Mybatis完整版詳解
一、簡介
1.什麼是MyBatis
-
MyBatis 是一款優秀的持久層框架
-
它支援自定義 SQL、儲存過程以及高階對映。
-
MyBatis 免除了幾乎所有的 JDBC 程式碼以及設定引數和獲取結果集的工作。
-
MyBatis 可以通過簡單的 XML 或註解來設定和對映原始型別、介面和 Java POJO(Plain Old Java Objects,普通老式 Java 物件)為資料庫中的記錄。
-
MyBatis本是apache的一個開源專案iBatis,2010年這個專案由apache software foundation遷移到了google code,並且改名為MyBatis。
-
2013年11月遷移到Github。
(1)如何獲得MyBatis
-
maven倉庫
<dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.10</version> </dependency>
2.持久化
資料持久化
-
持久化就是將程式的資料在持久狀態和瞬時狀態轉化的過程
-
記憶體:斷電即失
-
資料庫(jdbc),io檔案持久化
為什麼需要持久化
-
有一些物件,不能讓它丟掉
-
記憶體太貴了
3.持久層
Dao層,Service層,Controller層 什麼叫層-
完成持久化工作的程式碼塊
-
層是界限十分明顯的
4.為什麼需要Mybatis
-
幫助程式設計師將資料存入到資料庫中
-
方便
-
傳統的JDBC程式碼太複雜了,Mybatis對其進行了簡化,
二、第一個Mybatis程式
思路:搭建環境-->匯入Mybatis-->編寫程式碼-->測試1.搭建環境
搭建一個資料庫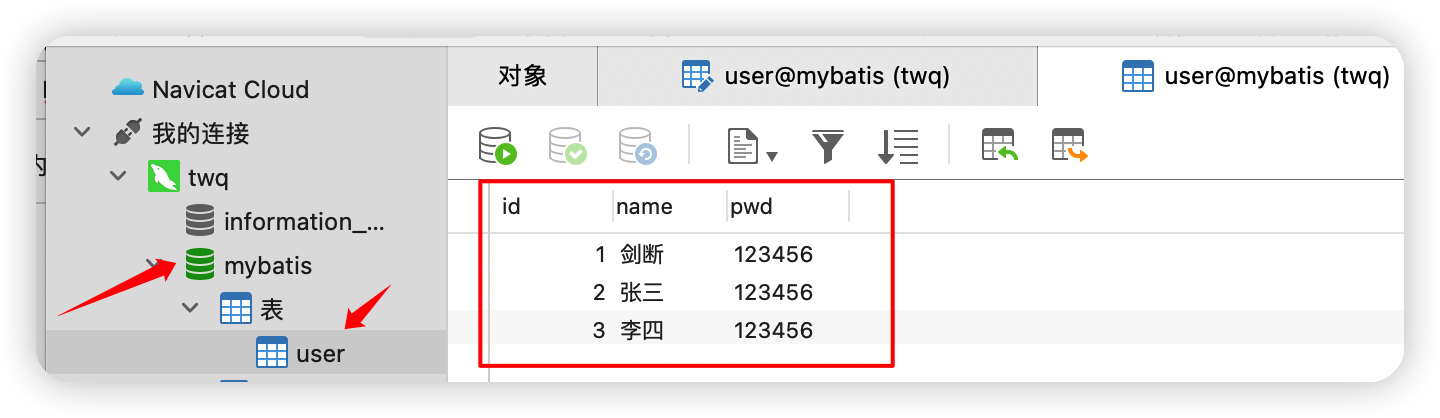
新建一個maven專案,並匯入maven依賴,要注意匯入mybatis時需要手動開啟Tomcat的bin目錄下startup.sh(只針對本機,Windows開啟startup.bat)
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
</dependency>
</dependencies>
2.建立一個模組
編寫mybatis的核心組態檔
mybatis-config.xml檔案程式碼 <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--核心組態檔-->
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!-- &在xml檔案中與符號需要這樣來跳脫-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=Asia/Shanghai&useSSL=true&useUnicode=true&characterEncoding=utf8"/>
<property name="username" value="root"/>
<property name="password" value="root123456"/>
</dataSource>
</environment>
</environments>
<!-- 每一個mapper.xml都需要在Mybatis核心組態檔中註冊-->
<mappers>
<mapper resource="com/tang/dao/UserMapper.xml"/>
</mappers>
</configuration>
注意:這裡如果沒寫載入驅動的話會報以下錯誤
org.apache.ibatis.exceptions.PersistenceException: Error querying database. Cause: java.lang.NullPointerException: Cannot invoke "Object.hashCode()" because "key" is null
但是寫了又會說會自動載入,載入多餘,不過這並不是錯誤,因此還是寫上安全
編寫mybatis工具類
//sqlSessionFactory-->sqlSession
public class MybatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static{
try {
//使用Mybatis第一步,獲取sqlSessionFactory物件
//這三行程式碼是從mybatis中文檔案中獲取到的,規定這麼寫的
String resource = "mybatis-config.xml";//這裡寫上自己的mybatis組態檔的檔名即可
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//既然有了 SqlSessionFactory,顧名思義,我們可以從中獲得 SqlSession 的範例。
// SqlSession 提供了在資料庫執行 SQL 命令所需的所有方法。
public static SqlSession getSqlSession(){
SqlSession sqlSession = sqlSessionFactory.openSession();
return sqlSession;
}
}
3.編寫程式碼
實體類
欄位名和資料裡的欄位一一對應public class User {
private int id;
private String name;
private String pwd;
public User() {
}
public User(int id, String name, String pwd) {
this.id = id;
this.name = name;
this.pwd = pwd;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPwd() {
return pwd;
}
public void setPwd(String pwd) {
this.pwd = pwd;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", pwd='" + pwd + '\'' +
'}';
}
}
Dao介面
public interface UserDao {
List<User> getUserList();
}
介面實現類由Impl轉為一個Mapper組態檔
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace=繫結一個對應的Dao/Mapper介面,等價於以前去實現介面並重寫方法-->
<mapper namespace="com.tang.dao.UserDao">
<!-- select查詢語句 -->
<!--id等價於以前去實現介面並重寫方法 resultType:執行sql返回的結果集,僅需要返回介面的方法中的泛型型別即可 -->
<select id="getUserList" resultType="com.tang.pojo.User">
select * from mybatis.user
</select>
</mapper>
4.測試
注意點:-
若在介面的組態檔中沒有寫以下程式碼則會報下面的錯
<mappers> <mapper resource="com/tang/dao/UserMapper.xml"/> </mappers>org.apache.ibatis.binding.BindingException: Type interface com.tang.dao.UserDao is not known to the MapperRegistry.
-
若在pom中沒有以下程式碼則resources下的組態檔和java目錄下的xml組態檔就不會被打包,也就是在target中並沒有相應的class檔案
<build> <resources> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>true</filtering> </resource> <resource> <directory>src/main/java</directory> <includes> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>true</filtering> </resource> </resources> </build>*測試程式碼:
public class UserDaoTest { @Test public void test(){ //第一步:獲得sqlSession物件 SqlSession sqlSession = MybatisUtils.getSqlSession(); //方式一:getMapper 執行SQL UserDao userDao = sqlSession.getMapper(UserDao.class); List<User> userList = userDao.getUserList(); for(User user: userList){ System.out.println(user); } //關閉SQLSession sqlSession.close(); } }
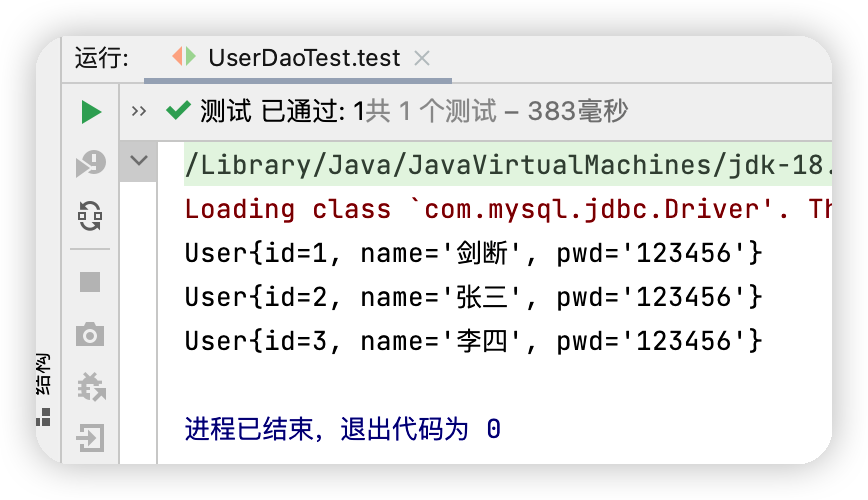
執行結果圖
三、CRUD(增刪改查)
1.Select
選擇,查詢語句-
id:就是對應namespace中的方法名
-
resultType:Sql語句執行的返回值
-
parameterType:引數型別
編寫介面
//查詢指定id的使用者
User getUserById(int id);
編寫對應Dao中的sql語句
<select id="getUserById" parameterType="int" resultType="com.tang.pojo.User">
select * from mybatis.user where id= #{id}
</select>
測試
//查詢指定使用者
@Test
public void getUserByID(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
User user = mapper.getUserById(1);
System.out.println(user);
sqlSession.close();
}
2.Insert
編寫介面
//新增一個使用者
int addUser(User user);
編寫對應Dao中的sql語句
<insert id="addUser" parameterType="com.tang.pojo.User">
insert into mybatis.user(id,name,pwd) values(#{id},#{name},#{pwd})
</insert>
測試
//新增使用者
@Test
public void addUserTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
mapper.addUser(new User(4,"twq","1233"));
sqlSession.commit();//增刪改必須要提交事務,否則在資料庫中就無法檢視增刪改後的結果
sqlSession.close();
}
3.update
編寫介面
//修改一個使用者
int updateUser(User user);
編寫對應Dao中的sql語句
<update id="updateUser" parameterType="com.tang.pojo.User">
update mybatis.user set name=#{name},pwd=#{pwd} where id=#{id};
</update>
測試
//修改使用者
@Test
public void updateUserTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
mapper.updateUser(new User(1,"唐","1234"));
sqlSession.commit();
sqlSession.close();
}
4.delete
編寫介面
//刪除一個使用者
int deleteUser(int id);
編寫對應Dao中的sql語句
<delete id="deleteUser" parameterType="int">
delete from mybatis.user where id=#{id};
</delete>
測試
@Test
public void deleteUserTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
mapper.deleteUser(2);
sqlSession.commit();
sqlSession.close();
}
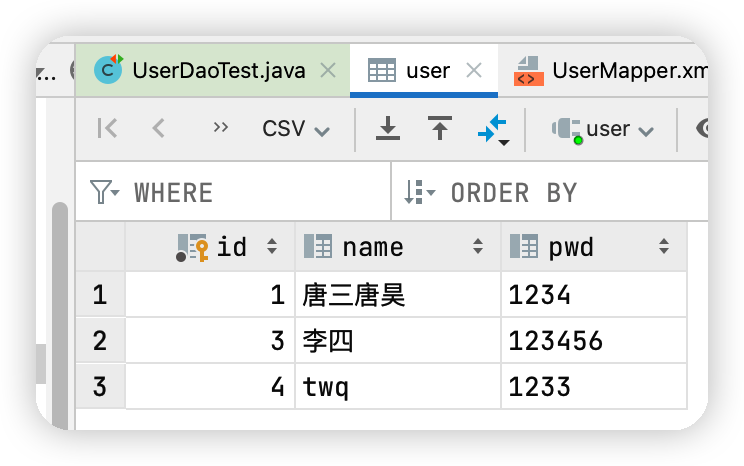
執行前user中表的資料

執行增刪改查之後結果圖

5.萬能的map
目的:將user表中id=1的name改為「唐三唐昊」 介面程式碼//萬能的map
