通過重新構建Kubernetes來實現更具彈性的容器編排系統
通過重新構建Kubernetes來實現更具彈性的容器編排系統
譯自:rearchitecting-kubernetes-for-the-edge
摘要
近年來,kubernetes已經發展為容器編排的首要選擇。kubernetes主要面向雲環境,但新的邊緣場景要求效能、可用性和可延伸編排。kubernetes在etcd(一個強一致的鍵值儲存)中儲存了所有叢集資訊。我們發現規模較大的etcd叢集可以提供更高的可用性,但請求延遲也會顯著增加,吞吐量顯著下降。再加上大約30%的Kubernetes請求是寫入的,這直接影響了Kubernete的請求延遲和可用性,降低了其對邊緣的適用性。我們重新審視了強一致的需求,並提出了一個最終一致性的方案。該方案可以提供更高的效能、可用性和可延伸性,且能夠支援大部分對kubernetes的需求。目的是為了讓kubernetes更適用於對效能有嚴格要求,且需要動態伸縮的邊緣場景。
1 簡介
近年來,容器和相關的編排技術已經廣泛用於工業領域。kubernetes[12]儼然已經成為一個重要的資料中心解決方案。邊緣場景下普遍會涉及上千個使用有限CPU和RAM的節點,因此它們對效能、可用性以及可靠的編排能力有一定要求。Kubernetes已經廣泛應用於整個行業,其中59%的大型組織已經在生產中使用Kubernetes[15]。kubernetes的靈活性可以實現函數服務、儲存編排和公有云整合[7]等。這種採納度和靈活性使得Kubernetes成為一個有吸引力的邊緣部署平臺。kubernetes使用etcd[8]作為所有控制面元件的唯一可信源。這使得etcd成為所有請求路徑的關鍵因素。第二章介紹了Kubernetes和etcd的背景。
雖然在邊緣部署Kubernetes很有吸引力,但仍然存在一些挑戰。Kubernetes和etcd都可能是資源密集型的[9,11],因此傾向於將Kubernetes部署到邊緣[3,4,10]。相比雲資料中心,邊緣環境通常具有更慢的頻寬以及更高的網路連線延遲,尤其是到非本地服務的連線。這些環境可能會分佈在更大的範圍內,並且由於鄰近性,會對使用者互動做出更多響應,同時需要容忍多種型別的故障。由於這些嚴苛的條件,因此效能、可靠性和可延伸編排就成為其關鍵需求。第三章我們調研了etcd的效能限制,以及對可延伸性和kubernetes的影響。
Kubernetes依賴etcd,但其有限的可延伸性會導致邊緣的可用性和效率問題。Kubernetes受到根本設計決策的限制:依賴儲存的強一致性。第四章我們會審視用於提升邊緣效能、可用性和可延伸編排的設計決策。
如果不依賴強一致性,架構可能會相對容易一些,特別是在實現效能、可用性和可延伸性方面。第五和第六章會討論實現上的相關工作。
本論文的主要貢獻是:(1)解釋了etcd如何成為Kubernetes叢集的瓶頸,第二章;(2)大規模場景下驗證etcd的效能,並討論對可用性的影響,,第三章;(3)回到強一致性設計上,並提出使用最終一致性,第四章。
2 KUBERNETES和ETCD
Kubernetes 將容器進行分組管理,稱為Pods。Pods會被分配到工作節點,並使用本地守護行程(Kubelet)管理其生命週期。當需要在控制面實現如Pods和services副本時,會需要更多的資源。控制面由主節點的Pods構成,實現了核心功能,如排程和API server。
| request type | Count | percentage |
|---|---|---|
| Range | 1542 | 52.3 |
| Txn Range | 476 | 16.1 |
| Txn Put | 866 | 29.3 |
| Watch create | 67 | 2.3 |
| Total | 2951 | 100 |
表1:Etcd請求計數。範圍請求都是線性化的。忽略可忽略不計的請求。
這些控制面元件都是無狀態的,可以通過水平擴充套件來幫助提升效能和冗餘。期望的叢集狀態以及當前應用狀態、節點和其他資源都儲存在一個etcd叢集中。Kubernetes通常部署在一個具有高頻寬、低延遲網路的資料中心環境中。理想情況下,為了提高可靠性[9],可以部署在多個資料中心中,這需要在每個資料中心中同時執行主節點和etcd。但跨資料中心部署etcd需要在權衡其可用性和一致性,根據CAP理論[24],在網路分割區場景下,etcd犧牲了可用性來保證強一致性。
2.1 etcd
etcd是一個強一致的分散式鍵值儲存,它使用Raft一致性協定[33]來維護一致性和寫仲裁。作為Kubernetes的控制面元件,與其他控制面服務一樣,etcd會被部署在叢集的單獨機器或主機上。但由於存在與其他節點保證強一致性帶來的開銷,因此它並不是可以水平擴容的。推薦的etcd節點為3或5個,在保證高可用的時候減少強一致性帶來的開銷[14]。
表1劃分了到一個單節點etcd叢集的Kubernetes請求,這些請求用於做一些基本的Kubernetes操作(包括設定),平均執行10次。操作中會建立含3個Pods的deployment,擴容到10個副本,然後縮容到5個副本,最後刪除該deployment。這種驗證方式簡單描述了Kubernetes中deployment的擴縮容場景。Range 請求是通過多個鍵進行的GET操作,PUT是對單個鍵的寫入,這些請求也可以包含在事務中(txn)。一個watch create請求告訴etcd通知請求者所提供範圍內所有鍵的變更資訊。從這張表中,我們可以看到,Put佔了大約30%的總請求量,Put請求在叢集生存期內可能會按比例增加。在變更頻繁時,元件會依賴watch進行更新,而不是通過range請求輪詢。因此,Etcd對寫入的有效處理是Kubernetes正常執行的一個重要因素。
2.2 排程
本章看下如何排程一個ReplicaSet的一個新Pod(見圖1)。當變更一個Replicaset資源的replicas欄位時會觸發排程新的Pod。該值的變化可能源於故障節點、自動縮放器或手動縮放。步驟1和2中,ReplicaSet controller通過watch觀察到ReplicaSet資源產生了更新,並確定必要的後續動作,本場景下會建立一個新的Pod資源。步驟3和4可以看到Pod資源被寫入etcd。由於etcd的強一致性,步驟5要求大部分成員完成寫操作(寫仲裁)。
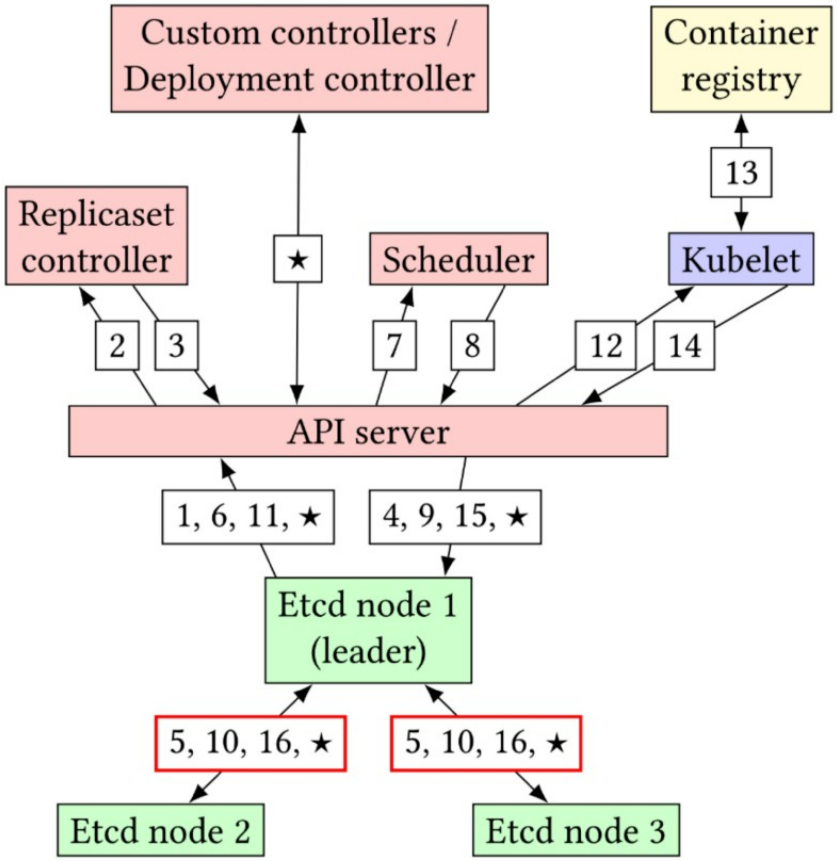
圖1:排程Pod的請求流。控制平面元件為紅色,etcd節點為綠色,節點本地元件為藍色,群集外部元件為黃色。
步驟6和7中,新的Pod資源會傳遞到排程器,這也是通過一個註冊的watch完成的,但此處watch的是Pod資源。現在Pod資源並不會指定哪個節點去執行。排程器會過濾出適合的節點,並選出合適的節點去執行該Pod。然後在步驟8和9中,排程器會將更新後的Pod資源(帶分配的節點)資訊寫入etcd。在步驟10中,需要再一次將資料傳遞給大部分成員。更新後的Pod資源會通知到相關節點上的Kubelet(步驟11和12)。至此Kubelet會開始啟動容器流程,包括從容器倉庫拉取容器映象(步驟13)。在啟動Pod過程中,會將事件寫入etcd(步驟14和15,以及相關的寫仲裁--步驟16)。
在完成這些步驟之後,就可以在節點上成功設定並執行Pod(由Kubelet管理)。後面會持續產生更多事件,如在指定新的副本數時會觸發ReplicaSet資源的更新。但這些事件價值並不大,因為ReplicaSet資源通常受Department資源的控制,這些事件反而增加了額外的通訊和延遲,類似地,Kubernetes自定義控制器和資源也會導致通訊和排程延遲顯著增加,並延遲Pod的初始化,在圖1中使用★來表示這些步驟。可以看到,很多步驟需要進行獨立的寫仲裁,這些步驟增加了Pod排程延遲,併成為影響可靠性和可用性的依賴鏈上的一部分。雖然etcd叢集中的寫仲裁是並行的,且整體延遲受限於最慢的節點,但大型叢集會加劇這種情況,由於主節點承受著更多的通訊負載,因此節點不太可能在相同的時間內執行寫操作。
3 etcd效能
在大型環境(如edge)中的etcd需要同時保證效能和高效的擴充套件性。本章會展示對etcd擴充套件性的初步驗證結果。
測試採用etcd官方的效能驗證工具來測試兩種不同的操作:put和線性range請求。在etcd中,線性讀必須返回叢集的共識值。每次測試只會使用單一的請求型別。
為了執行一定數量(3.4.13版本)的etcd節點,我們使用Docker來範例化etcd節點,並通過Docker網路組成具有安全通訊的叢集。每個容器的資源限制為2CPUs和1GB RAM,使用SSD作為儲存。主機為Linux,核心版本4.15.0,CPU為Intel Xeon 4112,含16核CPU以及196GB RAM。每個測試設定會重複執行10次,並給出這些重複的中間值。測試會涉及所有節點(不僅僅是主節點),每次執行都會使用1000個使用者端,每個使用者端會建立100條連線,總計100000個操作。目的是在一個沒有網路延遲的理想環境下提供一個最佳的場景來驗證etcd的效能和可延伸性。網路干擾會進一步增加系統的可變性和不穩定性,導致更多故障場景,如部分分割區[1,17]。
圖2a展示了通過一系列延遲開銷來達到強一致寫的目的,每次寫操作都需要保證將資料寫入大部分節點。同時讀延遲相對較低,避免該延遲影響到資料(到磁碟)的重新整理。隨著叢集規模的增加,主節點需要執行的同步工作也會增加,進而導致可見的效能下降。使用最終一致性儲存時,讀寫延遲曲線比較類似,並隨著叢集的擴充套件而降低(可以更有效地分散負載)。
圖2b展示了節點數目增加對吞吐量的影響。在這兩種測試場景下,大型etcd叢集規模都會導致嚴重的吞吐量下降。由於請求需要多數仲裁,因此會導致節點間產生大量請求,最終成為瓶頸並降低吞吐量。使用最終一致性儲存可以提升吞吐量,原因是不需要在節點之間協調請求[41]。
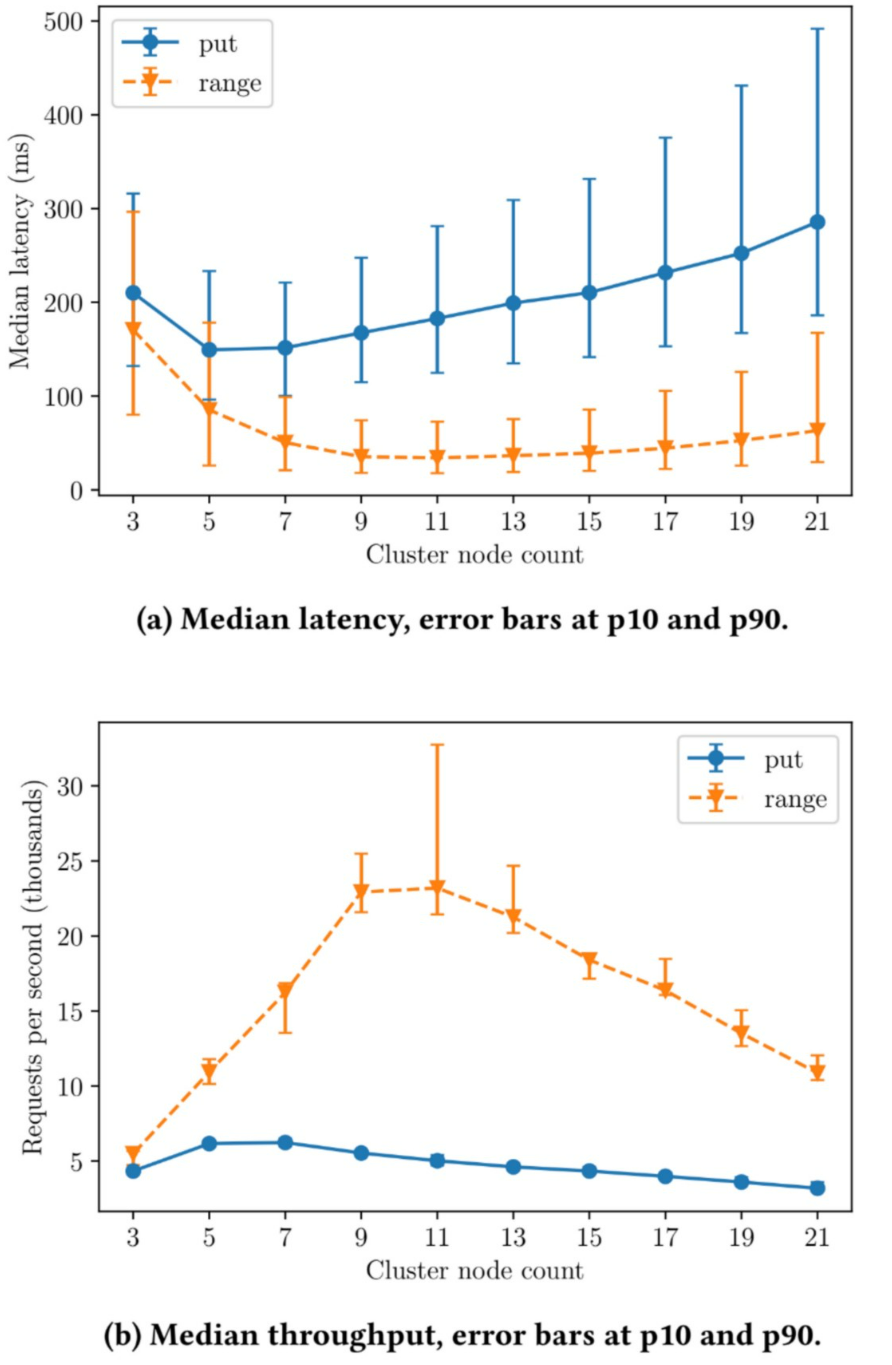
由於在擴充套件時存在效能限制,etcd需要權衡效能和可用性。這種可用性上的限制限制可能會導致Kubernetes叢集無法處理故障,或無法通過擴充套件服務來滿足需求。這些結論和佔相當比例的Kubernetes puts請求表明etcd和這類強一致性資料儲存在更苛刻的邊緣環境下是不夠的。
4 最終一致性儲存
本章介紹如何使用最終一致性儲存來替換etcd,以及相關的實現考量點。
4.1 etcd API
由於API server和etcd之間存在耦合,因此需要實現實現並暴露相同的API(儘管內部運作和保障有所不同)。這種方式可以確保不需要對Kubernetes的元件進行修改。
由於架構上的差異,提議的方式將暴露不同於etcd的API行為。
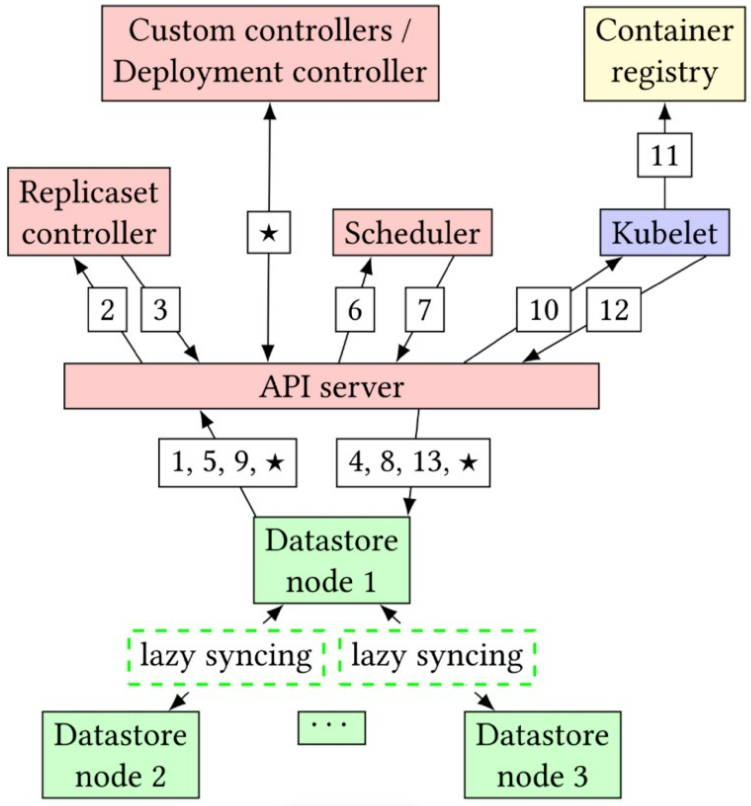
圖3:提議的資料儲存分配Pod的請求流。資料儲存節點之間的同步現在是延遲的,不會干擾請求的關鍵路徑。
例如,在提議的工作中,確定哪個節點是主節點是不明智的,相反,它可能會將每個節點作為領導者。
4.2 延遲同步
為了實現API的功能來獲得低延遲,提議的資料儲存需要支援單節點的讀寫,而無需立即與其他節點建立通訊。這可能會因為並行寫入其他節點而引入資料衝突。無衝突複製資料型別(CRDTs)[37]可以以延遲同步的方式解決資料衝突。由於關鍵路徑中的資料儲存節點之間沒有請求,這樣就可以在大規模叢集下快速響應API server。
CRDTs 有兩種主要的型別:基於狀態的和基於操作的。為了同步基於狀態的兩個副本,CRDTs 會傳輸整個本地狀態來與遠端狀態進行合併。相反,對於基於操作的CRDTs,只會給遠端傳輸下發的操作。相比於基於狀態的CRDTs ,基於操作的CRDTs 的頻寬要求更小 [18, 23, 40]。
Kubernetes使用protobuf格式檔案來宣告儲存到etcd種的資源格式,然後解析為Json。由於這些資源還不是CRDTs,因此只會在儲存中進行轉換,該過程可能會需要計算新值和儲存值的區別,並匯出相應的操作到CRDT。通過這些操作和對資料格式的瞭解,我們可以使用JSON CRDT[27]來提供對Kubernetes資源的最終一致性。最近的工作中[28],我們在不可信環境的不同節點的單次往返同步中引入了低延遲。這可以應用於CRDTs,進而為邊緣提供高效的同步方式。
4.3 對Kubernetes的影響
從表1中,我們看到事務在etcd的請求中佔很大的比例。由於沒有了一致性,提議的資料儲存中的事務在執行時間內僅會操作目標儲存的資料。這意味著可能會操作不同於其他節點的舊資料。但概率有界過時[19]表明最終一致性系統仍然可以顯示資料的最新更新。此外,由於Kubernetes元件的控制迴路,任何錯誤都可以被及時矯正。例如,如果兩個不同的節點同時增加了一個ReplicaSet資源,此時可能會排程兩個新的Pods。這些資料節點同步時,可能會將這些變更合併為總計增加兩個副本。Kubernetes控制器會觀察到新的值,然後決定是否可以保持或減少副本數。
