一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同位元組序下的設計與實現
讓我們來到微觀世界重新認識 Netty
在前面 Netty 原始碼解析系列 《聊聊 Netty 那些事兒》中,筆者帶領大家從宏觀世界詳細剖析了 Netty 的整個運轉流程。從一個網路封包在核心中的收發過程開始聊起,總體介紹了 Netty 的 IO 執行緒模型,後面我們圍繞著這個 IO 模型又詳細介紹了整個 Reactor 模型在 Netty 中的實現。
這個宏觀流程包括:Reactor模型的建立,啟動,運轉架構,網路連線的接收和關閉,網路資料的接收和傳送,利用 pipeline 對 IO 處理邏輯的編排,Netty 的優雅關閉。
Netty 的原始碼解析系列寫到這裡,筆者算是帶著大家在 Netty 的宏觀世界中翱翔了一圈,但筆者還是不捨得和大家說再見,於是決定在帶領大家到 Netty 的微觀世界中一探究竟,這個系列的目的就是想讓大家從核心層面深入地搞透 Netty。
在 Netty 的微觀世界系列中,筆者會為大家講述 Netty 中的高效能元件的相關設計和實現以及應用。內容包括:
-
Netty 中的網路資料容器 ByteBuf 的整個設計體系的實現。
-
Netty 中的記憶體池設計與實現,在這個過程中,筆者會把 Linux 核心中記憶體管理子系統相關原始碼帶大家走讀一遍,讓大家從核心層面到應用層面徹底搞透徹高效能記憶體分配的原理及其實現。
-
Netty 中用於執行海量延時任務的時間輪相關設計與實現,並與 Kafka 中的時間輪設計做出詳細對比。
-
Netty 中用到的零拷貝技術在核心中的實現。
-
Netty 中用到的 MPSC (多生產者單消費者)佇列的設計與實現以及應用場景。
-
Netty 中實現無鎖化並行的關鍵元件 FastThreadLocal 的設計與實現,並詳細對比 FastThreadLocal 究竟比 JDK 中 ThreadLocal 快在了哪裡。
-
理論講完了,實踐是必不可少的,最後筆者會帶大家剖析 Netty 在各個著名中介軟體中是如何使用的,進一步加深大家對 Netty 的理解。
筆者的這個 Netty 微觀世界系列會涉及大量豐富的細節描述,對於喜歡細節控的同學一定不要錯過~~
寫在本文開始之前.....
本文我們開始 Netty 微觀世界系列第一部分的內容,聊聊 Netty 中的網路資料容器 ByteBuf ,對於 ByteBuf 我想大家一定不會陌生,它曾多次出現在前面的系列文章中,比如在《Netty如何高效接收網路資料 | 一文聊透ByteBuffer動態自適應擴縮容機制》和《一文搞懂Netty傳送資料全流程 | 你想知道的細節全在這裡》這兩篇文章中提到的 Netty 接收網路資料和傳送網路資料時用到的ByteBuf。
ByteBuf 是 Netty 中的資料容器,Netty 在接收網路資料和傳送網路資料時,都會首先將這些網路資料事先快取在 ByteBuf 中,然後在將它們丟給 pipeline 處理或者傳送給 Socket ,這樣做的目的是防止在接收網路資料的過程中網路資料一直積壓在 Socket 的接收緩衝區中使得接收緩衝區的資料越來越多,導致對端 TCP 協定中的視窗關閉(滑動視窗),影響到了整個 TCP 通訊的速度。而有了 ByteBuf,我們可以先將讀取的資料快取在 ByteBuf 中,提高 TCP 的通訊能力。
而在 Netty 傳送資料的時候,也可以事先將資料快取在 ByteBuf 中,如果 Socket 傳送緩衝區已滿變為不可寫狀態時,由於資料我們已經快取在 ByteBuf 中了,使用者的傳送執行緒不需要阻塞等待,當 Socket 傳送緩衝區再次變得可寫時,Netty 會將 ByteBuf 中的資料寫入到 Socket 中。這也是 Netty 實現非同步傳送資料的核心所在。
而 Netty 中的 ByteBuf 底層依賴了JDK NIO 中的 ByteBuffer 。眾所周知 JDK NIO 中的 ByteBuffer 設計的非常複雜而且提供的相關 API 使用起來也很反人類,易用性不是很好,所以 Netty 的 ByteBuf 針對 JDK NIO ByteBuffer 進行了優化,再此基礎上重新設計出了一套簡潔易用的 API 出來。
熟悉筆者寫作風格的讀者朋友都知道,筆者一向是喜歡把技術的脈絡給大家鋪展開來講解,一層一層地介紹技術的演變過程,力求給大家清晰地展現出整個技術的全貌。通過技術的演變過程,我們不僅可以知道這個技術點最初的樣貌,它的優缺點是什麼?瓶頸是什麼?我們還可以針對這些缺點和瓶頸觸發自己的思考,如何優化?如何演變?通過這個過程的洗禮,我們才能夠對現有技術理解的清晰透徹。
根據這個思路,在介紹 Netty 的 ByteBuf 設計之前,筆者想專門用一篇文章來為大家介紹下 JDK NIO Buffer 的設計,看一下 NIO ByteBuffer 是如何設計的,它有哪些缺點。針對這些缺點,Netty 又是如何優化的。徹底理解 Netty 資料載體 ByteBuf 的前世今生。

1. JDK NIO 中的 Buffer
在 NIO 沒有出現之前,Java 傳統的 IO 操作都是通過流的形式實現的(包括網路 IO 和檔案 IO ),也就是我們常見的輸入流 InputStream 和輸出流 OutputStream。
但是 Java 傳統 IO 的 InputStream 和 OutputStream 的相關操作全部都是阻塞的,比如我們使用 InputStream 的 read 方法從流中讀取資料時,如果此時流中沒有資料,那麼使用者執行緒就必須阻塞等待。
還有一點就是傳統的這些輸入輸出流在處理位元組流的時候一次只能處理一個位元組,這樣在處理網路 IO 的時候讀取 Socket 緩衝區中的資料效率就會很低,而且在操作位元組流的時候只能線性的處理流中的位元組,不能來回移動位元組流中的資料。這樣導致我們在處理位元組流中的資料的時候就顯得不是很靈活。
所以綜上所述,Java 傳統 IO 是面向流的,流的處理是單向,阻塞的,而且無論是從輸入流中讀取資料還是向輸出流中寫入資料都是一個位元組一個位元組來處理的。通常都是從輸入流中邊讀取資料邊處理資料,這樣 IO 處理效率就會很低,
基於上述原因,JDK1.4 引入了 NIO,而 NIO 是面向 Buffer 的,在處理 IO 操作的時候,會一次性將 Channel 中的資料讀取到 Buffer 中然後在做後續處理,向 Channel 中寫入資料也是一樣,也是需要一個 Buffer 做中轉,然後將 Buffer 中的資料批次寫入 Channel 中。這樣一來我們可以利用 Buffer 將裡面的位元組資料來回移動並根據我們想要的處理方式靈活處理。
除此之外,Nio Buffer 還提供了堆外的直接記憶體和記憶體對映相關的存取方式,來避免記憶體之間的來回拷貝,所以即使在傳統 IO 中用到了 BufferedInputStream 也還是沒辦法和 Nio Buffer 相匹敵。
那麼接下來就讓我們正式進入JDK NIO Buffer 如何設計與實現的相關主題
2. NIO 對 Buffer 的頂層抽象
JDK NIO 提供的 Buffer 其實本質上是一塊記憶體,大家可以把它簡單想象成一個陣列,JDK 將這塊記憶體在語言層面封裝成了 Buffer 的形式,我們可以通過 Buffer 對這塊記憶體進行讀取或者寫入資料,以及執行各種騷操作。
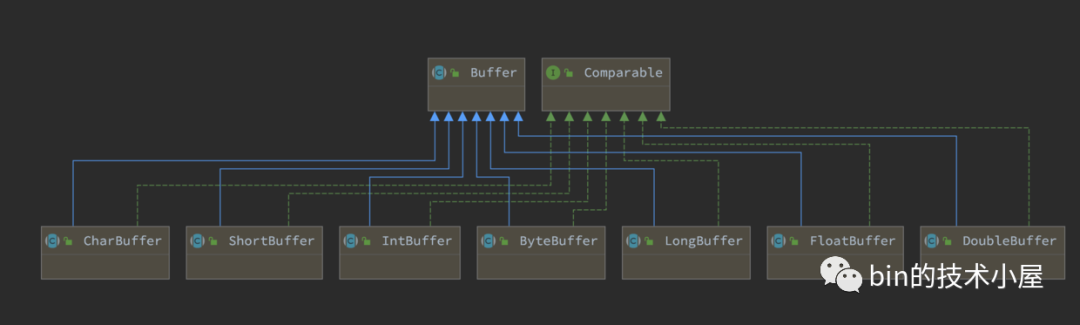
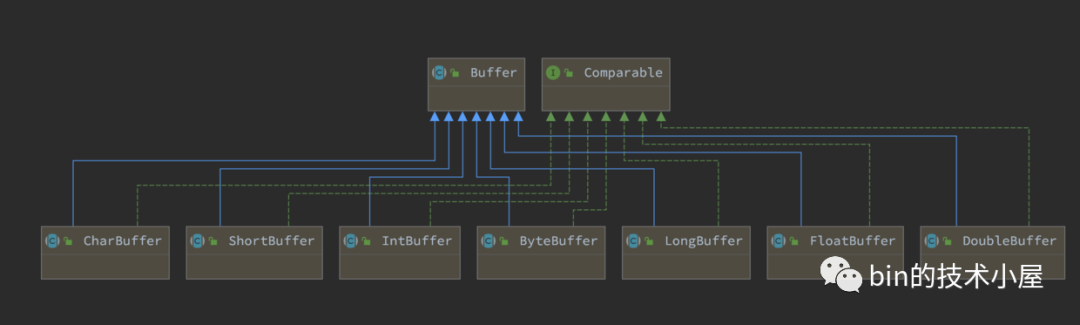
如下圖中所示,Buffer 類是JDK NIO 定義的一個頂層抽象類,對於緩衝區的所有基本操作和基礎屬性全部定義在頂層 Buffer 類中,在 Java 中一共有八種基本型別,JDK NIO 也為這八種基本型別分別提供了其對應的 Buffer 類,大家可以把這些 Buffer 類當做成對應基礎型別的陣列,我們可以利用這些基礎型別相關的 Buffer 類對陣列進行各種操作。
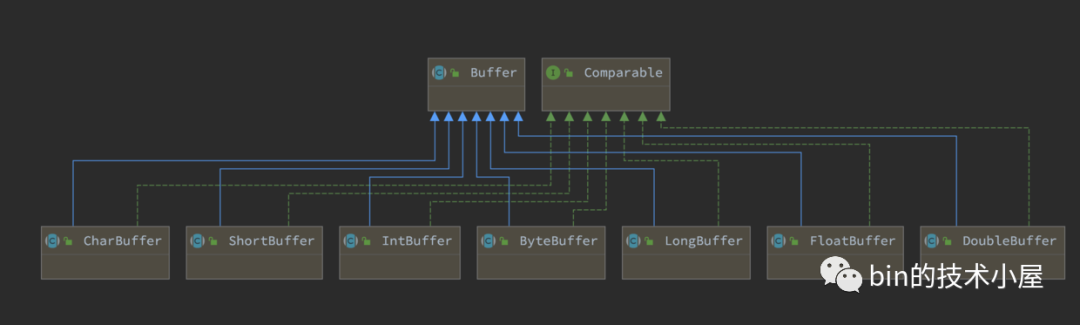
在為大家解析具體的緩衝區實現之前,我們先來看下這個緩衝區的頂層抽象類 Buffer 中到底定義規範了哪些抽象操作,具有哪些屬性,這些屬性分別是用來幹什麼的?先帶大家從總體上認識一下JDK NIO 中的 Buffer 設計。
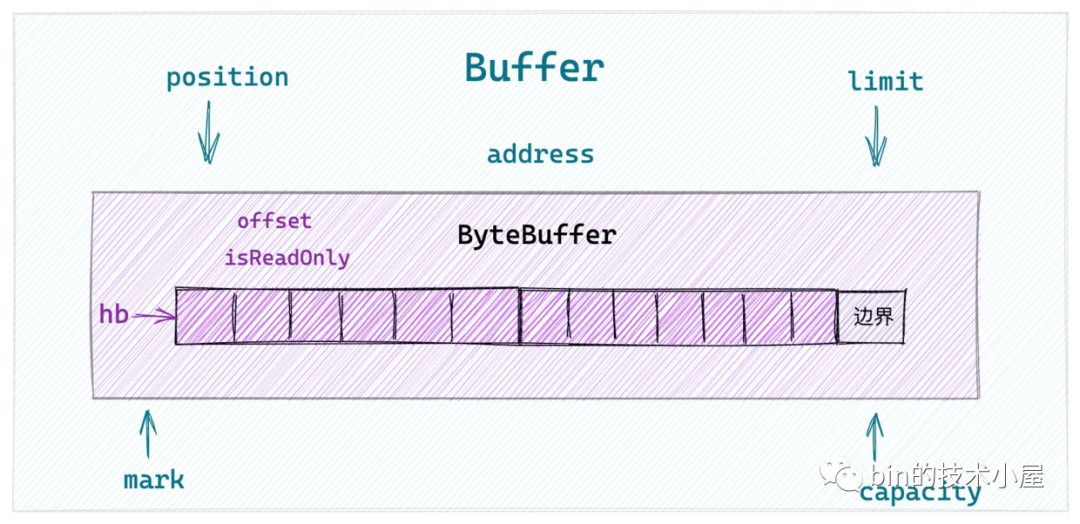
2.1 Buffer 中的屬性
public abstract class Buffer {
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
.............
