在Go中如何正確重試請求
轉載請宣告出處哦~,本篇文章釋出於luozhiyun的部落格:https://www.luozhiyun.com/archives/677
我們平時在開發中肯定避不開的一個問題是如何在不可靠的網路服務中實現可靠的網路通訊,其中 http 請求重試是經常用的技術。但是 Go 標準庫 net/http 實際上是沒有重試這個功能的,所以本篇文章主要講解如何在 Go 中實現請求重試。
概述
一般而言,對於網路通訊失敗的處理分為以下幾步:
- 感知錯誤。通過不同的錯誤碼來識別不同的錯誤,在HTTP中status code可以用來識別不同型別的錯誤;
- 重試決策。這一步主要用來減少不必要的重試,比如HTTP的4xx的錯誤,通常4xx表示的是使用者端的錯誤,這時候使用者端不應該進行重試操作,或者在業務中自定義的一些錯誤也不應該被重試。根據這些規則的判斷可以有效的減少不必要的重試次數,提升響應速度;
- 重試策略。重試策略就包含了重試間隔時間,重試次數等。如果次數不夠,可能並不能有效的覆蓋這個短時間故障的時間段,如果重試次數過多,或者重試間隔太小,又可能造成大量的資源(CPU、記憶體、執行緒、網路)浪費。這個我們下面再說;
- 對衝策略。對衝是指在不等待響應的情況主動傳送單次呼叫的多個請求,然後取首個返回的回包。這個概念是 grpc 中的概念,我把它也借用過來;
- 熔斷降級;如果重試之後還是不行,說明這個故障不是短時間的故障,而是長時間的故障。那麼可以對服務進行熔斷降級,後面的請求不再重試,這段時間做降級處理,減少沒必要的請求,等伺服器端恢復了之後再進行請求,這方面的實現很多 go-zero 、 sentinel 、hystrix-go,也蠻有意思的;
重試策略
重試策略可以分為很多種,一方面要考慮到本次請求時長過長而影響到的業務忍受度,另一方面要考慮到重試會對下游服務產生過多的請求而帶來的影響,總之就是一個trade-off的問題。
所以對於重試演演算法,一般是在重試之間加一個 gap 時間,感興趣的朋友也可以去看看這篇文章。結合我們自己平時的實踐加上這篇文章的演演算法一般可以總結出以下幾條規則:
- 線性間隔(Linear Backoff):每次重試間隔時間是固定的進行重試,如每1s重試一次;
- 線性間隔+隨機時間(Linear Jitter Backoff):有時候每次重試間隔時間一致可能會導致多個請求在同一時間請求,那麼我們可以加入一個隨機時間,線上性間隔時間的基礎上波動一個百分比的時間;
- 指數間隔(Exponential Backoff):每次間隔時間是2指數型的遞增,如等 3s 9s 27s後重試;
- 指數間隔+隨機時間(Exponential Jitter Backoff):這個就和第二個類似了,在指數遞增的基礎上新增一個波動時間;
上面有兩種策略都加入了擾動(jitter),目的是防止驚群問題 (Thundering Herd Problem)的發生。
In computer science, the thundering herd problem occurs when a large number of processes or threads waiting for an event are awoken when that event occurs, but only one process is able to handle the event. When the processes wake up, they will each try to handle the event, but only one will win. All processes will compete for resources, possibly freezing the computer, until the herd is calmed down again
所謂驚群問題當許多程序都在等待被同一事件喚醒的時候,當事件發生後最後只有一個程序能獲得處理。其餘程序又造成阻塞,這會造成上下文切換的浪費。所以加入一個隨機時間來避免同一時間同時請求伺服器端還是很有必要的。
使用 net/http 重試所帶來的問題
重試這個操作其實對於 Go 來說其實還不能直接加一個 for 迴圈根據次數來進行,對於 Get 請求重試的時候沒有請求體,可以直接進行重試,但是對於 Post 請求來說需要把請求體放到Reader 裡面,如下:
req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello"))
伺服器端收到請求之後就會從這個Reader中呼叫Read()函數去讀取資料,通常情況當伺服器端去讀取資料的時候,offset會隨之改變,下一次再讀的時候會從offset位置繼續向後讀取。所以如果直接重試,會出現讀不到 Reader的情況。
我們可以先弄一個例子:
func main() {
go func() {
http.HandleFunc("/", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
time.Sleep(time.Millisecond * 20)
body, _ := ioutil.ReadAll(r.Body)
fmt.Printf("received body with length %v containing: %v\n", len(body), string(body))
w.WriteHeader(http.StatusOK)
}))
http.ListenAndServe(":8090", nil)
}()
fmt.Print("Try with bare strings.Reader\n")
retryDo(req)
}
func retryDo() {
originalBody := []byte("abcdefghigklmnopqrst")
reader := strings.NewReader(string(originalBody))
req, _ := http.NewRequest("POST", "http://localhost:8090/", reader)
client := http.Client{
Timeout: time.Millisecond * 10,
}
for {
_, err := client.Do(req)
if err != nil {
fmt.Printf("error sending the first time: %v\n", err)
}
time.Sleep(1000)
}
}
// output:
error sending the first time: Post "http://localhost:8090/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0
error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0
received body with length 20 containing: abcdefghigklmnopqrst
error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0
....