5 架構實現
由於提議的資料儲存提升了可延伸性且去除了一致性的要求,因此,它可以使用自動擴縮容。這樣可以更加優化資源使用。如果資料儲存部署在Kubernetes叢集內部,那麼可以使用原生的水平擴縮容器作為低複雜度的解決方案。目前的etcd並沒有使用這種特性,原因是存在與強一致性系統耦合的縮放限制。
而提議的資料儲存可以通過可延伸性來提高可用性,還可以使分割區資料中心保持可操作性。快速響應故障或需求變更是一種重要的運維優勢,因為系統故障通常會導致複雜問題[1]。
在邊緣環境中,提議的資料儲存可以隨Kubernetes叢集的規則擴大而擴大。可以通過對無狀態的控制面進行水平擴容來降低延遲,特別適用於排程。而etcd由於無法擴充套件到這個程度,因而對請求延遲的限制也相對較低。
通過這種可延伸性,可以很靈活地將(帶資料儲存的)控制面部署到每個工作節點,從而使Kubernetes去中心化。當前的Kubernetes排程器會被一個本地優先的分散式排程器[34, 38, 39, 42]取代。重構意味著在排程過程中,任何請求無需離開始發節點,大大減少了排程延遲。通過這種方式可以實現高效的反應式自動擴縮容,並可以實現原生的函數即服務。
6 相關工作
新的邊緣場景包括5G網路[20],網路計算[30]和彈性CDN[31]。所有這些場景都要求在邊緣保證低延遲和可靠性的前提下編排大量機器。Kubernetes在邊緣編排中已經非常流行[21,22]。Kubernetes的高效能和高可用性,使其非常適合從這些場景。
聯邦Kubernetes[5]會在叢集之間分配工作,由負責在成員叢集之間分配任務的主機叢集組成。這種中心化的方式存在與大型但叢集類似的問題,這導致了新的針對使用CRDT的分散式聯邦模型的研究[32]。它將叢集本地狀態與聯邦狀態分開,只關注聯邦狀態。 相反,我們的工作解決了叢集區域性狀態的問題。
DOCMA [26]是一個新的基於微服務的容器編排器。它實現了一種去中心化的架構,可以在上千個節點中進行服務部署。但它缺少Kubernetes可以提供的很多特性。DOCMA 表明區中心話的編排具有更高的擴充套件性,並提供了冗餘。
針對邊緣環境提出的Kubernetes架構各不相同,但都受到etcd中集中狀態的限制。一些提議中會將主節點和etcd部署在一個資料中心中,只將工作節點部署在雲端[3]。但到雲端的網路可能延遲較高且不穩定,這意味著需要做進一步設計來保證邊緣的健壯性[2,6]。其他提議會將所有元件部署在邊緣,包括資料中心[4],但這種方式可能會收到資源的限制。
軟體定義網路中有很多圍繞控制面狀態一致性的研究[25,29,36]。自適應一致性[36]和基於資料分割區的一致性需求[29]可能會有助於增強我們的資料儲存。或者,如果強一致性系統可以避免多數仲裁,就可以產生出更具可延伸性的系統[16,35]。但這些都需要在延遲和一致性之間進行權衡。相反,我們專注於最小化延遲,使之可以在具有挑戰性的邊緣環境中提供效能和可用性。
7 總結
本文強調了Kubernetes對etcd的依賴關係,以及導致可用性降低和排程延遲的因素。我們觀察到etcd會成為叢集擴充套件的瓶頸,由於其在大規模下的效能限制,會影響排程延遲和整個系統的可用性。我們的結論支援我們的觀察到的現象,即依賴資料儲存中的強一致性限制了Kubernetes的效能、可用性和可延伸性。.為了解決這些問題,我們建議建立一個分散化的、最終一致的、專門針對Kubernetes的儲存。這種設計還為邊緣環境帶來了重構Kubernetes的機會,從而提高了效能、可用性和可延伸性。 這些改進可以降低延遲,支援在邊緣進行更大規模的部署,可以為編排平臺的未來提供相關資訊,以分散的方式來實現可用性和效能。
參照
[1] 2020. A Byzantine failure in the real world. Retrieved January 13, 2021 from https://blog.cloudflare.com/a-byzantine-failure-in-the-real-world/
[2] 2020. An open platform that extends upstream Kubernetes to Edge. Retrieved January 13, 2021 from https://openyurt.io/en-us/index.html
[3] 2020. K3s: The certified Kubernetes distribution built for IoT & Edge computing. Retrieved January 13, 2021 from https://k3s.io/
[4] 2020. KubeEdge An open platform to enable Edge computing. Retrieved January 13, 2021 from https://kubeedge.io/en/
[5] 2020. KubeFed: Kubernetes Cluster Federation. Retrieved January 13, 2021 from https://github.com/kubernetes-sigs/kubefed
[6] 2020. SuperEdge: An edge-native container management system for edge computing. Retrieved January 13, 2021 from https://github.com/superedge/superedge
[7] 2021. Cloud Controller Manager. Retrieved February 09, 2021 from https:// kubernetes.io/docs/concepts/architecture/cloud-controller/
[8] 2021. Etcd: A distributed, reliable key-value store for the most critical data of a distributed system. Retrieved February 09, 2021 from https://etcd.io/
[9] 2021. Etcd: Hardware recommendations. Retrieved February 09, 2021 from https://etcd.io/docs/v3.4.0/op-guide/hardware
[10] 2021. K0s: The Simple, Solid & Certified Kubernetes Distribution. Retrieved January 13, 2021 from https://k0sproject.io/
[11] 2021. Kubernetes kubeadm resource requirements. Retrieved February 16, 2021 from https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ create-cluster-kubeadm/
[12] 2021. Kubernetes: Production-Grade Container Orchestration. Retrieved February 09, 2021 from https://kubernetes.io/
[13] 2021. Rook: Open-Source, Cloud-Native Storage for Kubernetes. Retrieved February 09, 2021 from https://rook.io/
[14] 2021. Scaling up etcd clusters. Retrieved February 09, 2021 from https://kubernetes.io/docs/tasks/administer-cluster/configure-upgradeetcd/#scaling-up-etcd-clusters
