編譯器優化:何為SLP向量化
摘要:SLP向量化的目標是將相似的獨立指令組合成向量指令,記憶體存取、算術運算、比較運算、PHI節點都可以使用這種技術進行向量化。
本文分享自華為雲社群《編譯器優化那些事兒(1):SLP向量化介紹》,作者:畢昇小助手。
0.Introduction
Superword Level Parallelism (SLP)向量化是llvm auto-vectorization中的一種,另一種是loop vectorizer,詳見於Auto-Vectorization in LLVM[1]。 它在2000年由Larsen 和 Amarasinghe首次作為basic block向量化提出。SLP向量化的目標是將相似的獨立指令組合成向量指令,記憶體存取、算術運算、比較運算、PHI節點都可以使用這種技術進行向量化。它和迴圈向量化最大的差異在於,迴圈向量化關注迭代間的向量化機會,而SLP更關注於迭代內basic block中的向量化的機會。
一個簡單的小例子 case.cpp[1]:
void foo(float a1, float a2, float b1, float b2, float *A) { A[0] = a1*(a1 + b1); A[1] = a2*(a2 + b2); A[2] = a1*(a1 + b1); A[3] = a2*(a2 + b2); }
命令:clang++ case.cpp -O3 -S ;SLP在clang中是預設使能的,可以看到組合中已出現使用向量暫存器的fadd和fmul。
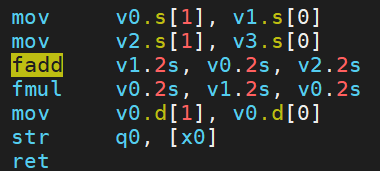
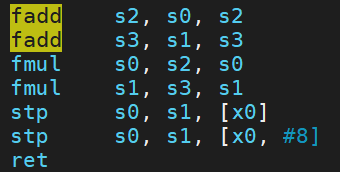
如果編譯命令中加上選項-fno-slp-vectorize 或者 -mllvm -vectorize-slp=false 關閉該優化,則只能得到標量的版本。
讓我們來跟隨《Exploiting Superword Level Parallelism with Multimedia Instruction Sets》[2]這篇經典論文來探究一下SLP向量化的奧祕。
1.原始SLP演演算法介紹
1.1概述
論文中用一張圖來解釋了SLP要做的事情:
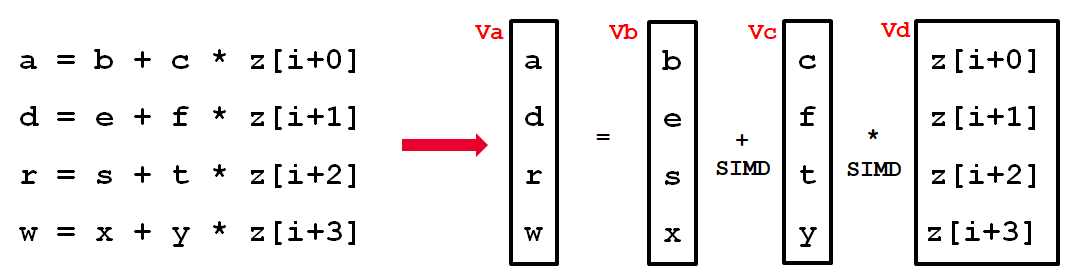
原始SLP例子[2]
這四條語句中的位置相對應的運算元,比如(b,e,s,x)可以pack到一個向量暫存器 Vb 中,同樣的,(c,f,t,y)可以pack到 Vc,(z[i+0]~z[i+3])可以到 Vd。然後可以利用simd指令進行相應的向量化計算。最後根據 Va 中 (a,d,r,w) 的被使用方式,可能還需要將他們從向量暫存器中load出來,稱為unpack。
所以,如果pack運算元的開銷 + 向量化執行的開銷 + unpack運算元的開銷小於原本執行的開銷,那就證明SLP向量化具有效能收益[3]。
1.2 優化場景
為了進一步說明SLP和迴圈向量化在優化場景上的差異,論文[2]中給了兩個例子(可以通過https://godbolt.org/z/EWr4zTc3P直接檢視組合情況)。
1)對於原始迴圈 a,既可以通過 scalar expansion (a method of converting scalar data to match the dimensions of vector or matrix data.) 和 loop fission (the opposite of loop fusion: a loop is split into two or more loops. ) 後被轉換為可以進行迴圈向量化的形式 b,一個induction和一個reduction;也可以經過unroll和rename之後變為 d 這樣的形式,做SLP。但其實由於論文比較老了,目前llvm編譯器對於a這樣形式的迴圈可以直接做向量化。
for (i=0; i<16; i++) { localdiff = ref<i> - curr<i>; diff += abs(localdiff); }
(a)Original loop.
for (i=0; i<16; i++) { T<i> = ref<i> - curr<i>; } for (i=0; i<16; i++) { diff += abs(T<i>); }
(b)After scalar expansion and loop fission.
for (i=0; i<16; i+=4) { localdiff = ref[i+0] - curr[i+0]; diff += abs(localdiff); localdiff = ref[i+1] - curr[i+1]; diff += abs(localdiff); localdiff = ref[i+2] - curr[i+2]; diff += abs(localdiff); localdiff = ref[i+3] - curr[i+3]; diff += abs(localdiff); }
(c)Superword level parallelism exposed after unrolling.
for (i=0; i<16; i+=4) { localdiff0 = ref[i+0] - curr[i+0]; localdiff1 = ref[i+1] - curr[i+1]; localdiff2 = ref[i+2] - curr[i+2]; localdiff3 = ref[i+3] - curr[i+3]; diff += abs(localdiff0); diff += abs(localdiff1); diff += abs(localdiff2); diff += abs(localdiff3); }
(d) Packable statements grouped together after renaming.
2)但是對於如下例子,迴圈向量化需要將do while迴圈轉換為for迴圈,恢復歸納變數,將展開後的迴圈恢復為未展開的形式(loop rerolling)。而SLP只需要將計算 dst[{0, 1, 2, 3}] 的這四條語句組合成一條 使用向量化指令的語句即可。
do { dst[0] = (src1[0] + src2[0]) >> 1; dst[1] = (src1[1] + src2[1]) >> 1; dst[2] = (src1[2] + src2[2]) >> 1; dst[3] = (src1[3] + src2[3]) >> 1; dst += 4; src1 += 4; src2 += 4; } while (dst != end);
看到這裡,可以瞭解到哪些是SLP的優化機會。論文中提出了一種簡單的演演算法來實現,簡而言之是通過尋找independent(無資料依賴)、isomorphic(相同操作)的指令組合成一條向量化指令。
那麼如何找呢?
1.3 演演算法描述
作者注意到如果被 pack 的指令的運算元參照的是相鄰的記憶體,那麼特別適合 SLP 執行。所以核心演演算法就是從識別 adjacent memory references 開始的。
當然尋找這樣的相鄰記憶體參照前也需要做一些準備工作,主要是三部分:(1) Loop Unrolling;(2) Alignment analysis;(3) Pre-Optimization(主要是一些死程式碼和冗餘程式碼消除)。具體不展開講。
接下來我們來看看核心演演算法,主要分為以下4步:
- Identifying Adjacent Memory References
- Extending the PackSet
- Combination
- Scheduling
虛擬碼[4]是:

(1)第一步 find_adj_refs