}
首先我們先來介紹下 Buffer 中最重要的這三個屬性,後面即將介紹的關於 Buffer 的各種騷操作均依賴於這三個屬性的動態變化。
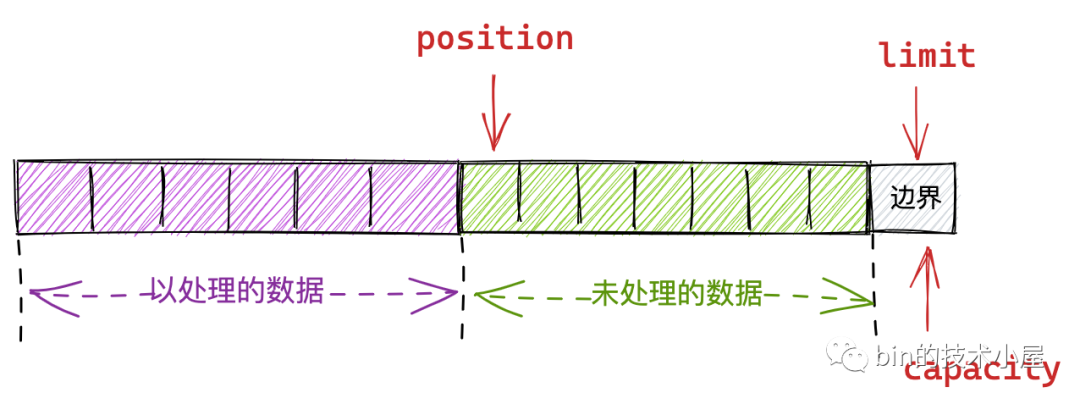
-
capacity:這個很好理解,它規定了整個 Buffer 的容量,具體可以容納多少個元素。capacity 指標之前的元素均是 Buffer 可操作的空間。
-
position:用於指向 Buffer 中下一個可操作性的元素,初始值為 0。在 Buffer 的寫模式下,position 指標用於指向下一個可寫位置。在讀模式下,position 指標指向下一個可讀位置。
-
limit:表示 Buffer 可操作元素的上限。什麼意思呢?比如在 Buffer 的寫模式下,可寫元素的上限就是 Buffer 的整體容量也就是 capacity ,capacity - 1 即為 Buffer 最後一個可寫位置。在讀模式下,Buffer 中可讀元素的上限即為上一次 Buffer 在寫模式下最後一個寫入元素的位置。也就是上一次寫模式中的 position。
-
mark:用於標記 Buffer 當前 position 的位置。這個欄位在我們對網路封包解碼的時候非常有用,在我們使用 TCP 協定進行網路資料傳輸的時候經常會出現粘包拆包的現象,所以為了應對粘包拆包的問題,在解碼之前都需要先呼叫
mark 方法將 Buffer 的當前 position 指標儲存至 mark 屬性中,如果 Buffer 中的資料足夠我們解碼為一個完整的包,我們就執行解碼操作。如果 Buffer 中的資料不夠我們解碼為一個完整的包(也就是半包),我們就呼叫 reset 方法,將 position 還原到原來的位置,等待剩下的網路資料到來。
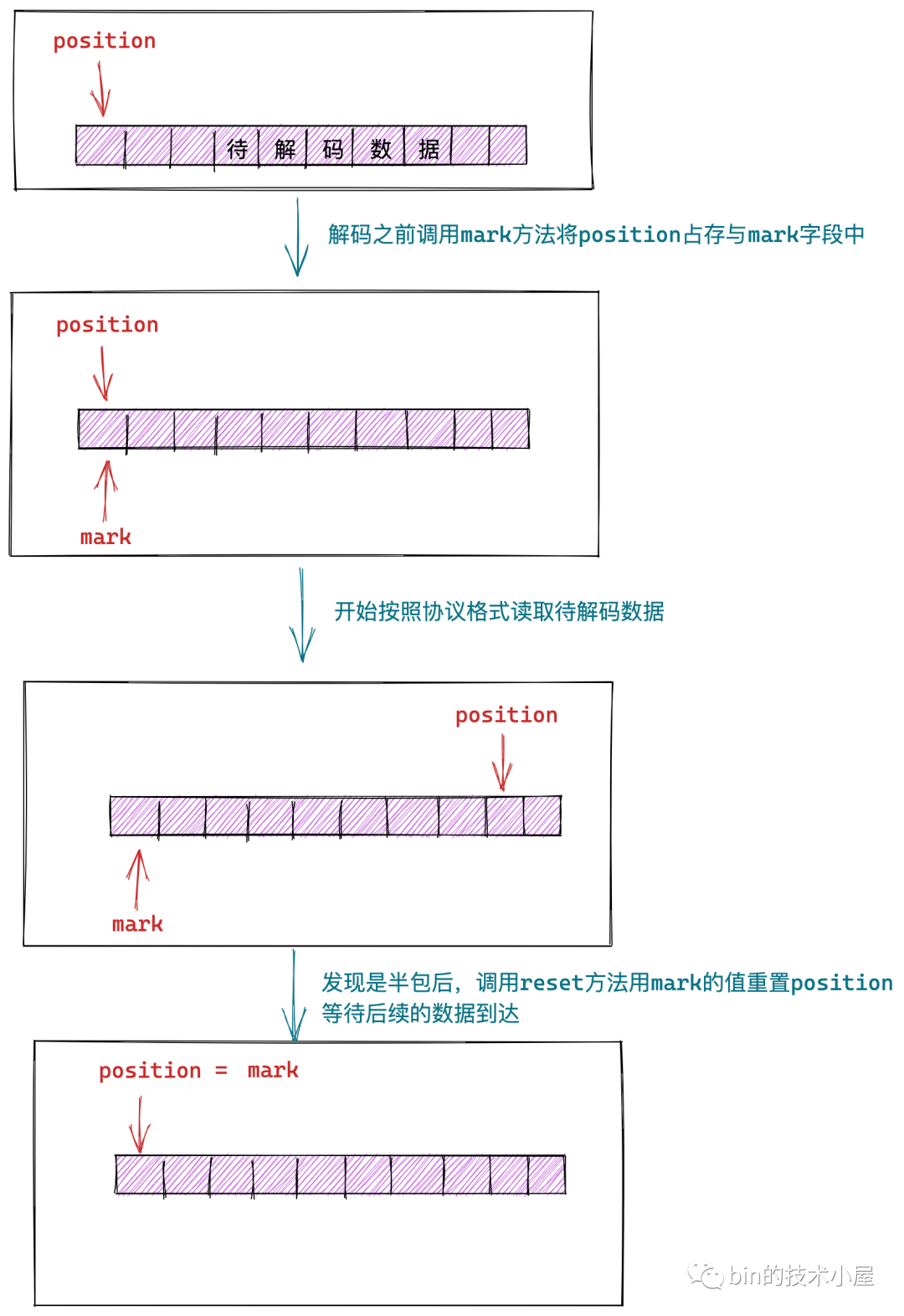
在我們理解了 Buffer 中這幾個重要屬性的含義之後,接下來我們就來看一看 JDK NIO 在 Buffer 頂層設計類中定義規範的那些抽象操作。
2.2 Buffer 中定義的核心抽象操作
本小節中介紹的這幾個關於 Buffer 的核心操作均是基於上小節中介紹的那些核心指標的動態調整實現的。
2.2.1 Buffer 的構造
構造 Buffer 的主要邏輯就是根據使用者指定的引數來初始化 Buffer 中的這四個重要屬性:mark,position,limit,capacity。它們之間的關係為:mark <= position <= limit <= capacity 。其中 mark 初始預設為 -1,position 初始預設為 0。

public abstract class Buffer {
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
Buffer(int mark, int pos, int lim, int cap) {
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
}
2.2.2 獲取 Buffer 下一個可讀取位置
當我們在 Buffer 的讀模式下,需要從 Buffer 中讀取資料時,需要首先知道當前 Buffer 中 position 的位置,然後根據 position 的位置讀取 Buffer 中的元素。隨後 position 向後移動指定的步長 nb。
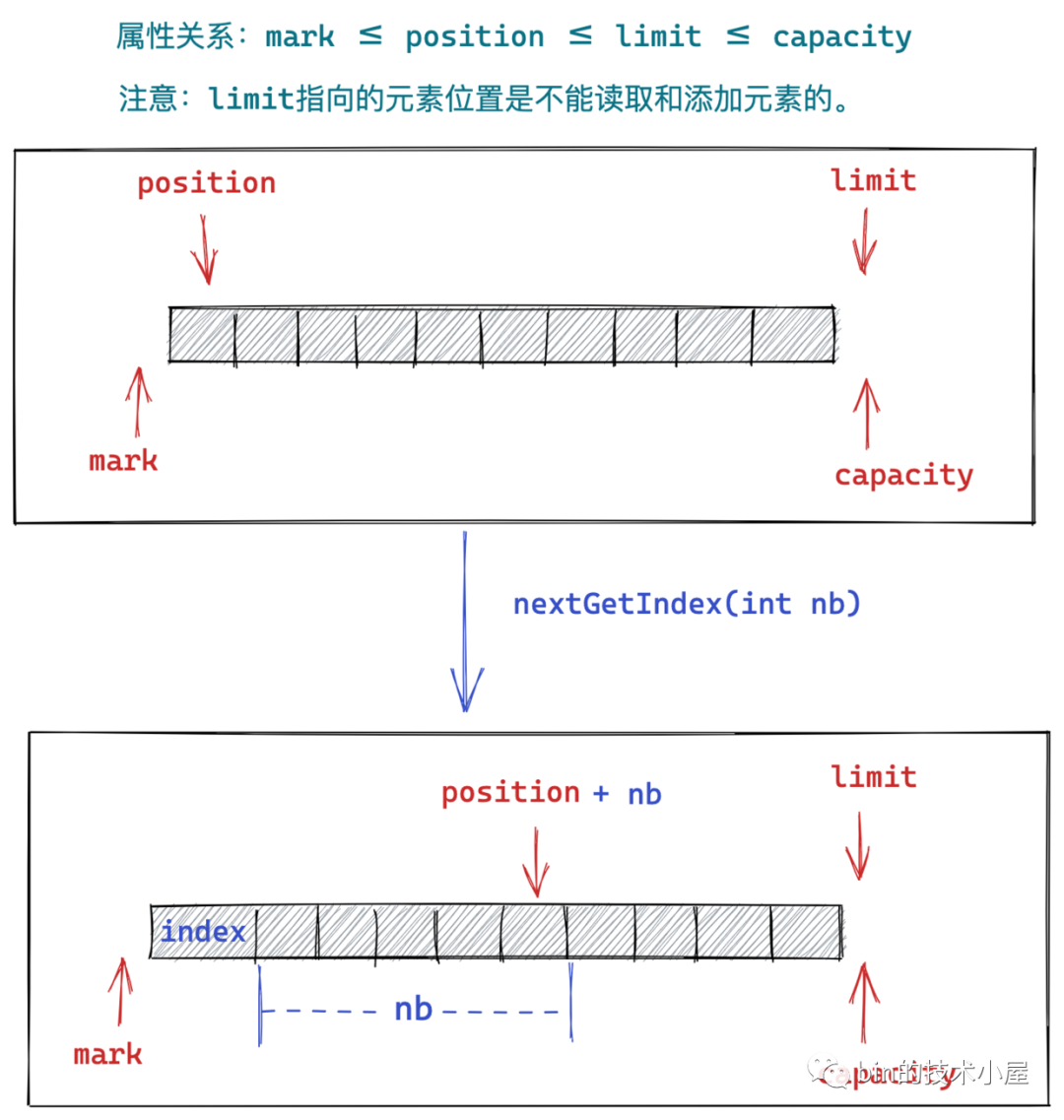
nextGetIndex() 方法首先獲取 Buffer 當前 position 的位置作為 readIndex 返回給使用者,然後 position 向後移動一位。這裡的步長 nb 預設為1。
final int nextGetIndex() {
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
nextGetIndex(int nb) 方法的邏輯和 nextGetIndex() 方法一樣,唯一不同的是該方法指定了position 向後移動的步長 nb。
final int nextGetIndex(int nb) {
if (limit - position < nb)
throw new BufferUnderflowException();
int p = position;
position += nb;
return p;
}
大家這裡可能會感到好奇,為什麼會增加一個指定 position 移動步長的 nextGetIndex(int nb) 方法呢?
在《2. NIO 對 Buffer 的頂層抽象》小節的開始,我們介紹了 JDK NIO 中 Buffer 頂層設計體系,除了 boolean 這個基本型別,NIO 為幾乎所有的 Java 基本型別定義了對應的 Buffer 類。
假如我們從一個 ByteBuffer 中讀取一個 int 型別的資料時,我們就需要在讀取完畢後將 position 的位置向後移動 4 位。在這種情況下 nextGetIndex(int nb) 方法的步長 nb 就應該指定為 4.
public int getInt() {
return getInt(ix(nextGetIndex((1 << 2))));
}
2.2.3 獲取 Buffer 下一個可寫入位置
同獲取 readIndex 的過程一樣,當我們處於 Buffer 的寫模式下,向 Buffer 寫入資料時,首先也需要獲取 Buffer 當前 position 的位置(writeIndex),當寫入元素後,position 向後移動指定的步長 nb。
同樣的道理,我們可以向 ByteBuffer 中寫入一個 int 型的資料,這時候指定的步長 nb 也是 4 。
final int nextPutIndex() {
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
final int nextPutIndex(int nb) {
if (limit - position < nb)
throw new BufferOverflowException();
int p = position;
position += nb;
return p;
}
2.2.4 Buffer 讀模式的切換
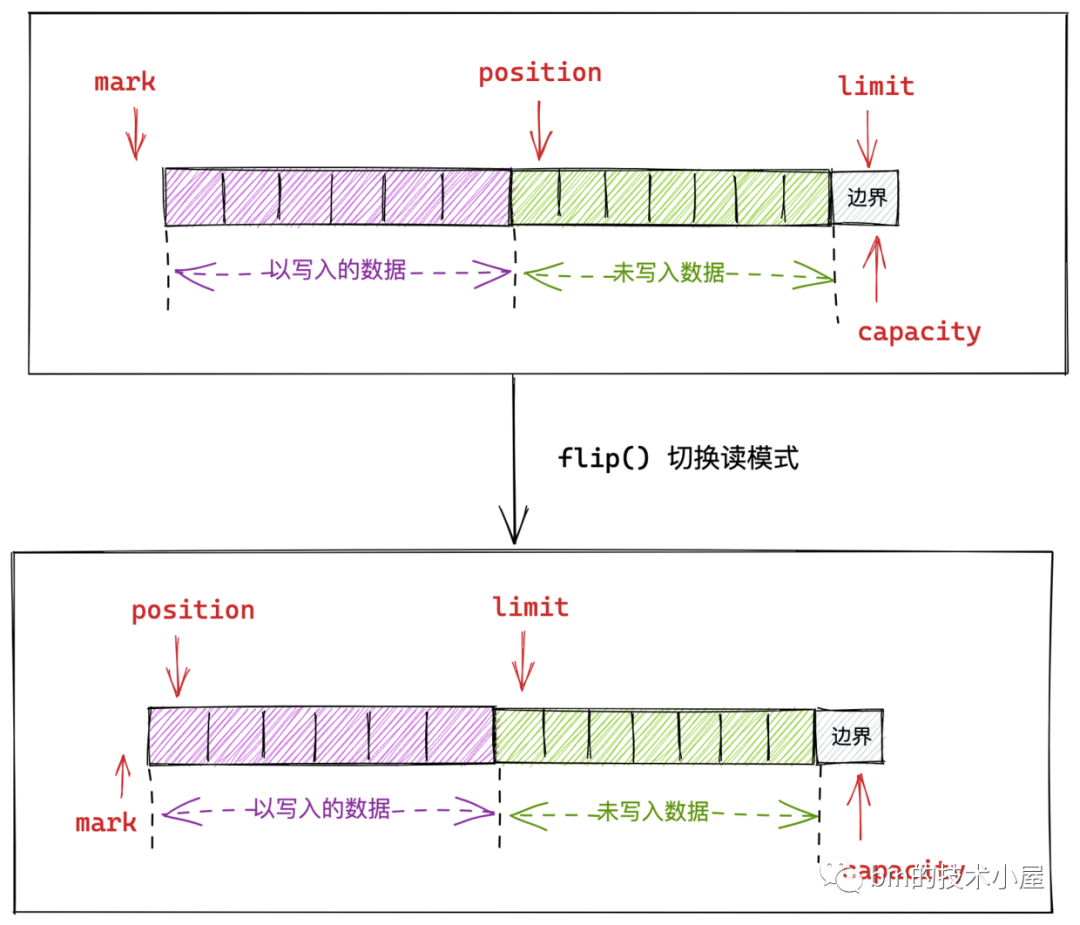
