論文解讀(soft-mask GNN)《Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks》
論文資訊
論文標題:Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks
論文作者:Mingqi Yang, Yanming Shen, Heng Qi, Baocai Yin
論文來源:2021, WWW
論文地址:download
論文程式碼:download
1 Abstract
GNN 應該能夠有效地提取與任務相關的結構,並且對無關的部分保持不變。
本文提出的解決方法:從原始圖的子圖序列中學習圖的表示,以更好地捕獲與任務相關的子結構或層次結構,並跳過噪聲部分。
該論文建議看看程式碼,論文寫的令人疑惑......(程式碼簡單)
2 Introduction
訊息傳遞機制的回顧:
$\begin{aligned}h_{\mathcal{N}(i)}^{(l+1)} &=\text { aggregate }\left(\left\{h_{j}^{l}, \forall j \in \mathcal{N}(i)\right\}\right) \\h_{i}^{(l+1)} &=\sigma\left(W \cdot \operatorname{concat}\left(h_{i}^{l}, h_{\mathcal{N}(i)}^{+1}\right)\right) \\h_{i}^{(l+1)} &=\operatorname{norm}\left(h_{i}^{(l+1)}\right)\end{aligned}$
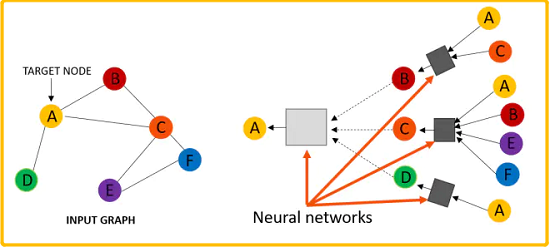
訊息傳遞機制的問題:
-
- 所有節點在更新表示的時候,共用著一樣的權重;
- 與任務相關的結構資訊很可能與不相關(或噪聲)部分混合,使得下游處理無法區分,特別是對於深度模型[4,17,22]中更高層捕獲的長期依賴;
直觀的解決方法是:區分不同的圖拓撲結構,希望有用的結構資訊將被保留並傳遞到更高的層次進行進一步處理。例如:GIN [32]、[5, 18, 19]。
對於具有層次結構的圖,GNNs 應該以分層的方式對它們進行編碼,一個高度為 $2$的層次圖的簡單例子,如 Figure 1 (a) 所示:
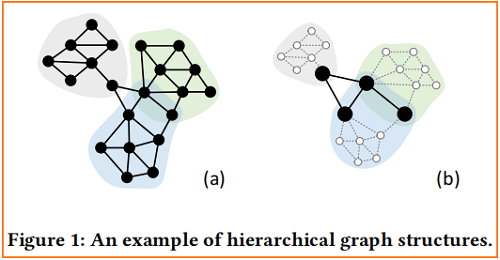
Figure 1(b) 表明,在本圖中,節點可以分為兩組:
-
- Leaf node. Nodes only have connections within each part such as white nodes in Figure 1(b);
- Root node. Nodes have connections with other parts or shared with other parts such as black nodes in Figure 1(b);
底層使用 leaf node 進行子圖學習,高層使用 Root node 進行層次表示學習。
根據以上分析,從一組子圖序列中學習圖表示實際上統一了子圖表示學習和層次表示學習。要實現這一目標,主要面臨兩個挑戰:
-
- 如何在保持可微性的同時有效地表示每一層中的任何隨機子圖?
- 如何決定由模型學習到的子圖的序列?
