詳解ConCurrentHashMap原始碼(jdk1.8)
ConCurrentHashMap是一個支援高並行集合,常用的集合之一,在jdk1.8中ConCurrentHashMap的結構和操作和HashMap都很類似:
- 資料結構基於
陣列+連結串列/紅黑樹。 get通過計算hash值後取模陣列長度確認索引來查詢元素。put方法也是先找索引位置,然後不存在就直接新增,存在相同key就替換。- 擴容都是建立新的
table陣列,原來的資料轉移到新的table陣列中。
唯一不同的是,HashMap不支援並行操作,ConCurrentHashMap是支援並行操作的。所以ConCurrentHashMap的設計也比HashMap也複雜的多,通過閱讀ConCurrentHashMap的原始碼,也更加了解一些並行的操作,比如:
volatile執行緒可見性CAS樂觀鎖synchronized同步鎖/悲觀鎖
詳見HashMap相關文章:
資料結構
ConCurrentHashMap是由陣列+連結串列/紅黑樹組成的:
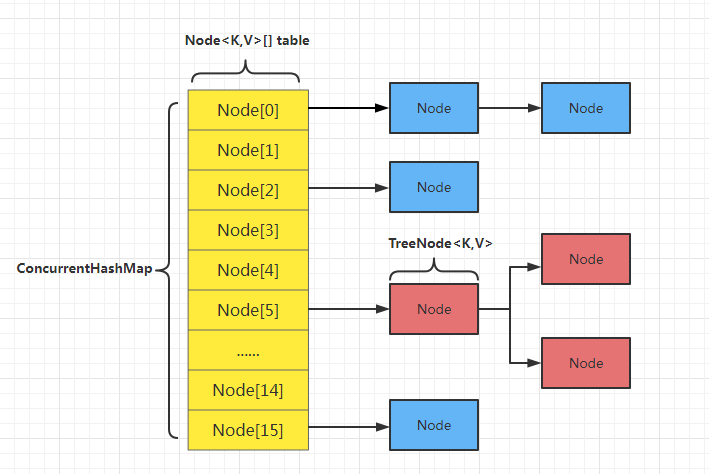
其中左側部分是一個雜湊表,通過hash演演算法確定元素在陣列的下標:
transient volatile Node<K,V>[] table;
連結串列是為了解決hash衝突,當發生衝突的時候。採用連結串列法,將元素新增到連結串列的尾部。其中Node節點儲存資料:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
}
Node節點包含:
hashhash值key值value值nextnext指標
主要屬性欄位
// 最大容量
int MAXIMUM_CAPACITY = 1 << 30;
// 初始化容量
int DEFAULT_CAPACITY = 16
// 控制陣列初始化或者擴容,為負數時,表示陣列正在初始化或者擴容。-1表示正在初始化。其他情況-n表示n執行緒正在擴容。
private transient volatile int sizeCtl;
// 裝載因子
float LOAD_FACTOR = 0.75f
// 連結串列長度為 8 轉成紅黑樹
int TREEIFY_THRESHOLD = 8
// 紅黑樹長度小於6退化成連結串列
int UNTREEIFY_THRESHOLD = 6;
獲取資料get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 計算hash值
int h = spread(key.hashCode());
// 判斷 tab 不為空並且 tab對應的下標不為空
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// eh < 0 表示遇到擴容