int updateUser2(Map<String,Object> map);
對應Dao中sql程式碼
<update id="updateUser2" parameterType="map">
-- 這裡就沒有必要在把user中的所有欄位都寫進來,用到哪個就可以寫哪個欄位,且傳進去的欄位名可以任意寫
update mybatis.user set name=#{username} where id=#{userid};
</update>
測試程式碼
//map實現使用者修改
@Test
public void updateUser2Test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("userid",1);
map.put("username","唐三唐昊");
mapper.updateUser2(map);
sqlSession.commit();//增刪改必須要提交事務,否則在資料庫中就無法檢視增刪改後的結果
sqlSession.close();
}
執行結果圖
Map傳遞引數,直接在sql中取出key即可
物件傳遞引數,直接在sql中取物件的屬性即可
只有一個基本型別引數的情況下,可以直接在sql中取到
6.模糊查詢
目的:利用模糊查詢 查詢所有姓唐的人 介面 List<User> getUserLike(String value);
sql程式碼
<select id="getUserLike" resultType="com.tang.pojo.User">
select *from mybatis.user where name like #{value}
</select>
測試程式碼
在Java程式碼執行的時候,傳遞萬用字元% %,不會存在sql注入的問題
//模糊查詢
@Test
public void getUserLikeTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
List<User> userLike = mapper.getUserLike("%唐%");
for(User user: userLike){
System.out.println(user);
}
sqlSession.close();
}
在sql拼接中使用萬用字元,存在sql注入問題
<select id="getUserLike" resultType="com.tang.pojo.User">
select *from mybatis.user where name like "%"#{value}"%"
</select>
List<User> userLike = mapper.getUserLike("唐");
兩種情況的執行結果

四、設定解析
1.核心組態檔
-
mybatis-config.xml
-
Mybatis的組態檔包含了會深深影響Mybatis行為的設定和屬性資訊
-
configuration(設定)
- properties(屬性)
- settings(設定)
- typeAliases(型別別名)
- typeHandlers(型別處理器)
- objectFactory(物件工廠)
- plugins(外掛)
- environments(環境設定)
- environment(環境變數)
- transactionManager(事務管理器)
- dataSource(資料來源)
- environment(環境變數)
- databaseIdProvider(資料庫廠商標識)
- mappers(對映器)
2.環境設定(environments)
MyBatis 可以設定成適應多種環境
不過要記住:儘管可以設定多個環境,但每個 SqlSessionFactory 範例只能選擇一種環境。
學會使用設定多套執行環境,比如如下這種方式就可以選擇id為test的設定環境,雖然有多套設定環境,但是最終執行的只會是其中一種
<configuration>
<environments default="test">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!-- &在xml檔案中與符號需要這樣來跳脫-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=Asia/Shanghai&useSSL=true&useUnicode=true&characterEncoding=utf8"/>
<property name="username" value="root"/>
<property name="password" value="root123456"/>
</dataSource>
</environment>
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!-- &在xml檔案中與符號需要這樣來跳脫-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=Asia/Shanghai&useSSL=true&useUnicode=true&characterEncoding=utf8"/>
<property name="username" value="root"/>
<property name="password" value="root123456"/>
</dataSource>
</environment>
</environments>
<!-- 每一個mapper.xml都需要在Mybatis核心組態檔中註冊-->
<mappers>
<mapper resource="com/tang/dao/UserMapper.xml"/>
</mappers>
</configuration>
Mybatis預設的事務管理器就是JDBC,連線池為POOLED
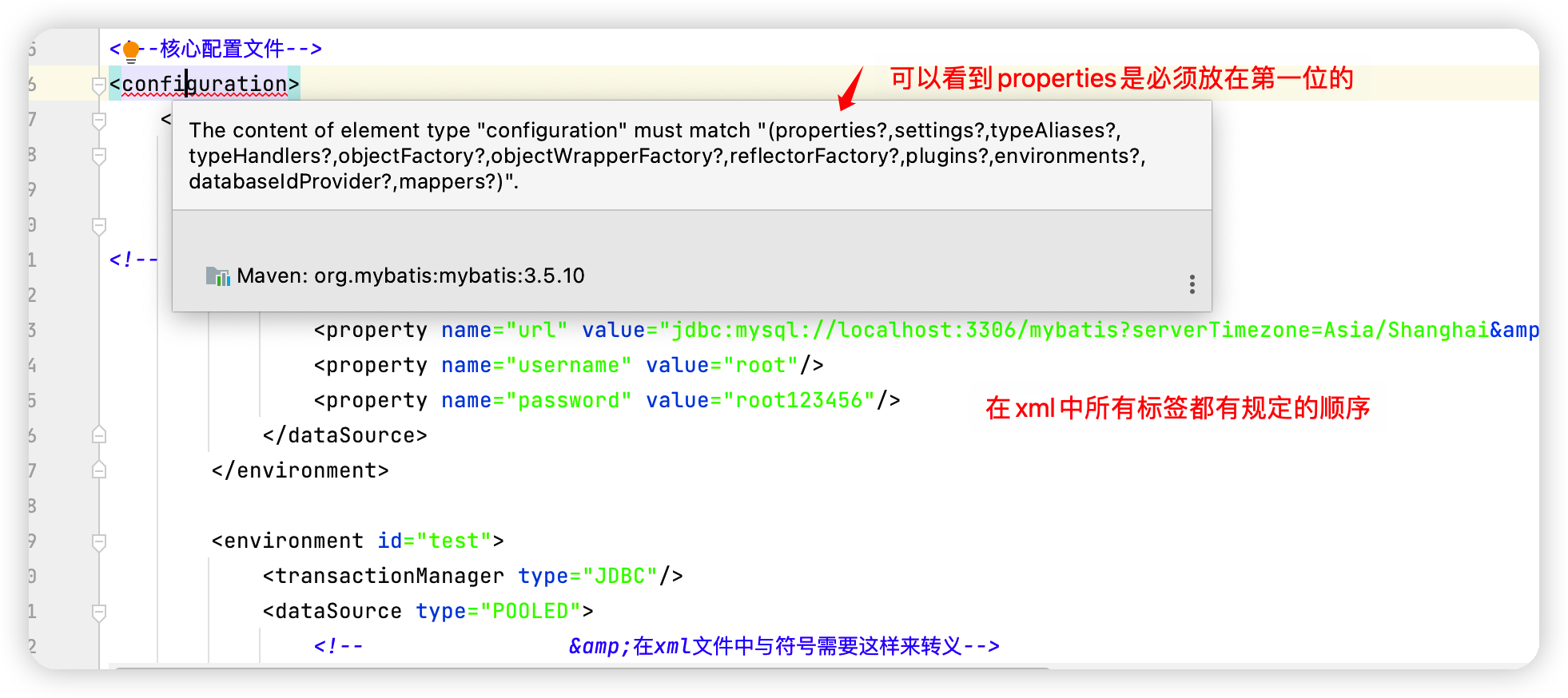
3.屬性(properties)
我們可以通過properties屬性來實現參照組態檔這些屬性都是可外部設定且可動態替換的,既可以在典型的Java屬性檔案中設定,也可通過properties元素的子元素來傳遞【db.properties】
編寫一個組態檔
db.properties
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=utf8"
username=root
password=root123456
在核心組態檔中引入
<!--引入外部組態檔-->
<properties resource="db.properties"/>
然後就可以通過如下的方式去讀取db.properties檔案裡的值
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
-
可以直接引入外部檔案
-
可以在其中增加一些屬性設定
-
如果兩個檔案有同一個欄位,優先使用外部組態檔中的
4.型別別名(typeAliases)
作用-
型別別名可為 Java 型別設定一個縮寫名字。
-
它僅用於 XML 設定,意在降低冗餘的全限定類名書寫
<!--可以給實體類起別名-->
<typeAliases>
<typeAlias type="com.tang.pojo.User" alias="User"></typeAlias>
</typeAliases>
也可以指定一個包名,MyBatis 會在包名下面搜尋需要的 Java Bean,比如:
掃描實體類的包,它的預設別名就為這個類的 類名,首字母小寫,大寫也行!
如下程式碼在呼叫到pojo包下面的類的時候可以直接使用類名的小寫字母完成
<typeAliases>
<package name="com.tang.pojo"/>
</typeAliases>
在實體類比較少的時候使用第一種方式
如果實體類比較多,建議使用第二種
第一種可以DIY起別名,第二種則不行,如果非要改,需要在實體類上增加註解
在實體類上加註解給類名起別名
@Alias("user")
public class User {
5.設定(settings)
這是 MyBatis 中極為重要的調整設定,它們會改變 MyBatis 的執行時行為


6.對映器(mappers)
MapperRegistry:註冊繫結我們的Mapper檔案;
方式一:【推薦使用】
<!-- 每一個mapper.xml都需要在Mybatis核心組態檔中註冊-->
<mappers>
<mapper resource="com/tang/dao/UserMapper.xml"/>
</mappers>
方式二:使用class檔案繫結註冊
<mappers>
<mapper class="com.tang.dao.UserMapper"/>
</mappers>
注意點
-
介面和它的Mapper組態檔必須同名
-
介面和它的Mapper組態檔必須在同一個包下
7.作用域(Scope)和生命週期
不同作用域和生命週期類別是至關重要的,因為錯誤的使用會導致非常嚴重的並行問題
SqlSessionFactoryBuilder
-
這個類可以被範例化、使用和丟棄,一旦建立了 SqlSessionFactory,就不再需要它了
SqlSessionFactory -
可以想象為:資料庫連線池
-
SqlSessionFactory 一旦被建立就應該在應用的執行期間一直存在,沒有任何理由丟棄它或重新建立另一個範例
-
SqlSessionFactory 的最佳作用域是應用作用域
-
最簡單的就是使用單例模式或者靜態單例模式
SqlSession -
連線到連線池的一個請求
-
SqlSession 的範例不是執行緒安全的,因此是不能被共用的,所以它的最佳的作用域是請求或方法作用域。
-
用完之後需要趕緊關閉,否則資源被佔用
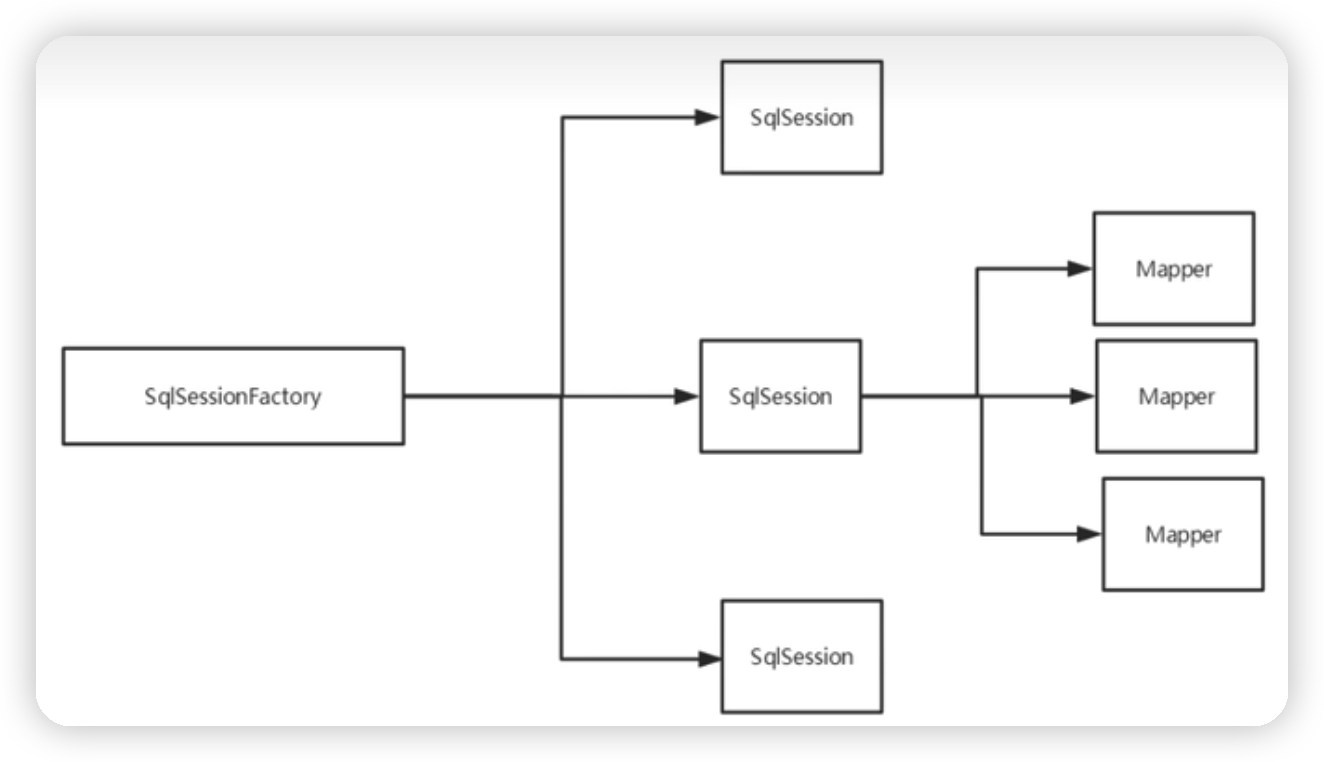
這裡面的每一個Mapper,就代表一個具體的業務
五、解決屬性名和欄位名不一致的問題
1.問題
資料庫中的欄位
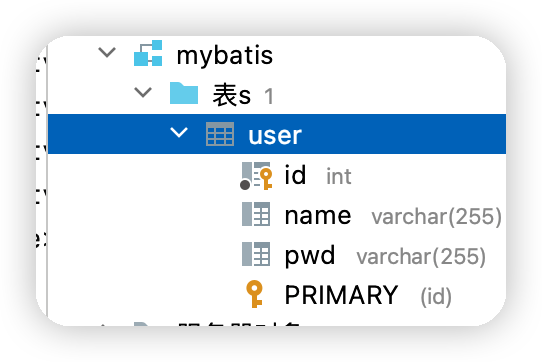
新建一個專案,拷貝之前的,情況測試實體類欄位不一致的情況
public class User {
private int id;
private String name;
private String password;
測試出現問題
select * from mybatis.user where id= #{id}
//類處理器,以上等價於
select id,name,pwd from mybatis.user where id = #{id}
//所以並未查詢到pwd欄位所以測試結果password為空
解決方法:
-
起別名
<select id="getUserById" parameterType="int" resultType="com.tang.pojo.User"> select id,name,pwd as password from mybatis.user where id = #{id} </select>
2.resultMap
結果集對映資料庫中的欄位為 id name pwd
User實體類欄位為 id name password
<!--結果集對映-->
<resultMap id="UserMap" type="user">
<!--column資料庫中的欄位,property實體類中的屬性-->
<!--id和name屬性可以不寫,只需要寫實體類中與資料庫不一樣的欄位的對映即可-->
<result column="id" property="id"></result>
<result column="name" property="name"></result>
<result column="pwd" property="password"></result>
</resultMap>
<!--select中resultMap的值必須與上面resultMap的id的值相同-->
<select id="getUserById" resultMap="UserMap">
select * from mybatis.user where id= #{id}
</select>
-
resultMap 元素是 MyBatis 中最重要最強大的元素
-
ResultMap 的設計思想是,對簡單的語句做到零設定,對於複雜一點的語句,只需要描述語句之間的關係就行了
六、紀錄檔
1.紀錄檔工廠
如果一個資料庫操作出現了異常,我們需要排錯,紀錄檔就是最好的助手
曾經出現異常通常使用:sout、debug來找到異常
現在:使用紀錄檔工廠來實現

-
SLF4J
-
LOG4J(3.5.9 起廢棄)【要掌握】
-
LOG4J2
-
JDK_LOGGING
-
COMMONS_LOGGING
-
STDOUT_LOGGING【要掌握】
-
NO_LOGGING
在Mybatis中具體使用哪個紀錄檔實現,在設定中設定
STDOUT_LOGGING標準紀錄檔輸出
<settings>
<!--標準的紀錄檔工廠實現-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
2.Log4j
什麼是log4j?
