畢昇編譯器優化:Lazy Code Motion
摘要:本文中,我們將介紹通過程式碼移動(插入)的方式消除冗餘計算的一個典型方法。
本文分享自華為雲社群《編譯器優化那些事兒(3):Lazy Code Motion》,作者:畢昇小助手。
導語
本文中,我們將介紹通過程式碼移動(插入)的方式消除冗餘計算的一個典型方法。
下圖給出的簡要程式流圖中, ①是我們想要優化的程式碼,②和③是優化後的程式碼,讓我們先思考下面幾個問題:
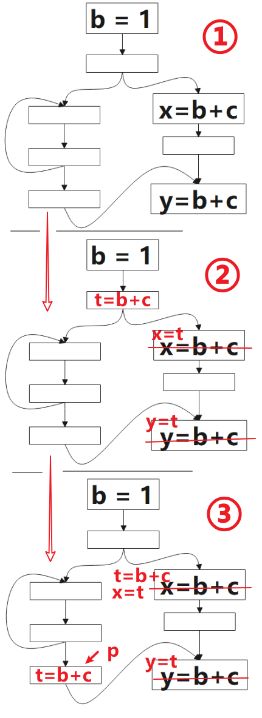
- ②和③哪個優化效果更好一點?
③ 更好一點,相比 ② 暫存器生存週期更短
- ③這種情況,在 p 點直接插入 t=b+c 會帶來安全或效能問題嗎? 會改變程式的行為嗎?
這裡不會引入冗餘的計算,也沒有改變程式行為。但如果 p 是下文介紹的 非預期的 點,我們就需要使用在 臨界邊上增加合成塊的方式避免這個問題了。
- 能否由編譯器來完成一個演演算法,找到一個通用的、尋找到合適的插入點的方法以消除冗餘計算?
這是本文要介紹的內容,我們會在下面演演算法章節引入四個定義,為程式在各個點上打上標籤,通過這些點的集合之間的運算,得到插入點的集合。
0.1 開始之前
介紹演演算法之前,我們來看三個在寫應用層程式碼時可能會遇到的問題。
(1)我們可以把計算移動到不會重複計算的路徑嗎?
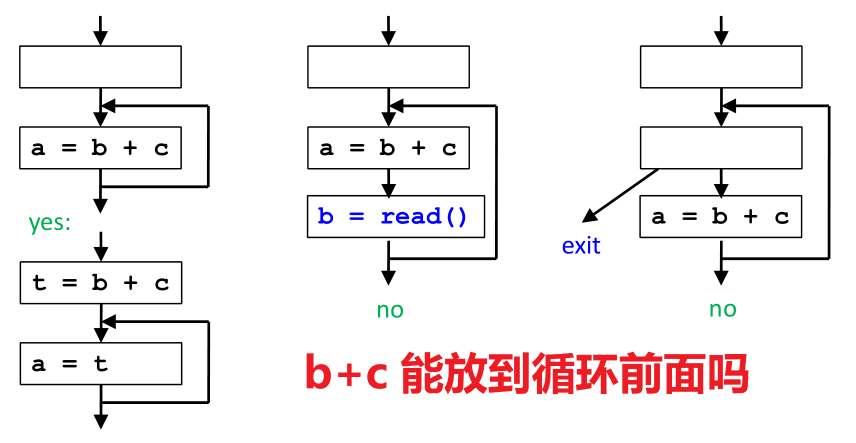
答案已在圖中給出:
- 左邊例子是可以的。這也是下文演演算法要找的情景。當然實際應用程式中會更復雜,以致我們不能明顯看出或不經意間引入冗餘的計算,比如 《Lazy code motion》1 裡給出的例子。
- 中間不可以,因為 b 被重新定義了,所以 a = b + c 不是冗餘計算了。
- 右邊不可以,因為 a = b + c 可能一次也沒執行,移動到迴圈前可能會改變程式的行為。
(2)左圖到右圖的變化有優化效果嗎
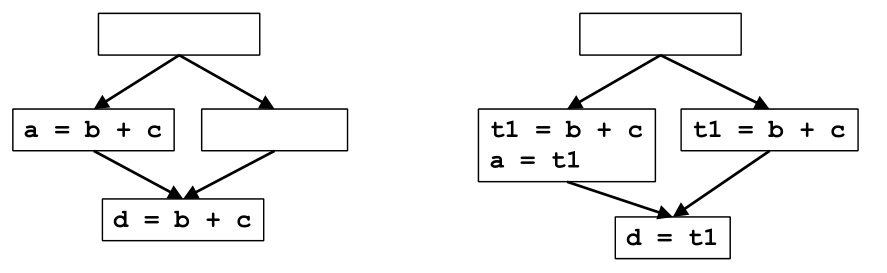
有的,這也是下面演演算法中要尋找的情景,左邊的路徑消除了一次冗餘計算,右邊為了保持程式正確性插入了一個計算,但並沒有引入冗餘的計算,所以總體是有優化的.