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍歷連結串列,直到遍歷key相等的值
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
- 獲取資料流程:
- 呼叫
spread獲取hash值,通過(n - 1) & h取餘獲取陣列下標的資料。 - 首節點符合就返回資料。
eh<0表示遇到了擴容,會呼叫正在擴容節點ForwardingNode的find方法,查詢該節點,匹配就返回。- 遍歷連結串列,匹配到資料就返回。
- 以上都不符合,返回
null。
- 呼叫
get如何實現執行緒安全
get方法裡面沒有使用到鎖,那是如何實現執行緒安全。主要使用到了volatile。
volatile
一個執行緒對共用變數的修改,另外一個執行緒能夠立刻看到,我們稱為可見性。
cpu執行速度比記憶體速度快很多,為了均衡和記憶體之間的速度差異,增加了cpu快取,如果在cpu快取中存在cpu需要資料,說明命中了cpu快取,就不經過存取記憶體。如果不存在,則要先把記憶體的資料載入到cpu快取中,在返回給cpu處理器。
在多核cpu的伺服器中,每個cpu都有自己的快取,cpu之間的快取是不共用的。 當多個執行緒在不同的cpu上執行時,比如下圖中,執行緒A操作的是cpu-1上的快取,執行緒B操作的是cpu-2上的快取,這個時候,執行緒A對變數V的操作對於執行緒B是不可見的。
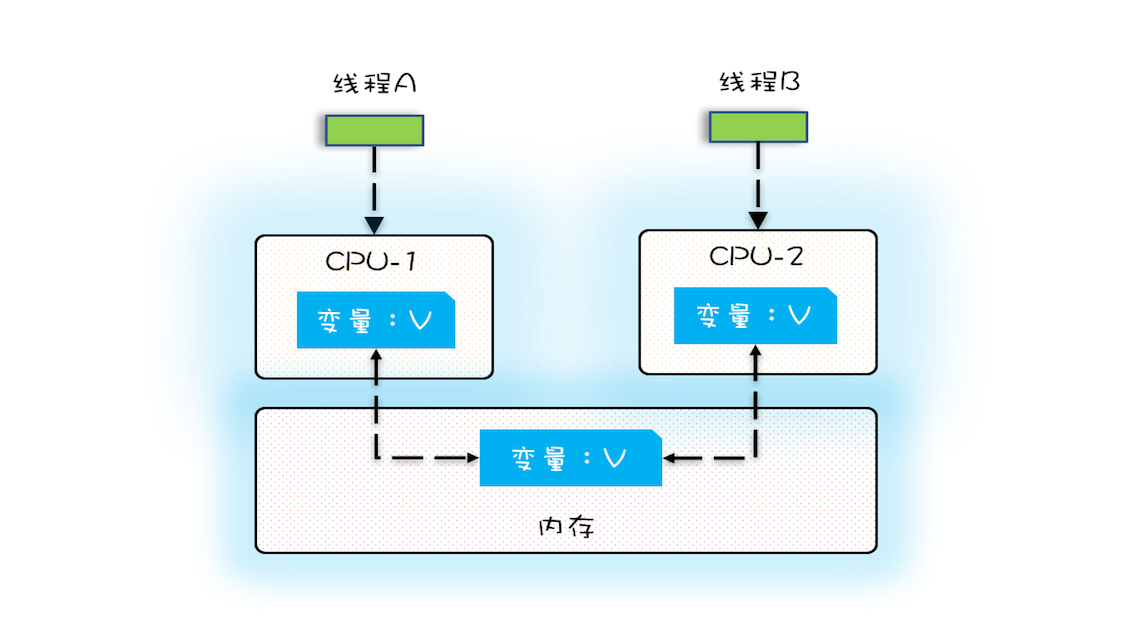
但是一個變數被volatile宣告,它的意思是:
告訴編譯器,對這個變數的讀寫,不能使用cpu快取,必須從記憶體中讀取或者寫入。
上面的變數V被volatile宣告,執行緒A在cup-1中修改了資料,會直接寫到記憶體中,不會寫入到cpu快取中。而執行緒B無法從cpu快取讀取變數,需要從主記憶體拉取資料。
- 總結:
- 使用
volatile關鍵字的變數會將修改的變數強制寫入記憶體中。 - 其他執行緒讀取變數時,會直接從記憶體中讀取變數。
- 使用
volatile在get應用
table雜湊表
transient volatile Node<K,V>[] table;
使用volatile宣告陣列,表示參照地址是volatile而不是陣列元素是volatile。
既然不是
陣列元素被修飾成volatile,那實現執行緒安全在看Node節點。
Node節點
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
其中val和next都用了volatile修飾,在多執行緒環境下,執行緒A修改節點val或者新增節點對別人執行緒是可見的。
所以get方法使用無鎖操作是可以保證執行緒安全。
既然
volatile修飾陣列對get操作沒有效果,那加在volatile上有什麼目的呢?
是為了陣列在擴容的時候對其他執行緒具有可見性。
- jdk 1.8 的get操作不使用鎖,主要有兩個方面:
- Node節點的
val和next都用volatile修飾,保證執行緒修改或者新增節點對別人執行緒是可見的。 volatile修飾table陣列,保證陣列在擴容時其它執行緒是具有可見性的。
- Node節點的
新增資料put
put(K key, V value)直接呼叫putVal(key, value, false)方法。
public V put(K key, V value) {
return putVal(key, value, false);
}
putVal()方法:
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key或者value為空,報空指標錯誤
if (key == null || value == null) throw new NullPointerException();
// 計算hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// tab為空或者長度為0,初始化table
tab = initTable();
// 使用volatile查詢索引下的資料
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 索引位置沒有資料,使用cas新增資料
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// MOVED表示陣列正在進行陣列擴容,當前進行也參加到陣列複製
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 陣列不在擴容和也有值,說明資料下標處有值
// 連結串列中有資料,使用synchronized同步鎖
synchronized (f) {
if (tabAt(tab, i) == f) {
// 為連結串列
if (fh >= 0) {
binCount = 1;
// 遍歷連結串列
for (Node<K,V> e = f;; ++binCount) {
K ek;
// hash 以及key相同,替換value值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 遍歷到連結串列尾,新增連結串列節點
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 紅黑樹,TreeBin雜湊值固定為-2
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 連結串列轉紅黑樹
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
- 新增資料流程:
- 判斷
key或者value為null都會報空指標錯誤。 - 計算
hash值,然後開啟沒有終止條件的迴圈。 - 如果
table陣列為null,初始化陣列。 - 陣列
table不為空,通過volatile找到陣列對應下標是否為空,為空就使用CAS新增頭結點。 - 節點的
hash=-1表示陣列正在擴容,一起進行擴容操作。 - 以上不符合,說明索引處有值,使用
synchronized鎖住當前位置的節點,防止被其他執行緒修改。- 如果是連結串列,遍歷連結串列,匹配到相同的
key替換value值。如果連結串列找不到,就新增到連結串列尾部。 - 如果是紅黑樹,就新增到紅黑樹中。
- 如果是連結串列,遍歷連結串列,匹配到相同的
- 節點的連結串列個數大於
8,連結串列就轉成紅黑樹。
- 判斷
ConcurrentHashMap鍵值對為什麼都不能為null,而HashMap就可以?
通過get獲取資料時,如果獲取的資料是null,就無法判斷,是put時的value為null,還是找個key就沒做過對映。HashMap是非並行的,可以通過contains(key)判斷,而支援並行的ConcurrentHashMap在呼叫contains方法和get方法的時候,map可能已經不同了。參考
如果陣列table為空呼叫initTable初始化陣列:
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
// table 為 null
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
// sizeCtl<0表示其它執行緒正在初始化陣列陣列,當前執行緒需要讓出CPU
Thread.yield(); // lost initialization race; just spin
// 呼叫CAS初始化table表
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
initTable判斷sizeCtl值,如果sizeCtl為-1表示有其他執行緒正在初始化陣列,當前執行緒呼叫Thread.yield讓出CPU。而正在初始化陣列的執行緒通過Unsafe.compareAndSwapInt方法將sizeCtl改成-1。
initTable最外層一直使用while迴圈,而非if條件判斷,就是確保陣列可以初始化成功。
陣列初始化成功之後,再執行新增的操作,呼叫tableAt通過volatile的方式找到(n-1)&hash處的bin節點。
- 如果為空,使用
CAS新增節點。 - 不為空,需要使用
synchronized鎖,索引對應的bin節點,進行新增或者更新操作。
Insertion (via put or its variants) of the first node in an
empty bin is performed by just CASing it to the bin. This is
by far the most common case for put operations under most
key/hash distributions. Other update operations (insert,
delete, and replace) require locks. We do not want to waste
the space required to associate a distinct lock object with
each bin, so instead use the first node of a bin list itself as
a lock. Locking support for these locks relies on builtin
"synchronized" monitors.
