[演演算法1-排序](.NET原始碼學習)& LINQ & Lambda
[演演算法1-排序](.NET原始碼學習)& LINQ & Lambda
說起排序演演算法,在日常實際開發中我們基本不在意這些事情,有API不用不是沒事找事嘛。但必要的基礎還是需要了解掌握。
排序的目的是為了讓無序的資料,變得「有序」。此處的有序指的是,滿足當前使用需求的順序,除了自帶的API,我們還可以自定義比較器物件、使用LINQ語句、Lambda表示式等方式完成排序。本文將逐一介紹十大排序,並著重介紹分析基於C#的LINQ常用語句和Lambda表示式,二者對排序的實現。
【# 請先閱讀注意事項】
【注:(1)以下提到的複雜度僅為演演算法本身,不計入演演算法之外的部分(如,待排序陣列的空間佔用)且時間複雜度為平均時間複雜度
(2)除特殊標識外,測試環境與程式碼均為.NET 6/C#
(3)預設情況下,所有解釋與用例的目標資料均為升序
(4)預設情況下,圖片與文字的關係:圖片下方,是該幅圖片的解釋
(5)本文篇幅較長,和主標題(排序)契合度較低,建議分期閱讀;也可能存在較多錯誤,歡迎指出並提出意見,請見諒】
一. 十大排序
這十大排序對於有基礎的程式設計師並不陌生,只是一些經常不用的小細節可能記憶模糊,該部分內容會對排序方法簡要分析,旨在作為筆記,需要的時候幫助回憶相關內容。
(一) 氣泡排序(BubbleSort)
名字的起源十分生動形象:氣泡從水底向上浮,隨氣壓變化氣泡體積逐漸變大最終破裂;在某一時刻讓時間靜止,可觀察到從水面到水底,氣泡體積依次減小,體積排列有序,故得此名。
1. 原理:兩兩比較,按照比較器物件進行交換。
2. 複雜度:時間O(n2) 空間O(1)
3. 實現:(C++14 GCC 9)

- Line 12:在建構函式內獲取當前執行緒的Id。
- Line 21:Current屬性包含一個get存取器(唯讀),返回當前物件。
- Line 26:該類繼承了介面IEnumerable,所以必須實現GetEnumerator()方法。如果當前迭代器的執行緒Id和當前執行緒的Id不同,則克隆一個新的迭代器返回,否則返回當前迭代器。
- Line 29:該類繼承了介面IDisposable,所以必須實現Dispose()方法。必要情況下釋放物件。
- Line 36~40:因為需要進行篩選(迭代器遍歷)工作,所以需要定義迭代器,並將其初始狀態設定為1,返回當前迭代器。
- Line 44:該方法MoveNext()來自於所繼承的介面IEnumerator,其根據不同的容器,有不同的實現(就像剛才提到的List和Array的迭代方式),所以定義為抽象方法。
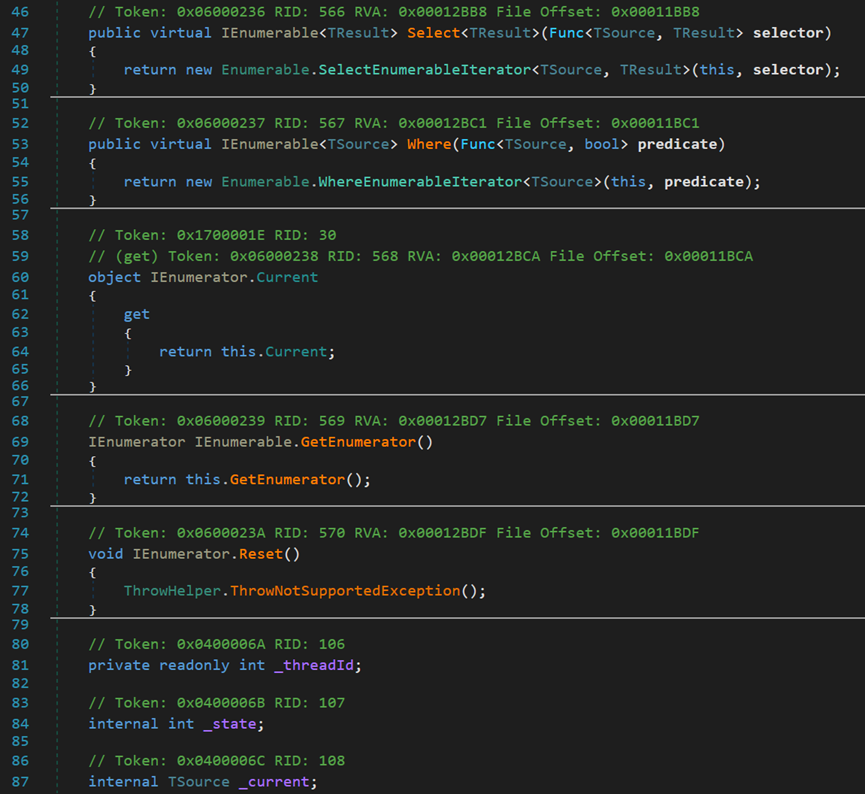
- Line 47~50:虛方法Select(),預設返回WhereEnumerableIterator迭代器。
- Line 53~56:虛方法Where(),預設返回WhereSelectEnumerableIterator迭代器。
這兩個迭代器均不參與過濾運算,兩個虛方法主要用於具體容器的複用或重寫。如果呼叫Where的迭代器,屬於剛才提到的不參與過濾運算的六個迭代器物件,則會覆蓋父類別中的某些方法;如果是其它迭代器,例如Distinct迭代器,則會呼叫父類別的Where和Select方法。

Where擴充套件方法(一)
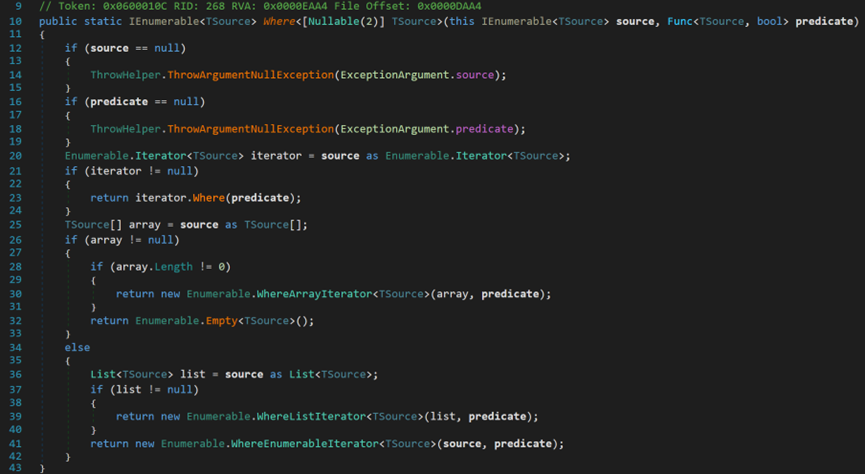
- Line 12~19:檢查資料來源和過濾器是否為空。
- Line 20:嘗試將source轉換為迭代器物件,會產生兩種情況:
(1)如果是Where相關的迭代器,如呼叫形式為XX.Where().Where()。此處iterator.Where(predicate)的Iterator是Where相關的迭代器物件(WhereListIterator、WhereArrayIterator),此時呼叫的Where方法是派生類WhereXXXIterator重寫後的Where方法,返回的是WhereXXXIterator物件,XXX表示List或Array或Enumerable。
(2)如果是其他迭代器,如呼叫形式為XX.Distinct().Where(),此處iterator.Where(predicate)的Iterator是Distinct的迭代器物件,此時呼叫的Where方法是父類別Iterator種的Where方法,返回的是預設的WhereEnumerableIterator物件。
- Line 25~33:嘗試將source轉換為陣列型別。若轉換成功且長度不為0,則返回WhereArrayIterator範例。
- Line 34~41:嘗試將source轉換為List型別。若轉換成功且長度不為0,則返回WhereListIterator範例。
- 若兩種型別均無法轉換,則返回預設範例WhereEnumerableIterator。
Where擴充套件方法(二)
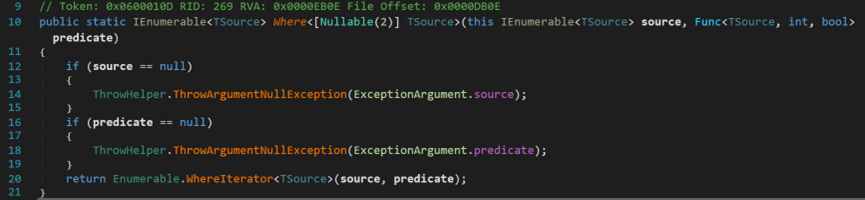
該方法為帶索引引數的擴充套件方法,其沒有對執行緒對資源的佔用情況進行檢查,而是直接呼叫了WhereIterator方法
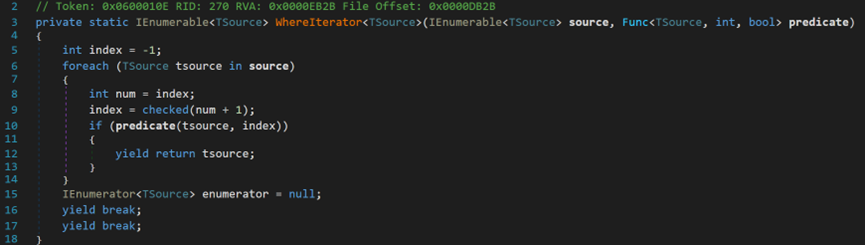
WhereIterator方法中維護了一個計數器,每回圈一次,計數器加1,計數器中如果出現整型數位溢位情況,則丟擲異常。yield return將結果以值的形式返回給列舉元物件,可一次返回一個元素;yield break將控制權無條件地交給迭代器的呼叫方,該呼叫方為列舉元物件的IEnumerator.MoveNext方法(或其對應的泛型System.Collections.Generic.IEnumerable<T>)或Dispose方法。
[# 有關迭代器WhereEnumerableIterator的原始碼]
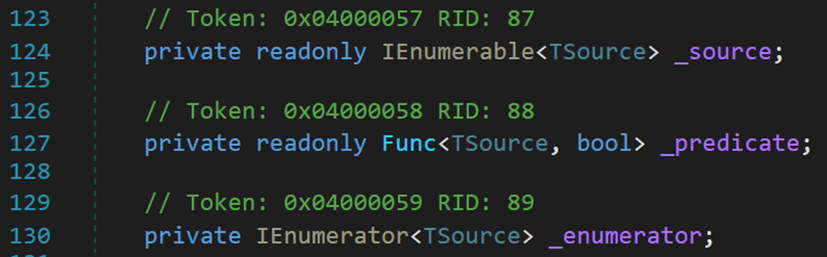
其包含三個欄位:源資料、過濾器、迭代器物件。
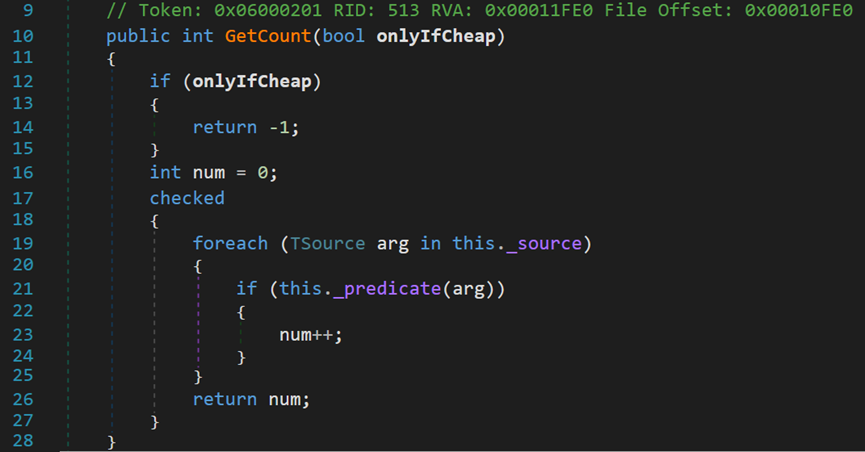
GetCount()方法在上文提到過,用於計算源資料集中,符合條件的元素個數,預設傳入true。
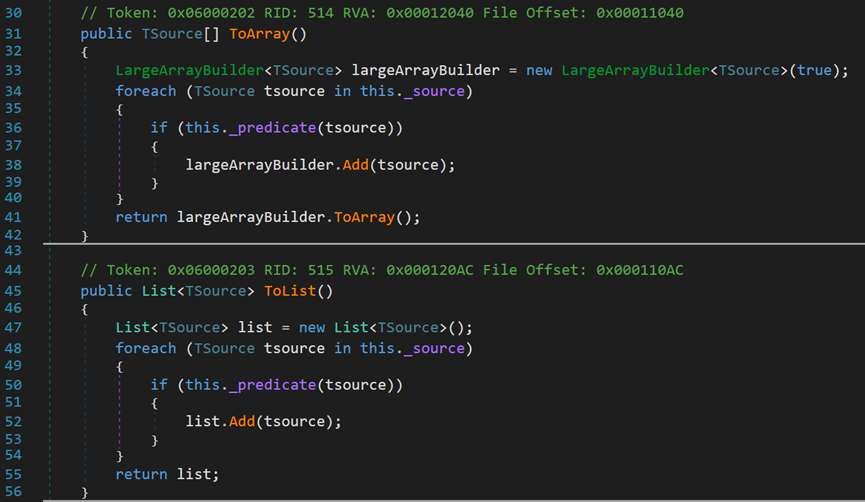
包含兩個型別轉換方法,分別轉換為陣列型別和泛型集合型別。轉換原理均是通過建立相應物件,並寫入資料完成。

一個構造方法,初始化源資料集和過濾器物件。

繼承的類與介面。
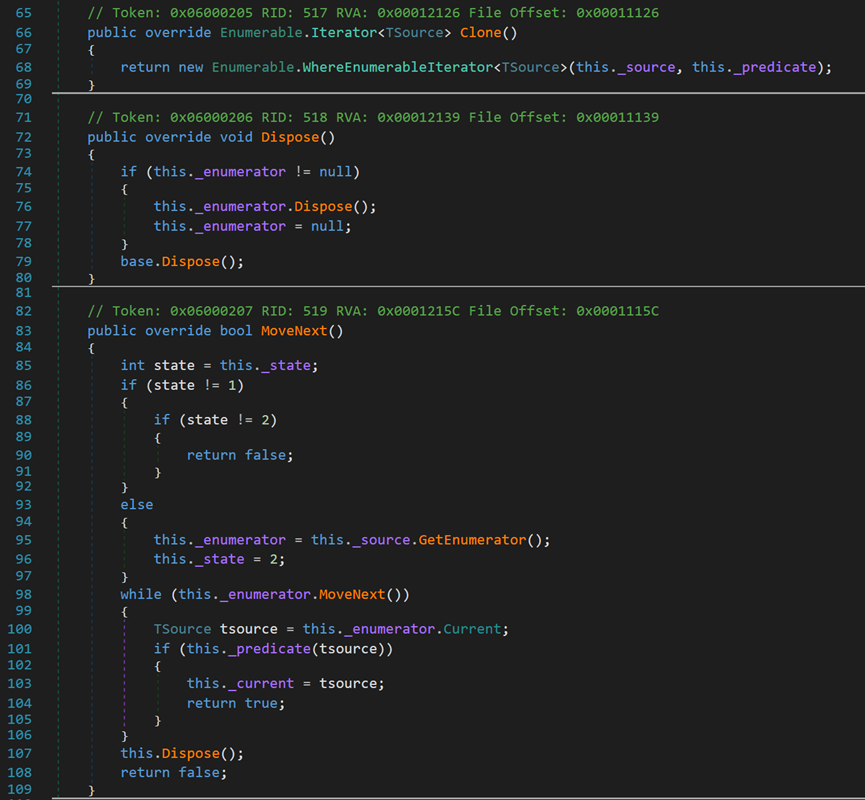
由於其繼承了許多介面和類,所以此處重寫了介面中的方法,包括建立並返回新的(克隆)迭代器物件、釋放物件、向後移動到下一個元素。
- Line 85:變數 _state 位於類Enumerable中的Iterator型別中,初始值為1,用於表示當前狀態,指示出下一步應當怎麼做。
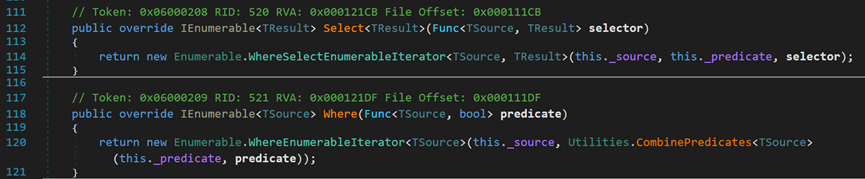
重寫了IEnumerable<TSource>介面中的Select()和Where()方法,用於當呼叫Where的迭代器不屬於六大型別時,呼叫上一級的方法。
【Select()方法和Where()方法原理類似,在此不作敘述】
(五)排序
將了這麼多題外話,終於拉回了主題。Linq中也有用於排序的方法,包括OrderBy、OrderByDescending、ThenBy、ThenByDescending,在一個語句中,以OrderBy型開頭,之後的只能用ThenBy型,但ThenBy型可多次使用。一般地,O/T型共同存在的排序多用於多關鍵字排序。
基礎語法如下:
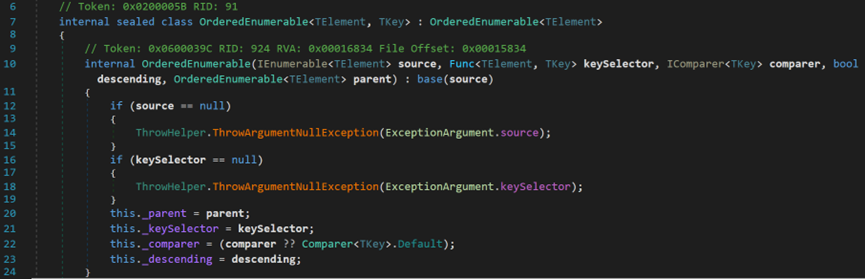
[# 有關OrderBy的原始碼]


OrderBy()方法有兩個過載方法,均返回一個OrderedEnumerable型別的物件。
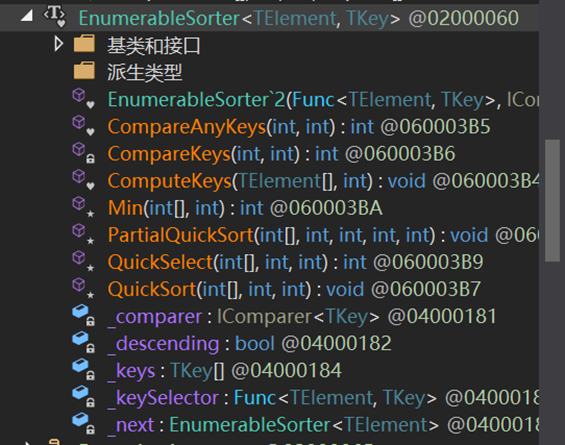
其內建的排序方法,位於類EnumerableSorter<TElement, TKey>中,分別為PartialQuickSort()和QuickSort()。
在排序前,
(1) 對於QuickSort()方法


其重寫了父類別EnumerableSorter<TElement>中的同名抽象方法,並呼叫類ArraySortHelper<T>中的IntrospectiveSort()方法,這與前一篇文章中提到的陣列排序方法Array.Sort(),方法一致。
(2) 對於PartialQuickSort()方法
該方法直接定義在類EnumerableSorter<TElement, TKey>中,針對源資料集的某一部分進行排序。
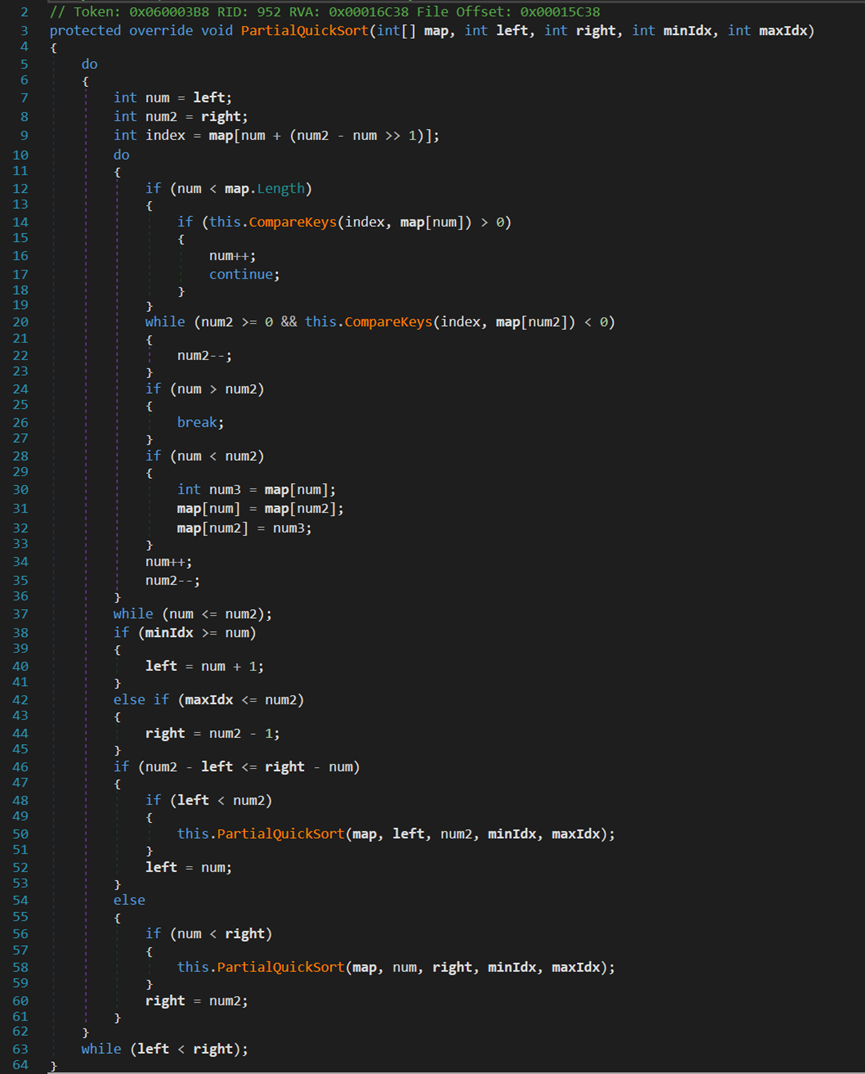
- Line 3:map為待排序陣列;letf與right為邊界指標(此處的指標有別於C/C++中的指標,此處僅代表一個標記);minIdx與maxIdx為排序區域。
- Line 12~19:當left小於length(未越界)時,CompareKeys()方法用於返回兩元素的大小關係:相等返回0,左大右小返回1,反之返回-1。
從左往右,找到第一個大於等於中間位置的元素。
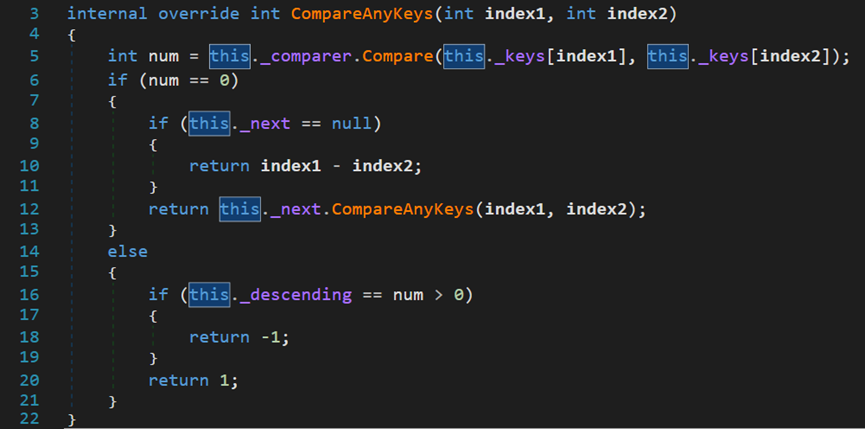
其方法內部的四個紫色欄位均在類EnumerableSorter中