(3)下圖中,能否在 block d 的父項 p 上插入表示式 t=b+c:
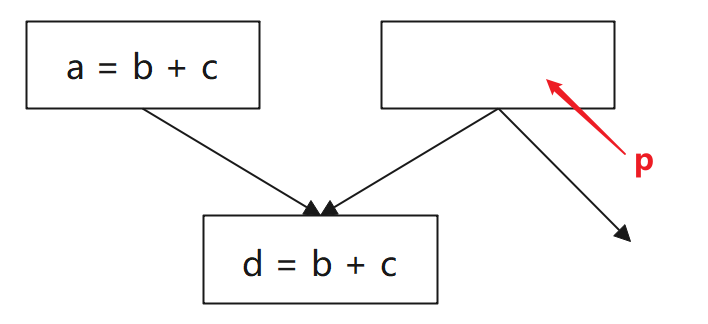
不能,因為插入不能改變程式的行為: 這裡 t=b+c 可能難以看出問題,但如果表示式換成 b/c (c==0) 或 b^c 就能明顯的看到造成了執行問題或效能問題。
解決方法:可在 臨界邊(Critical Edge)上增加 合成塊(Synthetic Block)。
0.2 臨界邊(Critical Edge)的定義
定義:源基本塊有多個後繼,目標基本塊有多個前驅,連線它們的邊就叫臨界邊(Critical Edge)。
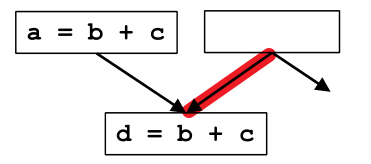
臨界邊如上圖紅色部分所示。
打破臨界邊(Critical Edge)的辦法: 增加合成塊(Synthetic Block)
步驟:
- 為每個指向擁有多個前置的基本塊新增一個基本塊(不僅僅是在 臨界邊 上)。
- 為了保持演演算法簡單,將每個語句視為其自己的基本塊,並將指令的放置限制在基本塊的開頭。
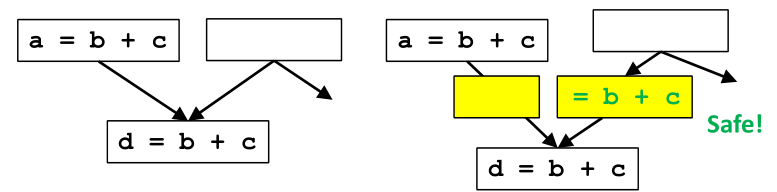
上圖中我們插入了兩個合成塊,其中一個是多餘的,但不用擔心,我們可以在最後消除它。
1、演演算法
上文中,我們介紹了一個可以放心插入表示式而不會引入安全問題的方法,下面我們將正式介紹導語中提到的演演算法。
部分冗餘消除演演算法要儘可能延遲計算, 這也是標題中 lazy 的含義。
程式流程圖如下:
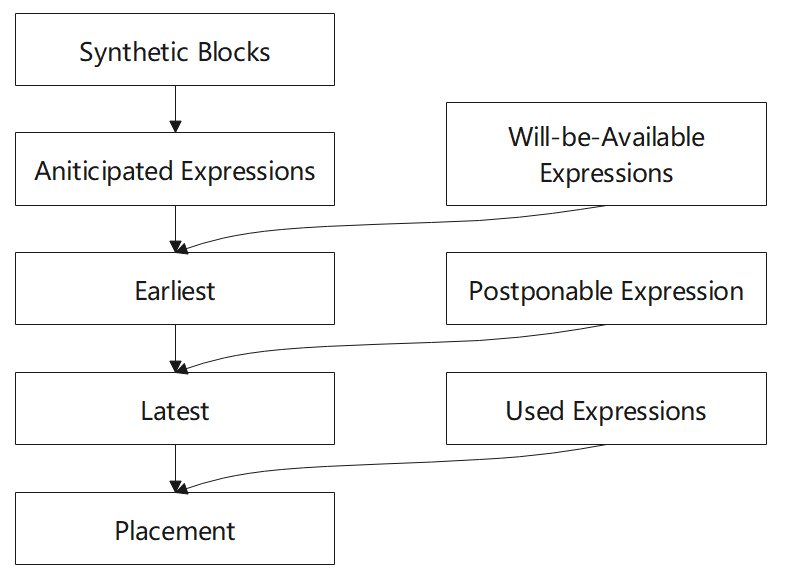
演演算法步驟:
- 首先計算預期表示式(Anticipated)集合
- 計算將可用的表示式(Will-be-Available)集合
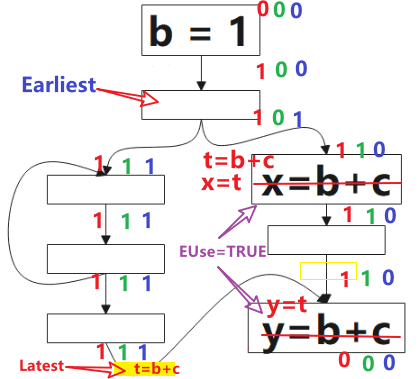
- 從 AVAIL 和 ANT ,我們為每個表示式計算出最早的插入位置(Earliest)集合,這最大限度地消除了冗餘,但可能會增大暫存器生存期
- 再計算延遲表示式(Postponable)集合
- 經過上面的計算,引入 Latest 的定義,計算最晚插入的點的集合,實現與 earliest 相同數量的冗餘消除,但縮短了儲存表示式值的暫存器的生存期
- 計算使用表示式(Used)
- 計算最後的插入位置的集合,替換冗餘表示式
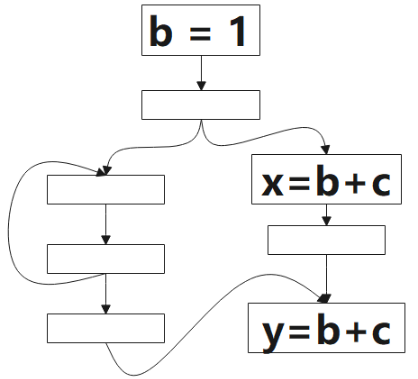
我們會以下圖為例,說明整個計算過程。根據以往的經驗,下面給出的幾個公式,必須結合圖例去理解,文字無法闡述清楚準確定義。
1.1 預期表示式(Anticipated)
Anticipated:An expression is said to be anticipated at program point if all paths leading from eventually computes (from the values of ’s operands that are available at ).
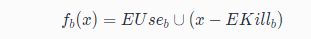
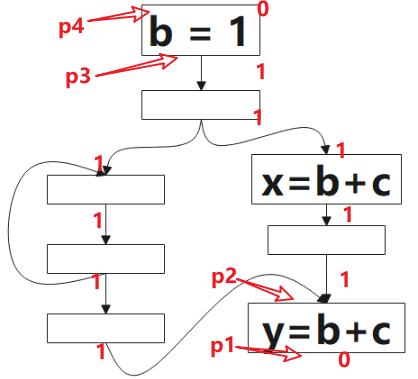