當我們在 Buffer 的寫模式下向 Buffer 寫入資料之後,接下來我們就需要從 Buffer 中讀取剛剛寫入的資料。由於 NIO 在對 Buffer 的設計中讀寫模式是混用一個 position 屬性,所以我們需要做讀模式的切換。
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
我們看到 flip() 方法是對 Buffer 中的這四個指標做了一些調整達到了讀模式切換的目的:
- 將下一個可寫入位置 position 作為讀模式下的上限 limit。
- position設定為 0 。這樣使得我們可以從頭開始讀取 Buffer 中寫入的資料。
2.2.5 Buffer 寫模式的切換
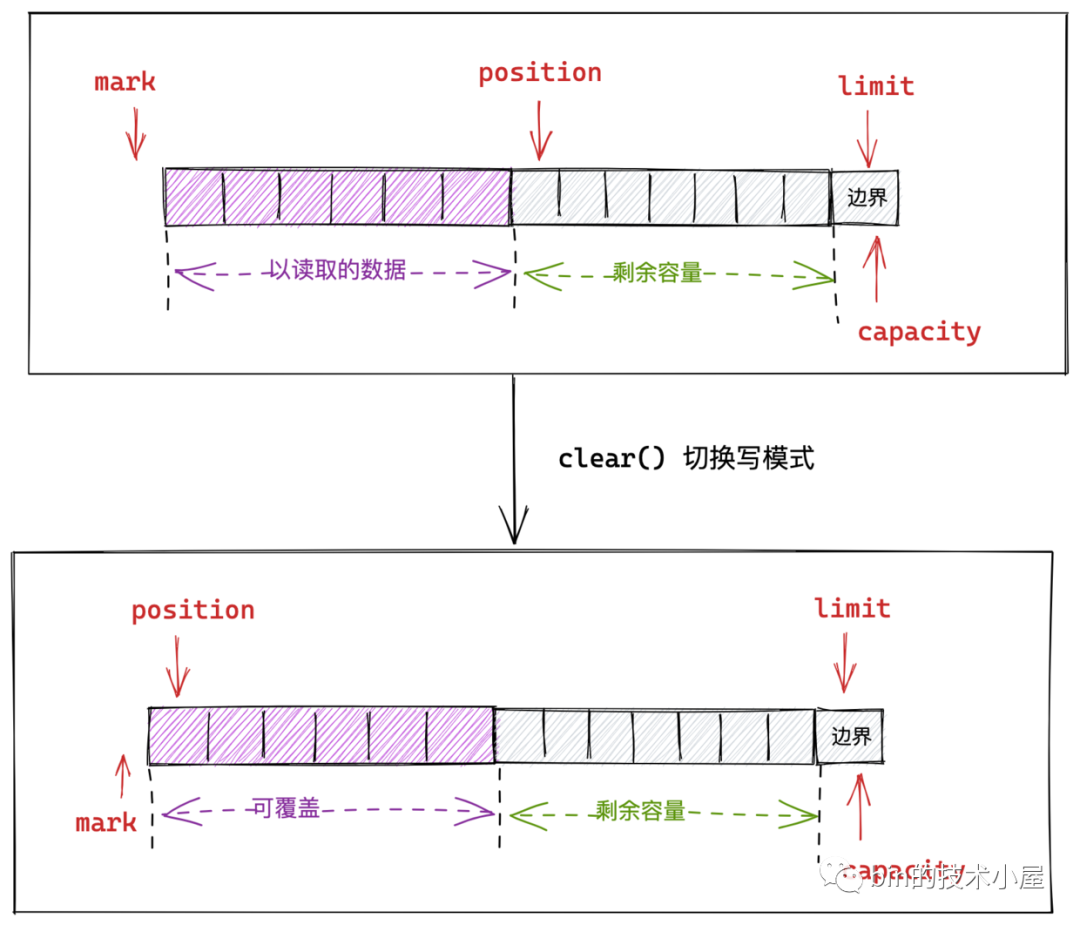
有讀模式的切換肯定就會有對應的寫模式切換,當我們在讀模式下以將 Buffer 中的資料讀取完畢之後,這時候如果再次向 Buffer 寫入資料的話,就需要切換到 Buffer 的寫模式下。
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
我們看到呼叫 clear() 方法之後,Buffer 中各個指標的狀態又回到了最初的狀態:
-
position 位置重新指向起始位置 0 處。寫入上限 limit 重新指向了 capacity 的位置。
-
這時向 Buffer 中寫入資料時,就會從 Buffer 的開頭處依次寫入,新寫入的資料就會把已經讀取的那部分資料覆蓋掉。
但是這裡就會有一問題,當我們在讀模式下將 Buffer 中的資料全部讀取完畢時,呼叫 clear() 方法開啟寫模式,是沒有問題的。
如果我們只是讀取了 Buffer 中的部分資料,但是還有一部分資料沒有讀取,這時候,呼叫 clear() 方法開啟寫模式向 Buffer 中寫入資料的話,就會出問題,因為這會覆蓋掉我們還沒有讀取的資料部分。
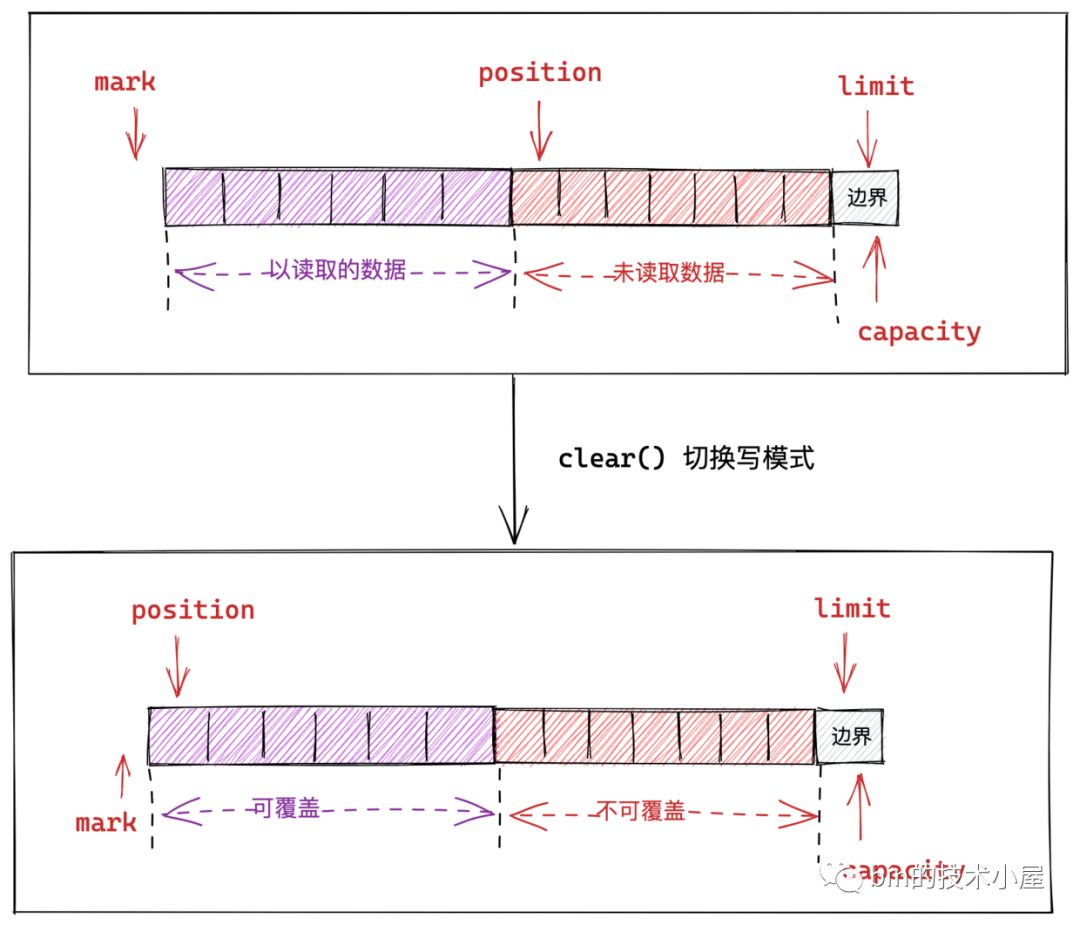
針對這種情況,我們就不能簡單粗暴的設定 position 指標了,為了保證未讀取的資料部分不被覆蓋,我們就需要先將不可覆蓋的資料部分移動到 Buffer 的最前邊,然後將 position 指標指向可覆蓋資料區域的第一個位置。
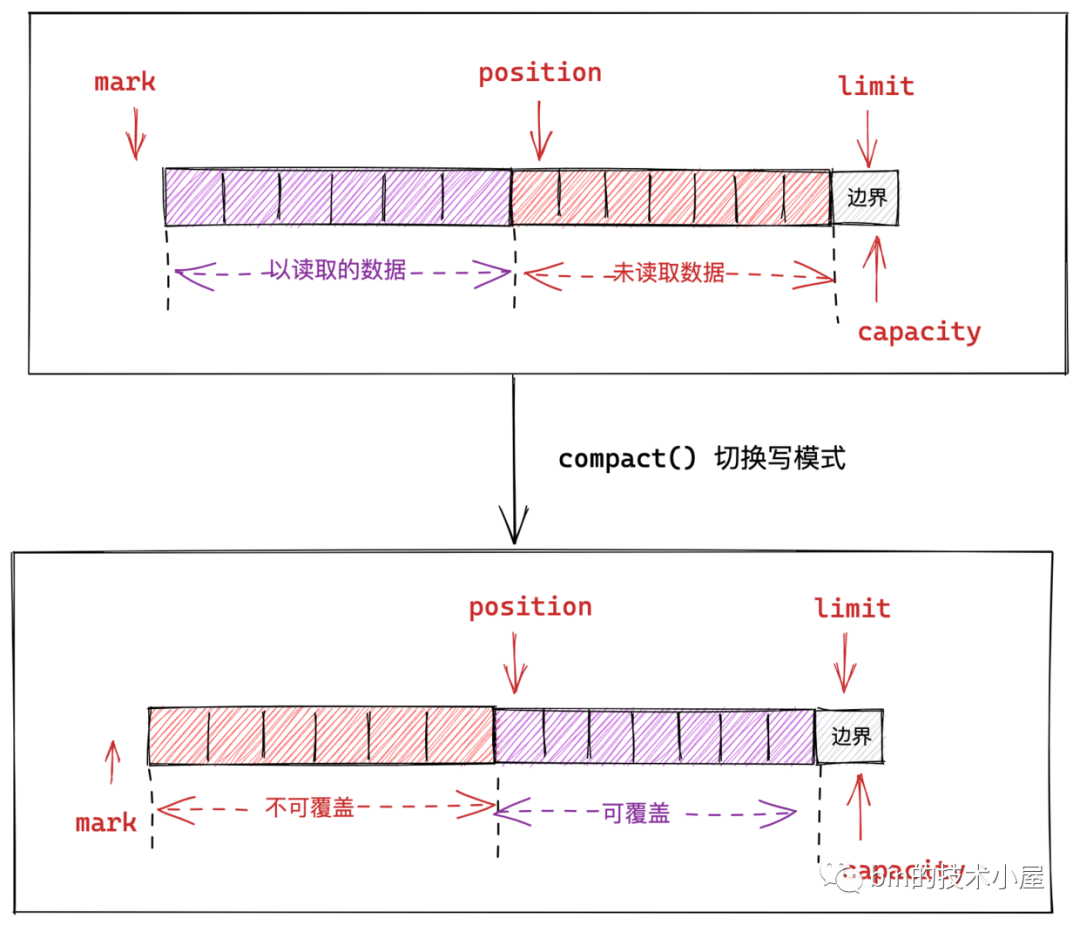
由於 Buffer 是頂層設計只是負責定義 Buffer 相關的操作規範,並未定義具體的資料儲存方式,因為 compact() 涉及到行動資料,所以實現在了 Buffer 具體子類中,這裡我們以 HeapByteBuffer 舉例說明:
class HeapByteBuffer extends ByteBuffer {
//HeapBuffer中底層負責儲存資料的陣列
final byte[] hb;
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
position(remaining());
limit(capacity());
discardMark();
return this;
}
public final int remaining() {
return limit - position;
}
final void discardMark() {
mark = -1;
}
}
2.2.6 重新讀取 Buffer 中的資料 rewind
rewind() 方法可以幫助我們重新讀取 Buffer 中的資料,它會將 position 的值重新設定為 0,並丟棄 mark。
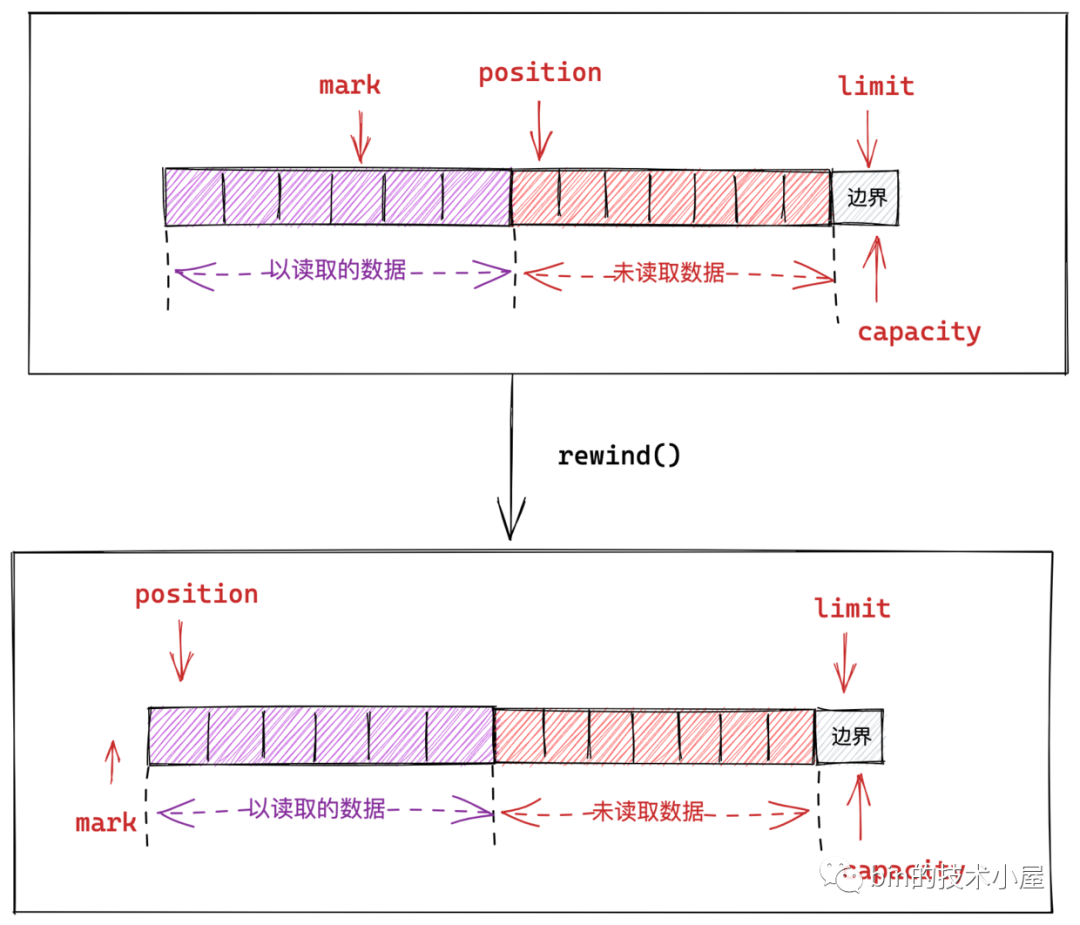
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
3. NIO Buffer 背後的儲存機制
在《2. NIO 對 Buffer 的頂層抽象》小節的開頭提到我們可以把 Buffer 簡單的看做是一個陣列,然後基於前邊介紹的四個指標:mark,position,limit,capacity 的動態調整來實現對 Buffer 的各種操作。
同時我們也提到了除了 boolean 這種基本型別之外,NIO 為其他幾種 Java 基本型別都提供了其對應的 Buffer 類。
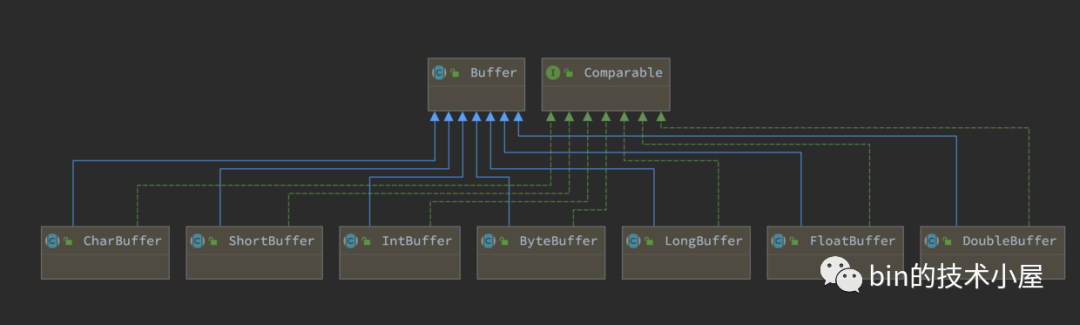
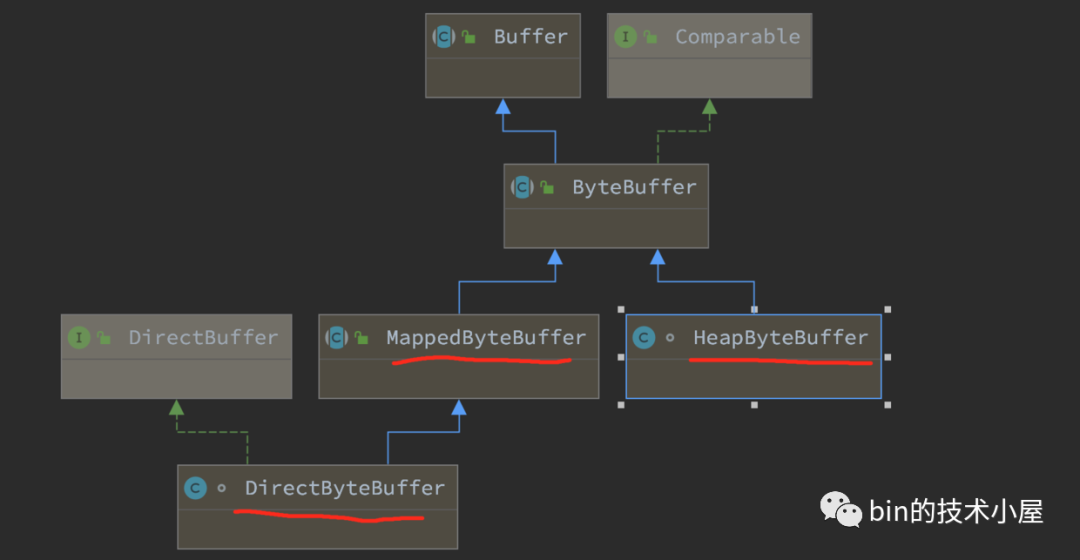
而針對每一種基本型別的 Buffer ,NIO 又根據 Buffer 背後的資料儲存記憶體不同分為了:HeapBuffer,DirectBuffer,MappedBuffer。
HeapBuffer 顧名思義它背後的儲存記憶體是在 JVM 堆中分配,在堆中分配一個陣列用來存放 Buffer 中的資料。
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
//在堆中使用一個陣列存放Buffer資料
final byte[] hb;
}
DirectBuffer 背後的儲存記憶體是在堆外記憶體中分配,MappedBuffer 是通過記憶體檔案對映將檔案中的內容直接對映到堆外記憶體中,其本質也是一個 DirectBuffer 。
由於 DirectBuffer 和 MappedBuffer 背後的儲存記憶體是在堆外記憶體中分配,不受 JVM 管理,所以不能用一個 Java 基本型別的陣列表示,而是直接記錄這段堆外記憶體的起始地址。
public abstract class Buffer {
//堆外記憶體地址
long address;
}
筆者後面還會為大家詳細講解 DirectBuffer 和 MappedBuffer。這裡提前引出只是讓大家理解這三種不同型別的 Buffer 背後記憶體區域的不同。
綜上所述,HeapBuffer 背後是有一個對應的基本型別陣列作為儲存的。而 DirectBuffer 和 MappedBuffer 背後是一塊堆外記憶體做儲存。並沒有一個基本型別的陣列。
hasArray() 方法 就是用來判斷一個 Buffer 背後是否有一個 Java 基本型別的陣列做支撐。
public abstract boolean hasArray();
如果 hasArray() 方法返回 true,我們就可以呼叫 Object array() 方法獲取 Buffer 背後的支撐陣列。
public abstract Object array();
其中 Buffer 中還有一個不太好理解的屬性是 offset,而這個 offset 到底是用來幹什麼的呢?
