HDFS核心原理
HDFS 讀寫解析
HDFS 讀資料流程
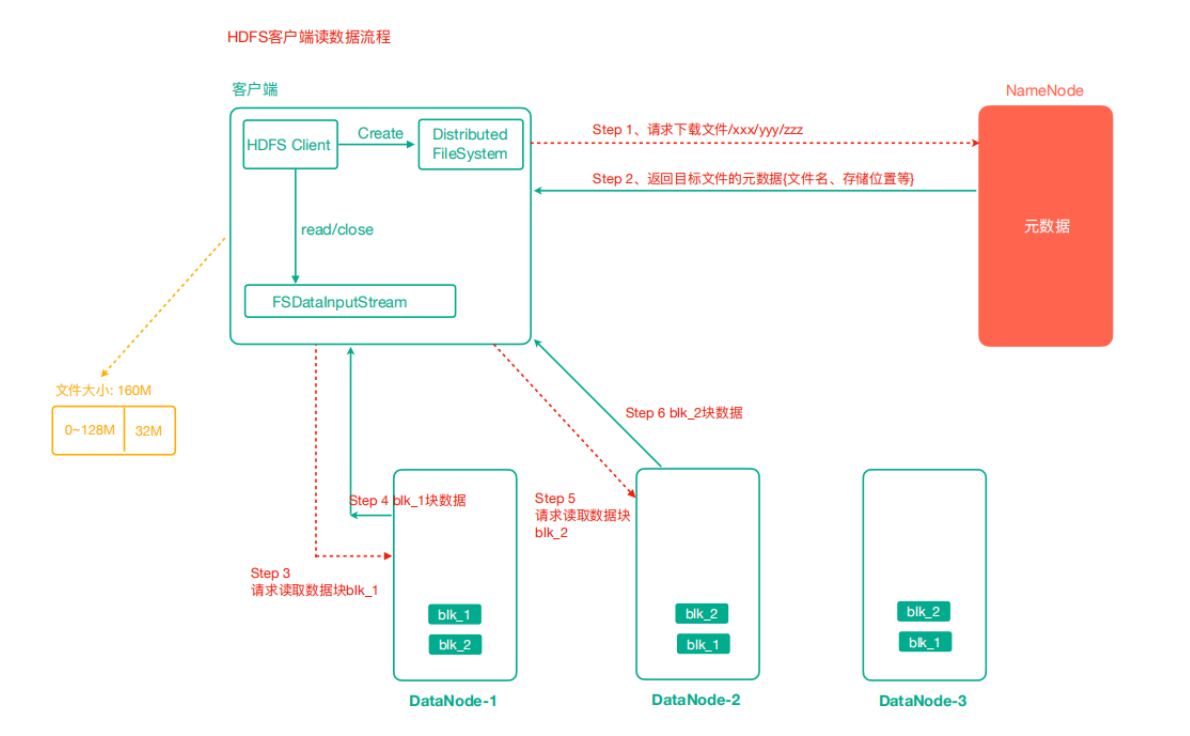
- 使用者端通過 FileSystem 向 NameNode 發起請求下載檔案,NameNode 通過查詢後設資料找到檔案所在的 DataNode 地址
- 挑選一臺 DataNode(就近原則)伺服器,傳送讀取資料請求
- DataNode 開始傳輸資料給使用者端
- 使用者端以 Packet 為單位接收,先在本地快取,然後寫入目標檔案
HDFS 寫資料流程
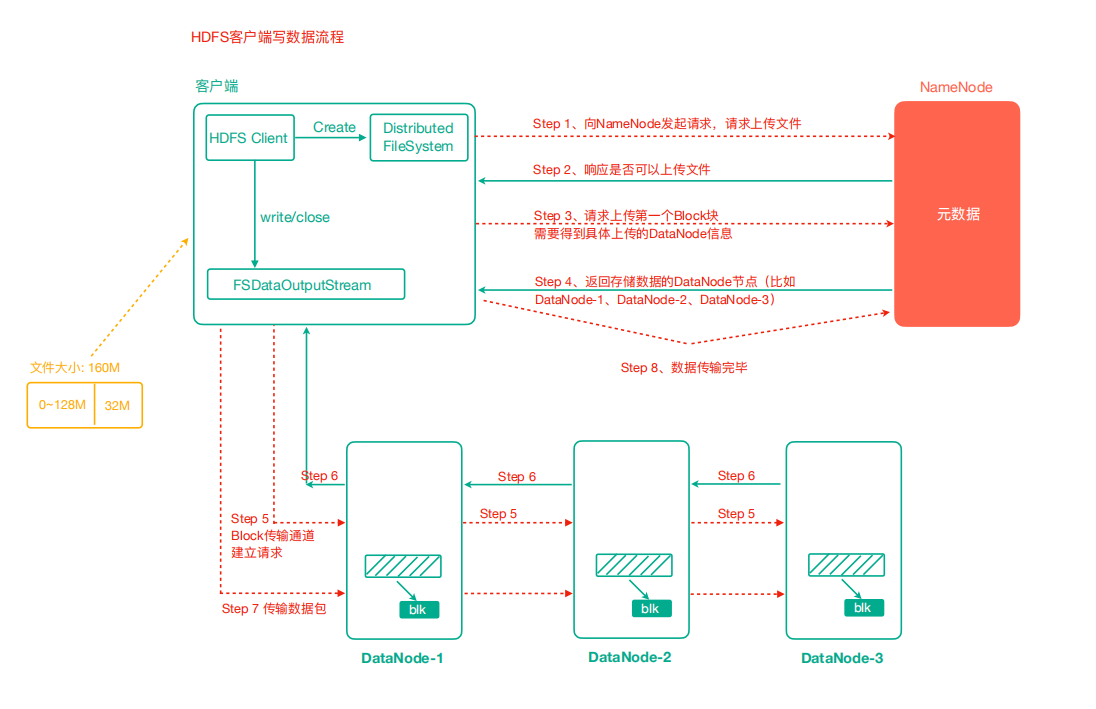
- 使用者端通過 FileSystem 模組向 NameNode 傳送上傳檔案請求,NameNode 檢查目標檔案是否已存在,父目錄是否存在
- NameNode 返回是否可以上傳
- 使用者端請求詢問第一個 Block 上傳到哪幾個 DataNode 伺服器
- NameNode 返回 n 個 DataNode 節點,如 dn1、dn2、nd3
- 使用者端通過 FSDataOutputStream 模組請求 dn1 上傳資料,dn1 收到請求會繼續呼叫 dn2,然後 dn2 呼叫 dn3,將這個通訊管道建立完成
- dn1、dn2、nd3 逐級應答使用者端
- 使用者端開始往 dn1 上傳第一個 Block(先從磁碟讀取資料放到一個本地記憶體快取),以 Packet 為單位,dn1 收到一個 Packet 就會傳給 dn2,dn2 傳給 dn3,dn1 每傳一個 packet 會放入一個確認佇列等待確認
- 當一個 Block 傳輸完成之後,使用者端再次請求 NameNode 上傳第二個 Block 的伺服器。(重複執行 3-7 步)
預設情況下每 64kb 一個 Packet
程式碼驗證:最開始會有一個輸出,也就是一個 64k 的檔案會輸出兩次。
@Test
public void testUploadPacket() throws IOException {
FileInputStream fis = new FileInputStream(new File("e://11.txt"));
FSDataOutputStream fos = fs.create(new Path("bbb.txt"), () -> System.out.println("每傳輸一個packet就會執行一次"));
IOUtils.copyBytes(fis,fos,new Configuration());
}
NameNode 和 SecondNamenode
後設資料管理機制解析
- NameNode 如何管理和儲存後設資料?
我們一般計算機儲存資料無非兩種方式:記憶體或磁碟。記憶體處理資料快,但斷電資料會丟失。磁碟資料處理慢,但是安全性高。
綜合以上兩點,NameNode 後設資料的管理採用的是:記憶體+磁碟(FsImage 檔案)的方式。
- 磁碟和記憶體中後設資料怎麼劃分?