【注:下方有關五個引數的解釋為推斷得出】
_keySelector表示委託方法Func(),過濾器;_compare表示比較器物件;_descending表示是否降序;_next下一個迭代排序器物件;_keys表示經過濾器篩選出的待排序資料集;
- Line 20~23:從右往左,找到第一個小於等於中間位置的元素。
- Line 24~37:如果left與right沒有彼此越過對方,則交換位置,並開始下一次查詢。
此時,內層迴圈結束,完成了以中間位置元素為基準值的排序,保證基準值左側小、右側大。
- Line 38~45:若此時兩指標並未在需求的排序區域內,則相對應方向移動。
- Line 46~61:當內層迴圈結束時兩指標的大小關係為num = num2 + 1,所以Line 46在判斷被兩指標分割的兩部分,哪一部分更短,優選處理短的一部分。
整個排序過程以遞迴的方式進行,類似於快速排序。
【注:以下內容屬於推斷得出】
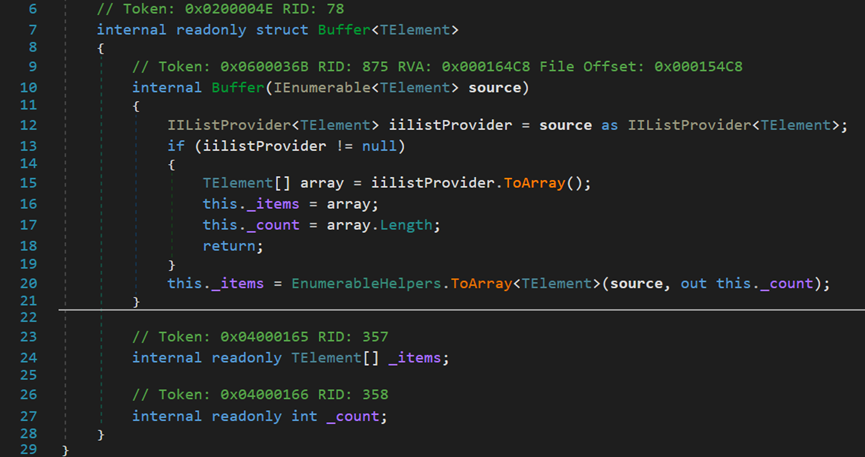
資料集在呼叫OrderBy()等一類排序方法後,會先將源資料轉換為泛型Buffer型別
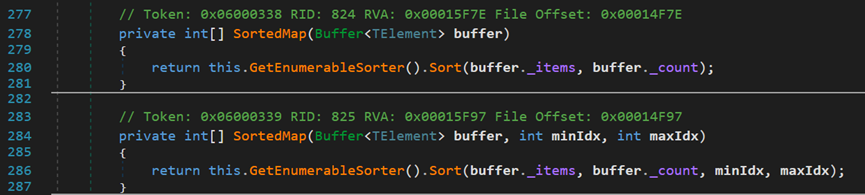
之後,再呼叫類OrderedEnumerable中的SortedMap()方法
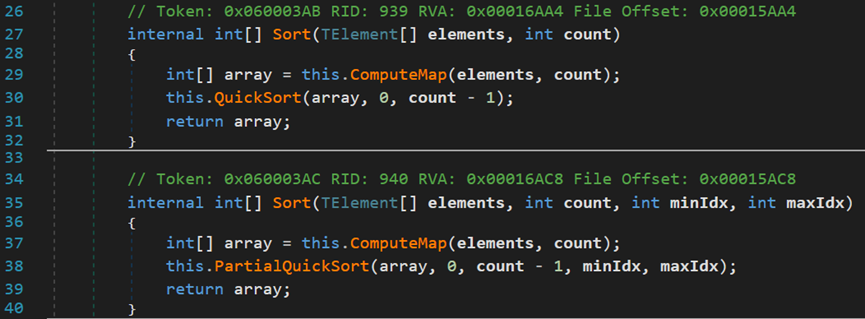
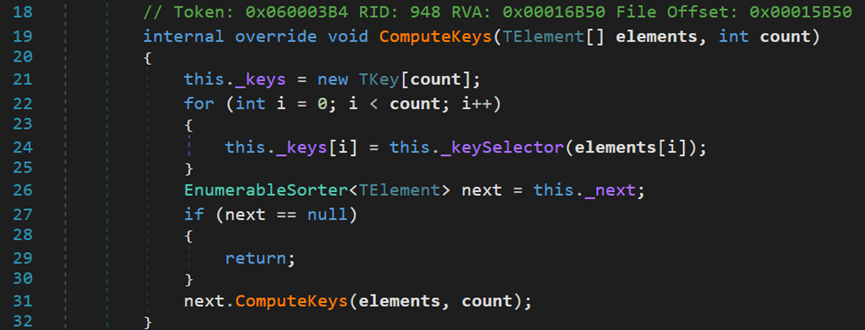
在呼叫真正開始排序前,首先呼叫ComputeMap()方法,根據過濾器,篩選出要排序的元素,並儲存在_keys中。再根據不同的引數,呼叫不同的方法進行排序。
以上為OrderBy一類排序方法的「前搖」和過程,其餘的OrderByDescenidng()、ThenBy()、ThenByDescending()方法與OrderBy()類似。
流程圖如下:

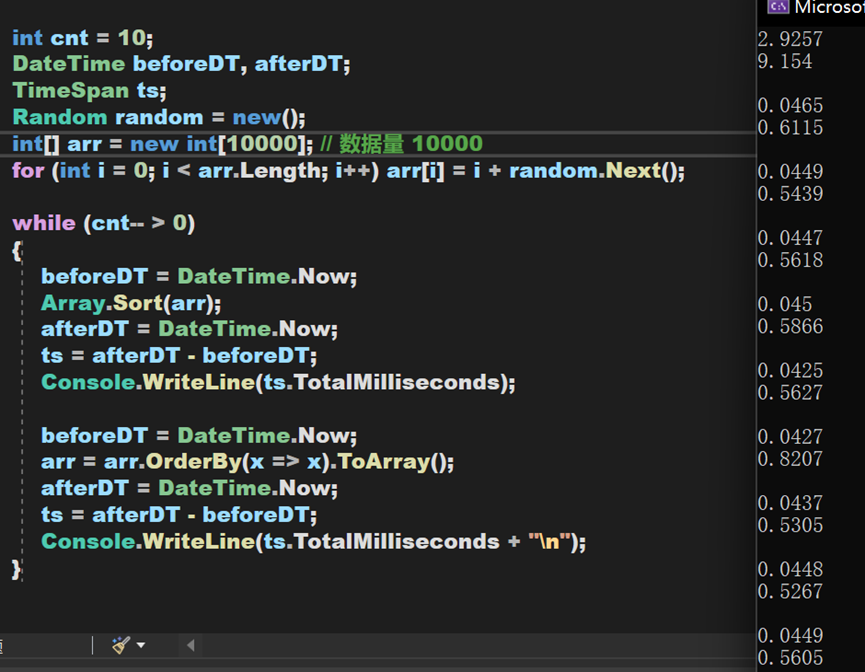
小結二
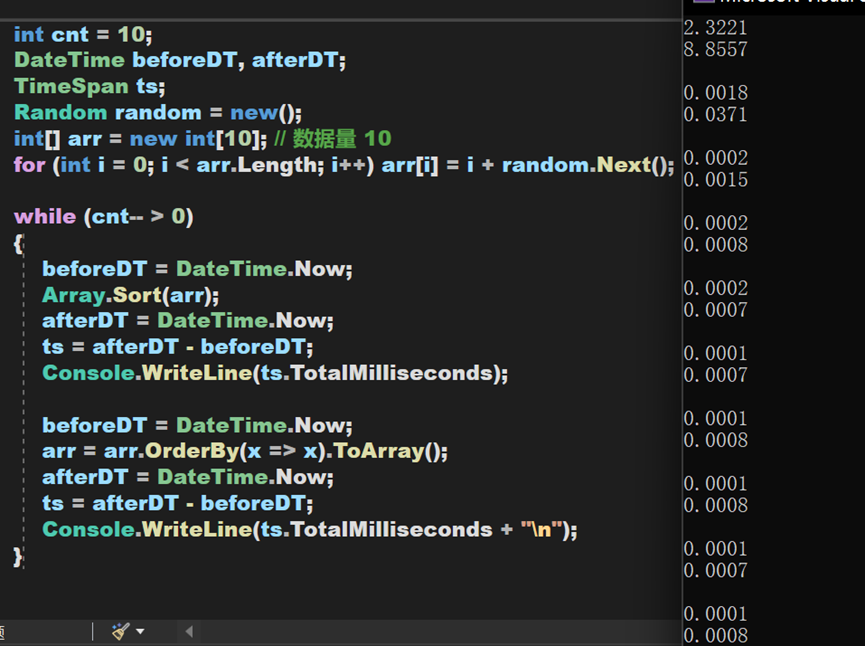
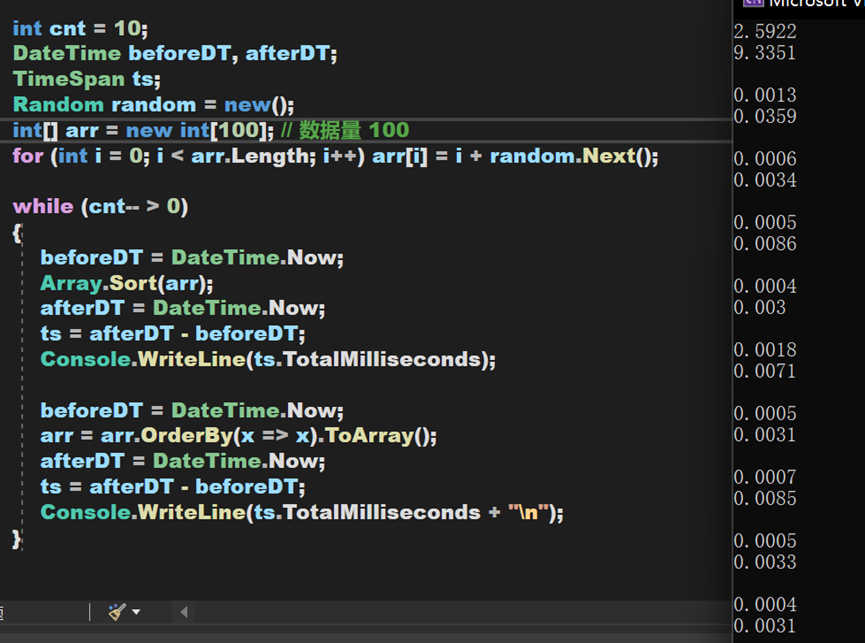
綜合來看,就對於OrderBy一類排序演演算法本身,其時間複雜度和Array中的Sort()方法相差不大,但實際執行效果卻要比Array.Sort()方法慢。原因應該在於其需要頻繁建立EnumerableSorter物件、將資料型別轉換為Buffer再轉換為陣列、排序後從IOrderByEnumerable型別轉換為源資料型別,這些過程大大延長了總時間,尤其是在資料量較大的時候,所需時間將會產生較大差異。
三.有關Lambda表示式
Lambda表示式用來建立匿名函數,常用於委託、回撥,且可以存取到外部變數。使用Lambda運運算元「=>」,從其主體中分離 lambda 參數列,可採用以下任意一種形式:
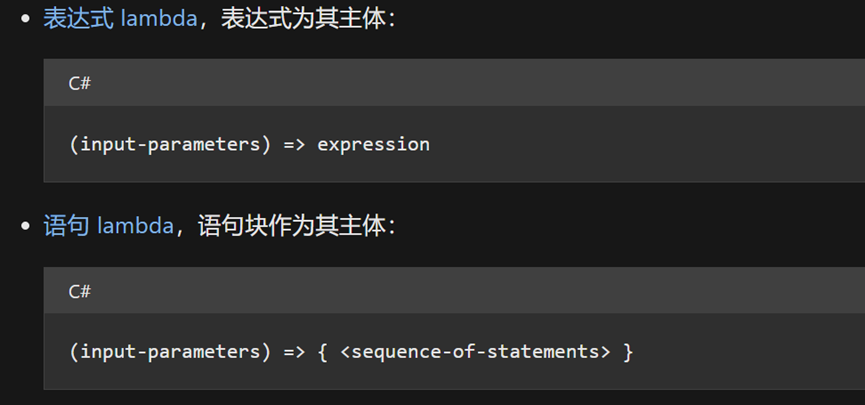
一般地,輸入的引數不需要顯示指定型別。但當編譯器無法判斷其型別時,可顯示指明各個引數的型別:

(一) 有關匿名
(1)匿名型別
該型別可用來將一組唯讀屬性封裝到單個物件中,而無需顯式定義一個型別。型別由編譯器在編譯階段生成,並且不能在原始碼級使用。可結合使用new運運算元和物件初始值設定項建立匿名型別。
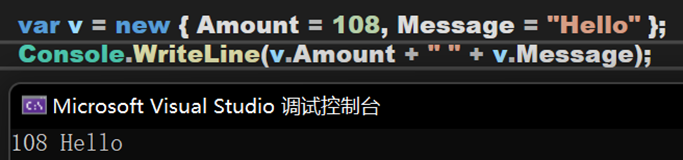
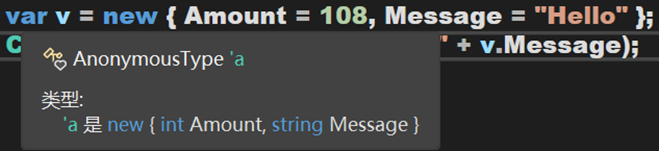
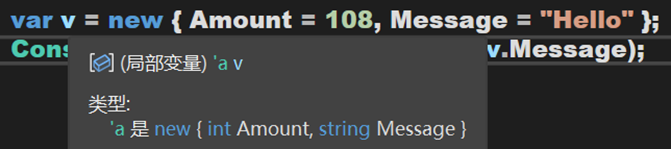
其中,這裡的var被定義為匿名型別(AnonymousType),v被定義為型別 `a 。
在反編譯程式中,查詢到20中相關的方法
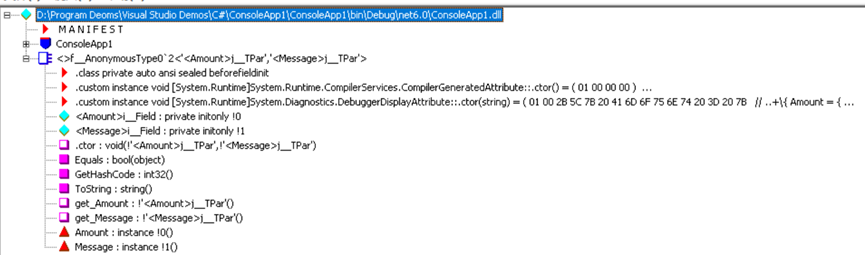
根據IL DASM工具可以發現,其包含的主要資訊:類<>f__AnonymousType0`2<’<引數para>j__TPar’,’<Message>j__TPar’>;私有唯讀欄位<Amount>i__Field和<Message>i__Field;三個非靜態重寫方法Equals()、GetHashCode()、ToString()。
以此為例,在原始碼中找到相關資訊,其位於程式集PresentationFramwork.dll中
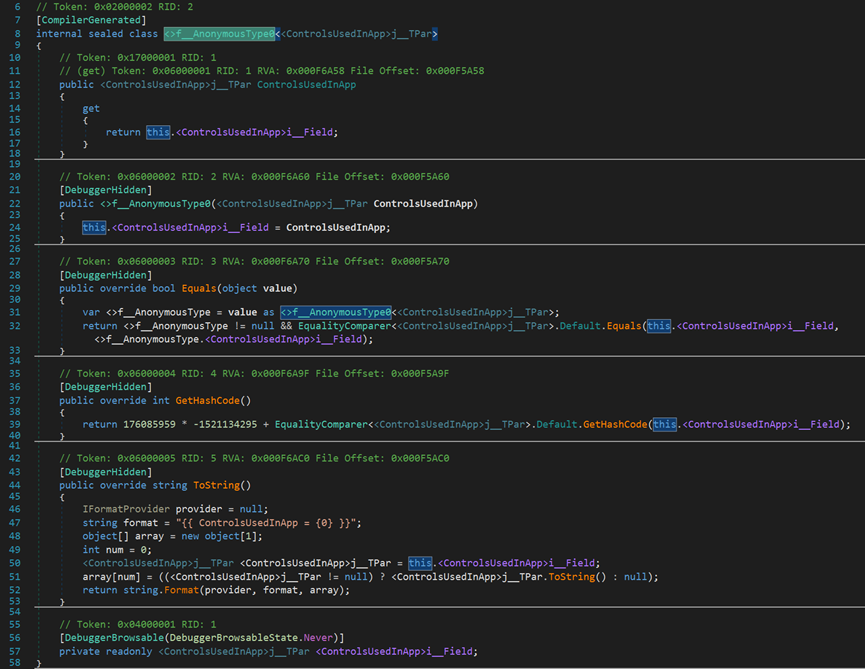
- Line 8:內部密封類,類名為<>f__AnonymousType0;泛型型別為<ControlsUsedInApp>j__TPar。
- Line 12~17:定義引數變數的屬性—get(唯讀)。
- Line 21~25:建構函式,將傳入的引數賦值給類的內部變數。
- Line 29~33:Equals()方法,嘗試將傳入的Object型別物件轉換為與被比較物件相同的匿名型別,並按照預設比較其和基本原則,按順序逐一比較內部引數。
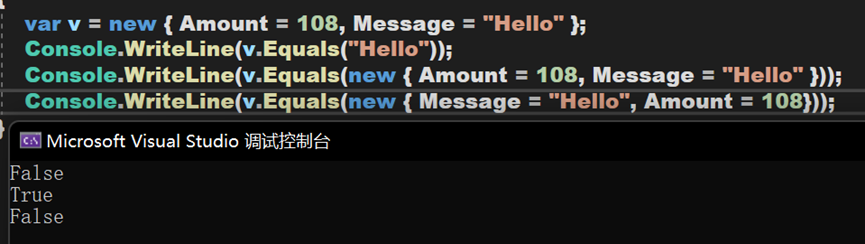
- Line 37~40:返回當前物件的雜湊程式碼。雜湊碼為每個變數/物件的唯一識別符號,用於在一定情況下相互區別。
- Line 44~53:將匿名型別的整個部分轉化為字串的形式(大括號居然也算!?)。
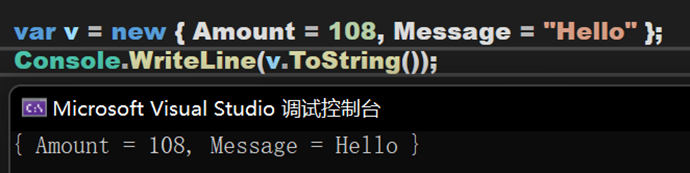
(2)匿名方法
委託是用於參照與其具有相同標籤的方法。即,可以使用委託物件呼叫可由委託參照的方法。匿名方法提供了一種傳遞程式碼塊作為委託引數的技術,其沒有名稱只有方法體;沒有返回值型別,型別根據具體方法中的return語句推斷。如,Func()方法、Action()方法、Predicate()方法。