兩類現有工作:
-
- GAM [16] 通過表示一個包含從原始圖中取樣的固定長度的節點序列的圖來提取所需的子結構;
- Top-k graph pooling [7,14,15] 對每個節點的重要性進行評分,並逐層刪除低評分節點和相關邊;
這些策略可以動態地關注資訊部分,使神經網路在處理噪聲圖時更加魯棒。然而,GAM 要求取樣的節點序列具有固定的長度,而 top-k 池需要一個固定的下降比,這限制可能是用任意尺度表示所需的子圖的障礙。
本文提出的 soft-mask GNN,它通過控制節點掩碼來提取任何大小的子圖。然後將尋找所需子圖的問題轉化為尋找適當的掩模分配。
2 Graph Neural Networks
在形式上,GNN 的第 $k$ 層為:
$\mathbf{h}_{v}^{(k)}=\operatorname{Update}\left(\mathbf{h}_{v}^{(k-1)}, \operatorname{Aggregate}\left(\left\{\left\{\mathbf{h}_{u}^{(k-1)} \mid u \in \mathcal{N}(v)\right\}\right\}\right)\right) \quad\quad\quad(1)$
最後一層的節點嵌入矩陣可以直接用於節點分類,而對於圖分類需要進一步做 Readout 處理:
$\mathbf{h}_{G}=\operatorname{Readout}\left(\left\{\left\{\mathbf{h}_{v}^{(K)} \mid v \in V_{G}\right\}\right\}\right)\quad\quad\quad(2)$
最後將 $\mathbf{h}_{G}$ 傳遞給一個分類器進行圖分類。
在 $\text{Eq.1}$ 中,$Aggregate(.)$ 用於聚合鄰居的表示以生成當前節點表示,在 $\text{Eq.2}$ 中 $Readout(.)$,用於聚合所有節點表示,以生成整個圖表示。為了使 GNN 對圖的同構不變,$Aggregate(.)$ 和 $Readout(.)$ 應該是排列不變的。同時,$\text{Eq.1}$ 和$\text{Eq.2}$ 應該是可微的,以使網路可以通過反向傳播進行訓練。
3 Soft-mask GNN
在本節中,首先介紹SMG層,並解釋如何通過控制掩碼分配來提取所需的子圖。然後,展示多層 SMG 如何分別學習具有相應子圖序列的子圖的表示和層次表示。還提出了一種計算掩模分配的方法,它可以通過反向傳播自動提取子結構或層次結構。最後,將SMG推廣到多通道場景中。
3.1 Sparse Aggregation and Subgraph Representation Learning
GNN 操作被看作是一種平滑操作 [4,17,22],其中每個節點與其相鄰節點交換特徵資訊。這種方案不會明確地跳過不相關的部分。相反,我們的 SMG 層提取的子結構如下:
$\mathbf{h}_{v}^{(k)}=\operatorname{ReLU}\left(\mathbf{W}_{1}^{(k)} m_{v}^{(k)}\left[\mathbf{h}_{v}^{(k-1)} \| \sum\limits _{u \in \mathcal{N}(v)} m_{u}^{(k)} \mathbf{h}_{u}^{(k-1)}\right]\right) \quad\quad\quad(2)$
其中 $m_{v}^{(k)} \in[0,1]$ 為節點 $v$ 在第 $k$ 層的 soft-mask,$||$ 表示連線操作,$\mathbf{W}_{1}^{(k)} \in \mathrm{R}^{d \times d}$ 為可訓練矩陣,其中 $d$ 為節點表示的維數。$m_{v}^{(k)}$ 的計算將在第 3.3 節中介紹。SMG 圖層應滿足以下約束條件:
- 線性變換 $\mathrm{W}_{1}^{(k)}$ 不包括常數部分(即 bias);
- 啟用函數(ReLU)滿足 $\sigma(0)=0$;
- 聚合運運算元(SUM)為 zero invariant;
Zero invariant. The aggregation function $f:\left\{\left\{\mathbb{R}^{m}\right\}\right\} \rightarrow \mathbb{R}^{n}$ is zero invariant if and only if
$f(\mathcal{S})=\left\{\begin{array}{ll}0 & \mathcal{S}=\emptyset \\f(\mathcal{S} /\{\mathbf{0}\}) & \text { otherwise }\end{array}\right.$
