語言模型大串燒之變形金剛
- 詞嵌入
- 語言模型
- N-gram
- 困惑度perplexity
- word2vec 2013
- GloVe
- 子詞嵌入
- fastText 文字分類模型
- Skip-Thought Vectors
- NLP研究與應用模式
- ELMo 2018
- Seq2Seq
- Attention機制
- Transformer 2017
- Transformers-hub
- Longformer 2020
- GPT 2018~2020
- BERT 2018
- RoBERTa 2019
- Transformer-XL 2018
- XLNet 2019
- SpanBERT 2019
- StructBERT 2019
- MASS/BART 2019
- UniLM 2019
- T5 2019
- ALBERT 2019
- ELECTRA 2020
- DeBERTa 2020
- ERNIE 2019~2021
- 發展維度-位置編碼
- 發展維度-masking 改進
- MLM 擴充套件延伸
本文起筆於2019.8,更新於 2022.8。
主要介紹近十年來NLP領域的一些經典的語言模型,包括 Word2vec, ELMo, Transformer, GPT, BERT, XLNet, UniLM, T5, ALBERT, ELECTRA, DeBERTa, ERNIE 等。文中標題標註了各方法大致的年份,多數為論文公開的時間,方便按照時間線對比。從釋出年份上可以看出2019年是基於Transformer的NLP研究最熱的一年。但本文並未嚴格按照時間線來依次介紹各個模型。發展脈絡主要參考的文章如下,值的一讀:
-
從Word Embedding到Bert模型—自然語言處理中的預訓練技術發展史 - 張俊林的文章
詞嵌入
詞嵌入目的:表示文字、理解文字。
Embedding是一種典型的利用無監督資訊提升監督問題效果的手段。
當詞典容量比較大時,對單詞進行one-hot encoding或hash編碼得到的詞向量(word vectors)的特點是:稀疏、高維、寫死(hard-coded)。而用詞嵌入表示,特點與之相反:稠密、低維,並且可從資料中學習得到。
為了瞭解一個詞彙的含義,可以根據它的上下文(context)來得到。
比如兩句文字:
- 「小馬 520宣誓就職」
- 「阿蔡 520宣誓就職」
由於後文相同,因此可以認為「小馬」和「阿蔡B」之間有某種程度的相似性。
那麼,怎樣通過詞嵌入來表達這種相近的關係呢?
詞嵌入方式
基於計數的詞嵌入(count based)
如果兩個詞 \(w_i\) 和 \(w_j\) 頻繁共同出現,那麼對應的詞嵌入\(V(w_i), V(w_j)\)應當很接近。令:\(V(w_i)\cdot V(w_j)=N_{ij}\)即可用於優化求解,\(N_{ij}\)是 \(w_i\) 和 \(w_j\) 在檔案中的共現次數。這個概念跟matrix factorozation的概念很類似,這個方法的一個代表性的例子是Glove vector。
基於預測(prediction based)
模型:給定前邊的一個或若干個詞,預測下一個詞(預測詞集中每個詞是下一次出現的概率)。假定模型是多層感知機模型。
當我們訓練得到這樣一個預測模型之後,相似的詞應當具有相同的輸出,在多層感知機模型的第一個隱藏層應具有相近的表示,因此可以用第一個隱藏層當作word embedding。
這種由一個單詞的上文,去預測這個單詞的模型與Bengio 於2003年提出的神經網路語言模型(NNLM, JMLR2003)非常類似。NNLM的主要任務是要學習一個解決語言模型任務的網路結構,語言模型就是要看到上文預測下文。
模型推廣:前面說的模型是由前幾個詞預測下一個詞,可以推廣到由上下文預測當前詞,即CBOW模型。以及拿中間的詞彙預測context,即Skip-gram.
多語言嵌入:Multi-lingual Embedding,比如中英文,如果詞彙之間存在一一對應的關係(如「咖啡」與cofee),那麼我們如何使得機器能夠知道不同語言的詞對應同一含義?可以在得到中英文的不同embedding之後,再訓練一個模型分別將中英文對映到同一空間內比較接近的位置。
語言模型
首先介紹最基礎的N-gram模型,再介紹Word2vec,然後依次介紹現代的基於深度學習的語言模型,如BERT預訓練模型。
預訓練語言模型發展維度有很多,例如多模態、跨語言、粒度範圍、位置編碼等。
粒度範圍維度 :從粗粒度學習、細粒度學習,向多粒度學習發展
位置編碼維度 :從絕對位置編碼、相對位置編碼,向混合位置編碼發展
本文僅介紹部分維度和模型。
N-gram
N元語法是基於n-1階馬爾科夫鏈的概率語言模型,其中n衡量了計算複雜度和模型準確性。N元語法模型通過馬爾科夫假設簡化了語言模型的計算,雖然該假設並非一定成立。馬爾科夫假設是指一個詞的出現只與前面n個詞相關,即n階馬爾科夫鏈(Markov chain of order n),基於n-1階馬爾科夫鏈,語言模型為:
困惑度perplexity
困惑度(Perplexity, PP)是對交叉熵損失函數做指數運算後得到的值,常用於評價語言模型的好壞,是一個簡單、行之有效的評測指標。
設N-gram模型 \(M = P(w_i|w_{i-N+1}...w_{i-1})\) 的交叉熵損失為 \(H(W)=-{1\over N}\log_2 P(w_1w_2...w_N)\)
困惑度定義為:
句子的概率越大,語言模型越好,困惑度越小。N-gram給的單詞序列資訊越多,困惑度也越低。當然降低困惑度不一定保證能夠提高NLP任務的效能。
參考:Speech and Language Processing
word2vec 2013
- Efficient Estimation of Word Representations in Vector Space
- Distributed Representations of Words and Phrases and their Compositionality
word2vec(NIPS 2013)可以把對文字內容的處理簡化為K維向量空間中的向量運算,而向量空間的相似度可以用來表示文字語意上的相似度。而one-hot表示無法準確表達不同詞之間的相似度,比如餘弦相似度為0。word2vec將每個詞表示成一個定長的向量,比one-hot的維度低很多。把詞對映為實數域向量的技術也叫詞嵌入。
Word2Vec 是一種淺層的神經網路模型, 它有兩種網路結構, 分別是 CBOW(Continues Bag of Words) 和 Skip-gram. 兩種網路結構均包含一個隱藏層,通過權重矩陣W將輸入的one-hot編碼對映到低維詞向量。CBOW 的目標是根據上下文出現的詞語來預測當前詞的生成概率; 而 Skip-gram 是根據當前詞來預測上下文中各詞的生成概率.
Distributed Representation
word2vec使用的是一種分散式表示,這種表示方式最早由Hinton在1986年提出。其基本思想是通過訓練將每個詞對映成 K 維實數向量(K 一般為模型中的超引數),通過詞之間的距離(比如 cosine 相似度、歐氏距離等)來判斷它們之間的語意相似度。
Skip-Gram
Skip-Gram模型假設基於某 個 詞 來 生 成 它 在 文 本 序 列 周 圍 的 詞。 假設存在一個 w1,w2,w3,...,wT 的片語序列,Skip-gram 的目標是最大化似然函數,\(\prod_{t=1}^T\prod_{-c\le j\le c,j\ne 0} p(w_{t+j}|w_t)\),即最小化損失:
c越大,則需要考慮的 pair 就越多,一般能夠帶來更精確的結果,但是訓練時間也會增加。
假設中心詞在詞典中索引為i,當它為中心詞時向量表示為vi ,而為背景詞時向量表示為ui 。設中心詞wc 在詞典中索引為c,背景詞wo 在詞典中索引為o,給定中心詞生成背景詞的條件概率可以通過對向量內積做softmax運算而得到(V為詞典索引集):
若使用隨機梯度下降,那麼在每一次迭代裡我們隨機取樣一個較短的子序列來計算有關該子序列的損失,然後計算梯度來更新模型引數。對於每個中心詞向量,通過梯度進行更新:
訓練結束後,對於詞典中的任一索引為i的詞,我們均得到該詞作為中心詞和背景詞的兩組詞向量vi 和ui 。在自然語言處理應用中,一般使用跳字模型的中心詞向量作為詞的表徵向量。
CBOW
CBOW 是 Continuous Bag-of-Words Model 的縮寫,CBOW 模型是預測 \(P(w_t|w_{t-k},w_{t-(k-1)},...,w_{t-1},w_{t+1},w_{t+2},...,w_{t+k})\)。連續詞袋模型假設基於某中心詞在文字序列前後的背景詞來生成該中心詞。因為連續詞袋模型的背景詞有多個,我們將這些背景詞向量取平均,然後使用和跳字模型一樣的方法來計算條件概率。
梯度更新時將平均值的更新量整個應用到每個參與平均的詞向量上去。一般使用連續詞袋模型的背景詞向量作為詞的表徵向量。
CBOW和Skip-Gram都將\(w_i\)作為條件詞(背景詞)時的詞向量記為\(v_i\),作為目標詞詞向量時記為\(u_i\),在下游應用中使用作為條件詞時的向量。
淺層神經網路
可以將Word2vec視作兩層的神經網路,包含輸入層、隱藏層、輸出層。網路引數為輸入和輸出權重矩陣 \(W_I, W_O\). 背景詞向量對應輸入矩陣,目標詞向量對應輸出矩陣,在下游應用中採用輸入矩陣作為初始化embedding。
近似訓練
Skip-gram 的核心在於使用softmax運算得到給定中心詞wc 來生成背景詞wo 的條件概率:\(p(w_o|w_c)={\text{exp}(u_o^Tv_c)\over\sum_{i\in V}\text{exp}(u_i^Tv_c)}\),以及該條件概率相應的對數損失。無論Skip-Gram或CBOW的softmax運算的背景詞可能是詞典V中的任一詞,對於含幾十萬或上百萬詞的較大詞典,每次的梯度計算開銷可能過大。為了降低該計算複雜度,本節將介紹兩種近似訓練方法,即負取樣(negative sampling)、層序softmax(hierarchical softmax)。
-
負取樣
負取樣修改了原來的目標函數。給定中心詞wc 的一個背景視窗,我們把背景詞wo 出現在該背景視窗看作一個事件,並將該事件的概率計算為\(P (D = 1 | w_c , w_o ) = σ(u_o^⊤ v _c )\), σ函數定義為sigmoid啟用函數(將softmax替換為了sigmoid簡化計算,不依賴整個大詞表)。目標是最大化聯合概率:\(\prod_{t=1}^T\prod_{-c\le j\le c,j\ne 0}P(D=1|w_t,w_{t+j})\).
然而,以上模型中包含的事件僅考慮了正類樣本。這導致當所有詞向量相等且值為無窮大時,以上的聯合概率才被最大化為1。很明顯,這樣的詞向量毫無意義。負取樣通過取樣負類樣本使目標函數更有意義。設背景詞\(w_o\) 出現在中心詞\(w_c\) 的一個背景視窗內為事件\(P\) , 對每一箇中心詞根據分佈\(P (w)\)取樣\(K\)個未出現在該背景視窗中的詞,即噪聲詞。條件概率近似為:
\[P(w^{(t+j)} \mid w^{(t)}) =P(D=1\mid w^{(t)}, w^{(t+j)})\prod_{k=1,\ w_k \sim P(w)}^K P(D=0\mid w^{(t)}, w_k) \]負取樣通過考慮同時含有正類樣本和負類樣本的相互獨立事件來構造損失函數。其訓練中每一步的梯度計算開銷與取樣的噪聲詞的個數線性相關。論文中將取樣概率設定為正比於詞的頻率的3/4次方(實現中會進行歸一化)。
-
層序softmax
層序softmax是另一種近似訓練法。它使用了二元樹這一資料結構,樹的每個葉結點代表詞典V中的每個詞。通過哈夫曼樹的構造方式,將詞典根據詞頻等資訊構造成一棵二元樹。對於跳字模型中的條件概率\(P(w_o|w_c)\),將其視為讓\(w_c\)從根節點開始走,能夠走到\(w_o\)葉節點的概率。對於每一步,向左還是向右走是一個二分類問題。可以用邏輯迴歸中的sigmoid來得到向左走的概率\(p=\sigma(\theta w_c)\),向右走的概率為\(1-p=1-\sigma(\theta w_c)=\sigma(-\theta w_c)\). 而每個節點儲存了邏輯迴歸的引數\(\theta\).
假設\(L(w)\)為從二元樹的根結點到詞\(w\)的葉結點的路徑(包括根結點和葉結點)上的結點數。設\(n(w, j)\)為該路徑上第 j 個結點,並設該結點的背景詞向量為\(\mathbf{u}_{n(w, j)}\) ,背景詞向量充當了\(\theta\)的作用。層序softmax將跳字模型中的條件概率近似表示為
\[P(w_o|w_c)=\prod_{j=1}^{L(w_o)-1}\sigma(\text{sign}[n(w_o,j+1)=\text{leftChild}(n(w_o,j))]\cdot u^T_n(w_o,j)v_c) \]式中如果節點\(n(w_o,j+1)\)是節點\(n(w_o,j)\)的左孩子,則sign為1,反之為-1.
層序softmax使用了二元樹,並根據根結點到葉結點的路徑來構造損失函數。其訓練中每一步的梯度計算開銷與詞典大小的對數相關(\(\mathcal O(\log_2 |V|)\))。每一層的節點相當於神經網路隱藏層的神經元。
層次化的Softmax的思想實質上是將一個全域性多分類的問題,轉化成為了若干個二元分類問題,從而將計算複雜度從O(V)降到O(logV)。在做Hierarchical Softmax之前,我們需要先利用所有詞彙(類別)及其頻次構建一棵霍夫曼樹。這樣,不同詞彙(類別)作為輸出時,所需要的判斷次數實際上是不同的。越頻繁出現的詞彙,離根結點越近,所需要的判斷次數也越少。從而使最終整體的判斷效率更高。[1]
對比選擇
Mikolov 關於超引數的建議如下:
- 模型架構:Skip-gram 更慢一些,但是對低頻詞效果更好; CBOW 則速度更快一些。為什麼?CBOW對context取了平均,計算量較小(減少了softmax的次數),並且生僻詞由於與高頻詞取平均,預測效果降低。
- 訓練演演算法:層次 softmax 對低頻詞效果更好(不存在按頻次取樣的問題); negative sampling 對高頻詞效果更好,向量維度較低時效果更好。
Subsampling
在實際應用中需要對過於低頻和高頻的詞彙做處理:
-
低頻詞:統一處理成
<unk>標記,減少詞表的大小 -
高頻詞:從句子中隨機抹除,詞頻越高,設定drop out概率越大:
\[P(w_i) = \max\left(1 - \sqrt{\frac{t}{f(w_i)}}, 0\right) \]閾值t=1e-4, f(w)為頻率,在\(f(w_i) > t\) 時才會進行隨機抹除。高頻詞與很多詞的共現頻次都很高,通過隨機抹除,能夠消減高頻詞對訓練的影響。
哈夫曼樹構建演演算法
在word2vec和fastText中的層序softmax均涉及到哈夫曼樹的構建,構建過程為迭代查詢當前權重最小的兩個子樹,並將它們合併。不同的實現方式導致不同的時間和空間複雜度:
- 每次線性查詢最小的子樹:時間O(n^2), 空間O(1)
- 使用優先順序佇列維護堆查詢最小值:時間O(nlog n),空間O(n),堆操作較頻繁。
- 使用固定長度為2n的陣列存放葉子節點與新合併節點:時間O(nlog n),空間O(n)。
下面介紹word2vec和fastText工具中所使用的第三種方法:
長度為2n的陣列(n為葉子節點數)前半部分儲存每個葉子節點的詞頻,降序排列。後半部分隨著迭代查詢合併的過程依次插入新節點。用兩個指標leaf、node分別指向當前迭代過程中剩餘未合併的葉子節點、非葉子節點中的最小詞頻節點。迭代一次,找出leaf、node兩者的最小值,若leaf最小,將leaf指標向左移動一位,否則將node指標向右移動一位。繼續第二次迭代找到第二小的值(同時左移或右移),將當前找到的兩個最小值合併後插入陣列右半部分的後邊。由於左半部分是降序,右半部分是增序(每次合併,值會不斷增加),所以兩個指標向相反的方向移動。演演算法只用了一次排序 + 一次遍歷,簡潔優雅。
QA
Word2Vec中的條件概率是怎麼算出來的?
- 兩個單詞間的相似度:詞向量求內積
- 一個單詞與詞典中所有詞的相似度通過softmax轉概率得到條件概率(該單詞出現的條件下詞典中每個詞是下一個出現的概率)
為什麼條件概率的計算採用了向量的內積?
- 歸一化之後的兩個向量的內積正是cosine相似度,因此兩個向量越相近,計算出的條件概率也越大。
為什麼word2vec中的詞向量同時用中心詞和背景詞向量來表示?
- 數學形式上更簡單,如果只用一個向量來表示,那麼Softmax計算的概率公式裡分母會出現一項平方項\(e^{v_c\cdot v_c}\) 那麼再對 \(v_c\) 求導就會比較麻煩。相反如果用兩套詞向量,求導結果就會很乾淨。但其實,因為在視窗移動的時候,先前視窗的中心詞會變成當前視窗的上下文詞,先前視窗的某一個上下文詞會變成當前視窗的中心詞。所以這兩組詞向量用來訓練的詞對其實很相近,訓練結果也會很相近。一般做法是取兩組向量的平均值作為最後的詞向量。參考CS224N
- 一個詞出現在以自己為中心的視窗內的概率很小,向量相乘運算的結果也應當比較小,如果只用一個向量表示,\(v\cdot v\) 計算結果很難保證較小值。
Negative Sampling是主要解決什麼問題?
softmax計算量大的問題,也就是解決分類數量過大的問題。
為什麼Word2Vec負取樣訓練中需要對權重開3/4次冪?
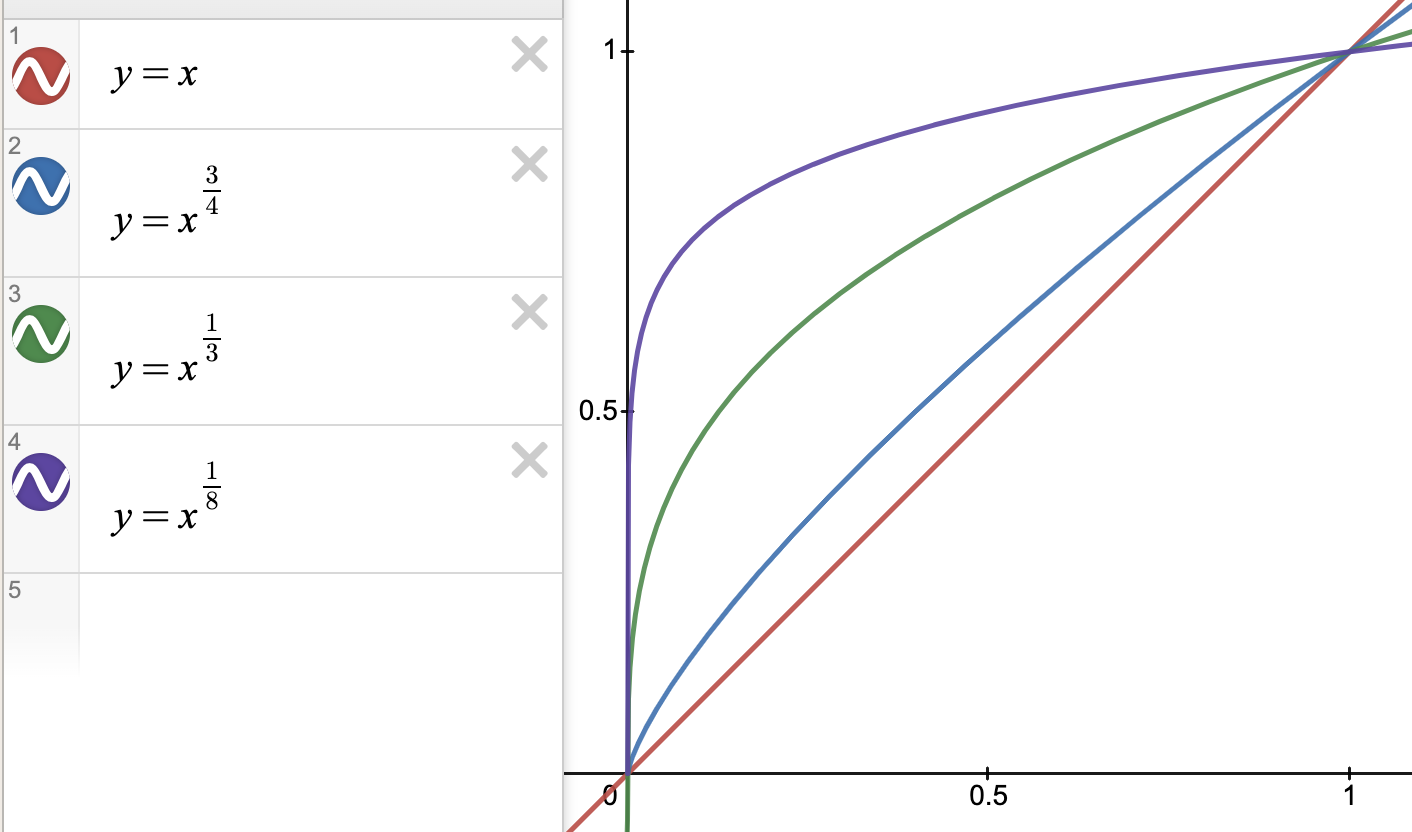
在保證高頻詞容易被抽到的前提下,通過權重 3/4 次冪的方式,適當提升低頻詞、罕見詞被抽到的概率,避免低頻詞、罕見詞很難被抽到,以至於不被更新對應 Embedding 的情況。而選擇3/4這個數值是靠經驗選擇嘗試出來的,也可以選擇其它小於1的數。可以結合 \(y=x^k\) 的函數影象來看,k越接近0,y越接近1,並且y>=x,這樣低頻詞的權重會被放大,通過輪盤賭被選中的概率也會增加。參考:為什麼Word2Vec訓練中, 需要對負取樣權重開3/4次冪?
參考:
GloVe
Word2vec在預估條件概率 \(P(w_j \mid w_i)\) 時採用了Softmax,不僅計算量大,而且在非常見詞較多時在損失函數中累加較小的值會導致條件概率計算的不準確。
GloVe[2]從另外的角度來預估 \(P(w_j \mid w_i)\),避免Word2vec中的這兩個問題。
將 \(w_j\) 出現在 \(w_i\) 的上下文視窗中的次數記為 \(x_{ij}\), \(w_i\) 的上下文視窗中的word數累加得到 \(x_i\),定義條件概率 \(p_{ij}=x_{ij}/x_i\).
GloVe 用兩個word的預估概率 \(P(w_j \mid w_i)\) 相除,即可去除Softmax函數中共同的分母,並以此來擬合從整體樣本中統計出的兩個條件概率 \(p_{ij}\) 的比值:
接著,再做一步近似:\(\exp\left(\mathbf{u}_j^\top {\mathbf{v}}_i\right) \approx \alpha p_{ij} = \alpha x_{ij}/x_i\). 其中\(\alpha\)是常數。
兩邊取log:\(\mathbf{u}_j^\top {\mathbf{v}}_i \approx \log\,x_{ij} + \log\,\alpha - \log\,x_i\)
用兩個word的bias之和來代替 \(- \log\, \alpha + \log\, x_i\). 得到\(\mathbf{u}_j^\top \mathbf{v}_i + b_i + c_j \approx \log(x_{ij})\).
採用平方誤差作為損失,並新增每一項的權重 \(h(x)\),最終損失函數定義為:
\(h(x)\) 設定為單調遞增的函數: 當 x<c (e.g c=100)時 \(h(x)=(x/c)^α\) (e.g α=0.75), 否則 h(x)=1.
在每次SGD中隨機取樣一個 \(x_{ij}\) 作為minibatch。這些非零值 \(x_{ij}\) 提前在整個資料集上計算好,由於包含資料集的全域性統計資訊,因此該方法取名「Global Vectors」.