所以在OrderBy一類排序中,其內部需要傳入一個匿名方法,以賦值給Func()方法,故使用Lambda表示式。
(二) Lambda 表示式的自然型別
Lambda表示式本身沒有型別,因為CLS(通用型別系統)沒有「Lambda 表示式」這一固有概念。不過,有時以非正式的方式談論 Lambda 表示式的「型別」會很方便。該非正式「型別」是指委託型別或 Lambda 表示式所轉換到的Expression型別。
從C# 10開始,Lambda表示式可能具有自然型別。編譯器不會強制為 Lambda 表示式宣告委託型別(如Func<>或Action<>),而是根據 Lambda 表示式推斷委託型別。

也就是說,一開始的Lambda表示式只能賦值給委託型別。而在此之後,Lambda表示式可以根據具體的情況,賦值給具體的型別。
【注:更多Lambda表示式內容請參閱Lambda 表示式 - C# 參照 | Microsoft Docs】
[# 有關泛型的協變與逆變]
據官方解釋,協變指能夠使用比原始指定的派生型別的派生程度更大(更具體的)的型別;逆變指能夠使用比原始指定的派生型別的派生程度更小(不太具體的)的型別。
在談論協變與逆變之前先來看一下泛型集合中的物件轉換。
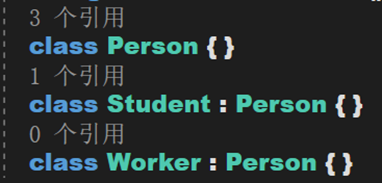
此處有三個類。其中Student與Worker派生自Person,那麼可以將Person稱為Student和Worker的上層資料型別;Student和Worker稱為Person的下層型別。
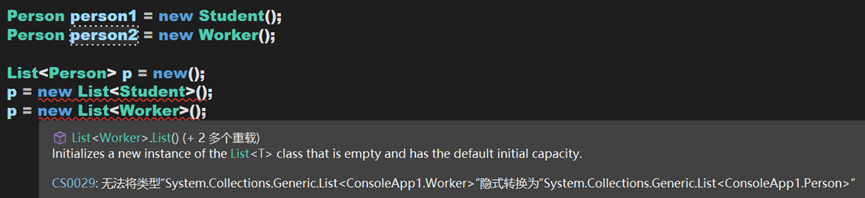
可以發現,雖然Person時Student和Worker的父類別,但List<Person>不是List<Student>和List<Worker>的父類別,所以後兩行的賦值會報錯。
在C# 4之前,類似於上述的賦值操作是不被允許的。因為假設其能夠賦值,即List<Person> p = new List<Student>();成立,那麼雖然p的型別為List<Person>但其範例物件使List<Student>,在呼叫方法時,呼叫的也就是Student的方法。如果現在實現這個語句:p.Add(new Person());其實質上是用Student中的Add方法,而Student又是Person的子類,Person無法安全(直接)轉換為Studnt物件,所以這樣的集合定義沒有意義,因此不被允許。
從C# 4開始,類似的操作,在泛型委託、泛型介面中,允許發生。但上述操作依舊是無法實現的,因為其違反型別型別轉換的基本流程。
定義一個無參泛型委託。

- 協變:

我們嘗試在上層型別中存放下層型別。不出意外,依舊報錯。根據剛才的分析,要想解決這個錯誤,需要解決兩個問題:
(1) 在呼叫p()方法時,實際上呼叫的是s()方法,所以需要s執行的結果能轉換為p執行後所返回的型別。即,s能夠轉換為p型別。
(2) 解除編譯器的檢查限制,在此處允許將Work<Student>型別的物件賦值給Work<Person>型別的變數。
對於(1)已經滿足,由隱式轉換直接完成;而條件(2)就需要在委託中加上out關鍵字。

- 逆變

嘗試在上層型別中存放下層型別。解決這個錯誤,也需要解決兩個問題:
(1)在呼叫s()方法時,實際上呼叫的是p()方法,即,p能夠轉換為s型別。
(2)解除編譯器的檢查限制,在此處允許將Work<Person>型別的物件賦值給Work<Student>型別的變數。
對於(1)因為Student為Person的子類,所以二者存在聯絡,通過強制型別轉換可以實現;而條件(2)需要在委託中加上in關鍵字。

【注:如果沒有子父類別的關係,加上in/out關鍵字,也無法實現】
簡而言之:協變可以在上層資料型別中存放下層物件;逆變可以在下層的資料型別中存放上層物件(這裡的上層與下層是相對而言),這兩個過程本質上是引數的型別轉換。

據微軟官方的說法,協變於逆變只發生在陣列、委託、泛型引數之上,對於類的上下轉型而言不算做協變於逆變。