如何用WebGPU流暢渲染千萬級2D物體:基於光追管線
大家好~我們已經實現了百萬級2D物體的流暢渲染,不過是基於計算管線實現的。本文在它的基礎上,改為基於光追管線實現,主要進行了CPU和GPU端記憶體的優化,成功地將渲染的2D物體數量由4百萬提高到了2千萬
相關文章如下:
如何用WebGPU流暢渲染百萬級2D物體?
本文不需要實現構建和遍歷BVH,而是直接使用光追管線提供的加速結構
本文的重點工作在於對CPU記憶體和GPU記憶體的優化,突破記憶體限制(如突破加速結構最大大小限制),使其支援千萬級物體的資料
本文使用WebGPU Node專案,作者的介紹在這裡。它在底層封裝了Vulkan SDK,在上層提供了WebGPU API,實現了在Nodejs環境中使用WebGPU API和光追管線來實現硬體加速的光線追蹤(需要使用nvdia的RTX顯示卡)!
我在2020年就已經基於該專案實現了3D場景渲染,相關介紹如下:
WebGPU+光線追蹤Ray Tracing 開發三個月總結
需求
跟百萬級的Demo的需求是一樣的,除了提高渲染的2D物體數量到千萬級,目的是為了探索基於硬體的光追管線的實現能帶來的優化極限
成果
我們最終能夠流暢渲染2千萬個圓環
效能指標:
- 跟百萬級的Demo的FPS一樣,為45左右,也就是每幀花費21毫秒
硬體:
- Win10作業系統
- Nodejs環境+Vulkan驅動
- RTX2060s顯示卡
跟百萬級Demo的效能比較
提高的地方:
- 渲染的物體數量多了4倍
降低的地方:
- 構造加速結構的時間多了1.5倍
不過相信隨著RTX顯示卡的升級,會越來越快
下面讓我們從0開始,介紹實現和優化的步驟:
1、選擇渲染的演演算法
跟百萬級的Demo一樣,選擇光線追蹤演演算法
不過這裡需要傳送Primary Ray去計算射線與物體的相交,這樣才能觸發光追管線中關於相交的著色器
2、實現記憶體需求
跟百萬級的Demo一樣,場景依然使用ECS架構
3、渲染1個圓環
光追管線支援兩種geometry的型別:
三角形和AABB包圍盒
因為圓環是引數化的(引數化為圓點座標、半徑、圓環寬度),所以geometry型別使用AABB包圍盒
這種型別geometry被稱為「Procedural Geometry」
光追管線的加速結構跟百萬級Demo的TopLevel、BottomLevel類似,分為TLAS(top level acceleration structure)和BLAS(bottom level acceleration structure),如下圖所示:
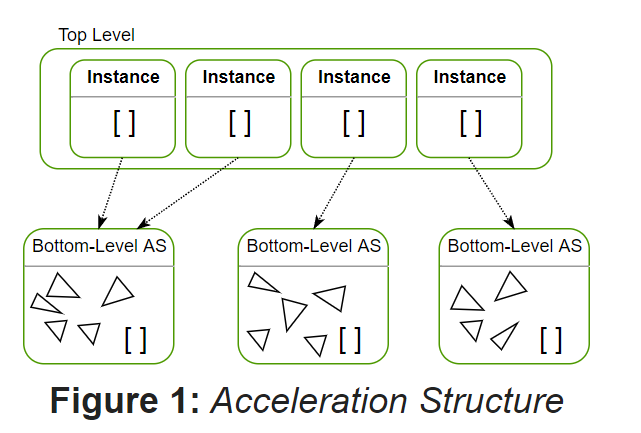
因為場景只有1個Geometry和1個Instance,所以在BLAS中加入1個aabb(根據Geometry的引數計算aabb,其中aabb的min.z和max.z設為0),在TLAS中加入1個Instance的資料(主要包括該圓環的transform matrix、instanceId)
現在介紹下光追管線通常包含哪些著色器:
- .rgen
每個畫素會執行一次著色器,分別產生一條Primary Ray - .rint
該著色器用於AABB包圍盒的geometry型別,當Primary Ray與AABB相交時被觸發 - .rchit
該著色器用來處理Primary Ray與第一個圓環相交的情況 - .rmiss