其中,$\mathcal{S}$ 是一個向量的多集。注意,SUM算符是 zero invariant,而 MEAN 不是。
有了上述限制,
-
- 對於中心節點 $v$ ,設定 $m_{v}^{(k)}=0$ ,有 $\mathbf{h}_{v}^{(k)}=0$ ;
- 對於 $v$ 的鄰域 $u \in \mathcal{N}(v)$,有 $\mathbf{h}_{u}^{(k)}=\operatorname{ReLU}\left(\mathbf{W}_{1}^{(k)} m_{u}^{(k)}\left[\mathbf{h}_{u}^{(k-1)} \| \sum_{u^{\prime} \in \mathcal{N}(u) /\{v\}} m_{u^{\prime}}^{(k)} \mathbf{h}_{u^{\prime}}^{(k-1)}\right]\right)$;
即節點 $v$ 對其鄰居是不可存取的。因此,對於任何 $G$ 的子圖 $G_{S}$,一層 SMG 和一個 zero invariant Readout 函數可以表示子圖 $G_{S}$。並且可以跳過其他部分,通過控制 mask 分配:
$ \begin{array}{l}&\mathbf{h}_{G}|_{ m_{v}^{(1)}=1, v \in V_{G_{S}} ; m_{v}^{(1)}=0, v \in V_{G} / V_{G_{S}} }\\&=\sum\limits_{v \in V_{G_{S}}} \mathbf{h}_{v}^{(1)}+\sum\limits_{v \in V_{G} / V_{G_{S}}} \mathbf{h}_{v}^{(1)} \\&=\sum\limits_{v \in V_{G_{S}}} \operatorname{ReLU}\left(\mathbf{W}_{1}^{(1)}\left[\mathbf{x}_{v} \| \sum\limits_{u \in \mathcal{N}_{G_{S}}(v)} \mathbf{x}_{u}\right]\right)+\mathbf{0} \\&=\left.\mathbf{h}_{G_{S}}\right|_{m_{v}^{(1)}=1, v \in V_{G_{S}}} .\end{array}$
Note:根據上述公式 ,知要求子圖 $G_{S}$ 的表示,設定 $m_{u}=1$ 。
它消除了一般 GNNs 的限制,即在所有節點上進行聚合,因此我們稱之為 sparse aggregation。所選的子圖包括具有 $mask=1$ 和相關邊的所有節點。
在多層SMG中
不管在多層 SMG 或者單層SMG 中均滿足:為學習同一個子圖 $G_{S}$ 的子圖表示,設定 $m_{v}^{(k)}=1$ for all $v \in V_{G_{S}}$ 、$m_{u}^{(k)}=0$ for all $u \in V_{G} / V_{G_{S}}$ in all layers.
不同的子圖所對應的 mask 序列是不一樣的。
然而,並不是所有分配在不同層中的節點上的掩碼都對最終的表示有影響,而且某些層中的掩碼可以取任意值。由於不同的掩碼導致不同的子圖序列,這意味著所需的子圖表示可能對應於不同的子圖序列。
在多層 SMG 中,具有 $m_{u}^{(k)}=0$ 的節點實際上不會被刪除。以下各層中的 GNN 操作也會涉及到它們。為了表示子圖 $G_{S}$,一個基本思想是通過為 $v \in V_{G_{S}}$ 分配 $m_{v}^{(k)}=1$,併為$u \in V_{G} / V_{G_{S}}$ 分配 $m_{u}^{(k)}=0$ ,來限制在同一子圖 $G_{S}$ 上學習。
這對應於一個所有子圖都相同的特定子圖的序列。然而,並不是所有分配在不同層中的節點上的掩碼都對最終的表示有影響,而且某些層中的掩碼可以取任意值。由於不同的掩碼導致不同的子圖序列,這意味著所需的子圖表示可能對應於不同的子圖序列。為了解釋這個問題,我們使用 $\mathbf{H}_{G}^{(k)}=\left\{\left\{\mathbf{h}_{v}^{(k)} \mid v \in V_{G}\right\}\right\}=\mathrm{SMG}_{k}\left(\mathbf{X}_{G}, \mathbf{A}_{G}, \mathbf{M}\right)$ 去代表表示由 $k$ 層 SMG 學習到的節點表示集,其中輸入的 $\mathbf{M} \in[0,1]^{k \times n}$ 是在所有 $k$ 層上預先分配的掩碼,使用 $\mathbf{M}_{k, v}=m_{v}^{(k)}$ 。