假設 1:如果要保持磁碟和後設資料資料一致,那麼對後設資料增刪改操作的時候,需要同步操作磁碟,這樣效率也不高。
假設 2:兩個資料合起來才是完整的資料。NameNode 引入了 edits 檔案(紀錄檔檔案,只能追加寫入),記錄增刪改操作。
具體流程如下:
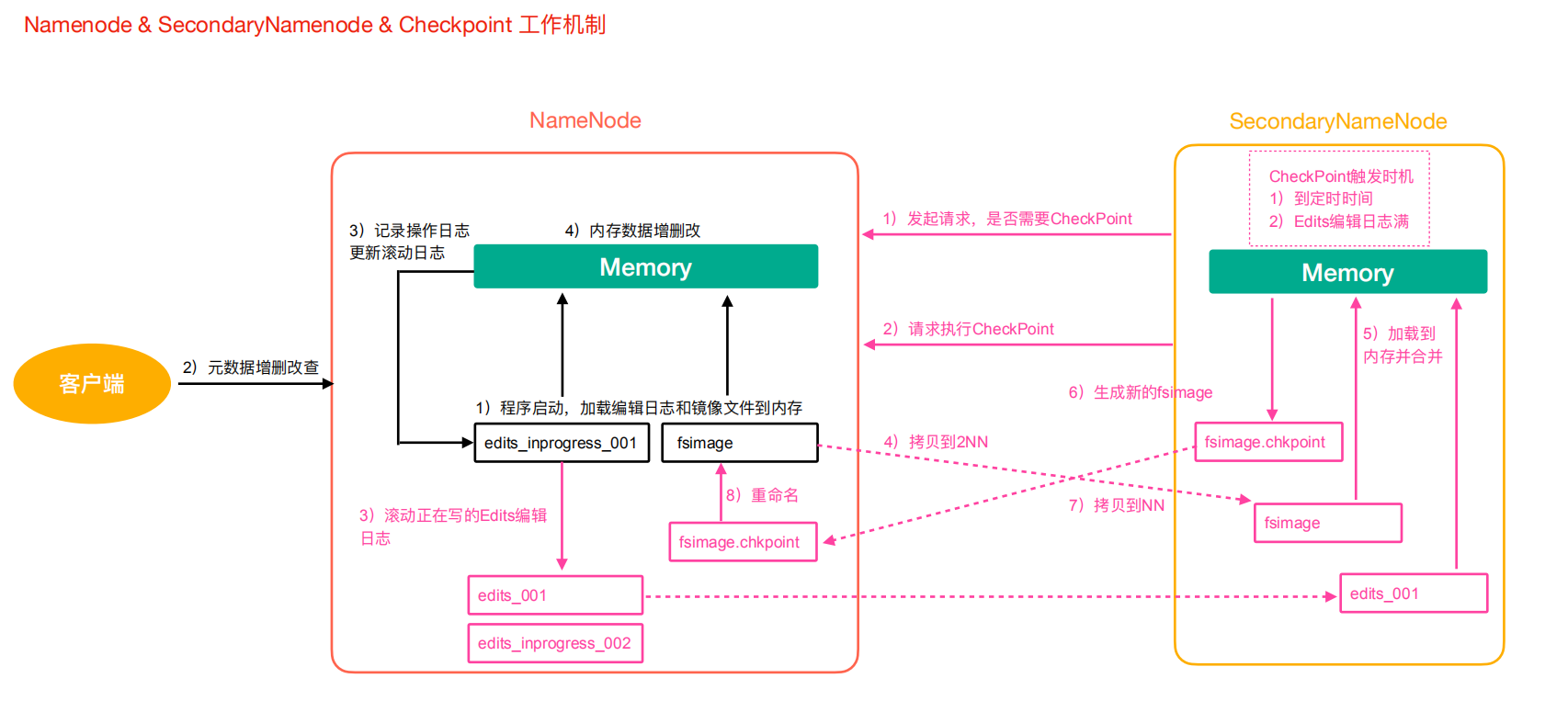
1)第一階段:NameNode 啟動
- 第一次啟動 NameNode 格式化後,會建立 Fsimage 和 Edits 檔案。如果部署第一次啟動,直接載入編輯紀錄檔和映象檔案到記憶體
- 使用者端對後設資料增刪改的請求
- NameNode 記錄操作紀錄檔,更新捲動紀錄檔
- NameNode 在記憶體中對資料進行增刪改
2)第二階段:Secondary NameNode 工作
- Secondary NameNode 詢問 NameNode 是否需要 CheckPoint。直接帶回 NameNode 是否執行檢查點操作結果
- Secondary NameNode 請求執行 CheckPoint
- NameNode 捲動正在寫的 Edits 紀錄檔