在GloVe中單詞作為中心詞和作為背景詞的向量是相同的,採用了相同的學習方式。但是由於隨機初始化時初始值的不同導致最後學習出來的向量不相同,在下游應用中使用時採用兩者之和(一些經驗表明訓練同一個神經網路多次,並組合最終的結果能一定程度上提高效果,減少過擬合和噪聲)。
在從樣本中統計 \(p_{ij}\) 時還可以考慮兩個word的間距,對距離較遠的兩個word,雖然出現在設定的固定大小的視窗內,但是相關性會差一些。論文中將兩個word之間的間隔數 d 的倒數 1/d 作為 \(p_{ij}\) 的權重。
Glove這種訓練詞向量的方法的核心思想是通過對「詞-詞」共現矩陣進行分解從而得到詞表示的方法。
設 \(N_{ij}\) 是 \(w_i\) 和 \(w_j\) 在檔案中的共現次數,令:\(V(w_i)\cdot V(w_j)=N_{ij}\) 即可用於優化求解。這個概念跟matrix factorozation很類似。
Q:glove 與 word2vec 效能比較?
GloVe 的訓練速度更快,然而詞向量的效能在通用性上弱一些,僅在少量任務上表現優於 Word2Vec,在多數任務上比 Word2Vec 差。
參考:
子詞嵌入
在word2vec中,我們並沒有直接利用構詞學(morphology)中的資訊。構詞學作為語言學的一個重要分支,研究的正是詞的內部結構和形成方式。比如單複數cat,cats在word2vec中使用了不同的向量表示,而模型中並未直接表達這兩個向量之間的關係。鑑於此,Facebook的論文Enriching Word Vectors with Subword Information[3]提出了子詞嵌入(subword embedding)的方法,從而試圖將構詞資訊引入word2vec中的skip-gram跳字模型中。在該方法中,每個中心詞被表示成子詞的集合,將中心詞向量表示成單詞的子詞向量之和。子詞嵌入利用構詞上的規律,通常可以提升生僻詞表示的質量。較生僻的複雜單詞,甚至是詞典中沒有的單詞(未登入詞),可能會從同它結構類似的其他詞那裡獲取更好的詞向量表示。
論文提出了一種方法學習字元級的n-grams表徵向量,用子字元n-grams表徵向量的和來表示原詞,這樣具有相同詞根的詞有較高的相似度。字元級的n-grams範例如下:對於單詞「where」,在兩端新增特殊字元「<」和「>」以區分作為前字尾的子詞。當n=3時,我們得到所有長度為3的子詞:「<wh」,「whe」,「her」,「ere」,「re>」以及特殊子詞「<where>」。
對於一個詞w,我們將它所有長度在3∼6的子詞和特殊子詞的並集記為\(\mathcal{G}_w\)。那麼詞典則是所有詞的子詞集合的並集。假設詞典中子詞g的向量為\(\boldsymbol{z}_g\),那麼跳字模型中詞w的作為中心詞的向量\(\boldsymbol{v}_w\)則表示成
子詞數量過多帶來的問題
子詞數量過多導致記憶體需求較大,為了應對這一問題,論文提出採用雜湊函數將所有子詞對映到一個固定大小為K的列表中,用下標來表示子詞。雜湊函數採用Fowler-Noll-Vo hash(FNV-1a變體),需要考慮雜湊衝突帶來的效能影響。
Subword演演算法與傳統空格分隔tokenization技術的對比優勢:
- 傳統詞表示方法無法很好的處理未知或罕見的詞彙(OOV問題)
- 傳統詞tokenization方法不利於模型學習詞綴之前的關係
子詞嵌入應用
子詞嵌入的方法除了用於skip-gram同樣可以用於CBOW,並能使用負取樣或層序softmax來加速訓練。但是在原word2vec基礎上新增子詞嵌入導致詞典規模更大,模型引數更多,同時一個詞的向量需要對所有子詞向量求和,繼而導致計算複雜度更高。
fastText工具採用了子詞嵌入的方法。
byte pair encoding (BPE)
採用了子詞嵌入之後n-gram字典的大小不能預先定義,為了在固定字典大小的情況下支援變長的子詞,可以應用byte pair encoding (BPE)[4]方法來提取子詞。BPE及其變體已經在GPT-2、RoBERTa等較現代的NLP模型中有所應用。
BPE的基本思想為:設定子詞字典的容量m,初始統計單個字元[a-z]的頻次,加入字典。開始迭代:選擇頻次最高的兩個子詞組合後統計頻次,加入字典。迭代過程同哈夫曼編碼的貪心過程,直至字典滿為止。生成字典之後從長到短排序得到vocab詞表。
在用一份預料得到BPE字典之後,對一個詞(可以是不同的預料、資料集中的詞)進行劃分子詞的過程為:從前往後依次貪心匹配字典中最長的子詞。
注:在處理子詞時對結尾子詞新增一個特徵的字尾,如</w>來區分字尾與開頭或中間出現的相同的子詞,因為通常會有不同的意義。
Wordpiece
BERT原始碼中採用的WordpieceTokenizer來對文字進行分割,轉換為token id。使用 貪婪最長匹配優先演演算法(greedy longest-match-first algorithm) 從左往右不重疊地將一段文字進行 tokenization ,變成相應的 wordpiece,主要針對英文。
在BERT中將漢字當做unicode單字字元處理的,因此WordpieceTokenizer不起作用,只在英文單詞上產生作用。如 "unaffable" → ["un", "##aff", "##able"]。其中字首##表示子詞間的連線符。
如果要用這種思想來處理中文,我理解的應該是將中文文字分詞當做word,將單字或偏旁部首分形作為piece處理,分詞粒度通常包括短語粒度與基礎粒度。在ERNIE 1.0中則對中文做了處理,分詞作為word(分詞方式不限於簡單的貪婪最長匹配或專業的漢語分詞工具),並在vocab.txt中包含##字首的漢字單字piece,在WordpieceTokenizer中與英文處理方式一致。
BERT所採用的Wordpiece演演算法與BPE演演算法很相似,僅僅是合併token時選擇的屬性不同。BPE選擇用頻率,Wordpiece選擇用概率(互資訊)。即BPE 選擇頻數最高的相鄰子詞合併,而 WordPiece 選擇能夠提升語言模型概率最大的相鄰子詞加入詞表。
Wordpiece及後來提出的Unigram Language Model都利用語言模型建立subword詞表。
注:生成詞表(vocab.txt)的程式碼未包含在BERT WordpieceTokenizer中,我們可直接使用開源專案中生成好的各語言的vocab.txt詞表或者根據自己的具體任務的語料來生成。
參考:
fastText 文字分類模型
論文Bag of Tricks for Efficient Text Classification提出了用於文字分類的fastText方法,開原始碼見 github 及 fasttext網站(包含多種語言的預訓練詞向量)。fastText開源、免費、輕量級,適用於文字分類和文字向量化表示場景,執行於標準硬體環境。裁剪壓縮過的模型甚至可以輕鬆跑在移動裝置上。值的注意的是fastText相關的三篇論文的作者均包括word2vec論文的作者 Tomas Mikolov。
fastText做文字分類的思想非常簡單,對文字分類的baseline方法( 使用bag of words (BoW) 訓練一個線性分類器)稍加改進:
- BoW沒有保留次序資訊,採用n-gram來保留區域性的次序資訊(這裡指的是單詞word級別的n-gram,而非字元char級別的)。該論文並未提及和參照前作Enriching word vectors with subword information中的子詞嵌入思想(字元級n-gram),但fastText工具中可以使用子詞嵌入,在預測時可以得到未登入詞的向量。
- 對一個句子的詞級 n-gram在lookup table中的低秩向量加和平均作為線性分類模型的輸入特徵。這裡的lookup table與word2vec一樣都是隨機初始化並可學習。
分類器部分採用線性模型:f(Wx),並採用層次 softmax 來計算類別概率、計算損失。
論文和char-CNN等基於GPU的深度模型在Sogou等資料集上做了效能和速度的對比實驗,表現不俗。
論文主要提出了文字分類模型,詞向量只是其中的副產物。但是fastText工具的實現中除了分類模型,還提供了專用於詞向量表示的CBOW、skip-gram模型,並且共用了一套介面。程式碼相比word2vec原始版本更具可讀性,模組化程度較好。
由於單詞級別 n-gram 的數量遠大於 word 的數量,完全儲存不現實,為了節省空間,fastText工具對n-gram做了hash分桶,hash到同一個位置的多個n-gram會共用同一個embedding,潛在的問題是存在雜湊衝突。此外,該工具還支援模型壓縮,以便在移動裝置上執行。
實踐經驗表明,fastText更適用於樣本數量大、類別標籤多的任務,一般能夠得到很好的效果,大多數情況下強於傳統的BOW + LR/SVM分類器。
fastText在多個方面體現它的fast:
- 輕量級,結構簡單,沒有采用深度網路
- fastText採用了層序Softmax
- 支援模型壓縮:參考FastText.zip: Compressing text classification models
fastText與word2vec訓練目標不一致:
- fastText 預測目標為檔案的類別,屬於分類模型,詞向量屬於附屬產物。而word2vec的訓練目的僅為得到詞向量。
- word2vec的葉子節點是詞和詞頻,fastText葉子節點是類標和類標的頻數。
為什麼有時候層序softmax比原始full softmax的效能指標差?
- 層序softmax對原softmax做了近似,使得執行效率更高,但往往會損失一定的效能,尤其在類別不平衡時。如果類別較平衡的話可以嘗試負取樣,但測試時需要使用full softmax會相對慢一些。
沒考慮詞序資訊?
- cbow,skipgram,以及fasttext分類模型,都放棄了詞序資訊(fastText通過單詞級的n-gram考慮了區域性詞序資訊)。如果考慮詞序資訊,短文字可以考慮用一維折積來捕捉,稍微長一點的文字,可以用lstm.
層序softmax預測時為什麼採用深度優先遍歷?
在訓練fastText時採用Hierarchical softmax,在測試時也需要採用樹形結構得到每個類別的概率值。當類別數較大時,線性查詢最大概率的值時間複雜度O(k),而採用深度優先遍歷來找到概率值最大的類別時間複雜度可以是O(log k)。
樹的每個葉子節點是不同的類別,設類別數為k,則樹的深度為log k。從根節點走到葉子節點將每個節點的二分類概率值累乘後得到葉子節點的類別概率,因此走到每個節點時累積概率值總是小於其父節點的累積概率值。在dfs走的過程記錄當前已經走過的葉子節點裡邊的最大值,在繼續走時發現當前節點的累積概率值小於已經發現的最大值,則停止向前,直接回溯。因此預測時的時間複雜度從softmax的O(k)變成層次softmax的O(log k). 如果要給出概率值最大的top T個類別,則採用優先順序佇列(小頂堆),時間複雜度O(log T).
參考:
Skip-Thought Vectors
Skip-Thought Vectors(NIPS 2015)藉助於 skip-gram 的思想實現了 Sentence2vector,即句子的表示向量,可以更方便地用於文字相似性判斷、文字分類等任務。
在skip-thought中利用中心句子來預測上下文的句子,輸入 \(s_t\) ,輸出 \((s_{t−1},s_{t+1})\) ,模型結構採用在機器翻譯中最常用的 Encoder-Decoder 架構(具體實現採用GRU、LSTM),用Encoder的輸出作為最終句子的表示向量。
資料集採用BookCorpus小說書籍中連續的句子,BookCorpus包含一萬多本書,七千多萬個句子,平均每個句子包含13個單詞,131w個單詞。範例如下:
連續的三個句子:「I got back home. I could see the cat on the steps. This was strange.」
對中間句子送入Encoder,相鄰句子送入兩個不同的Decoder。

詞彙擴充套件
論文在對BookCorpus做預處理後僅用了2w單詞,因此訓練後模型存在的一個問題是單詞數量較少,而英文詞彙常用詞也有三四萬,加上不常用詞、淘汰詞後可達百萬。因此未登入詞的問題比較嚴重。
在訓練完成後通過詞彙擴充套件將詞彙量擴充套件到百萬級別,使得對於訓練時未見過的多數詞能通過詞彙擴充套件找到近似的向量。具體的做法是:
1)用 Vw2v 表示訓練的Word2vec詞向量空間,用Vrnn 表示Skip-Thought模型中的詞向量空間,在這裡 Vw2v 數量遠大於 Vrnn 。
2)引入一個矩陣 W 來構建一個線性對映函數:f: Vw2v−>Vrnn 。使得有v′=Wv ,其中 v∈Vw2v,v′∈Vrnn 。
3)通過對映函數就可以將任何在 Vw2v 中的詞對映到 Vrnn 中。
其中第2點是受論文 "Tomas Mikolov, Quoc V Le, and Ilya Sutskever. Exploiting similarities among languages for machine translation. arXiv preprint arXiv:1309.4168, 2013." (對不同的語言空間通過線性對映得到word embedding)的啟發,權重 W 通過不加正則化的線性迴歸訓練得到。
這個線性對映的思想還可用於Image caption任務,給定圖片做文字分類或者通過文字檢索圖片,分別對圖片和文字的模型向量進行對映,在同一向量空間中計算相似度。
NLP研究與應用模式
研究方向:發展更強的特徵抽取器;如何優雅地引入大量無監督資料中包含的語言學知識。
應用模式:超大規模預訓練+具體任務Finetuing、具體任務特徵補充。
詞向量的應用
- 在大規模語料上預訓練的詞向量常常可以應用於下游自然語言處理任務中。
- 可以應用預訓練的詞向量求近義詞和類比詞。(比如運用KNN)
下游任務模型預訓練
Word Embedding 等價於把Onehot層到embedding層的網路用預訓練好的引數矩陣Q初始化了。句子中每個單詞以Onehot形式作為輸入,然後乘以學好的Word Embedding矩陣Q,就得到單詞對應的Word Embedding了,這類似於查表的操作。下游NLP任務在使用Word Embedding的時候也類似CV領域有兩種做法,一種是Frozen,就是Word Embedding那層網路引數固定不動;另外一種是Fine-Tuning,就是Word Embedding這層引數使用新的訓練集合訓練也需要跟著訓練過程更新掉。
Word Embedding對於很多下游NLP任務是有幫助的,但是幫助沒有特別明顯。Word Embedding存在一個缺點:多義詞的問題。一個詞的多種語意都被編碼到同一個embedding空間,這樣embedding混合了不同上下文中的語意,是靜態的,不能隨著上下文的改變而改變。一種相對簡潔優雅的解決方案是ELMo。
ELMo 2018
ELMo是「Embedding from Language Models」的簡稱,出自論文 Deep contextualized word representations(NAACL2018 最佳論文)。ELMo可以根據當前上下文對Word Embedding動態調整,ELMo 是第一個基於上下文的現代的語意理解模型。ELMo 使用了兩層雙向的LSTM,採用上下文語言模型進行預訓練。ELMo 的模型結構和下游任務的使用方法如下圖所示:
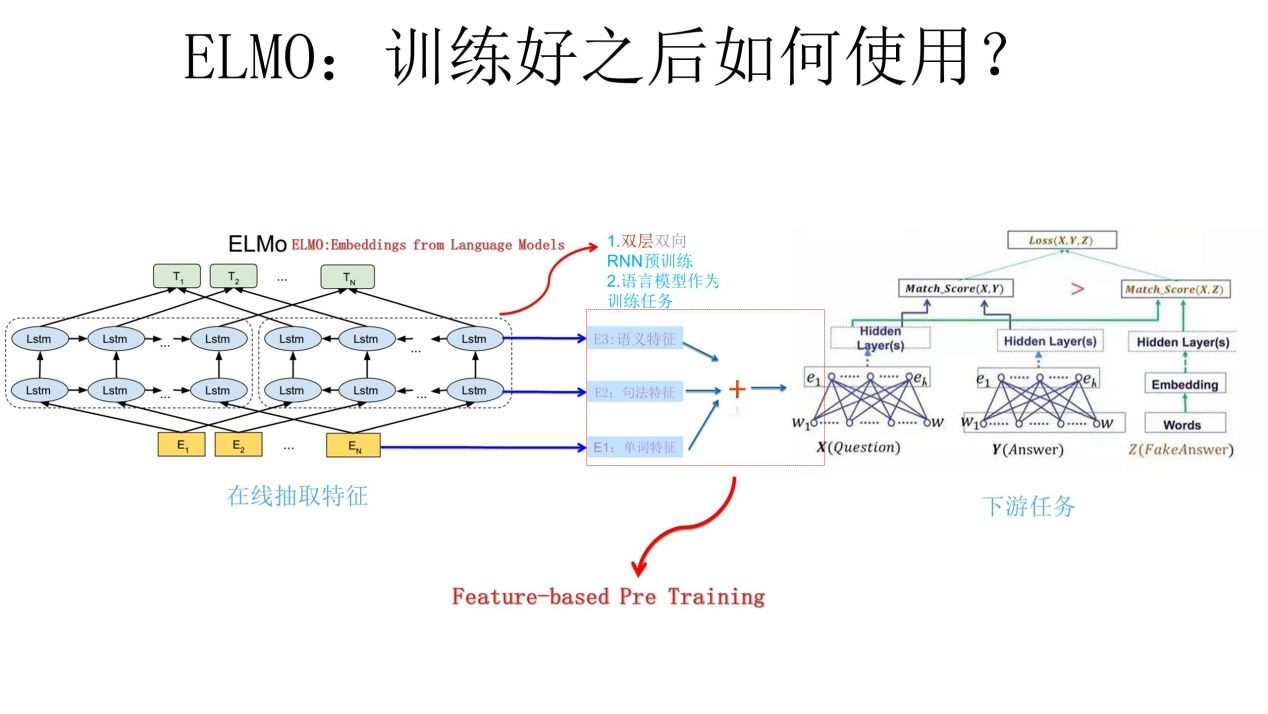
下游任務使用ELMo的方式為:將輸入資料送入ELMo得到三種特徵(單詞、句法、語意特徵),並將三種特徵按權相加(權重可以學習,並通過softmax層歸一化)並進行一定的scaling作為下游任務的輸入(scaling引數還是比較重要的,調整到合適的方差以更好的適應下游任務)。embedding輸出即:
其原始碼實現上也支援用Highway Net或者CNN來額外引入char-level encoding。
訓練採用語言模型標準的最大化似然函數,即
雙向的LSTM有各自的引數\(\overrightarrow\Theta_{LSTM},\overleftarrow\Theta_{LSTM}\),但是word embedding引數 \(\Theta_x\) 和softmax引數 \(\Theta_s\) 是共用的。
由於ELMO給下游提供的是每個單詞的特徵形式,所以這一類預訓練的方法被稱為 "Feature-based Pre-Training"。
ELMo可改進之處(反觀歷史):
-
LSTM抽取特徵的能力遠弱於Transformer。
-
上下文編碼的方式可繼續改進,雙向融合特徵的拼接方式的融合能力偏弱。
ELMo的「雙向」不夠充分,因為bi-LSTM訓練時是採用的兩套引數,僅共用輸入,並對輸出拼接後反向傳播更新引數。而後來的BERT的雙向是用一套引數(共用)。ELMo這種「偽雙向」有一點好處是不會存在深度雙向語言模型中自己預測自己的問題,BERT論文作者 Jacob 在 reddit 貼文裡提到:It’s unfortunately impossible to train a deep bidirectional model like a normal LM, because that would create cycles where words can indirectly 「see themselves,」 and the predictions become trivial.
即當前待預測詞的資訊在前邊層中會被包含,而BERT在做上下文編碼時為了避免這個問題,在 Transformer 輸入資料時使用mask將當前待預測詞抹去,這樣每層的全域性 self-attention 都不會看到當前詞。但mask的方式也帶來了其它問題(見XLNet的分析及GPT堅持採用單向語言模型的原因)。參考:從語言模型看Bert的善變與GPT的堅守。
Seq2Seq
Encoder-Decoder模型
通常來說,Seq2Seq任務最常見的是使用Encoder+Decoder的模式,先將一個固定長度的序列編碼成一個上下文矩陣,再使用Decoder來解碼。當然,我們僅僅把context vector作為編碼器到解碼器的輸入。編碼器要將整個序列的資訊壓縮成一個固定長度的向量。它存在三個弊端:[5]
(1)對於編碼器來說,語意向量context vector可能無法完全表示整個序列的資訊。
(2)對於編碼器來說,先輸入到網路的序列攜帶的資訊可能會被後輸入的序列覆蓋掉,輸入的序列越長,這種現象就越嚴重。
(3)對於解碼器來說,在解碼的時候,對於輸入的每個單詞的權重是不一致的。
以上三個弊端使得在解碼的時候解碼器一開始可能就沒有獲得輸入序列足夠多的資訊,自然解碼的準確率也就不高。所以,在NMT(Neural Machine Translation,神經機器翻譯)任務上,還新增了attention的機制。
在transformer之前的seq2seq任務主要方案是由RNN/LSTM這類迴圈網路或者是CNN構成的 encoder+decoder的框架。還有在此基礎上應用Attention機制也取得了非常大的成功,但依然存在很多痛點,比如RNN無法並行、速度慢。
Google 提出的 Transformer 正是基於 encoder-decoder 結構,但是通過特別的attention來試圖改善傳統encoder-decoder 結構的這三個弊端。可以平行計算,並能更好的解決長距離依賴問題。Transformer的 encoder-decoder 連線結構如下:
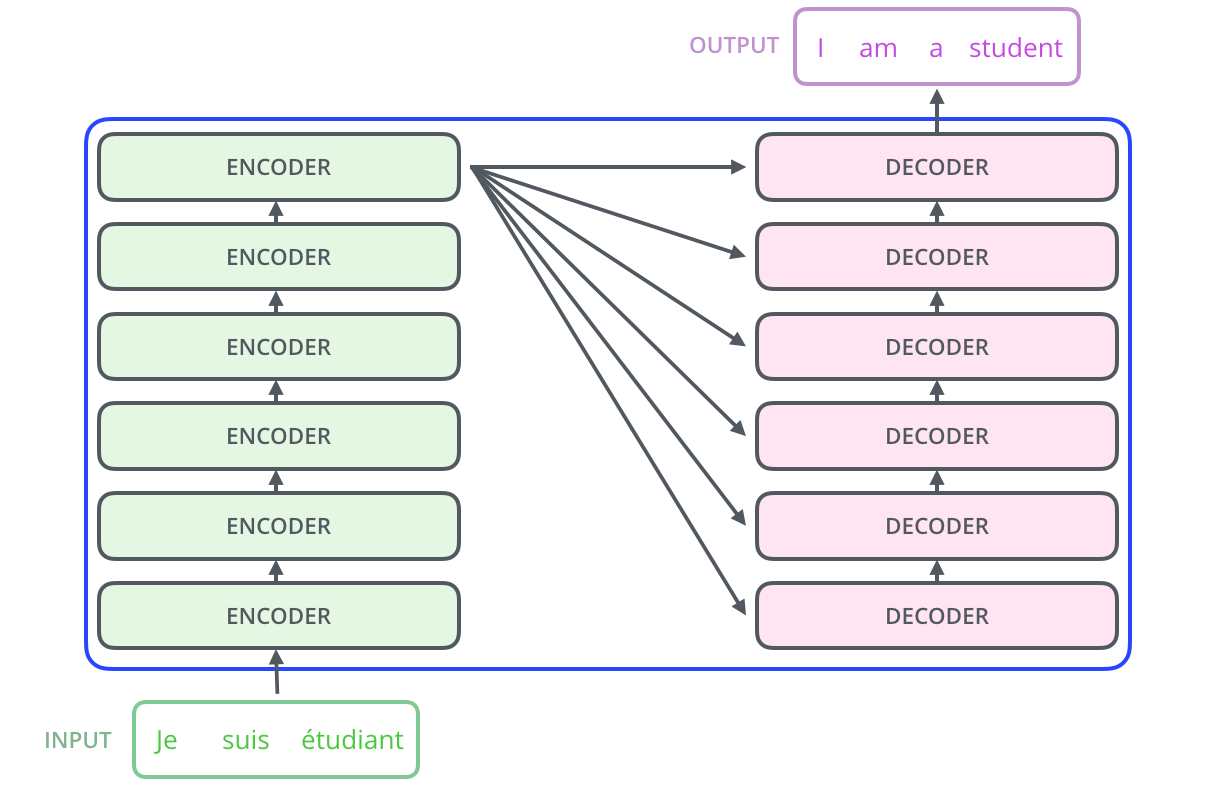
(source:https://jalammar.github.io/images/t/The_transformer_encoder_decoder_stack.png)
Encoder-Decoder的內部連線結構如下圖:
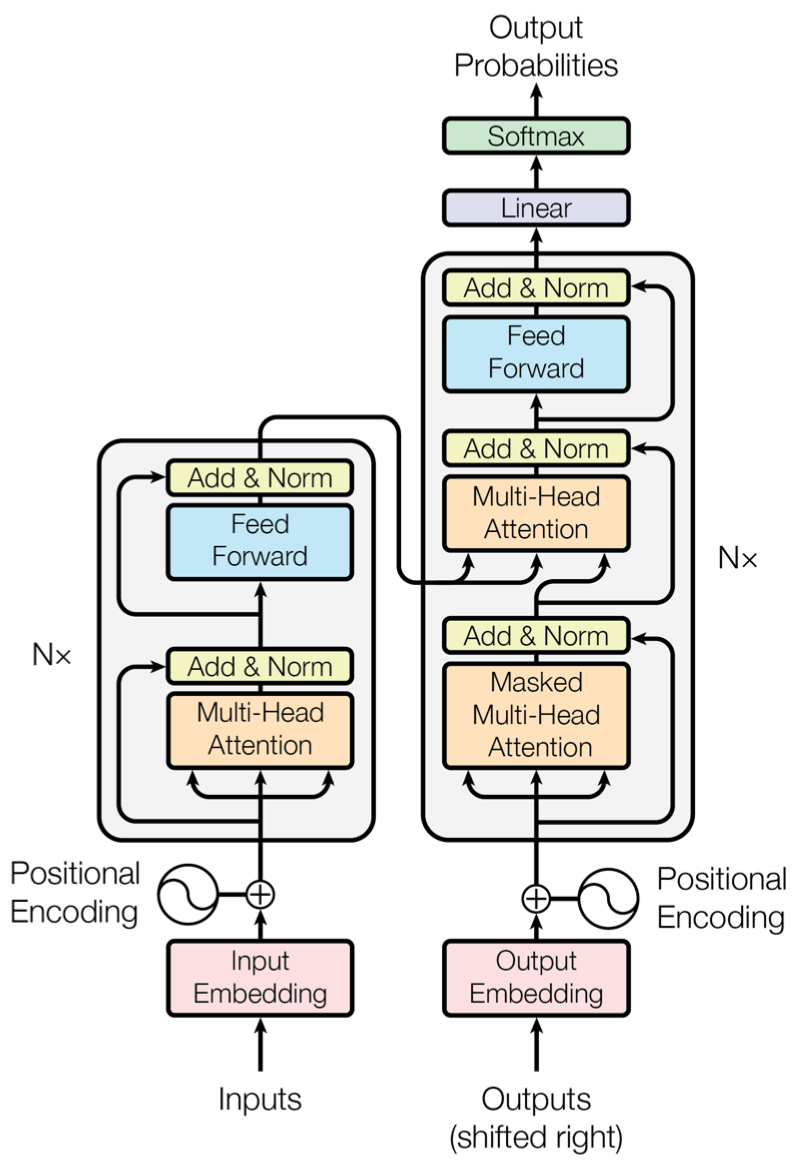
Q:decoder和encoder的區別?
結構類似,但是block內多了一個 soft attention 的 sub-layer,而非self attention。 K,V 來自 encoder,Q 來自上一位置 decoder 的輸出解碼。而在self attention輸入時將當前位置及之後的詞mask掉,與輸入右移實現並行化有關。
Q:Decoder的輸入為什麼要右移一位?
因為語言模型是根據第i個位置之前的input token來預測第i個target token,通過將decoder的input token右移一位就可以實現這個目的。
在一般的Seq2seq模型中,Decoder是迭代對每一個輸出位置進行解碼,並用前一個的輸出作為後一個的輸入,與普通的RNN類似,執行效率較低。Transformer則沒有按照舊方式來做,而是將解碼器也同編碼器一樣,一次接收解碼時所有時刻的輸入進行計算。這樣做的好處,一是通過多樣本平行計算能夠加快網路的訓練速度;二是在訓練過程中直接喂入解碼器正確的結果而不是上一時刻的預測值能夠更好的訓練網路。[6]
Decoder 的並行化僅在訓練階段,在測試階段,因為我們沒有正確的目標語句,t 時刻的輸入必然依賴 t-1 時刻的輸出,這時跟之前的 seq2seq 就沒什麼區別了。
Beam Search
Seq2seq的decoder輸出需要選擇輸出最可能的序列,通常採用beam search的方式。貪心選擇與窮舉方式都可以看作是beam search的特例。
集束搜尋是一種啟發式演演算法,會儲存 beam size 個當前的較佳選擇,然後解碼時每一步根據儲存的選擇進行下一步擴充套件和排序,接著選擇前beam size個進行儲存,迴圈迭代,直到結束時選擇最佳的一個序列作為解碼的結果輸出。
計算複雜度為 \(\text{beam_size * |vocabulary| * out_seq_len} = \mathcal{O}(k\left|\mathcal{Y}\right|T')\)
參考 https://d2l.ai/chapter_recurrent-modern/beam-search.html
Attention機制
基本思想:Attention is a generalized pooling method with bias alignment over inputs.
主要包括Soft Attention與Hard Attention兩種:機器學習中 soft 常常表示可微分,比如sigmoid和softmax機制;而hard常常表示不可微分。
Encoder-Decoder加Attention架構由於其卓越的實際效果,目前在深度學習領域裡得到了廣泛的使用。
Soft Attention
將Source中的構成元素想象成是由一系列的<Key,Value>資料對構成,此時給定Target中的某個元素Query,通過計算Query和各個Key的相似性或者相關性,得到每個Key對應Value的權重係數,然後對Value進行加權求和,即得到了最終的Attention數值。所以本質上Soft Attention機制是對Source中元素的Value值進行加權求和,而Query和Key用來計算對應Value的權重係數。即可以將其本質思想改寫為如下公式:
其中,\(L_x=\|Source\|\)代表Source的長度。根據Query和Key的相似性進行取值的過程也可以看作一種軟定址(Soft Addressing)。計算兩者的相似性或者相關性,最常見的方法包括:求兩者的向量點積、求兩者的向量Cosine相似性或者通過再引入額外的神經網路來求值。再計算相似度之後通常使用softmax來進行歸一化和突出重要元素的權重。
對於向量維度相同的query和key的相似度可以採用內積,並對所有的keys進行softmax得到歸一化的值。
Dot Product Attention:
計算分數時除以 \(\sqrt{d}\) 來消除維度 \(d\) 對分數計算的不相關影響。Transformer論文中稱之為 Scaled Dot-Product Attention。
為什麼除以d的開方?
假設兩個 d 維向量每個分量都是一個相互獨立的服從標準正態分佈的隨機變數,那麼他們的點乘結果會變得很大,並且服從均值為0,方差為d的分佈。方差越大,正態分佈越扁平,softmax輸出的最大值的梯度也越小。對點乘結果除以 sqrt(d) 可以讓點乘的方差變成 1,避免出現梯度消失。
(概率論知識:方差等於每個變數取值減均值後的平方和再除以變數個數或者個數減1)
至於是否可以除以d而不用d的開方,肯定也是可以的,計算開銷更低一點,但是方差有所不同,最終效果可能也有些許差異。
Scaled Dot-Product Attention只是注意力的一種形式,還有一些其他選擇,比如 query 跟 key 的運算方式不一定是點乘(還可以是拼接後再內積一個引數向量),甚至權重都不一定要歸一化,等等。
對於向量維度不同的query和key的相似度,不能直接採用點積計算,需要轉換為維度相同的向量後再做點積。
Multilayer Perceptron Attention:
通過可學習的引數將query和keys對映到相同維度空間 \(\mathbb R^{h}\) :
三個可學習引數通過Dense層(全連線層)即可實現。
Soft Attention 應用範例:
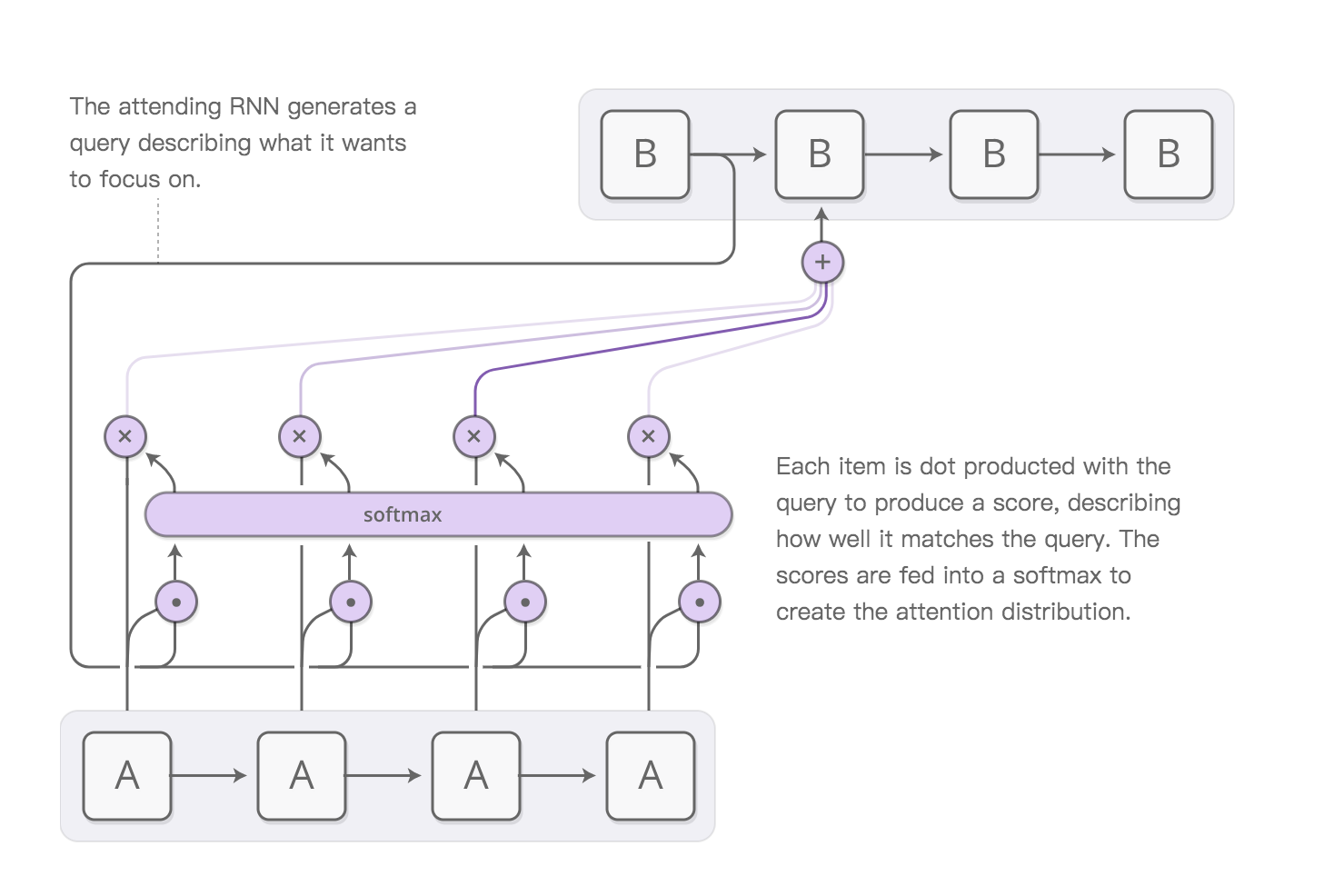
機器翻譯加Soft Attention如上圖所示,A網路的每個輸入詞的輸出向量為 \(\mathbf s_j\),B網路的隱藏狀態 \(\mathbf h_i\),那麼Similarity可以是如下的形式:
-
乘法Attention,引數較少
\[f_{att}(\mathbf h_i,\mathbf s_j)=\mathbf h_i^\mathsf{T} \mathbf W_a \mathbf s_j \] -
加法-拼接 \(\mathbf s_j\) 與 \(\mathbf h_i\)
\[f_{att}(\mathbf h_i,\mathbf s_j)=\mathbf v_a^\mathsf{T} \tanh(\mathbf W_a [\mathbf h_i;\mathbf s_j]) \] -
加法-獨立
\[f_{att}(\mathbf h_i,\mathbf s_j)=\mathbf v_a^\mathsf{T} \tanh(\mathbf W_1 \mathbf h_i + \mathbf W_2\mathbf s_j) \]
Self Attention
自注意力機制是注意力機制的變體,其減少了對外部資訊的依賴,更擅長捕捉資料或特徵的內部相關性。
Self Attention也經常被稱為intra Attention(內部Attention),指的不是Target和Source之間的Attention機制,而是Source內部元素之間或者Target內部元素之間發生的Attention機制,也可以理解為Target=Source這種特殊情況下的注意力計算機制。Self Attention在機器翻譯中可以捕獲同一個句子中單詞之間的一些句法特徵(比如短語結構)或者語意特徵(比如it/its與指代物件具有相關性)。
引入Self Attention後會更容易捕獲句子中長距離的相互依賴的特徵,而RNN或LSTM,需要依次序序列計算,對於遠距離的相互依賴的特徵,要經過若干時間步步驟的資訊累積才能將兩者聯絡起來,而距離越遠,有效捕獲的可能性越小。因此Self Attention也有利用計算的並行性。
為什麼self attention有效?是怎樣學習的?通過人工強制加入self attention,迫使網路將相關的元素找出來,並且使得相關的元素的embedding比較相近。
Attention在Transformer中的應用
Transformer在三個地方使用了multi-head attention。
- 在encoder中包含self-attention層,在每個self-attention層所有的key, value, query都是由上一層而來,因為每個位置都含有之前層的資訊。
- 在decoder中也包含了一個類似encoder中的self-attention層,避免看見未來的詞,在decoder中加入了mask。key, value, query都是由上一層而來。
- 在encoder-decoder層,query是上一個decoder層產生,key, value來自於encoder,這可以讓decoder中每一個位置都可以學習到輸入序列中的資訊。不屬於Self Attention而屬於Soft Attention。
Transformer 2017
Transformer源自谷歌論文 Attention Is All You Need NIPS 2017,本質是個self attention疊加結構,其提取特徵的能力要遠強於LSTM。優點是易於並行,捕獲長距離特徵能力強。
RNN的明顯缺點之一就是無法並行,速度較慢,這是遞迴的天然缺陷。RNN遞迴的過程無法很好地學習到全域性的結構資訊,因為它本質是一個馬爾科夫決策過程。RNN一般要雙向才比較好。CNN只能獲取區域性資訊,需要通過層疊來增大感受野。Attention的思路最為直接,它一步到位獲取了全域性資訊。
Transformer的結構圖見上文Seq2Seq,包含Encoder、Decoder兩部分,每部分均包含N個block,每個block中包括multi-head attention、FFN、add&norm等操作。add&norm中採用了Layer Normalization而不是Batch Normalization。
Transformer將單個attention用在整個句子中。句子長度適用於多長?文章級別需要分段嗎?不適宜過長的文章級別的文字,因為self Attention的計算複雜度為長度的平方級,Longformer論文提出了新的Attention機制來解決文章級別的文字任務,使Attention的計算複雜度與長度呈線性關係。而如果對文章進行分段處理,勢必會丟失資訊。
multi-head attention 和 FFN都是在sequence的每個單詞位置進行變換,沒有采用RNN中的迴圈結構或者CNN中的折積,不涉及詞的先後順序,因此可以平行計算。但是單詞的先後位置資訊沒有被利用到,可以將位置資訊提前編碼加入原始輸入特徵X再經過multi-head attention 和 FFN。
輸入編碼表示:輸入文字經過 Token Embeddings 再與 position embedding 相加。
Multi-Head Attention
Multi-Head Attention
通過三個可學習的權重矩陣:\(\mathbf W_q^{(i)}\in\mathbb R^{p_q\times d_q},\ \mathbf W_k^{(i)}\in\mathbb R^{p_k\times d_k},\ \mathbf W_v^{(i)}\in\mathbb R^{p_v\times d_v}\) 對query, key, value 進行轉換。然後可以使用上邊提到的 Scaled Dot-Product Attention 或 Multilayer Perceptron Attention。
然後通過h個引數獨立的attention得到h個輸出,拼接後經過額外的權重矩陣轉換(全連線dense層)得到Multi-Head Attention輸出:
Transformer論文中實驗設定為 \(h=8,\ d_k=d_v=d_{\rm{model}}/h=64\).
Multi-Head Attention 結構示意圖如下:
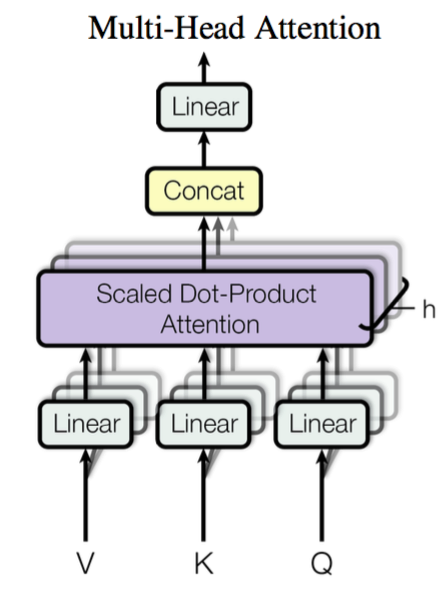
平行計算:h個header可以平行計算,但程式碼中可以通過reshape的方式將h個矩陣乘法合併成一次,而將矩陣乘法交給底層來加速。[7]
使用多頭的原因
多次 attention 綜合的結果能夠起到增強模型的作用,可以類比 CNN 中同時使用多個折積核的作用。直觀上講,多頭的注意力有助於網路捕捉到更豐富的特徵/資訊。
位置編碼
position embedding位置編碼有很多種選擇,有固定引數的和可學習的,參考文獻[8].
Transformer的位置編碼採用了固定引數的包含正餘弦的函數形式,為什麼設計的那麼奇葩?直接採用位置編號(0、1、2...)不行嗎?
不行,因為絕對位置在不同長度的句子中意義不同。比如長度分別為5、20的句子中位置3的意義相差可能較大。在長度較長時,數值會比較大。並且訓練樣本的最長長度固定,當測試時文字長度超過之後,無法準確預測,導致模型泛化能力較差。如果將位置編號換成[0, 1]之間的浮點數,將喪失字元個數資訊,且在不同長度的句子中尾號編碼的意義也不同。
位置編碼函數期望:[9]
- 句子中每個詞應對應一個唯一的編碼
- 在不同長度的句子中兩個點之間的編碼距離應該一致
- 值有界,且適用於較長的句子
- 位置編碼函數具有確定性的值輸出
採用具有周期性的sin、cos函數能夠表示相對位置資訊,且適用於不定長度的句子。
sin(wx)的週期/波長為:2π/w,因此位置編碼函數的波長為: \(2π \cdot 10000^{2j/d}\) 範圍為 2π ~ 10000⋅2π.
-
論文的位置編碼是使用三角函數去生成一個編碼向量,而不是標量:
-
- 值域只有[-1,1]
- 容易計算相對位置。
\(P_{pos+k}\) 可以表示為 \(P_{pos}\) 的線性函數。why?正餘弦公式:參考 addition theorem
為什麼設計成sin、cos組合的形式來生成編碼向量,並且向量的各個維度具有不同的頻率?
讓我們觀察二進位制數位表示形式:
可以看出:不同的位元位具有不同的變化頻率,LSB(Least Significant Bit,最低有效位)變化最頻繁,MSB(最高有效位)變化週期最長。然而直接用二進位制表示位置編碼,在浮點型環境下會比較浪費空間。採用正餘弦函數取得[-1,1]之間平滑的取值, 能夠節省空間。
為什麼同時使用sin、cos,只用一個函數不行嗎?[sin(x+k), cos(x+k)] 可以通過 [sin(x), cos(x)] 線性變化得到(通過旋轉矩陣 rotation matrix),但是隻用一個sin(或cos),無法僅用sin(或cos)來實現線性變換。
對該位置編碼函數的更形象的理解:將每對(sin, cos)看作時鐘上的一個指標(時針、分針、秒針、毫秒、微秒、納秒...),位置改變的過程就是鐘錶指標旋轉的過程。因此,可以想到位置變化可以用旋轉矩陣來得到。
相對位置可以通過線性變換有什麼意義?論文提到可以使模型更容易學習attention。給定一個位置pos的編碼,想要將attention聚焦於pos+k的位置,只需要讓網路學習一個Mk的權重,與起始位置pos無關。
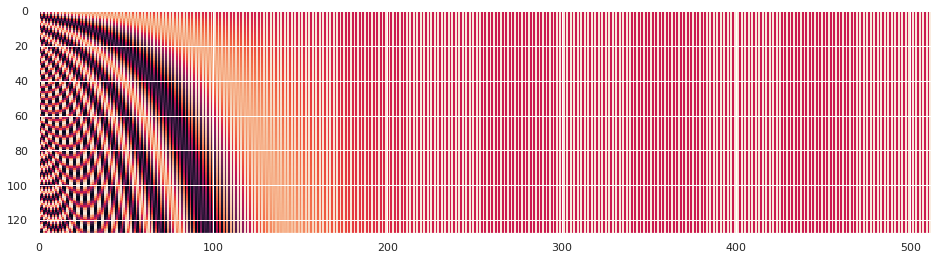
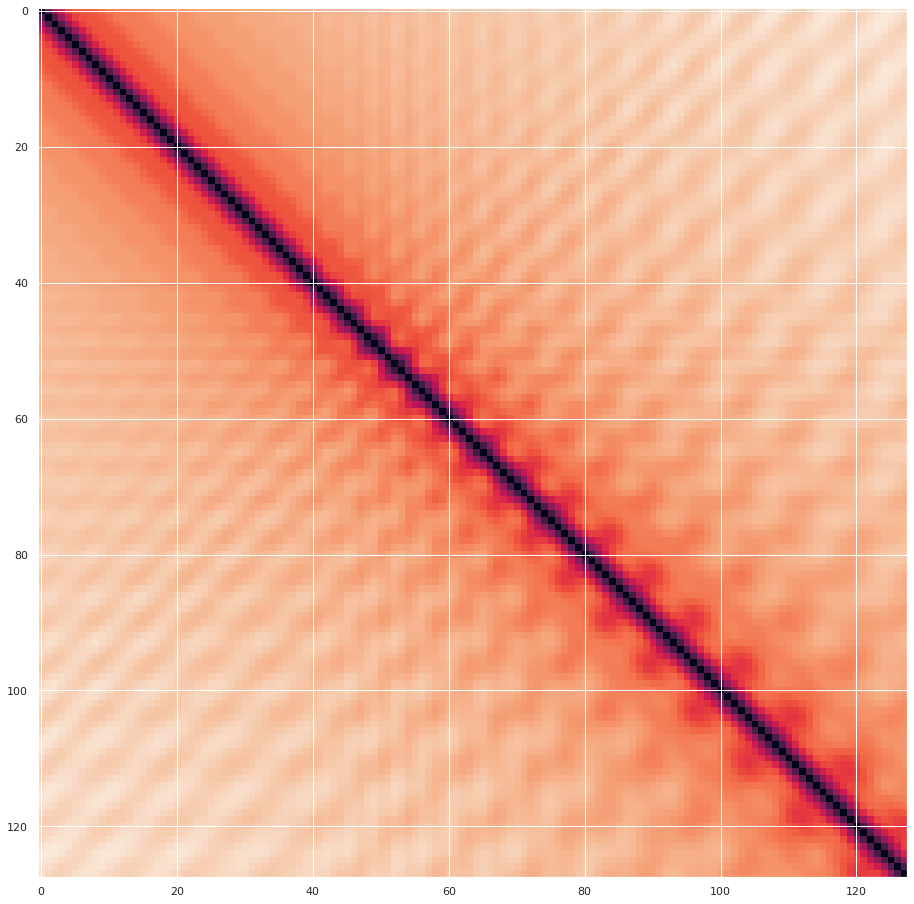
下面圖一位置編碼函數影象,可以反映出不同維度隨著位置改變的變化頻率。圖二的編碼距離可以看出具有對稱性,位置距離越遠,編碼距離也越大。
圖一:位置編碼函數,x軸:embedding維度,y軸:位置
圖二:不同位置編碼的歐式距離,x,y軸:位置
Position Embedding本身是一個絕對位置的資訊,但在自然語言中,相對位置也很重要,Google選擇前述的位置向量公式的一個重要原因是:由於 \(\sin(α+β)=\sinα\cosβ+\cosα\sinβ\) 以及 \(\cos(α+β)=\cosα\cosβ−\sinα\sinβ\),這表明位置p+k的向量可以表示成位置p的向量的線性變換,這提供了表達相對位置資訊的可能性,在遇到比訓練集中更長的句子時泛化能力可能更強。儘管論文給出的Position Embedding是 sin,cos 交錯的形式,但其實這個交錯形式沒有特別的意義,你可以按照任意的方式重排它(比如前sin後cos拼接)[10]
位置編碼方式選擇
論文也指出,通過自動學習的位置編碼和人為選擇的固定的編碼在實驗效果上差距不大。自動學習的位置編碼可解釋性肯定就比較差了,而人為選擇的編碼滿足我們對距離的理解,相比於訓練出來的向量,三角函數的公式可以處理比訓練樣本更長的文字序列。
對於機器翻譯任務,encoder 的核心是提取完整句子的語意資訊,它並不關注某個詞的具體位置是什麼,只需要將每個位置區分開(三角函數對相對位置有幫助); 而對於序列標註類的下游任務 ,是要給出每個位置的預測結果的。 Bert 模型採用了自動學習位置編碼的方式,並非是因為自動學習的方式有顯著的提升,而是基於神經網路能模擬任意函數的思路,統一採用網路自動學習的方式可能會表現更好。
對於位置編碼的使用方式:通過與原輸入做拼接(concat)能很好地滿足正交性,但是通常embedding的維度比較大,拼接的方式導致需要學習更多的引數。通過與原輸入直接相加的方式能夠得到近似的正交性,而且也不需要獲取絕對精確的位置資訊。參考1[11],參考2[12].相加的方式要求位置編碼與單詞embedding具有相同的維度(論文中是512)。
位置資訊前向傳播經過許多層之後不會變質或者消失嗎?由於採用了殘差結構,能夠直接傳播過去。
OpenAI 的實現的位置編碼如下:參考stackexchange
Multi-head可以讓模型在不同的位置從不同的視角進行學習,與單attention head相比學習到資訊更豐富,每一個head可以並行。
位置編碼的應用方式:與輸入直接相加再進行Attention和FFN,有些實現中在新增位置編碼之前對輸入的embedding乘上\(\sqrt d\) 來防止值太小(d是embedding的維度)。
FFN
Position-wise Feed-Forward Networks
對於三維特徵輸入:(batch size, sequence length, feature size) ,使用兩個dense層(全連線層)對最後一個維度進行變換,保持輸出維度不變。等價於使用兩個1x1的一維折積(為什麼?一維折積在sequence length維度上滑動,kernel_size=1則在每個位置上(position-wise)進行feature size維度上的變化)。
可調引數
可調整的引數:訓練資料集中最長句子的長度,beam_size(候選集的個數) 和 max_out_len(最大輸出的句子長度)。
Transformer優缺點[13]
- 優點
- 模型的設計主要是矩陣乘法,可以高度並行化,計算複雜度大大降低。
- 計算不同step之間的相關性,self attention不需要進行序列計算,直接進行point-wise計算。
- 在Encoder中,若想要獲得最終的hidden state結果,RNN需要從前往後逐個沿著序列計算,CNN需要堆疊多層的折積層來擴充套件視野,而Transformer只需要多層的矩陣計算即可。
- 缺點-序列長度限制
- Transformer使用了position embedding加入了序列的資訊,但是在訓練的時候設定了max_length,如果在預測中遇到超過max_length的case,可能不能得到很好的結果。
- 無法藉助while op來處理變長序列的輸入,而只能通過pad或者截斷來預處理資料。
- 對於長輸入的任務,典型的比如篇章級別的任務(例如文字摘要),因為任務的輸入太長,Transformer會有巨大的計算複雜度,導致速度會急劇變慢。但是可以通過文字切分,用層級的Transformer來提取特徵,比如Transforme-XL採用了類似的思路。而Longformer則從Attention的角度進行了優化。
Transformers-hub
開源huggingface庫整合了眾多基於Transformer的模型,開箱即用。
利用Transformer結構思想的後續模型很多僅採用了encoder或decoder兩者之一,如GPT decoder, BERT encoder。
NLP任務大體可分為自然語言理解(NLU,Natural Language Understanding)和自然語言生成(NLG,Natural Language Generation)兩種型別。僅含Encoder的模型主要做NLU,僅含Decoder的模型主要做NLG,而兩部分都包含的模型兩者皆可做。
可以將Transformers寬泛地分為三類:
- GPT-like (auto-regressive Transformer models)
- BERT-like (auto-encoding Transformer models)
- BART/T5-like (sequence-to-sequence Transformer models)
Q:什麼情況下用encoder,什麼情況下用decoder?
如何選擇語言模型(language models)取決於任務型別:
- Decoder:GPT系列(GPT-2、GPT-3)、XLNet,擅長自由創作等文字生成應用場景。在傳統的單向 language models (LMs) 中, 每個 token 基於前邊的 tokens 進行預測,因此僅需要decoder.
- Encoder:BERT、RoBERTa、ALBERT等輸入內容理解(NLU)模型,適合分類問題(如句子分類、命名實體識別)。在BERT的masked LMs中,每個 token 基於兩邊的 tokens 進行預測,在encoder中就可完成,因此僅需要encoder。在其他的 masked LM 架構中有用encoder-decoder實現的, 比如 MASS 。
- Encoder-Decoder:T5。對生成式、判別式模型均適用。擅長給定輸入,產生對應的輸出的應用:比如翻譯,知識問答、文章摘要等。在機器翻譯 Neural Machine Translation (NMT) 模型中, 每個 token 基於前邊的已預測tokens (decoder)和源語言文字(encoder)進行預測,因此是encoder-decoder結構。當然也有一些僅用 decoder 的模型,如 this one.
參考:nlp - Why is the decoder not a part of BERT architecture? - Data Science Stack Exchange
Transformers 模型時間線,from BERT 101 - State Of The Art NLP Model Explained
引數量 from How do Transformers work? - Hugging Face Course
Longformer 2020
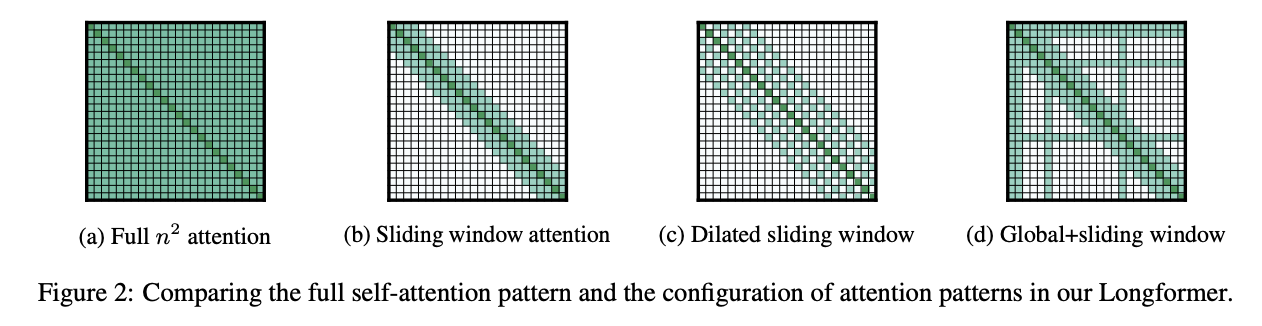
Longformer 通過簡化Attention的計算來減少長輸入的計算複雜度。Attention的設計思想為Global+Local(sliding window ) Attention。
sliding window attention 是對每個token在長度為W的視窗內進行softmax attention的計算,計算複雜度為O(WL).
對於不同的下游任務設定不同的Global attention:
- 在分類任務上,這個global attention就落在[CLS]標籤上。
- 在QA任務上,就在整個問句上計算global attention。
可以看出,global attention是視具體任務而定的,換個任務可能之前的做法就不適用了,但作者認為,這仍然比現有的trunk或者shorten的做法要簡單很多。
GPT 2018~2020
GPT:Improving Language Understandingby Generative Pre-Training(OpenAI,2018)
GPT是「Generative Pre-Training」的簡稱,從名字看其含義是指的通用的預訓練,核心在通用上。
GPT也採用兩階段過程,第一個階段是利用語言模型進行預訓練,第二階段通過Fine-tuning的模式解決下游任務。
GPT採用Transformer作為特徵抽取器,預訓練雖然仍然是以語言模型作為目標任務,但是採用的是單向的語言模型,即僅靠上文來進行預測。相比於ELMo的採用上下文來做預測,GPT在某些應用場景下會受限,比如閱讀理解任務(可以充分利用下文)。
為了下游任務能夠fine-tuning,下游任務不能再任意設計自己的網路結構,需要和GPT保持一致。那麼如何改造下游任務使之接近GPT的網路模型呢?
- 分類問題,不用怎麼動,加上一個起始和終結符號即可;
- 句子關係判斷問題,比如Entailment,兩個句子中間再加個分隔符即可;
- 文字相似性判斷問題,把兩個句子順序顛倒下做出兩個輸入即可,這是為了告訴模型句子順序不重要;
- 多項選擇問題,則多路輸入,每一路把文章和答案選項拼接作為輸入即可。
GPT-2 : Language Models Are Unsupervised Multitask Learners (2019)
GPT-2 相比GPT-1,在結構框架上沒有大的差異(依然僅使用Decoder),而是擴大的模型容量:更大的模型、更大的訓練語料。GPT-2將Transformer層數增加到48層,引數規模15億。採用包含800萬網際網路網頁的資料作為語言模型的訓練資料,稱為WebText(40GB)。網際網路網頁的優點是覆蓋的主題範圍非常廣,這樣訓練出來的語言模型,通用性好,能廣泛適用於任意領域的下游任務。WebText採用的reddit中獲得高投票的網頁連結,並在資料質量方面下了很大的功夫。
GPT-2 通過無監督大模型驗證了只要模型夠大、資料夠多,通過Transformer就可以學到很多通用的包含各個領域的知識,這樣下游任務幾乎不需要再微調了。當然如果在下游資料上微調可能還能獲得更好的結果。
Zero-Shot Learning:在沒有采用監督資料訓練的情況下嘗試完成下游任務。GPT-2 通過給模型一個提示(prompt)讓模型按生成模型的方式來生成答案。比如做文字摘要,在輸入時候加入「TL:DR」引導字串。
GPT-3 : Language Models are Few-Shot Learners(2020)
GPT-3 再次提升了模型的規模,使用了45TB的訓練資料,擁有175B的引數量。
One-shot/Few-shot learning:對某些類別只提供一個或者少量的訓練樣本。
GPT-3 對於下游任務的預測,仿照人類出題答題的方式:給一個問題說明,並舉一個或多個例子來說明問題。
對比:
與Transformer的區別:僅用了decoder部分,採用無監督資料做預訓練,而Transformer是直接用模型做的機器翻譯等任務,沒有預訓練過程。
與BERT的區別:GPT是基於自迴歸模型,可以應用在NLU和NLG兩大任務,而原生的BERT採用的基於自編碼模型,只能完成NLU任務,無法直接應用在文字生成上面。
GPT的可改進之處:單向語言模型的問題 => 改成雙向(結合BERT的MLM 掩碼方式、結合Encoder:MASS/BART/UniLM)。
GPT系列均採用單向語言模型的原因:可能主要為完成生成式的任務,在生成式相關任務場景下一般只能看到上文,因此傳統的單向語言模型更方便。但是不排除有更好的雙向模型出現的可能,比如後文的MASS通過seq2seq既能夠利用雙向又能夠實現生成式。
BERT 2018
Bert(Pre-training of Deep Bidirectional Transformers for Language Understanding)採用和GPT完全相同的兩階段模型,首先是語言模型預訓練;其次是使用Fine-Tuning模式解決下游任務。和GPT的最主要不同在於在預訓練階段採用了類似ELMo的雙向語言模型,當然另外一點是語言模型的資料規模要比GPT大。
Bert在模型和方法上的創新表現在Masked 語言模型和Next Sentence Prediction。而Masked語言模型的本質思想和CBOW類似,但是細節方面有改進。
- Masked雙向語言模型:類似CBOW,用一個詞周圍的詞,去預測其本身。隨機選擇語料中15%的單詞,把它摳掉,也就是用[Mask]掩碼代替原始單詞,然後要求模型去正確預測被摳掉的單詞。但是這裡存在一個問題:訓練過程大量看到[mask]標記,但是真正後面用的時候是不會有這個標記的,這會引導模型認為輸出是針對[mask]這個標記的,但是實際使用又見不到這個標記。為了緩解這個問題,Bert對15%的被選中要替換成[mask]的單詞進行如下的隨機操作:
- 80%真正被替換成[mask]標記;
- 10%被隨機替換成另外一個單詞;
- 10%不做替換。
- Next Sentence Prediction:為了訓練一個可以理解句子關係(句子B是否是A的下一句)的模型,可以訓練一個二值化的Next Sentence Prediction任務。訓練樣本可以從任何的單語言語料庫中簡單地生成(50%的概率選擇一個句子的實際的下一句,50%的概率從語料庫中隨機選擇一個句子)。考慮到很多NLP任務是句子關係判斷任務,單詞預測粒度的訓練到不了句子關係這個層級,增加這個任務有助於下游句子關係判斷任務。值得注意的是這裡的句子級負取樣與word2vec的詞級負取樣做法類似。
Bert的預訓練是個多工過程,即同時訓練這兩個任務 MLM (50%) + NSP (50%),採用多目標損失函數。
MLM任務僅用於預訓練,這也帶來一個缺點:[mask] 使pre-training和fine-tuning不匹配。
Bert使用了Transformer的encoder結構,但是在位置編碼上沒有采用Transformer論文(Attention is all you need)中的sin、cos編碼方式,而是直接簡單訓練一個位置編碼,與word embedding直接相加。
輸入預處理:新增特殊token,將輸入的pair變為[cls] text_a [sep] text_b [sep],如果僅用單句,則只需要[cls]
- [cls] 匯聚句子的表示
- [sep] 區分句子
這兩個特殊token同時用於預訓練和微調,而GPT中僅用於微調。
開原始碼:https://github.com/google-research/bert
論文中的 BERT-base 與 BERT-large 對比:
| Model | Transformer Layers | Hidden Size | Attention Heads | Parameters | Processing | Length of Training |
|---|---|---|---|---|---|---|
| BERTbase | 12 | 768 | 12 | 110M | 4 TPUs | 4 days |
| BERTlarge | 24 | 1024 | 16 | 340M | 16 TPUs | 4 days |
注:BERT-base的引數設計是為了和OpenAI GPT保持相同的引數量,用於模型比較。
Hidden Size是指Multi-head Attention的輸出維度及feed-forward的輸出維度,兩個模型中feed-forward/filter size = 4H,filter size是指用折積或全連線實現的feed-forward。即feed-forward中間隱藏層維度分別為4x768,4x1024,先升維再降維。
Q:為什麼bert是雙向的?
因為語言模型訓練方式的緣故,GPT根據上文預測下文,因此是單向的,而bert採用了MLM預訓練任務根據上下文預測mask位置,因此是雙向的。參考 how the model reflect 'bidirectional'?
Q: bert這種masked language model 預訓練的收斂速度相比left-to-right language model快還是慢?
慢,自己猜測的原因:因為15%的token被隨機mask,需要隨機很多次才能遍歷完,需要更充分的迭代。
Q:為什麼用[CLS] token作為整個句子的表示參與最終的分類?
[CLS] token是給任意的句子新增在句首的dummy token,與位置無關。最主要的是經過了多層attention之後,融合了句子的上下文資訊。如果選用n-th token則與位置有關,並且需要考慮句子長度是否小於n的問題。
Q:BERT與Transformer的區別 [14]
-
BERT 是個語言模型,無監督預訓練+有監督微調下游任務;Transformer則直接用於具體任務。
-
BERT 僅採用了 encoder 部分,沒有Transformer decoder中的迴圈連線。原因:預訓練採用masked language model,是一個用上下文去推測中心詞[MASK]的任務,和Encoder-Decoder架構無關,只需要Encoder做特徵提取器,不需要Decoder解析序列輸出結果。而在微調任務中採用了encoder的編碼表示來做分類等下游任務,對於機器翻譯等下游任務,可以繼續新增decoder來微調訓練。
-
輸入編碼:原始 transformer 僅採用 word embeddings 和 positional encodings. BERT 額外採用了 segment embeddings,並且設定輸入的三種embedding均可學習更新。為什麼用[SEP]分隔句子了還要用segment embeddings,並且還是可學習的?用於區分token是屬於哪個句子,主要用於NSP任務(這個任務是否有必要存在爭議,這個embedding可能作用不是很大)。1)[sep]沒有直接被用到可能比segment embeddings作用弱。2)與位置編碼類似,設定成可學習的不影響效果,統一學習有可能取得更好的結果。 segment embeddings限制只有0、1兩種取值,而其它可以是浮點數,這三個embedding lookup table分別更新。[15][16]
不重要的區別包括
- 超引數,如multi head數量,bert:12、16 ,Transformer 8;Hidden Size 768 feedforward networks的單元數量。
Q:為什麼對三個輸入向量直接相加而不是concat方式
首先,相加是對同一token的三個embedding相加,這其實等價於三個one-hot concat之後乘以lookup table得到的向量。本質可以看作一個特徵的融合,隨著模型越來越深,相加後的向量在高維空間中又變成了可分的。
在實際場景中,疊加是一個更為常態的操作。比如聲音、影象等訊號。一個時序的波可以用多個不同頻率的正弦波疊加來表示。只要疊加的波的頻率不同,我們就可以通過傅立葉變換進行逆向轉換。
一串文字也可以看作是一些時序訊號,也可以有很多訊號進行疊加,只要頻率不同,都可以在後面的複雜神經網路中得到解耦(但也不一定真的要得到解耦)。在BERT這個設定中,token,segment,position明顯可以對應三種非常不同的頻率。
參考:為什麼 Bert 的三個 Embedding 可以進行相加? - 知乎
Q:為什麼在inference階段調換兩個句子的順序作為輸入時會得到不同的輸出?
因為inference時每個位置的segment embedding、position embedding是固定不變的,但是調換兩個句子的位置之後 token embedding發生變化,三個向量之和發生了變化。
Q:BERT 計算文字相似度的方法,及效果不好有什麼改進方法
Bert 模型的做句向量的缺陷及解決辦法
獲取句向量,計算cosine距離,BERT 句向量的獲取方式有:
- 取最後一兩層的 embedding 的各單詞的平均
- 直接用[CLS]對應的 embedding
效果不好原因:
簡單來說,直接使用 Bert 做句向量的輸出,會發現所有的句向量兩兩相似度都很高。
1、因為對於句子來說,大多數的句子都是使用常見的片語成的。
2、Bert 的詞向量空間是非凸的,大量的常見的詞向量都是在 0 點附近,從而計算出的句子向量,都很相似。
對於詞向量平均法而言,語句越長分出的詞多,資訊量越雜,重要的詞的資訊會在平均的過程中極大的被消弱, 從而分類效果差。
更深層次的說法:
一、BERT 句向量的空間分佈是不均勻的,受到詞頻的影響。因為詞向量在訓練的過程中起到連線上 下文的作用,詞向量分佈受到了詞頻的影響,導致了上下文句向量中包含的語意資訊也受到了破壞。
二、BERT 句向量空間是各向異性的,高頻詞分佈較密集且整體上更靠近原點,低頻詞分佈較稀疏且 整體分佈離原點相對較遠。因為高詞頻的詞和低頻詞的空間分佈特性,導致了相似度計算時,相似度過高 或過低的問題。在句子級:如果兩個句子都是由高頻片語成,那麼它們存在共現詞時,相似度可能會很高 ,而如果都是由低頻片語成時,得到的相似度則可能會相對較低;在單詞級:假設兩個詞在語意上是等價的,但是它們的詞頻差異導致了它們空間上的距離偏差,這時詞向量的距離就不能很好的表徵語意相關度 。
解決辦法:
-
使用雙塔的形式,將兩個句子傳入兩個引數共用的 Bert 模型,將兩個句向量做拼接,進行有監督的學習,從而調整 Bert 引數。此方法叫 Sentence-Bert:在微調的時候直接把損失函數改寫為餘弦相似度,然後採用平方損失函數(MSE)。關於餘弦相似度該配合使用什麼損失函數沒有定論,可以用CE、MSE、1-cosine值等。
-
線性變換進行句向量校正:BERT-flow、BERT-Whitening。這兩者更像是後處理,通過對 BERT 提取的句向量進行某些變換,從而緩解各向異性問題。
BERT-Flow:利用標準化流(Normalizing Flows)將 BERT 句向量分佈變換為一個光滑的、各向同性的標準高斯分佈。
蘇劍林提出:簡單的BERT-whitening線性變換直接校正句向量的協方差矩陣就能取得跟BERT-flow媲美的結果。同時,BERT-whitening還支援降維操作,能達到提速又提效的效果。參考 你可能不需要BERT-flow:一個線性變換媲美BERT-flow
-
對比學習:SimCSE。 對比學習的思想是拉近相似的樣本,推開不相似的樣本,從而提升模型的句子表示能力。無監督SimCSE的方法:將同一個句子兩次傳入同一個帶dropout的 bert(dropout = 0.3)得到句子對(同一個句子的不同表示),設定標籤為正例;不同句子設定標籤為負。 通過這種訓練樣本對 Bert 微調。其本質是利用 Dropout 進行資料增廣。refer 2021 NLP 比較火的論文 《SimCSE: Simple Contrastive Learning of Sentence Embeddings》
Q:如何處理長文字預料?
對於長文字,常見的處理方式有:截斷和切分。
截斷:一般來說文字中最重要的資訊是開始和結尾,因此文中對於長文字做了截斷處理。
head-only:保留前 510 個字元
tail-only:保留後 510 個字元
head+tail:保留前 128 個和後 382 個字元
切分: 用sliding window將文字切片,獨立放進去BERT得到[CLS]的表示,所有[CLS]再進行融合。融合方式有:
Max-pooling, Average pooling 和 self-attention,以及複雜點的疊加Transformer。
模型層面的改進處理長文字:Transformer-XL, sparse Transformer, Longformer, Reformer等。
Q:如何加速Bert模型的訓練。
BERT 基線模型的訓練使用 AdamW(Adam with weight decay,Adam優化器的變體)作為優化器。
可用LAMB優化器來提高並行訓練能力,LAMB 是一款通用優化器,它適用於小批次和大批次,且除了學習率以外其他超引數均無需調整。LAMB 優化器支援自適應元素級更新(adaptive element-wise updating)和準確的逐層修正(layer-wise correction)。LAMB 可將 BERT 預訓練的批次大小擴充套件到 64K,且不會造成準確率損失,76分鐘就可以完成BERT的訓練。
下游任務
Q:微調的方式
在預訓練模型的最後新增一層額外的輸出層(分類層,一般為全連線層+softxax層),對於不同的任務採用不同的設計。在預訓練完成之後對於子任務僅需要少量的引數進行學習。
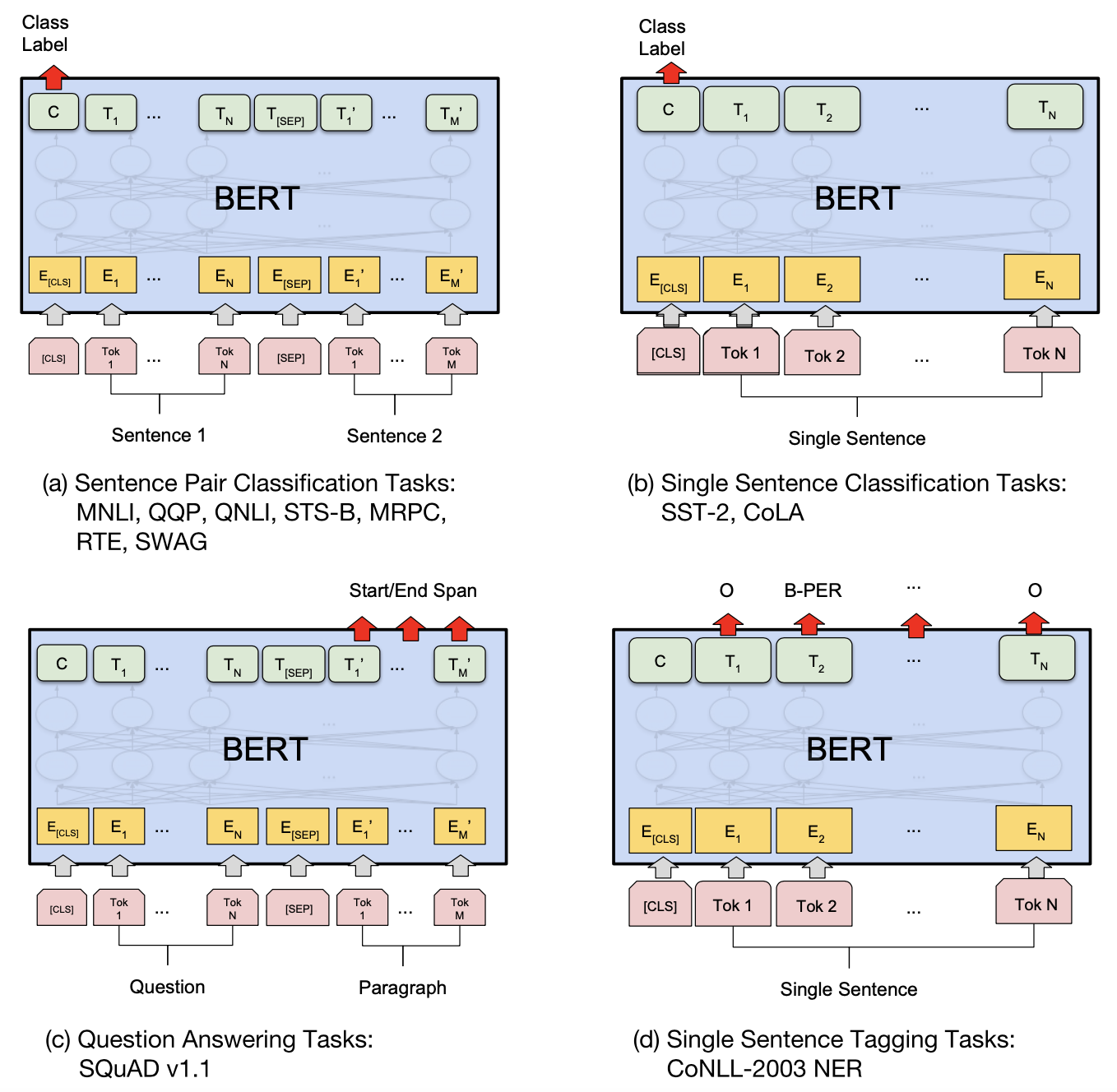
BERT在11項NLU任務上取得更優的結果,這些任務可歸類為四大類NLP下游任務,分別是 句子對分類任務、單句子分類任務、問答任務、單句子標註 任務,如下圖所示:
-
對於單、雙句句子分類任務,在[CLS]token位置的輸出進行分類。
-
對於問答任務,屬於token級任務。將答案段落(text_b)對應的所有token向量接全連線層,每個token輸出維度為2(表示答案的起止位置start, end)。根據每個token預測起止位置與真實答案起止位置之間的平均差值計算loss。通過取所有token中softmax概率最大的作為最終預測的起止位置。
-
單句標註任務,同屬於token級任務,與問答任務類似,也用全連線+softmax作為輸出層,每個token進行多分類(BIOX,B表示實體開頭,I表示在實體內部,O表示非實體,X用於標註英文單詞分詞之後的非首單詞)。
-
注:未用於機器翻譯等NLG任務,僅用encoder不容易取得顯著效果。
Q:Bert 模型適合做什麼任務,不適合做什麼任務?
-
適合:Bert 模型是 Transformer 的 encoder,適合做情感分類、文字分類、意圖識別、命名實體識別、句子是否相似、句子是否有被包含、半指標半標註的 SPO 三元組抽取、問答等任務。
-
不適合:Bert 未包含 decoder,不能做任何生成式的任務。比如翻譯、文字摘要、問題生成等 seq2seq 任務。當然有些後續工作已經在嘗試用於機器翻譯等任務,但可能還沒取得顯著成效。參考 如何使用BERT模型應用到機器翻譯任務中?
Q:如何做文字摘要?
自動文字摘要的一種簡單形式是抽取式摘要:從一篇文章中抽取幾個句子(段落),將每個句子做二分類判斷是否用作摘要。
論文 Fine-tune BERT for Extractive Summarization 給出了一種模型結構方法,將多個句子同時輸入模型,在輸出上接二分類的線性層預測每個句子。對於BERT輸入的改造方式比較簡單:
- 每個句子開頭加[CLS]用於每個句子的分類。
- segment embedding採用A、B交替式:ABABA...。
由於BERT對超長文字不易訓練,採用XLNet會更好一些,參考XLNet。
啟用函數-GELU
在FFN中採用gelu,與GPT一致。gelu的函數形式,參考我的部落格-啟用函數。
RELU及其變種與Dropout從兩個獨立的方面來決定網路的輸出,有沒有什麼比較中庸的方法把兩者合二為一呢?在網路正則化方面,Dropout將神經單元輸出隨機置0(乘0),Zoneout將RNN的單元隨機跳過(乘1)。兩者均是將輸出乘上了服從伯努利分佈的隨機變數m ~ Bernoulli(p),其中p是指定的確定的引數,表示取1的概率。
然而啟用函數由於在訓練和測試時使用方式完全相同,所以是需要有確定性的輸出,不能直接對輸入x乘隨機變數m,這點與Dropout不同(Dropout在測試時並不隨機置0)。由於概率分佈的數學期望是確定值,因此可以改為求輸出的期望:\(E[mx]=xE[m]\),即對輸入乘上伯努利分佈的期望值\(p=E[m]\)。
論文中希望p能夠隨著輸入x的不同而不同,在x較小時以較大概率將其置0。 由於神經元的輸入通常服從正態分佈,尤其是在加入了Batch Normalization的網路中,因此令p等於正態分佈的累積分佈函數即可滿足。
正態分佈的概率密度函數:\(f(x)={\frac {1}{\sigma {\sqrt {2\pi }}}}\;e^{-{\frac {\left(x-\mu \right)^{2}}{2\sigma ^{2}}}}\),累積分佈函數:\(F(x) = \frac{1}{\sigma\sqrt{2\pi}} \int_{-\infty}^x \exp \left( -\frac{(t - \mu)^2}{2\sigma^2} \ \right)\, dt\). 正態分佈的累積分佈函數曲線與sigmoid曲線相似。
標準正態分佈:\(X\sim \mathcal N(0,1)\),標準正態分佈的累積分佈函數習慣上記為\(\Phi\),\(\Phi(x)=P(X\le x)\).
因此GELU採用的啟用函數為 \(g(x)=x\cdot p=x\Phi(x)\)
RoBERTa 2019
RoBERTa: A Robustly optimized BERT Pretraining approach,由Facebook團隊 2019釋出(同作者在同期還發布了另一篇論文SpanBERT,有很多相通的思想),釋出時間晚於XLNet。
核心思想:通過改進bert的細節,更好地訓練。在不大改網路結構的前提下實現了比BERT的後起之秀更好或接近的表現。
改動點:
(1)語料訓練=>更多
- 採用更大的預訓練語料(BERT 16GB -> 160GB),但這導致不好公平比較各模型。
- 更大的batch size:256 -> 8K,512 -> 32k
- 更多的迭代次數:100K -> 300K -> 500K.
- BPE詞表擴充套件:由30k字元級 -> 50K 位元組級subword units. 對於漢字等多位元組的unicode字元可能會有優勢,並且不會存在任何UNKNOWN token的問題。
(2)預訓練模型=>精簡、改進
- Dynamic Masking,動態改變訓練資料的掩碼模式,不像bert那樣預先對訓練集生成固定mask。原始BERT實現方式是預先增加了隨機掩碼的模式,如對每條訓練樣本複製10次,建立10種不同的隨機掩碼,迭代40個epoch,平均每個模式被4個epoch共用。而RoBERTa的Dynamic Masking是完全的隨機(動態,每次迭代時不同)。但是並沒有帶來特別顯著的提升,我覺得原始BERT可能就是為了實現簡單、方便復現,沒有采用每次隨機的方式。
- 去掉NSP任務,因為之前就被指出NSP帶來的提升不顯著,作者通過對比實驗發現去掉NSP效果還能更好,並指出BERT原論文中寫的去掉NSP指標大幅下降的可能原因是輸入資料格式的問題,沒有將
SEGMENT-PAIR格式改為DOC-SENTENCES。 - 文字長度設定:取消 BERT中前90%次迭代採用128長度的短文字,後10%採用512長文字的設定,統一用512長文字。
| 引數\模型 | Bert | RoBerta |
|---|---|---|
| Batch_size | 256 | 2K、8K或更高(受記憶體/視訊記憶體限制) |
| 訓練資料 | 13G(Bert Large) | 16G、160G |
| 訓練步數 | 1M | 125K、31K |
| 是否有 NSP | 是 | 否 |
| Mask 方式 | static mask(靜態 mask) | dynamic(動態 mask) |
| text Encoding | 基於 char-level 的 BPE | 基於 bytes-level 的 BPE |
Transformer-XL 2018
Transformer的Attention機制雖然理論上可以適用於任意長度的文字,但是受限於記憶體和計算資源限制,往往只能採用較小的長度值,比如512。傳統的長文書處理方式可能有:
- 對於長文字進行分段處理,但是很難準確的分句和分段。本來具有上下文聯絡的文字可能被分到兩段,導致上下文資訊不能接續。
- 滑動視窗,採用固定長度的左側視窗文字預測當前token,這種方式比分段方式好在可以維持固定長度的上下文資訊。但由於視窗文字隨時刻變化,每個時刻都需要用Transformer計算一次,計算效能很差。
Transformer-XL 設計了一種片段迴圈機制結合了上邊的兩點,對每個片段的計算結果進行cache,在計算當前片段時利用前邊視窗內cache的結果與當前片段拼接起來計算Attention。對於cache的部分不會重複計算,在反向傳播時,cache裡的內容也不參與梯度的計算。
相對位置編碼
由於Transformer-XL對長文字進行了分段,這樣不能採用Transformer(三角函數固定初始化)或BERT(可學習位置編碼)中的「絕對「位置編碼方式,因為無法從編碼上區分出文字屬於哪一段。
為了解決這個問題,Transformer-XL引入了」真正」的相對位置編碼方法。它不是把位置資訊提前編碼在輸入的Embedding裡,而是在計算attention的時候根據當前的位置和要attend to的位置的相對距離來」實時」告訴attention head。採用了和Transformer中的三角函數式編碼,不可學習。詳情見後文「相對位置編碼」對比部分。
XLNet 2019
XLNet: Generalized Autoregressive Pretraining for Language Understanding(NeurlPS 2019)
關鍵點:
- Permutation Language Model:和語言模型相比,XLNet最大的優勢就是通過輸入序列的各種排列,同時學習到上下文的資訊。
- Transformer-XL,解決長文字的問題
核心與借鑑思想:
(1)XLNet核心思想
仍使用語言模型,但是為了解決雙向上下文的問題,引入了排列語言模型。
排列語言模型在預測時需要target的位置資訊,因此通過引入Two-Stream,Content流編碼到當前時刻的所有內容,而Query流只能參考之前的歷史以及當前要預測的位置。
最後為了解決計算量過大的問題,對於一個句子,我們只預測後面的1/K的詞。
(2)Transformer XL 借鑑思想
XLNet借鑑了Transformer XL的主要思想來處理長文字:
- Transoformer-XL的分段cache隱狀態的思想。
- Transoformer-XL的相對位置編碼。
引數設定:
XLNet-Large採用了和BERT-Large一樣的超引數,從而得到類似大小的模型。序列長度和cache分別設定為512和384。
AR與AE語言模型
目前主流的nlp預訓練模型包括兩類 autoregressive (AR) language model 與autoencoding (AE) language model。
- AR是常規的單向語言模型,比如open AI提出的GPT、GPT2.0就是採用的AR模式。
- AE模型採用的是以上下文的方式,最典型的成功案例就是bert,通過Masked Language Model實現上下文編碼。
但 Masked Language Model 存在預訓練和微調資料不統一的問題,並且其條件獨立的假設——那些被MASK的詞在給定非MASK的詞的條件下是獨立的並不總是成立。比如「New York」兩個token經常連續出現,只mask掉其中一個不滿足條件獨立假設(ERNIE通過將詞擴大到實體和短語來解決這個問題)。
XLNet從其它角度來引入上下文,依然採用AR模式。XLNet 設計了 Permutation Language Model 來利用上下文,同時避免mask的問題。其思想受NADE(一種生成模型)的啟發。
Permutation LM
思想:對原序列打亂順序生成多種亂序序列(設序列長度為T,一共有 \(T!\) 種可能)再按單向語言模型的方式訓練,這樣語言模型能夠學習各種排列順序下通過上文預測下文的方法,而「上文」實際可能是原序列裡的下文,因此能夠學習到各種上下文。排列語言模型的目標是調整模型引數使得下面的似然概率最大:
因為 finetuning 的時候只能按原本的自然順序,所以在預訓練時未真正打亂原序列輸入,而是採用Attention mask來實現(對每種排列生成一個mask方陣,在計算Attention時使用,可參考後文UniLM中Attention mask的設計思路,這裡先忽略),位置編碼仍按原序列順序。
Permutation LM 存在沒有目標(target)位置資訊的問題
由於將原序列打亂順序,在預測亂序序列中由上文預測當前詞時無法得到當前待預測詞是原序列中哪個位置的詞。雖然在輸入時新增了位置編碼,但傳統LM不使用當前待預測詞的位置編碼。而在原始LM中是按順序的,能夠推斷出當前詞的位置。而缺失位置資訊會怎樣?導致不同的序列可能有相同的預測。比如兩個原始序列ABCD與ABDC,其排列組合構成的集合是相等的,如果打亂順序後均採用了ABCD這個順序進行預測,那麼C、D將得到相同的預測概率值,但在原始序列中應當有不同的概率值。這樣導致模型無法學到有效的表示。
既然由於打亂順序導致位置資訊丟失,那麼可以顯式將當前待預測詞在原序列中的位置告訴網路(好比是給原本的位置資訊打修補程式)。論文中提出來新的分佈計算方法,來實現目標位置感知:
其中e(x)是x 的embedding,\(g_{\theta}(x_{z_{<t}},z_t)\) 是上文的表示embedding,並且把位置資訊 \(z_t\) 作為了其輸入。
論文對於\(g_{\theta}(x_{z_{<t}},z_t)\)的實現採用了masked attention,提出了 Two-Stream Self-Attention 雙流自注意力方法。在位置\(z_t\)來從context \(x_{z<t}\)裡通過Attention機制提取需要的資訊來預測這個位置的詞。那麼它需要滿足如下兩點要求:
- 為了預測 \(\mathbb x_{z_t}\),\(g_θ(x_{z<t},z_t)\)只能使用位置資訊\(z_t\)而不能使用內容資訊 \(\mathbb x_{z_t}\)。
- 為了預測\(z_t\)之後的詞,\(g_{\theta}(x_{z_{<t}},z_t)\) 必須編碼 \(\mathbb x_{z_t}\)的資訊(語意)。
但是上面兩點要求是矛盾的,不能用一種\(g_{\theta}(x_{z_{<t}},z_t)\) 來實現,對於普通的Transformer來說是無法滿足的。
論文在標準的Transformer Decoder之上採用兩種Attention,分別編碼兩個隱狀態:
- 內容隱狀態\(h_θ(x_{z<t})\),簡寫為\(h_{z_t}\),既編碼上下文(context)也編碼 \(\mathbb x_{z_t}\)的內容。初始化為詞的Embedding \(e(x_i)\)。
- 查詢隱狀態\(g_{\theta}(x_{z_{<t}},z_t)\),簡寫為\(g_{z_t}\),它只編碼上下文和要預測的位置\(z_t\),但是不包含 \(\mathbb x_{z_t}\)。初始值隨機初始化。
從m=1到第M層,逐層計算:
\(g_{z_{t}}^{(m)} \leftarrow\) Attention \(\left(Q=g_{z_{t}}^{(m-1)}, K V=h_{z_{<t}}^{(m-1)} ; \theta\right)\) Query流, 可以使用 \(z_{t}\) 但不能用其內容
\(h_{z_{t}}^{(m)} \leftarrow\) Attention \(\left(Q=h_{z_{t}}^{(m-1)}, K V=h_{z_{\leq t}}^{(m-1)} ; \theta\right)\) Content流, 同時使用 \(z_{t}\) 和 \(x_{z_{t}}\)
訓練時兩個流的網路權重共用。在最終預測 \(p_{\theta} (X_{z_t}=x | x_{z_{<t}})\) 時採用最後一層的query表示:\(g_{z_{t}}^{(m)}\) 。
當將這種雙流自注意力Permutation LM 預訓練模型用在finetune階段時,只採用content stream即可,不需要計算query stream。
雙流自注意力模型的計算過程示意圖如下:
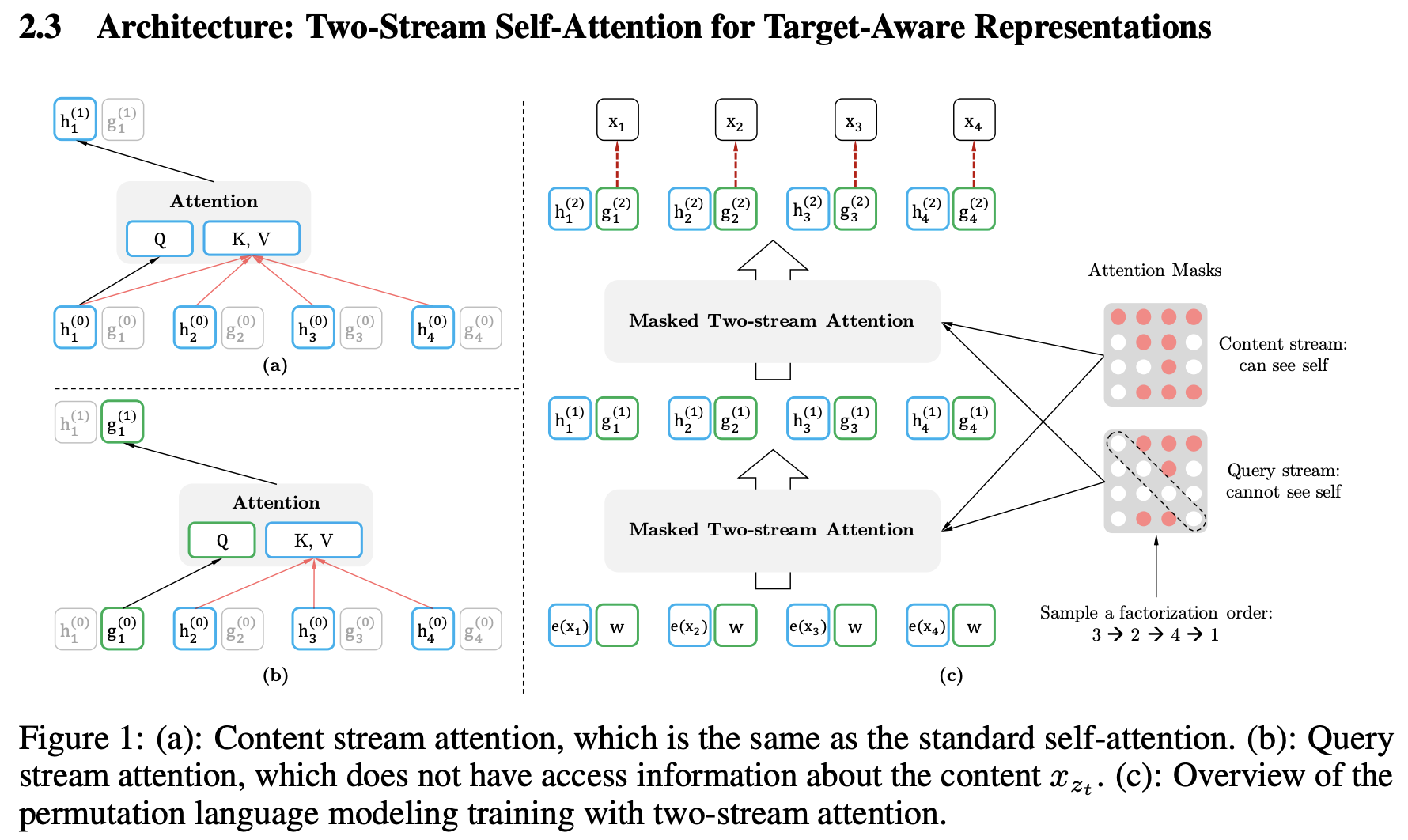
Partial Prediction 加速計算:Permutation LM的排列組合太多,為了提高計算速度,XLNet選擇僅預測靠後位置的token,而忽略對靠前位置的token的預測。因為前面的詞的上下文資訊相對較少,很難讓模型學習到很有效的模式。對於前面不用預測的token,不需要計算其Query流,從而能夠減少計算,同時節省記憶體。
預訓練時僅採用了Permutation LM,而去除了Next Sentence Prediction,作者發現該任務對結果的提升並沒有太大的影響。雖未採用NSP任務,但是採用類似的輸入格式:A [SEP] B [SEP] [CLS],將CLS放在最後是Partial Prediction只預測靠後位置的token的原因。NSP的格式可以處理QA問答等型別的資料,在下游任務中常常被使用。
相對Segment編碼
在BERT的NSP格式資料輸入時採用了segment編碼來區分句子(屬於A還是B),但如果調換句子順序,編碼發生改變會導致預測結果發生變化。為避免這個問題,XLNet採用相對Segment編碼,與相對位置編碼類似,將編碼移到了計算Attention的時候而不是提前在輸入的時候。對於兩個token的segment編碼,只需關心它們是否屬於同一個句子,而不關心絕對值(屬於哪個句子)。設在同一個句子時採用編碼 \(s_{ij}=s_+\),否則 \(s_{ij}=s_−\)。計算一個新的attention score:\(a_{ij}=(q_i+b)^Ts_{ij}\)。這裡的 \(q_i\) 是第i個位置的Query向量,b是一個可以學習的bias。最後把這個attention score加到原本的Attention score裡。
SpanBERT 2019
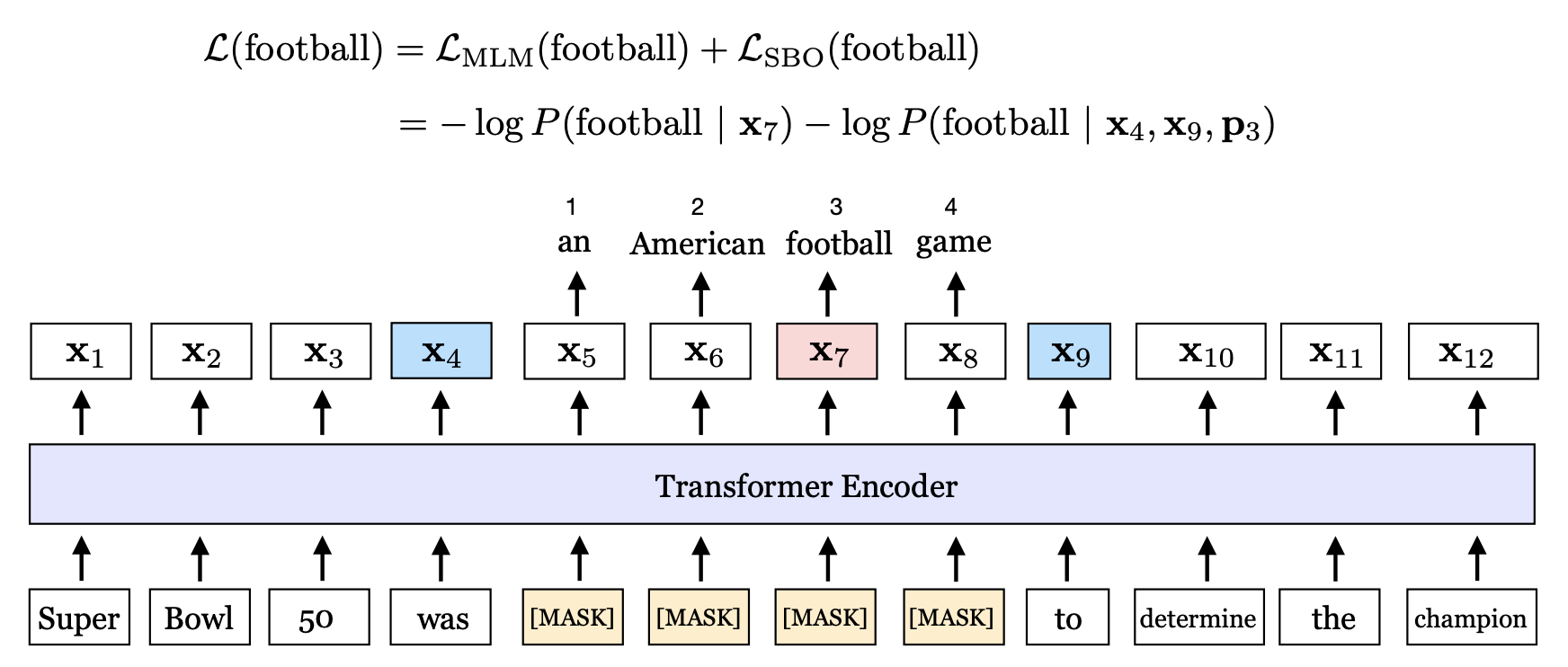
SpanBERT: Improving Pre-training by Representing and Predicting Spans(TACL 2020.)
這篇Facebook AI Research 2019的論文對 Span Mask 方案 進行了很細節地探索,主要包含兩點改進:
-
隨機mask一段連續文字,展示了隨機遮蓋連續一段字要比隨機遮蓋掉分散的字效果好。
-
加入 Span Boundary Objective (SBO) 訓練目標,更好地預測被遮蓋的文字,增強了 BERT 的效能。
遮蓋(span)的設定方式:從幾何分佈( \(\ell \sim \operatorname{Geo}(p=0.2)\) s.t. \(\ell_{\max }=10\))中取樣1~10作為span長度(拒絕取樣法拒絕超過10的數位,實現時採用迭代隨機取樣,每次有p=0.2 的機率繼續擴充套件Span, 1−p=0.8 的機率停止擴充套件Span);從均勻分佈取樣起始位置。並確保總是遮蓋完整的詞,即避免出現子詞(subwords)被切割到兩部分的情況。
幾何分佈,是一種長尾分佈。參考:幾何分佈 - 維基百科
幾何分佈(Geometric distribution)指的是以下兩種離散型概率分佈中的一種:
- 在伯努利試驗中,得到一次成功所需要的試驗次數X。X的值域是{ 1, 2, 3, ... }
- 在得到第一次成功之前所經歷的失敗次數Y = X − 1。Y的值域是{ 0, 1, 2, 3, ... }
實際使用中指的是哪一個取決於慣例和使用方便。在這裡我們用從1開始的形式,每次試驗的成功概率是p,第k次才得到成功的概率是:
\(P(X=k)=(1-p)^{k-1}p\), k取無窮極限時數學期望是 1/p
由於SpanBERT中採用了拒絕取樣法取樣1~10,span長度的期望並非 1/p = 5,而是需要考慮排除超過10的概率 \((1-p)^{10}\). 設 \(q=1-p\),那麼拒絕取樣取到長度為k的概率是:\(P(X=k)={q^{k-1}p \over 1-q^{10}}\).
即 span 長度為 1 的概率是 \(p/(1-q^{10})=0.224\),span 長度的期望是 \(p(1+2q+3q^2+...10q^9)/(1-q^{10}) = 3.797\)。
實現:仿照原BERT中的引數設定對隨機的15%的token進行mask(在其中80%用[M]替換,10%用隨機詞替換,10%不變)。SpanBERT與之類似,只是在隨機生成span mask的時候需要控制下token的總數量,對每個span中的連續token替換成[M]或取樣的隨機詞。
實驗表現:隨機的span方式略勝出於WWM或ERNIE中引入命名實體外部知識masking方法,或許可以說明引入類似詞邊界資訊不是特別需要。當然由於不太好公平地對比模型,說服力不足。
論文繼續設計了一個利用邊界和位置編碼來對mask進行預測的任務損失函數,能夠提升指代消解等任務的表現。
具體做法是,在訓練時取 Span 前後邊界之外的兩個詞的向量加上 Span 中被遮蓋掉詞的位置向量,來預測原詞:\(\mathbf{y}_i =f \left(\mathbf{x}_{s-1} , \mathbf{x}_{e+1} , \mathbf{p}_{i-s+1}\right)\), 其中位置編碼採用的第i個待預測詞\(x_i\)相對於左邊界\(x_{s−1}\)的偏移位置編碼,即第 $ i-(s-1)$ 個位置對應的位置編碼。應該還是採用的原BERT或Transformer的絕對位置編碼,而不是XLNet等模型中採用的相對位置編碼實現方式。
\(f(\cdot)\) 函數具體用的是BERT的FFN結構來實現:
然後這個SBO任務和MLM一樣通過交叉熵計算損失並求和:
SpanBERT 預訓練任務的示意圖:
MLM的損失函數是怎樣的?和CBOW類似,對每一個被mask的token通過輸出embedding與輸入的lookup embedding相乘取softmax求損失,然後計算所有mask token的平均值。參考BERT原始碼run_pretraining.py中的 get_masked_lm_output 函數。
SpanBERT具體實現的一些細節同作者同時期釋出的另一篇RoBerta論文:
- 採用動態mask(Dynamic Masking)
- 取消 BERT 中隨機取樣短句的策略:取消 BERT中前90%次迭代採用128長度的短文字,後10%採用512長文字的設定,統一用512長文字。
- 去除NSP任務,1)句子對的引入限制了單句最長文字長度. 使用單句訓練, 最長文字長度可以直接翻倍. 2)句子對上下不相關時, 會引入非常大的噪聲.
參考:SpanBert:對 Bert 預訓練的一次深度探索 - 知乎
StructBERT 2019
StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding(ICLR 2020. 阿里2019.9)
之前的BERT、RoBERTa等模型雖然主要集中解決自然語言理解(NLU)問題,但仍然沒有把語言結構資訊整合進去。
StructBERT對原始BERT進行了擴充套件,在單詞和句子級別應用語言結構,新增兩個輔助任務: word-level ordering and sentence-level ordering ,使其能夠注意到句子中的結構資訊的變化。具體方式為通過打亂單詞和句子的順序,讓模型學習單詞和句子的原始順序(較流利的表達方式)。這兩個輔助任務分別體現在MLM、NSP任務上:
- Word Structural Objective:隨機選擇一些長度為K的子序列打亂單詞順序,通過Transformer的編碼表示預測對應位置原本的單詞,通過極大似然估計:\(\arg \max _{\theta} \sum \log P\left(\operatorname{pos}_{1}=t_{1}, \operatorname{pos}_{2}=t_{2}, \ldots, \operatorname{pos}_{K}=t_{K} \mid t_{1}, t_{2}, \ldots, t_{K}, \theta\right)\)。為達到模型魯棒性和模型重建能力的平衡,論文設定K=3,取樣5%的三元組做隨機打亂。該任務與原始MLM進行聯合訓練。
- Sentence Structural Objective:原始BERT的NSP任務過於簡單,能夠很輕易達到 98% 左右,在RoBERTa等方法中未被使用。而通過增加該任務的難度還是能夠對於預訓練模型有幫助的,具體方式為將NSP改為三分類:下一句、上一句、負例(其他檔案的隨機一句),等概率抽樣三部分的樣本。相當於將NSP任務與「PSP」任務結合起來。這個思路比ALBERT的段落連續性任務(調換順序作為負例)更高階一些,比ERNIE2.0的Sentence Reordering Task低階。
這兩個輔助任務都屬於排序任務,但在實現方式上做了簡化,兩類任務的圖示如下:
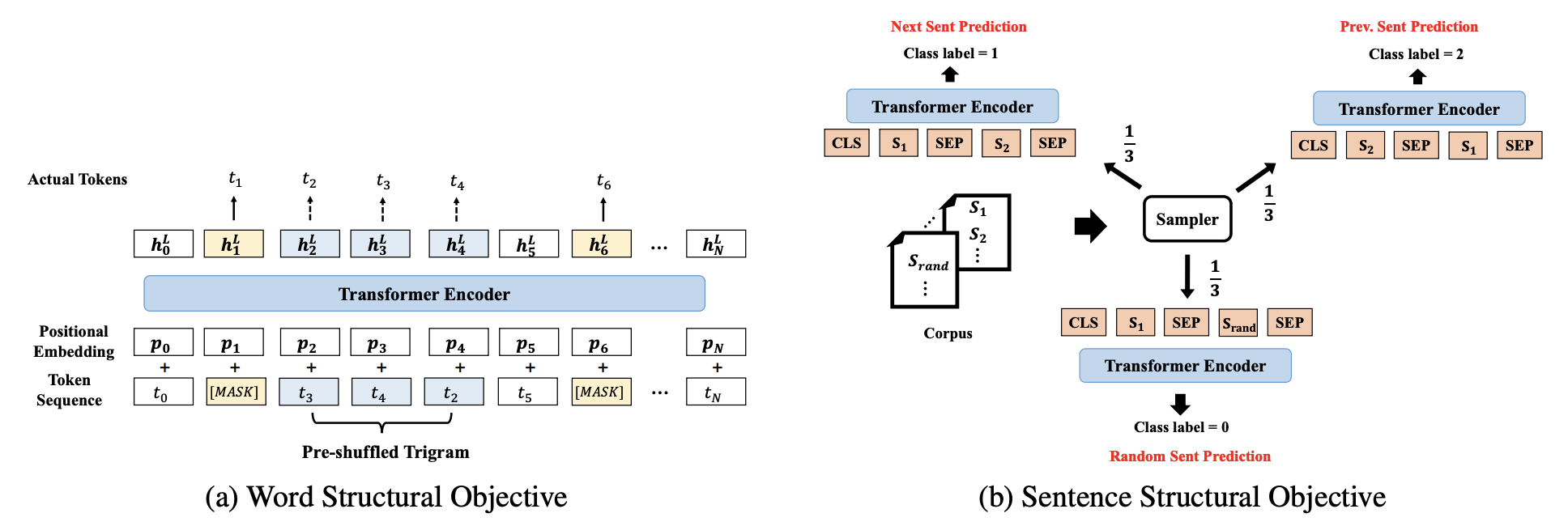
MASS/BART 2019
MASS: Masked Sequence to Sequence Pre-training for Language Generation (ICML 2019,微軟)
前面提到的GPT、BERT各有特點,但是應用受限:
- GPT採用decoder、單向、生成式;
- BERT採用encoder、雙向、判別式。
微軟的 MASS 用seq2seq框架結合了BERT與GPT的思想,能夠應用於機器翻譯、對話等 seq2seq 任務。在encoder中對部分子序列片段進行mask,在decoder中利用encoder的輸出對被mask的子序列進行解碼預測。
不同於傳統seq2seq的是,Decoder的目標為重構被mask(加噪)的文字。訓練時Decoder的輸入為對Encoder輸入反mask之後右移一位(Teacher Forcing)的結果。至於為什麼在Decoder中對於不需要預測的部分用mask來替換,作者的解釋是這樣能更充分利用Encoder的編碼,而BART模型則未設定為mask。
MASS 結構示意圖如下:
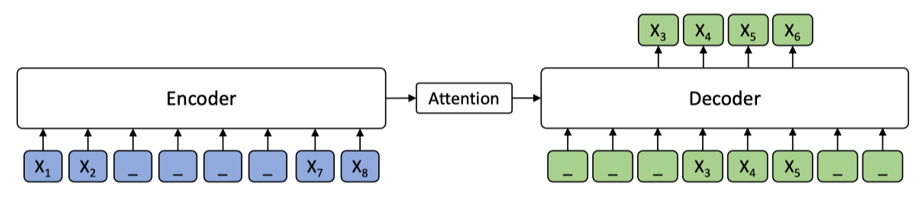
Mask策略:隨機選一個位置開始(純隨機,不考慮被切割後兩個子詞subword分離的問題),連續mask掉句子長度50%的token(閾值是通過實驗對比選定的較優值)。並且參考BERT的策略,80%的時間用[M],10%用隨機的token,10%保留原token。
連續mask的長度k在兩個極值情況下對應兩個特例:BERT、GPT,因此MASS可以看作是對BERT、GPT的統一框架。
MASS特點:
- Encoder和Decoder聯合訓練. 統一了BERT、GPT這兩類單獨訓練Encoder或Decoder的模型。用於生成模型時相比GPT,能使Decoder從Encoder獲取更多的資訊。
- 連續mask獲得更好的效能(相對於原始BERT單個token級別的掩碼)
MASS主要應用於機器翻譯任務,相比分開預訓練encoder和decoder(BERT+LM),聯合訓練效果要好一些。但是MASS的提升不是很顯著,可能還有更好的聯合訓練方式。
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019.10 略晚於MASS,Facebook)
BART(Bidirectional and Auto - Regressive Transformers) 是一個和MASS類似的思想,同樣採用Transformer,讓Decoder解碼噪聲。
特點:
- 沒有采用BERT的FFN,這使得BART只比同級別的BERT多了10%的引數。
- Encoder 新增噪聲擾動的方式不受限制,容許任意的方式。
異同:
- BERT、MASS和BART都是去噪自編碼器(Denoising AutoEncoder),隨機mask便是一種噪聲,使用自編碼器進行自學習,目標為去除噪聲還原輸入。
- BART給出了除mask外的更多的噪聲種類:隨機刪除、重排列打亂順序、旋轉字元陣列、連續文字替換成一個[Mask] token,組合這些方式使得模型的學習難度可大大增加。
- MASS對Decoder的設計比較特別,對於不需要預測的部分用mask來替換,更充分利用Encoder的編碼。但是由於Encoder/Decoder採用不相交的文字集合作為輸入,不利於判別式任務。而BART模型未設定為mask,給的說法是減少預訓練與下游生成式任務之間的mismatch,都用不加噪聲的文字作為輸入。
其中連續文字替換成一個[Mask] token的方式,論文稱之為 Text Infilling ,受SpanBERT的啟發。但相比SpanBERT的替換為mask序列,BART僅替換成一個mask,帶來的好處是能讓模型學習缺失的token個數(增加學習難度)。
BART效果比MASS顯著,並能取得與RoBERTa相近的結果。
下游任務:
- 分類任務:讓Encoder和Decoder以相同的資料輸入, 利用Decoder的最後一次輸出作為tokens或句子的表示進行分類。
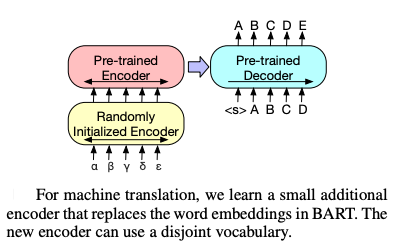
- 機器翻譯:額外訓練一個外語對映的Encoder,將源語言與目標語言進行語意空間對齊,替代掉原來的Word Embedding,示意圖如下。訓練方式為:1. 固定住BART的大部分預訓練引數,僅學習額外的編碼器+BART的位置編碼+BART Encoder的第一層Self Attention投影矩陣。2. 原BART+額外Encoder整體訓練,做少量次數的迭代。mBART 是多語言版的機器翻譯模型。
UniLM 2019
UniLM 是與MASS同時期的微軟研究院出的另一篇論文 Unified Language Model Pre-training for Natural Language Understanding and Generation(NeurIPS 2019,MSRA),自然語言理解與生成的統一預訓練語言模型。程式碼地址:程式碼:unilm,中文Unilm
UniLM出發點和MASS類似,也是因為BERT的MLM的雙向性使得它很難應用於自然語言生成任務。但是UniLM與MASS的實現方法卻截然相反,MASS將BERT MLM引入傳統seq2seq,而UniLM將seq2seq的思想引入到BERT。UniLM通過修改訓練時額外新增的Mask矩陣控制預測時依賴的上下文,既可以應用於自然語言理解(NLU)任務,又可以應用於自然語言生成(NLG)任務。
UniLM 在 Transformer 每層中的自注意力頭輸出 \(\mathbf A_l\) 表示中新增了Mask矩陣 M 來控制Attention的範圍,從而能夠靈活地改變模型的執行模式(單向、雙向、seq2seq):
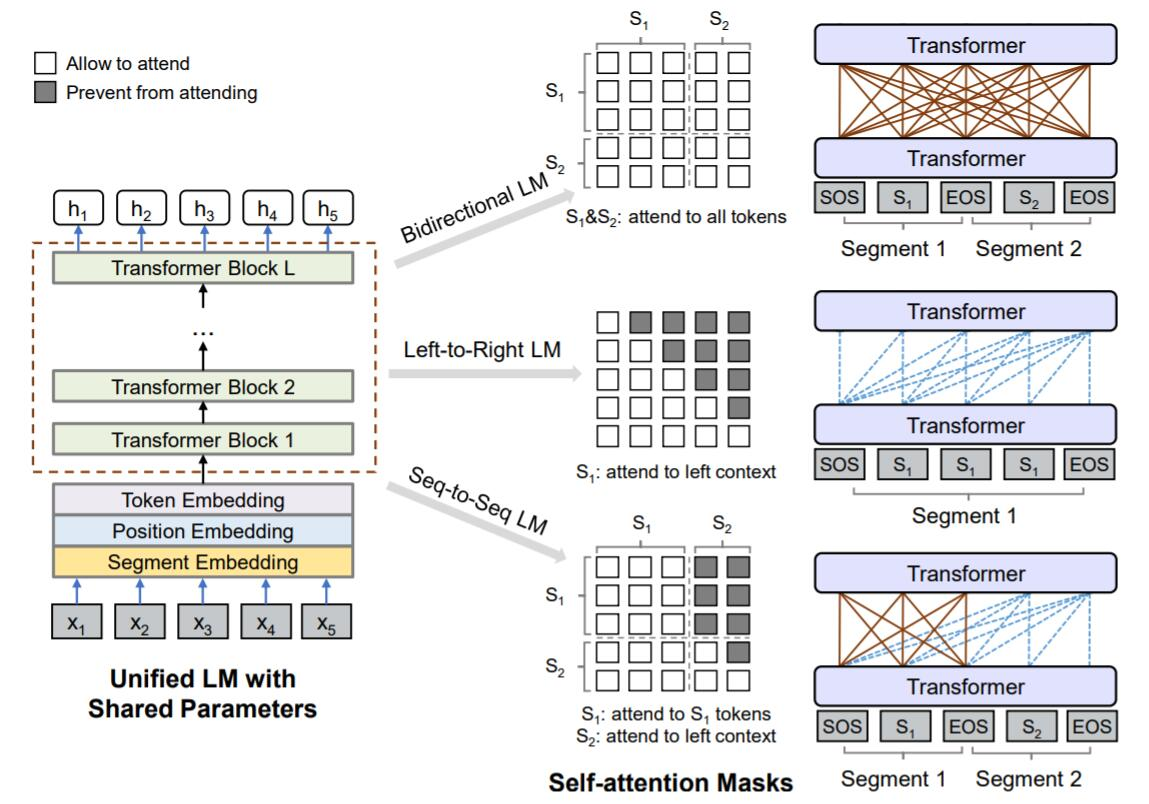
輸入表示:為統一NLU、NLG,在輸入表示上對文欄位新增起始和結束token標誌:[SOS]、[EOS]. 在NLU任務上對應BERT的 [CLS]、[SEP],其中[EOS]作為NLU任務的邊界標記,NLG任務的生成結束標記。
模型結構:UniLM的巧妙之處在於使Encoder和Decoder共用權重,實際上合併成一個Encoder或Decoder(姑且稱這個掩碼矩陣控制的編解碼器為"X-coder"吧,相比Transformer去除了Encoder-Decoder間的跨層Attention連線),這樣與BERT(Encoder)的結構完全相容,能夠使用BERT的預訓練權重做初始化(論文從BERT-large初始化)。
預訓練:包括unidirectional, bidirectional, sequence-to-sequence prediction三種,均採用BERT的MLM訓練方式,對於bidirectional單獨再新增了NSP任務。對於單向LM而言僅能用左邊/右邊的tokens預測被mask的詞,seq2seq模式則是雙向LM(對應 \(S_1\) encoder部分)與單向LM(對應 \(S_2\) decoder部分)的組合。
具體地,在一個訓練batch中,(1)使用1/3的資料進行雙向語言模型優化,(2)1/3的資料進行序列到序列語言模型優化,(3)1/6的資料進行從左向右的單向語言模型優化,1/6的資料進行從右向左的單向語言模型優化。這種multi-task learning方式與常規的方式(batch所有資料計算所有任務的loss按權相加)應該沒有本質的不同。
模型對比:
- 統一方式:UniLM具有和BERT相同的結構,這種統一方式相比MASS/BART更為簡介,在做下游任務時不需要考慮丟棄Encoder/Decoder的問題。當然這種「權重共用」的方式相比非共用的Encoder-Decoder,在機器翻譯等任務上可能表現較差。
- 預訓練任務:UniLM利用了多種任務聯合訓練,而MASS僅有MLM一種。
UniLM-v2 論文 UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training(ICML 2020),譯為偽掩碼語言模型預訓練的統一語言模型,是MSRA對前作UniLM的改進。UniLM通過Self Attention Masks將AE、AR、Seq2seq統一到一個模型結構中進行聯合訓練,但每個任務(加上NSP是4個任務)的輸入資料格式不同(有無mask、單雙多句),均需要經過encode,整體預訓練耗時較高。UniLMv2將預訓練任務數縮減為兩個(AE、PAR),並統一為相同的輸入,實現了encode的重複利用。
-
自編碼任務(autoencoding, AE):普通的MLM,預測每個mask掩碼時是互相獨立的。
-
自迴歸任務(autoregressive, AR):在XLNet部分介紹過自迴歸(AR)任務,前一個預測結果會被用於預測下一個結果。UniLMv2為了統一AE與AR的輸入資料格式,(1)借鑑了XLNet的Permutation LM的思想通過打亂AR的預測順序實現雙向的編碼;(2)加入了[Mask]使其與MLM格式相容,並且修改了預測目標,僅預測被mask的token,而不像傳統LM那樣預測連續的每一個token。極大似然估計也改為基於所有非mask文字預測按指定順序自迴歸預測被mask的tokens。和XLNet不同的是,PAR只對mask打亂順序,而非mask token保持原順序;而XLNet則沒有采用mask做訓練,全部token打亂順序。(3)對AR引入mask後帶來的一個問題是當某個mask token在某一步被預測之後需要替換成預測值再被用於預測後續的mask token,這個替換過程不易實現,可能會影響訓練速度。為解決這一問題,作者巧妙地設計了一個偽掩碼語言模型(PMLM),在做資料預處理時並不直接將原token替換為[Mask],而是改成在原token之後(或之前)插入[Mask]、[Pseudo]這兩個token,並且使其與原token共用同一個位置編碼,稱這兩個掩碼token為偽掩碼。因此該論文所述的AR任務與傳統的單向LM有了較大的區別。
-
部分自迴歸任務(partially autoregressive, PAR):部分自迴歸任務是在上述修改後的AR任務上像SpanBERT那樣對連續的token span進行掩碼後預測,對於一個span內的多個token可以做獨立並行預測,因此稱為部分自迴歸。
引數設定:在掩碼中設定40%的比例採用n-gram的span mask(\(n\sim U[2, 6]\))。
為了統一AE、PAR任務的輸入,論文設計瞭如下的偽掩碼語言模型(PMLM):
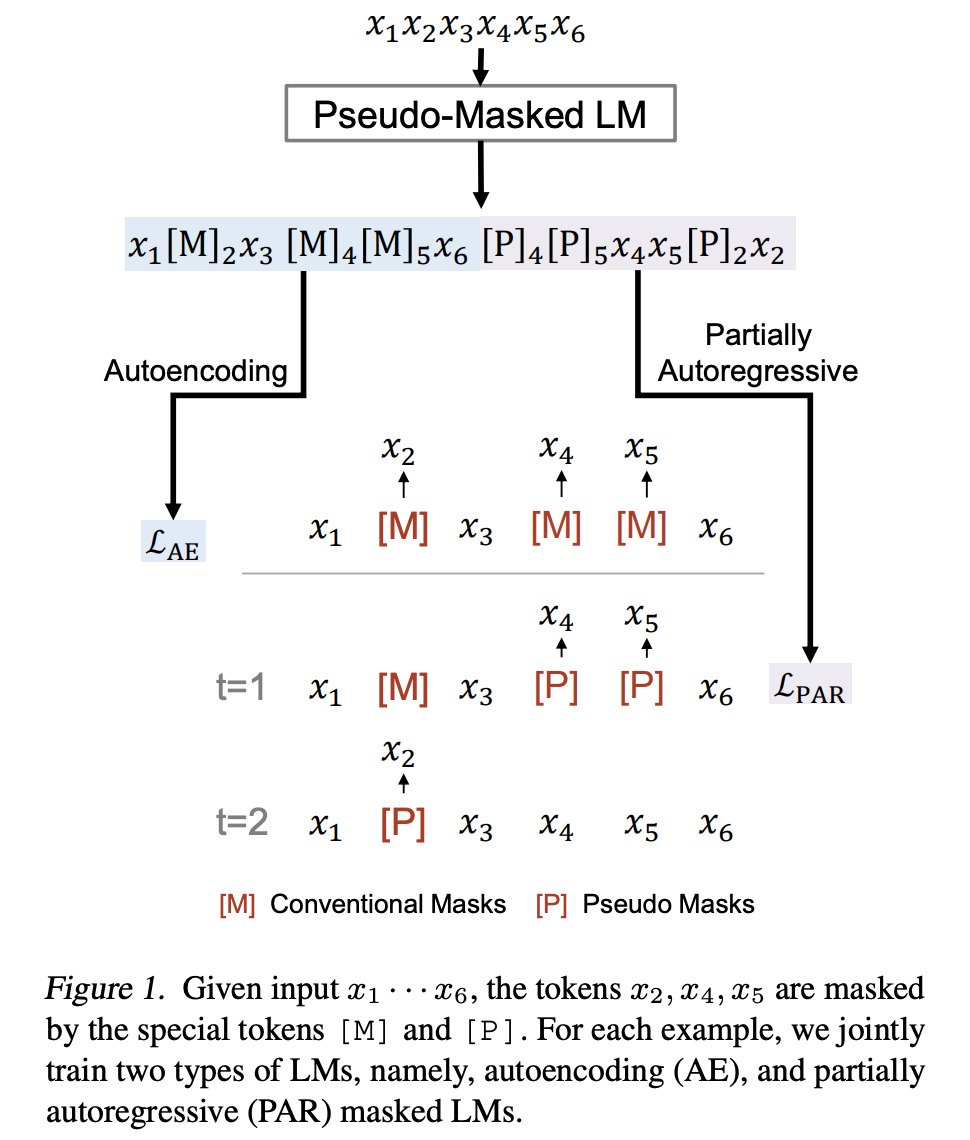
圖中待預測的排列組合順序為 4, 5 → 2,其中4,5處於同一個span mask。在輸入編碼上AE、AR表現為先後的關係,左半部分(淺藍色部分)即常規的MLM,右半部分為隨機的待預測掩碼[P]及目標token拼接在了MLM的末尾,PAR任務作用在整個的輸入上,conditioned on left 從左向右進行自迴歸預測。其中[P]僅用於PAR任務,conditioned on 左側的原始token及[M].
和XLNet類似,在實現上圖所示的模型時並不真正地在預處理資料時打亂順序,而是通過Attention Mask來設定順序。
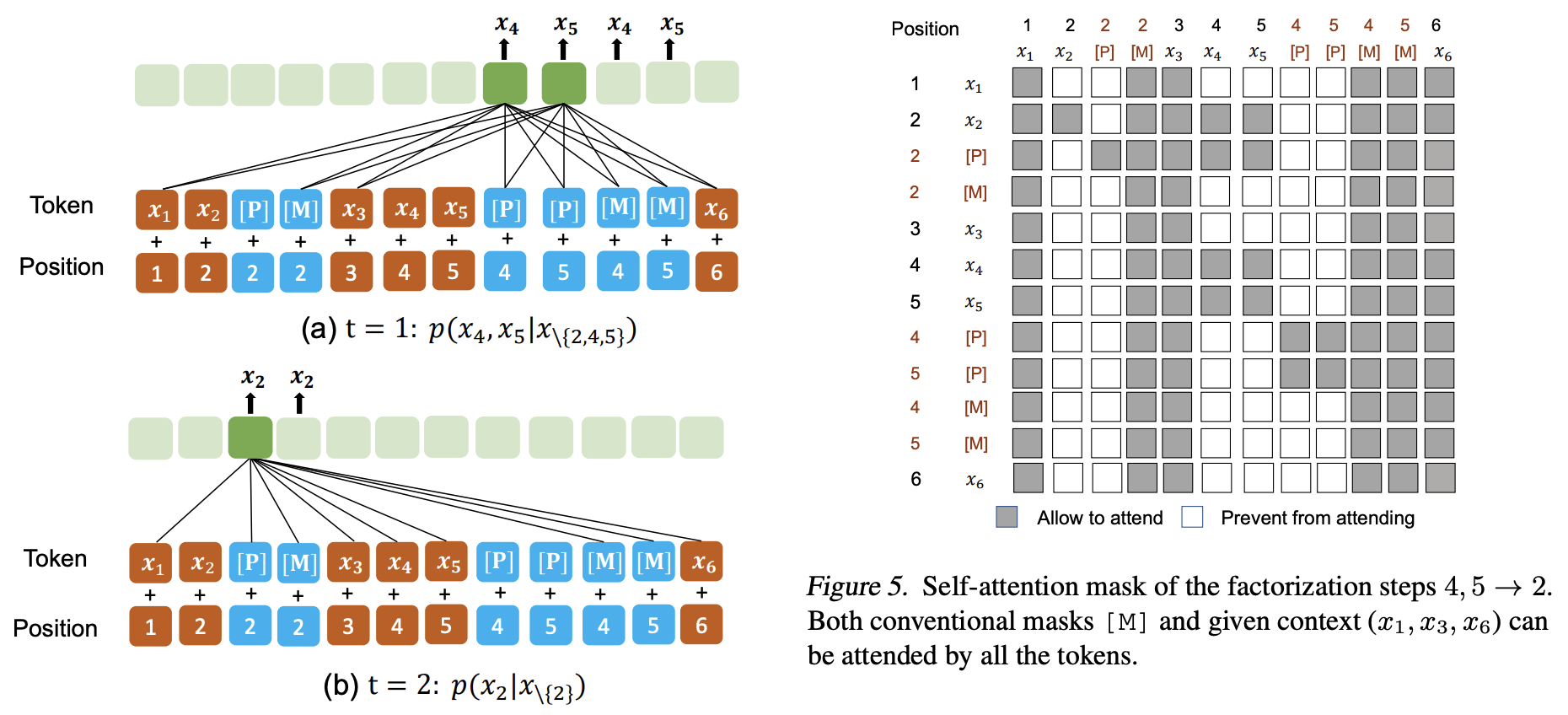
共用位置編碼的設計使得PAR任務中的[M]、[P]與MLM任務中的[M]無異,通過Attention Mask來控制條件,使得[M]、[P]容易被替換為原token。
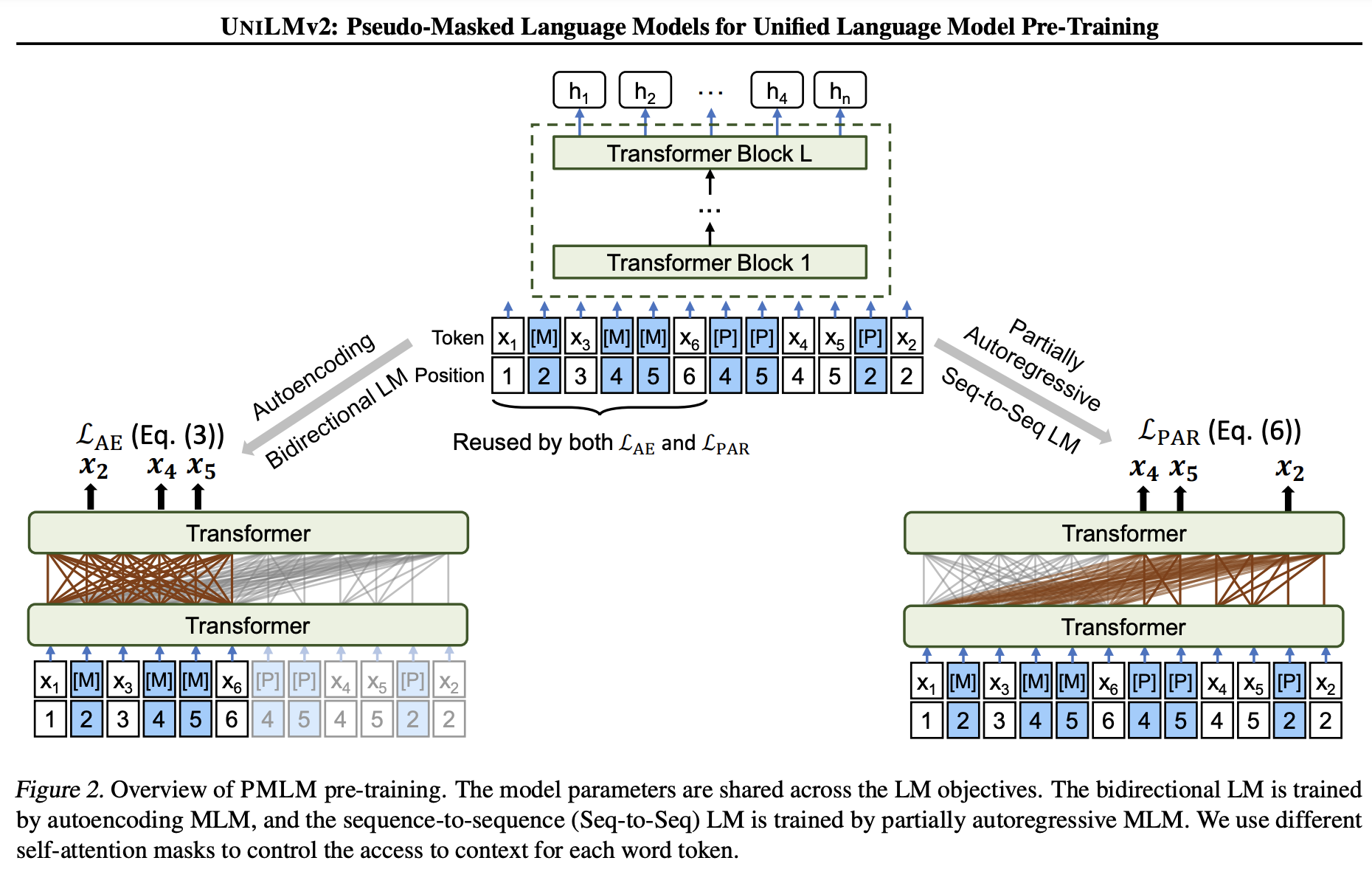
模型對比:UniLMv2相比v1,
- 縮減任務數量為AE+AR,通過偽掩碼統一了輸入格式,使得兩個任務共用前向計算。模型結構更加統一、訓練更加高效。
- 通過span mask,鼓勵學習長距離的依賴關係。
實驗結果表明,PMLM提高了多種語言理解和生成基準的最終結果。在問題生成和文章摘要抽取等任務上,\(\text{UniLMv2}_{BASE}\) 取得了比 \(\text{UniLM}_{LARGE}\) (引數量大三倍)更好的結果。此外,與BERT相容,可以直接採用BERT預訓練權重進行初始化,即便不繼續做預訓練調整直接在下游的生成任務上做finetune,也能取得不錯的效果。
參考:
T5 2019
Text-to-Text Transfer Transformer (T5):Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (JMLR2020)
Google 出品的預訓練模型,提出了NLP遷移學習的新思路:將每個NLP 問題看作 text-to-text 任務。其理念為「萬事皆可Seq2Seq」。
-
對於監督任務通過在原始輸入文字新增字首來區分任務,如:「translate English to German:」, 「summarize:」。這種轉化跟 GPT-2、GPT-3、PET 的思想一致,用文字把要做的任務表達出來,然後都轉化為對文字的預測,即通過給模型一個提示(prompt)讓模型按生成模型的方式來生成答案。
-
對於無監督任務,如MLM的Seq2Seq模式可以是下面這樣,和MASS模型的輸入格式也類似,mask後的文字是encoder的輸入,decoder 輸出重建文字。
輸入:明月幾時有,[M0] 問青天,不知 [M1],今夕是何年。我欲[M2]歸去,唯恐瓊樓玉宇,高處 [M3];起舞 [M4] 清影,何似在人間。
輸出:[M0] 把酒 [M1] 天上宮闕 [M2] 乘風 [M3] 不勝寒 [M4] 弄 [END]
模型:Text-to-Text Transfer Transformer (T5),大模型11B( 110 億)引數。 和Transformer一樣同時採用了encoder和decoder,即標準的 Seq2Seq 模式。GPT-2 則僅用了decoder。
資料:採用了比GPT-2 WebText(40GB)更大的清洗過的網頁資料集 Colossal Clean Crawled Corpus (C4) (超大型乾淨爬取資料,750GB,在TensorFlow Datasets開放),資料與程式碼連結:GitHub。資料來源於 Common Crawl(一個公開的網頁存檔資料集,每個月大概抓取 20TB 文字資料),經過多種策略清洗:只保留結尾是正常符號的行;去掉包含 Javascript 、各類程式語言的行,等等。
多國語言版 mT5: A massively multilingual pre-trained text-to-text transformer,資料集 mC4,與T5結構一致,僅資料集不同。參考:那個屠榜的T5模型,現在可以在中文上玩玩了
預訓練
- 參考SpanBERT,mask掉15%的span(固定span len=3)。ALBERT也是類似做法,但設定了不同的1-3 gram的取樣概率。
- 學習率 \(\eta =1 / \sqrt{\max(t, k_\text{warmup})}\), 前1w步warm-up設定固定學習率0.01,後邊步驟按逆平方根衰減。也嘗試了consine學習率,在確定最大迭代次數的前提下能得到比較好的學習結果,但因為需要頻繁實驗,沒有都採用cosine。
- 模型架構:Prefix LM。
Transformers 預訓練模型中的三種模型架構對比:
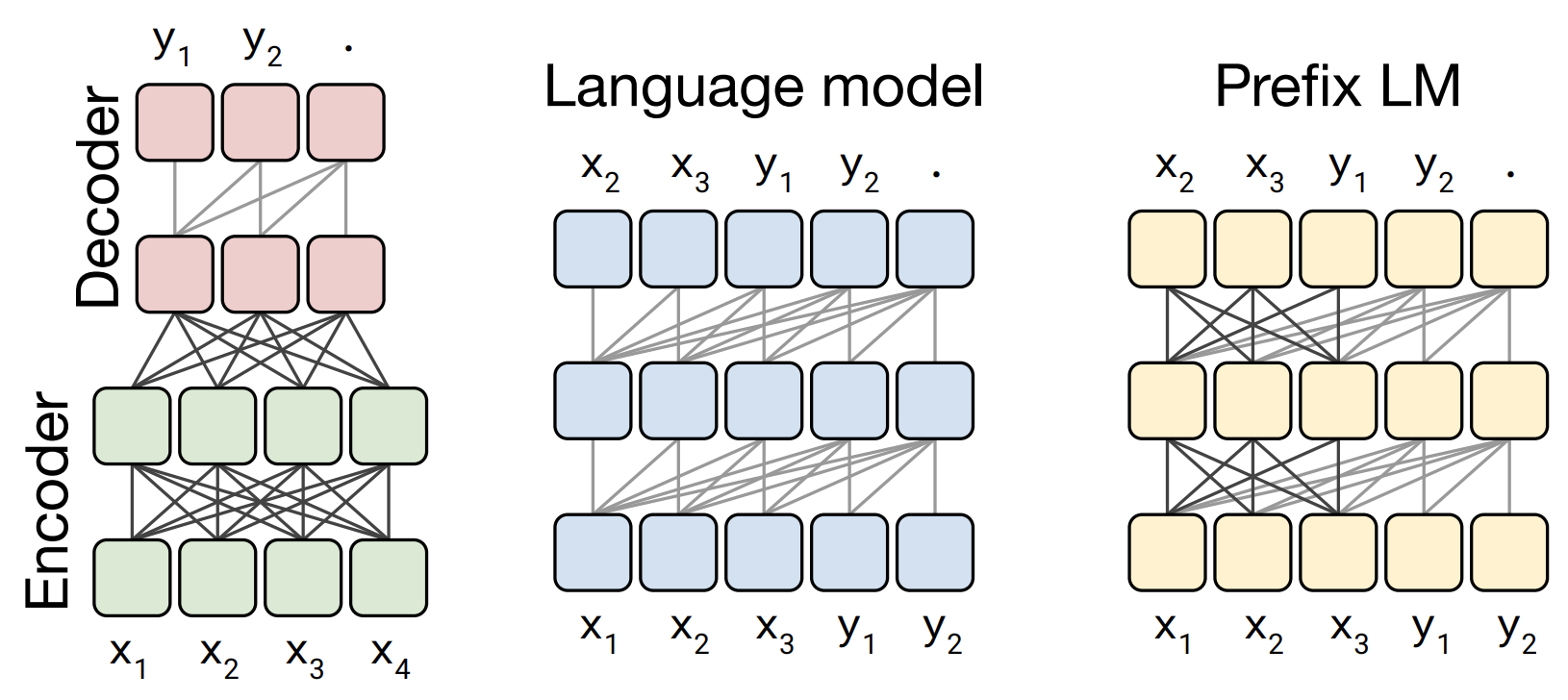
灰線表示常規語言模型中只對上文的依賴,即包含字首mask的Attention,實線表示全連線,完全的Attention。句點.表示輸出的終結符。
- Encoder-Decoder,原始的Transformer正是屬於這種,Encoder中採用完全Attention,而Decoder中mask掉待預測的部分。
- Decoder,如GPT,僅用了Transformer的Decoder部分。對於text-to-text任務,將input和target拼起來作為語言模型的輸入。
- Prefix LM,對於text-to-text任務,第2種Decoder的方式按序列預測input的部分顯然沒必要,增加了多餘的約束。可將input和target分兩部分看待,input部分採用full attention,target部分採用原Decoder 方式只看過去的資訊。UniLM 模型 便是此結構。
Attention Mask的區別:
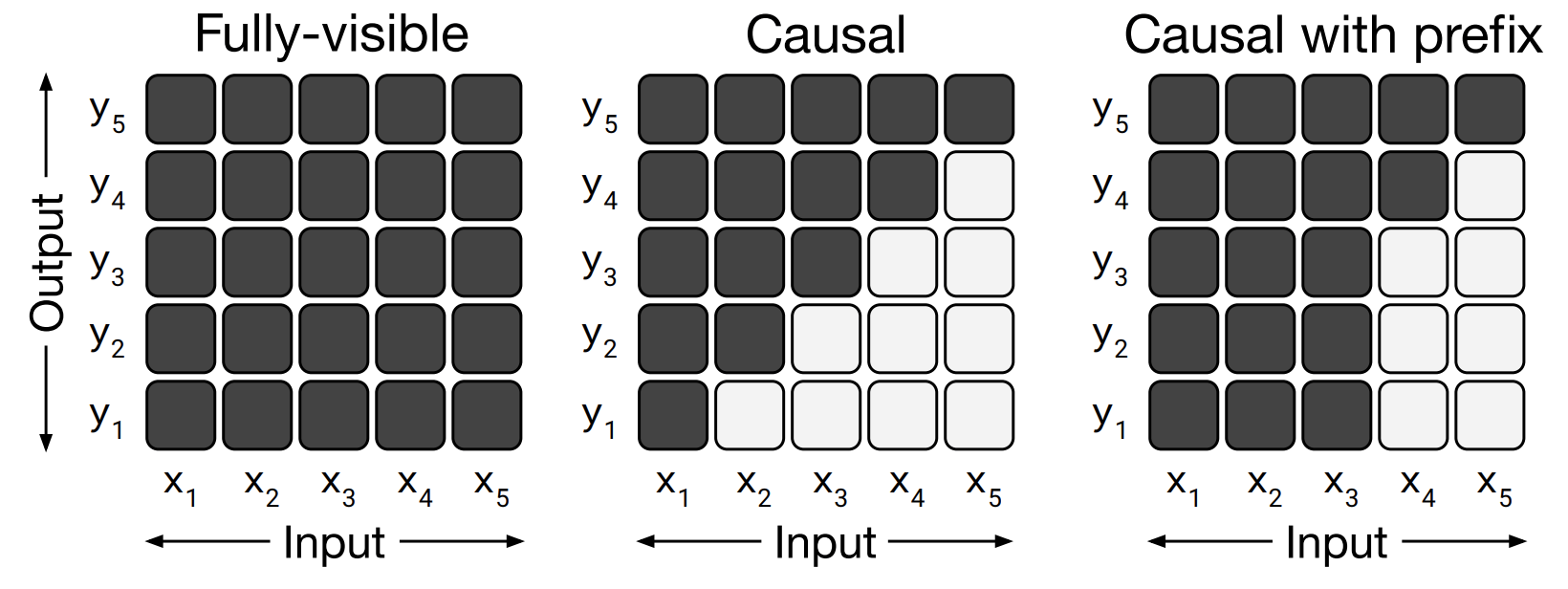
Prefix LM架構,可以類比BERT(採用Encoder完全Attention)做分類的方式,BERT新增了[CLS] token來做分類,而Prefix LM可以看作是用input來預測target標籤類別,只不過這裡的target是純文字,而不是one-hot編碼。
相比於原始的Transformer, Prefix LM可以看作encoder和decoder共用引數,而兩者之間聯絡的encoder-decoder attention被換成target和input之間的full attention。
This architecture is similar to an encoder-decoder model with parameters shared across the encoder and decoder and with the encoder-decoder attention replaced with full attention across the input and target sequence.
T5通過實驗對比了不同的架構的表現,發現還是原始的Transformer結構表現最好,並且如果用shared方式共用encoder和decoder的引數不會使效果差太多。而Prefix LM架構會稍差一些。
T5在解碼時大部分任務使用Greedy decoding,對於輸出句子較長的任務使用beam search。對於 WMT translation 和 CNN/Daily Mail summarization tasks 設定 beam width = 4 ,length penalty α = 0.6 .
相對位置編碼 Relative position embeddings (PE)
T5使用了簡化的相對位置編碼,用一個數值標量\(b_{j-i}\)而不是向量來表示相對位置資訊,將數值加在attention的softmax計算公式中的logits之上,不過對mult-head的每個head設定了不同的PE,所有的層共用一套PE。在BERT中,attention公式中的(Qc + Qp) x (Kc + Kp) 包含了內容-內容、內容-位置、位置-內容、位置-位置四項組合。T5的設計思路為假設內容資訊與位置資訊是獨立的,它們之間不應該有互動,僅利用位置-位置的互動。而後起之秀DeBERTa的相對位置編碼設計思路與之恰恰相反。
不同於常規的相對位置編碼的j-i截斷方式,T5設定了一種分桶截斷方法,128以內距離的位置越遠共用編碼的桶越大。
啟用函數
T5在論文放出之後的程式碼實現中做過一次升級(版本T5.1.1,參考 released_checkpoints.md 這裡的說明):
-
預訓練時關閉Dropout,而微調時開啟。
-
將Transformer的FFN中的啟用函數由 ReLU 替換成 GEGLU,而BERT則是採用GELU,兩個G的含義不同 門控 vs 高斯。
GEGLU 是 GLU (Gated Linear Unit)啟用函數的變體,源自 GLU Variants Improve Transformer (Google, 2020),將GLU中的sigmoid替換為GELU,函數形式如下(忽略bias項的書寫):
GLU通過門控機制對輸出進行把控,像Attention一樣可看作是對重要特徵的選擇。其優勢是不僅具有通用啟用函數的非線性,而且反向傳播梯度時具有線性通道,類似ResNet殘差網路中的加和操作傳遞梯度,能夠緩解梯度消失問題。
為什麼?對比下sigmoid 及 LSTM中使用的 gated tanh unit (GTU) 的梯度:
由於 sigmoid和tanh的導數會downscaling,導致梯度消失問題。而GLU相比sigmoid多出一個線性乘積項,梯度中的\(∇X \odot σ(X)\) 不會對 σ(X) downscaling,因此能夠加速收斂。
注:T5 沒用 bias,使用的簡化版的 Layer Normalization 去掉了bias,僅用縮放。因為輸入歸一化到0,因此後邊的FFN也不再需要bias。 而Transformer、BERT中都是採用 Bias 的。採用GEGLU的FFN公式演變為:
可以看出增加了一個W3的引數,引數量增加50%,但是效能提升比較顯著。
除了用GELU替代GLU中的sigmoid外,還可用ReLU、Swish等,甚至取消其中的啟用函數(Bilinear(x, W, V) = xW · xV),但是這些變體相比GLU差異不是很顯著。
ALBERT 2019
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations(ICLR 2020)
論文提出了引數更少的 BERT,可以看作是谷歌對先前提出的BERT的訓練方法的bag of tricks。
ALBERT 採用了兩種方式來縮減引數:
-
嵌入矩陣分解 (factorized embedding parameterization)
-
引數共用(cross-layer parameter sharing):共用層與層之間的引數,減少模型引數。
(1)嵌入矩陣分解:縮減輸入的嵌入向量(lookup table)的維度,BERT中為了簡便利用ResNet那種短路連線將嵌入向量維度和後續的隱藏層維度設定成相同值便於後續的Add&Norm。但實際嵌入向量只需要能夠區分每個不同的輸入即可,不需要太大的向量空間。lookup table的大小為詞表大小Vx向量維度E,對於BERT-base是3w x 768. ALBERT通過矩陣分解的思想,將嵌入向量維度設定為較小值(如128)再通過矩陣變換到原維度H=768(通過全連線層實現)。引數量級變化:\(O(V\times H) \rightarrow O(V \times E + E \times H)\)。量級變化顯著,指標也會有一定的損失。
(2)多層引數共用:對每個encoder block(多頭注意力和 FFN)共用引數,注意力層的引數對效果的減弱影響小一點。如BERT-base 12層,通過多層引數共用降低為1層的的引數量,降為原來的1/12,但不改變計算量.
其它提分點
- 預訓練用長句:BERT 在預訓練的時候,為了加速,前 90% 的 steps 用長度為 128 的句子,而後 10% 的 steps 用長度為 512 的句子,來訓練位置編碼。ALBERT 則是反過來,90%-512,10%-128。
- MLM 任務改進-遮擋連續詞:借鑑 SpanBERT 中的方法,對 MLM 任務,每次不隨機遮一個詞,而是隨機遮連續的多個詞(n-gram 片段,n最大取3),包含更完整的語意資訊。隨機選用 1-gram 、2-gram、3-gram 的概率分別為 6/11,3/11,2/11。越長概率越小:\(p(n)=\frac{1 / n}{\sum_{k=1}^{N} 1 / k}\)。
- 增加預訓練資料:像XLNet 和 RoBERTa 那樣使用額外的預訓練資料集。
- 去掉 Dropout 層:因為共用引數降低了引數量,再使用Dropout會正則化過度。論文提到在訓練到一定步數時仍未收斂,停掉了dropout。也許一開始就可以不使用?
- 段落連續性任務修改:用 Sentence-Order prediction (SOP) 任務替代NSP任務。正例和原BERT一致,使用從一個檔案中連續的兩個文欄位落;負例,使用從一個檔案中連續的兩個文欄位落,但調換位置(self-supervised loss)。NSP任務的負例則是隨機選的不同的檔案中的段落(肯定能保證是不連續的),但是這會導致這個任務隱含」topic prediction」,任務變得簡單,不利用預訓練的效果。ALBERT 提出的 SOP 則是單純地學習文字的連貫性,相比NSP在實現上也更加簡單。在百度 ERNIE 2.0 裡提出了更強的 Sentence Reordering Task (SRT) ,預測更多種句子片段順序排列(相應地程式碼實現變複雜)。
- 採用LAMB優化器以適應特別大的batch size,加快訓練速度。
ALBERT-large相比原始BERT-large縮減了 18倍的引數量,提高1.7倍的訓練速度, 取得接近的指標表現。整體來看ALBERT 只減引數(視訊記憶體)不減計算量。
參考:
brightmart/albert_zh: 中文預訓練ALBERT模型
ELECTRA 2020
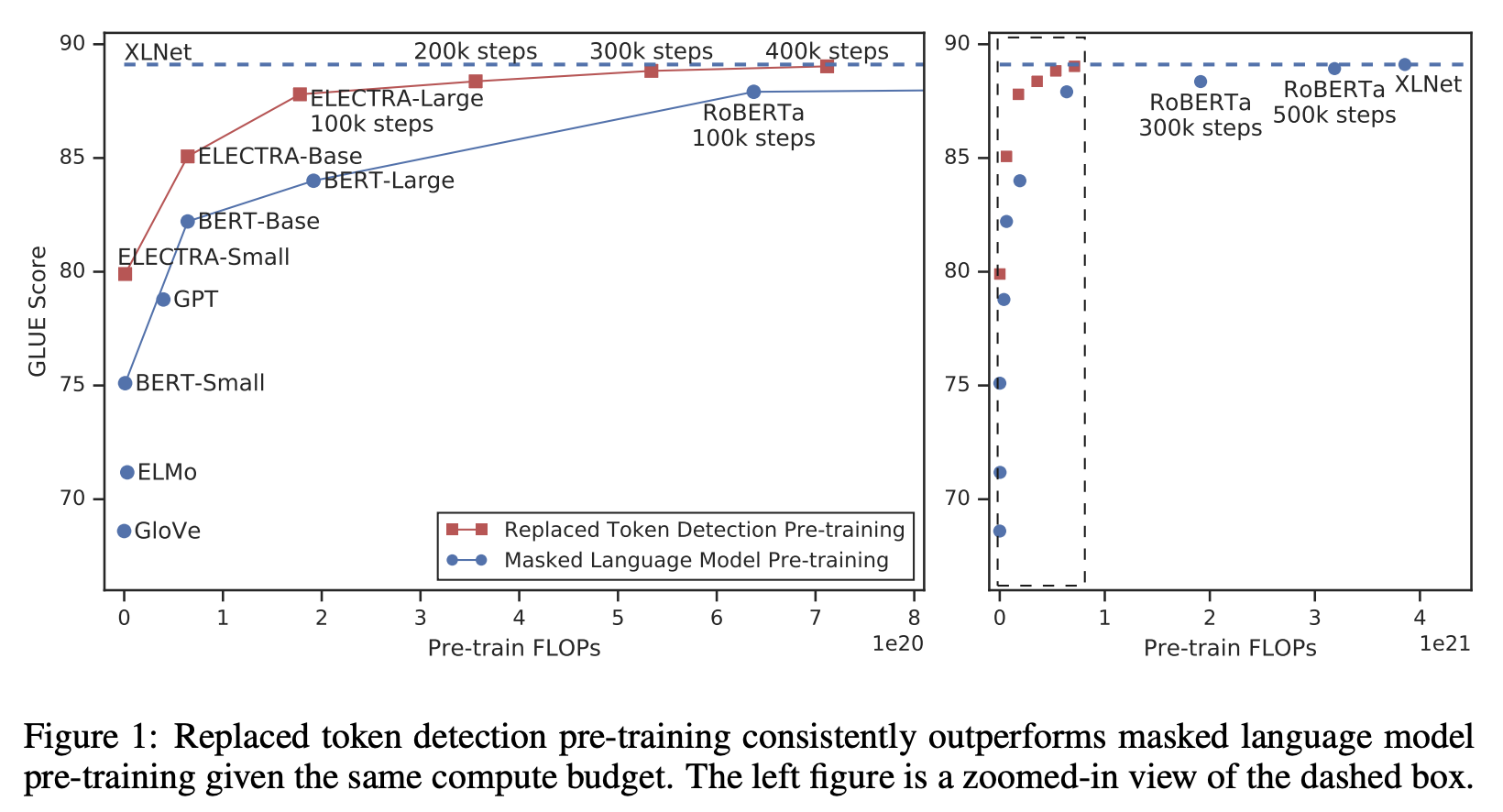
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators(ICLR 2020,Stanford University & Google Brain,2019年最佳NLP預訓練模型)
ELECTRA 是 Efficiently Learning an Encoder that Classifies Token Replacements Accurately 的縮寫,論文題目和這個縮寫的句子點明瞭論文的核心思想:MLM模型需要大量的樣本取樣進行訓練,效率並不高(每步僅將一小部分token作為預測目標,如15%),ELECTRA提出了一種效率更高地取樣方法,稱為Replaced token detection(RTD)。其借鑑了GAN的思想,將本來需mask的token替換為由一個較小的生成式語言模型生成的token,然後將預訓練模型當做判別模型去預測每一個token是原始值還是被替換的值(序列標註,二分類)。
相比於MLM僅預測掩碼token,ELECTRA預測全部token,學習效率更高,同時也避免了下游任務與MLM訓練資料格式不一致的問題(下游任務不用Mask)。MLM模型是用其它位置的文字資訊預測當前位置的文字,而ELECTRA可認為是第一個有效學到用當前位置提取的資訊預測當前位置的輸出的模型(在BERT中被mask的token中設定了10%並不真正替換為[M],用來緩解與下游任務的不一致問題,然而會導致資訊洩露)。此外,相比於MLM和GPT的AR任務這種生成式,ELECTRA預訓練模型屬於判別式。
模型結構
直接採用隨機替換的方式讓判別模型去判別會比較簡單,效果不佳。可以用一個小型的MLM(如BERT-small)來對mask位置生成token,生成模型與判別模型做聯合訓練,通過這種方式將生成對抗網路的部分思想應用到了BERT之中,然而不是真正的對抗模型(ELECTRA≠BERT+GAN),因為對於文字這種離散型資料,不能通過輕微擾動來改變生成器,即判別器的梯度無法回傳到生成模型(應用GAN到文字上比較難,參考Language GANs falling short. arXiv:1811.02549, 2018. 快速理解可參考為什麼GANs不適合做NLP?)。生成器的損失函數繼續用極大似然估計,而不是GAN的迭代對抗訓練。這種預訓練方式和CV中的Faster R-CNN目標檢測網路非常像,都是two-stage,第二個stage利用到第一個stage的結果,並且交替訓練兩個子網路(而Faster R-CNN存在兩種訓練方式,一種是交替式,一種是同時聯合訓練。我理解的在權重共用比較少的情況下用交替式更合適)。在預訓練完成之後僅用判別器做下游任務的finetune。
示意圖如下:
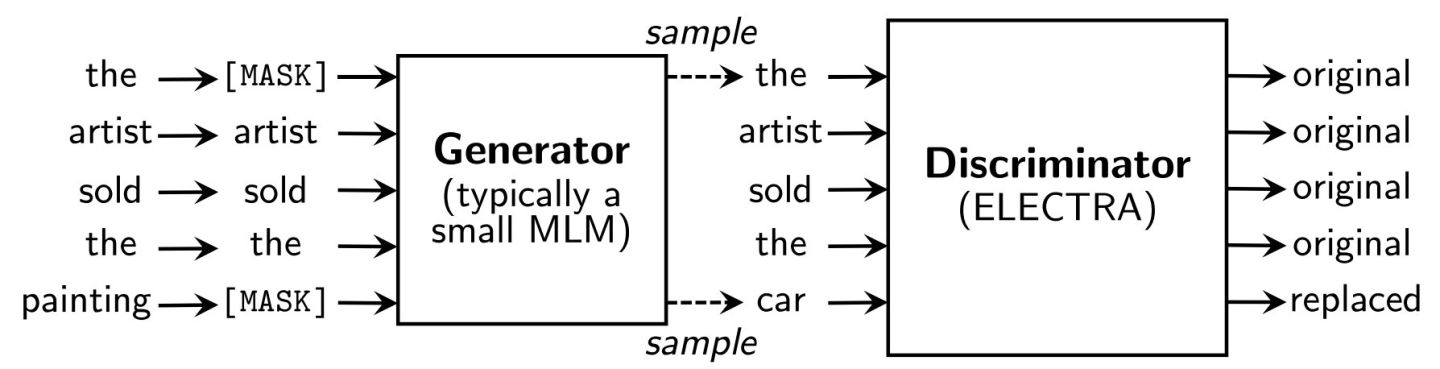
損失函數為兩部分的組合,其中判別器相對較易學習,增加其權重:
除了梯度的反向傳播,還有以下幾點和GAN的區別:
| 對比 | ELECTRA | GAN |
|---|---|---|
| 輸入資料 | 真實文字 | 隨機噪聲 |
| 訓練目標 | 生成器學習語言模型, 判別器學習區分真假文字 |
生成器學習欺騙判別器, 判別器學習區分真假資料(影象) |
| 反向傳播 | 梯度無法從判別器傳到生成器 | 梯度可以從判別器傳到生成器 |
| 特殊情況 | 生成器生成真實文字時標記為判別器的正例 | 生成器的結果全部作為負例 |
接下來看下生成器怎樣設計,如何訓練。容易想到兩種方式:
-
單獨接一個額外的MLM到判別器之前(引數不共用),這種方式比較靈活,可選擇任意大小、結構的BERT類模型。
-
共用同一個結構引數(引數共用),僅輸入和學習目標不同。
在方式1中還可利用常見的輸入embedding共用的方式,在BERT中指token embedding和位置編碼。作者通過實驗表明,共用輸入embedding能夠獲得較大的提升,因為MLM會通過softmax更新整個詞表,而判別器僅更新在輸入中見過的token。共用完整的結構引數相比只共用輸入embedding,提升不顯著。因此為了靈活性,選擇僅共用輸入embedding的額外的生成器。
作者實驗了最簡單的unigram LM作為生成器(根據預料中詞頻的統計進行生成,無須訓練),也能取得不算很差的結果。而更大型的生成器對效果反而並不好,因為當生成器預測準確的時候會作為判別器的正例,這樣生成器走向兩個極端,太弱或太強,都不利於判別器的訓練。當生成器Transformer的層數是判別器的1/4-1/2之間時效果最好。
實驗效果
能夠以原1/4的算力達到和 RoBERTa、XLNet 接近的效果,在訓練充分時效果更佳。效果對比:
DeBERTa 2020
DeBERTa: Decoding-enhanced BERT with Disentangled Attention(ICLR 2021,MSRA 2020.6,與UniLM有相同的作者團隊)
DeBERTa 是使用了「解綁注意力」的「解碼增強」的BERT。
核心點:注意力解耦(disentangled attention) 、 enhanced mask decoder
一、Disentangled attention
作者認為兩個token之間的依賴關係程度不僅與字面含義有關,還與表達形式有關,表現為相對位置、順序。如deep learning兩個單詞相鄰與不相鄰的含義可能大不相同。
在Self-Attention with Relative Position Representations中提出的相對位置編碼只包含content-to-content, content-to-position兩部分,作者認為引入position-to-content self-attention可使得相對位置的建模更完整。
用 Qc、Kc、Vc 表示內容向量,Qp、Kp、Vp 表示絕對位置編碼,Qr、Kr、Vr 表示相對位置編碼。
在原始BERT中採用(token 內容embedding+絕對位置編碼)送入self-attention網路。那麼attention矩陣就是通過 (Qc + Qp) x (Kc + Kp) 參與計算得到,可分離成四部分:content-to-content, content-to-position, position-to-content, position-to-position,完整包含了對稱的content-to-position、position-to-content。而position-to-position由於不包含額外的內容資訊,作者認為不應被使用(在T5中恰恰相反,丟掉了c2p,p2c,僅用c2c+p2p)。
延續這種思路,用相對位置編碼替換絕對位置編碼,但並不真正像BERT那樣直接耦合相加,而是解耦成用一個單獨的向量表示相對位置資訊 \(P\in R^{2k\times d}\),並採用不同的投射矩陣\(W_{q,r}\)(而BERT中內容和位置共用了投射矩陣),參與和content之間的attention計算,並在所有的Transformer attention層中共用。將attention計算分離成三項,公式如下:
DeBERTa 將相對位置偏移編碼 \(\delta\) 定義為:
最大相對距離設定k=512。
二、Enhanced mask decoder
用增強的 mask decoder替換原始輸出的 softmax層,以預測模型預訓練時候被 mask 掉的token。以此解決BERT的預訓練和微調階段的不一致問題。其包括兩點改動:
- 在softmax層之前用絕對位置資訊替代那些本該被mask但實際未mask的tokens,因為那些token以本身為條件進行預測導致資訊洩露,而絕對位置資訊對於區分單詞、理解句子的重點有幫助。例如「a new [store] opened beside the new [mall]」,其中store和mall被mask用於預測,主題是store,顯然只用上下文內容和相對位置編碼是難以區分store和mall的,需要將絕對位置編碼作為補充。作者實驗對比了BERT式的早期新增絕對編碼的方式和末期新增絕對位置編碼的方式,發現後者更好一些。(關於絕對位置編碼的新增位置這一塊的理論分析和實驗可能不太充分)
- 增加decoder的層數。可以將BERT最後一層Transformer block+softmax看作decoder,前邊層看作encoder。DeBERTa增加了decoder的層數,並類似ALBERT進行引數共用。DeBERTa-base相對於BERT-base而言,前11層看作encoder,對最後一層複製一層作為decoder,引數量保持一致,計算量增加一層。在對DeBERTa模型進行預訓練後,對11層encoder和1層decoder進行疊加,以恢復出標準的BERT-base結構進行微調。
我理解第二點改動是為了配合第一點改動,第一點可看作是將絕對位置編碼插入到了最後倒數n層中,為了提升效果繼續增加decoder的層數,但又需要跟其他論文同等引數量的模型做對比,採用了ALBERT引數共用的方式保持引數量不變。
Enhanced mask decoder結構示意圖如下圖(b)所示,將decoder中每一層的Q替換為絕對位置編碼。
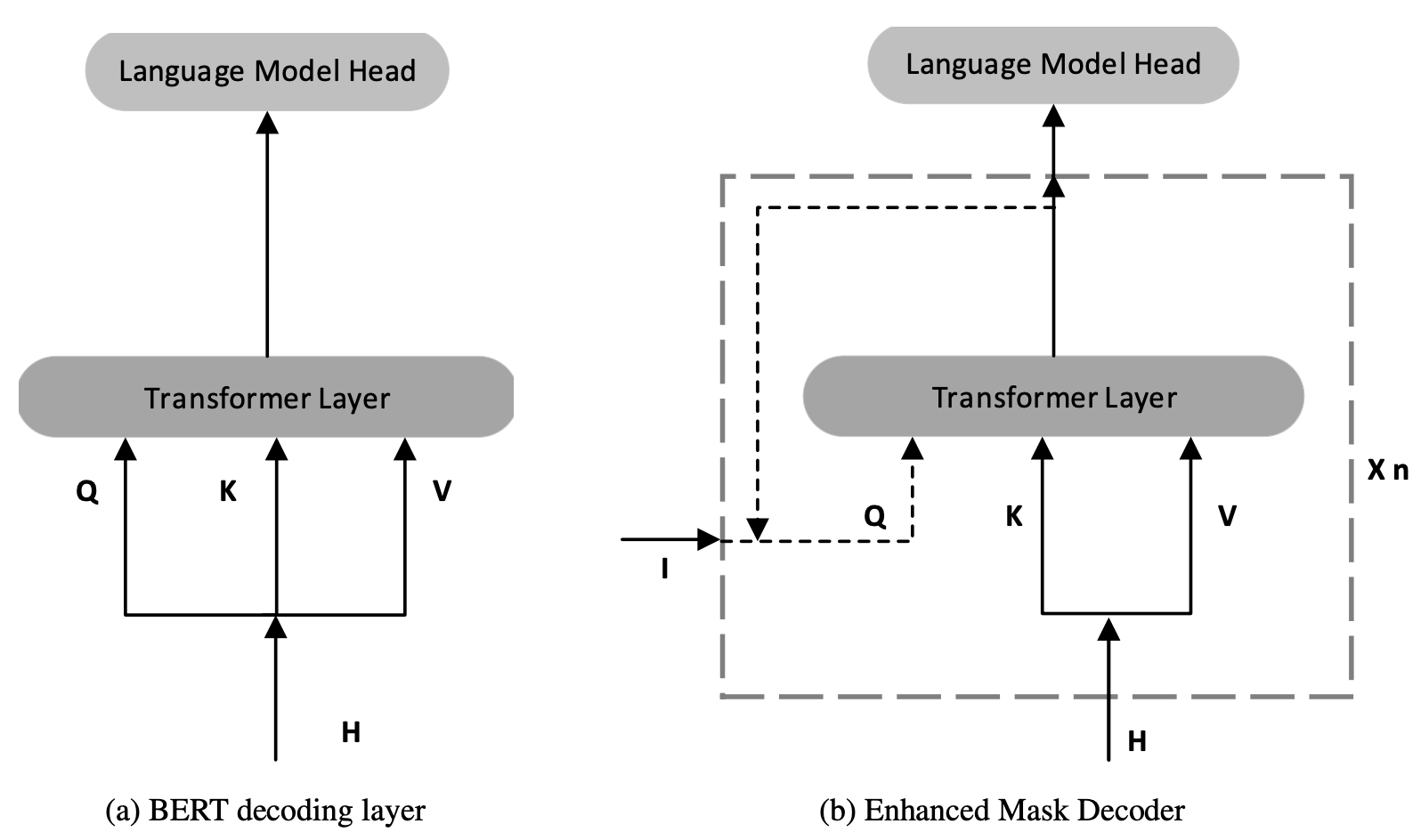
當I=H,而且n=1時,Enhanced mask decoder就和bert decoder layer完全一樣了。但I還可以是H與絕對位置編碼的組合,這使得模型結構更靈活。
三、Scale-invariant fine-tuning 虛擬對抗學習
論文還提出了一個虛擬對抗學習的方法,用於微調下游任務。借鑑了CV中對抗樣本學習的思想,對輸入新增輕微的噪聲擾動。相當於新增正則項(regularization),能夠提高模型的泛化能力。
對於影象,新增隨機的畫素點即可。對於文字,由於是離散型資料,不便於直接擾動,但可以轉而在word embedding空間中新增噪聲。
然而不同word和模型的embedding向量的方差差異較大,並且模型越大方差也越大,需要新增的噪聲的方差也需要加大,這導致對抗學習不穩定。容易想到的解決思路是對方差標準化(normalization),對 word embedding 進行LayerNorm使其Scale-invariant,然後再新增噪聲,會穩定一些。
巧的是,這個方法的縮寫SiFT恰好與CV中的SIFT(Scale-invariant feature transform)特徵重名了。
在論文中SiFT僅被用在1.5B大模型上面,用於測試SuperGLUE任務,並且取得顯著的提升,在未來會被繼續研究。
效果
相比於RoBERTa,Disentangled attention增加了引數量(及計算量),Enhanced mask decoder增加了計算量,但DeBERTa 收斂速度更快,僅用一半預訓練資料即可在眾多NLP任務中超越RoBERTa-Large。通過48層1.5B引數量的模型,在SuperGLUE榜單上更是超越人類基準(89.9 vs. 89.8),2021年初取得榜首地位。
DeBERTa-Large的引數量是390M,其他的BERT、RoBERTa、XLNet模型Large版在335~355M左右。
強強聯合 DeBERTa