[15] 2021. Why Large Organizations Trust Kubernetes. Retrieved March 31, 2021 from https://tanzu.vmware.com/content/blog/why-large-organizations-trustkubernetes
[16] Ailidani Ailijiang, Aleksey Charapko, Murat Demirbas, and Tevfik Kosar. 2020. WPaxos: Wide Area Network Flexible Consensus. IEEE Transactions on Parallel and Distributed Systems 31, 1 (2020), 211–223. https://doi.org/10.1109/TPDS.2019. 2929793
[17] Mohammed Alfatafta, Basil Alkhatib, Ahmed Alquraan, and Samer Al-Kiswany. 2020. Toward a Generic Fault Tolerance Technique for Partial Network Partitioning. In Operating Systems Design and Implementation (OSDI) 2020.
[18] Paulo Sèrgio Almeida, Ali Shoker, and Carlos Baquero. 2015. Efficient state-based CRDTs by delta-mutation. https://doi.org/10.1007/978-3-319-26850-7_5
[19] Peter Bailis, Shivaram Venkataraman, Michael J. Franklin, Joseph M. Hellerstein, and Ion Stoica. 2012. Probabilistically Bounded Staleness for Practical Partial Quorums. Proceedings of the VLDB Endowment 5, 8 (April 2012), 776–787. https: https://doi.org/10.14778/2212351.2212359
[20] Leonardo Bonati, Michele Polese, Salvatore D’Oro, Stefano Basagni, and Tommaso Melodia. 2020. Open, Programmable, and Virtualized 5G Networks: State-ofthe-Art and the Road Ahead. Computer Networks 182 (2020), 107516. https: https://doi.org/10.1016/j.comnet.2020.107516
[21] Hung-Li Chen and Fuchun J. Lin. 2019. Scalable IoT/M2M Platforms Based on Kubernetes-Enabled NFV MANO Architecture. In International Conference on Internet of Things (iThings) 2019. https://doi.org/10.1109/iThings/GreenCom/ CPSCom/SmartData.2019.00188
[22] Corentin Dupont, Raffaele Giaffreda, and Luca Capra. 2017. Edge computing in IoT context: Horizontal and vertical Linux container migration. In Global Internet of Things Summit (GIoTS) 2017. https://doi.org/10.1109/GIOTS.2017.8016218