- 將捲動前的 Edits 紀錄檔和映象檔案拷貝到 Secondary NameNode
- Secondary NameNode 載入 Edits 紀錄檔和映象檔案到記憶體,進行合併
- 生成新的映象檔案 fsimage.chkpint
- 拷貝 fsimage.chkpoint 到 NameNode
- NameNode 將 fsimage.chkpoint 重新命名為 fsimage
Edits 檔案和映象檔案(Fsimage)解析
這兩個檔案位於${hadoop.tmp.dir}/dfs/name/current/下
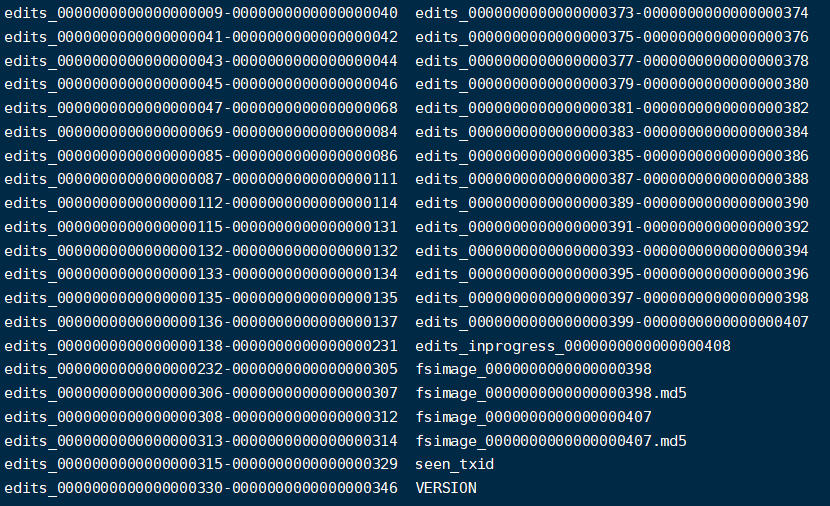
- Fsimage 檔案:是 NameNode 中後設資料的映象,包含了 HDFS 檔案系統的所有目錄及檔案資訊(Block 數量、副本數量、許可權等)
- Edits 檔案:儲存了使用者端對 HDFS 檔案系統的所有增刪改操作
- seen_txid:該檔案儲存了一個數位,對應最後一個 Edits 檔名的數位
- VERSION:記錄 NameNode 的一些版本號資訊
1. Fsimage 檔案內容檢視