4. Buffer 的檢視
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
//在堆中使用一個陣列存放Buffer資料
final byte[] hb;
// 陣列中的偏移,用於指定陣列中的哪一段資料是被 Buffer 包裝的
final int offset;
}
事實上我們可以根據一段連續的記憶體地址或者一個陣列建立出不同的 Buffer 檢視出來。
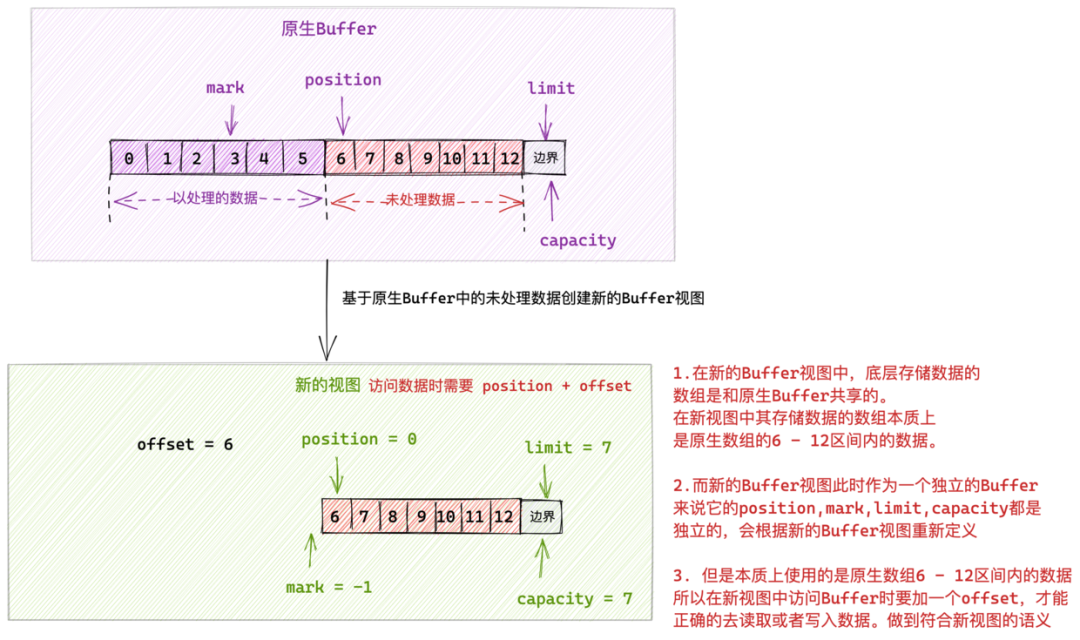
如上圖所示,我們可以根據原生 Buffer 中的部分資料(比如圖中的未處理資料部分)建立出一個新的 Buffer 檢視出來。
這個新的檢視 Buffer 本質上也是一個 Buffer ,擁有獨立的 mark,position,limit,capacity 指標。這個四個指標會在新的 Buffer 檢視下重新被建立賦值。所以在新的檢視 Buffer 下和操作普通 Buffer 是一樣的,也可以使用 《2.2 Buffer 中定義的核心抽象操作》小節中介紹的那些方法。只不過操作的資料範圍不一樣罷了。
新的檢視 Buffer 和原生 Buffer 共用一個儲存陣列或者一段連續記憶體。
站在新的檢視 Buffer 角度來說,它的儲存陣列範圍:0 - 6,所以再此檢視下 position = 0,limit = capacity = 7 。這其實是一個障眼法,真實情況是新的檢視 Buffer 其實是複用原生 Buffer 中的儲存陣列中的 6 - 12 這塊區域。
所以在新檢視 Buffer 中存取元素的時候,就需要加上一個偏移 offset : position + offset 才能正確的存取到真實陣列中的元素。這裡的 offset = 6。
我們可以通過 arrayOffset() 方法獲取檢視 Buffer 中的 offset。
public abstract int arrayOffset();
以上內容就是筆者要為大家介紹的 NIO Buffer 的頂層設計,下面我們來看下 Buffer 下具體的這些實現類。對於 Buffer 檢視相關的建立和操作,筆者會把這部分內容放到具體的 Buffer 實現類中為大家介紹,這裡大家只需要理解 Buffer 檢視的概念即可~~~
5. 抽象 Buffer 的具體實現類 ByteBuffer
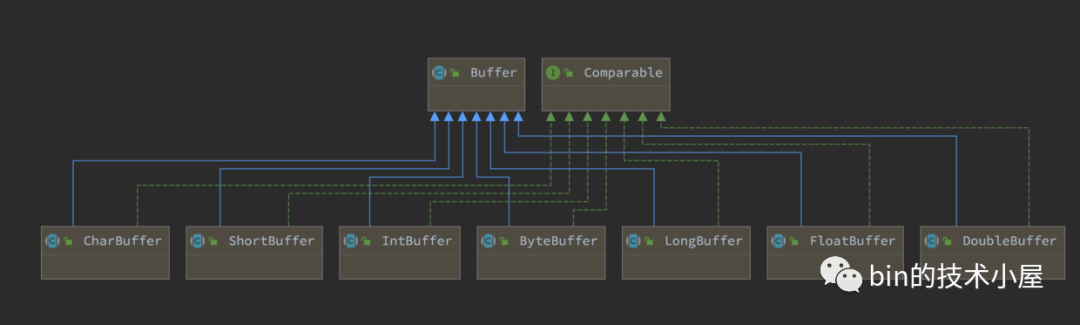
通過前面小節內容的介紹,我們知道了JDK NIO Buffer 為 Java 中每種基本型別都設計了對應的 Buffer 實現(除了 boolean 型別)。
而我們本系列的主題是 Netty 網路通訊框架的原始碼解析,在網路 IO 處理中出鏡率最高的當然是 ByteBuffer,所以在下面的例子中筆者均已 ByteBuffer 作為講解主線。相信大家在理解了 ByteBuffer 的整體脈絡設計之後,在看其他基本型別的 Buffer 實現就能非常容易理解,基本上大同小異。
下面我們就來正式開始 ByteBuffer 的介紹~~~
在前邊《3. NIO Buffer 背後的儲存機制》小節的介紹中,我們知道 NIO 中的 ByteBuffer 根據其背後記憶體分配的區域不同,分為了:HeapByteBuffer,MappedByteBuffer,DirectByteBuffer 這三種型別。
而這三種型別的 ByteBuffer 肯定會有一些通用的屬性以及方法,所以 ByteBuffer 這個類被設計成了一個抽象類,用來封裝這些通用的屬性和方法作為 ByteBuffer 這個基本型別 Buffer 的頂層規範。
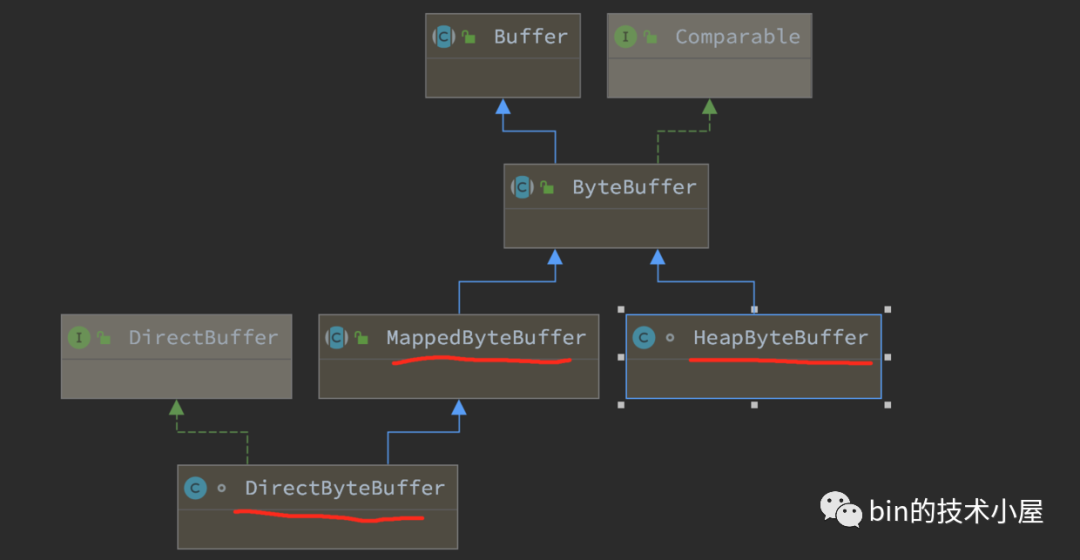
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
// Buffer背後的陣列
final byte[] hb;
// 陣列 offset,用於建立 Buffer 檢視
final int offset;
// 標識 Buffer 是否是唯讀的
boolean isReadOnly;
ByteBuffer(int mark, int pos, int lim, int cap,
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
ByteBuffer(int mark, int pos, int lim, int cap) {
this(mark, pos, lim, cap, null, 0);
}
}
ByteBuffer 中除了之前介紹的 Buffer 類中定義的四種重要屬性之外,又額外定義了三種屬性;
-
byte[] hb:ByteBuffer 中背後依賴的用於儲存資料的陣列,該欄位只適用於 HeapByteBuffer ,而 DirectByteBuffer 和 MappedByteBuffer 背後依賴於堆外記憶體。這塊堆外記憶體的起始地址儲存於 Buffer 類中的 address 欄位中。
-
int offset:ByteBuffer 中的記憶體偏移,用於建立新的 ByteBuffer 檢視。詳情可回看《4. Buffer 的檢視》小節。
-
boolean isReadOnly:用於標識該 ByteBuffer 是否是唯讀的。
5.1 建立具體儲存型別的 ByteBuffer
建立 DirectByteBuffer:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
建立 HeapByteBuffer:
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
由於 MappedByteBuffer 背後涉及到的原理比較複雜(雖然 API 簡單),所以筆者後面會有一篇專門講解 MappedByteBuffer 的文章,為了不使本文過於複雜,這裡就不列出了。
5.2 將位元組陣列對映成 ByteBuffer
經過前邊的介紹,我們知道 Buffer 其實本質上就是一個陣列,在 Buffer 中封裝了一些對這個陣列的便利操作方法。既然 Buffer 已經為陣列操作提供了便利,所以大家基本都不會願意去直接操作原生位元組陣列。這樣一來將一個原生位元組陣列對映成一個 ByteBuffer 的需求就誕生了。
public static ByteBuffer wrap(byte[] array, int offset, int length) {
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
ByteBuffer 中的 wrap 方法提供了這樣的對映實現,該方法可以將位元組陣列全部對映成一個 ByteBuffer,或者將位元組陣列中的部分位元組資料靈活對映成一個 ByteBuffer 。
-
byte[] array:需要對映成 ByteBuffer 的原生位元組陣列 array。
-
int offset:用於指定對映之後 Buffer 的 position。 position = offset。注意此處的 offset 並不是 Buffer 檢視中的 offset 。
-
int length:用於計算對映之後 Buffer 的 limit。 limit = offset + length,capacity = array,length。
對映後的 ByteBuffer 中 Mark = -1,offset = 0。此處的 offset 才是 Buffer 檢視中的 offset。
HeapByteBuffer(byte[] buf, int off, int len) { // package-private
super(-1, off, off + len, buf.length, buf, 0);
}
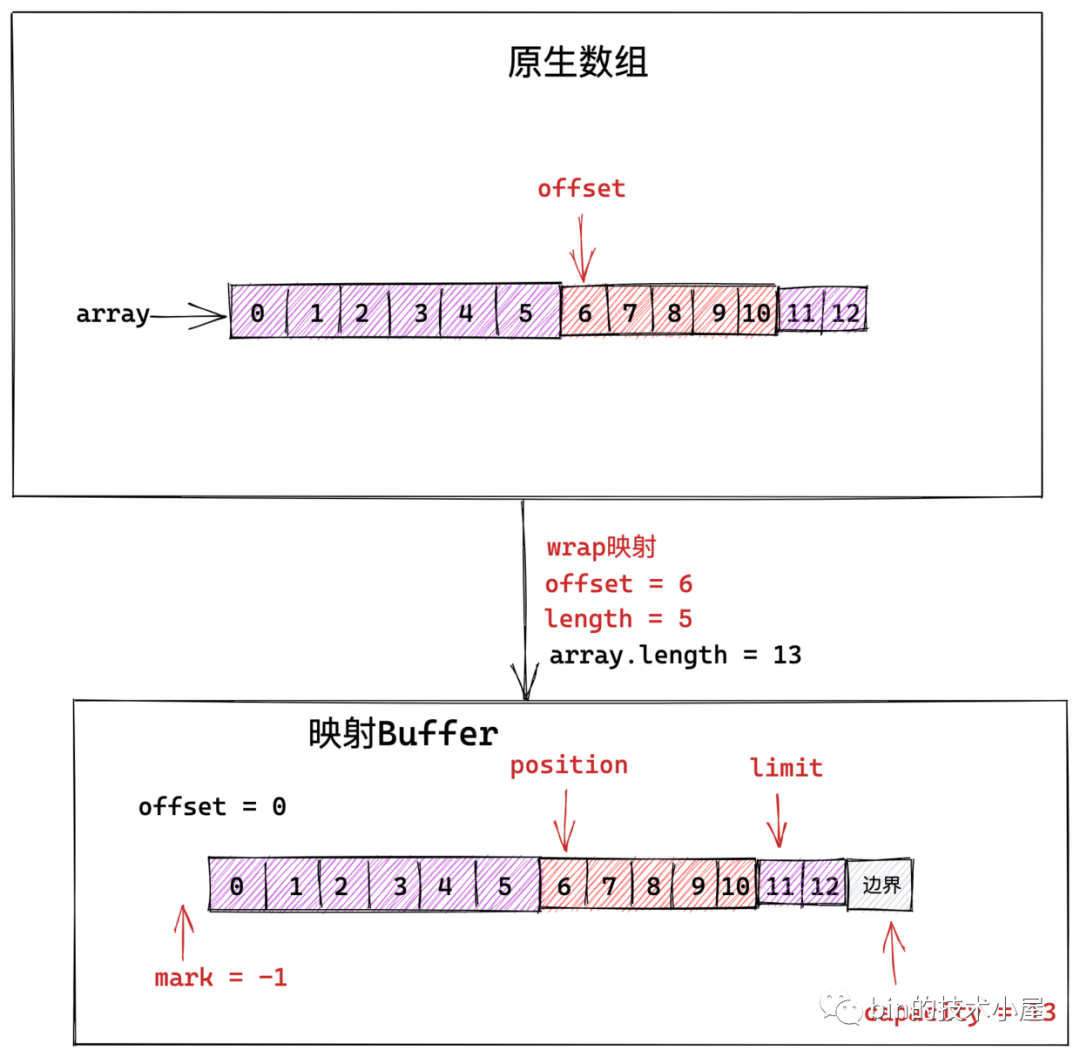
以上介紹的 wrap 對映方法是根據使用者自己指定的 position 和 limit 對原生位元組陣列進行靈活對映。當然 NIO 中還提供了一個方法是直接對原生位元組陣列 array 進行預設全部對映。對映之後的Buffer :position = 0,limit = capacity = array.length。
public static ByteBuffer wrap(byte[] array) {
return wrap(array, 0, array.length);
}
5.3 定義 ByteBuffer 檢視相關操作
在前邊《4. Buffer 的檢視》小節的介紹中,筆者介紹頂層抽象類 Buffer 中定義的 offset 屬性的時候,我們提到過這個 offset 屬性就是用來建立 Buffer 檢視的。在該小節中筆者其實已經將 Buffer 建立檢視的相關原理和過程已經給大家詳細的介紹完了。而檢視建立的相關操作就定義在 ByteBuffer 這個抽象類中,分別為 slice() 方法和 duplicate() 方法。
這裡還是需要再次和大家強調的是我們基於原生 ByteBuffer 建立出來新的 ByteBuffer 檢視其實是 NIO 設計的一個障眼法。原生的 ByteBuffer 和它的檢視 ByteBuffer 其實本質上共用的是同一塊記憶體。對於 HeapByteBuffer 來說這塊共用的記憶體就是 JVM 堆上的一個位元組陣列,而對於 DirectByteBuffer 和 MappedByteBuffer 來說這塊共用的記憶體是堆外記憶體中的同一塊記憶體區域。
ByteBuffer 的檢視本質上也是一個 ByteBuffer,原生的 ByteBuffer 和它的檢視 ByteBuffer 擁有各自獨立的 mark,position,limit,capacity 指標。只不過背後依靠的記憶體空間是一樣的。所以在檢視 ByteBuffer 做的任何內容上的改動,原生 ByteBuffer 是看得見的。同理在原生 ByteBuffer 上做的任何內容改動,檢視 ByteBuffer 也是看得見的。它們是相互影響的,這點大家需要注意。
5.3.1 slice()
public abstract ByteBuffer slice();
呼叫 slice() 方法建立出來的 ByteBuffer 檢視內容是從原生 ByteBufer 的當前位置 position 開始一直到 limit 之間的資料。也就是說通過 slice() 方法建立出來的檢視裡邊的資料是原生 ByteBuffer 中還未處理的資料部分。
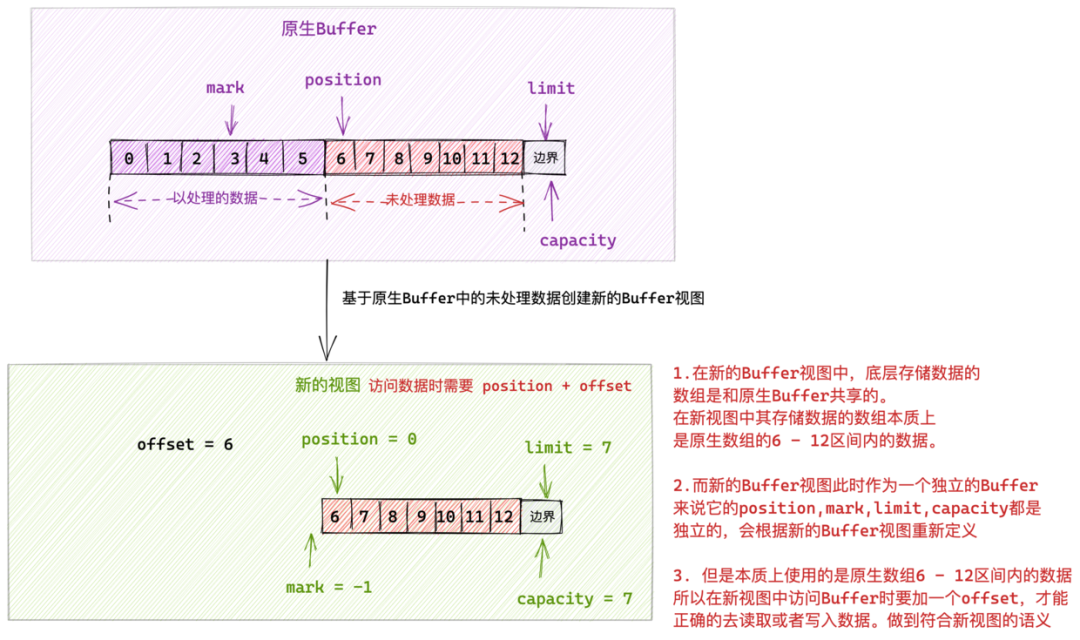
如上圖所屬,呼叫 slice() 方法建立出來的檢視 ByteBuffer 它的儲存陣列範圍:0 - 6,所以再此檢視下 position = 0,limit = capacity = 7。這其實是一個障眼法,真實情況是新的檢視 ByteBuffer 其實是複用原生 ByteBuffer 中的儲存陣列中的 6 - 12 這塊區域(未處理的資料部分)。
所以在檢視 ByteBuffer 中存取元素的時候,就需要 position + offset 來存取才能正確的存取到真實陣列中的元素。這裡的 offset = 6。
下面是 HeapByteBuffer 中關於 slice() 方法的具體實現:
class HeapByteBuffer extends ByteBuffer {
public ByteBuffer slice() {
return new HeapByteBuffer(hb,
-1,
0,
this.remaining(),
this.remaining(),
this.position() + offset);
}
}
5.3.2 duplicate()
而由 duplicate() 方法建立出來的檢視相當於就是完全復刻原生 ByteBuffer。它們的 offset,mark,position,limit,capacity 變數的值全部是一樣的,這裡需要注意雖然值是一樣的,但是它們各自之間是相互獨立的。用於對同一位元組陣列做不同的邏輯處理。
public abstract ByteBuffer duplicate();
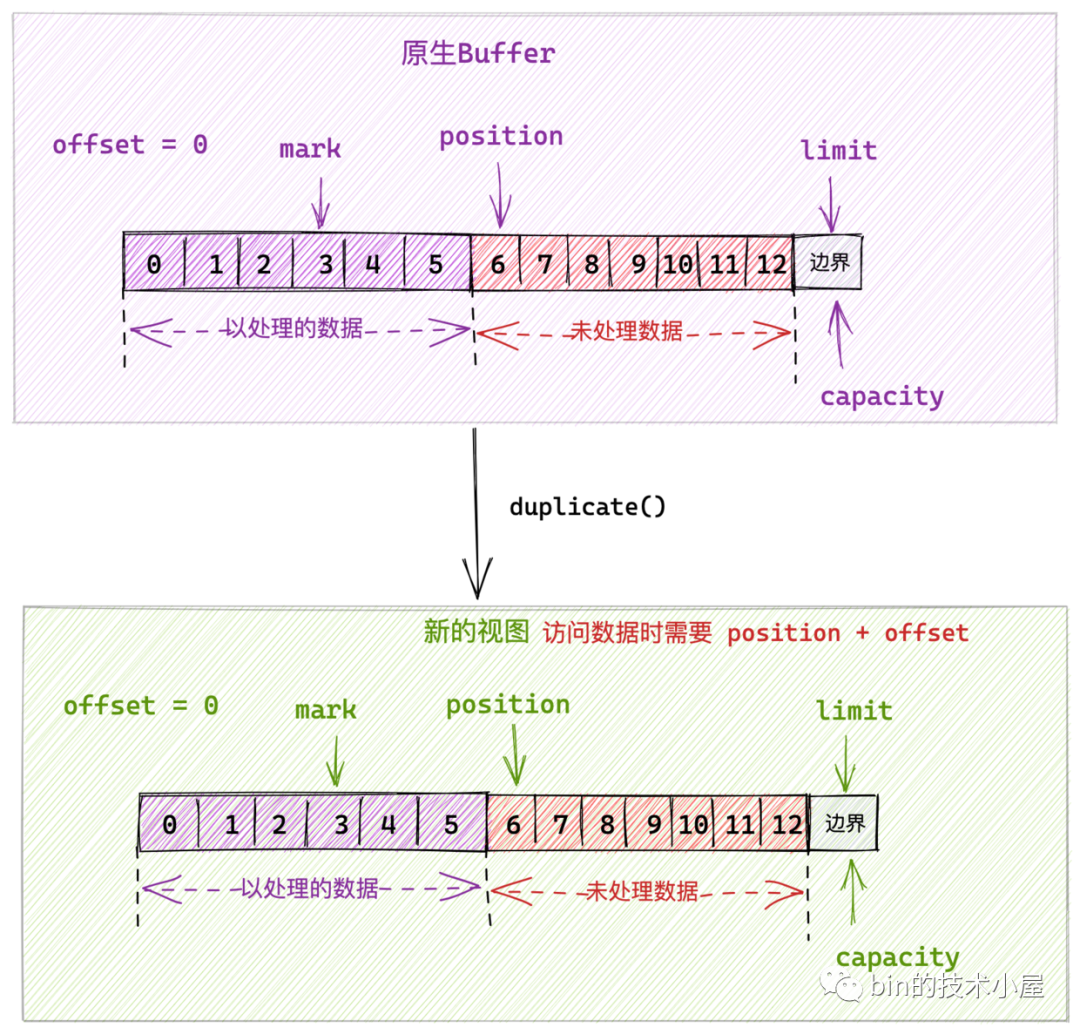
下面是 HeapByteBuffer 中關於 duplicate() 方法的具體實現:
class HeapByteBuffer extends ByteBuffer {
public ByteBuffer duplicate() {
return new HeapByteBuffer(hb,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
}
5.3.3 asReadOnlyBuffer()
public abstract ByteBuffer asReadOnlyBuffer();
通過 asReadOnlyBuffer() 方法我們可以基於原生 ByteBuffer 建立出一個唯讀檢視。對於唯讀檢視的 ByteBuffer 只能讀取不能寫入。對唯讀檢視進行寫入操作會丟擲 ReadOnlyBufferException 異常。
下面是 HeapByteBuffer 中關於 asReadOnlyBuffer() 方法的具體實現:
class HeapByteBuffer extends ByteBuffer {
public ByteBuffer asReadOnlyBuffer() {
return new HeapByteBufferR(hb,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
}
NIO 中專門設計了一個唯讀 ByteBufferR 檢視類。它的 isReadOnly 屬性為 true。
class HeapByteBufferR extends HeapByteBuffer {
protected HeapByteBufferR(byte[] buf,
int mark, int pos, int lim, int cap,
int off)
{
super(buf, mark, pos, lim, cap, off);
this.isReadOnly = true;
}
}
5.4 定義 ByteBuffer 讀寫相關操作
ByteBuffer 中定義了四種針對 Buffer 讀寫的基本操作方法,由於 ByteBuffer 這個抽象類是一個頂層設計類,只是規範定義了針對 ByteBuffer 操作的基本行為,它並不負責具體資料的儲存,所以這四種基本操作方法會在其具體的實現類中實現,這個我們後面會一一介紹。這裡只是向大家展示 NIO 針對 ByteBuffer 的頂層設計。
//從ByteBuffer中讀取一個位元組的資料,隨後position的位置向後移動一位
public abstract byte get();
//向ByteBuffer中寫入一個位元組的資料,隨後position的位置向後移動一位
public abstract ByteBuffer put(byte b);
//按照指定index從ByteBuffer中讀取一個位元組的資料,position的位置保持不變
public abstract byte get(int index);
//按照指定index向ByteBuffer中寫入一個位元組的資料,position的位置保持不變
public abstract ByteBuffer put(int index, byte b);
ByteBuffer 類中除了定義了這四種基本的讀寫操作,還依據這四個基本操作衍生出了幾種通用操作,下面筆者來為大家介紹下這幾種通用的操作:
1. 將 ByteBuffer中的位元組轉移到指定的位元組陣列 dst 中:
-
offset:dst 陣列存放轉移資料的起始位置。
-
length:從 ByteBuffer 中轉移位元組數。
public ByteBuffer get(byte[] dst, int offset, int length) {
//檢查指定index的邊界,確保不能越界
checkBounds(offset, length, dst.length);
//檢查ByteBuffer是否有足夠的轉移位元組
if (length > remaining())
throw new BufferUnderflowException();
int end = offset + length;
// 從當前ByteBuffer中position開始轉移length個位元組 到dst陣列中
for (int i = offset; i < end; i++)
dst[i] = get();
return this;
}
2. 將指定位元組陣列 src 中的資料轉移到 ByteBuffer中:
-
offset:從位元組陣列中的 offset 位置處開始轉移。
-
length:向 ByteBuffer轉移位元組個數。
public ByteBuffer put(byte[] src, int offset, int length) {
//檢查指定index的邊界,確保不能越界
checkBounds(offset, length, src.length);
//檢查ByteBuffer是否能夠容納得下
if (length > remaining())
throw new BufferOverflowException();
int end = offset + length;
//從位元組陣列的offset處,轉移length個位元組到ByteBuffer中
for (int i = offset; i < end; i++)
this.put(src[i]);
return this;
}
在為大家介紹完 ByteBuffer 的抽象設計之後,筆者相信大家現在已經對 NIO 的 ByteBuffer 有了一個整體上的認識。
接下來的內容,筆者將會為大家詳細介紹之前多次提到的這三種 ByteBuffer 的具體實現型別:
讓我們從 HeapByteBuffer 開始,HeapByteBuffer 的相關實現最簡單最容易理解的,我們會在 HeapByteBuffer 的介紹中,詳細介紹 Buffer 操作的實現。理解了 HeapByteBuffer 的相關實現,剩下的 Buffer 實現類就更容易理解了,都是大同小異。
6. HeapByteBuffer 的相關實現
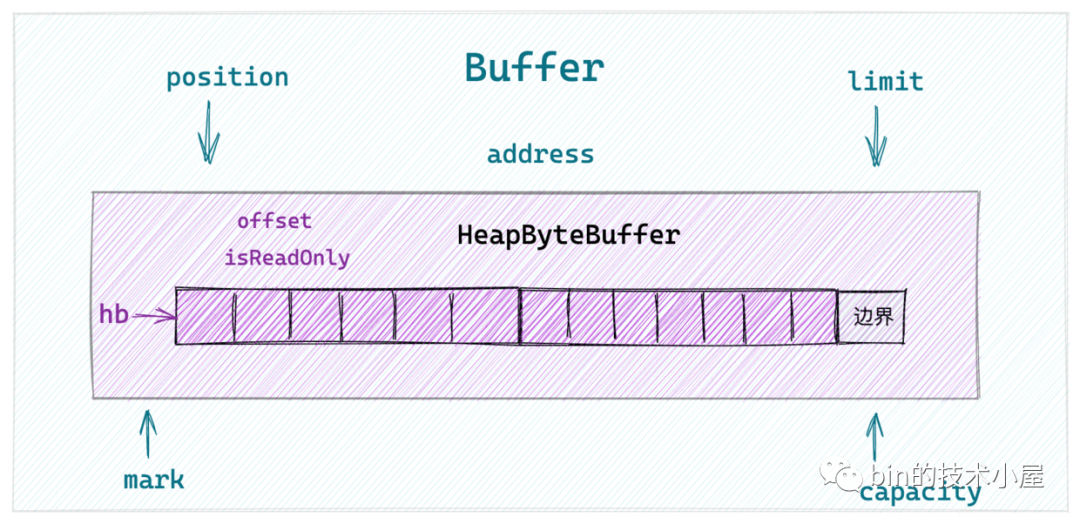
經過前邊幾個小節的介紹,大家應該對 HeapByteBuffer 的結構很清楚了,HeapByteBuffer 背後主要是依賴於 JVM 堆中的一個位元組陣列 byte[] hb。
在這個 JVM 堆中的位元組陣列的基礎上,實現了在 Buffer 類和 ByteBuffer類中定義的抽象方法。
6.1 HeapByteBuffer 的構造
在 HeapByteBuffer 的構造過程中首先就會根據使用者指定的 Buffer 容量 cap,在 JVM 堆中建立一個容量大小為 cap 的位元組陣列出來作為 HeapByteBuffer 底層儲存資料的容器。
class HeapByteBuffer extends ByteBuffer {
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
}
}
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
ByteBuffer(int mark, int pos, int lim, int cap,
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
}
還有我們《5.2 將位元組陣列對映成 ByteBuffer》小節介紹的用於將原生位元組陣列對映成 ByteBuffer 的 wrap 方法中用到的建構函式:
public static ByteBuffer wrap(byte[] array, int offset, int length) {
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
HeapByteBuffer(byte[] buf, int off, int len) {
super(-1, off, off + len, buf.length, buf, 0);
}
以及我們在《5.3 定義 ByteBuffer 檢視相關操作》小節介紹的用於建立 ByteBuffer 檢視的兩個方法 slice() 和 duplicate() 方法中用到的建構函式:
protected HeapByteBuffer(byte[] buf,
int mark, int pos, int lim, int cap,
int off)
{
super(mark, pos, lim, cap, buf, off);
}
6.2 從 HeapByteBuffer 中讀取位元組
6.2.1 根據 position 的位置讀取一個位元組
-
首先會通過《2.2.2 獲取 Buffer 下一個可讀取位置》小節介紹的 nextGetIndex() 方法獲取當前 HeapByteBuffer 中的 position 位置,根據 position 的位置讀取位元組。
-
為了相容 Buffer 檢視的相關操作,定位讀取位置 position 都會加上 offset。原生 Buffer 中的 offset = 0。
-
通過 position + offset 確定好存取 Index 之後,就是陣列的普通操作了,直接通過這個 Index 從 hb 位元組陣列中獲取位元組。隨後 Buffer 中的 position 向後移動一個位置。
class HeapByteBuffer extends ByteBuffer {
protected final byte[] hb;
protected final int offset;
public byte get() {
return hb[ix(nextGetIndex())];
}
// 確定存取 index
protected int ix(int i) {
return i + offset;
}
}
6.2.2 根據指定的 Index 讀取一個位元組
我們除了可以根據 Buffer 的 position 位置讀取位元組,還可以指定具體的 Index 來從 Buffer 中讀取位元組:
- 檢查 Index 是否超出 Buffer 的邊界範圍,通過檢查之後 Index + offset 確定讀取位置。
注意這個方法讀取位元組之後,position 的位置是不會改變的。
public byte get(int i) {
return hb[ix(checkIndex(i))];
}
6.2.3 將 HeapByteBuffer 中的位元組轉移到指定的位元組陣列中
這個方法其實筆者在《5.4 定義 ByteBuffer 讀寫相關操作》小節中介紹 ByteBuffer 的頂層規範設計時已經提到過了,由於 ByteBuffer 只是一個抽象類負責頂層操作規範的定義,本身並不具備具體儲存資料的能力,所以在 ByteBuffer 中只是提供了一個通用的實現。ByteBuffer 中的實現是通過在一個for () {....} 迴圈中不停的根據原生 Buffer 中的 position 指標(前邊介紹的 get() 方法)遍歷底層陣列並一個一個的拷貝到目標位元組陣列 dst 中。這樣的拷貝操作無疑是效率低下的。
而在 HeapByteBuffer 這個具體的 ByteBuffer 實現類中已經定義了具體的儲存方式,所以根據具體的儲存方式能夠做一下拷貝上的優化:
public ByteBuffer get(byte[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
if (length > remaining())
throw new BufferUnderflowException();
System.arraycopy(hb, ix(position()), dst, offset, length);
position(position() + length);
return this;
}
HeapByteBuffer 中對於拷貝位元組陣列中的資料使用了 System.arraycopy 方法,該方法在 JVM 中是一個 intrinsic method,是經過 JVM 編譯器特殊優化的,比通過 JNI 呼叫 native 方法的效能還要高。
利用 System.arraycopy 方法將 HeapByteBuffer 中的位元組資料從 position 開始,拷貝 length 個位元組到目標位元組陣列 dst 中。
6.3 向HeapByteBuffer中寫入位元組
6.3.1 根據 position 的位置寫入一個位元組
-
首先會通過《2.2.3 獲取 Buffer 下一個可寫入位置》小節中介紹的 nextPutIndex() 方法獲取當前 HeapByteBuffer 中的 position 位置,根據position的位置寫入位元組。
-
通過 position + offset 定位到寫入位置 Index,然後向 HeapByteBuffer 底層的位元組陣列 hb 直接寫入位元組資料。隨後 position 向後移動一個位置。
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
protected int ix(int i) {
return i + offset;
}
6.3.2 根據指定的 Index 寫入一個位元組
注意通過這個方法根據指定 Index 寫入位元組之後,position 的位置是不會改變的。
public ByteBuffer put(int i, byte x) {
hb[ix(checkIndex(i))] = x;
return this;
}
6.3.3 將指定位元組陣列轉移到 HeapByteBuffer 中
同理和《6.2.3 將 HeapByteBuffer 中的位元組轉移到指定的位元組陣列中》小節中介紹的相關方法一樣,HeapByteBuffer 也是採用了 JVM 中的 System.arraycopy 方法(intrinsic method )從而更加高效地進行位元組陣列的拷貝操作。
從位元組陣列 src 中的 offset 位置開始拷貝 length 個位元組到 HeapByteBuffer中
public ByteBuffer put(byte[] src, int offset, int length) {
checkBounds(offset, length, src.length);
if (length > remaining())
throw new BufferOverflowException();
System.arraycopy(src, offset, hb, ix(position()), length);
position(position() + length);
return this;
}
HeapByteBuffer 背後依靠的位元組陣列儲存的是一個一個的位元組,以上操作全部針對的是單個位元組來的,所以並不需要考慮位元組序的影響,但是如果我們想從 HeapByteBuffer 中讀取寫入一個 int 或者一個 double 型別的資料,那麼我們就需要考慮位元組序的問題了。
在介紹如何從 HeapByteBuffer 中讀取或者寫入一個指定基本型別資料之前,筆者先來為大家介紹一下:
-
到底什麼是位元組序?
-
為什麼會有位元組序的存在?
-
位元組序對 Buffer 的操作會有什麼影響?
7. 位元組序
談起位元組序來大家可能都會有這樣的感觸就是記了忘,忘了記,記了又忘。所以為了讓大家清晰地理解位元組序並且深深地刻入腦海中,筆者挖空心思終於想出了一個生活中的例子來為大家說明位元組序。
筆者平時有健身的習慣,已經堅持擼鐵四年多了,為了給身體補充蛋白質增加肌肉量,每天打底至少 15 個雞蛋,所以剝雞蛋就成為了筆者日常的一個重要任務。

那麼問題來了,在我們剝雞蛋的時候,我們到底是該從雞蛋大的一端剝起還是從雞蛋小的的一端剝起呢?
這還真是一個問題,有的人喜歡從小端剝起,但是筆者習慣從大端開始剝起。於是就有了大端-小端的剝法。

既然剝雞蛋有大端-小端的分歧在,那麼在計算機網路傳輸資料時也會存在這樣的問題,計算機中是怎麼扯出大端-小端的分歧呢?請耐心聽筆者接著講下去~~
我們都知道在計算機中儲存資料,字元編碼以及網路中傳輸資料時都是通過一個 bit 一個 bit 組成的 010101 這樣的二進位制形式傳輸儲存的。由於本系列的主題是關於網路 IO 的處理,所以筆者這裡以網路傳輸中的位元組序舉例:
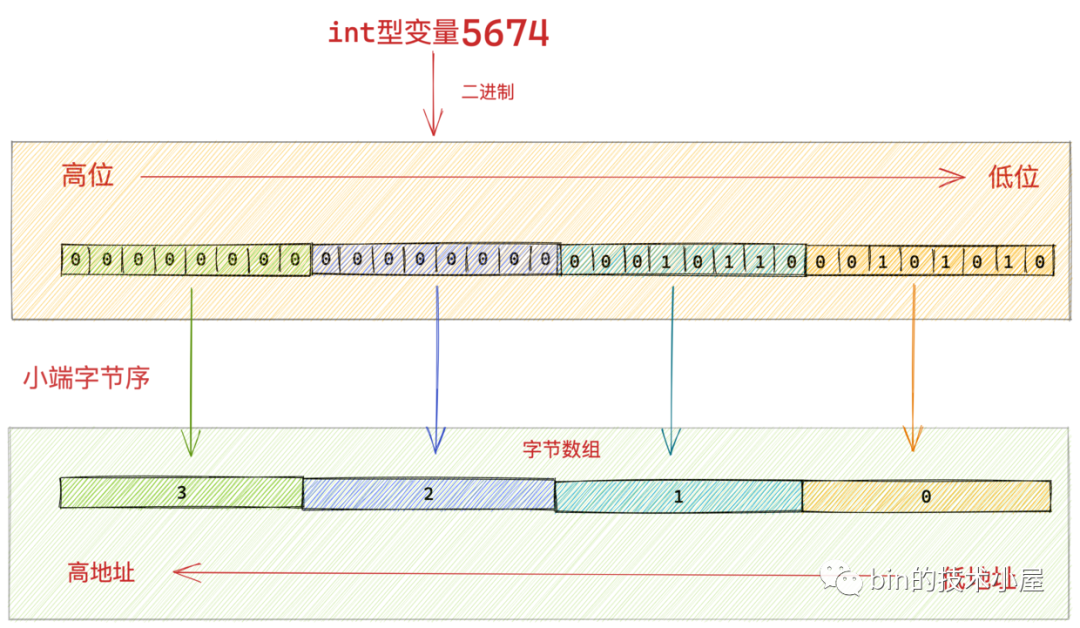
比如現在我們要傳輸一個 int 型的整數 5674 到對端主機中。int 型的變數 5674 對應的二進位制是 1011000101010 。如下圖所示:
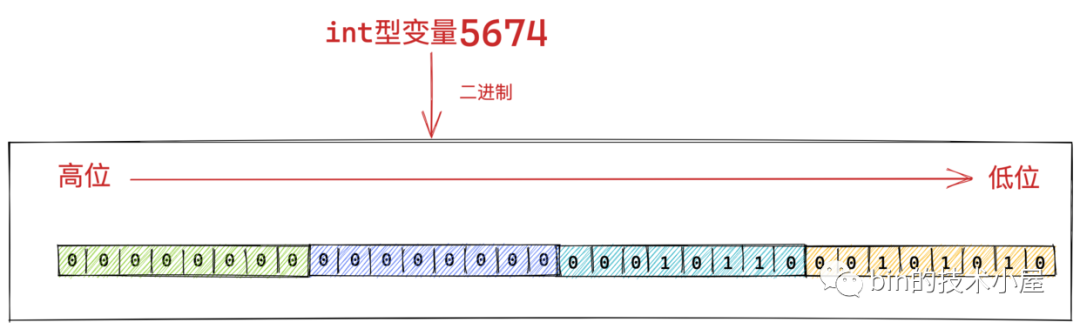
剝雞蛋的分歧在於是從大的一端開始剝還是從小的一端開始剝,從大的一端開始剝我們叫做大端剝法,而從小的一端開始剝我們叫做小端剝法。
同樣的道理,我們在網路傳輸二進位制資料的時候也有分歧:我們是從二進位制的高位開始傳輸呢(圖中綠色區域)?還是從二進位制的低位開始傳輸呢(圖中黃色區域)?
如果我們從二進位制資料的高位(類比雞蛋的大端)開始傳輸我們就叫大端位元組序,如果我們從二進位制的低位(類比雞蛋的小端)開始傳輸就叫小端位元組序。
網路協定採用的是大端位元組序傳輸
好了,現在關於網路傳輸位元組的順序問題,我們闡述清楚了,那麼接下來我們看下當網路位元組傳輸到對端時,對端如何接收?
當網路位元組按照大端位元組序傳輸到對端計算機時,對端會在作業系統的堆中開闢一塊記憶體用來接收網路位元組。而在作業系統的虛擬記憶體佈局中,堆空間的地址增長方向是從低地址向高地址增長,而棧空間的地址是從高地址向低地址增長。
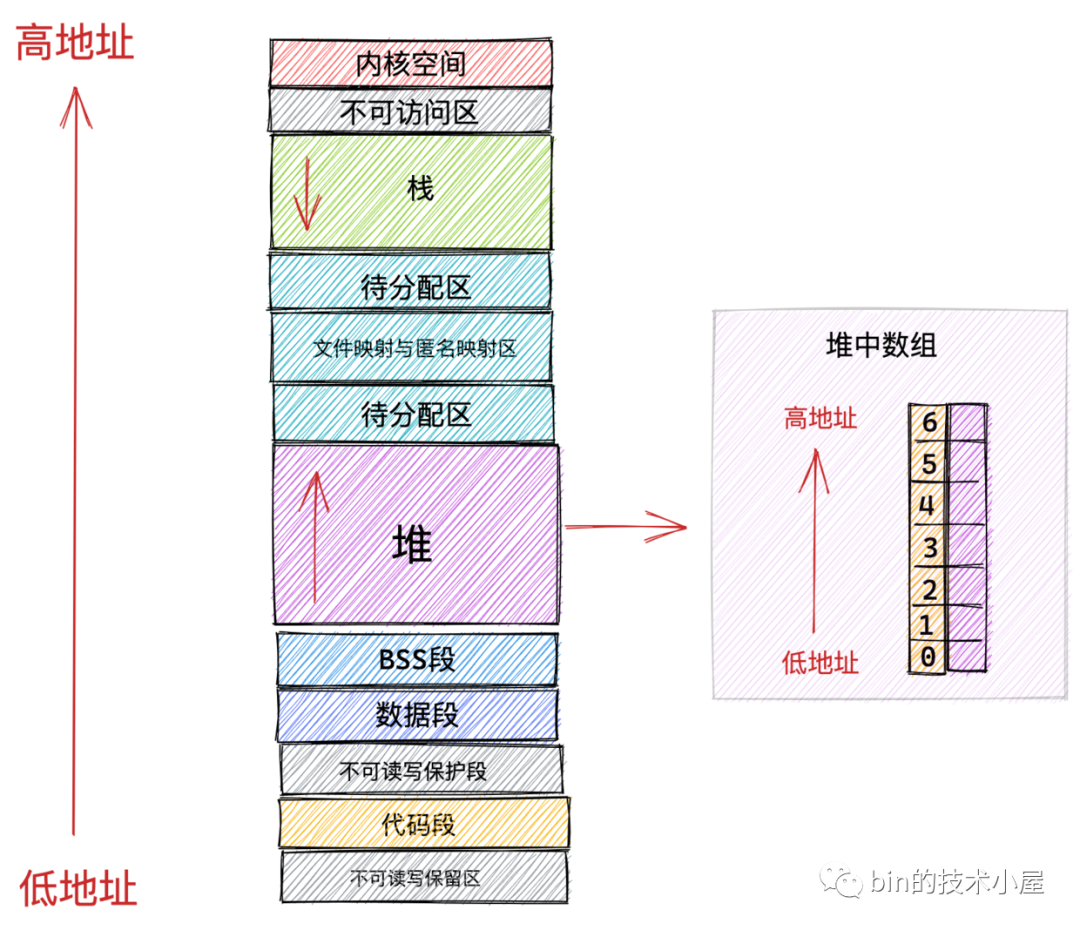
現在我們假設如果當網路位元組傳輸到對端計算機中,我們在對端使用 HeapByteBuffer 去接收網路位元組(這裡只是假設,實踐上都是使用 DirectByteBuffer ),經過前邊內容的介紹我們知道,HeapByteBuffer 背後其實依靠一個位元組陣列來儲存位元組。如圖中所示,位元組陣列從索引 0 開始到索引 6 它們在記憶體中的地址是從低地址到高地址。
理解了這些,下面我們就來看下位元組在不同位元組序下是如何接收儲存的。
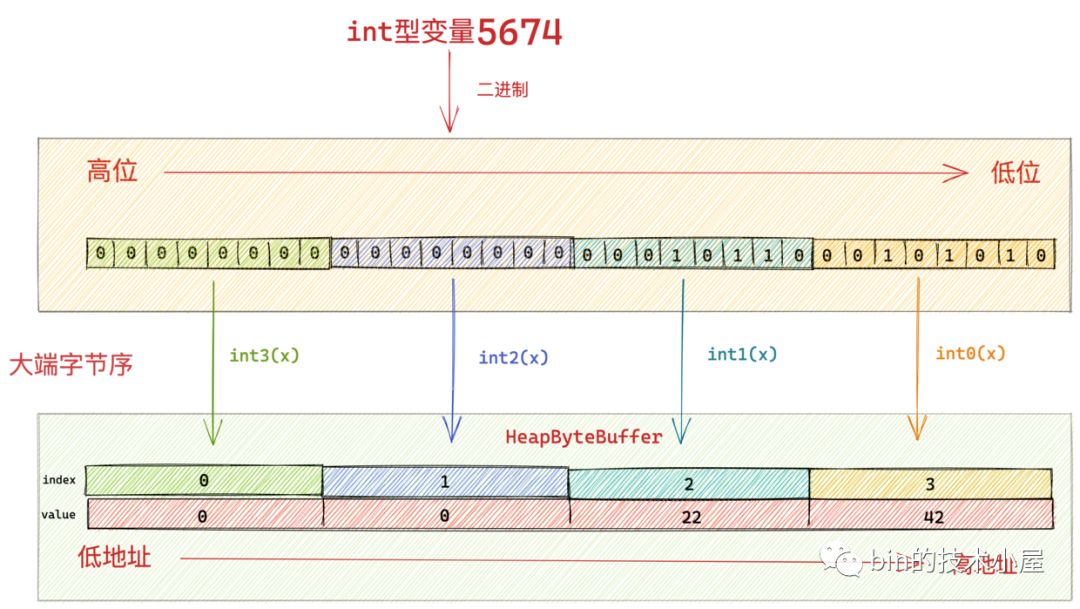
7.1 大端位元組序
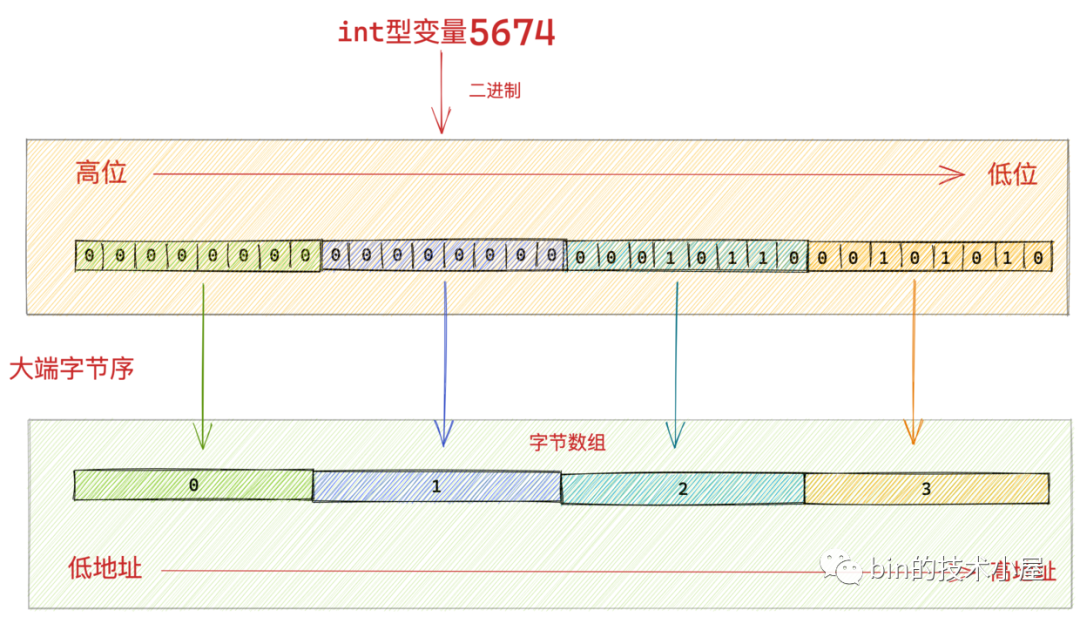
如圖中所示,在大端位元組序下 int 型變數 5674 它的位元組高位被儲存在了位元組陣列中的低地址中,位元組的低位被儲存在位元組陣列的高地址中。這就是大端位元組序,也是比較符合人類的直觀感受。
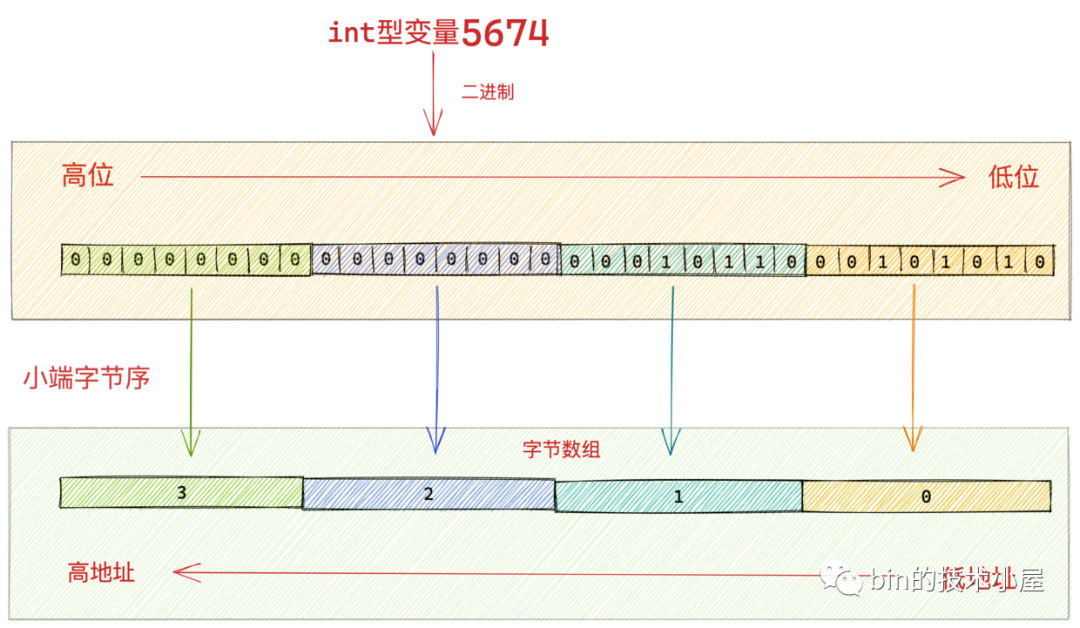
7.2 小端位元組序
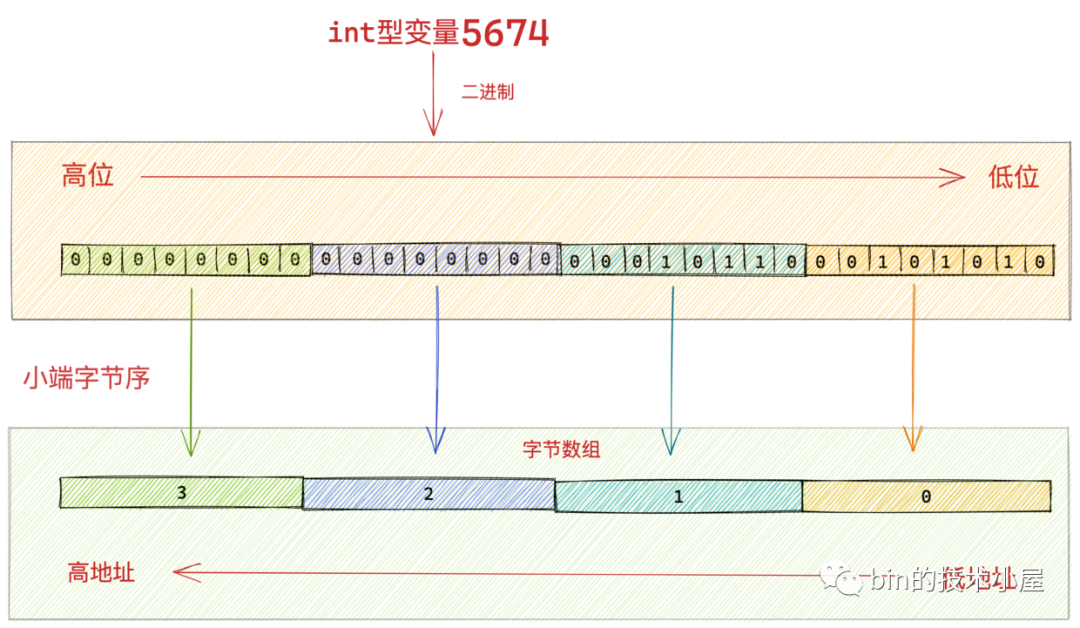
然而在小端位元組序下,int 型變數 5674 它的位元組高位被儲存在了位元組陣列中的高地址中,位元組的低位被儲存在位元組陣列的低地址中。這就是小端位元組序,正好和正常人類直觀感受是相反的。
到現在,我想大家應該最起碼從概念上知道什麼是大端位元組序?什麼是小端位元組序了吧?
下面筆者在帶大家到實戰中,再去體驗一把大端位元組序和小端位元組序的不同。徹底讓大家理解清楚。
8. 向 HeapByteBuffer 中寫入指定基本型別
HeapByteBuffer 背後是一個在 JVM 堆中開闢的一個位元組陣列,裡邊存放的是一個一個的位元組,當我們以單個位元組的形式操作 HeapByteBuffer 的時候並沒有什麼問題,可是當我們向 HeapByteBuffer 寫入一個指定的基本型別資料時,比如寫入一個 int 型 (佔用 4 個位元組),寫入一個 double 型 (佔用 8 個位元組),就必須要考慮位元組序的問題了。
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
boolean bigEndian = true;
boolean nativeByteOrder = (Bits.byteOrder() == ByteOrder.BIG_ENDIAN);
}
我們可以強制網路協定傳輸使用大端位元組序,但是我們無法強制主機中採用的位元組序,所以我們需要經常在網路 IO 場景下做一些位元組序的轉換工作。
JDK NIO ByteBuffer 預設的位元組序為大端模式,我們可以通過 NIO 提供的操作類 Bits 獲取主機位元組序 Bits.byteOrder(),或者直接獲取 NIO ByteBuffer 中的 nativeByteOrder 欄位判斷主機位元組序:true 表示主機位元組序為大端模式,false 表示主機位元組序為小端模式。
當然我們也可以通過 ByteBuffer 中的 order 方法來指定我們想要的位元組序:
public final ByteBuffer order(ByteOrder bo) {
bigEndian = (bo == ByteOrder.BIG_ENDIAN);
nativeByteOrder =
(bigEndian == (Bits.byteOrder() == ByteOrder.BIG_ENDIAN));
return this;
}
下面筆者就帶大家分別從大端模式和小端模式下來看一下如何向 HeapByteBuffer 寫入一個指定基本型別的資料。我們以 int 型資料舉例,假設要寫入的 int 值 為 5674。
8.1 大端位元組序
class HeapByteBuffer extends ByteBuffer {
public ByteBuffer putInt(int x) {
Bits.putInt(this, ix(nextPutIndex(4)), x, bigEndian);
return this;
}
}
首先我們會獲取當前 HeapByteBuffer 的寫入位置 position,因為我們需要寫入的是一個 int 型的資料,所以當寫入完畢之後 position 的位置需要向後移動 4 位。nextPutIndex 方法的邏輯筆者在之前的內容中已經詳細介紹過了,這裡不在贅述。
class Bits {
static void putInt(ByteBuffer bb, int bi, int x, boolean bigEndian) {
if (bigEndian)
// 採用大端位元組序寫入 int 資料
putIntB(bb, bi, x);
else
// 採用小端位元組序寫入 int 資料
putIntL(bb, bi, x);
}
static void putIntB(ByteBuffer bb, int bi, int x) {
bb._put(bi , int3(x));
bb._put(bi + 1, int2(x));
bb._put(bi + 2, int1(x));
bb._put(bi + 3, int0(x));
}
}
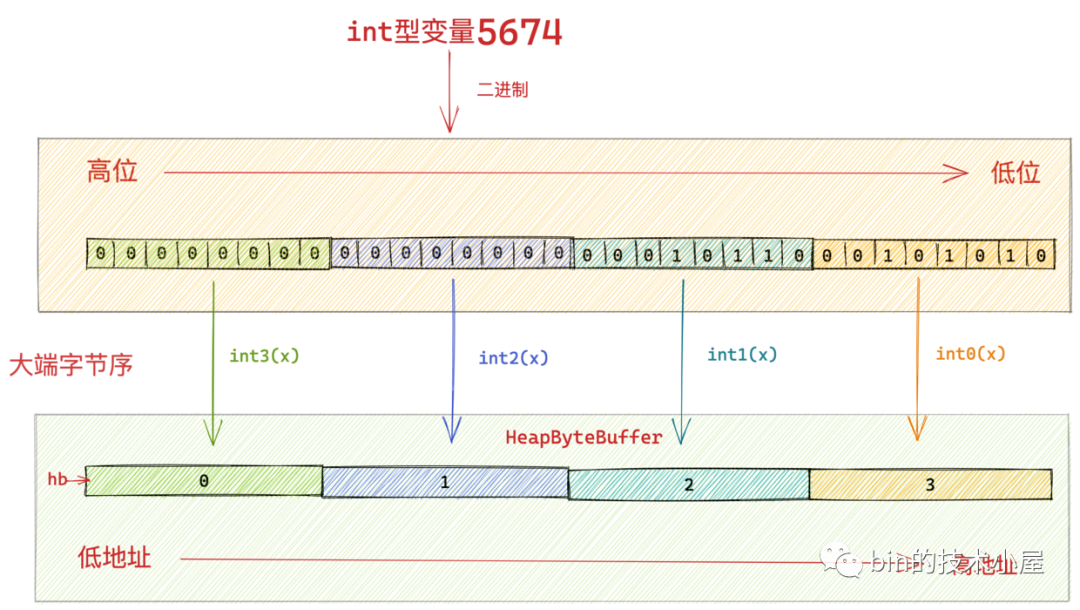
大家看到了嗎,這裡就是按照我們之前介紹的大端位元組序,從 int 值 5674 的二進位制高位位元組到低位位元組依次寫入 HeapByteBuffer中位元組陣列的低地址中。
這裡的 int3(x) 方法就是負責獲取寫入資料 x 的最高位位元組,並將最高位位元組(下圖中綠色部分)寫入位元組陣列中的低地址中(下圖中對應綠色部分)。
同理 int2(x),int1(x),int0(x) 方法依次獲取 x 的次高位位元組,依次寫入位元組陣列中的低地址中。
那麼我們如何依次獲得一個 int 型資料的高位位元組呢?大家接著跟著筆者往下走~
8.1.1 int3(x) 獲取 int 型最高位位元組
class Bits {
private static byte int3(int x) { return (byte)(x >> 24); }
}
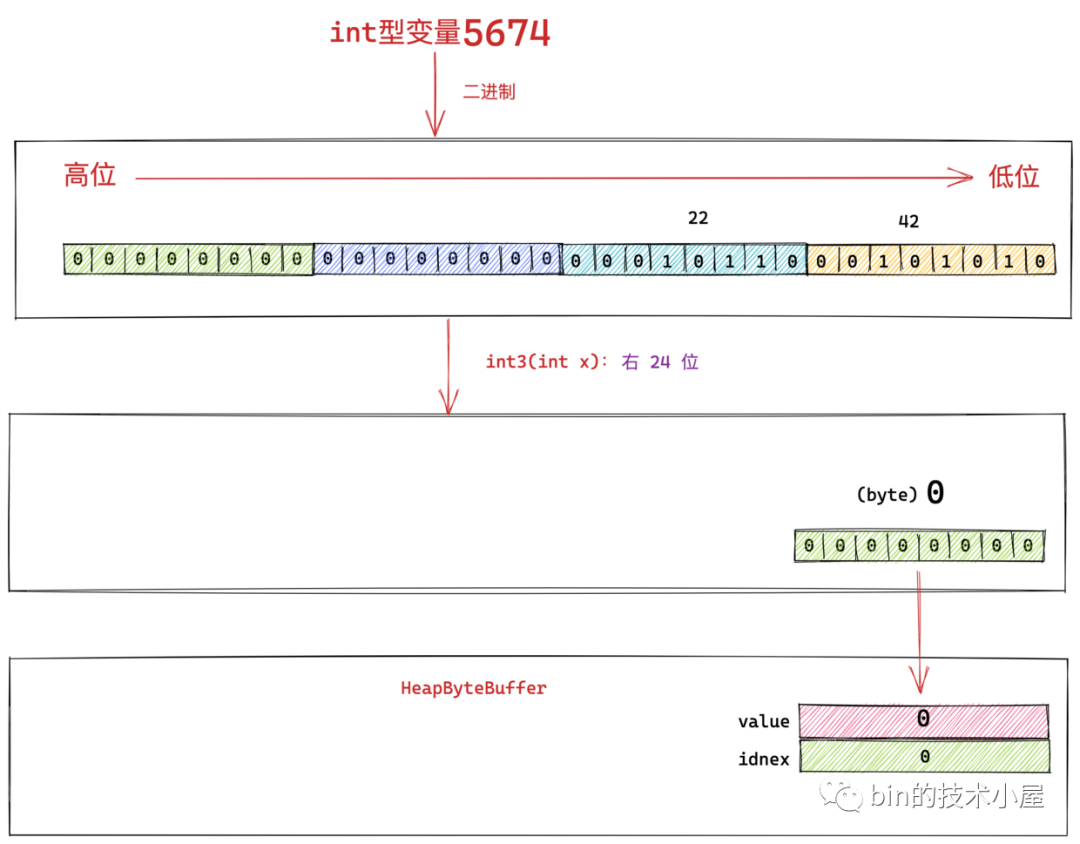
8.1.2 int2(x) 獲取 int 型次高位位元組
class Bits {
private static byte int2(int x) { return (byte)(x >> 16); }
}
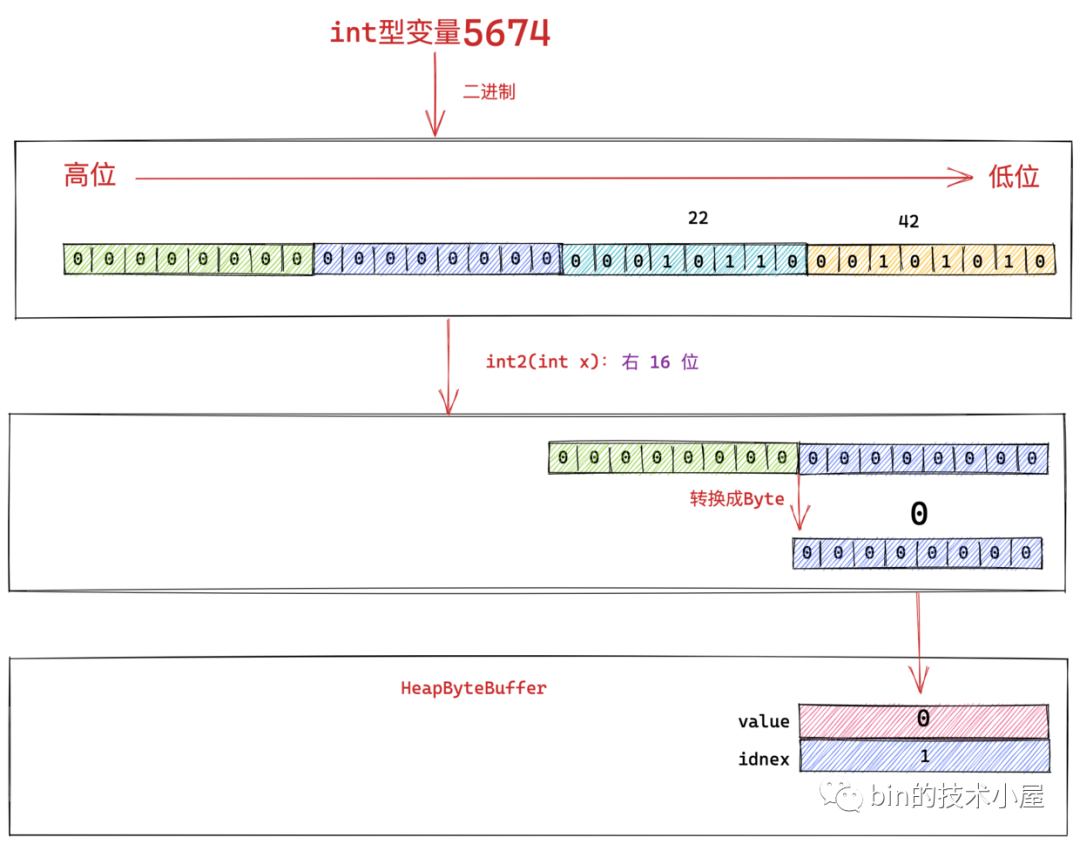
8.1.3 int1(x) 獲取 int 型第三高位位元組
class Bits {
private static byte int1(int x) { return (byte)(x >> 8); }
}
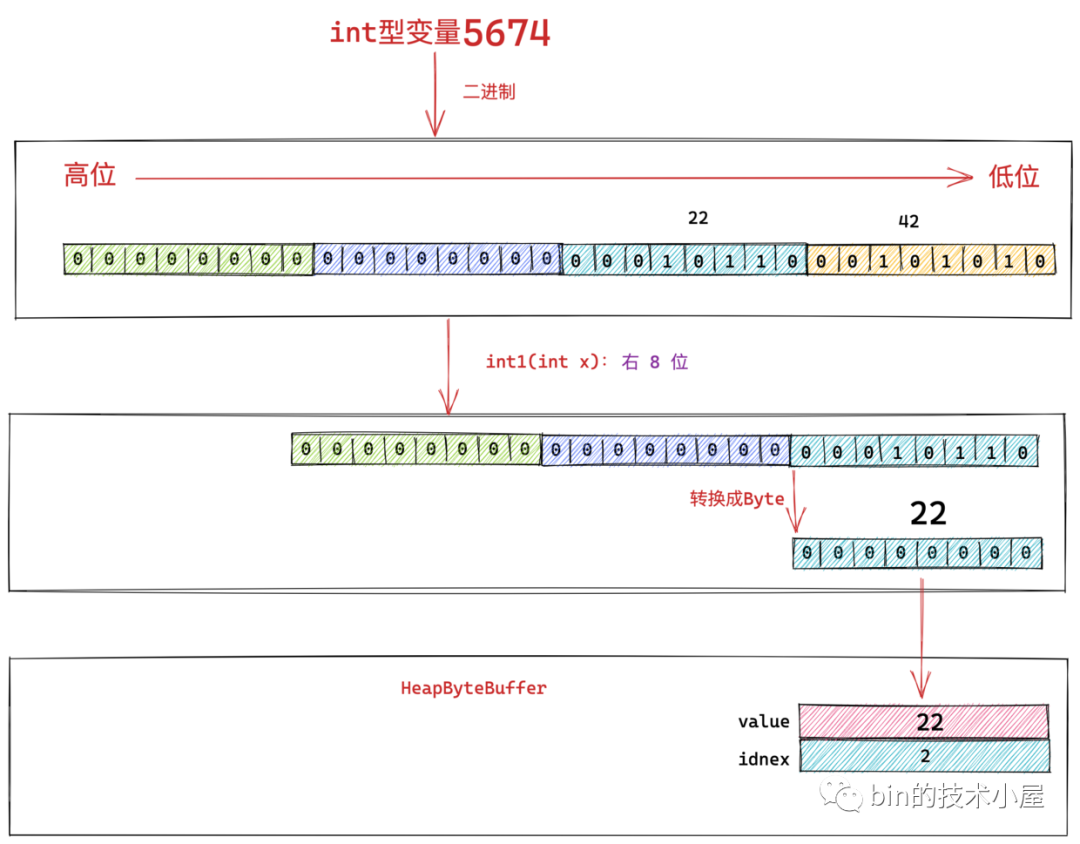
8.1.4 int0(x) 獲取 int 型最低位位元組
class Bits {
private static byte int0(int x) { return (byte)(x ); }
}
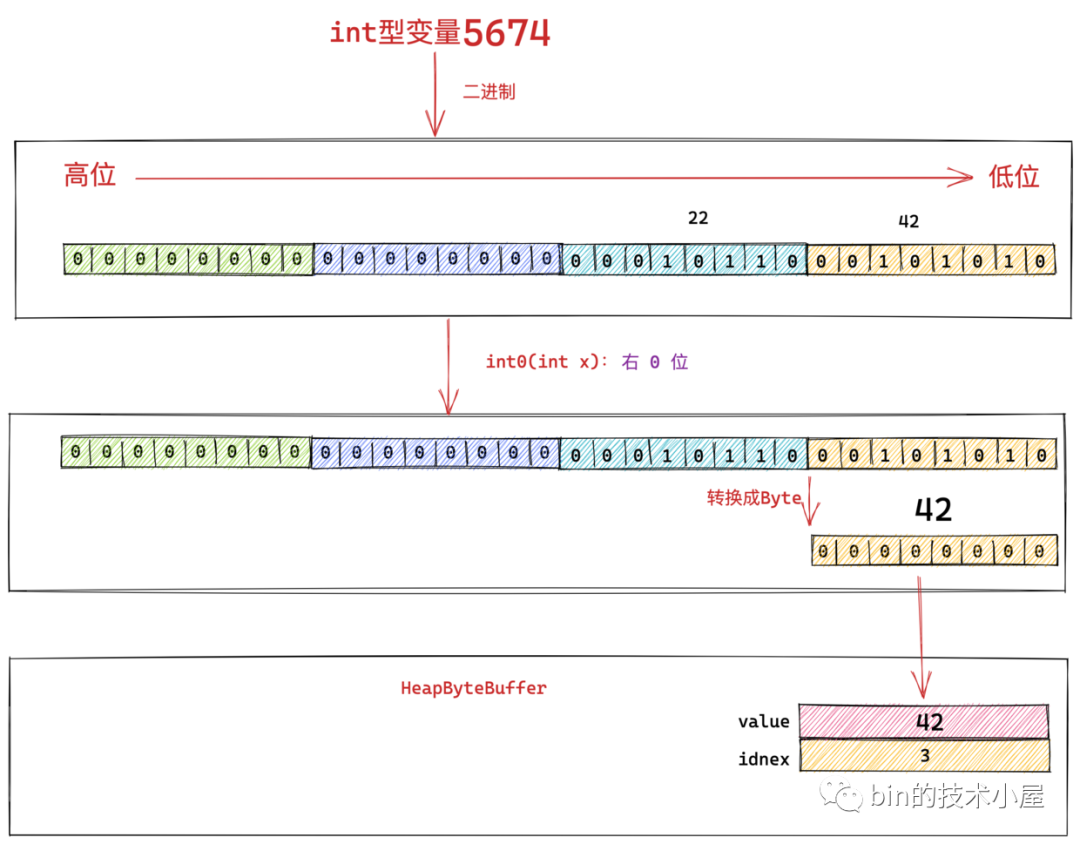
最終 int 型變數 5764 按照大端位元組序寫入到 HeapByteBuffer之後的位元組陣列結構如下:
8.2 小端位元組序
在我們徹底理解了大端位元組序的操作之後,小端位元組序的相關操作就很好理解了。
static void putIntL(ByteBuffer bb, int bi, int x) {
bb._put(bi + 3, int3(x));
bb._put(bi + 2, int2(x));
bb._put(bi + 1, int1(x));
bb._put(bi , int0(x));
}
根據我們之前介紹的小端位元組序的定義,在小端模式下二進位制資料的高位是儲存在位元組陣列中的高地址中,二進位制資料的低位是儲存在位元組陣列中的低地址中。
9. 從 HeapByteBuffer 中讀取指定基本型別
當我們清楚了在不同的位元組序下如何向 HeapByteBuffer 中寫入指定基本型別資料的過程之後,那麼在不同位元組序下向 HeapByteBuffer 讀取指定基本型別資料的過程,我想大家就能很容易理解了。
我們還是以 int 型資料舉例,假設要從 HeapByteBuffer 中讀取一個 int 型的資料。
首先我們還是獲取當前 HeapByteBuffer 中的讀取位置 position,從 position 位置開始讀取四個位元組出來,然後通過這四個位元組組裝成一個 int 資料返回。
class HeapByteBuffer extends ByteBuffer {
public int getInt() {
return Bits.getInt(this, ix(nextGetIndex(4)), bigEndian);
}
}
class Bits {
static int getInt(ByteBuffer bb, int bi, boolean bigEndian) {
return bigEndian ? getIntB(bb, bi) : getIntL(bb, bi) ;
}
}
我們還是先來介紹大端模式下的讀取過程:
9.1 大端位元組序
class Bits {
static int getIntB(ByteBuffer bb, int bi) {
return makeInt(bb._get(bi ),
bb._get(bi + 1),
bb._get(bi + 2),
bb._get(bi + 3));
}
}
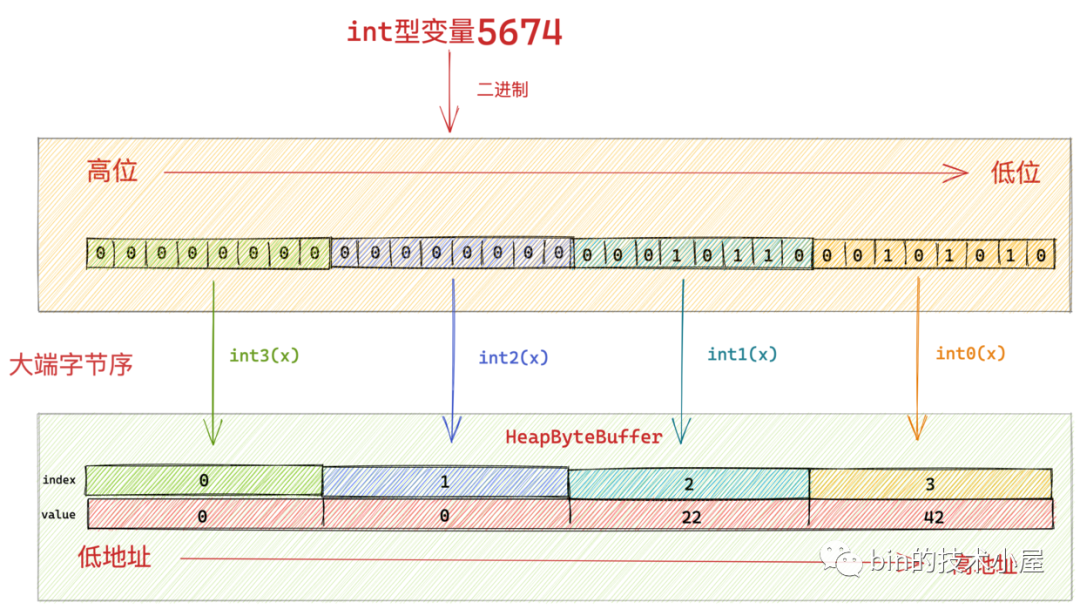
由於在大端模式下,二進位制資料的高位是存放於位元組陣列中的低地址中,我們需要從位元組陣列中的低地址中依次讀取二進位制資料的高位出來。
然後我們從高位開始依次組裝 int 型資料,正好和寫入過程相反。
static private int makeInt(byte b3, byte b2, byte b1, byte b0) {
return (((b3 ) << 24) |
((b2 & 0xff) << 16) |
((b1 & 0xff) << 8) |
((b0 & 0xff) ));
}
9.2 小端位元組序
class Bits {
static int getIntL(ByteBuffer bb, int bi) {
return makeInt(bb._get(bi + 3),
bb._get(bi + 2),
bb._get(bi + 1),
bb._get(bi ));
}
}
而在小端模式下,我們則需要先從位元組陣列中的高地址中將二進位制資料的高位依次讀取出來,然後在從高位開始依次組裝 int 型資料。
在筆者介紹完了關於 int 資料的讀寫過程之後,相信大家可以很輕鬆的理解其他基本型別在不同位元組序下的讀寫操作過程了。
10. 將 HeapByteBuffer 轉換成指定基本型別的 Buffer
在《2. NIO 對 Buffer 的頂層抽象》小節一開始就介紹到,NIO 其實為我們提供了多種基本型別的 Buffer 實現。
NIO 允許我們將 ByteBuffer 轉換成任意一種基本型別的 Buffer,這裡我們以轉換 IntBuffer 為例說明:
class HeapByteBuffer extends ByteBuffer {
public IntBuffer asIntBuffer() {
int size = this.remaining() >> 2;
int off = offset + position();
return (bigEndian
? (IntBuffer)(new ByteBufferAsIntBufferB(this,
-1,
0,
size,
size,
off))
: (IntBuffer)(new ByteBufferAsIntBufferL(this,
-1,
0,
size,
size,
off)));
}
}
IntBuffer 底層其實依託了一個 ByteBuffer,當我們向 IntBuffer 讀取一個 int 資料時,其實是從底層依託的這個 ByteBuffer 中讀取 4 個位元組出來然後組裝成 int 資料返回。
class ByteBufferAsIntBufferB extends IntBuffer {
protected final ByteBuffer bb;
public int get() {
return Bits.getIntB(bb, ix(nextGetIndex()));
}
}
class Bits {
static int getIntB(ByteBuffer bb, int bi) {
return makeInt(bb._get(bi ),
bb._get(bi + 1),
bb._get(bi + 2),
bb._get(bi + 3));
}
static private int makeInt(byte b3, byte b2, byte b1, byte b0) {
return (((b3 ) << 24) |
((b2 & 0xff) << 16) |
((b1 & 0xff) << 8) |
((b0 & 0xff) ));
}
}
同理,我們向 IntBuffer 中寫入一個int資料時,其實是想底層依託的這個 ByteBuffer 寫入 4 個位元組。
IntBuffer 底層依託的這個 ByteBuffer ,會根據位元組序的不同分為:ByteBufferAsIntBufferB(大端實現)和 ByteBufferAsIntBufferL(小端實現)。
在我們詳細介紹完 HeapByteBuffer 的實現之後,筆者這裡就不在為大家詳細介紹 ByteBufferAsIntBufferB 和 ByteBufferAsIntBufferL 了。操作全部是一樣的,感興趣的大家可以自行檢視一下。
總結

本文我們以 JDK NIO Buffer 中最簡單的一個實現類 HeapByteBuffer 為主線從 NIO 對 Buffer 的頂層抽象設計開始從整體上為大家介紹了 Buffer 的設計。
在這個過程中,我們可以體會到 NIO 對 Buffer 的設計還是比較複雜的,尤其是我們針對裸 NIO 進行程式設計的時候會有非常多的反人類操作,一不小心就會出錯。
比如:用於 Buffer 讀模式切換 flip() 方法,寫模式切換的 clear() 方法和 compact() 方法以及用於重新處理 Buffer 中資料的 rewind() 方法。在我們使用這些方法處理位元組資料的時候需要時刻清楚 Buffer 中的資料分佈情況,一不小心就會造成資料的覆蓋和丟失。
後面我們又介紹了 Buffer 中檢視的概念和相關操作 slice() 方法和 duplicate() 方法,以及關於檢視 Buffer 和原生 Buffer 之間的區別和聯絡。
我們以 HeapByteBuffer 為例,介紹了 NIO Buffer 相關頂層抽象方法的實現,並再次基礎上更進一步介紹了在不同位元組序下 ByteBuffer 相關的讀取寫入操作的詳細過程。
最後我們介紹了 ByteBuffer 與相關指定基本型別 Buffer (比如 IntBuffer,LongBuffer)在不同位元組序下的轉換。
另外我們還穿插介紹了:到底什麼是位元組序? 為什麼會有位元組序的存在? 位元組序對 Buffer 的操作會有什麼影響?
因為 HeapByteBuffer 足夠簡單,所以利用它能夠把整個 NIO 對 Buffer 的設計與實現串聯起來,但是根據 Buffer 背後的儲存機制不同,還有 DirectByteBuffer 和 MappedByteBuffer ,它們的 API 在使用上基本和 HeapByteBuffer 是一致的。但是它們背後涉及到的原理卻是非常複雜的(尤其是 MappedByteBuffer)。
所以筆者後面會單獨寫兩篇文章來詳細分別為大家介紹 DirectByteBuffer 和 MappedByteBuffer 背後涉及到的複雜原理,目的是讓大家不僅會使用而且還要把它們背後涉及到的複雜原理徹底搞透徹弄清楚,要知其然並且還要知其所以然~~~