該著色器用來處理Primary Ray與所有圓環都沒有相交的情況 - rahit
Primary Ray與第一個圓環相交後繼續傳播,當與第二個及以後的圓環相交時觸發該著色器(本Demo沒用到該著色器)
渲染的步驟為:
1、在.rgen著色器中逐個畫素產生Primary Ray
2、如果Primary Ray與AABB相交,則執行.rint著色器;否則執行.rmiss著色器,將畫素設定為黑色
在執行.rint著色器時:
- 根據gl_LaunchIDEXT、gl_LaunchSizeEXT得到畫素座標,即為Primary Ray與AABB的相交點
- 如果該畫素座標在圓環內,則通過reportIntersectionEXT來觸發.rchit著色器
在執行.rchit著色器時:
- 根據material設定畫素顏色(為紅色)
關於Procedural Geometry渲染的參考資料如下:
Vulkan->Intersection Shader - Tutorial
D3D12 Raytracing Procedural Geometry sample
4、渲染10個圓環
場景中建立10個圓環,它們的ECS資料為:
10個gameObject
10個transform
1個geometry
1個material
geometry仍然只有1個,但instance變為10個,所以在TLAS中改為加入10個Instance的資料,BLAS不變
渲染結果如下圖所示:

5、顯示FPS
我們使用「平均取樣法」來計算FPS。這個方法跟我之前實現的深度學習->優化演演算法->動量法->指數加權移動平均類似,並且那裡還做了數學證明。
這個方法的基本思想就是計算多個相鄰幀的平均值,但又不需要額外的空間來儲存多幀
參考資料如下:
影格率(FPS)計算的六種方法總結
6、實現剔除
實現思路如下:
將TLAS中每個instance的層設為transform matrix中的position.z;
將Primary Ray的flag設為gl_RayFlagsOpaqueEXT,這樣的話Primary Ray與最大層的圓環相交時會觸發.rchit著色器,然後就停止傳播,從而實現只渲染最大層的圓環
注:這裡的層不再是從1開始的正整數,而是為0.00001, 0.00002這樣的小數。這是因為為了效能考慮,將Primary Ray的最大距離設為一個很小的值(如1.0),所以層的值不能超過1.0
7、測試渲染極限
當嘗試跟百萬級Demo一樣渲染4百萬個圓環時,報了下面的錯誤:
Error: Out of memory Error: vkAllocateMemory failed with VK_ERROR_OUT_OF_DEVICE_MEMORY
這是因為WebGPU Node專案底層使用Vulkan來渲染,它申請的單個TLAS的記憶體容納不了4百萬個instance資料
所以我們減少圓環數量,發現當其為3百50萬個時,能夠成功渲染。其中構造加速結構的時間為25秒,FPS為1000(因為這裡使用setInterval而不是requestAnimationFrame啟動主迴圈,所以FPS可以大於60)
8、拆分加速結構
如果要渲染4百萬個甚至更多的圓環,就需要將1個TLAS拆成多個TLAS(BLAS還是不變,只有一個)
這樣的話,如果每個TLAS都有3百50萬個Instance資料,那麼3個TLAS就可以有超過1千萬個Instance資料了
如何拆分TLAS呢?