在上面這個例子中,在使用者端設值了 10ms 的超時時間。在伺服器端模擬請求處理超時情況,先sleep 20ms,然後再讀請求資料,這樣必然會超時。
當再次請求的時候,發現 client 請求的 Body 資料並不是我們預期的20個長度,而是 0,導致了 err。因此需要將Body這個Reader 進行重置,如下:
func resetBody(request *http.Request, originalBody []byte) {
request.Body = io.NopCloser(bytes.NewBuffer(originalBody))
request.GetBody = func() (io.ReadCloser, error) {
return io.NopCloser(bytes.NewBuffer(originalBody)), nil
}
}
上面這段程式碼中,我們使用 io.NopCloser 對請求的 Body 資料進行了重置,避免下次請求的時候出現非預期的異常。
那麼相對於上面簡陋的例子,還可以完善一下,加上我們上面說的 StatusCode 重試判斷、重試策略、重試次數等等,可以寫成這樣:
func retryDo(req *http.Request, maxRetries int, timeout time.Duration,
backoffStrategy BackoffStrategy) (*http.Response, error) {
var (
originalBody []byte
err error
)
if req != nil && req.Body != nil {
originalBody, err = copyBody(req.Body)
resetBody(req, originalBody)
}
if err != nil {
return nil, err
}
AttemptLimit := maxRetries
if AttemptLimit <= 0 {
AttemptLimit = 1
}
client := http.Client{
Timeout: timeout,
}
var resp *http.Response
//重試次數
for i := 1; i <= AttemptLimit; i++ {
resp, err = client.Do(req)
if err != nil {
fmt.Printf("error sending the first time: %v\n", err)
}
// 重試 500 以上的錯誤碼
if err == nil && resp.StatusCode < 500 {
return resp, err
}
// 如果正在重試,那麼釋放fd
if resp != nil {
resp.Body.Close()
}
// 重置body
if req.Body != nil {
resetBody(req, originalBody)
}
time.Sleep(backoffStrategy(i) + 1*time.Microsecond)
}
// 到這裡,說明重試也沒用
return resp, req.Context().Err()
}
func copyBody(src io.ReadCloser) ([]byte, error) {
b, err := ioutil.ReadAll(src)
if err != nil {
return nil, ErrReadingRequestBody
}
src.Close()
return b, nil
}
func resetBody(request *http.Request, originalBody []byte) {
request.Body = io.NopCloser(bytes.NewBuffer(originalBody))
request.GetBody = func() (io.ReadCloser, error) {
return io.NopCloser(bytes.NewBuffer(originalBody)), nil
}
}
對衝策略
上面講的是重試的概念,那麼有時候我們介面只是偶然會出問題,並且我們的下游服務並不在乎多請求幾次,那麼我們可以借用 grpc 裡面的概念:對衝策略(Hedged requests)。
對衝是指在不等待響應的情況主動傳送單次呼叫的多個請求,然後取首個返回的回包。對衝和重試的區別點主要在:對衝在超過指定時間沒有響應就會直接發起請求,而重試則必須要伺服器端響應後才會發起請求。所以對衝更像是比較激進的重試策略。
使用對衝的時候需要注意一點是,因為下游服務可能會做負載均衡策略,所以要求請求的下游服務一般是要求冪等的,能夠在多次並行請求中是安全的,並且是符合預期的。
對衝請求一般是用來處理「長尾」請求的,關於」長尾「請求的概念可以看這篇文章:https://segmentfault.com/a/1190000039978117
並行模式的處理
因為對衝重試加上了並行的概念,要用到 goroutine 來並行請求,所以我們可以把資料封裝到 channel 裡面來進行訊息的非同步處理。
並且由於是多個goroutine處理訊息,我們需要在每個goroutine處理完畢,但是都失敗的情況下返回err,不能直接由於channel等待卡住主流程,這一點十分重要。
但是由於在 Go 中是無法獲取每個 goroutine 的執行結果的,我們又只關注正確處理結果,需要忽略錯誤,所以需要配合 WaitGroup 來實現流程控制,範例如下:
func main() {
totalSentRequests := &sync.WaitGroup{}
allRequestsBackCh := make(chan struct{})
multiplexCh := make(chan struct {
result string
retry int
})
go func() {
//所有請求完成之後會close掉allRequestsBackCh
totalSentRequests.Wait()
close(allRequestsBackCh)
}()
for i := 1; i <= 10; i++ {
totalSentRequests.Add(1)
go func() {
// 標記已經執行完
defer totalSentRequests.Done()
// 模擬耗時操作
time.Sleep(500 * time.Microsecond)
// 模擬處理成功
if random.Intn(500)%2 == 0 {
multiplexCh <- struct {
result string
retry int
}{"finsh success", i}
}
// 處理失敗不關心,當然,也可以加入一個錯誤的channel中進一步處理
}()
}
select {
case <-multiplexCh:
fmt.Println("finish success")
case <-allRequestsBackCh:
// 到這裡,說明全部的 goroutine 都執行完畢,但是都請求失敗了
fmt.Println("all req finish,but all fail")
}
}
從上面這段程式碼看為了進行流程控制,多用了兩個 channel :totalSentRequests 、allRequestsBackCh,多用了一個 goroutine 非同步關停 allRequestsBackCh,才實現的流程控制,實在太過於麻煩,有新的實現方案的同學不妨和我探討一下。
除了上面的並行請求控制的問題,對於對衝重試來說,還需要注意的是,由於請求不是序列的,所以 http.Request 的上下文會變,所以每次請求前需要 clone 一次 context,保證每個不同請求的 context 是獨立的。但是每次 clone 之後 Reader 的offset位置又變了,所以我們還需要進行重新 reset:
func main() {
req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello"))
req2 := req.Clone(req.Context())
contents, _ := io.ReadAll(req.Body)
contents2, _ := io.ReadAll(req2.Body)
fmt.Printf("First read: %v\n", string(contents))
fmt.Printf("Second read: %v\n", string(contents2))
}
//output:
First read: hello
Second read:
所以結合一下上面的例子,我們可以將對衝重試的程式碼變為:
func retryHedged(req *http.Request, maxRetries int, timeout time.Duration,
backoffStrategy BackoffStrategy) (*http.Response, error) {
var (
originalBody []byte
err error
)
if req != nil && req.Body != nil {
originalBody, err = copyBody(req.Body)
}
if err != nil {
return nil, err
}
AttemptLimit := maxRetries
if AttemptLimit <= 0 {
AttemptLimit = 1
}
client := http.Client{
Timeout: timeout,
}
// 每次請求copy新的request
copyRequest := func() (request *http.Request) {
request = req.Clone(req.Context())
if request.Body != nil {
resetBody(request, originalBody)
}
return
}
multiplexCh := make(chan struct {
resp *http.Response
err error
retry int
})
totalSentRequests := &sync.WaitGroup{}
allRequestsBackCh := make(chan struct{})
go func() {
totalSentRequests.Wait()
close(allRequestsBackCh)
}()
var resp *http.Response
for i := 1; i <= AttemptLimit; i++ {
totalSentRequests.Add(1)
go func() {
// 標記已經執行完
defer totalSentRequests.Done()
req = copyRequest()
resp, err = client.Do(req)
if err != nil {
fmt.Printf("error sending the first time: %v\n", err)
}
// 重試 500 以上的錯誤碼
if err == nil && resp.StatusCode < 500 {
multiplexCh <- struct {
resp *http.Response
err error
retry int
}{resp: resp, err: err, retry: i}
return
}
// 如果正在重試,那麼釋放fd
if resp != nil {
resp.Body.Close()
}
// 重置body
if req.Body != nil {
resetBody(req, originalBody)
}
time.Sleep(backoffStrategy(i) + 1*time.Microsecond)
}()
}
select {
case res := <-multiplexCh:
return res.resp, res.err
case <-allRequestsBackCh:
// 到這裡,說明全部的 goroutine 都執行完畢,但是都請求失敗了
return nil, errors.New("all req finish,but all fail")
}
}
熔斷 & 降級
因為在我們使用 http 呼叫的時候,呼叫的外部服務很多時候其實並不可靠,很有可能因為外部的服務問題導致自身服務介面呼叫等待,從而呼叫時間過長,產生大量的呼叫積壓,慢慢耗盡服務資源,最終導致服務呼叫雪崩的發生,所以在服務中使用熔斷降級是非常有必要的一件事。
其實熔斷降級的概念總體上來說,實現都差不多。核心思想就是通過全域性的計數器,用來統計呼叫次數、成功/失敗次數。通過統計的計數器來判斷熔斷器的開關,熔斷器的狀態由三種狀態表示:closed、open、half open,下面借用了 sentinel 的圖來表示三者的關係:
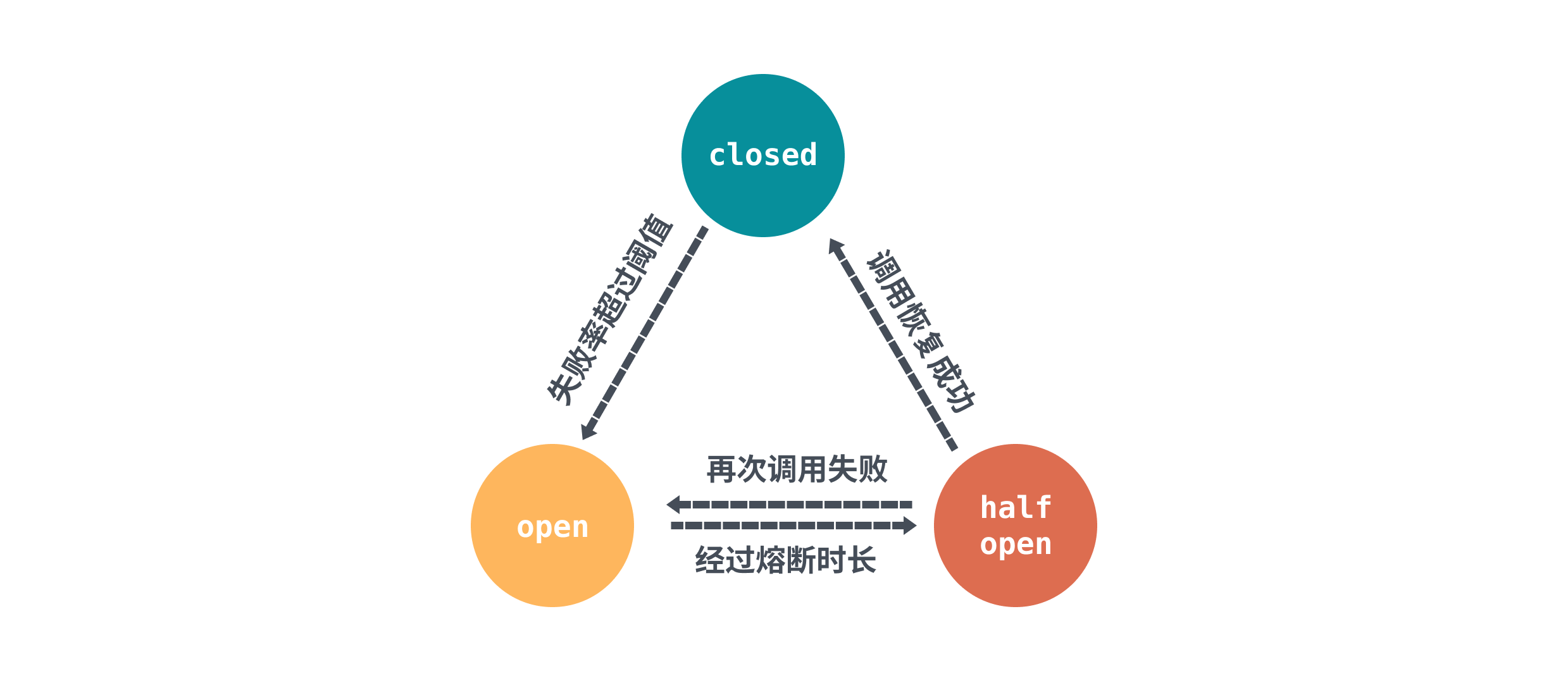
首先初始狀態是closed,每次呼叫都會經過計數器統計總次數和成功/失敗次數,然後在達到一定閾值或條件之後熔斷器會切換到 open狀態,發起的請求會被拒絕。
熔斷器規則中會設定一個熔斷超時重試的時間,經過熔斷超時重試時長後熔斷器會將狀態置為 half-open 狀態。這個狀態對於 sentinel 來說會發起定時探測,對於 go-zero 來說會允許通過一定比例的請求,不管是主動定時探測,還是被動通過的請求呼叫,只要請求的結果返回正常,那麼就需要重置計數器恢復到 closed 狀態。
一般而言會支援兩種熔斷策略:
- 錯誤比率:熔斷時間視窗內的請求數閾值錯誤率大於錯誤率閾值,從而觸發熔斷。
- 平均 RT(響應時間):熔斷時間視窗內的請求數閾值大於平均 RT 閾值,從而觸發熔斷。
比如我們使用 hystrix-go 來處理我們的服務介面的熔斷,可以結合我們上面說的重試從而進一步保障我們的服務。
hystrix.ConfigureCommand("my_service", hystrix.CommandConfig{
ErrorPercentThreshold: 30,
})
_ = hystrix.Do("my_service", func() error {
req, _ := http.NewRequest("POST", "http://localhost:8090/", strings.NewReader("test"))
_, err := retryDo(req, 5, 20*time.Millisecond, ExponentialBackoff)
if err != nil {
fmt.Println("get error:%v",err)
return err
}
return nil
}, func(err error) error {
fmt.Printf("handle error:%v\n", err)
return nil
})
上面這個例子中就利用 hystrix-go 設定了最大錯誤百分比等於30,超過這個閾值就會進行熔斷。
總結
這篇文章從介面呼叫出發,探究了重試的幾個要點,講解了重試的幾種策略;然後在實踐環節中講解了直接使用 net/http重試會有什麼問題,對於對衝策略使用 channel 加上 waitgroup 來實現並行請求控制;最後使用 hystrix-go 來對故障服務進行熔斷,防止請求堆積引起資源耗盡的問題。
Reference
https://github.com/sethgrid/pester
https://juejin.cn/post/6844904105354199047
https://github.com/ma6174/blog/issues/11
https://aws.amazon.com/cn/blogs/architecture/exponential-backoff-and-jitter/
https://medium.com/@trongdan_tran/circuit-breaker-and-retry-64830e71d0f6
https://www.lixueduan.com/post/grpc/09-retry/
https://en.wikipedia.org/wiki/Thundering_herd_problem
https://go-zero.dev/cn/docs/blog/governance/breaker-algorithms/
https://sre.google/sre-book/handling-overload/
https://sentinelguard.io/zh-cn/docs/golang/circuit-breaking.html
https://github.com/afex/hystrix-go
https://segmentfault.com/a/1190000039978117