$M$ 定義了一個長度為 $k$ 的子圖序列。$\hat{\mathbf{H}}_{G}^{(k)}=\left\{\left\{\hat{\mathbf{h}}_{v}^{(k)} \mid v \in V_{G}\right\}\right\}=\operatorname{SMG}_{k}\left(\mathbf{X}_{G}, \mathbf{A}_{G}, 1\right) $ 是由 k-layer SMG與$\mathbf{M}=1^{k \times n}$ 學習到的節點表示集,以及相應的 $\hat{\mathbf{h}}_{v}^{(k)}=\operatorname{ReLU}\left(\mathbf{W}_{1}^{(k)}\left[\hat{\mathbf{h}}_{v}^{(k-1)} \| \sum_{u \in \mathcal{N}(v)} \hat{\mathbf{h}}_{u}^{(k-1)}\right]\right)$ 。
Lemma 3.1. For any subgraph $G_{S}$ of $G$ , Let $\mathbf{H}_{G}^{(K)}=\left\{\left\{\mathbf{h}_{v}^{(k)} \mid v \in\right.\right. \left.\left.V_{G}\right\}\right\}$ and $\hat{\mathbf{H}}_{G_{S}}^{(K)}=\left\{\left\{\hat{\mathbf{h}}_{v}^{(k)} \mid v \in V_{G_{S}}\right\}\right\}$ . Then we have $\mathbf{h}_{v}^{(K)}=\hat{\mathbf{h}}_{v}^{(K)}$ for any $v \in V_{G_{S}}$ , if the following condition holds,
$\mathbf{M}_{k, v}=m_{v}^{(k)}=\left\{\begin{array}{ll}0 & \{v\} \subseteq V_{G} / V_{G_{S}} \\& \wedge \mathcal{N}_{G}(v) \cap V_{G_{S}} \neq \emptyset \\& \wedge k \% 2=1 \\1 & \{v\} \subseteq V_{G_{S}} \wedge\{k\} \subseteq[K]\end{array}\right.$
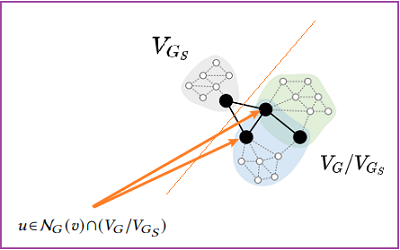
證明:

$\mathbf{h}_{u}^{(k-1)}=0$ 由於 $\mathbf{h}_{u}^{(k)}=\operatorname{ReLU}\left(\mathbf{W}_{1}^{(k)} m_{u}^{(k)}\left[\mathbf{h}_{u}^{(k-1)} \| \sum_{u^{\prime} \in \mathcal{N}(u) /\{v\}} m_{u^{\prime}}^{(k)} \mathbf{h}_{u^{\prime}}^{(k-1)}\right]\right)$
Theorem 3.2. Let $\mathbf{h}_{G}=S U M\left(\mathbf{H}_{G}^{(K)}\right)$ and $\hat{\mathbf{h}}_{G_{S}}=S U M\left(\hat{\mathbf{H}}_{G_{S}}^{(K)}\right)$ , where $G_{S}$ can be any subgraph of $G$ . Then there exist assignments of $\mathbf{M}$ such that $\mathbf{h}_{G}=\hat{\mathbf{h}}_{G_{S}}$ .
證明:

Lemma 3.1 和 Theorem 3.2 表明,子圖的表示對應於一組 $M$,所以可以將尋找子圖的問題轉化為尋找合適的 $M$。
3.2 Hierarchical Representation Learning
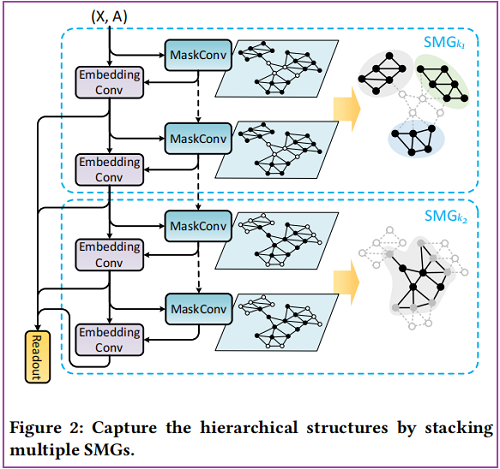