首先,我們可以根據Instance的層,按照下面的方法將所有Instance分為3組:
- 每組有最小層和最大層這兩個資料,將層在其中的Instance放在該組中
- 每組按照層的大小從大到小排列,使得下一組的最大層小於等於上一組的最小層
然後,將每組的Instance資料分別傳入1個TLAS中;
然後,建立3個bindGroup,每個bindGroup分別使用1個TLAS;
最後,在begin ray tracing pass時,繫結對應的bindGroup,traceRays3次,程式碼如下:
...
let commandEncoder = device.createCommandEncoder({});
let passEncoder = commandEncoder.beginRayTracingPass({});
passEncoder.setPipeline(pipeline);
bindGroups.forEach(bindGroup => {
passEncoder.setBindGroup(0, bindGroup);
passEncoder.traceRays(
0, // sbt ray-generation offset
1, // sbt ray-hit offset
2, // sbt ray-miss offset
window.width, // query width dimension
window.height, // query height dimension
1 // query depth dimension
);
})
passEncoder.endPass();
queue.submit([commandEncoder.finish()]);
這裡我們先對層最大的一組Instance做遍歷,然後再對層小一點的一組Instance做遍歷,然後再對層更小一點的一組Instance做遍歷。。。。。。
這是一個優化的方法,因為每個畫素只渲染最大層的圓環的顏色,所以如果在遍歷1個TLAS時Primary Ray與圓環相交而得到了畫素的顏色,那麼就不再對後面的TLAS進行遍歷了!
9、拆分Instance Buffer
Instance Buffer儲存了所有Instance的元件資料,是一個storage buffer。當Instance的數量大於1千萬後,它的大小會超過buffer的最大大小:128MB,會報錯
所以,跟拆分加速結構TLAS一樣,我們把Instance Buffer也對應拆分,使得3個bindGroup分別使用1個TLAS和1個Instance Buffer
10、優化CPU端的記憶體佔用
之前是在優化GPU端的記憶體佔用,現在要優化CPU端的記憶體佔用
當Instance數量超過1千6百萬時,在CPU端設定TLAS的instances資料時會超出記憶體大小,報下面的錯誤:
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory
現在的實現思路為:
我們有5組Instance,對應5個TLAS,每個TLAS最多有3百50萬個Instance
首先現在建立了5個陣列,每個陣列最多儲存3百50萬個Instance資料;
然後將對應的陣列設定為對應的TLAS的instances資料
因為這5個陣列共包含了1千6百萬個Instance資料,超出了CPU端v8的記憶體限制,所以會報錯
可以做下面兩個優化來解決問題:
- 因為每個陣列的最大容量都是一樣的(3百50萬),所以只建立1個容量為3百50萬的陣列,通過"arr[index]=instance資料"來儲存一個組的Instance資料,然後將其設定給對應的TLAS;然後重複使用該陣列,儲存下一組的Instance資料,將其設定給對應的TLAS,依次類推。。。。。。
經過這樣的優化, CPU端就只需要分配3百50萬個Instance資料的記憶體了,大大減少了記憶體佔用 - 使用ArrayBuffer而不是陣列來儲存每組的Instance資料,這樣可以提高速度並且減少記憶體佔用
11、測試渲染極限
現在我們來渲染2千萬個圓環,測試下FPS
渲染結果如下圖所示:

效能指標如下:
- FPS為1000以上
- 構造加速結構的時間為150秒
為什麼FPS跟渲染3百50萬個圓環時一樣?
因為第一個TLAS包含的3百50萬個圓環為最高層,它們已經填滿了螢幕,所以遍歷第一個TLAS後就停止遍歷了!
我們希望測試下最壞的情況,所以強制遍歷所有的TLAS,此時FPS為45左右
當我們嘗試渲染大於2千萬個圓環時,報了下面的錯誤:
Error: Out of memory Error: vkAllocateMemory failed with VK_ERROR_OUT_OF_DEVICE_MEMORY
這說明雖然每個TLAS沒有超過最大限制(3百50萬個Instance資料),但是應該是超過了總的大小限制,也就是所有TLAS包含的總的Instance資料(大於2千萬個)超過了限制!