先來看第一步:Identifying Adjacent Memory References

函數 find_adj_refs 的輸入是 BasicBlock,輸出為集合 PackSet。
遍歷BasicBlock裡面的任意語句對(s, s’),如果他們存取了相鄰的記憶體(比如s存取了arr[1],s’存取了arr[2]),並且他倆能夠pack到一起(即stmts_can_pack() 返回true),那麼將語句對(s, s’)加入集合PacketSet。
這裡用到了一個輔助函數stmts_can_pack,虛擬碼如下:

宣告了可以pack到一起的條件:
- s 和 s’是相同操作 (isomorphic)
- s 和 s’無資料依賴 (independent)
- s 之前沒有作為左運算元出現在 PackSet 中,s’之前沒有作為右運算元出現在 PackSet 中
- s 和 s’滿足對齊要求 (consistent),即要求新加入的語句對的資料型別也是可以和已存在的語句對在記憶體上是對齊的
(2)第二步:Extending the PackSet
從第一步我們可以獲得PacketSet,第二步沿著其中包含的語句的defs 和 uses 來擴充PacketSet。所以這一步的輸入是PacketSet,輸出是擴充後的PacketSet。
虛擬碼如下:

對於PacketSet中的每一個元素pack, 即語句對(s, s’),不斷執行follow_use_defs 和 follow_def_uses函數來分別在同一個BasicBlock中尋找s和s’的源運算元和目標運算元相關的語句,判斷兩個條件,一個是stmts_can_pack是否可以pack,另一個是根據cost model判斷是否有收益,從而擴充PacketSet,直至其不能加入更多的Pack。
(3)第三步:Combination
這一步的輸入為已經儘可能多的(s,s’)語句對組成的PacketSet,輸出則為儘可能可以合併語句對之後的PacketSet。
那麼怎麼合併呢?虛擬碼如下:
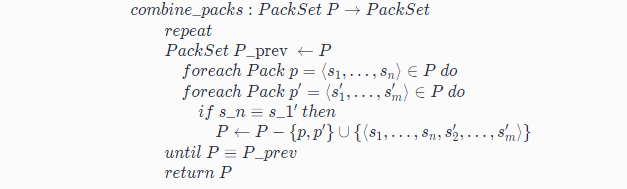
對於兩個Pack,p = (s1,…,sn)和 p’ = (s1’,…,sm’),如果sn與s1‘相同,那麼恭喜,p和 p’ 可以合併成新的 p’’ = (s1,…,sn,s2’,…,sm’)。
(4)最後一步:Scheduling
將PackSet中的語句對根據資料依賴關係整理成simd指令,如果是有迴圈依賴的pack,那麼revert掉,不再對這pack裡的指令向量化。
最後輸出的是包含SIMD指令的BasicBlock。
1.4 一個例子
為了更好理解,論文中也給出了一個例子,我們簡單過一下:
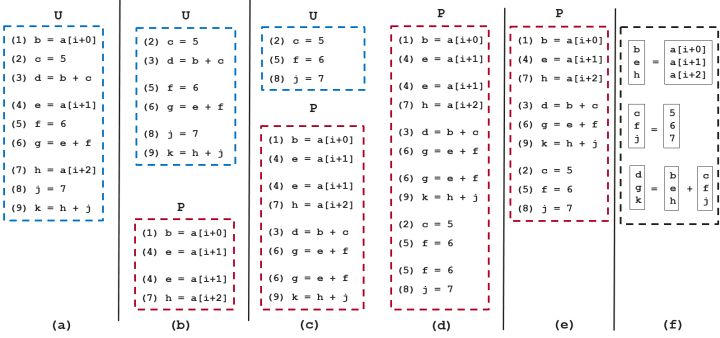
(1)初始狀態,BasicBlock中指令,如(a)。
(2)執行find_adj_refs, 將(1, 4) 和 (4, 7) 加入PackSet, 如(b)。
(3)執行extern_packlist:
a. 函數follow_use_defs 去尋找對a[i+0], a[i+1], a[i+2]進行def的語句,無語句對加入P
b. 函數follow_def_uses 去尋找對b, e, h 使用的語句,將(3, 6) 和 (6, 9) 加入P ,如(c)
c. 函數follow_use_defs 去尋找 c, f, j 進行def的語句,將(2, 5) 和 (5, 8) 加入P ,如(d)
d. 再執行一次follow_def_uses,發現沒有新的語句對可以加入P了,停止。
(4)執行combine_packs:
a. (1), (4))和 (4), (7) 合併為 (1), (4), (7)
b. (3), (6) 和 (6), (9) 合併為 (3), (6), (9)
c. (2), (5) 和 (5), (8) 合併為 (2), (5), (8)
合併後狀態,如(e)。
(5) 執行 scheduling:注意依賴關係,比如 3 依賴於1, 2,最終狀態如(f)。
2.Loop-Aware SLP 演演算法介紹
LLVM 中的 SLP vectorization ,是受Loop-Aware SLP in GCC(by Ira Rosen, Dorit Nuzman,Ayal Zaks) [4]這篇論文啟發來實現的。
2.1 簡介
Loop-Aware 方法是對基礎 SLP 方法的改進,更加重視對跟Loop相關的向量化機會挖掘,其思想是 :
首先,通過迴圈展開將迭代間並行轉換為迭代內並行,使迴圈體內的同構語句條數足夠多;
再利用 SLP 方法進行向量發掘。 當迴圈展開次數為 1 時,Loop-Aware 方法相當於 SLP 方法,當迴圈展開次數為向量化因子 (vector factor,簡稱 VF) 時,將同一條語句展開後的多條語句打包成向量。然而,當迴圈展開不合法或者並行度低於向量化因子時,Loop-Aware 方法無法簡單實施。
換言之,Loop-Aware 向量化方法的實質就是當迭代內並行度較低時,通過迴圈展開將迭代間並行轉換為迭代內並行,其要求迴圈的迭代間並行度較高。
一個典型例子,它可以使能以下因同構語句條數不夠多而原始SLP無法向量化的場景:
for (i=0; i<N; i++) { a[2*i] = b[2*i] + x0; a[2*i+1] = b[2*i+1] + x1; }
需要藉助loop unroll,最終向量化為以下形式:
for (i=0; i<N/2; i++) { va[4*i:4*i+3] = vb[4*i:4*i+3] + {x0,x1,x0,x1}; }
2.2 具體差異
與原始SLP方法的差別,論文作者在其提交給GCC的PATCH中有說明[5],主要有以下三條:
(1)Loop-Aware SLP 著眼於Loop相關的bb塊,而不是程式中的任意bb塊。這麼做的原因有兩個,一是可以複用已有的迴圈向量化的框架,二是大多數有價值的優化機會都在迴圈中。
(2)原始SLP演演算法起始於相鄰記憶體的load或stroe,稱之為seed,根據def-use擴充套件,併合併成Vectorize Size(VS)大小的組。Loop-Aware SLP的seed來自於interleaving analysis之後預先確定的一組相鄰store,所以不需要原始演演算法中的合併這一步驟。具體來說就是,Loop-Aware藉助loop-unroll使得在尋找seed時就能天然地找到能夠剛好合併到一個向量暫存器中的指令,而原始SLP需要在合併階段做排布。
(3)Loop-Aware SLP結合了SLP-based和Loop-based向量化,所以對於以下回圈:
for (i=0; i<N; i++) { a[4*i] = b[4*i] + x0; a[4*i+1] = b[4*i+1] + x1; a[4*i+2] = b[4*i+2] + x2; a[4*i+3] = b[4*i+3] + x3; c<i> = 0; }
可以優化成以下形式:
for (i=0; i<N/4; i++) { //SLP向量化部分 va[16*i:16*i+3] = vb[16*i:16*i+3] + {x0,x1,x2,x3}; va[16*i+4:16*i+7] = vb[16*i+4:16*i+7] + {x0,x1,x2,x3}; va[16*i+8:16*i+11] = vb[16*i+8:16*i+11] + {x0,x1,x2,x3}; va[16*i+12:16*i+15] = vb[16*i+12:16*i+15] + {x0,x1,x2,x3}; //Loop向量化部分 vc[4*i:4*i+3] = {0,0,0,0}; }
3.原始碼閱讀
SLP 是一個 transform pass,在 LLVM 14 中該pass 的實現程式碼位於llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp 和 llvm/Transforms/Vectorize/SLPVectorizer.h中。
3.1 提供的選項
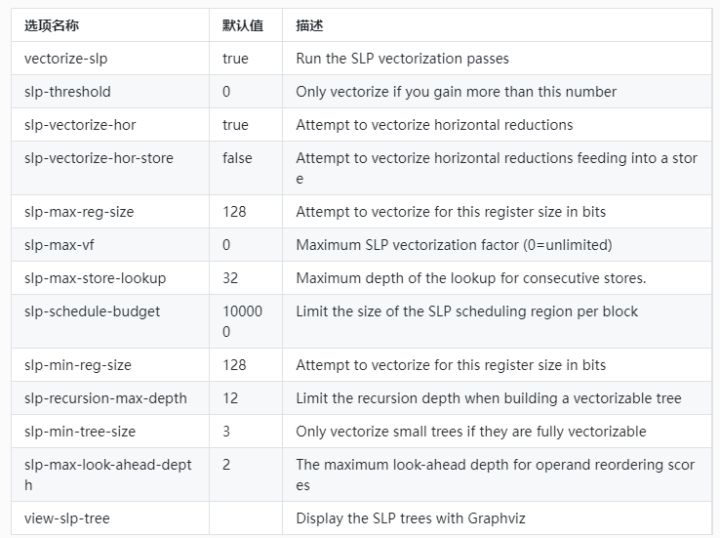
(1)開源選項
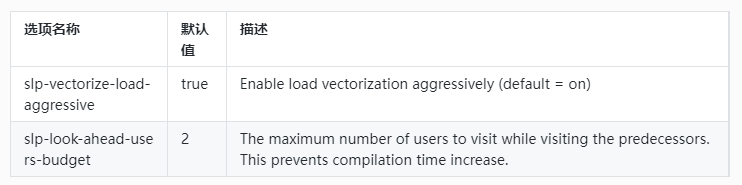
(2)畢昇編譯器額外提供選項
3.2 實現
該 pass 的實現較為複雜,原始碼有10k+,粗略結構如下:
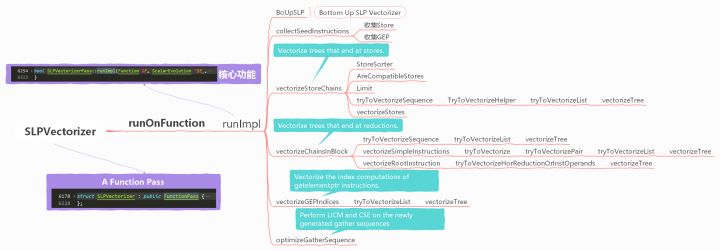
(1)SLPVectorizer
程式碼行數:6178 ~ 6228
該Pass是個function pass,以function為單位進行優化,意味著用的資源也是function級別的。addRequired指的是該PASS中用到的分析結果,addPreserved指的是該pass執行後相應的analysis pass的分析結果仍然有效。
(2)runImpl()
程式碼行數:6254~ 6323
該Pass的核心功能在此函數中管理,用到了兩個容器 Stores和GEPs,定義在標頭檔案:
using StoreList = SmallVector<StoreInst *, 8>; using StoreListMap = MapVector<Value *, StoreList>; using GEPList = SmallVector<GetElementPtrInst *, 8>; using GEPListMap = MapVector<Value *, GEPList>; /// The store instructions in a basic block organized by base pointer. StoreListMap Stores; /// The getelementptr instructions in a basic block organized by base pointer. GEPListMap GEPs;
可以理解成兩個map,以base pointer為key,instructions為 value。
開始優化前,先做兩個無法SLP的判斷:(1)判斷架構是否有向量化暫存器;(2)判斷function attribute是否包含NoImplicitFloat,如果包含則不做。
然後先使用 bottom-up SLP 類從store開始構建從store開始的的指令鏈。
之後呼叫DT->updateDFSNumbers(); 來排序(/// updateDFSNumbers - Assign In and Out numbers to the nodes while walking dominator tree in dfs order.)
接著使用post order(後序)遍歷當前function中所有BB塊,在遍歷中嘗試去向量化,三個場景,(1)Vectorize trees that end at stores.(2)Vectorize trees that end at reductions.(3)vectorize the index computations of getelementptr instructions.
