使用.NET簡單實現一個Redis的高效能克隆版(六)
譯者注
該原文是Ayende Rahien大佬業餘自己在使用C# 和 .NET構建一個簡單、高效能相容Redis協定的資料庫的經歷。
首先這個"Redis"是非常簡單的實現,但是他在優化這個簡單"Redis"路程很有趣,也能給我們在從事效能優化工作時帶來一些啟示。
原作者:Ayende Rahien
原連結:
https://ayende.com/blog/197569-B/high-performance-net-building-a-redis-clone-skipping-strings
另外Ayende大佬是.NET開源的高效能多正規化資料庫RavenDB所在公司的CTO,不排除這些文章是為了以後會在RavenDB上相容Redis協定做的嘗試。大家也可以多多支援,下方給出了連結
RavenDB地址:https://github.com/ravendb/ravendb
構建Redis克隆版-字串處理
我克隆版Redis目前程式碼中高成本的地方就是字串的處理,下面的分析器圖表實際上有一些誤導:
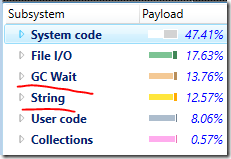
字串佔用了執行時的12.57%的時間,另外就是GC Wait, 我們需要清理掉這些開銷。這意味著我們之前寫的程式碼是非常低效的。
我們的測試場景現在也只涉及 GET 和 SET 請求,沒有刪除、過期等。我提到這一點是因為我們正在考慮用什麼來替換字串。
最簡單的選擇是用位元組陣列替換它,但它仍然是託管記憶體,並且會產生與 GC 相關的成本。我們可以池化這些位元組陣列,但是我們還有一個重要的問題要回答,我們如何知道什麼時候不再使用池化的陣列,也就是說,什麼什麼把它歸還到池中?
考慮以下一組事件流程:

在上面的例子中,執行緒2存取了值緩衝區,但是在Time-3中我們使用SET abc命令替換了原來的資料,導致執行緒2存取的不再是原來的資料。
我們需要找一個方法,將值緩衝區保留到沒有任何物件參照它的時候,另外在銷燬它時我們要將它歸還到池中。
我們可以通過手動管理記憶體的方式來實現這個,這是很可怕的。實際上我們可以使用一些不同的方式,比如利用GC來達到我們的目的。
public class ReusableBuffer
{
public byte[] Buffer;
public int Length;
public Span<byte> Span => new Span<byte>(Buffer, 0, Length);
public ReusableBuffer(byte[] buffer, int length)
{
Buffer = buffer;
Length = length;
}
public override bool Equals(object? obj)
{
if (obj is not ReusableBuffer o)
return false;
return o.Span.SequenceEqual(Span);
}
public override int GetHashCode()
{
var hc = new HashCode();
hc.AddBytes(Span);
return hc.ToHashCode();
}
// 關鍵是這裡,宣告一個解構函式
// 當GC需要釋放它的時候會呼叫
~ReusableBuffer()
{
ArrayPool<byte>.Shared.Return(Buffer);
}
}
想法很簡單。我們有一個持有緩衝區的類,當 GC 注意到它不再被使用時,它將把它的緩衝區歸還到池中。這個想法是我們依靠 GC 來為我們解決這個(真正困難的)問題。雖然這會將一些成本轉移到終端子,但是目前來說我們不必擔心這個問題。不然,你就得經歷很多困難來編寫手動管理記憶體的程式碼。
ReusableBuffer類還實現了GetHashCode()/Equals(),它允許我們將其用作字典中的Key。
現在我們有了鍵和值的後臺儲存,讓我們看看如何從網路讀寫。現在我將回到 ConcurrentDictionary 實現,一次只處理一個事情。
以前,我們使用 StreamReader/StreamWriter 來完成工作,現在我們將使用 System.IO.Pipelines 中的 PipeReader/PipeWriter。這將使我們能夠輕鬆地直接處理原始位元組資料,並且這是為高效能場景設計的。
我編寫了兩次程式碼,一次使用可重用的緩衝區模型,一次使用 PipeReader/PipeWriter 並分配字串。我驚訝地發現,我的可重用緩衝區的效能差距只有字串實現的1% (簡單得多)。順便說一句,那是1%的錯誤方向。
在我的機器上,基於可重用的緩衝區是16.5w/s,而基於字串的系統是每秒16.6w/s。
下面是基於可重用緩衝區的完整方法原始碼。比較一下,這是基於字串的。基於字串的程式碼行比基於字串的程式碼行短50%左右。
- 基於可重用緩衝區:https://gist.github.com/ayende/f6263d5ddd331a7f8263ef892b45f526
- 基於字串:https://gist.github.com/ayende/bc52b3cbdb6d5ebd8fa00ac5d014a876
我猜測是因為我們這個場景的分配模式非常適合GC所做的那種啟發式處理。我們要麼有長期物件(在快取中),麼有非常短期的物件。
值得指出的是,網路中命令的實際解析並不使用字串。只有實際的鍵和值實際上被轉換為字串。其餘部分使用原始位元組資料。
下面是對字串版本的程式碼進行分析的結果:
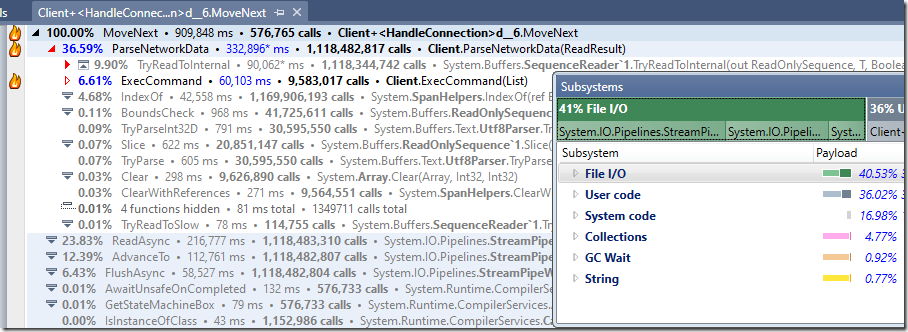
使用可重用緩衝區也如下所示:
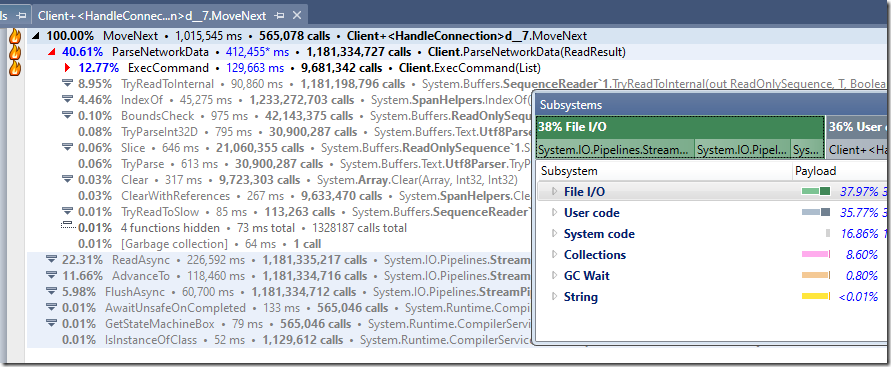
這裡有一些有趣的事情值得注意。ExecCommand 的成本幾乎是基於字串版本嘗試的兩倍。深入挖掘,我相信錯誤就在這裡:
var buffer = ArrayPool<byte>.Shared.Rent((int)cmds[2].Length);
cmds[2].CopyTo(buffer);
var val = new ReusableBuffer(buffer, (int)cmds[2].Length);
Item newItem;
ReusableBuffer key;
if (_state.TryGetValue(_reusable, out var item))
{
// can reuse key buffer
newItem = new Item(item.Key, val);
key = item.Key;
}
else
{
var keyBuffer = ArrayPool<byte>.Shared.Rent((int)cmds[1].Length);
cmds[1].CopyTo(keyBuffer);
key = new ReusableBuffer(keyBuffer, (int)cmds[1].Length);
newItem = new Item(key, val);
}
_state[key] = newItem;
WriteMissing();
這段程式碼負責在字典中設定項。但是,請注意,我們正在對每個寫操作執行讀操作?這裡的想法是,如果我們現在_state中已經存在了這個值,那麼我們就避免再次為它分配緩衝區,而是重用它。
但是,這段程式碼處於這個基準測試的關鍵路徑中,代價相當高昂。我修改了這段程式碼,不再重用,總是new物件進行分配,我們得到了一個比字串版本快1~3%的版本。這看起來是這樣的:
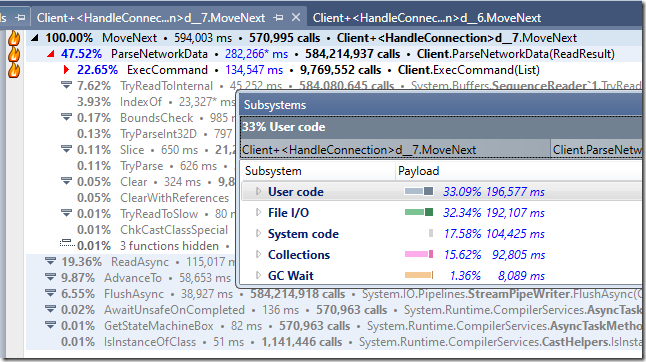
換句話說,這是當前每次操作對應的效能表(在探查器下):
- 1.57 ms - 基於字串
- 1.79 ms - 基於可重用緩衝區(減少記憶體使用量)
- 1.04 ms - 基於可重用緩衝區(優化查詢)
得出的那些結果都在我計算機使用分析器執行的。讓我們看看當我在生產範例上執行它們時,最終的結果是怎麼樣的?
- 基於字串 – 16.0w次/秒
- 可重用緩衝區(減少記憶體程式碼)– 18.6w次/秒
- 可重用緩衝區(優化查詢)– 17.5w次/秒
這些結果與我們在開發機器中看到的結果並不匹配。可能的原因是並行和請求數量足夠高,負載足夠大,以至於我們看到大規模記憶體優化的效果要好很多。
這是我能得出的唯一結論,減少分配記憶體,能夠在這樣的高負載場景下處理更多的請求。
系列連結
使用.NET簡單實現一個Redis的高效能克隆版(一)
使用.NET簡單實現一個Redis的高效能克隆版(二)
使用.NET簡單實現一個Redis的高效能克隆版(三)
使用.NET簡單實現一個Redis的高效能克隆版(四、五)