使用.NET簡單實現一個Redis的高效能克隆版(七-完結)
譯者注
該原文是Ayende Rahien大佬業餘自己在使用C# 和 .NET構建一個簡單、高效能相容Redis協定的資料庫的經歷。
首先這個"Redis"是非常簡單的實現,但是他在優化這個簡單"Redis"路程很有趣,也能給我們在從事效能優化工作時帶來一些啟示。
原作者:Ayende Rahien
原連結:
https://ayende.com/blog/197665-C/high-performance-net-building-a-redis-clone-analysis-ii
另外Ayende大佬是.NET開源的高效能多正規化資料庫RavenDB所在公司的CTO,不排除這些文章是為了以後會在RavenDB上相容Redis協定做的嘗試。大家也可以多多支援,下方給出了連結
RavenDB地址:https://github.com/ravendb/ravendb
構建Redis克隆版-第二次分析
我要倒退幾步,看看我接下來應該看哪裡,看看我應該注意哪裡。到目前為止,在本系列中,我主要關注的是如何讀取和處理資料。但我認為我們應該退一兩步,看看我們現在的總體情況。我在分析器中執行了使用Pipelines和字串的版本,試圖瞭解我們的進展情況。例如,在上一篇文章中,我使用的 ConcurrentDictionary 有很大的效能開銷。現在還是這樣嗎?
以下是程式碼庫中當前的熱點資料:

更詳細來看,如下所示:

可以看到處理網路請求佔用了大部分的時間,我們再來看看HandleConnection程式碼:
public async Task HandleConnection()
{
while (true)
{
var result = await _netReader.ReadAsync();
var (consumed, examined) = ParseNetworkData(result);
_netReader.AdvanceTo(consumed, examined);
await _netWriter.FlushAsync();
}
}
檢視程式碼和分析器的結果,我覺得我知道如何做的更好。下面的一個小修改給我帶來了2%的效能提升。
public async Task HandleConnection()
{
// 複用了readTask 和 flushTask
// 降低了一些記憶體佔用
ValueTask<ReadResult> readTask = _netReader.ReadAsync();
ValueTask<FlushResult> flushTask = ValueTask.FromResult(new FlushResult());
while (true)
{
var result = await readTask;
await flushTask;
var (consumed, examined) = ParseNetworkData(result);
_netReader.AdvanceTo(consumed, examined);
readTask = _netReader.ReadAsync();
flushTask = _netWriter.FlushAsync();
}
}
我們的想法是將網路的讀寫並行化。這是一個小小的提升,但是任何一點點幫助都是好的,特別是當各種優化會關聯影響時。
看看這個,我們已經有將近20億個ReadAsync呼叫,讓我們看看它的成本是多少:

真是... 哇。
為什麼InternalTokenSource如此昂貴?我敢打賭問題就在這裡,它被鎖定了。在我的用例中,我知道有一個單獨的執行緒在執行這些命令,不會有並行問題,所以值得看看是否可以跳過它。不幸的是,沒有一個簡單的方法可以跳過檢查。幸運的是,我可以從框架中複製程式碼並在本地對其進行修改,以瞭解這樣做的影響。所以我就這樣做了(在建構函式中初始化一次) :
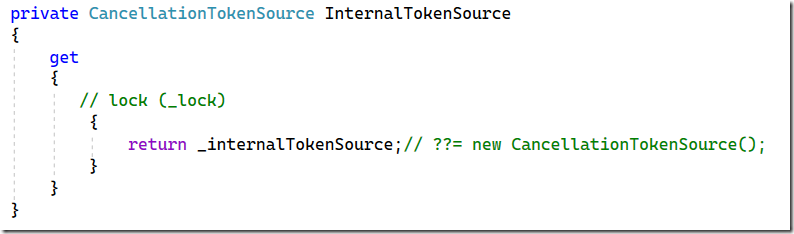
這意味著我們在每次請求處理上有大約40%的改進。正如我前面提到的,這不是我們現在能夠做到的,因為原始碼裡面就有lock,但是這是一個關於使用 PipeReader 讀取資料效能損耗有趣的點。
另一個非常有趣的方面是後端儲存,它是一個ConcurrentDictionary。如果我們看看它的成本,我們會發現:

您會注意到,我正在使用NonBlocking的NuGet包,它提供了一個無鎖的 ConcurrentDictionary實現。如果我們使用.NET框架中的預設實現,它確實使用了鎖,我們將看到:

下面有它們的對比:
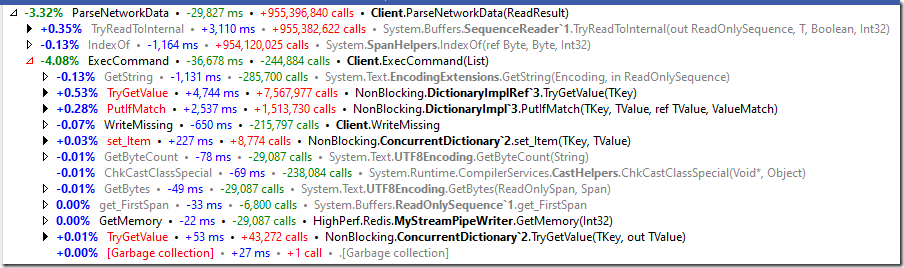
請注意,這兩個選項之間存在非常大的成本差別(有利於非阻塞)。但是,當我們執行一個真實的基準測試時,它並沒有特別大的差別。
那接下來呢?
看看分析器的結果,我們沒有什麼可以繼續改進的。我們的大部分成本都在網路中,而不是在我們執行的程式碼中。
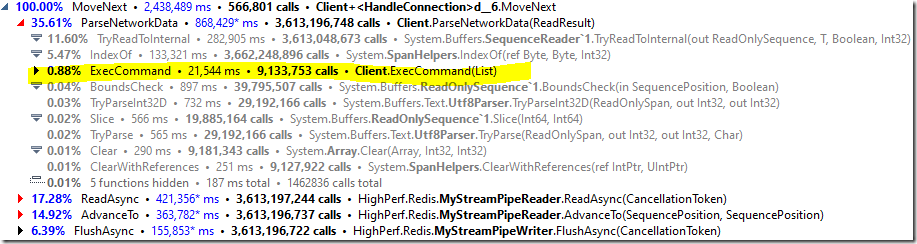
我們的大部分程式碼都在 ParseNetworkData 呼叫中,看起來像這樣:

所以我們實際上花在執行伺服器核心功能上的時間是可以忽略不計的。實際上,解析來自緩衝區的命令花費了大量時間。注意,在這裡,我們實際上並不執行任何 I/O 操作,所有操作都在記憶體中的緩衝區上進行操作。
Redis協定對於機器解析來說並不友好,需要我們進行大量的查詢才能找到分隔符(因此有很多的IndexOf()呼叫)。我不認為你能在這方面有顯著的改進。這意味著我們必須考慮其他更好的效能選擇。
我們花費了35% 的執行時來解析來自使用者端的命令流,而我們執行的程式碼不到執行時的1% 。我不認為流解析還有重要的優化機會,因此我們只剩I/O的優化方向。我們能做得更好嗎?
我們目前使用的是非同步I/O和Pipelines。看看這個讓我感興趣的專案,它在Linux使用了IO_Uring(通過這個API)來滿足他們的需要。它們的解析也很簡單,請看這裡,與我的程式碼執行的方式非常相似。
因此,為了進入效能的下一個階段(提醒一下,我們現在的效能是180w/s) ,我們可能還需要使用基於IO_Uring的方法。有一個NuGet軟體包來支援它,但是這使得我可以在一個晚上花幾個小時來完成這個任務,而不是花幾天或者一週的時間來完成。我不認為在不久的將來我會繼續追求這個目標。
結尾
完結撒花!!!按照Ayende大佬的意思是後面會嘗試在linux上使用IO_Uring來實現,目前來看大佬還沒有其它的更新,已經發布的博文已經全部翻譯。
我也在大佬博文底部提出了其它的一些效能優化的小建議,建議來自我之前釋出的文章,同樣高效能的網路服務開發。有興趣的可以檢視下方連結。
https://www.cnblogs.com/InCerry/p/highperformance-alternats.html
系列連結
使用.NET簡單實現一個Redis的高效能克隆版(一)
使用.NET簡單實現一個Redis的高效能克隆版(二)
使用.NET簡單實現一個Redis的高效能克隆版(三)
使用.NET簡單實現一個Redis的高效能克隆版(四、五)
使用.NET簡單實現一個Redis的高效能克隆版(六)
後續大佬有其它更新的話,也歡迎艾特我催更