巨量資料應用開發流程
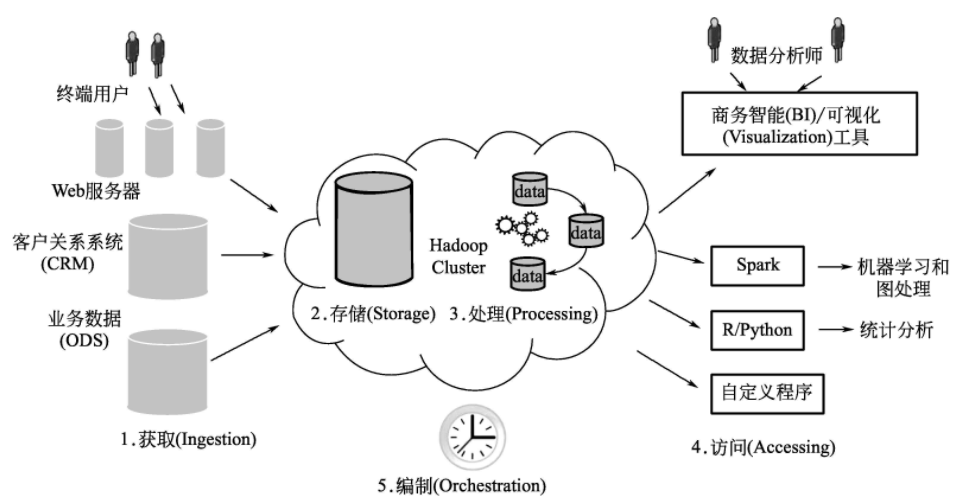
通過點選流分析來介紹巨量資料應用開發流程中的每一步如何實現。在點選流分析的例子中,利用分散式檔案系統(GFS)來儲存資料,通過Flume 獲取ingestion網站紀錄檔檔案及其他輔助資料並匯入到分散式系統中。同時,利用Spark 來處理資料,通過連線商業智慧工具,分散式系統互動地進行資料處理查詢,並利用工具將操作過程編製成單一的工作流程。
(1)巨量資料獲取
有多種獲取資料並匯入至巨量資料管理系統的方法:
①檔案傳輸∶此方法適合一次性傳輸檔案,對於本任務面臨可靠的大規模點選流資料獲取,將不適用。
②Sqoop∶ Sqoop 是Hadoop 生態系統提供的將關係型資料管理系統等外部資料匯入巨量資料管理系統的工具。
③Kafka∶ Kafka的架構用於將大規模的紀錄檔檔案可靠地從網路伺服器傳輸到分散式系統中。
④Flume∶Flume工具和Kafka類似,也能可靠地將大量資料(如紀錄檔檔案)傳輸至分散式系統中。Kafka和Flume都適用於獲取紀錄檔資料,都可以提供可靠的、可延伸的紀錄檔資料獲取。
(2)巨量資料儲存
在資料處理的每個步驟中,包括初始資料、資料變換的中間結果及最終的資料集都需要儲存。由於每一個資料處理步驟的資料集都有不同的目的,選擇資料儲存的時候要確保資料的形式及模型和資料相匹配。
原始資料的儲存是將文字格式的資料儲存到分散式系統中。分散式系統具有以下一些優點:
①在序列資料處理過程中,需要通過多條記錄來進行批次處理轉換;
②分散式系統可以高效率地通過批次處理,處理大規模資料。
(3)巨量資料處理
使用Flume獲取點選流資料,網路伺服器上的原始資料在分析前需要進行清洗。例如,需要移除無效和空缺的紀錄檔資料、需要刪除這些重複資料。清洗完資料後,還要將資料進行統一ID編號,在處理資料前需要對點選資料做進一步的處理和分析,包括對資料以每天或每小時為單位進行彙總,這能更快地進行之後的查詢操作。事實上,對資料進行預處理是為了之後能高效地進行查詢操作。巨量資料處理需要經歷以下四步:
①資料淨化清理原始資料。
②資料抽取∶從原始點選資料流中提取出需要的資料。
③資料轉換∶對提取後的資料進行轉換,以便之後產生處理後的資料集。
④資料儲存∶儲存在分散式檔案系統中的資料支援高效能查詢方式。
(4)巨量資料分析
資料經過獲取和處理後,將通過分析資料來獲得想要了解的知識及答案。商業分析師通過以下幾個工具來探索和分析資料:
①視覺化(visualization)和商業智慧工具(BI),例如Tableau和MicroStrategy.
②統計分析工具,例如R或Python。
③基於機器學習的高階分析,例如Mahout和Spark MLlib。
④SQL。
(5)巨量資料編制
資料分析經常臨時性的需要,需要進行自動化編制。編制點選流分析的步驟如下:
首先,在獲取資料階段,通過Flume將資料連續傳輸到分散式系統中。
其次, 在資料處理階段, 因為在一天結束時終止所有連線是常見的, 故採用每天執行對談演演算法。在開始處理工作資料流前,驗證Flume寫入分散式系統的當天資料。這種同步驗證方式是常見的,因為通過簡單地檢視當前日期分割區的情況,可以校驗當前日期資料是否開始寫入巨量資料管理系統。