網路]
- AlexNet不用預訓練和逐層訓練,首次使用了很多現代深度網路的技術
- 隨著大規模平行計算以及GPU裝置的普及,計算機的計算能力得以大幅提高。此外,可供機器學習的資料規模也越來越大。在計算能力和資料規模的支援下,計算機已經可以訓練大規模的人工神經網路。
教學視訊傳送門:https://aistudio.baidu.com/aistudio/course/introduce/25876?directly=1&shared=1
原創作者:孤飛-部落格園
原文地址:https://www.cnblogs.com/ranxi169/p/16582854.html