如 Figure 1(a)所示的層次圖由每個單獨的部分及其相互作用組成。同時,每個部分由幾個較小部分的互動組成,使圖結構識別遞迴。為了捕獲層次結構,神經網路應該首先單獨編碼每個區域性部分,然後編碼它們的相互作用。從節點的角度來看,首先聚合葉節點,然後考慮根節點。這對應於堆疊多個SMGs,其中每個 $\mathrm{SMG}_{k_{i}}$ 學習子圖 $G_{S_{i}}$ 的節點表示,輸入節點特徵是由之前的 $\mathrm{GNN}_{k_{i-1}}$ 學習到的節點表示。在第 $i$ 層的 $\mathrm{GNN}_{k_{i}}$ 中,$\mathbf{H}_{G}^{\star}=\mathrm{SMG}_{k_{i}}\left(\mathrm{H}_{G}^{\star-k_{i}}, \mathbf{A}_{G}, \mathbf{M}_{G_{S_{i}}}\right)$,其中 $\mathbf{M}_{G_{S_{i}}}$ 是 Lemma 3.1 對應於 $G_{S_{i}}$ 的賦值,$k_{i}$ 是 $\mathrm{SMG}_{k_{i}}$ 的層數。在第一步中,$\mathbf{H}_{G}^{0}=\mathbf{X}_{G}$ 。
我們用 Figure 1 中的層次圖範例來解釋這個過程。其層次結構的特點是由三個獨立的部分及其相互作用組成。我們使用 $2$ 層的 SMGs 學習這個圖表,如 Figure 2 所示。根據 Lemma 3.1 的觀察,$\mathrm{SMG}_{k_{1}}$ 學習到的表示對應於只涉及子圖1的葉節點,導致學習到的節點表示被限制在相應的部分內。此外,$\mathrm{SMG}_{k_{2}}$ 學習到的表示對應於子圖2中的由根節點(黑色)和葉節點(灰色)組成的,它們捕獲每個部分以及它們的相互作用。一致地,要擴充套件到高度大於 $2$ 的層次圖,需要在特定子圖上學習的每個疊加更多的 SMGs 。低水平的不同部分的相互作用被較低的 SMGs捕獲,而高水平的相互作用被較高的 SMGs 捕獲。
我們已經展示瞭如何通過將多個 SMGs 疊加到每個 SMGs 對應於一個子圖中來捕獲層次結構,如 Lemma 3.1中所分析的那樣。這是假設我們是瞭解圖的層次結構的。然而,層次結構並不是一種先驗的知識,應該由神經網路本身來捕獲。多虧了
$\begin{aligned}\mathbf{H}_{G}^{(K)}=& \mathrm{SMG}_{k_{L}}\left(\mathbf{H}_{G}^{\left(K-k_{L}\right)}, \mathbf{A}_{G}, \mathbf{M}_{G_{S_{L}}}\right) \\=& \mathrm{SMG}_{k_{L}}(\mathrm { SMG } _ { k _ { L - 1 } } (\ldots \mathrm{SMG}_{k_{1}}(\mathbf{X}_{G}, \mathbf{A}_{G}, \mathbf{M}_{G_{S_{1}}}),&\left.\left.\mathbf{A}_{G}, \mathbf{M}_{G_{S_{L-1}}}\right), \mathbf{A}_{G}, \mathbf{M}_{G_{S_{L}}}\right) \\=& \mathrm{SMG}_{K}\left(\mathbf{X}_{G}, \mathbf{A}_{G}, \prod\limits _{i=1}^{L} \mathbf{M}_{G_{S_{i}}}\right) \\=& \mathrm{SMG}_{K}\left(\mathbf{X}_{G}, \mathbf{A}_{G}, \mathbf{M}_{G}\right)\end{aligned}$
這意味著任何需要的堆疊 L 層的 SMGs 都等同於相同數量的 SMG 層,具有掩碼分配 $ \mathbf{M}_{G}=\|_{i=1}^{L} \mathbf{M}_{G_{S_{i}}}$。我們可以通過適當的 $\mathbf{M}_{G}$ 分配獲得所需的堆疊L SMGs。然後,將捕獲層次結構的問題轉換為尋找 $\mathbf{M}_{G}$ 的分配。
$\mathbf{M}_{G}$ 的靈活性使 SMG 能夠提取更豐富的結構資訊,而不僅僅是一般的基於密集聚合的 GNNs。我們已經證明了單層 SMG 只能捕獲子圖,而多層 SMG 可以捕獲圖的層次結構。當 $L>1$ 和 $G_{S_{i}}$ 被限制為 $G_{S_{i-1}}$ 的一個子圖時,所有 $i \in[L-1]$,SMG的工作方式類似於基於 top-k 的圖池[3,7,14,15],它迭代地一層一層地刪除一些節點和相關的邊。但是,圖1中所示的不同部分的互動不能被這種方案捕獲,因為以前跳過的下層節點不會涉及到更高的層中。
3.3 Mask Assignments Computations