如果f的hash值為-1,說明當前f是ForwaringNode節點,意味著有其它執行緒正在擴容,則一起進行擴容操作。
完成新增或者更新操作之後,才執行break終止最外層沒有終止條件的for迴圈,確保資料可以新增成功。
最後執行addCount方法。
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 利用CAS更新baseCoount
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
// check >= 0,需要檢查是否需要進行擴容操作
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
擴容transfer
什麼時候會擴容
*插入一個新的節點:
- 新增節點,所在的連結串列元素個數達到閾值8,則會呼叫
treeifyBin把連結串列轉成紅黑樹,在轉成之前,會判斷陣列長度小於MIN_TREEIFY_CAPACITY,預設是64,觸發擴容。 - 呼叫
put方法,在結尾addCount方法記錄元素個數,並檢查是否進行擴容,陣列元素達到閾值時,觸發擴容。
不使用加鎖的,支援多執行緒擴容。利用並行處理減少擴容帶來效能的影響。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
// 建立nextTab,容量為原來容量的兩倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
// 擴容是丟擲異常,將閾值設定成最大,表示不再擴容。
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
// 建立 ForwardingNode 節點,作為標記位,表明當前位置已經做過桶處理
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance = true 表明該節點已經處理過了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 控制 --i,遍歷原hash表中的節點
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 用CAS計算得到的transferIndex
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// 將原陣列中的節點賦值到新的陣列中,nextTab賦值給table,清空nextTable。
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// 所有節點完成複製工作,
if (finishing) {
nextTable = null;
table = nextTab;
// 設定新的閾值為原來的1.5倍
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 利用CAS方法更新擴容的閾值,sizeCtl減一,說明新加入一個執行緒參與到擴容中
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
// 遍歷的節點為null,則放入到ForwardingNode指標節點
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// f.hash==-1表示遍歷到ForwardingNode節點,說明該節點已經處理過了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 節點加鎖
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// fh>=0,表示為連結串列節點
if (fh >= 0) {
// 構建兩個連結串列,一個是原連結串列,另一個是原連結串列的反序連結串列
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 在nextTable i 位置處插入連結串列
setTabAt(nextTab, i, ln);
// 在nextTable i+n 位置處插入連結串列
setTabAt(nextTab, i + n, hn);
// 在table i的位置處插上ForwardingNode,表示該節點已經處理過
setTabAt(tab, i, fwd);
// 可以執行 --i的操作,再次遍歷節點
advance = true;
}
// TreeBin紅黑樹,按照紅黑樹處理,處理邏輯和連結串列類似
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 擴容後樹節點的個數<=6,紅黑樹轉成連結串列
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
擴容過程有的複雜,主要涉及到多執行緒的並行擴容,ForwardingNode的作用就是支援擴容操作,將已經處理過的節點和空節點置為ForwardingNode,並行處理時多個執行緒處理ForwardingNode表示已經處理過了,就往後遍歷。
總結
-
ConcurrentHashMap是基於陣列+連結串列/紅黑樹的資料結構,新增、刪除、更新都是先通過計算key的hash值確定資料的索引值,這和HashMap是類似的,只不過ConcurrentHashMap針對並行做了更多的處理。 -
get方法獲取資料,先計算hash值再再和陣列長度取餘操作獲取索引位置。- 通過
volatile關鍵字找到table保證多執行緒環境下,陣列擴容具有可見性,而Node節點中val和next指標都使用volatile修飾保證資料修改後別的執行緒是可見的。這就保證了ConcurrentHashMap的執行緒安全性。 - 如果遇到陣列擴容,就參與到擴容中。
- 首節點值匹配到資料就直接返回資料,否則就遍歷連結串列或者紅黑樹,直到匹配到資料。
- 通過
-
put方法新增或者更新資料。- 如果
key或value為空,就報錯。這是因為在呼叫get方法獲取資料為null,無法判斷是獲取的資料為null,還是對應的key就不存在對映,HashMap可以通過contains(key)判斷,而ConcurrentHashMap在多執行緒環境下呼叫contains和get方法的時候,map可能就不同了。 - 如果
table陣列為空,先初始化陣列,先通過sizeCtl控制並行,如果小於0表示有別的執行緒正在初始化陣列,就讓出CPU,否則使用CAS將sizeCtl設定成-1。 - 初始化陣列之後,如果節點為空,使用
CAS新增節點。 - 不為空,就鎖住該節點,進行新增或者更新操作。
- 如果
-
transfer擴容- 在新增一個節點時,連結串列個數達到閾值
8,會將連結串列轉成紅黑樹,在轉成之前,會先判斷陣列長度小於64,會觸發擴容。還有集合個數達到閾值時也會觸發擴容。 - 擴容陣列的長度是原來陣列的兩倍。
- 為了支援多執行緒擴容建立
ForwardingNode節點作為標記位,如果遍歷到該節點,說明已經做過處理。 - 遍歷賦值原來的資料給新的陣列。
- 在新增一個節點時,連結串列個數達到閾值
參考
Java並行——ConcurrentHashMap(JDK 1.8)