再談快速的高斯模糊演演算法(使用多次均值濾波逼近和擴充套件的二項式濾波濾波器)及其優化。
關於高斯模糊,我在我早期的部落格里也有兩篇文章予以描述:
SSE影象演演算法優化系列二:高斯模糊演演算法的全面優化過程分享(一)。
SSE影象演演算法優化系列二:高斯模糊演演算法的全面優化過程分享(二)。
一個是遞迴的IIR濾波器,一個Deriche濾波器,他們的速度都已經是頂級的了,而且都能夠使用SIMD指令優化,其中有講到《Recursive implementation of the Gaussian filter》這個方法在半徑較大的時候會出現一定的瑕疵,核心原因是大半徑會導致其中的某些係數特別小,因此造成浮點精度的丟失,因此,要保證效果就必須在計算過程中使用double資料型別,而使用了double,普通的sse指令集的增速效果就不是很明顯了,因此,為了速度可能需要使用AVX或者更高的AVX512。
那麼這兩個都是從離散角度來說比較精確的演演算法,因為有了SIMD指令,使得他們在PC上即使有了大量的浮點計算,計算的速度也比較不錯。在一些特殊的情況或者特殊的硬體中,還是存在浮點計算非常慢的情況(比如FPGA),因此,還是有不上資料和文章提出了一些近似的演演算法來減少計算量,在celerychen分享的文章快速高斯濾鏡演演算法中,除了上述兩個演演算法外,還提到了均值濾波逼近高斯濾波以及 擴充套件二項式濾波逼近高斯濾波兩個方法。
一、Binomial Filter 二項式濾波濾波器
多年前我也看過這個文章,那個時候也沒有怎麼在意,最近在研究halcon的一些濾波器時,偶爾翻到其binomial_filter函數的說明時,突然看到其有如下的一些描述:
The binomial filter is a very good approximation of a Gaussian filter that can be implemented extremely efficiently using only integer operations. Hence, binomial_filter is very fast.
他說這個binomial filter只有整形的計算,因此速度非常快。
是不是這樣的呢,於是我在網路上搜尋這方面的資料,大部分都指向 extended binomial filter for Fast gaussian Blur這篇文章,可以參考道客巴巴里的這篇文章:https://www.doc88.com/p-1896883955048.html
這個文章寫得很詳細,有著非常豐富的數學推導和公式,還有很多漂亮的曲線,比如下面這個描述了不同的半徑r和不同的n階畢竟的精度。當n=3或者n=4時,也已經相當的準確了。特別是半徑比價大時(模糊程度)。
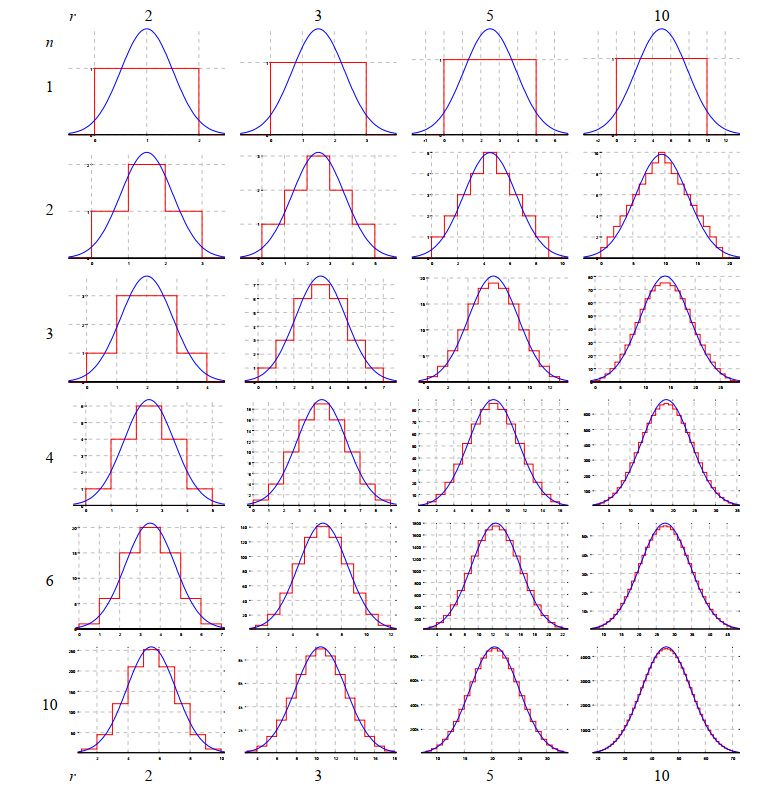
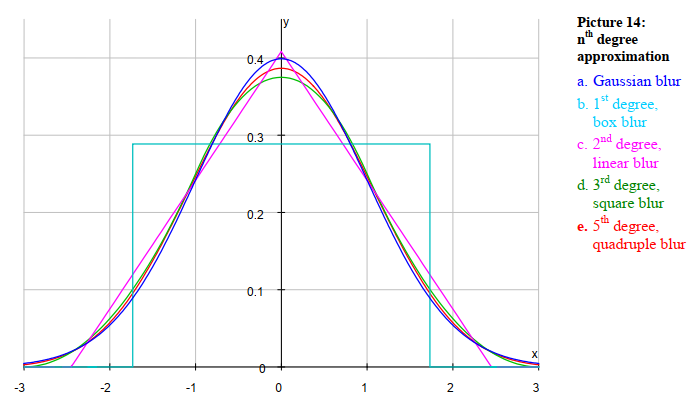
這個文章的末尾提供了相關的參考程式碼,但是那個參考程式碼有點凌亂,而且不知道是啥語言,好像是可以為PS寫外掛的指令碼一樣,不過大概還是能猜到是什麼意思。
celerychen在他的文章說裡面幾個重要的初始引數不知道如何確定,主要可能是指的scaleFactor,這個其實因該他做介面預覽時的一些縮放值,我們做演演算法時,他就是1。
另外,那個文章是比較早的了,作者提供的那個網站裡有提供最新的一批程式碼,詳細見:Efficient Gaussian Blur Algorithm
這個文章中提供的一個重要的計算公式即為:

其中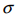 為使用者輸入的標準差,n為離散的階數,r為計算得到半徑,由上式我們可以推到出:
為使用者輸入的標準差,n為離散的階數,r為計算得到半徑,由上式我們可以推到出:
r = sqrtf(12.0 * Sigma * Sigma / n + 1)
注意,這裡得到的r應該是浮點數,但是浮點數,我們無法進行均值模糊,所以一般需要四捨五入取整。當然,如果要求精度的,那就要去上下兩個半徑值分別做處理後,在對結果進行插值。
這個公式在 均值濾波逼近高斯濾波 的文章裡也有提到。
我們從Efficient Gaussian Blur Algorithm 這個網站的相關連結裡可以有如下描述:
- gauss2.ffp: The program for the first degree approximation is a great improvement to the box blur. It is as easy to understand and has only slight approximation error.
- gauss3.ffp: The program for the second degree approximation is accurate enough for most applications.
- gauss4.ffp: The third degree approximation has nearly no difference to the Gaussian blur for 8-bit images apart of rounding errors
我想說的是gauss2.ffp其實是Third degree approximation對應的程式碼(n = 3),gauss3.ffp和gauss4.ffp都是Fourth degree approximation對應的程式碼(n=4),但是他們裡面的疊加順序寫法又有所不同(裡面的變數sum, deri1, deri2, diff疊加的順序),那麼真正的Second degree approximation文章裡沒有給連結,但是可以用在連結 http://members.chello.at/easyfilter/gauss1.ffp 裡開啟。感覺像是作者故意隱藏了一樣。
另外還要注意在論文裡的sum, deri1, deri2, diff和連結裡的順序也不太一樣。
為了方便大家測試,我從連結裡整理了一個可以執行的程式碼,很醜陋,但是確實效果和速度都還不錯。
int IM_BinomialFilter4_PureC_Gray_Raw(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Sigma)
{
int Channel = Stride / Width;
if ((Src == NULL) || (Dest == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE;
if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER;
if (Channel != 1) return IM_STATUS_NOTSUPPORTED;
int Status = IM_STATUS_OK;
Sigma = IM_Min(Sigma, 256); // 如果全部用整形的資料,半徑不能大於30, Sum和Deri用浮點半徑可以取得較大
int Radius = (int)(sqrtf(3.0 * Sigma * Sigma + 1) + 0.4999999f);
int Weight = Radius * Radius * Radius * Radius;
float InvWeight = 1.0f / Weight;
unsigned char *Buffer = (unsigned char *)malloc((IM_Max(Width, Height) + 4 * Radius) * sizeof(unsigned char));
unsigned char *Temp = (unsigned char *)malloc(Height * Stride * sizeof(unsigned char));
int *RowOffset = (int *)malloc((Width + 4 * Radius) * sizeof(int));
int *ColOffset = (int *)malloc((Height + 4 * Radius) * sizeof(int));
if ((Buffer == NULL) || (Temp == NULL) || (RowOffset == NULL) || (ColOffset == NULL))
{
Status = IM_STATUS_OUTOFMEMORY;
goto FreeMemory;
}
// 注意起點位置是偏移了一個1個畫素的
for (int X = 0; X < Width + 4 * Radius; X++)
RowOffset[X] = IM_GetMirrorPos(Width, X - 2 * Radius + 1);
for (int Y = 0; Y < Height + 4 * Radius; Y++)
ColOffset[Y] = IM_GetMirrorPos(Height, Y - 2 * Radius + 1);
for (int Y = 0; Y < Height; Y++) // horizontal blur...
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Temp + Y * Stride;
for (int X = 0; X < 2 * Radius - 1; X++)
Buffer[X] = LinePS[RowOffset[X]];
memcpy(Buffer + 2 * Radius - 1, LinePS, Width);
for (int X = 2 * Radius - 1 + Width; X < Width + 4 * Radius; X++)
Buffer[X] = LinePS[RowOffset[X]];
float Sum = 0, Deri1 = 0;
int Deri2 = 0, Diff = 0;
for (int X = -4 * Radius; X < 0; X++)
{
Sum += Deri1;
Deri1 += Deri2;
Deri2 += Diff; // accumulate pixel blur
Diff += Buffer[X + 4 * Radius];
if (X + 3 * Radius >= 0) Diff -= 4 * Buffer[X + 3 * Radius]; // -4,
if (X + 2 * Radius >= 0) Diff += 6 * Buffer[X + 2 * Radius]; // +6,
if (X + Radius >= 0) Diff -= 4 * Buffer[X + 1 * Radius]; // -4, (+1)}
}
for (int X = 0; X < Width; X++)