除非能夠修改WebGPU Node專案中的Vulkan關於TLAS記憶體分配的程式碼,否則我們通過WebGPU API無法修改該限制(因為WebGPU Node沒有提供相關的WebGPU API)
12、嘗試優化構造加速結構
在建立BLAS和TLAS時,可以指定為下面幾個flag:
NONE
ALLOW_UPDATE
PREFER_FAST_TRACE
PREFER_FAST_BUILD
LOW_MEMORY
當修改為PREFER_FAST_BUILD而不是PREFER_FAST_TRACE,並沒有效果!不知道是因為WebGPU Node在Vulkan這層沒有處理這個flag還是顯示卡RTX2060s不支援這個flag?
其它的優化思路包括:
- 不需要一次性構造所有TLAS,而是按需構造對應的TLAS
- 在worker中構造TLAS和BLAS,使其不阻塞主執行緒
目前雖然構造加速結構比較慢,但隨著RTX顯示卡的升級,相信會有改善!畢竟這個是由顯示卡完成的,我們這邊能優化的餘地較小
更多分析
我們來分析下面幾個情況:
為什麼「增大圓環geometry的半徑,FPS會明顯下降」?
這是因為:
這會增大圓環的AABB->增加重疊的AABB數量->增大遍歷的開銷->最終降低FPS
如果BLAS加入兩個圓環的AABB,是否就能渲染4千萬個圓環了?
這樣是可以的。之前實現的渲染是渲染2千萬個Instance,而每個Instance對應的BLAS只有一個圓環,所以就只渲染了2千萬個圓環。
實際上可以像這樣增加渲染的圓環數量,但是因為總的AABB的數量增加了一倍,導致遍歷開銷增大一倍,所以FPS也會下降一倍
能不能在相鄰的兩幀分別繪製不同的2千萬個Instance,這樣就可以渲染4千萬個Instance了?
這樣子的話不僅FPS會下降一倍,而且也是不可行的,因為不管分成幾次draw call,都需要把所有Instance資料載入到TLAS中(因為所有的Instance資料只建立一次,除非每幀都建立對應的Instance資料並且把之前的Instance資料銷燬!但這樣的話CG開銷應該會比較大),這樣所有的TLAS包含的Instance資料大小一樣不能超過2千萬個
可以在相鄰的兩幀分別繪製不同的1千萬個Instance,但這樣還不如在一幀中繪製2千萬個Instance省事
總結
感謝大家的支援和學習~
本文主要使用光追管線,優化了記憶體佔用,將2D物體數量提升到了千萬級
使用光追管線相比使用計算管線的優點是:
- 不需要實現BVH,實現和維護更加簡單
- 因為是硬體加速射線相交計算,遍歷的效能更好
缺點是:
- 相容性更差
需要Nodejs環境和RTX顯示卡 - 不能使用最新的WebGPU標準
WebGPU Node專案使用的是2020年版本的WebGPU標準,不是最新的標準
所以,我們可以考慮在Web版產品中使用瀏覽器的WebGPU標準(基於計算管線)來實現,而在桌面版產品中基於光追管線來實現
後續的改進方向
目前已達到加速結構的記憶體限制(2千萬個Instance),不容易繼續增加Instance數量
後面可以考慮優化基於計算管線的Demo,從百萬級提升到千萬級;
另外可以考慮GPU LOD,在計算著色器中替換geometry,從而減少BLAS的佔用
參考資料
如何用WebGPU流暢渲染百萬級2D物體?
WebGPU+光線追蹤Ray Tracing 開發三個月總結
Vulkan->Intersection Shader - Tutorial
影格率(FPS)計算的六種方法總結
WebGPU Ray-Tracing Spec
GLSL_NV_ray_tracing
Node.js heap out of memory
Node.js Default Memory Settings
歡迎瀏覽上一篇博文:如何用WebGPU流暢渲染百萬級2D物體?
歡迎來到Wonder~
掃碼加入我的QQ群:

掃碼加入免費知識星球-YYC的Web3D旅程:

掃碼關注微信公眾號:
