Apache Hudi vs Delta Lake:透明TPC-DS Lakehouse效能基準
1. 介紹
最近幾周,人們對比較 Hudi、Delta 和 Iceberg 的表現越來越感興趣。 我們認為社群應該得到更透明和可重複的分析。 我們想就如何執行和呈現這些基準、它們帶來什麼價值以及我們應該如何解釋它們新增我們的觀點。
2. 現有方法存在哪些問題?
最近 Databeans 釋出了一篇部落格,其中使用 TPC-DS 基準對 Hudi/Delta/Iceberg 的效能進行了正面比較。雖然很高興看到社群挺身而出並採取行動提高對行業當前技術水平的認識,但我們發現了一些與實驗進行方式和結果報告有關的問題,我們希望分享和今天更廣泛地討論。
作為一個社群,我們應該努力在釋出基準時增加更嚴格的標準。我們相信這些是任何基準測試工作的關鍵原則:
- 可重現性:如果結果不可重現,讀者別無選擇,只能盲目相信表面上的結果。相反,應該記錄基準,以便任何人都可以使用相同的工具獲得相同的結果。
- 開放:為了獲得相同的結果,確保用於基準測試的工具可用於檢查正確性至關重要。
- 公平:隨著正在測試的技術的複雜性不斷增長,基準設定需要確保所有競爭者都使用記錄在案的設定來測試工作負載。
關於這些基本問題,不幸的是,我們認為 Databeans 部落格沒有完整地分享結果是什麼以及如何實現的。例如:
-
基準 EMR 執行時設定未完全披露:尚不清楚,例如Spark 的動態分配功能是否被禁用,因為它有可能對測量產生不可預測的影響。
-
用於基準測試的程式碼是 Delta 基準測試框架的擴充套件,不幸的是它也沒有公開共用,因此無法檢視或重複相同的實驗。
-
無法存取程式碼也會影響分析應用於 Hudi/Delta/Iceberg 的設定的能力,這使得評估公平性具有挑戰性
3. 我們建議如何執行基準測試
我們會定期執行效能基準測試,以確保一起提供Hudi 豐富的功能集與基於 Hudi 的 EB 資料湖的最佳效能。我們的團隊在對複雜分散式系統(如 Apache Kafka 或 Pulsar)進行基準測試方面擁有豐富的經驗,符合上述原則。
為確保已釋出的基準符合以下原則:
- 我們關閉了 Spark 的動態分配功能,以確保我們在穩定的環境中執行基準測試,並消除 Spark 叢集決定擴大或縮小規模時結果中的任何抖動。 我們使用 EMR 6.6.0 版本,Spark 3.2.0 和 Hive 3.1.2(用於 HMS),具有以下設定(在建立時在 Spark EMR UI 中指定)有關如何設定 HMS 的更多詳細資訊,請按照說明進行操作 在README檔案中
[{
"Classification": "spark-defaults",
"Properties": {
"spark.dynamicAllocation.enabled": "false"
}
}, {
"Classification": "spark",
"Properties": {
"maximizeResourceAllocation": "true"
}
}, {
"Classification": "hive-site",
"Properties": {
"javax.jdo.option.ConnectionURL": < hive_metastore_url > ,
"javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionUserName": < username > ,
"javax.jdo.option.ConnectionPassword": < password >
}
}]
- 我們已經公開分享了我們對 Delta 基準測試框架的修改,以支援通過 Spark Datasource 或 Spark SQL 建立 Hudi 表。 這可以在基準定義中動態切換。
- TPC-DS 載入不涉及更新。 Hudi 載入的 databeans 設定使用了不適當的寫入操作
upsert,而明確記錄了 Hudibulk-insert是此用例的推薦寫入操作。 此外,我們調整了 Hudi parquet 檔案大小設定以匹配 Delta Lake 預設值。
CREATE TABLE ...
USING HUDI
OPTIONS (
type = 'cow',
primaryKey = '...',
precombineField = '',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
-- Disable Hudi’s record-level metadata for updates, incremental processing, etc
'hoodie.populate.meta.fields' = 'false',
-- Use 「bulk-insert」 write-operation instead of default 「upsert」
'hoodie.sql.insert.mode' = 'non-strict',
'hoodie.sql.bulk.insert.enable' = 'true',
-- Perform bulk-insert w/o sorting or automatic file-sizing
'hoodie.bulkinsert.sort.mode' = 'NONE',
-- Increasing the file-size to match Delta’s setting
'hoodie.parquet.max.file.size' = '141557760',
'hoodie.parquet.block.size' = '141557760',
'hoodie.parquet.compression.codec' = 'snappy',
– All TPC-DS tables are actually relatively small and don’t require the use of MT table (S3 file-listing is sufficient)
'hoodie.metadata.enable' = 'false',
'hoodie.parquet.writelegacyformat.enabled' = 'false'
)
LOCATION '...'
