分庫分表ShardingSphere-JDBC筆記整理
一、分庫分表解決的現狀問題
-
解決資料庫本身瓶頸
-
連線數: 連線數過多時,就會出現‘too many connections’的錯誤,存取量太大或者資料庫設定的最大連線數太小的原因
-
Mysql預設的最大連線數為100.可以修改,而mysql服務允許的最大連線數為16384
-
資料庫分表可以解決單表海量資料的查詢效能問題
-
資料庫分庫可以解決單臺資料庫的並行存取壓力問題
-
-
解決系統本身IO、CPU瓶頸
- 磁碟讀寫IO瓶頸,熱點資料太多,儘管使用了資料庫本身快取,但是依舊有大量IO,導致sql執行速度慢
- 網路IO瓶頸,請求的資料太多,資料傳輸大,網路頻寬不夠,鏈路響應時間變長
- CPU瓶頸,尤其在基礎資料量大單機複雜SQL計算,SQL語句執行佔用CPU使用率高,也有掃描行數大、鎖衝突、鎖等待等原因
- 可以通過 show processlist; 、show full processlist,發現 CPU 使用率比較高的SQL
- 常見的對於查詢時間長,State 列值是 Sending data,Copying to tmp table,Copying to tmp table on disk,Sorting result,Using filesort 等都是可能有效能問題SQL,清楚相關影響問題的情況可以kill掉
- 也存在執行時間短,但是CPU佔用率高的SQL,通過上面命令查詢不到,這個時候最好通過執行計劃分析explain進行分析
二、垂直和水平分庫分表區別
- 垂直角度(表結構不一樣)
- 垂直分表: 將一個表欄位拆分多個表,每個表儲存部分欄位
- 好處: 避免IO時鎖表的次數,分離熱點欄位和非熱點欄位,避免大欄位IO導致效能下降
- 原則:業務經常組合查詢的欄位一個表;不常用欄位一個表;text、blob型別欄位作為附屬表
- 垂直分庫:根據業務將表分類,放到不同的資料庫伺服器上
- 好處:避免表之間競爭同個物理機的資源,比如CPU/記憶體/硬碟/網路IO
- 原則:根據業務相關性進行劃分,領域模型,微服務劃分一般就是垂直分庫
- 垂直分表: 將一個表欄位拆分多個表,每個表儲存部分欄位
- 水平角度(表結構一樣)
- 水平分庫:把同個表的資料按照一定規則分到不同的資料庫中,資料庫在不同的伺服器上
- 好處: 多個資料庫,降低了系統的IO和CPU壓力
- 原則
- 選擇合適的分片鍵和分片策略,和業務場景配合
- 避免資料熱點和存取不均衡、避免二次擴容難度大
- 水平分表:同個資料庫內,把一個表的資料按照一定規則拆分到多個表中,對資料進行拆分,不影響表結構
- 單個表的資料量少了,業務SQL執行效率高,降低了系統的IO和CPU壓力
- 原則
- 選擇合適的分片鍵和分片策略,和業務場景配合
- 避免資料熱點和存取不均衡、避免二次擴容難度大
- 水平分庫:把同個表的資料按照一定規則分到不同的資料庫中,資料庫在不同的伺服器上
2.1垂直分表
-
也就是「大表拆小表」,基於列欄位進行的
-
拆分原則一般是表中的欄位較多,將不常用的或者資料較大,長度較長的拆分到「擴充套件表 如text型別欄位
-
存取頻次低、欄位大的商品描述資訊單獨存放在一張表中,存取頻次較高的商品基本資訊單獨放在一張表中
-
垂直拆分原則
-
把不常用的欄位單獨放在一張表;
-
把text,blob等大欄位拆分出來放在附表中;
-
業務經常組合查詢的列放在一張表中
-
2.2垂直分庫
- 垂直分庫針對的是一個系統中的不同業務進行拆分, 資料庫的連線資源比較寶貴且單機處理能力也有限
- 沒拆分之前全部都是落到單一的庫上的,單庫處理能力成為瓶頸,還有磁碟空間,記憶體,tps等限制
- 拆分之後,避免不同庫競爭同一個物理機的CPU、記憶體、網路IO、磁碟,所以在高並行場景下,垂直分庫一定程度上能夠突破IO、連線數及單機硬體資源的瓶頸
- 垂直分庫可以更好解決業務層面的耦合,業務清晰,且方便管理和維護
- 一般從單體專案升級改造為微服務專案,就是垂直分庫
2.3水平分表
-
把一個表的資料分到一個資料庫的多張表中,每個表只有這個表的部分資料
-
核心是把一個大表,分割N個小表,每個表的結構是一樣的,資料不一樣,全部表的資料合起來就是全部資料
-
針對資料量巨大的單張表(比如訂單表),按照某種規則(RANGE,HASH取模等),切分到多張表裡面去
-
但是這些表還是在同一個庫中,所以單資料庫操作還是有IO瓶頸,主要是解決單表資料量過大的問題
-
減少鎖表時間,沒分表前,如果是DDL(create/alter/add等)語句,當需要新增一列的時候mysql會鎖表,期間所有的讀寫操作只能等待
2.4水平分庫
- 把同個表的資料按照一定規則分到不同的資料庫中,資料庫在不同的伺服器上
- 水平分庫是把不同表拆到不同資料庫中,它是對資料行的拆分,不影響表結構
- 每個庫的結構都一樣,但每個庫的資料都不一樣,沒有交集,所有庫的並集就是全量資料
- 水平分庫的粒度,比水平分表更大
三、水平分庫分表常見策略
3.1 Range
-
範圍角度思考問題 (範圍的話更多是水平分表)
-
數位
- 自增id範圍
-
時間
- 年、月、日範圍
- 比如按照月份生成 庫或表 pay_log_2022_01、pay_log_2022_02
-
空間
-
地理位置:省份、區域(華東、華北、華南)
-
比如按照 省份 生成 庫或表
-
-
例如:自增id,根據ID範圍進行分表(左閉右開)
- 規則案例
- 1~1,000,000 是 table_1
- 1,000,000 ~2,000,000 是 table_2
- 2,000,000~3,000,000 是 table_3
- ...更多
- 優點
- id是自增長,可以無限增長
- 擴容不用遷移資料,容易理解和維護
- 缺點
- 大部分讀和寫都訪會問新的資料,有IO瓶頸,整體資源利用率低
- 資料傾斜嚴重,熱點資料過於集中,部分節點有瓶頸
基於Range範圍分庫分表業務場景
- 微博傳送記錄、微信訊息記錄、紀錄檔記錄,id增長/時間分割區都行
- 水平分表為主,水平分庫則容易造成資源的浪費
- 網站簽到等活動流水資料時間分割區最好
- 水平分表為主,水平分庫則容易造成資源的浪費
- 大區劃分(一二線城市和五六線城市活躍度不一樣,如果能避免熱點問題,即可選擇)
- saas業務水平分庫(華東、華南、華北等)
3.2Hash取模
hash取模(Hash分庫分表是最普遍的方案)
-
如果取模的欄位不是整數型要先hash,統一規則就行
-
案例規則
- 使用者ID是整數型的,要分2庫,每個庫表數量4表,一共8張表
- 使用者ID取模後,值是0到7的要平均分配到每張表
A庫ID = userId % 庫數量 2
表ID = userId / 庫數量 2 % 表數量4
- 優點
- 保證資料較均勻的分散落在不同的庫、表中,可以有效的避免熱點資料集中問題,
- 缺點
- 擴容不是很方便,需要資料遷移
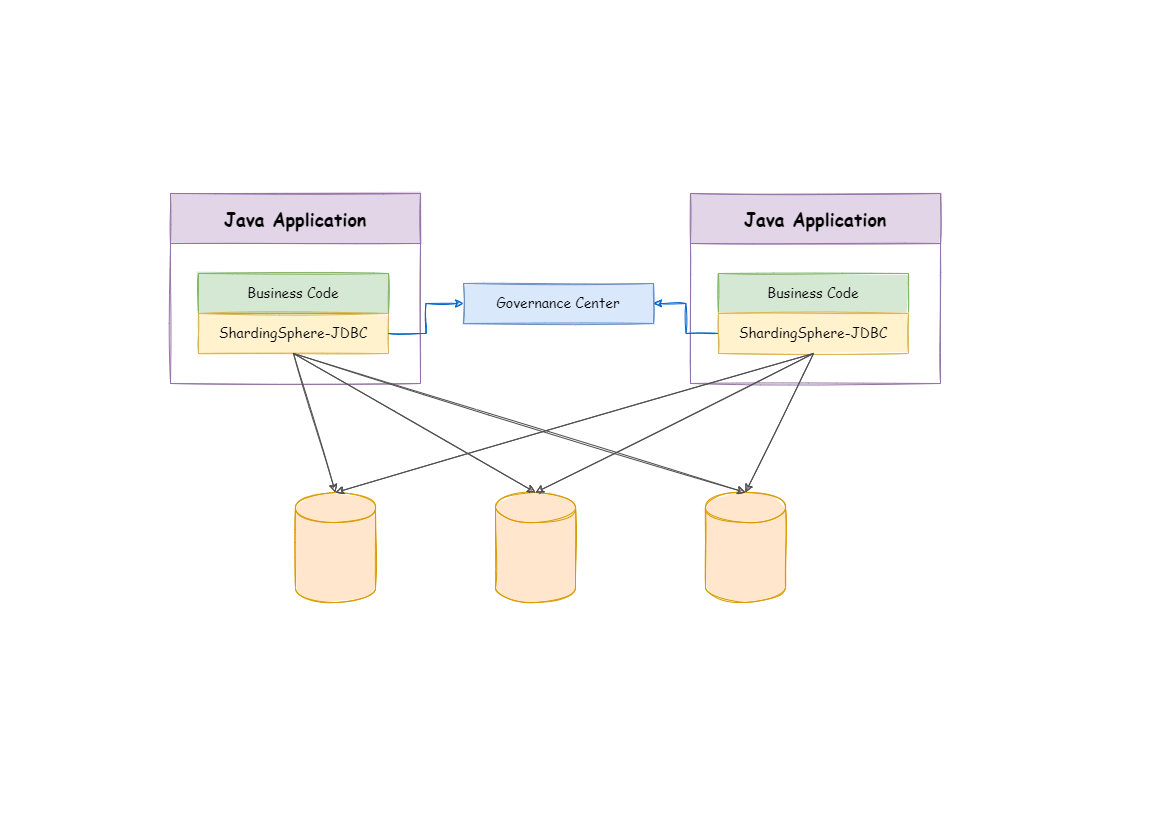
四、實現方案ShardingSphere-JDBC
-
Sharding-JDBC
-
基於jdbc驅動,不用額外的proxy,支援任意實現 JDBC 規範的資料庫
-
它使用使用者端直連資料庫,以 jar 包形式提供服務,無需額外部署和依賴
-
可理解為加強版的 JDBC 驅動,相容 JDBC 和各類 ORM 框架
-
-
它使用使用者端直連資料庫,以 jar 包形式提供服務
-
無需額外部署和依賴,可理解為增強版的 JDBC 驅動,完全相容 JDBC 和各種 ORM 框架
-
適用於任何基於 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis,或直接使用 JDBC
-
支援任何第三方的資料庫連線池,如:DBCP, C3P0, BoneCP, HikariCP 等;
-
支援任意實現 JDBC 規範的資料庫,目前支援 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 存取的資料庫
-
採用無中心化架構,與應用程式共用資源,適用於 Java 開發的高效能的輕量級 OLTP 應用
4.1常見概念術語講解
- 資料節點Node
- 資料分片的最小單元,由資料來源名稱和資料表組成
- 比如:ds_0.product_order_0
- 真實表
- 在分片的資料庫中真實存在的物理表
- 比如訂單表 product_order_0、product_order_1、product_order_2
- 邏輯表
- 水平拆分的資料庫(表)的相同邏輯和資料結構表的總稱
- 比如訂單表 product_order_0、product_order_1、product_order_2,邏輯表就是product_order
- 繫結表
- 指分片規則一致的主表和子表
- 比如product_order表和product_order_item表,均按照order_id分片,則此兩張表互為繫結表關係
- 繫結表之間的多表關聯查詢不會出現笛卡爾積關聯,關聯查詢效率將大大提升
- 廣播表
- 指所有的分片資料來源中都存在的表,表結構和表中的資料在每個資料庫中均完全一致
- 適用於資料量不大且需要與海量資料的表進行關聯查詢的場景
- 例如:字典表、設定表
4.2常見分片演演算法講解
分片演演算法包括兩部分:包含分片鍵和分片策略
-
分片鍵 (PartitionKey)
- 用於分片的資料庫欄位,是將資料庫(表)水平拆分的關鍵欄位
- 比如prouduct_order訂單表,根據訂單號 out_trade_no做雜湊取模,則out_trade_no是分片鍵
- 除了對單分片欄位的支援,ShardingSphere也支援根據多個欄位進行分片
-
分片策略
-
行表示式分片策略 InlineShardingStrategy(必備)
-
只支援【單分片鍵】使用Groovy的表示式,提供對SQL語句中的 =和IN 的分片操作支援
-
可以通過簡單的設定使用,無需自定義分片演演算法,從而避免繁瑣的Java程式碼開發
-
prouduct_order_$->{user_id % 8}` 表示訂單表根據user_id模8,而分成8張表,表名稱為`prouduct_order_0`到`prouduct_order_7
-
-
標準分片策略StandardShardingStrategy(需瞭解)
- 只支援【單分片鍵】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm兩個分片演演算法
- PreciseShardingAlgorithm 精準分片 是必選的,用於處理=和IN的分片
- RangeShardingAlgorithm 範圍分配 是可選的,用於處理BETWEEN AND分片
- 如果不設定RangeShardingAlgorithm,如果SQL中用了BETWEEN AND語法,則將按照全庫路由處理,效能下降
-
複合分片策略ComplexShardingStrategy(需瞭解)
- 支援【多分片鍵】,多分片鍵之間的關係複雜,由開發者自己實現,提供最大的靈活度
- 提供對SQL語句中的=, IN和BETWEEN AND的分片操作支援
-
Hint分片策略HintShardingStrategy(需瞭解)
-
這種分片策略無需設定分片健,分片健值也不再從 SQL中解析,外部手動指定分片健或分片庫,讓 SQL在指定的分庫、分表中執行
-
用於處理使用Hint行分片的場景,通過Hint而非SQL解析的方式分片的策略
-
Hint策略會繞過SQL解析的,對於這些比較複雜的需要分片的查詢,Hint分片策略效能可能會更好
-
-
不分片策略 NoneShardingStrategy(需瞭解)
- 不分片的策略。
-
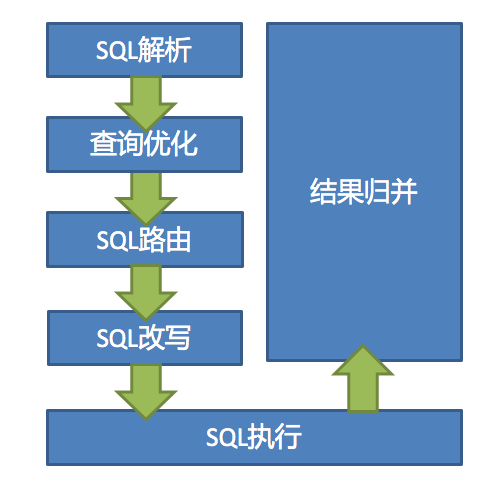
4.3執行流程原理
執行過程為:SQL解析 -> SQL優化 -> SQL路由 -> SQL改寫 -> SQL執行 -> 結果歸併 ->返回結果