{
Sum += Deri1;
Deri1 += Deri2;
Deri2 += Diff;
Diff += Buffer[X] - 4 * Buffer[X + Radius] + 6 * Buffer[X + 2 * Radius] - 4 * Buffer[X + 3 * Radius] + Buffer[X + 4 * Radius]; //{+1, -4, +6, -4, +1}
LinePD[X] = (int)(Sum * InvWeight + 0.499999f);
//LinePD[X] = (Sum + Weight / 2) / Weight;
}
}
for (int X = 0; X < Width; X++) // Vertical Blur
{
unsigned char *LinePS = Temp + X;
unsigned char *LinePD = Dest + X;
for (int Y = 0; Y < 2 * Radius - 1; Y++)
Buffer[Y] = LinePS[ColOffset[Y] * Stride];
for (int Y = 0; Y < Height; Y++)
{
Buffer[Y + 2 * Radius - 1] = LinePS[Y * Stride];
}
for (int Y = 2 * Radius - 1 + Height; Y < Height + 4 * Radius; Y++)
Buffer[Y] = LinePS[ColOffset[Y] * Stride];
float Sum = 0, Deri1 = 0;
int Deri2 = 0, Diff = 0;
for (int Y = -4 * Radius; Y < 0; Y++)
{
Sum += Deri1;
Deri1 += Deri2;
Deri2 += Diff; // accumulate pixel blur
Diff += Buffer[Y + 4 * Radius];
if (Y + 3 * Radius >= 0) Diff -= 4 * Buffer[Y + 3 * Radius]; // -4,
if (Y + 2 * Radius >= 0) Diff += 6 * Buffer[Y + 2 * Radius]; // +6,
if (Y + Radius >= 0) Diff -= 4 * Buffer[Y + 1 * Radius]; // -4, (+1)}
}
for (int Y = 0; Y < Height; Y++)
{
Sum += Deri1;
Deri1 += Deri2;
Deri2 += Diff;
Diff += Buffer[Y] - 4 * Buffer[Y + Radius] + 6 * Buffer[Y + 2 * Radius] - 4 * Buffer[Y + 3 * Radius] + Buffer[Y + 4 * Radius]; //{+1, -4, +6, -4, +1}
LinePD[0] = (int)(Sum * InvWeight + 0.499999f);
//LinePD[0] = (Sum + Weight / 2) / Weight;
LinePD += Stride;
}
}
FreeMemory:
if (Buffer != NULL) free(Buffer);
if (Temp != NULL) free(Temp);
if (RowOffset != NULL) free(RowOffset);
if (ColOffset != NULL) free(ColOffset);
return Status;
}
注意這個是翻譯自gauss3.ffp的程式碼並做了適當的調整,我們看到程式還是使用了很多的浮點數的,否則當Sigma稍微大一點,結果就溢位了,當然,程式碼裡也給出瞭如果SIgma不大於30,則可以全部用整形實現。
我們處理了一副3000*2000的灰度圖,出乎意料的是,就這個很隨意的程式碼能獲得82毫秒的成績。
優化:
乍一看起來,Vertical Blur那一部分的程式碼存取記憶體的方式很不友好,有著大量的跨行存取記憶體的地方,確實原始的程式碼是有這個問題,但是這種模糊都有這個特性,在 高斯模糊演演算法的全面優化過程分享(一) 中我們探討過垂直方向處理演演算法一般不宜直接寫,而應該用一個臨時的行快取進行處理,這裡同樣可以用這個方法來處理,而且處理的程式碼還能通用各種不同的通道,這裡不多贅述。
Horizontal blur部分,看程式碼知道是存在著嚴重的畫素前後依賴的,這種特性非常不利於指令集優化,處理的方式呢,我在部落格里也多次提到,把多行(比如四行)合併到一行後,進行處理,這樣合併的一行裡就有連續4個畫素的處理是毫無關係的,就可以藉助於SSE之類的指令予以處理了,這部分方式可以參考我的博文: SSE影象演演算法優化系列五:超高速指數模糊演演算法的實現和優化(10000*10000在100ms左右實現)。
經過一番折騰呢,這個演演算法可以優化到13ms左右(4階),當然,這個程式碼明顯有個特性,隨著Sigma的增大,程式裡的邊緣部分的計算量也會增加,因此,演演算法的耗時和引數有一定的關係,但是不是特別明顯。
如果是使用的2階演演算法,則內部計算要更加的少,同樣的圖片大約在11ms左右可以處理完成,而原始的Deriche演演算法嘛,耗時大概在18ms上下。
2階的有個比較好的特性,就是他的全部的計算過程裡的累加量都在整形的有效範圍呢,因此確實可以用整形計算實現效果。
完成了這個演演算法後,回頭在去看Halcon的binomial_filter ,感覺味道又變了,本來以為他的那個MaskWidth和MaskHeight就是對應的水平和垂直方向的Sigma的,結果測試不是,他的結果在MaskWidth和MaskHeight很大時,模糊的程度也比較小。目前還搞不清楚是怎麼回事。