Hudi 的起源植根於增量資料處理,以將所有老式批次處理作業變成增量。 因此,Hudi 的預設設定面向增量更新插入和為增量 ETL 管道生成更改流,而將初始負載視為罕見的一次性操作。 因此需要更加註意載入時間才能與 Delta 相媲美。
4. 執行基準測試
4.1 載入

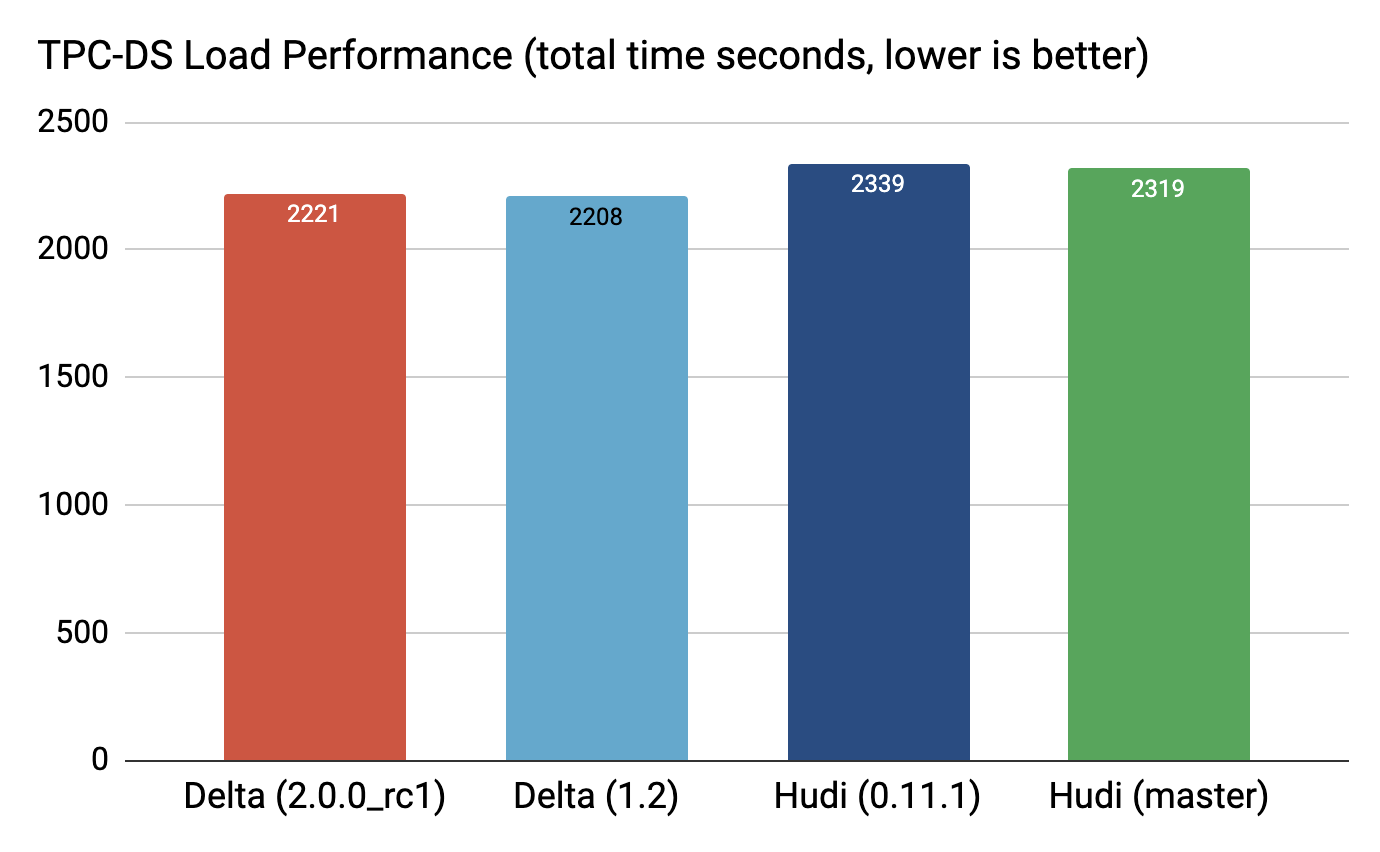
可以清楚地看到,Delta 和 Hudi 在 0.11.1 版本中的誤差在 6% 以內,在當前 Hudi 的 master* 中誤差在 5% 以內(我們還對 Hudi 的 master 分支進行了基準測試,因為我們最近在 Parquet 編碼設定中發現了一個錯誤 已及時解決)。
為 Hudi 在原始 Parquet 表之上提供的豐富功能集提供支援,例如:
還有更多,Hudi 在內部儲存了一組額外的後設資料以及每條稱為元欄位的記錄。 由於 tpc-ds 主要關注快照查詢,在這個特定的實驗中,這些欄位已被禁用(並且未計算),Hudi 仍然將它們保留為空值,以便在未來開啟它們而無需模式演進。 新增五個這樣的欄位作為空值,雖然開銷很低,但仍然不可忽略。
4.2 查詢
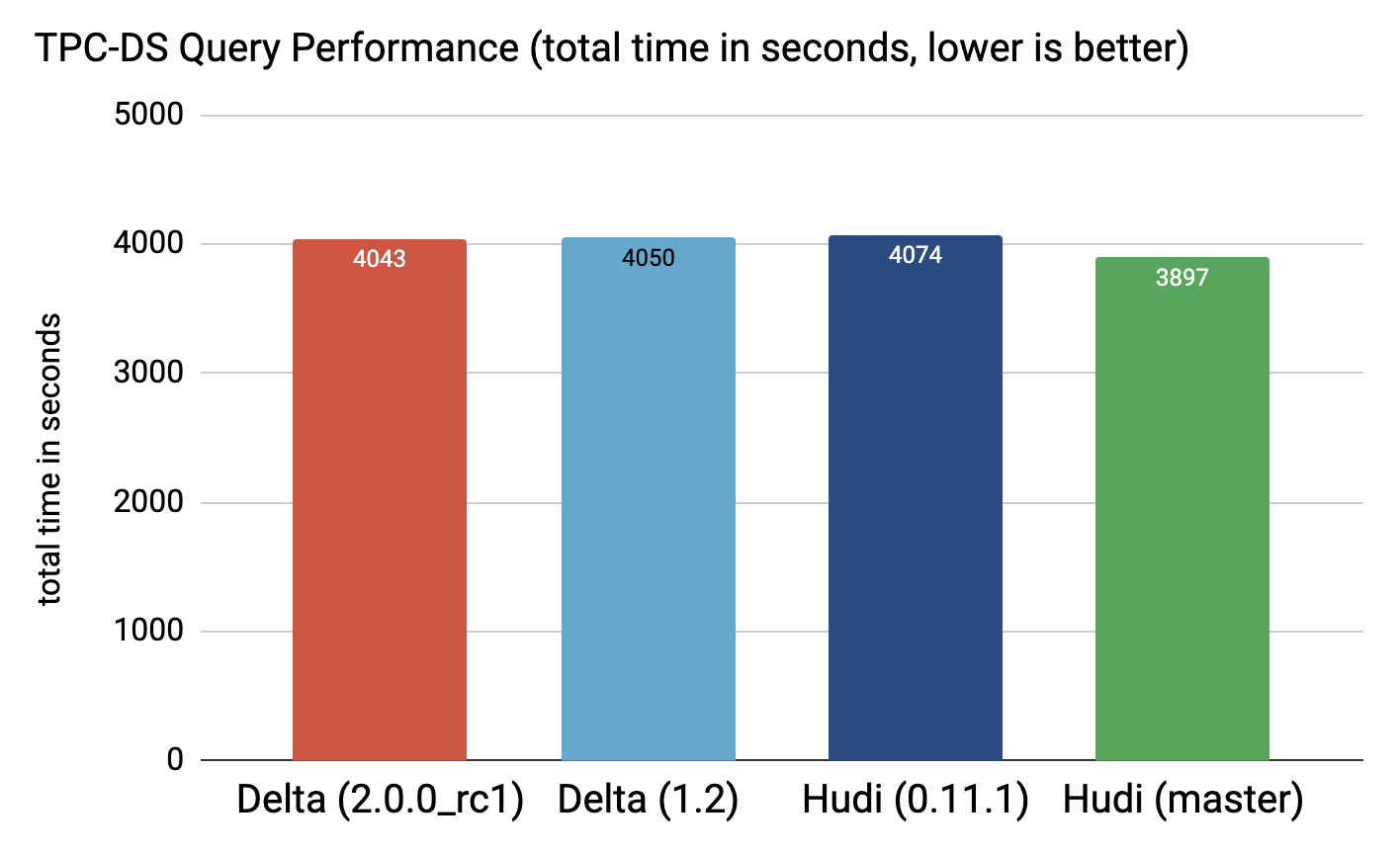
正如我們所見,Hudi 0.11.1 和 Delta 1.2.0 的效能幾乎沒有區別,而且 Hudi 目前的 master 速度要快一些(~5%)。
您可以在 Google Drive 上的此目錄中找到原始紀錄檔:
要重現上述結果,請使用我們在 Delta 基準儲存庫 中的分支並按照讀我檔案中的步驟進行操作。
5. 結論
總而言之,我們想強調開放性和可重複性在效能基準測試這樣敏感和複雜的領域的重要性。 正如我們反覆看到的那樣,獲得可靠和值得信賴的基準測試結果是乏味且具有挑戰性的,需要奉獻、勤奮和嚴謹的支援。
展望未來,我們計劃釋出更多內部基準測試,突出顯示 Hudi 豐富的功能集如何在其他常見行業工作負載中達到無與倫比的效能水平。 敬請關注!
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