預期表示式(Anticipated)的分析方向為後向(backword)。
圖示說明:
1 表示該點是可預期的(Anticipated),0 表示不是。 該演演算法的方向是 後向(backword)的,對應到圖中,我們要從 p1 開始判斷:對於表示式 b+c 而言,p1 是非預期的,因為到該點為止,沒有 b+c 的計算,繼續往上,看到了 b+c 的計算,所以 p2 點是可預期的(Anticipated),這情況一直持續到 p3,到 p4,由於該點看到了 b=1,b 被重新定義了,就是公式裡被 Kill 的表示式,所以 p4 點不是可預期的(Anticipated)點。
1.2 將可用的表示式(Will-be-Available)
Will-be-available:An expression is said to be will-be-available at program point if it is anticipated and not subsequently killed along all paths reaching .
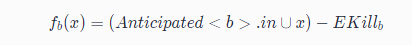
將可用的表示式(Will-be-Available)的分析方向為前向(forward)。
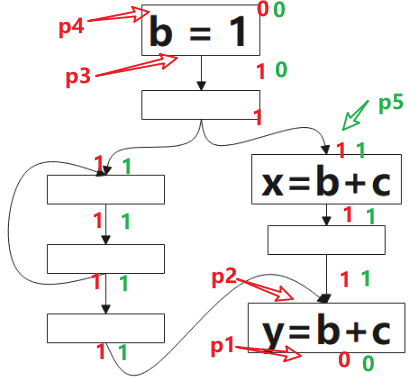
圖中綠色的 1 表示表示式 b+c 該點是將可用的(Will-be-Available),0 表示不是。該演演算法方向是前向的,就是分析時,我們從 p4 開始看,根據公式的定義,該點不是可預期的(Anticipated),也沒有計算表示式 b+c,所以該點不是將可用的(Will-be-Available),p3 雖然是可預期的(Anticipated),但因為 b=1 ,所以 p3 點對錶示式 b+c 來說是 Ekillp ,所以該點仍不是將可用的,p5 點是可預期的(Anticipated),且該點沒有 kill 的操作,該點是將可用的(Will-be-Available),後續的點類似。
接下來可以通過以下公式進行最早插入點的計算:
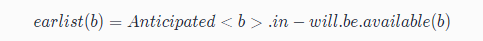
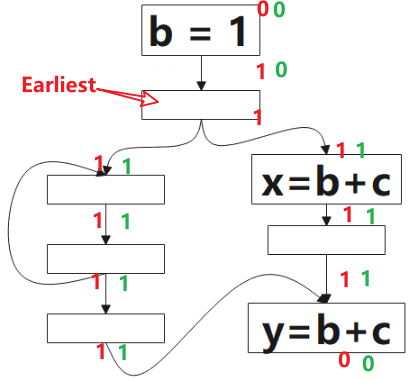
根據公式,最早可插入的點的集合是 可預期點的(Anticipated)集合(圖中紅色1部分) 減去 將可用點的(Will-be-Available)集合,得到圖中標記的點。
目前為止我們已經找了一種通用的消除重複計算的方法,就是在上圖中標註 Earliest 的點插入表示式 t=b+c, 然後在後面所有用到 b+c 的地方替換成 t,但這樣做會帶來一個問題,就是暫存器的生存期會很長。通過下一小節引入的定義,我們可以解決這個暫存器生存期的問題。
1.3 延緩表示式(Postponable)
An expression is said to be postponable at program point if all paths leading to have seen earliest placement of but not a subsequent use.