不過有一點,Halcon的這個運算元的速度那真叫一個牛逼,3000*2000的圖都只要幾豪秒(隨MaskWidth和MaskHegiht的增加耗時也在增加)。
二、使用多次均值模糊模擬高斯模糊
這個演演算法的參考文獻的正式名字應該是Fast Almost-Gaussian Filtering,而不是celerychen文章裡提的 Arbitrary Gaussian Filtering with 25 Addtions and 5 Multiplications per Pixel,那個文章里根本沒看到說25次加法和5次乘法。
這個文章的理論基礎其實也是這個公式:
英文的原文為:

他這裡給出了用均值模糊模擬高斯模糊的半徑的計算方式,即上圖中公式5,當給定均方差,給定均值模擬的次數,就可以計算出m。
在https://blog.ivank.net/fastest-gaussian-blur.html這裡作者給出了相關的簡易的範例程式碼,稍作整理如下所示:
// https://github.com/amazingyyc/fasted_gauss_blur // https://www.cnblogs.com/amazingyyc/p/4530634.html // https://www.doc88.com/p-1896883955048.html // 使用 N 個 BoxBlur 擬合 Sigma的高斯函數 // 參考:Arbitrary Gaussian Filtering with 25 Addtions and 5 Multiplications per Pixel.pdf // Fast Almost - Gaussian Filtering.pdf void IM_GetBoxRadiusForGauss(float Sigma, int *Size, int N) { float IdealW = sqrt(12.0 * Sigma * Sigma / N + 1.0); // 論文公式1 int LowerW = floor(IdealW); // 向下取整 if (LowerW % 2 == 0) LowerW--; // the first odd integer that is less than IdealW int UpperW = LowerW + 2; // the other being being the first odd integer greater than IdealW int M = round((12.0 * Sigma * Sigma - N * LowerW * LowerW - 4 * N * LowerW - 3 * N) / (-4 * LowerW - 4)); // 論文公式2 for (int Y = 0; Y < N; Y++) // Apply an averaging filter of width LowerW M times. Size[Y] = (Y < M ? LowerW : UpperW); // Apply an averaging filter of width UpperW N - M times. } int IM_FastGaussBlur(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Radius) { int Channel = Stride / Width; if ((Src == NULL) || (Dest == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER; if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_NOTSUPPORTED; int Status = IM_STATUS_OK; unsigned char *Temp = (unsigned char *)malloc(Height * Stride * sizeof(unsigned char)); if (Temp == NULL) { Status = IM_STATUS_OUTOFMEMORY; goto FreeMemory; } int BoxRadius[3]; // 使用3次均值模糊代替高斯 IM_GetBoxRadiusForGauss(Radius, BoxRadius, 3); // 計算擬合的半徑 Status = IM_BoxBlur(Src, Dest, Width, Height, Stride, (BoxRadius[0] - 1) / 2); if (Status != IM_STATUS_OK) goto FreeMemory; Status = IM_BoxBlur(Dest, Temp, Width, Height, Stride, (BoxRadius[1] - 1) / 2); if (Status != IM_STATUS_OK) goto FreeMemory; Status = IM_BoxBlur(Temp, Dest, Width, Height, Stride, (BoxRadius[2] - 1) / 2); if (Status != IM_STATUS_OK) goto FreeMemory; FreeMemory: if (Temp != NULL) free(Temp); return Status; }
可以看到,就是簡單的3次均值模糊,因為均值模糊可以高度的向量化程式設計,擁有特別特別快的速度,因此,也能獲得非常優異的效能。
三、效果比較
對標準的高斯模糊,二階二項式、4階二項式以及均值模糊模擬進行測試,發現他們在視覺上無特備明顯的差異。

可執行的DEMO下載地址為:https://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar?t=1660121429
如果想時刻關注本人的最新文章,也可關注公眾號:
