什麼是編輯器中的常數傳播?
摘要:常數傳播,顧名思義,就是把常數傳播到使用了這個常數的地方去,用常數替換原來的變數。
本文分享自華為雲社群《編譯器優化那些事兒(2):常數傳播》,作者:畢昇小助手。
基礎知識盤點
- 基本塊 (Basic Block):一個基本塊內的指令,處理器會從基本塊的第一條指令順序執行到基本塊的最後一條指令,中間不會跳轉到其它地方去,也不會有其它地方跳轉到基本塊的非首條指令上來。
- 控制流圖 (Control Flow Graph):控制流圖的節點是基本塊,邊代表基本塊之間的跳轉。基本塊A到基本塊B有一條邊,表示基本塊A的最後一條指令是一個跳轉指令,跳轉到了基本塊B的第一條指令;或者基本塊A的最後一條指令執行完可以順序的走向基本塊B的第一條指令。
- SSA (Static Single Assignment):靜態單賦值,指程式的一種表示形式,在該形式中變數只被賦值一次,如果變數需要更新,會使用一個新的變數。決定使用哪個分支處的變數,會使用Φ函數。
例如
min = a; if(min > b) min = b; return min;
轉換為SSA形式為:
min = a; if(min > b) min2 = b; return Φ(min, min2)
- 區域性優化:指基本塊內,跨指令的優化。
- 全域性優化:過程(函數)內的,跨基本塊的優化。
- 過程間的優化:跨過程(函數),編譯單元的優化。
1.什麼是常數傳播
首先來認識一下什麼是常數傳播,常數傳播也叫常數摺疊,但有些資料中對它們的定義又是區分開來的。下面來看看它們分別是什麼?
常數傳播,顧名思義,就是把常數傳播到使用了這個常數的地方去,用常數替換原來的變數。
x = 3; y = 4; z = x + y;
->
x = 3; y = 4; z = 3 + 4;
什麼是常數摺疊?常數摺疊就是當運運算元左右兩邊都是常數時,把結果計算出來替代原來的那部分表示式。
z = 3 + 4;
–>
z = 7;
現在的常數傳播優化技術能同時實現上面介紹的傳播和摺疊的功能,所以現在通常不對它們加以區分,本文後續就把常數傳播和摺疊統稱為常數傳播了。
為什麼會有常數?
程式中的常數來源有3種
- 程式設計師書寫的,比如magic number
- 宏定義展開後帶來的,這種情況在大型工程檔案中非常普遍
- 在程式優化過程中由其它的優化技術帶來的常數
為什麼要進行常數傳播優化?
從上面簡單的例子中可以看到,常數傳播可以把原本在執行時的計算轉移到編譯時進行,減小了程式執行時的開銷。同時常數傳播還有助於實現其它的優化,比如死程式碼消除。
如何實現?
前面介紹的常數傳播的例子非常簡單而且直觀。如果程式的控制邏輯比較複雜時,判斷一個變數是否是常數,就不是一件簡單的事了,需要藉助資料流的分析才能判斷某個變數是否是常數。而且這個判斷是保守的,即不能充分證明某個變數是常數的話就認為它是變數。這種保守的分析結果是可以接受的,因為我們優化程式的時候在效能提升與程式語意保證時優先選擇保證程式語意不變。
下面我們先初步學習一下資料流分析。
2.資料流分析
資料流分析常常是為了實現全域性優化、過程間優化,或者程式靜態分析而進行的分析技術。分析得到的資訊可以支撐各種優化技術的落實。
考慮下面這條指令,我們能對它做什麼優化呢?