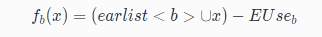
延緩表示式(Postponable)的分析方向為前向(forward)。
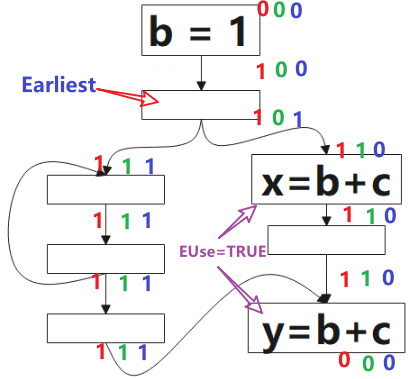
延遲建立冗餘計算表示式可以減少暫存器壓力:從公式看,Postponable點一定是在 Earliest 點的後面的,更接近表示式要被替換的地方,就是說,從表示式第一次被計算的點(結果在暫存器)到該結果被複用的點距離更近。
對於該圖的講解,可以參考 YouTube2 中的講解。
接下來可以通過以下公式進行最晚插入點(Latest)的計算:
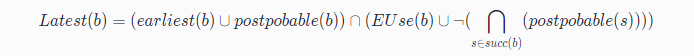
- 先在 Earliest 與 postpobable 集合的並集位置放置表示式 e 。
- 對上一步的點進行篩選,需要滿足:表示式 e 在 b 點(隨後的基本塊)被Use 或 它不是上一步點的後繼。
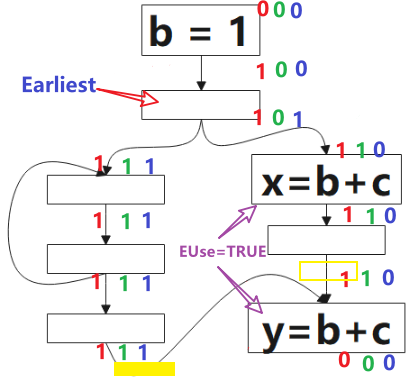
這裡插入的點(圖中黃色方塊)是增加的合成塊,是出於安全性的考慮。
1.4 已用表示式(Used Expressions)
An expression is said to be used at program point if there exists a path leading from that uses the expression before the operands are reevaluated.
已用表示式(Used Expressions)的分析方向為後向(backword)。
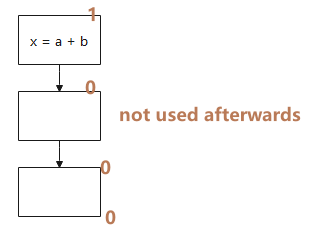
如圖所示,從下往上看,未使用的點標記為0,直到使用的地方被標記為1。
引入這個定義主要是為了消除當前塊之外未使用的臨時變數賦值,計算方式: Used.out: sets of used (live) expressions at exit of b.

2、最終的解決方案
對所有的基本塊/表示式 b,如果表示式屬於最晚插入點的集合與已用點位置的交集,
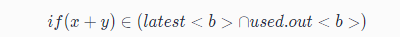
則在基本塊b的開頭,先建立 t = a + b,然後把所有的 x+y 替換為 t。
目前為止演演算法的介紹部分就已經全部講完了,但是有些定義還是比較模糊,需要結合程式碼才能講清楚, 大家可以翻看LLVM 原始碼3中關於該程式碼的具體實現: MachineCSE 類與 NaryReassociatePass 等類的實現。
參考
1. https://dl.acm.org/doi/abs/10.1145/143095.143136
2. https://www.youtube.com/watch?v=3s4oST3oZzQ&t=20s
3. https://github.com/llvm/llvm-project