[23] Vitor Enes, Paulo S. Almeida, Carlos Baquero, and João Leitão. 2019. Efficient Synchronization of State-Based CRDTs. In IEEE International Conference on Data Engineering (ICDE) 2019. https://doi.org/10.1109/ICDE.2019.00022
[24] Armando Fox and Eric A. Brewer. 1999. Harvest, yield, and scalable tolerant systems. In Hot Topics in Operating Systems (HotOS) 1999. https://doi.org/10. 1109/HOTOS.1999.798396
[25] Soheil Hassas Yeganeh and Yashar Ganjali. 2012. Kandoo: A Framework for Efficient and Scalable Offloading of Control Applications. In Hot Topics in Software Defined Networks (HotSDN) 2012. https://doi.org/10.1145/2342441.2342446
[26] Lara L. Jiménez and Olov Schelén. 2019. DOCMA: A Decentralized Orchestrator for Containerized Microservice Applications. In 2019 IEEE Cloud Summit. https: https://doi.org/10.1109/CloudSummit47114.2019.00014
[27] Martin Kleppmann and Alastair R. Beresford. 2017. A Conflict-Free Replicated JSON Datatype. IEEE Transactions on Parallel and Distributed Systems 28, 10 (2017), 2733–2746. https://doi.org/10.1109/TPDS.2017.2697382
[28] Martin Kleppmann and Heidi Howard. 2020. Byzantine Eventual Consistency and the Fundamental Limits of Peer-to-Peer Databases. arXiv:2012.00472 [cs.DC]
[29] Teemu Koponen, Martin Casado, Natasha Gude, Jeremy Stribling, Leon Poutievski, Min Zhu, Rajiv Ramanathan, Yuichiro Iwata, Hiroaki Inoue, Takayuki Hama,and Scott Shenker. 2010. Onix: A Distributed Control Platform for Large-Scale Production Networks. In Operating Systems Design and Implementation (OSDI) 2010.
[30] Michał Król, Spyridon Mastorakis, David Oran, and Dirk Kutscher. 2019. Compute First Networking: Distributed Computing Meets ICN. In Information-Centric Networking (ICN) 2019. https://doi.org/10.1145/3357150.3357395