下述講述使用 $\mathrm{GNN}-w$ 學習 $\mathbf{M}_{G}$ 的分配,第 $k$ 層中節點 $v$ 的值為:
$\begin{aligned}\mathbf{M}_{\mathbf{G} k, v}=& m_{v}^{(k)} \\=& \operatorname{MLP}^{(k)}(\operatorname { R e L U } ([\mathbf{L}_{1}^{(k)}(m_{v}^{(k-1)} \mathbf{h}_{v}^{(k-1)}) \|\sum_{u \in \mathcal{N}(v)} \mathbf{L}_{2}^{(k)}(m_{u}^{(k-1)} \mathbf{h}_{u}^{(k-1)})]))\end{aligned}\quad\quad\quad\quad(4)$
其中,$\mathbf{L}_{1}^{(k)}$ 和 $\mathbf{L}_{2}^{(k)}$ 為仿射對映【實際上程式碼並沒有體現】;$\sum\limits _{u \in \mathcal{N}(v)} \mathbf{L}_{2}^{(k)}\left(m_{u}^{(k-1)} \mathbf{h}_{u}^{(k-1)}\right)$ 其實就是一個訊息傳遞(採用 ''add'' 作為 aggragation),且第一次輸入的特徵矩陣並不是原始特徵,而是經線性對映的特徵,注意此處訊息聚合並沒有加上自環。
具體看程式碼:
class WeightConv1(MessagePassing):
def __init__(self, in_channels, hid_channels, out_channels=1, aggr='add', bias=True,
**kwargs):
super(WeightConv1, self).__init__(aggr=aggr, **kwargs)
self.lin1 = torch.nn.Linear(in_channels, hid_channels, bias=bias) #[128,128]
self.lin2 = torch.nn.Linear(in_channels, hid_channels, bias=bias) #[128,128]
self.lin3 = torch.nn.Linear(hid_channels * 2, hid_channels, bias=bias) #[256,128]
self.lin4 = torch.nn.Linear(hid_channels, out_channels, bias=bias) # [128,128]
def forward(self, x, edge_index, mask=None, edge_weight=None, size=None):
edge_index, _ = remove_self_loops(edge_index)
if mask is not None:
x = x * mask
h = self.lin1(x)
return self.propagate(edge_index, size=size, x=x, h=h,edge_weight=edge_weight)
def message(self, h_j, edge_weight): #edge_weight = None
print("in message")
return h_j if edge_weight is None else edge_weight.view(-1, 1) * h_j
def update(self, aggr_out, x):
print("in update")
weight = torch.cat([aggr_out, self.lin2(x)], dim=-1)
weight = F.relu(weight)
weight = self.lin3(weight)
weight = F.relu(weight)
weight = self.lin4(weight)
weight = torch.sigmoid(weight) #mask.shape = [Batch_N, 128])
return weight
Note:上述 $\mathbf{L}_{1}^{(k)}$ 和 $\mathbf{L}_{2}^{(k)}$ 以及 MLP 中的常數部分(即 bias )是被需要的,否則 $m_{v}^{(k-1)} \mathbf{h}_{v}^{(k-1)}=\mathbf{0}$ 和 $m_{u}^{(k-1)} \mathbf{h}_{u}^{(k-1)}=\mathbf{0}$,並且 $m_{v}^{(k)}$ 將長期固定為 $0.5$ 。