-
Log4j是Apache的一個開源專案,通過使用Log4j,我們可以控制紀錄檔資訊輸送的目的地是控制檯、檔案、GUI元件
-
我們也可以控制每一條紀錄檔的輸出格式
-
通過定義每一條紀錄檔資訊的級別,我們能夠更加細緻地控制紀錄檔的生成過程
-
通過一個組態檔來靈活地進行設定,而不需要修改應用的程式碼。
先匯入Log4j的包
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
log4j.properties
#將等級為DEBUG的紀錄檔資訊輸出到console和file這兩個目的地,console和file的定義在下面的程式碼
log4j.rootLogger=DEBUG,console,file
#控制檯輸出的相關設定
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
#檔案輸出的相關設定
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./log/tang.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n
#紀錄檔輸出級別
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
設定log4j紀錄檔的實現
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>
log4j的使用,直接測試
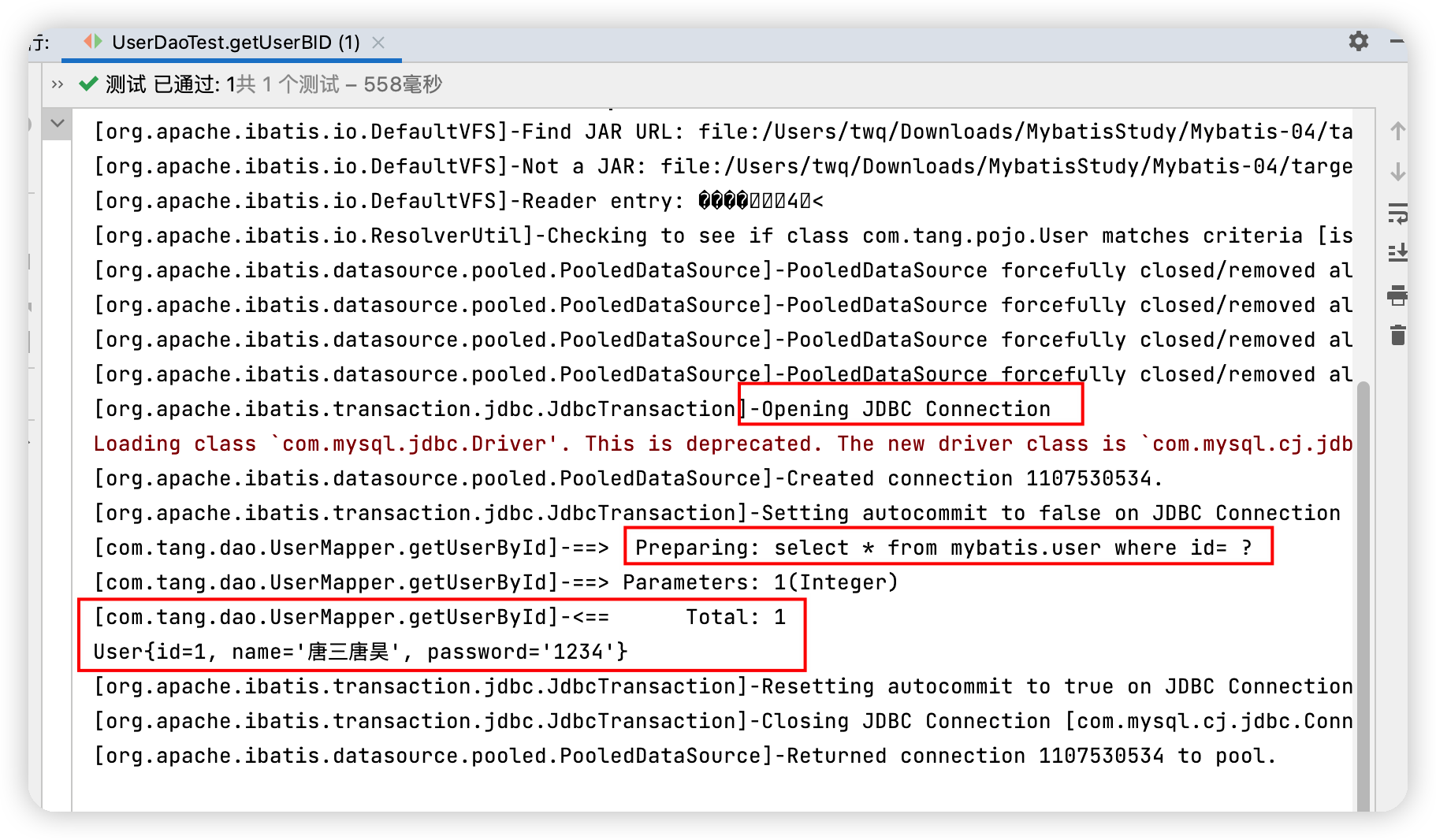
簡單使用
-
再要使用Log4j的類中,匯入包import org.apache.log4j.Logger;
-
紀錄檔物件,引數為當前類的class

紀錄檔級別
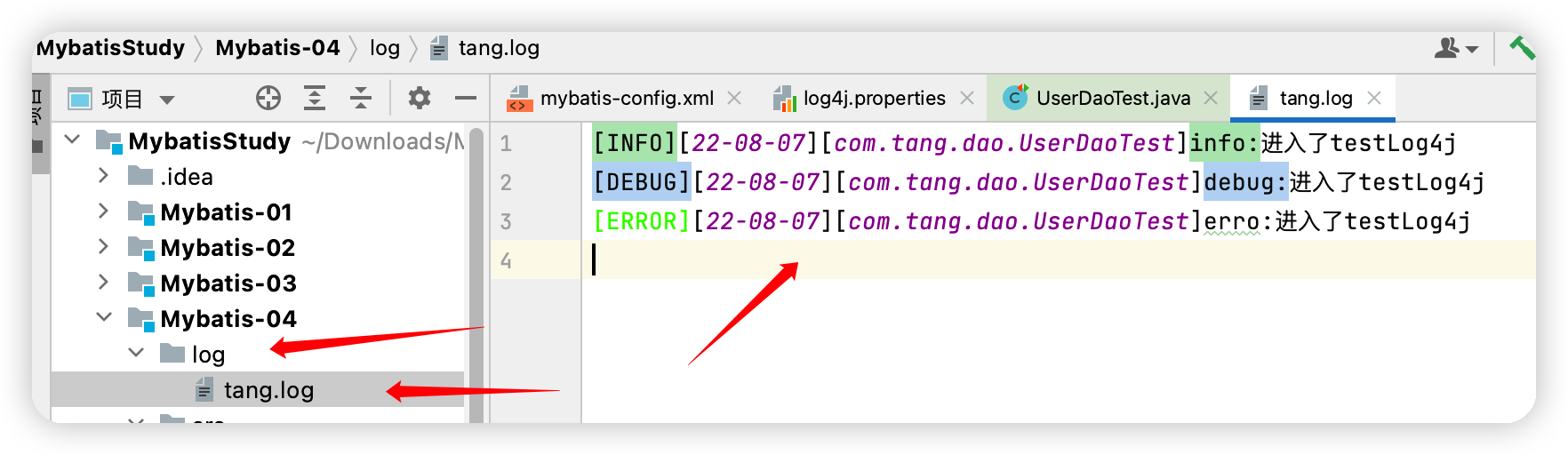
@Test
public void testLog4j(){
logger.info("info:進入了testLog4j");
logger.debug("debug:進入了testLog4j");
logger.error("erro:進入了testLog4j");
}
執行結果
七、分頁
1.使用Limit實現分頁
介面
//分頁
List<User> getUserByLimit(Map<String,Integer> map);
介面的xml檔案
<!-- 分頁實現查詢-->
<!-- 這裡寫user是因為我已經起過別名,所以可簡寫為user-->
<select id="getUserByLimit" parameterType="map" resultType="user">
select * from mybatis.user limit #{startIndex},#{pageSize}
</select>
測試
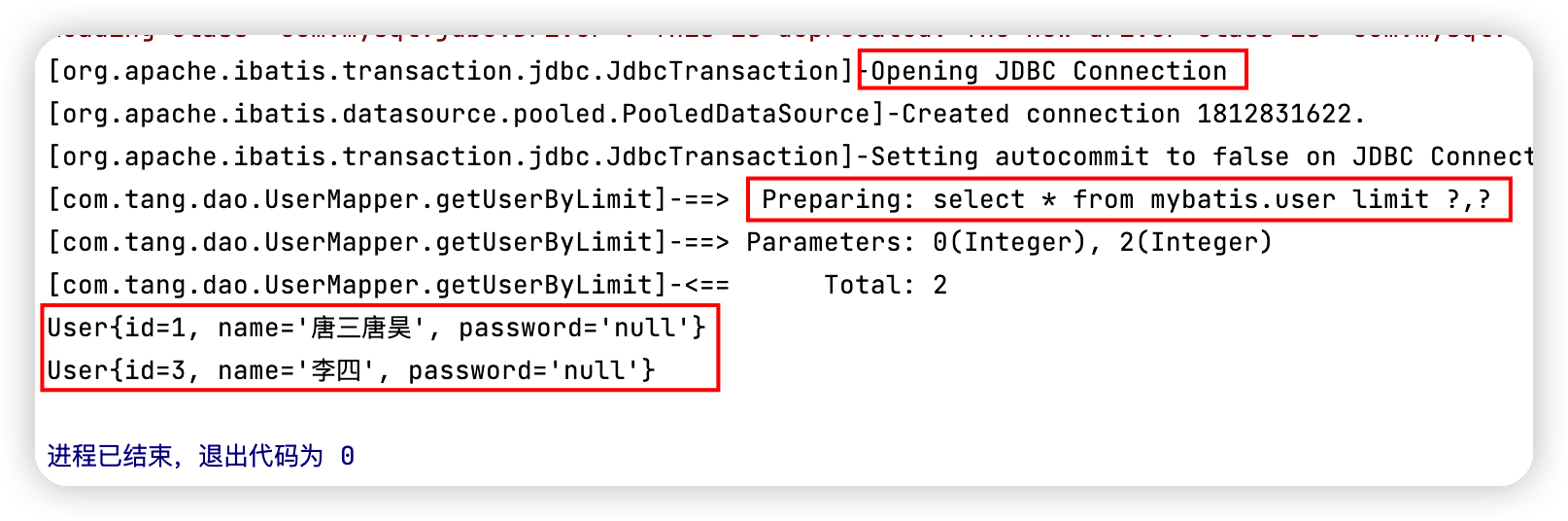
@Test
public void getUserByLimit(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("startIndex",0);
map.put("pageSize",2);
List<User> userList = mapper.getUserByLimit(map);
for(User user : userList){
System.out.println(user);
}
}
執行結果圖
八、使用註解開發
1.面向介面程式設計
-
大家之前都學過物件導向程式設計,也學習過介面,但在真正的開發中,很多時候我們會選擇面向介面程式設計
-
根本原因 : 解耦 , 可拓展 , 提高複用 , 分層開發中 , 上層不用管具體的實現 , 大家都遵守共同的標準 , 使得開發變得容易 , 規範性更好
關於介面的理解 -
介面從更深層次的理解,應是定義(規範,約束)與實現(名實分離的原則)的分離。
三個面向區別 -
物件導向是指,我們考慮問題時,以物件為單位,考慮它的屬性及方法 .
-
程式導向是指,我們考慮問題時,以一個具體的流程(事務過程)為單位,考慮它的實現 .
-
介面設計與非介面設計是針對複用技術而言的,與物件導向(過程)不是一個問題.更多的體現就是對系統整體的架構
2.註解的使用
註解在介面上實現
public interface UserMapper {
@Select("select * from user")
List<User> getUsers();
}
在核心組態檔中繫結介面
<!-- 繫結介面-->
<mappers>
<mapper class="com.tang.dao.UserMapper"></mapper>
</mappers>
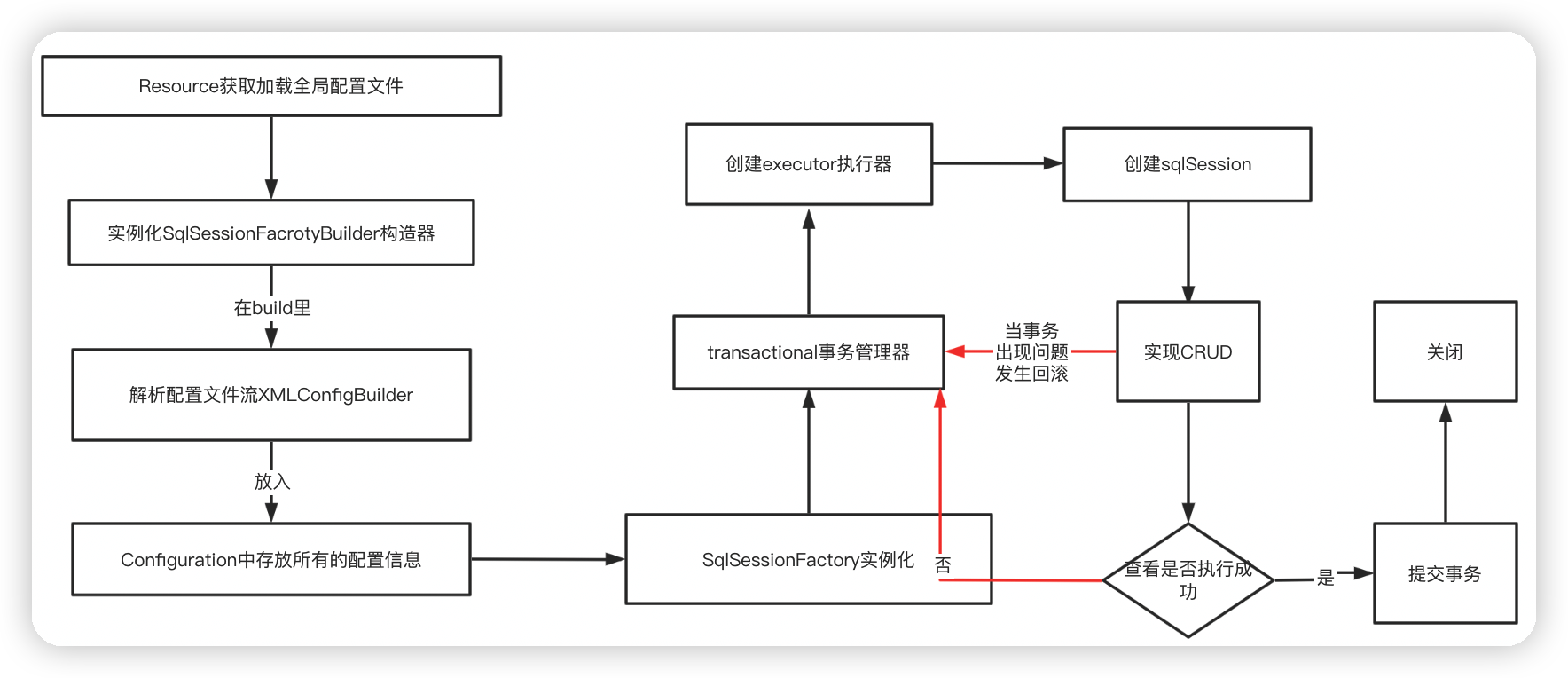
本質:反射機制實現
3.Mybatis詳細執行流程
4.註解實現CRUD
我們可以再工具類建立的時候實現自動提交事務 public static SqlSession getSqlSession(){
//這裡寫上true之後在進行增刪改之後就會自動提交事務
SqlSession sqlSession = sqlSessionFactory.openSession(true);
return sqlSession;
}
組態檔中對介面進行註冊
<mappers>
<mapper class="com.tang.dao.UserMapper"></mapper>
</mappers>
介面程式碼
//查詢所有使用者
@Select("select * from user")
List<User> getUserList();
//方法存在多個引數,所有的引數前面必須加上@Param註解
//查詢指定id的使用者
@Select("select * from user where id=#{id}")
User getUserById(@Param("id") int id);
//增加使用者
@Insert("insert into user(id,name,pwd) values(#{id},#{name},#{password})")
int addUser(User user);
//修改使用者
@Update("update user set name =#{name},pwd=#{password} where id=#{id}")
int updateUser(User user);
//刪除使用者
@Delete("delete from user where id=#{uid}")
int deleteUser(@Param("uid")int id);
增刪改查的測試類
@Test
public void getUserListTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> userList = mapper.getUserList();
for (User user : userList) {
System.out.println(user);
}
}
@Test
public void getUserBID(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User userById = mapper.getUserById(1);
System.out.println(userById);
sqlSession.close();
}
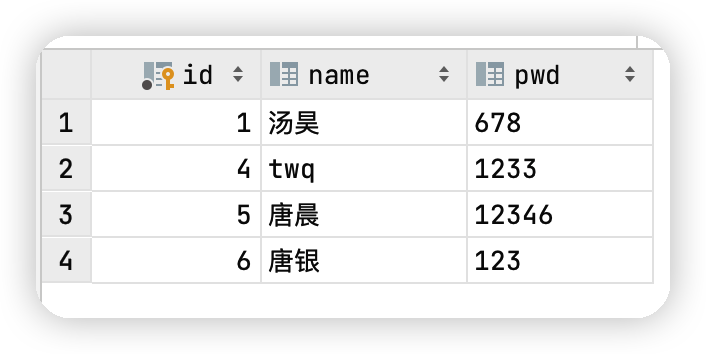
@Test
public void addUserTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
mapper.addUser(new User(6,"唐銀","123"));
sqlSession.close();
}
@Test
public void updateUserTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
mapper.updateUser(new User(1,"湯昊","678"));
sqlSession.close();
}
@Test
public void deleteUserTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
mapper.deleteUser(3);
sqlSession.close();
}
對user表操作之後的結果圖
【關於@Param()註解】
-
基本型別的引數或者String型別,需要加上@Param
-
參照型別不用加
-
如果只有一個進本型別的話,可以忽略,但是建議也加上
-
我們在SQL中參照的就是我們這裡的@Param()中設定的屬性名
九、Lombok
1.使用步驟
-
在IDEA中安裝Lombok外掛
-
在專案中匯入lombok的jar包
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
- 在實體類上加lombok註解
- @Data:無參構造,get,set,toString,hashcode,equals
- @NoArgsConstructor:無參構造
- @AllArgsConstructor:有參構造,寫了有參的註解和Data的註解,雖然Data會產生無參,但是在寫有參註解的同時無參會消失,因為顯示定義有參之後,無參需要手動賦值
十、多對一處理
如學生和老師之間的關係-
對於學生這邊而言,關聯,多個學生,關聯一個老師【多對一】
-
對於老師而言 ,集合,一個老師,有很多學生【一對多】
1.測試環境搭建
最終的包結構圖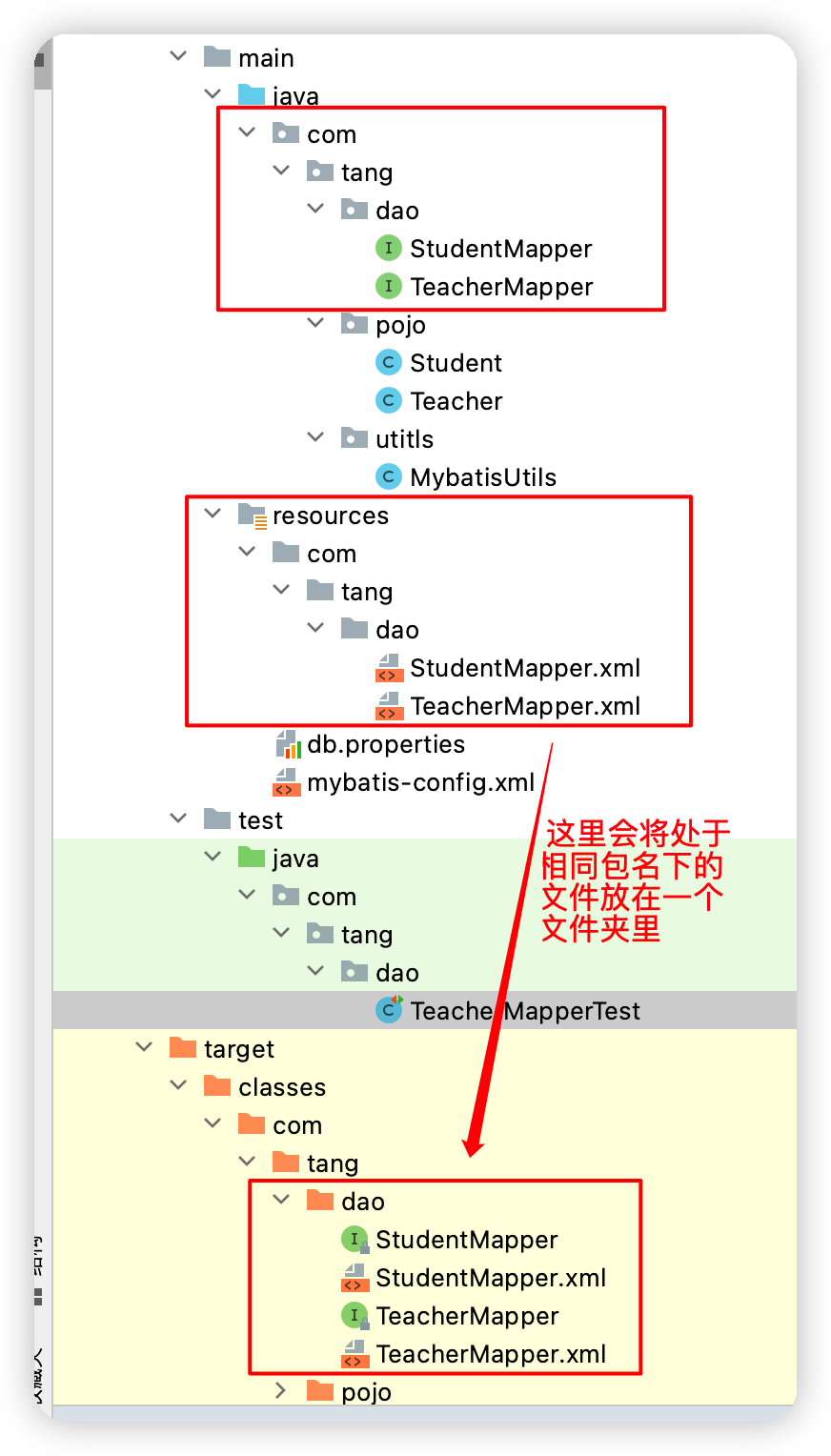
步驟
-
匯入lombok
-
新建實體類Teacher,Student
Student實體類import lombok.Data; @Data public class Student { private int id; private String name; //學生需要關聯一個老師 private Teacher teacher; }Teacher實體類
import lombok.Data; @Data public class Teacher { private int id; private String name; } -
建立Mapper介面
StudentMapper介面public interface StudentMapper { }TeacherMapper介面
import com.tang.pojo.Teacher; import org.apache.ibatis.annotations.Param; import org.apache.ibatis.annotations.Select; public interface TeacherMapper { @Select("select * from teacher where id = #{tid}") Teacher getTeacher(@Param("tid")int id); } -
建立Mapper.xml檔案
StudentMapper.xml程式碼<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!--核心組態檔--> <mapper namespace="com.tang.dao.StudentMapper"> </mapper>TeacherMapper.xml程式碼
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!--核心組態檔--> <mapper namespace="com.tang.dao.TeacherMapper"> </mapper> -
在核心組態檔中繫結註冊我們的Mapper介面或者檔案
<mappers> <mapper class="com.tang.dao.TeacherMapper"></mapper> <mapper class="com.tang.dao.StudentMapper"></mapper> </mappers> -
測試查詢對否成功
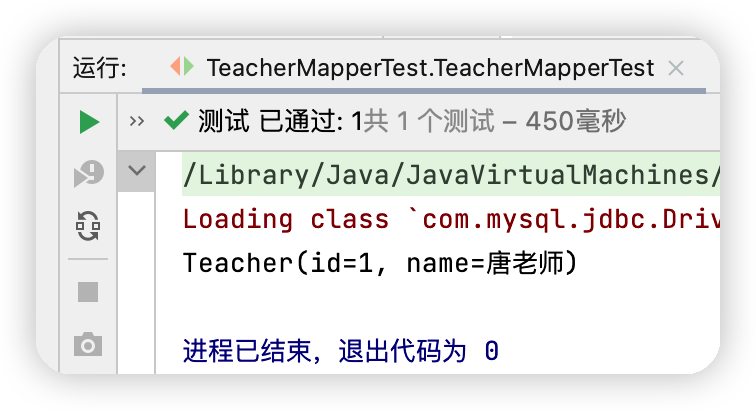
@Test public void TeacherMapperTest(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class); Teacher teacher = mapper.getTeacher(1); System.out.println(teacher); sqlSession.close(); }
執行結果圖
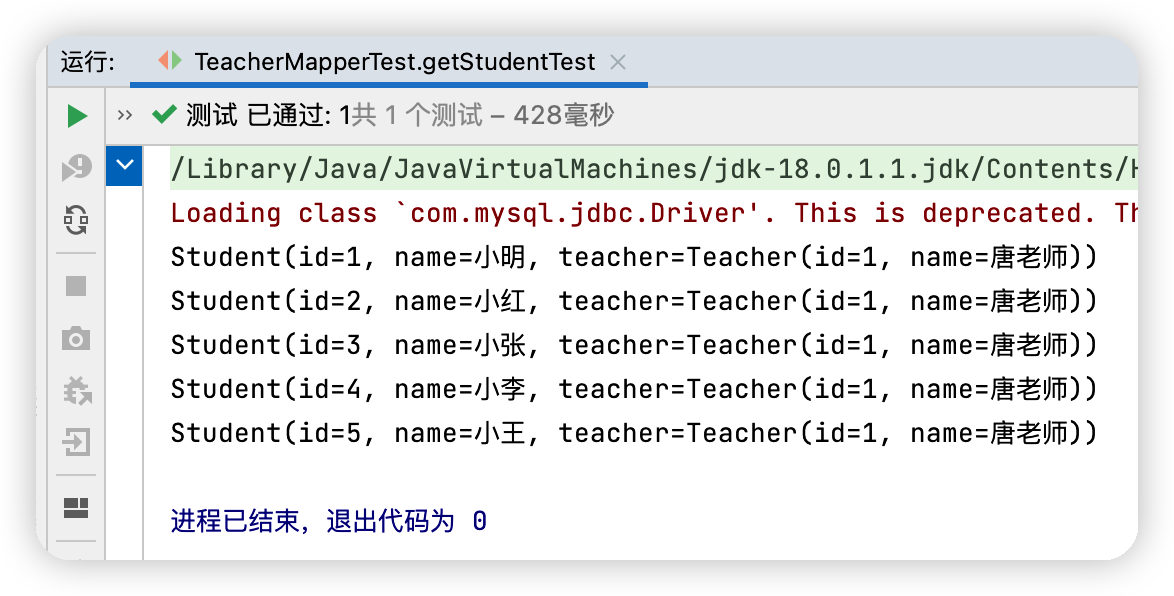
2.按照查詢巢狀處理
目的:查詢每個學生及對應老師的資訊<mapper namespace="com.tang.dao.StudentMapper">
<!--思路:
1.查詢所有的學生資訊
2.根據查詢出來的學生的tid,尋找對應的老師
-->
<select id="getStudent" resultMap="StudentTeacher">
-- select s.id,s.name,t.name from student s,teacher t where s.tid = t.id;
select * from student
</select>
<resultMap id="StudentTeacher" type="Student">
<!--因為student和Teacher表中id,和name欄位相同,因此這裡沒必要寫對映關係-->
<!--複雜的屬性,我們需要單獨處理
物件使用association
集合使用collection
-->
<association property="teacher" column="tid" javaType="Teacher" select="getTeacher"></association>
</resultMap>
<select id="getTeacher" resultType="Teacher">
select * from teacher where id=#{id}
</select>
</mapper>
執行結果圖
3.按照結果巢狀處理
目的:查詢每個學生及對應老師的資訊<!--按照結果巢狀處理-->
<select id="getStudent2" resultMap="StudentTeacher2">
select s.id sid,s.name snmae,t.id tid,t.name tname
from student s,teacher t
where s.tid = t.id;
</select>
<resultMap id="StudentTeacher2" type="Student">
<result property="id" column="sid"></result>
<result property="name" column="sname"></result>
<association property="teacher" javaType="Teacher" >
<result property="name" column="tname"></result>
<result property="id" column="tid"></result>
</association>
</resultMap>
十一、一對多處理
比如:一個老師擁有多個學生 對於老師而言,就是一對多的關係1.環境搭建
與之前環境搭建差不多 這裡實體類變為import lombok.Data;
@Data
public class Student {
private int id;
private String name;
private int tid;
}
import lombok.Data;
import java.util.List;
@Data
public class Teacher {
private int id;
private String name;
//一個老師對應多個學生
private List<Student> students;
}
2.按照結果查詢
目的:查詢每個老師及對應學生的資訊<mapper namespace="com.tang.dao.TeacherMapper">
<!--按結果巢狀查詢-->
<select id="getTeacher" resultMap="TeacherStudent">
select s.id sid,s.name snmae,t.id tid,t.name tname
from student s,teacher t
where s.tid = t.id and t.id=#{tid}
</select>
<resultMap id="TeacherStudent" type="Teacher">
<result property="id" column="tid"></result>
<result property="name" column="tname"></result>
<!--複雜的屬性,我們需要單獨處理
物件使用association
集合使用collection
javaType指定屬性的型別
集合中的泛型資訊,使用ofType獲取
-->
<collection property="students" ofType="Student">
<result property="id" column="sid"></result>
<result property="name" column="snmae"></result>
<result property="tid" column="tid"></result>
</collection>
</resultMap>
</mapper>
3.小結
-
關聯-association【多對一】
-
集合-collection 【一對多】
-
javaType & ofType
- javaType用來指定實體類中屬性的型別
- ofType用來指定對映到List或者集合中pojo型別,泛型中的約束型別
注意點:
-
保證SQL的可讀性,儘量保證通俗易懂
-
注意一對多和多對一中,屬性名和欄位的問題
-
如果問題不好排查錯誤,可以使用紀錄檔,建議使用log4j
【面試高頻】
-
Mysql引擎
問題描述:一張表,裡面有ID自增主鍵,當insert了17條記錄之後,刪除了第15,16,17條記錄,再把Mysql重啟,再insert一條記錄,這條記錄的ID是18還是15 ?(區分兩種資料庫引擎)(1)如果表的型別是MyISAM,那麼是18。
因為MyISAM表會把自增主鍵的最大ID記錄到資料檔案裡,重啟MySQL自增主鍵的最大ID也不會丟失。
(2)如果表的型別是InnoDB,那麼是15。
InnoDB表只是把自增主鍵的最大ID記錄到記憶體中,所以重啟資料庫或者是對錶進行OPTIMIZE操作,都會導致最大ID丟失。 -
InnoDB底層原理
innoDB 是聚集索引方式,因此資料和索引都儲存在同一個檔案裡。首 先 InnoDB 會根據主鍵 ID 作為 KEY 建立索引 B+樹,如左下圖所示,而 B+樹的葉子節點儲存的是主鍵 ID 對應的資料,比如在執行 select * from user_info where id=15 這個語句時,InnoDB 就會查詢這顆主鍵 ID 索引 B+樹,找到對應的 user_name='Bob'。這是建表的時候 InnoDB 就會自動建立好主鍵 ID 索引樹,這也是為什麼 Mysql 在建表時要求必須指定主鍵的原因。當我們為表裡某個欄位加索引時 InnoDB 會怎麼建立索引樹呢?比如我們要給 user_name 這個欄位加索引,那麼 InnoDB 就會建立 user_name 索引 B+樹,節點裡存的是 user_name 這個 KEY,葉子節點儲存的資料的是主鍵 KEY。注意,葉子儲存的是主鍵 KEY!拿到主鍵 KEY 後,InnoDB 才會去主鍵索引樹里根據剛在 user_name 索引樹找到的主鍵 KEY 查詢到對應的資料。
-
索引
問題描述:簡單描述MySQL中,索引,主鍵,唯一索引,聯合索引的區別,對資料庫的效能有什麼影響。(1)索引是一種特殊的檔案(InnoDB資料表上的索引是表空間的一個組成部分),它們包含著對資料表裡所有記錄的參照指標。
(2)普通索引(由關鍵字KEY或INDEX定義的索引)的唯一任務是加快對資料的存取速度。
(3)普通索引允許被索引的資料列包含重複的值,如果能確定某個資料列只包含彼此各不相同的值,在為這個資料索引建立索引的時候就應該用關鍵字UNIQE把它定義為一個唯一所以,唯一索引可以保證資料記錄的唯一性。
(4)主鍵,一種特殊的唯一索引,在一張表中只能定義一個主鍵索引,逐漸用於唯一標識一條記錄,是用關鍵字PRIMARY KEY來建立。
(5)索引可以覆蓋多個資料列,如像INDEX索引,這就是聯合索引。
(6)索引可以極大的提高資料的查詢速度,但是會降低插入刪除更新表的速度,因為在執行這些寫操作時,還要操作索引檔案。 -
索引優化
1.建立索引
對於查詢佔主要的應用來說,索引顯得尤為重要。很多時候效能問題很簡單的就是因為我們忘了新增索引而造成的,或者說沒有新增更為有效的索引導致。如果不加索引的話,那麼查詢任何哪怕只是一條特定的資料都會進行一次全表掃描,如果一張表的資料量很大而符合條件的結果又很少,那麼不加索引會引起致命的效能下降。但是也不是什麼情況都非得建索引不可,比如性別可能就只有兩個值,建索引不僅沒什麼優勢,還會影響到更新速度,這被稱為過度索引。
2.複合索引
比如有一條語句是這樣的:select * from users where area=’beijing’ and age=22;
如果我們是在area和age上分別建立單個索引的話,由於mysql查詢每次只能使用一個索引,所以雖然這樣已經相對不做索引時全表掃描提高了很多效率,但是如果在area、age兩列上建立複合索引的話將帶來更高的效率。如果我們建立了(area, age, salary)的複合索引,那麼其實相當於建立了(area,age,salary)、(area,age)、(area)三個索引,這被稱為最佳左字首特性。因此我們在建立複合索引時應該將最常用作限制條件的列放在最左邊,依次遞減。
3.索引不會包含有NULL值的列
只要列中包含有NULL值都將不會被包含在索引中,複合索引中只要有一列含有NULL值,那麼這一列對於此複合索引就是無效的。所以我們在資料庫設計時不要讓欄位的預設值為NULL。
4.使用短索引
對串列進行索引,如果可能應該指定一個字首長度。例如,如果有一個CHAR(255)的 列,如果在前10 個或20 個字元內,多數值是惟一的,那麼就不要對整個列進行索引。短索引不僅可以提高查詢速度而且可以節省磁碟空間和I/O操作。
5.排序的索引問題
mysql查詢只使用一個索引,因此如果where子句中已經使用了索引的話,那麼order by中的列是不會使用索引的。因此資料庫預設排序可以符合要求的情況下不要使用排序操作;儘量不要包含多個列的排序,如果需要最好給這些列建立複合索引。
6.like語句操作
一般情況下不鼓勵使用like操作,如果非使用不可,如何使用也是一個問題。like 「%aaa%」 不會使用索引而like 「aaa%」可以使用索引。
7.不要在列上進行運算
select * from users where YEAR(adddate)<2007;
將在每個行上進行運算,這將導致索引失效而進行全表掃描,因此我們可以改成
select * from users where adddate<‘2007-01-01’;
8.不使用NOT IN和操作
NOT IN和操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id3則可使用id>3 or id<3來代替。
十二、動態SQL
==什麼是動態SQL:動態SQL就是指根據不同的條件生成不同SQL語句==1.環境搭建
編寫實體類
import lombok.Data;
import java.util.Date;
@Data
public class Blog {
private String id;
private String title;
private String author;
private Date createTime;
private int views;
}
2.IF
<select id="queryBlogIF" parameterType="map" resultType="blog">
select * from mybatis.blog where 1=1
<if test="title!=null">
and title=#{title}
</if>
<if test="author!=null">
and author = #{author}
</if>
</select>
測試程式碼
@Test
public void queryBlogIFTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap map = new HashMap();
map.put("title","java很簡單");
List<Blog> blogs = mapper.queryBlogIF(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
執行結果圖

3.choose(when,otherwise)
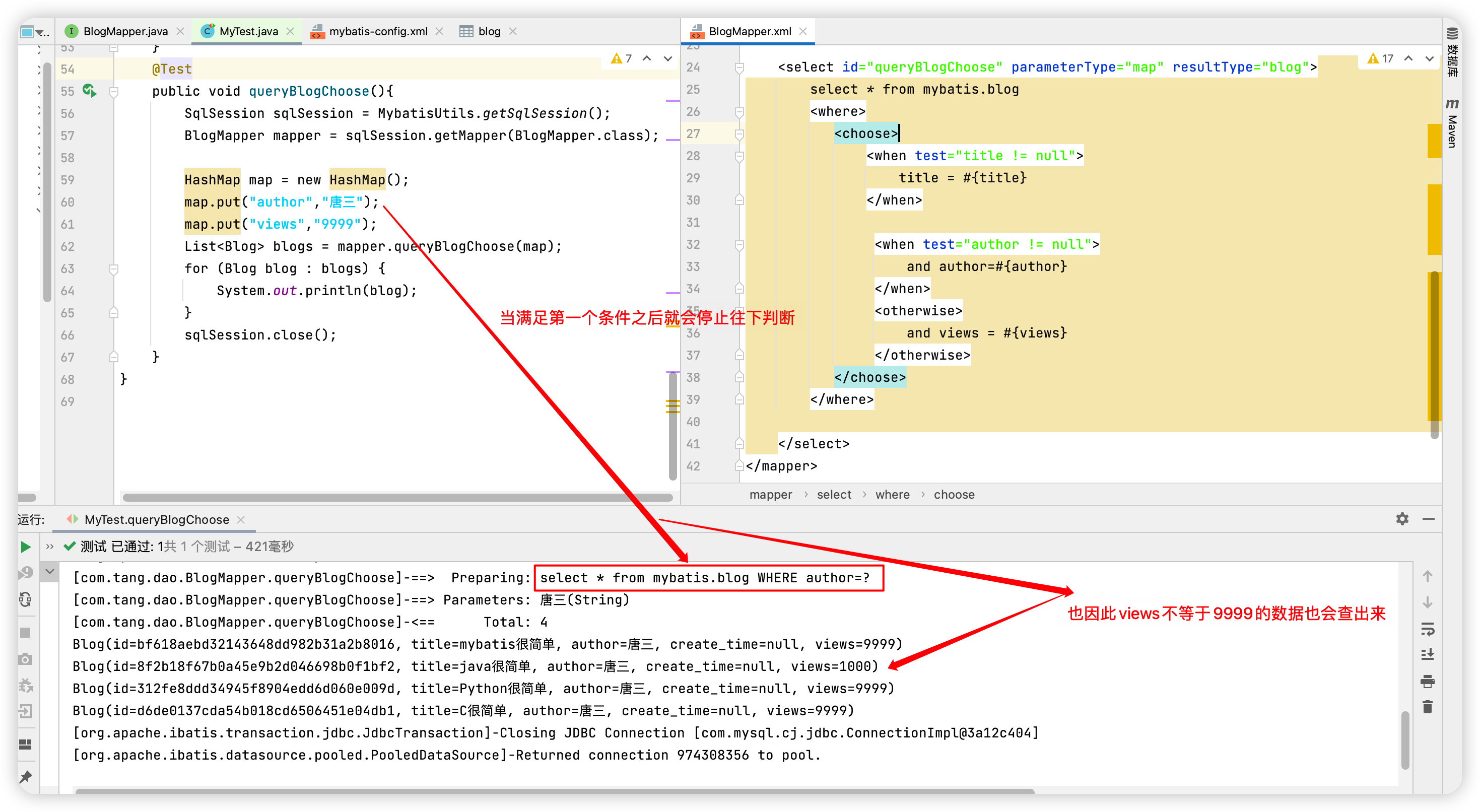
有時候,我們不想使用所有的條件,而只是想從多個條件中選擇一個使用。針對這種情況,MyBatis 提供了 choose 元素,它有點像 Java 中的 switch 語句。還是上面的例子,但是策略變為:傳入了 「title」 就按 「title」 查詢,傳入了 「author」 就按 「author」 查詢的情形。若兩者都沒有傳入,就返回標記為 featured 的 BLOG(這可能是管理員認為,與其返回大量的無意義隨機 Blog,還不如返回一些由管理員精選的 Blog)
<select id="queryBlogChoose" parameterType="map" resultType="blog">
select * from mybatis.blog
<where>
<choose>
<when test="title != null">
title = #{title}
</when>
<when test="author != null">
and author=#{author}
</when>
<otherwise>
and views = #{views}
</otherwise>
</choose>
</where>
</select>
測試程式碼
@Test
public void queryBlogChoose(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap map = new HashMap();
map.put("author","唐三");
map.put("views","9999");
List<Blog> blogs = mapper.queryBlogChoose(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
測試結果
4.trim、where、set
<update id="updateBlog" parameterType="map">
update mybatis.blog
<set>
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author =#{author}
</if>
</set>
where id =#{id}
</update>
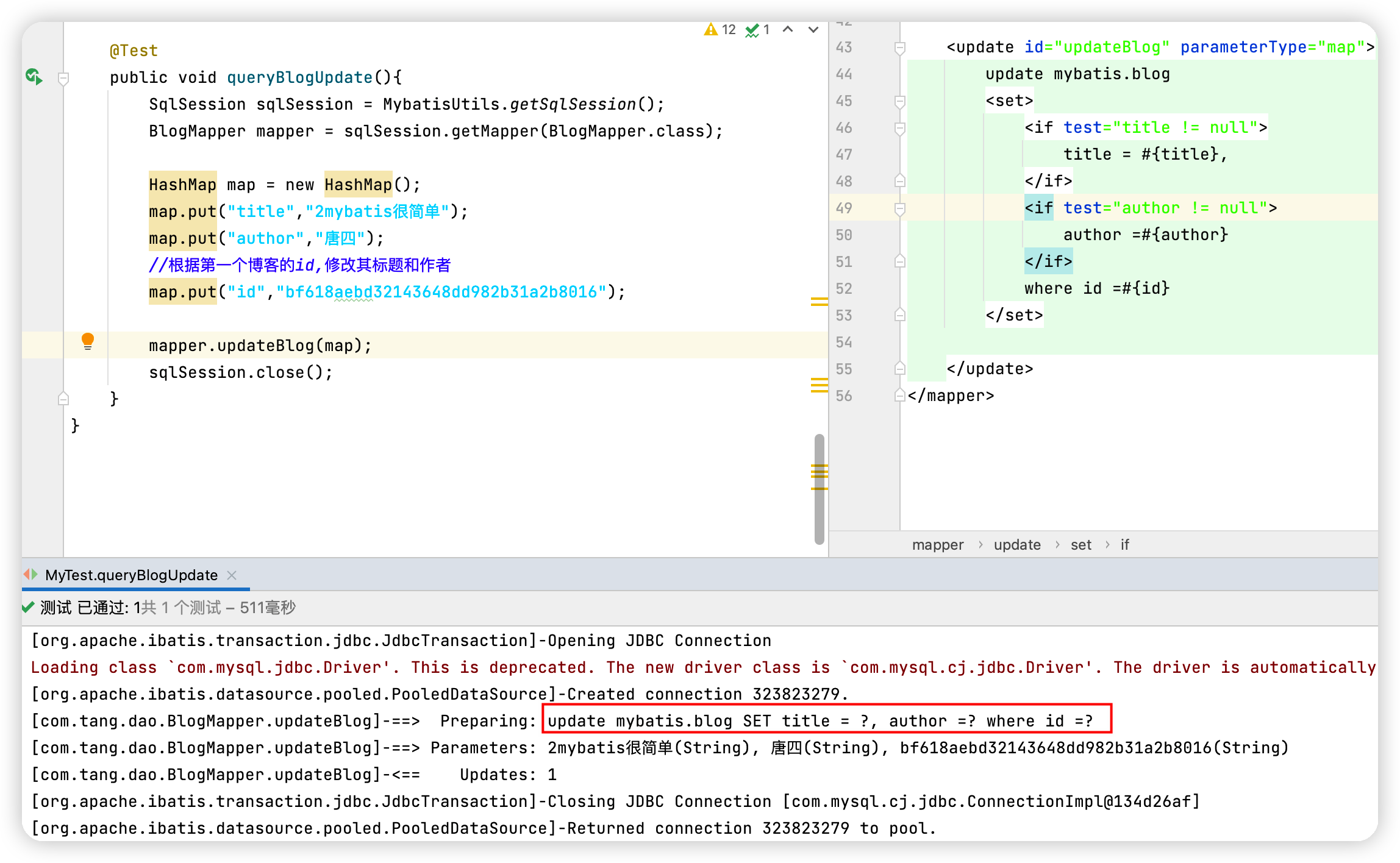
測試程式碼
@Test
public void queryBlogUpdate(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap map = new HashMap();
map.put("title","2mybatis很簡單");
map.put("author","唐四");
//根據第一個部落格的id,修改其標題和作者
map.put("id","bf618aebd32143648dd982b31a2b8016");
mapper.updateBlog(map);
sqlSession.close();
}
5.SQL片段
有的時候,我們可能會將一些功能的部分抽取出來,方便複用 (1)使用SQL標籤抽取公共的部分<sql id="if-title-author">
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author =#{author}
</if>
</sql>
(2)在需要使用的地方使用include標籤參照即可
<update id="updateBlog" parameterType="map">
update mybatis.blog
<set>
<include refid="if-title-author"></include>
</set>
where id =#{id}
</update>
注意事項:
-
最好基於單標來定義SQL片段
-
不要存在where標籤,一般SQL片段裡放的最多的就是if判斷
6.Foreach
foreach 元素的功能非常強大,它允許你指定一個集合,宣告可以在元素體內使用的集合項(item)和索引(index)變數。它也允許你指定開頭與結尾的字串以及集合項迭代之間的分隔符。這個元素也不會錯誤地新增多餘的分隔符,看它多智慧!
提示 你可以將任何可迭代物件(如 List、Set 等)、Map 物件或者陣列物件作為集合引數傳遞給 foreach。當使用可迭代物件或者陣列時,index 是當前迭代的序號,item 的值是本次迭代獲取到的元素。當使用 Map 物件(或者 Map.Entry 物件的集合)時,index 是鍵,item 是值。
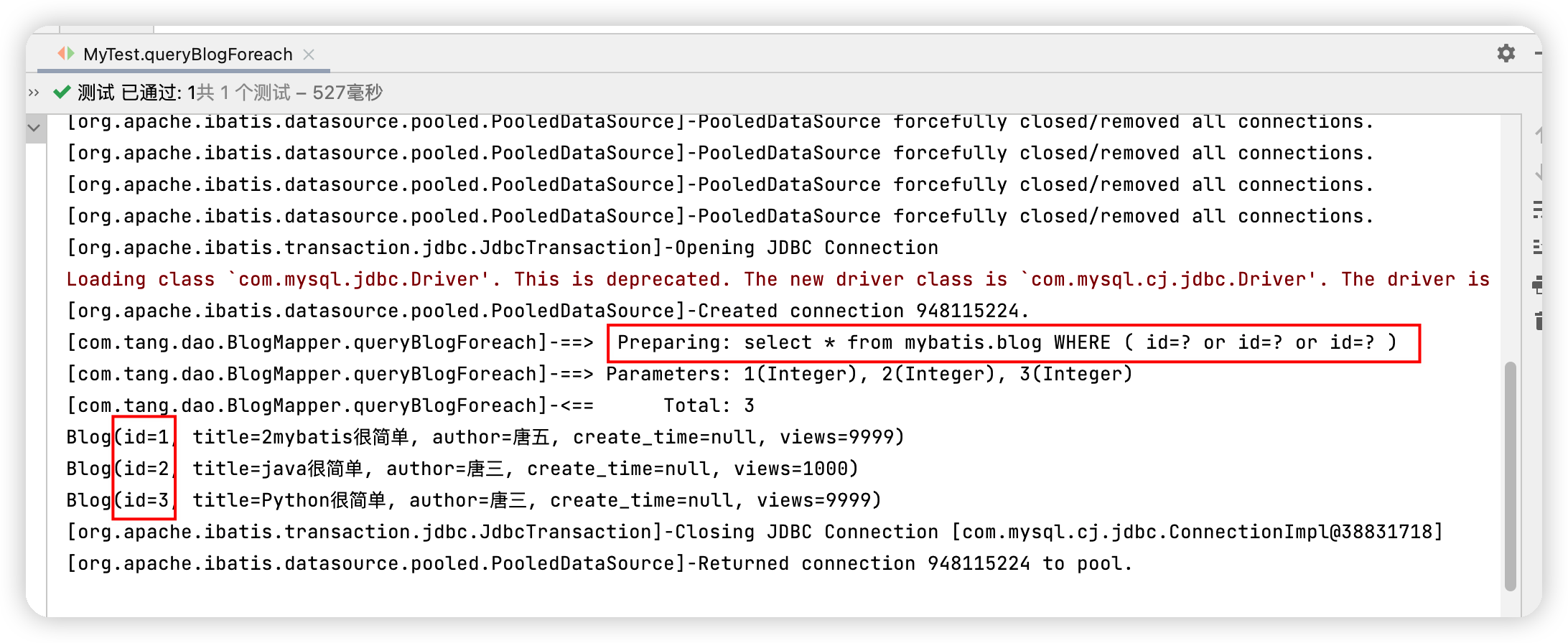
<select id="queryBlogForeach" parameterType="map" resultType="blog">
select * from mybatis.blog
<where>
<foreach collection="ids" item="id" open="and (" close=")" separator="or">
id=#{id}
</foreach>
</where>
</select>
測試程式碼如下
@Test
public void queryBlogForeach(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap map = new HashMap();
ArrayList<Integer> ids = new ArrayList<Integer>();
ids.add(1);
ids.add(2);
ids.add(3);
map.put("ids",ids);
List<Blog> blogs = mapper.queryBlogForeach(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
執行結果
動態SQL就是在拼接SQL語句,我們只需要保證SQL的正確性,按照SQL的格式,去排列組合就可以了
建議:先在MySQL中寫出完整的SQL,再對應的去修改成為我們的動態SQL實現通用即可!
十三、快取
1.簡介
平時我們常用的資料庫的查詢:主要用來連線資料庫,這樣做比較消耗資源
一次查詢的結果,給他暫存在一個可以直接取到的地方-->記憶體:快取
我們再次查詢相同資料的時候,直接走快取,就不用走資料庫了
【什麼是快取】
存在記憶體中的臨時資料,將使用者經常查詢的資料放在快取(記憶體)中,使用者去查詢資料就不用從磁碟上(關係型資料庫檔案)查詢,從快取中查詢,從而提高查詢效率,解決了 高並行系統的效能問題
【為什麼使用快取?】
減少和資料庫的互動次數,減少系統開銷,提高系統效率
【什麼樣的資料可以使用快取?】
經常查詢並且不經常改變的資料 【可以使用快取】。簡單理解,只有查詢才會用到快取!!!
2.MyBatis快取 (目前Redis使用最多)
-
MyBatis包含一個非常強大的查詢快取特性,它可以非常方便的客製化和設定快取,快取可以極大的提高查詢效率
-
MyBatis系統中預設定義了兩級快取:一級快取和二級快取
- 預設情況下,一級快取開啟(SqlSession級別的快取,也稱為本地快取)
- 二級快取需要手動開啟和設定,他是基於namespace級別的快取。 舉例:namespace="com.yff.dao.BlogMapper" namespace級別即介面級別
- 為了提高可延伸性,MyBatis定義了快取介面Cache。我們可以通過實現Cache介面來定義二級快取。
3.一級快取
一級快取也叫本地快取:SqlSession
-
與資料庫同義詞對談期間查詢到的資料會放在本地快取中
-
以後如果需要獲取相同的資料,直接從快取中拿,沒必須再去查詢資料庫
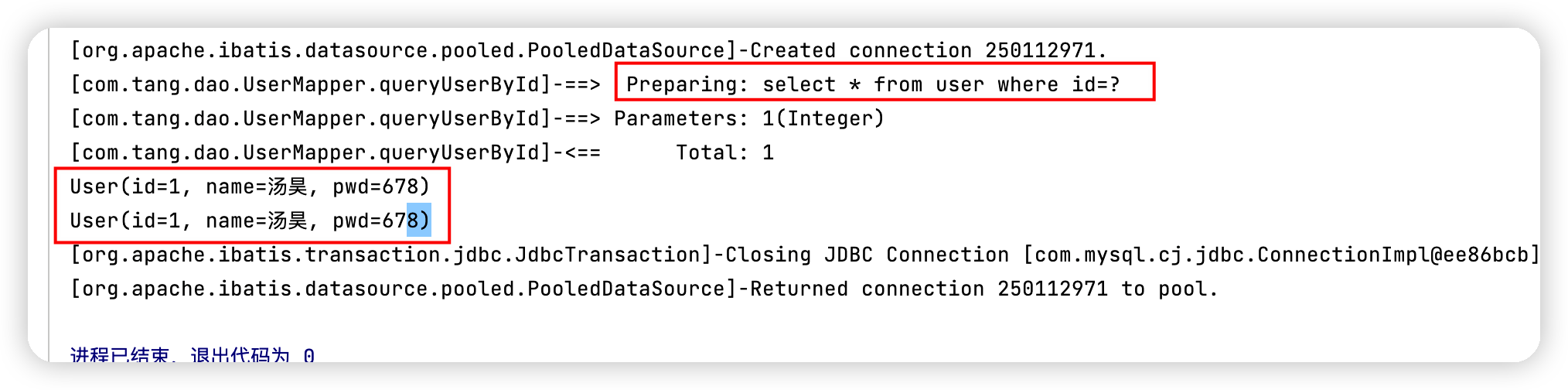
測試步驟:
-
開啟紀錄檔
-
測試在一個Sesion中查詢兩次相同的記錄
public void test(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.queryUserById(1); System.out.println(user); User user1 = mapper.queryUserById(1); System.out.println(user1); sqlSession.close(); } -
檢視紀錄檔輸出
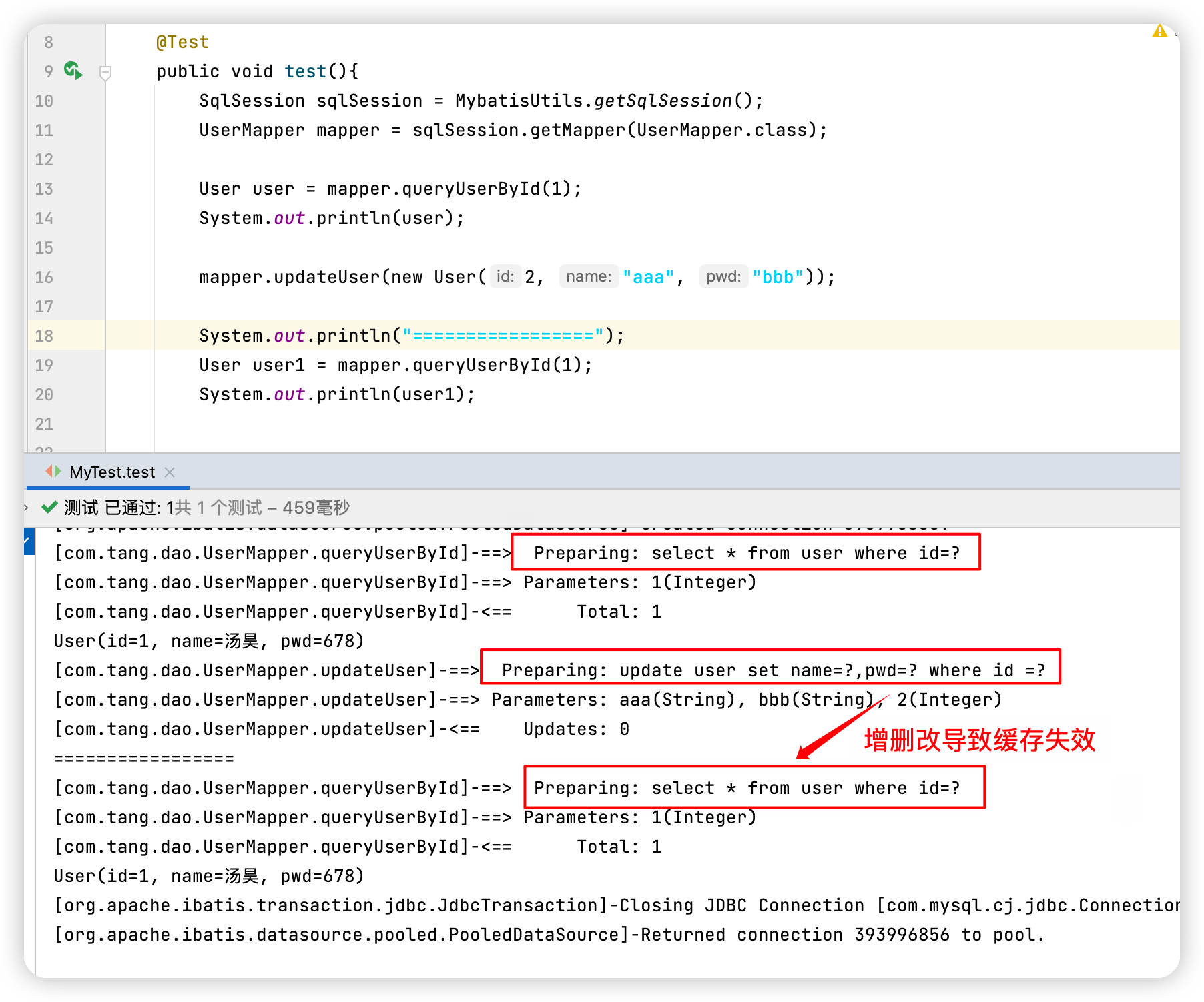
快取失效的情況 -
查詢不同的東西
-
增刪改操作,可能會改變原來的資料,所以必定會重新整理快取
-
查詢不同的Mapper.xml
-
手動清除快取
sqlSession.clearCache();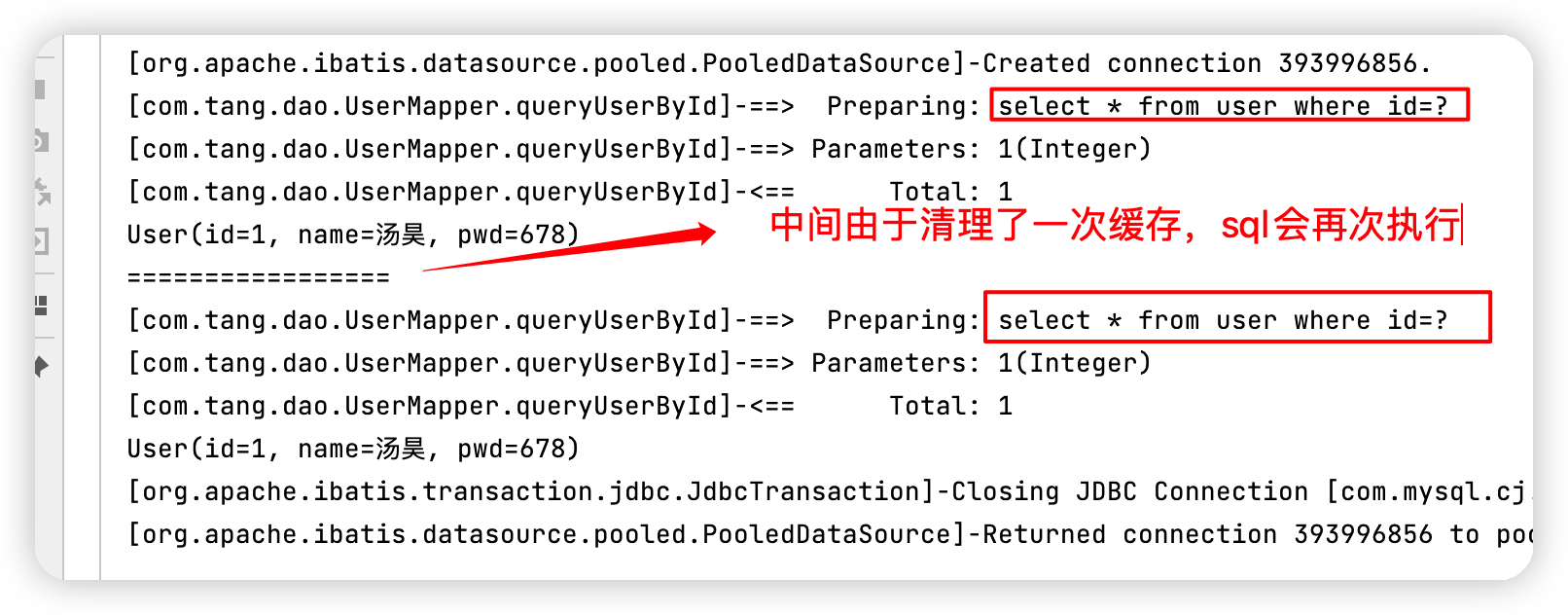
小結:一級快取預設是開啟的,只在一次Sqlsession中有效,也就是拿到連線直到連線關閉連線這個區間段類有效
一級快取就是一個map
4.二級快取
概念:-
二級快取與一級快取區別在於二級快取的範圍更大,多個sqlSession可以共用一個mapper中的二級快取區域。
-
mybatis是如何區分不同mapper的二級快取區域呢?它是按照不同mapper有不同的namespace來區分的,也就是說,如果兩個mapper的namespace相同,即使是兩個mapper,那麼這兩個mapper中執行sql查詢到的資料也將存在相同的二級快取區域中。
-
由於mybaits的二級快取是mapper範圍級別,所以除了在SqlMapConfig.xml設定二級快取的總開關外,還要在具體的mapper.xml中開啟二級快取。
-
二級快取是事務性的。這意味著,當 SqlSession 完成並提交時,或是完成並回滾,但沒有執行 flushCache=true 的 insert/delete/update 語句時,快取會獲得更新。
使用步驟:
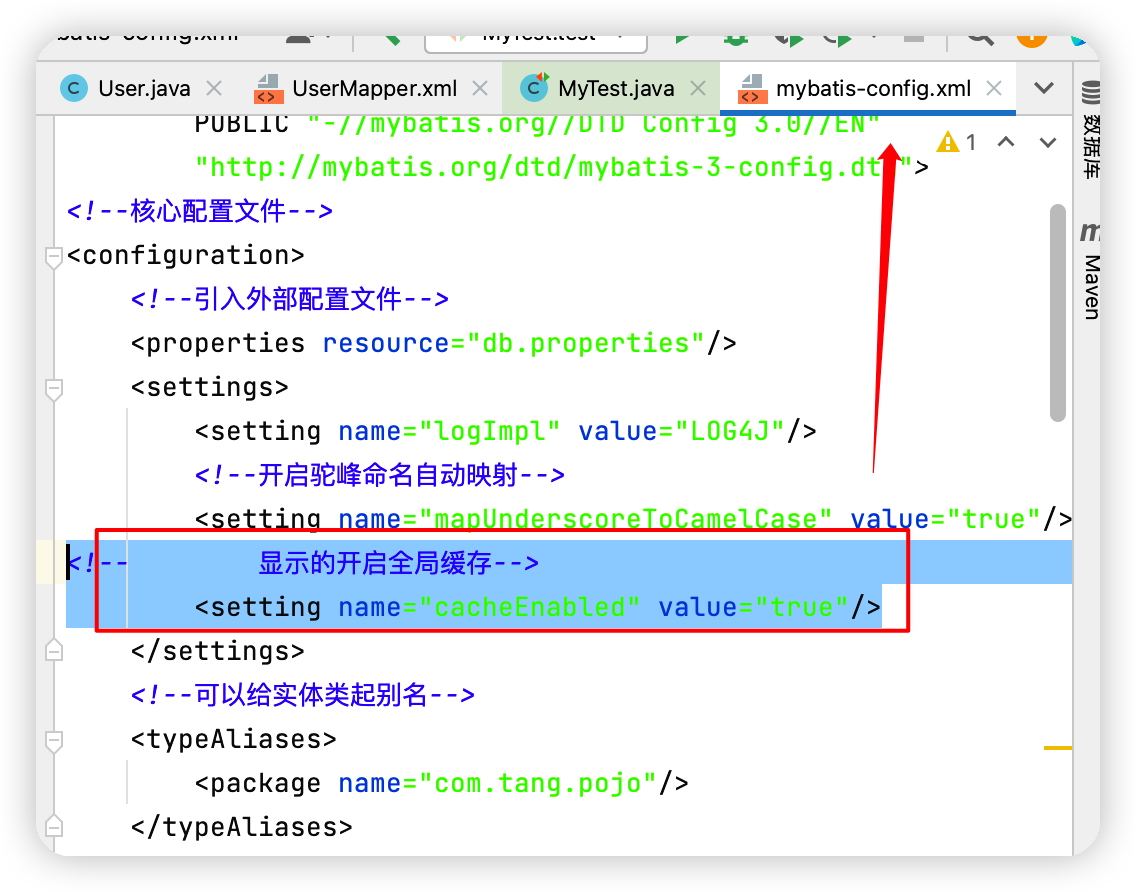
①開啟全域性快取
<!--顯示的開啟全域性快取-->
<setting name="cacheEnabled" value="true"/>
②在要使用二級快取的Mapper中開啟
<!--在當前Mapper.xml中使用二級快取-->
<!--
以下引數的解釋
eviction:使用FIFO這樣一個輸入輸出策略
flushInterval:每隔60秒重新整理一次快取
size:最多存512個快取
readOnly:是否唯讀
這些引數也可以不寫
-->
<cache eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
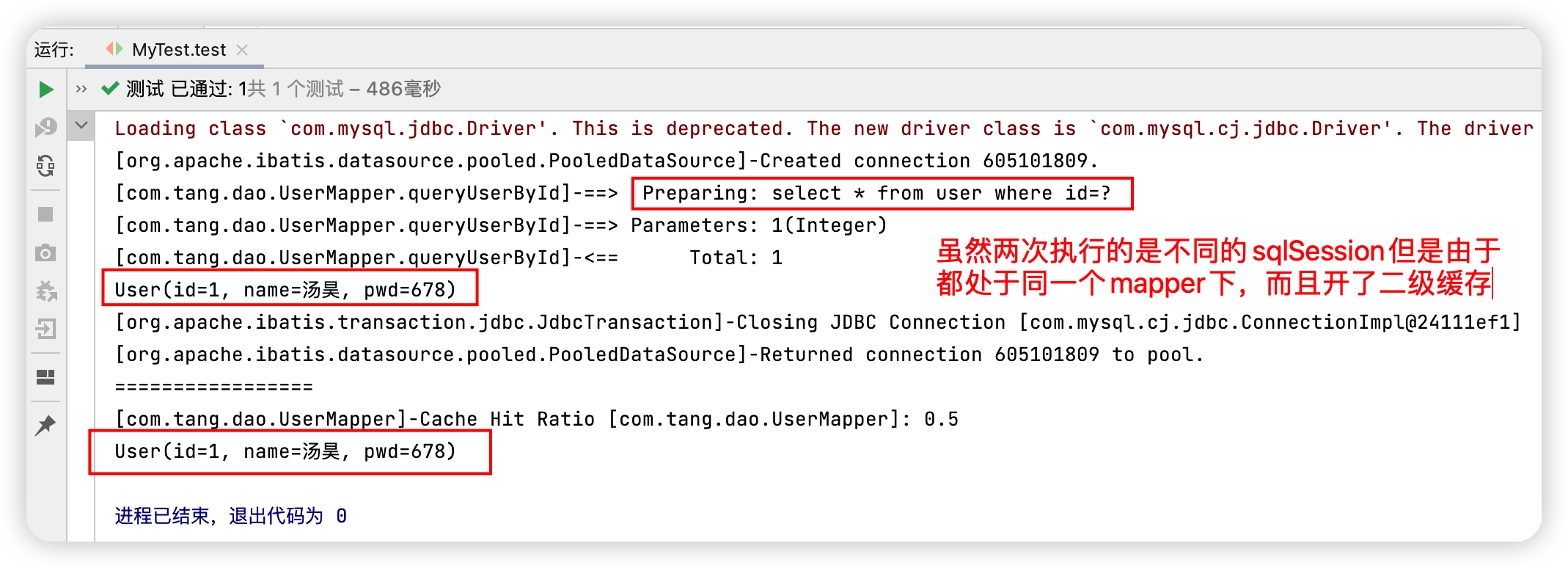
③測試
@Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
SqlSession sqlSession2 = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
sqlSession.close();
//mapper.updateUser(new User(2, "aaa", "bbb"));
// sqlSession.clearCache();
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
System.out.println("=================");
User user1 = mapper2.queryUserById(1);
System.out.println(user1);
}
測試結果
- 問題:如果二級快取中沒有寫那些引數,則我們的實體類需要序列化,否則就會報如下錯誤!
Cause: java.io.NotSerializableException: com.tang.pojo.User
解決方法:讓User實體類序列化即可,也就是如下實現Serializable介面即可實現實體類的序列化
import java.io.Serializable;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private int id;
private String name;
private String pwd;
}
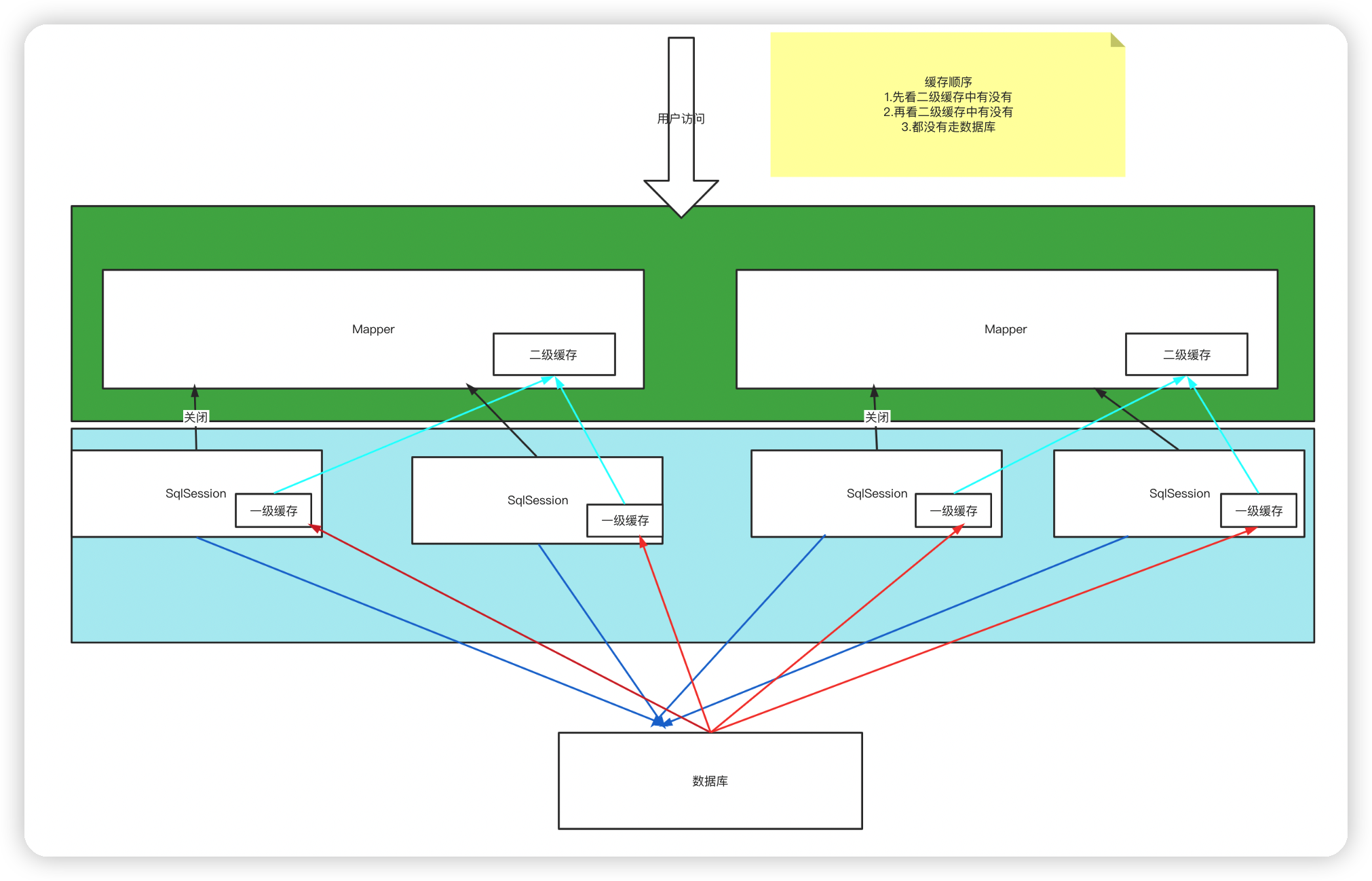
小結:
-
只要開啟了二級快取,在同一個Mapper下就有效
-
所有的資料都會先放在一級快取中;
-
只有當對談提交,或者關閉的時候,才會提交到二級快取中!
5.Mybatis快取原理
6.自定義快取Ehcache
Ehcahe是一種廣泛使用的開源Java分散式快取,主要面向通用快取要在程式中使用ehcahe,先要導包
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
如果執行報java.lang.NoClassDefFoundError: Could not initialize class net.sf.ehcache.CacheManager就表名ehcache的包導錯了,可以跟改為我上面的包即可
在mapper中指定使用我們的ehcache快取
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
ehcache.xml
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<diskStore path="./tmpdir/Tmp_EhCache"/>
<!--
defaultCache:預設快取策略,當ehcache找不到定義的快取時,則使用這個快取策略。只能定義一個。
-->
<!--
name:快取名稱。
maxElementsInMemory:快取最大數目
maxElementsOnDisk:硬碟最大快取個數。
eternal:物件是否永久有效,一但設定了,timeout將不起作用。
overflowToDisk:是否儲存到磁碟,當系統當機時
timeToIdleSeconds:設定物件在失效前的允許閒置時間(單位:秒)。僅當eternal=false物件不是永久有效時使用,可選屬性,預設值是0,也就是可閒置時間無窮大。
timeToLiveSeconds:設定物件在失效前允許存活時間(單位:秒)。最大時間介於建立時間和失效時間之間。僅當eternal=false物件不是永久有效時使用,預設是0.,也就是物件存活時間無窮大。
diskPersistent:是否快取虛擬機器器重啟期資料 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:這個引數設定DiskStore(磁碟快取)的快取區大小。預設是30MB。每個Cache都應該有自己的一個緩衝區。
diskExpiryThreadIntervalSeconds:磁碟失效執行緒執行時間間隔,預設是120秒。
memoryStoreEvictionPolicy:當達到maxElementsInMemory限制時,Ehcache將會根據指定的策略去清理記憶體。預設策略是LRU(最近最少使用)。你可以設定為FIFO(先進先出)或是LFU(較少使用)。
clearOnFlush:記憶體數量最大時是否清除。
memoryStoreEvictionPolicy:可選策略有:LRU(最近最少使用,預設策略)、FIFO(先進先出)、LFU(最少存取次數)。
FIFO,first in first out,這個是大家最熟的,先進先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一點就是講一直以來最少被使用的。如上面所講,快取的元素有一個hit屬性,hit值最小的將會被清出快取。
LRU,Least Recently Used,最近最少使用的,快取的元素有一個時間戳,當快取容量滿了,而又需要騰出地方來快取新的元素的時候,那麼現有快取元素中時間戳離當前時間最遠的元素將被清出快取。
-->
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="cloud_user"
eternal="false"
maxElementsInMemory="5000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LRU"/>
</ehcache>