z = x + y;
+ 代表各種有效的運運算元, 比如±*/等
最基本的,有下面3種假設:
- 如果x或者y是常數,我們可以做常數傳播, 用常數值替代變數x, y。 如果x和y都是常數,可以在編譯時刻把x+y計算出來,並賦值給z,這樣就不會在執行時做這樣的計算了。
- 如果x+y在前面已經被計算過了,而且x和y再沒有被賦值過(是一個可用表示式),那麼此處就可以將上次計算過的值直接賦值給z, 省去再次計算的代價,這樣的優化稱為公共子表示式的消除。
- 如果z從這裡開始到程式結尾再沒有被使用(z是不活躍變數),或者是有使用,但使用前被重新賦值了(z是不活躍變數),那麼這個賦值語句是沒用的,可以刪除掉這條語句。
可以看到對每一種可能的優化,都需要一定的依據。這些依據就需要進行資料流的分析來獲取。
下面我們介紹一下非常基礎的3種資料流模式。
- 到達定值
告訴我們在一個程式點上,過程(函數)裡的變數分別是在什麼位置被定值(賦值)的。常用在常數傳播,複製傳播上。 - 可用表示式
告訴我們在一個程式點上,可用的表示式有哪些。常用在公共子表示式消除。 - 活躍變數
告訴我們在一個程式點上,活躍變數(將來還會用到的變數)有哪些。常用於優化暫存器分配,刪除死程式碼。
2.1 到達定值
2.1.1 轉移函數
程式中的每一條語句都會對程式的狀態產生影響,程式的狀態包括了暫存器的值、記憶體的值、讀寫的檔案等。對於特定的資料流分析,我們只關心對我們分析或者程式優化有用的那部分內容。比如對到達定值分析,我們只跟蹤變數的定值情況,對可用表示式的分析,我們跟蹤表示式的生成以及表示式分量的賦值情況,對於活躍變數我們關心變數的賦值和使用情況。
我們用轉移函數來表示程式語句對程式狀態的影響:
OUT=f_d(IN)OUT=fd(IN)
f_dfd 是語句d的轉移函數。IN是語句d前面的程式狀態,OUT是語句d之後的程式狀態。
同樣的,基本塊對程式狀態也有影響,基本塊也有轉移函數:
OUT = f_B(IN)OUT=fB(IN)
f_BfB 是基本塊B的轉移函數,IN是基本塊B之前的程式狀態(也可表示為IN[B]),OUT是基本塊B結束後的程式狀態(也可表示為OUT[B])。
不同的分析目的,轉移函數不同,對於到達定值分析,如果遇到下面的一條語句
d: u = v + w

下面我們看一個具體的例子,在下面的這個流圖中,每一個基本塊生成的定值和殺死的定值已標記在圖右側。
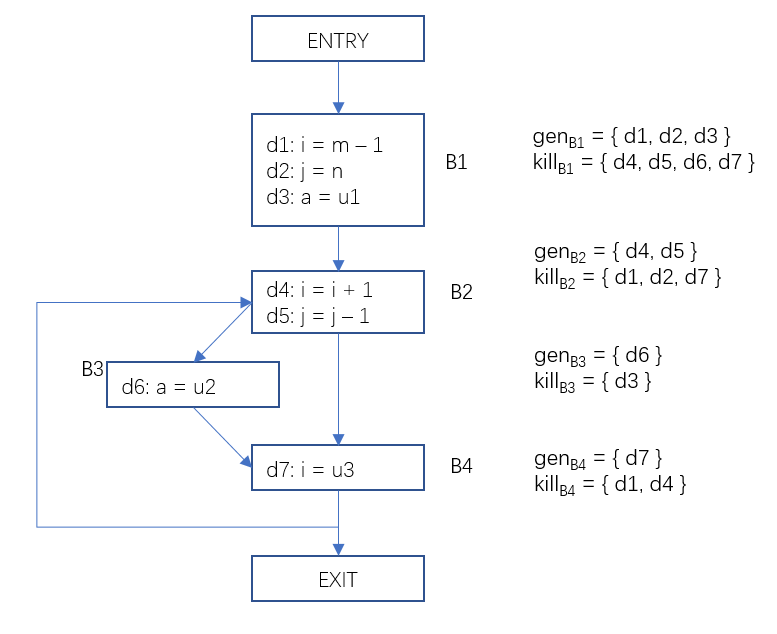
圖1 基本塊的生成定值和殺死定值集合
2.1.2 資料流分析的基本思想
對每個基本塊,根據輸入狀態,應用轉移函數,求解輸出狀態,迴圈進行此操作,直到所有的基本塊的輸出狀態不再變化為止。
2.1.3 交匯運算(meet operator)
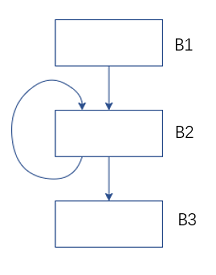
圖2 資料流分析-交匯運運算元的意義