每個節點上的 $m_{v}^{(k)}$ 值 是從 $0$ 到 $1$ ,並不是像預期的離散值 $0$ 或 $1$ 。在 SMG 圖層中,對於 $i \in \hat{\mathcal{N}}(v)$ 的 $m_{i}^{(k)} \in[0,1]$ 有 $\mathbf{h}_{v}^{(k)}=f\left(\left\{m_{i}^{(k)} \mid i \in \hat{\mathcal{N}}(v)\right\}\right)=\operatorname{ReLU}\left(\mathbf{W}_{1}^{(k)} m_{v}^{(k)}\left[\mathbf{h}_{v}^{(k-1)} \|\right.\right. \left.\left.\sum_{u \in \mathcal{N}(v)} m_{u}^{(k)} \mathbf{h}_{u}^{(k-1)}\right]\right)$ 。因此對於 $i \in \hat{\mathcal{N}}(v)$,我們有 $\lim _{m_{i}^{(k)} \rightarrow 0^{+}} f\left(m_{i}^{(k)}, \ldots\right)=f(0, \ldots) $ 和 $\lim _{m_{i}^{(k)} \rightarrow 1^{-}} f\left(m_{i}^{(k)}, \ldots\right)=f(1, \ldots)$,使它有可能被使用 $m_{v}^{(k)}$ 去近似於掩碼值 $0$ 或 $1$。
soft-mask 的好處是考慮到了權重。由於 $\mathbf{h}_{v}^{(k)}$ 表示一個基於 $v$ 的 k-hop子樹,該子樹捕獲了基於 $v$ 的區域性 k-hop 子結構的結構資訊,$m_{v}^{(k)}$ 與 $\mathbf{h}_{v}^{(k)}$ 相乘給出了以下聚合操作的子結構的權重。對於權值為 $0$ 的節點,相當於刪除邊。為了保持 zero invariant,使用 SUM 作為 Readout 函數。並在最後一層使用跳躍連線:
$\mathbf{h}_{G}=\|_{k=1}^{K}\left(\sum\limits _{i=1}^{N} \mathbf{h}_{i}^{(k)}\right) \quad\quad\quad(5)$
Equation 5 利用來自不同層的節點表示來計算整個圖表示 $\mathbf{h}_{G}$。由於第 $k$ 層 $\mathbf{h}_{v}^{(k)}$ 中的節點表示用權重 $m_{v}^{(k)}$ 編碼 k-hop子結構,當實現讀出函數作為 Equation 5 時,$\mathbf{h}_{v}^{(k)}$ 的所有子結構都考慮了不同跳躍的權重。
3.4 Multi-channel Soft-mask GNN Model
將 soft-mask 改成多通道使得 $m_{v}^{(k)} \in(0,1)^{d}$ 【特徵級】,SMG層(Equation 3)被改寫為:
$\begin{aligned}\mathbf{h}_{v}^{(k)}=& \operatorname{ReLU}(m _ { v } ^ { ( k ) } \odot \mathbf { W } _ { 2 } ^ { ( k ) } [\mathbf{h}_{v}^{(k-1)} \|\sum\limits _{u \in \mathcal{N}(v)} m_{u}^{(k)} \odot \mathbf{h}_{u}^{(k-1)}])\end{aligned} \quad\quad\quad(6)$
4 Experiments
Graph Classification Task
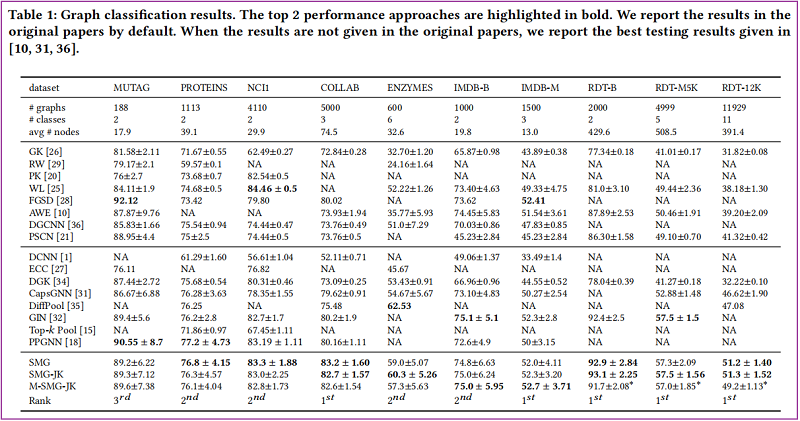
Graph Regression Task
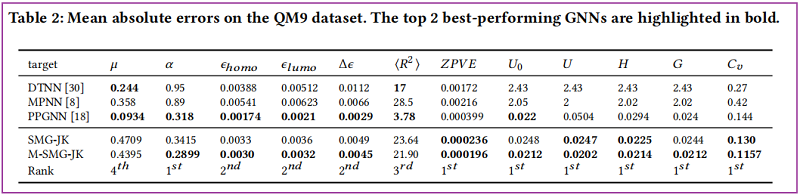
5 Conclusion
通過有效地跳過圖的不相關部分,我們提出了軟掩模GNN(SMG)層,它從一系列子圖序列中學習圖的表示。我們展示了它顯式地提取所需的子結構或層次結構的能力。在基準圖分類和圖迴歸資料集上的實驗結果表明,SMG獲得了顯著的改進,掩模的視覺化提供了模型學習到的結構的可解釋性。
==========
因上求緣,果上努力~~~~ 作者:關注我更新論文解讀,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16558913.html