如果向量化成功了,那麼做收尾的調整。
/// Perform LICM and CSE on the newly generated gather sequences. void optimizeGatherSequence();
(3)BoUpSLP
程式碼行數:550 ~ 2448
宣告成員函數和結構型別,具體可以參考 https://llvm.org/doxygen/classllvm_1_1slpvectorizer_1_1BoUpSLP.html。
(4)collectSeedInstructions
程式碼行數:6468 ~ 6501
遍歷BB塊,尋找兩樣東西,符合條件的store和GEP。Stores和GEPs是兩個map,存取同一個基地址的操作放進同一個key的value中。
store 條件1:
bool isSimple() const { return !isAtomic() && !isVolatile(); }
store 條件2:
isValidElementType(SI->getValueOperand()->getType())
GEP條件1:
!(GEP->getNumIndices() > 1 || isa<Constant>(Idx))
GEP條件2:
isValidElementType(Idx->getType())
GEP條件3:
!(GEP->getType()->isVectorTy())
符合以上條件的store或GEP可以做為seed。
(5) vectorizeStoreChains
// Vectorize trees that end at stores.
程式碼行數:10423 ~ 10511
(這部分和llvm-12差異較大,引入了一個函數模板tryToVectorizeSequence)
遍歷Stores,如果一個base pointer相關的指令不少於兩條,就嘗試向量化,呼叫函數 vectorizeStores
程式碼行數:8442 ~ 8573
定義了兩個比較器StoreSorter 和 AreCompatibleStores, 對Stores中的store進行排序(///Sort by type, base pointers and values operand)。以及limit,獲取最小的VF。
以上三個輔助函數給函數 tryToVectorizeSequence 用。
(6)vectorizeChainsInBlock
// Vectorize trees that end at reductions. // Ran into an instruction without users, like terminator, or function call with ignored return value, store
程式碼行數:10089 ~ 10330
對PHI節點下手,將PHI節點作為key。
(7)vectorizeGEPIndices
// Vectorize the index computations of getelementptr instructions. This // is primarily intended to catch gather-like idioms ending at // non-consecutive loads.
程式碼行數:10331 ~ 10422
(8)vectorizeTree
以上(5),(6),(7)三大類向量化場景,最終都要用到vectorizeTree函數。
4.總結
最後以一個例子來總結,SLP和迴圈向量化的差異[6]:

SLP與LV差異[6]
本文主要帶大家瞭解了傳統SLP向量化優化的基本思想,以及Loop-Aware SLP的使用場景,並且大致瞭解了llvm中SLP pass 的原始碼架構,對於具體實現向量化程式碼的建構函式以及cost model機制需要各位對SLP感興趣的讀者深入學習,同時llvm作為一個優秀的現代C++專案,其中的資料結構,程式設計技巧都能啟發大家,受益頗多。
另外,SLP本身作為llvm中自動向量化中的一部分,可以彌補一部分迴圈向量化無法覆蓋到的優化場景。社群中對於SLP的討論也比較火熱,感興趣的讀者也可以到llvm社群參與討論 https://llvm.org/。
以下列舉了一些近年來關於SLP的研究論文:
- PostSLP: Cross-Region Vectorization of Fully or Partially Vectorized Code, LCPC,2019
- Super-Node SLP: Optimized Vectorization for Code Sequences Containing Operators and Their Inverse, CGO,2019
- goSLP: globally optimized superword level parallelism framework, SPLASH, 2018
- Look-Ahead SLP: Auto-vectorization in the presence of commutative operations, CGO, 2018
- VW-SLP: Auto-vectorization with adaptive vector width, PACT, 2018
- SuperGraph-SLP Auto-Vectorization,PACT,2017
- PSLP: padded SLP automatic vectorization, PACT, 2015
- Throttling Automatic Vectorization: When Less is More, CGO, 2015
5.參考資料
[1].https://llvm.org/docs/Vectorizers.html
[2].https://groups.csail.mit.edu/cag/slp/SLP-PLDI-2000.pdf
[3].https://llvm-clang-study-notes.readthedocs.io/_/downloads/en/latest/pdf/
[4].https://gcc.gnu.org/wiki/HomePage?action=AttachFile&do=get&target=GCC2007-Proceedings.pdf
[5].https://gcc.gnu.org/legacy-ml/gcc-patches/2007-08/msg00854.html
[6].http://vporpo.me/papers/postslp_lcpc2019_slides.pdf