對於上面的控制流圖,B2前驅節點包括B1和B2自身。B2的輸入狀態需要匯合B1結束後的狀態OUT[B1] 和 B2結束後的狀態OUT[B2], 如何匯合呢?這取決於我們的分析目的,對於到達定值分析,我們要彙集所有路徑上過來的定值集合,所以對前驅節點的輸出做並集運算OUT[B1]∪OUT[B2];而對於可用表示式分析,只有每一條通往此基本塊的路徑上都有這個表示式的生成時我們才說這個表示式在此基本塊上是可用的,所以交匯運算是求交集OUT[B1]∩OUT[B2]。交匯運算用符號∧表示。
對上面的這個控制流圖中的B2基本塊,在第一次分析時,它自身的輸出是初始化的值∅, 第二次分析時,它的輸出就是上一次分析後得到輸出了,就可能不再是∅了。這樣迭代多次後,它的輸出不再變化。當所有的基本塊的輸出都不再變化時,我們說這個時候到了一個定點(fix point)。
當分析達到定點時,資料流分析的結果也就得到了。
2.1.4 到達定值分析的迭代演演算法

說明:此演演算法是非SSA表示上的到達定值分析的演演算法,這裡用這個相對來說比較原始的演演算法旨在介紹它最基本的思路;如果要在SSA形式上進行到達定值分析會更加高效,前提條件是需要把程式轉換為SSA形式的表示。後續介紹的活躍變數分析,可用表示式分析也是如此。
程式範例
下面我們用真實的程式對上「圖1」表示的程式做到達定值分析,(這裡僅列出主要的程式片段)
// 定義一個基本塊的屬性結構 struct N{ string name; // 基本塊名稱 bitset gen {}; // 生成的定值 bitset kill {}; // 殺死的定值 bitset in {}; // 輸入定值集合 bitset out {}; // 輸出定值集合 vector pre{}; // 前驅基本塊 }; // 基本塊的屬性和初始化 shared_ptr entry, b1, b2, b3, b4, exit{}; entry = make_shared(N{"entry", 0, 0, 0, 0, {}}); b1 = make_shared(N{"b1", 0B0000111, 0B1111000, 0, 0, {}}); b2 = make_shared(N{"b2", 0B0011000, 0B1000011, 0, 0, {}}); b3 = make_shared(N{"b3", 0B0100000, 0B0000100, 0, 0, {}}); b4 = make_shared(N{"b4", 0B1000000, 0B0001001, 0, 0, {}}); exit = make_shared(N{"exit", 0, 0, 0, 0, {}}); // 構建基本塊的前驅,形成CFG entry->pre = {nullptr}; b1->pre = {entry}; b2->pre = {b1, b4}; b3->pre = {b2}; b4->pre = {b2, b3}; exit->pre = {b4}; // 到達定值分析過程 bool anyChange{}; vector BBs{b1, b2, b3, b4, exit}; do { anyChange = false; for (auto B : BBs) { for (auto p : B->pre) { B->in |= p->out; } auto new_out = B->gen | B->in & ~B->kill; if (new_out != B->out) { anyChange = true; } B->out = new_out; } } while (anyChange); // 輸出每個基本塊的輸入定值,和輸出定值 for (auto B : BBs) { cout < < *B < < endl; }
輸出結果:
b1 0000000 1110000 b2 1110111 0011110 b3 0011110 0001110 b4 0011110 0010111 exit 0010111 0010111
第一列是基本塊名稱,第二列是輸入定值集合的位向量,第三列是輸出集合的位向量。
這樣我們就得到了每一個基本塊的輸入定值集合和輸出定值集合。例如對於基本塊B4, 位向量<0011110>代表{d3,d4,d5,d6},是基本塊開始處的到達定值集合,位向量<0010111>代表{d3,d5,d6,d7},是基本塊結尾處的到達定值集合。有了這些資訊就能很容易的得到在某一個程式點處p, 有哪些變數在何處被定值了。
把結果反饋到流圖中如下:
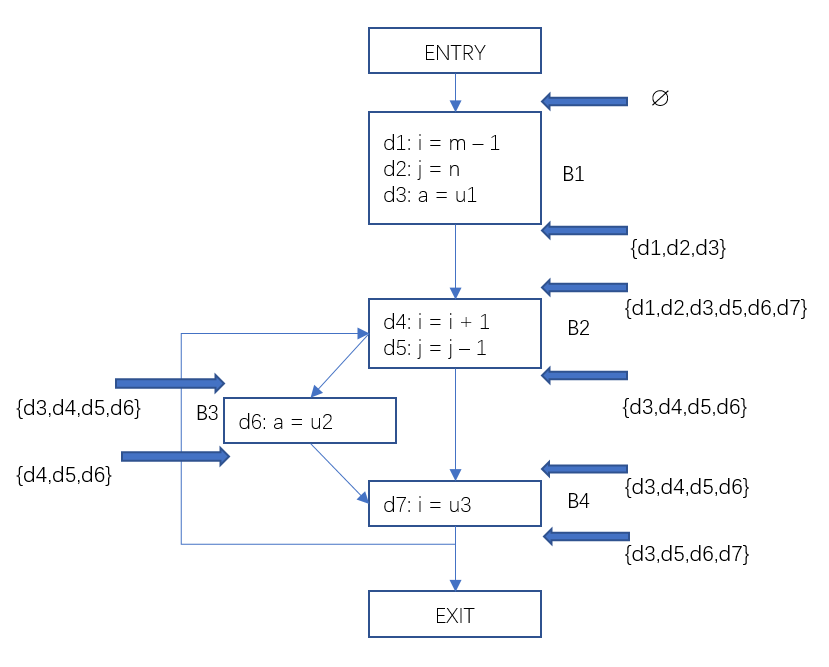
圖3 資料流分析-到達定值結果範例
類似的,我們用相似的方法可以進行活躍變數,可用表示式的分析。
2.2 活躍變數
一個變數x在程式點p上活躍,是說這個變數x從程式點p到程式結尾的路徑上被使用,且在使用前沒有對它進行新的賦值(沒有被殺死)。
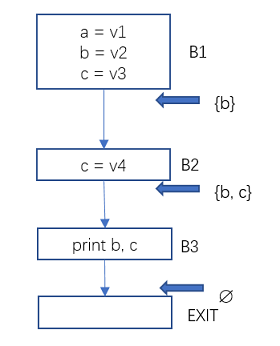
圖4 資料流分析-活躍變數範例1
B1出口處的活躍變數只有b, 這是因為變數a再未被使用過,變數c被B2中的賦值殺死了。
B2出口處的活躍變數有b和c。因為只有b和c在後面的路徑中被使用,且使用前未被重新賦值。
活躍變數分析的迭代演演算法

範例
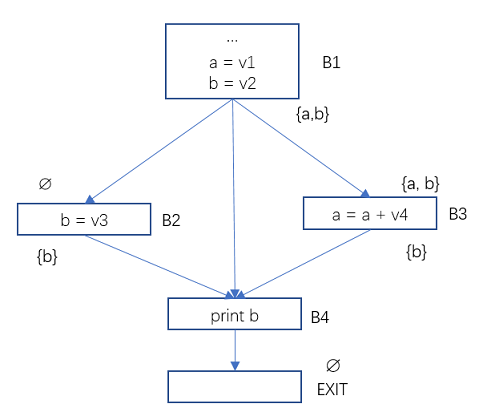
圖5 資料流分析-活躍變數範例2
上面的程式流圖中,基本塊B2, B3, B4的Use和Def為:
Use[B2] = ∅, Def[B2] = {b} Use[B3] = {a}, Def[B3] = {a} Use[B4] = {b}, Def[B4] = ∅

2.3 可用表示式
一個表示式是可用的,是說在通往程式點p的所有路徑上都對那個表示式進行過計算,且計算後再未對錶示式的分量進行賦值過。
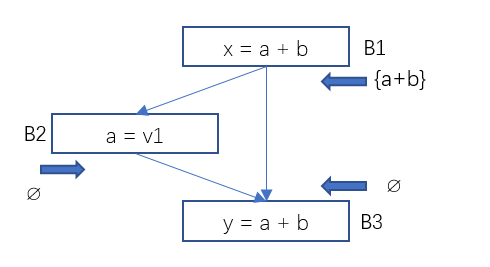
圖6 資料流分析-可用表示式範例1

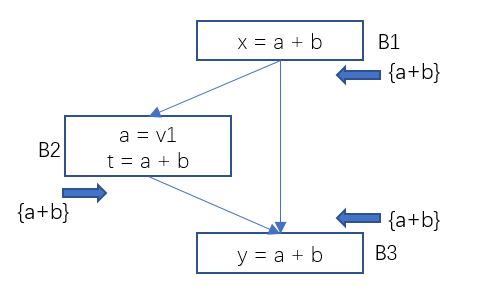
圖7 資料流分析-可用表示式範例2

\qquad for(除ENTRY之外的每個基本塊B)\{ \\ \qquad \qquad IN[B]=\cap_{P是B的一個前驅}OUT[P]; \\ \qquad \qquad OUT[B] = e\_gen_B∪(IN[B]-e\_kill_B); \\ \qquad \} \\ } \ \end{array} $$
3.常數傳播的資料流分析方法
前面介紹了到達定值分析,活躍變數分析,可用表示式分析。它們都是非常基礎的資料流分析,在很多優化過程中會使用到這些資料流分析的結果。現在我們再次回到常數傳播的優化上來。常數傳播也是需要進行資料流的分析。它非常類似於到達定值,但因為常數的性質,又有所不同。
3.1 常數傳播使用的半格
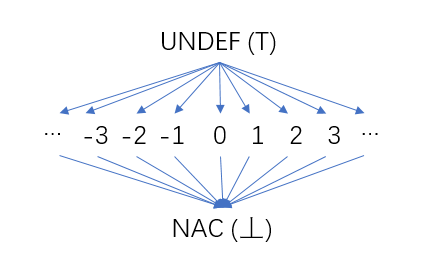
圖8 常數傳播-半格
過程(函數)中的每一個變數都這樣的一個半格,變數的值就是半格中的元素。在常數傳播分析的初始階段,所有的變數的值是不確定的,我們用UNDEF表示(對應格論中的最大值⊤); 隨著我們的分析,有些變數的值是常數,它的值就可以對應到半格的中間那一行的某一個元素,比如常數2。隨著分析的進行,一些變數的值不是常數時(比如定值來自不同的前驅,每個前驅中對該變數的定值不同),用半格最底下的NAC(Not a Constant)表示(對應格論中的最小值⊥)。
前面提到過,交匯運算是對不同集合的合併。對於常數傳播,每個變數的交運算(Meet Operator) 是它的不同取值在半格中的最大下界。交匯運算的規則如下:
- UNDEF ∧ C = C (C表示一個具體的常數)
- UNDEF ∧ NAC = NAC
- C ∧ NAC = NAC
- NAC ∧ NAC = NAC
- C ∧ C = C
- C1 ∧ C2 = NAC (C1≠C2)
例子:
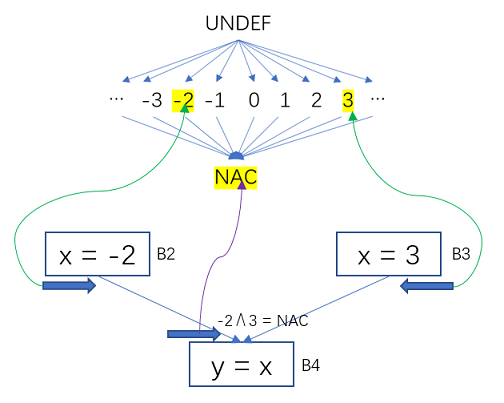
圖9 常數傳播-變數對映到半格的值
B2對x的定值為常數-2,B3對x定值為常數3,-2 ∧ 3就是在x變數的半格上取它們倆的最大下界,為NAC。
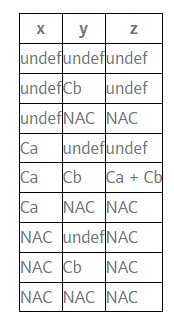
3.2 常數傳播的轉移函數
對語句 z = x + y,轉移函數如下:
例如下面的一個流圖,黃色標記表示因為程式語句的影響而發生變化的變數狀態。變數x在基本塊B2中的值是3, 在B3中的值是undef, 他們匯合後(最大下界)是常數3。
在B4中,x是常數3, x + 3 就是常數6,所以B4中的指令就可以優化為 y = 6了。
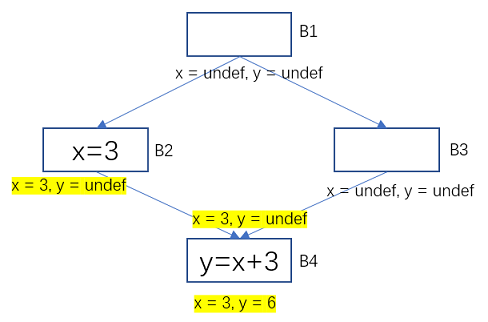
圖10 常數傳播-轉移函數的範例
3.3 常數傳播的一個簡易演演算法
M[entry] == init do change = false worklist < - all BBs; ∀B visisted(B) = false while worklist not empty do B = worklist.remove visited(B) = true m' = fB(m) ∀B' ∈ successors of B if visited(B') then continue end else m[B'] ∧= m' if m[B'] change then change = true end worklist.add(B') end end while(change == true)
範例
下面的程式程式碼
j = 1; x = 10; y = 1; while(myRead()!=0){ x = x * y; y = y * y; j = j + y; } p = j + x + y; printf("%d\n", p);
它的控制流圖
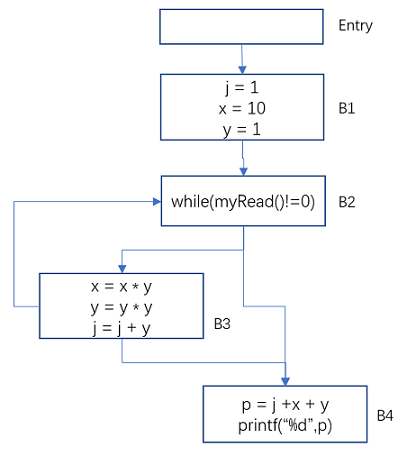
圖11 常數傳播-範例的控制流圖
對此控制流圖應用上面的演演算法
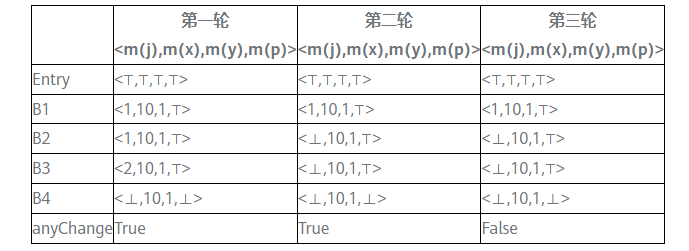
⊤表示undef, ⊥表示NAC (not a constant)
在第三輪迭代時每一個基本塊的輸出不再變化,到達定點。可以看出在基本塊B3出口處,只有x和y是常數,分別是10和1,j和p是非常數。
基於上面的分析,上述程式可以做出如下優化

圖12 常數傳播-程式優化的效果
4.畢昇和LLVM中的常數傳播
畢昇和LLVM的SCCP是一個比較高階的常數傳播的pass, 它使用的演演算法是 Sparse Conditional Constant Propagation。
它的原理和上述的簡易演演算法類似,有2點區別:
- SCCP是在SSA的表示上進行的分析。在SSA的表示上進行常數傳播分析,比非SSA表示的分析要快,但得到的結果是一致的。
- SCCP會對條件分支中的條件進行判斷,區分哪些基本塊是可執行的,哪些是不可執行的,這樣能夠去除不可執行分支的影響,使常數傳播更加準確(減少能傳播但沒有傳播的情況)。
好了,常數傳播就為大家介紹到這裡。常數傳播涉及到資料流的分析,所以這篇文章在介紹常數傳播時也介紹了一下資料流分析,以及常見的三種資料流分析的思路。
5.參考文獻
-
Compilers Principles, Techniques, & Tools
-
http://www.cse.iitm.ac.in/~rupesh/teaching/pa/jan17/scribes/0-cp.pdf
-
Constant propagation with conditional branches https://dl.acm.org/doi/pdf/10.1145/103135.103136
-
https://www.youtube.com/watch?v=S1s4WYABiq0