正規表示式實戰:最新豆瓣top250爬蟲超詳細教學
檢查網頁原始碼
首先讓我們來檢查豆瓣top250的原始碼,一切網頁爬蟲都需要從這裡開始。F12開啟開發者模式,在元素(element)頁面通過Ctrl+F直接搜尋你想要爬取的內容,然後就可以開始編寫正規表示式了。
如下是我們將要爬取內容的html區域性區域:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100">
匹配正規表示式
<em class="">1</em>這顯然是‘索引’可以用於匹配‘序號’
相應正規表示式為:
<em class="">(\d+)</em>
其中\d+的含義是匹配1個及以上的數位
正規表示式詳解請看:正規表示式完整入門教學,含線上練習
正規表示式速查表請看:正規表示式速查表
<a href="https://movie.douban.com/subject/1292052/">這個表示的是標題對應的超連結,也就是對應電影的詳情頁,如果我們要做進一步的內容爬取,這個連結也是值得儲存的。
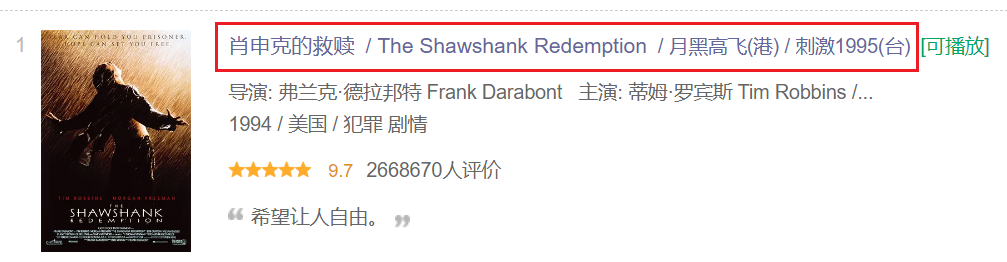
這裡介紹一下re.S引數,它可以讓我們跨行匹配正規表示式。而且我們知道,正規表示式越詳細,匹配的精確度就越高,於是我們可以將上下兩行一起匹配。
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
相應的正規表示式為:
'<em class="">(\d+)</em>.*?<a href="(.*?)">.*?'
然後我來解釋下為什麼我們要加括號(),這是因為,有的時候我們想要的不是每一個存在變化的變數,它們僅僅需要作為萬用字元來使用,於是我們將需要返回的匹配值加上括號作為返回值,未加括號的正規表示式匹配的值不會被返回。上面的.*?就是不會被返回的正規表示式。
接下來看看我們的完整正規表示式吧:
pattern = re.compile(
'<em class="">(\d+)</em>.*?<a href="(.*?)">.*?' +
'<img width="100" alt=".*?" src="(.*?)" class=""' +
'>.*?<span class="title">(.*?)</span>.*?<span ' +
'class="other"> / (.*?)</span>.*?<div ' +
'class="bd">.*?<p class="">.*?導演: (.*?) .*?<br>' +
'.*?(\d{4}) / (.*?) / (.*?)\n' +
'.*?</p>.*?<span class="rating_num" property="v:' +
'average">(.*?)</span>',
re.S)
正規表示式中.表示任意字元;*表示前置字元任意次數;?表示前置字元可有可無。
這個+號,即是常用的連線字串的用法。我們可以發現,上述表示式一共有10個括號(),也就是說最終會在一個item中返回10個值,以列表(陣列)形式。
- 正則中沒有括號時,返回的是 list,list的元素是 str ;
- 正則中有括號時,返回的是 list,list的元素是
tuple ,tuple 中的各項對應的是括號中的匹配結果;
下面我們來認識一下re的幾個庫函數:
-
re.compile 是預編譯正規表示式函數,是用來優化正則的,它將正規表示式轉化為物件
-
re.compile 函數用於編譯正規表示式,生成一個 Pattern 物件,pattern 是一個字串形式的正規表示式
-
pattern 是一個匹配物件( Regular Expression),它單獨使用就沒有任何意義,需要和findall(), search(), match()搭配使用。
-
使用re.S引數以後,正規表示式會將這個字串作為一個整體,將「\n」當做一個普通的字元加入到這個字串中,在整體中進行匹配,而不是在一行內進行匹配。
-
re.findall返回string中所有與pattern相匹配的全部字串,返回形式為陣列
現在我們通過re.compile獲得了正規表示式物件,我們就可以直接使用這個pattern對html進行內容匹配了。
items = re.findall(pattern, html)
然後儲存為python字典:
for item in items:
yield {
'index': item[0],
'page_src': item[1],
'img_src': item[2],
'title': item[3],
'other_title': item[4],
'director': item[5],
'release_date': item[6],
'country': item[7],
'type': item[8],
'rate': item[9],
}
完整程式碼
匯入包
# json包
import json
#正規表示式包
import re
import requests
from requests import RequestException
定義獲取html函數
#函數:獲取一頁html
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# Response物件返回包含了整個伺服器的資源
# Response物件的屬性,有以下幾種
# r.status_code: HTTP請求的返回狀態,200表示連線成功,404表示失敗
# 2.r.text: HTTP響應內容的字串形式,即,url對應的頁面內容
# 3.r.encoding:從HTTP header中猜測的響應內容編碼方式
# 4.r.apparent_encoding:從內容中分析出的響應內容編碼方式(備選編碼方式)
# 5.r.content: HTTP響應內容的二進位制形式
response = requests.get(url, headers=headers, timeout=1000)
if response.status_code == 200:
return response.text
except requests.exceptions.RequestException as e:
print(e)
定義解析html函數【正則】
#函數:解析一頁html
def parse_one_page(html):
pattern = re.compile(
'<em class="">(\d+)</em>.*?<a href="(.*?)">.*?' +
'<img width="100" alt=".*?" src="(.*?)" class=""' +
'>.*?<span class="title">(.*?)</span>.*?<span ' +
'class="other"> / (.*?)</span>.*?<div ' +
'class="bd">.*?<p class="">.*?導演: (.*?) .*?<br>' +
'.*?(\d{4}) / (.*?) / (.*?)\n' +
'.*?</p>.*?<span class="rating_num" property="v:' +
'average">(.*?)</span>',
re.S)
#使用re.S引數以後,正規表示式會將這個字串作為一個整體,將「\n」當做一個普通的字元加入到這個字串中,在整體中進行匹配,而不是在一行內進行匹配。
#re.findall返回string中所有與pattern相匹配的全部字串,返回形式為陣列
#上述pattern正好有10個括號
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'page_src': item[1],
'img_src': item[2],
'title': item[3],
'other_title': item[4],
'director': item[5],
'release_date': item[6],
'country': item[7],
'type': item[8],
'rate': item[9],
}
定義儲存內容函數
#函數:將內容寫入檔案
def write_to_file(content):
with open('douban_movie_rankings.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
定義主函數
#主控函數
def main():
#用於翻頁
for offset in range(10):
#獲取網址
url = f'https://movie.douban.com/top250?start={offset * 25}&filter='
#獲取html檔案
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
定義魔法函數
if __name__ == '__main__':
main()
原創作者:孤飛-部落格園
原文連結:https://www.cnblogs.com/ranxi169/p/16565717.html