[31] Simon Kuenzer, Anton Ivanov, Filipe Manco, Jose Mendes, Yuri Volchkov, Florian Schmidt, Kenichi Yasukata, Michio Honda, and Felipe Huici. 2017. Unikernels Everywhere: The Case for Elastic CDNs. In Virtual Execution Environments (VEE) 2017. https://doi.org/10.1145/3050748.3050757
[32] Lars Larsson, Harald Gustafsson, Cristian Klein, and Erik Elmroth. 2020. Decentralized Kubernetes Federation Control Plane. In Utility and Cloud Computing (UCC) 2020. https://doi.org/10.1109/UCC48980.2020.00056
[33] Diego Ongaro and John Ousterhout. 2014. In Search of an Understandable Consensus Algorithm. In USENIX Annual Technical Conference (USENIX ATC) 2014.
[34] Xiaoqi Ren, Ganesh Ananthanarayanan, Adam Wierman, and Minlan Yu. 2015. Hopper: Decentralized Speculation-Aware Cluster Scheduling at Scale. In Special Interest Group on Data Communication (SIGCOMM) 2015. https://doi.org/10.1145/ 2785956.2787481
[35] Denis Rystsov. 2018. CASPaxos: Replicated State Machines without logs. arXiv:1802.07000 [cs.DC][36]
[36] Ermin Sakic, Fragkiskos Sardis, Jochen W. Guck, and Wolfgang Kellerer. 2017. Towards adaptive state consistency in distributed SDN control plane. In IEEE International Conference on Communications (ICC) 2017. https://doi.org/10.1109/ ICC.2017.7997164
[37] Marc Shapiro, Nuno Preguiça, Carlos Baquero, and Marek Zawirski. 2011. Conflict-Free Replicated Data Types. In Stabilization, Safety, and Security of Distributed Systems.
[38] John A Stankovic. 1984. Simulations of three adaptive, decentralized controlled, job scheduling algorithms. Computer Networks (1976) 8, 3 (1984), 199–217. https: https://doi.org/10.1016/0376-5075(84)90048-5
[39] John A. Stankovic. 1985. Stability and Distributed Scheduling Algorithms. IEEE Transactions on Software Engineering SE-11, 10 (1985), 1141–1152. https://doi. org/10.1109/TSE.1985.231862
[40] Albert van der Linde, João Leitão, and Nuno Preguiça. 2016. Δ-CRDTs: Making