這些檔案本身開啟是亂碼不可檢視的,好在官方給我們提供了檢視這些檔案的命令。
語法:
hdfs oiv -p 檔案型別(xml) -i 映象檔案 -o 轉換後檔案輸出路徑
範例:
hdfs oiv -p XML -i fsimage_0000000000000000409 -o ./fsimage.xml
我們開啟 xml 檔案:
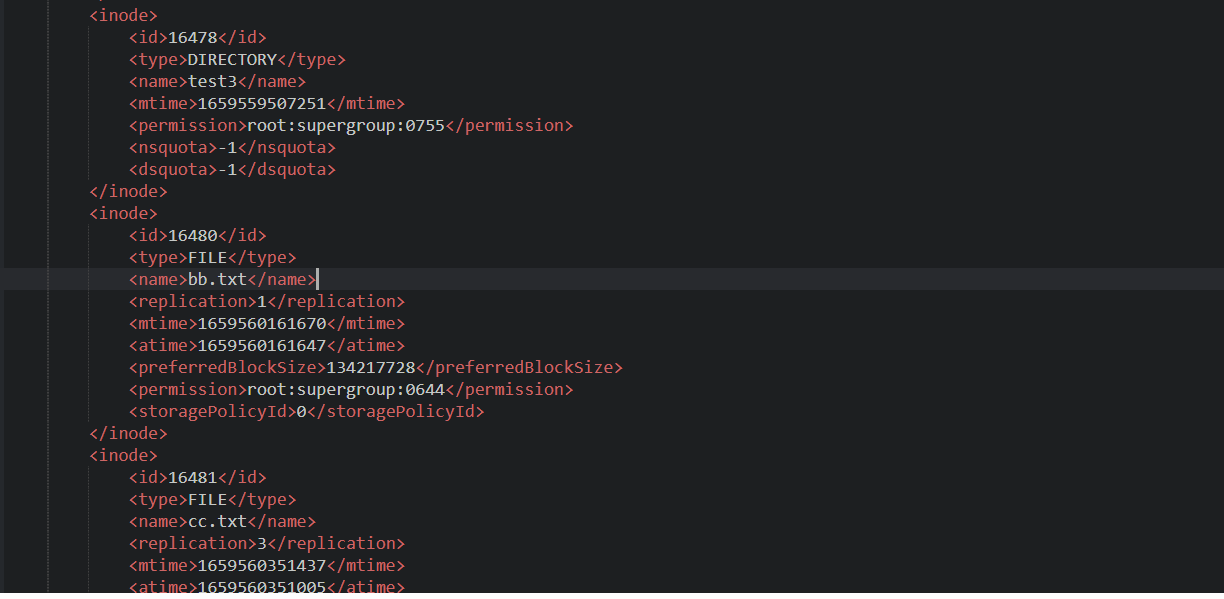
裡面包含了型別、檔名、副本數、許可權等等資訊。注意沒有儲存塊對應的 DataNode 的資訊。
因為這個節點資訊由 DataNode 自己彙報有哪些檔案,而不是檔案裡記錄屬於哪個節點。否則如果每個節點宕機了,那麼所有的檔案都需要進行變更資訊。
2. Edits 檔案內容
基本語法:
hdfs oev -p 檔案型別 -i編輯紀錄檔 -o 轉換後檔案輸出路徑
範例:
hdfs oev -p XML -i edits_inprogress_0000000000000000420 -o ./edits.xml
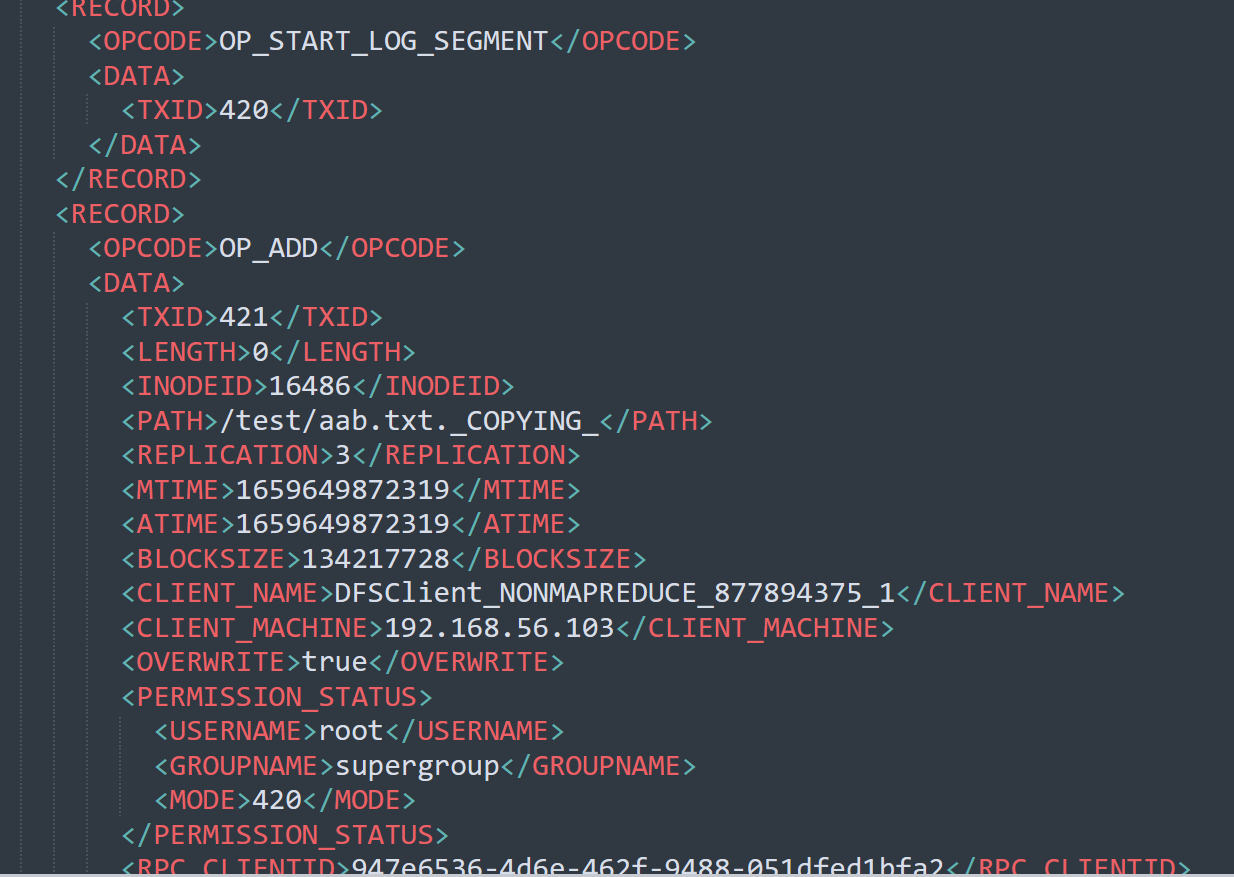
這個檔案記錄了我們的增刪改的一些操作。我們如何確認哪些 Edits 檔案沒有被合併過呢?
可以通過 fsimage 檔案自身的編號來確定。大於這個編號的 edits 檔案就是沒有合併的。
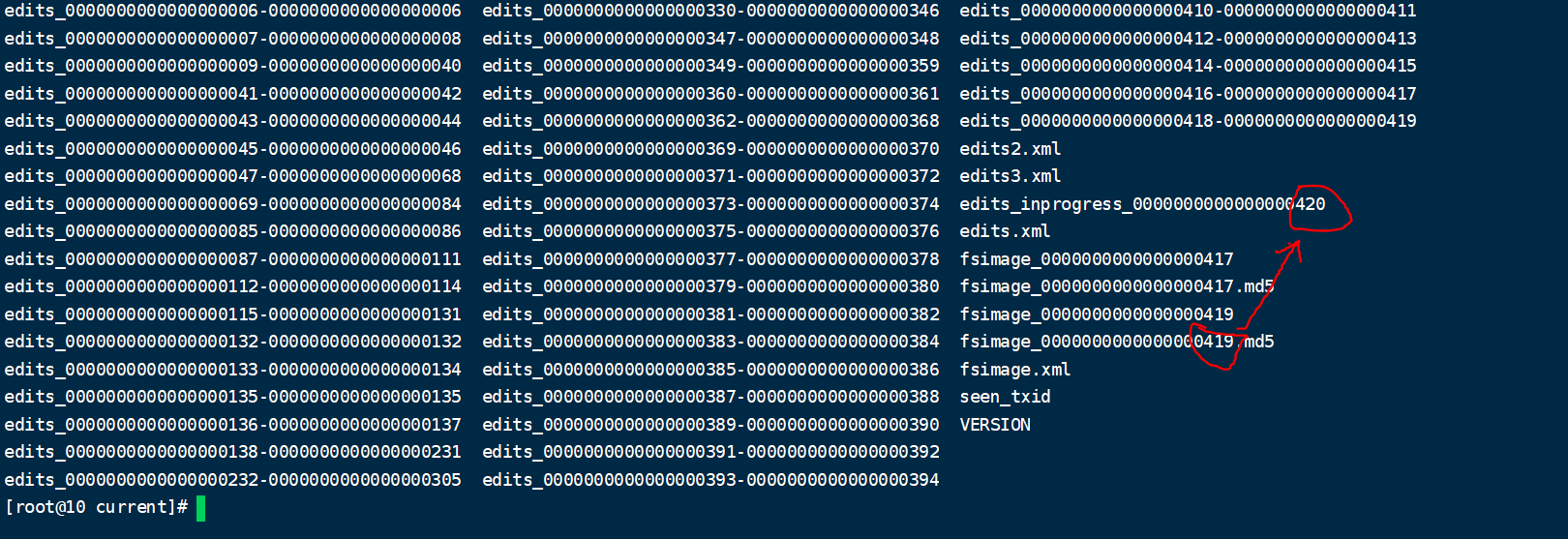
3. chekpoint 週期
週期設定我們可以在預設組態檔 hdfs-default.xml 裡找到。
<!-- 定時一小時 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一分鐘檢查一次操作次數,當操作次數達到1百萬時,SecondaryNameNode執行一次 -->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作動作次數</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分鐘檢查一次操作次數</description>
</property >
4. NameNode 故障處理
NameNode 儲存著所有的後設資料資訊,如果故障,整個 HDFS 叢集都無法正常工作。
如果後設資料出現丟失或損壞怎麼恢復呢?
- 將 2nn 的後設資料拷貝到 nn 下(存在一定數量的後設資料丟失)
- 搭建 HDFS 的高可用叢集,藉助 Zookeeper 實現 HA,一個 Active 的 NameNode,一個是 Standby 的 NameNode,解決 NameNode 單點故障問題。
Hadoop 高階命令
1. HDFS 檔案限額設定
HDFS 檔案的限額設定允許我們以檔案的大小或檔案的個數來限制我們在某個目錄上傳的檔案數量或檔案大小。
- 數量限額
#設定2個的數量限制,代表只能上傳一個檔案
hdfs dfsadmin -setQuota 2 /west
上傳第二個的時候報錯:
put: The NameSpace quota (directories and files) of directory /west is exceeded: quota=2 file count=3
清除數量限制
hdfs dfsadmin -clrQuota /west
- 空間限額
#限定1k的空間
hdfs dfsadmin -setSpaceQuota 1k /west
# 清除限額
hdfs dfsadmin -clrSpaceQuota /west
#檢視限額
hdfs dfs -count -q -h /west
2. HDFS 的安全模式
安全模式是 HDFS 所處的一種特殊狀態,這種狀態下,檔案系統只能接受讀請求。
在 NameNode 主節點啟動時,HDFS 首先進入安全模式,DataNode 在啟動的時候會向 NameNode 彙報可用的 block 等狀態,當整個系統達到安全標準時,HDFS 自動離開安全模式。如果 HDFS 出於安全模式下,則檔案 block 不能進行任何的副本複製操作,因此達到最小的副本數量要求是基於 DataNode 啟動的狀態來判定的。啟動時不會再做任何複製,HDFS 叢集剛啟動的時候,預設 30S 的時間是處於安全期的,只有過了安全期,才可以對叢集進行操作。
#進入安全模式
hdfs dfsadmin -safemode enter
#離開安全模式
hdfs dfsadmin -safemode leave
3. Hadoop 歸檔技術
主要解決 HDFS 叢集存在大量小檔案的問題。由於大量小檔案佔用 NameNode 的記憶體,因此對於 HDFS 來說儲存大量小檔案造成 NameNode 記憶體資源的浪費。
Hadoop 存檔檔案 HAR 檔案,是一個更高效的檔案存檔工具,HAR 檔案是由一組檔案通過 archive 工具建立而來,在減少了 NameNode 的記憶體使用的同時,可以對檔案進行透明的存取,通俗來說就是 HAR 檔案對 NameNode 來說是一個檔案減少了記憶體的浪費,對於實際操作處理檔案依然是一個個獨立的檔案。

範例:
- 先啟動 yarn
start-yarn.sh
- 歸檔檔案
hadoop archive -archiveName input.har -p /west /westAr
- 檢視歸檔
hadoop fs -lsr /user/root/output/input.har
- 解歸檔檔案
hadoop fs -cp har:/// user/root/output/input.har/* /user/root