HDFS基礎入門
HDFS簡介
HDFS(全稱:Hadoop Distribute File System)分散式檔案系統,是Hadoop核心組成。
HDFS中的重要概念
分塊儲存
HDFS中的檔案在物理上是分塊儲存的,塊的大小可以通過設定引數來規定;Hadoop2.x版本預設的block大小是128M
名稱空間
HDFS支援傳統的層次性檔案組織結構。使用者或者應用程式可以建立目錄,然後將檔案儲存在這些目錄裡。檔案系統名稱空間的層次結構和大多數現有的檔案系統類似:使用者可以建立、刪除、移動或重新命名這些檔案。
NameNode負責維護檔案系統的名稱空間,任何對檔案系統名稱空間或屬性的修改都被NameNode記錄下來。
NameNode後設資料
我們把目錄結構及檔案分塊位置資訊叫做後設資料。NameNode的後設資料記錄每一個檔案對應的block資訊。
DataNode資料儲存
檔案的各個block的具體儲存管理由DataNode負責。一個block會有多個DataNode來儲存,DataNode會定時向NameNode來彙報自己持有的block資訊。
副本機制
為了容錯,檔案的所有block都會有副本。每隔檔案的block大小和副本數都是可設定的。副本數預設是3個。
一次寫入,多次讀出
HDFS是設計成適應一次寫入,多次讀出的場景,且不支援檔案的隨機修改。正因為如此,HDFS適合用來做巨量資料分析的底層儲存服務,而不適合做網路硬碟等應用。(修改不方便,延遲大)
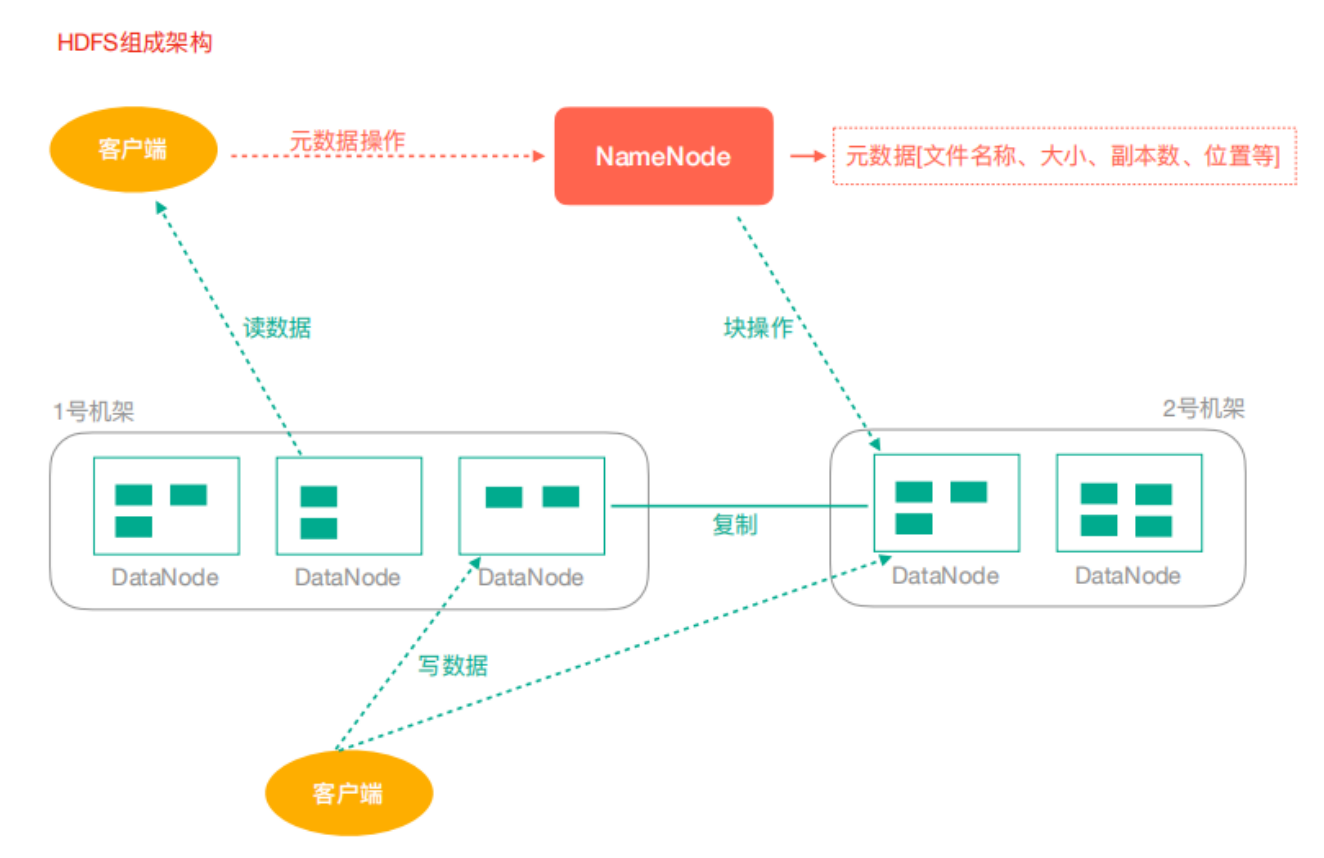
HDFS架構
-
NameNode:Hdfs叢集的管理者
- 維護管理Hdfs的名稱空間
- 維護副本策略
- 記錄檔案塊的對映關係
- 負責處理使用者端讀寫請求
-
DataNode:NameNode下達命令,DataNode執行實際操作
- 儲存實際的資料塊
- 負責資料塊的讀寫
-
Client:使用者端
- 上傳檔案到HDFS的時候,Client負責將檔案切分成Block,然後進行上傳
- 請求NameNode互動,獲取檔案的位置資訊
- 讀取或寫入檔案,與DataNode互動
- Client可以使用一些命令來管理HDFS或者存取HDFS
寫資料流程:
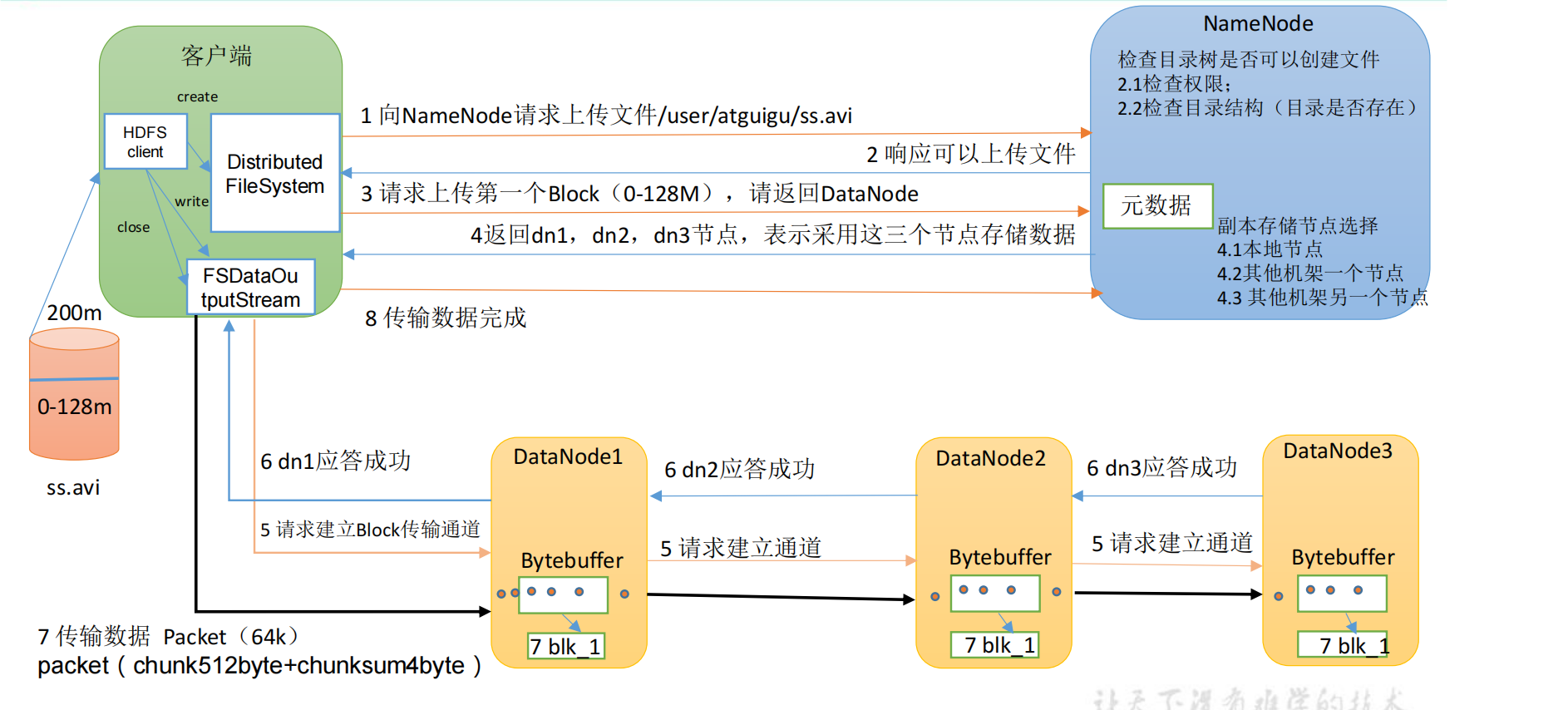
HDFS使用者端操作
Shell使用者端
- 檢視所有命令
hadoop fs
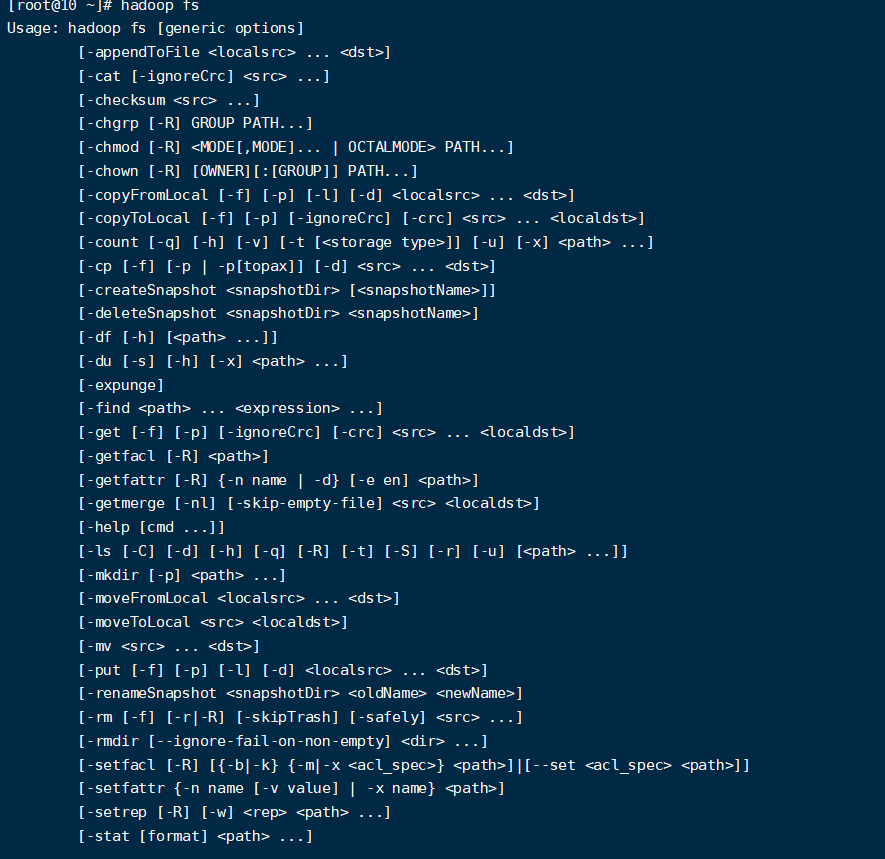
- 檢視命令幫助
#檢視rm的幫助資訊
hadoop fs -help rm
- 顯示目錄資訊
hadoop fs -ls /
- 建立目錄
hadoop fs -mkdir -p /test/data
- 從本地剪下到HDFS
hadoop fs -moveFromLocal ./word.txt /test/data
- 追加檔案內容到指定檔案
hadoop fs -appendToFile test.txt /test/data/word.txt
- 顯示檔案內容
hadoop fs -cat /test/data/word.txt
- 修改檔案所屬許可權
hadoop fs -chmod 666 /test/data/word.txt
hadoop fs -chown root:root /test/data/word.txt
- 從本地檔案系統拷貝檔案到HDFS路徑去
hadoop fs -copyFromLocal test.txt /test
- 從HDFS拷貝到本地
hadoop fs -copyToLocal /test/data/word.txt /opt
- 從HDFS的一個路徑拷貝到HDFS的另一個路徑
hadoop fs -cp /test/data/word.txt /test/input/t.txt
- 在HDFS目錄中移動檔案
hadoop fs -mv /test/input/t.txt /
- 從HDFS中下載檔案,等同於copyToLocal
hadoop fs -get /t.txt ./
- 從本地上傳檔案到HDFS,等同於copyFromLocal
hadoop fs -put ./yarn.txt /user/root/test/
- 顯示一個檔案的末尾
hadoop fs -tail /t.txt
- 刪除檔案或資料夾
hadoop fs -rm /t.txt
- 刪除空目錄
hadoop fs -rmdir /test
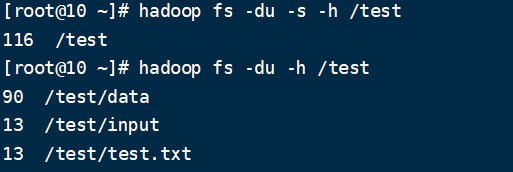
- 統計資料夾的大小資訊
hadoop fs -du -s -h /test
hadoop fs -du -h /test
- 設定HDFS的副本數量
hadoop fs -setrep 10 /lagou/bigdata/hadoop.txt
注意:這裡設定的副本數只是記錄在NameNode的後設資料中,是否真的會有這麼多副本,還得看DataNode的數量。因為目前只有3臺裝置,最多也就3個副本,只有節點數的增加到10臺時,副本數才能達到10.
Java使用者端
環境準備
- 將Hadoop安裝包解壓到非中文路徑
- 設定環境變數
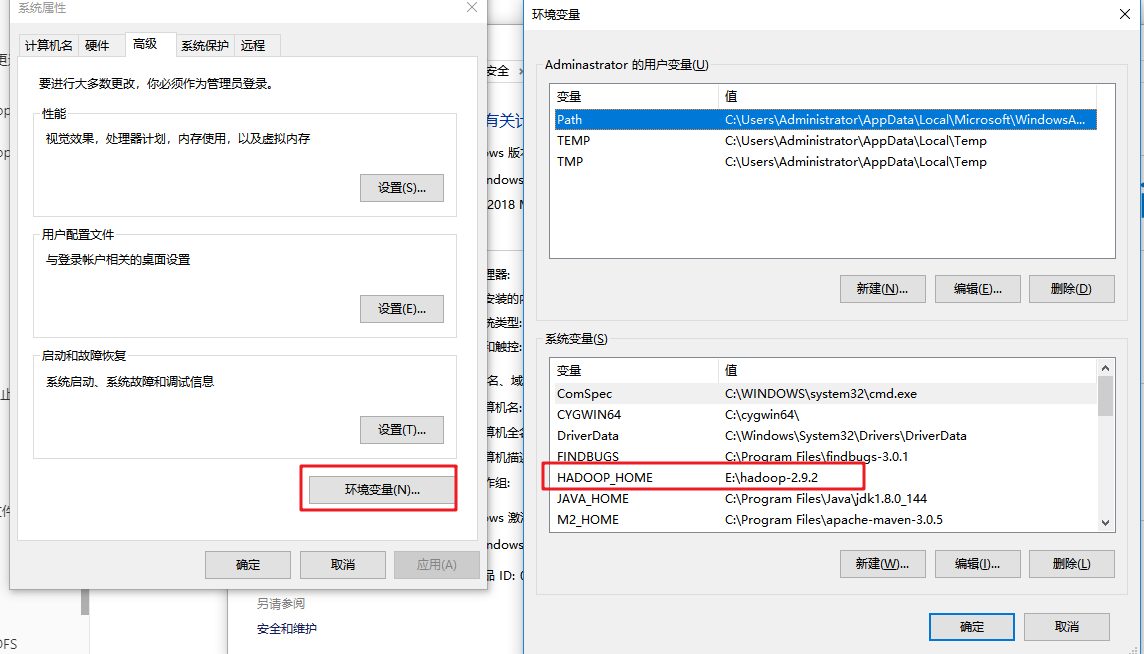
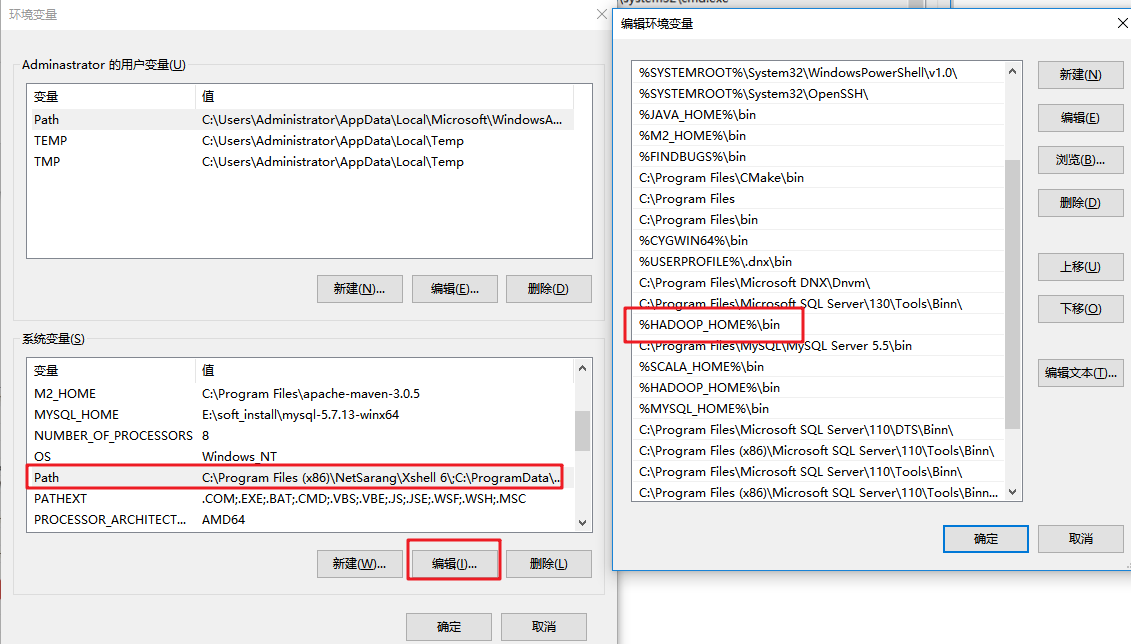
- 依賴匯入
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop-version}</version>
</dependency>
- 組態檔(可選步驟)
將hdfs-site.xml(內容如下)拷貝到專案的resources下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
引數優先順序排序:(1)程式碼中設定的值 >(2)使用者自定義組態檔 >(3)伺服器的預設設定
HDFS Java API
- 上傳檔案
@Test
public void testCopyFromLocalFile() throws Exception{
Configuration conf = new Configuration();
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.56.103:9000"),conf,"root");
fs.copyFromLocalFile(new Path("e://aa.txt"),new Path("/cc.txt"));
fs.close();
}
為了方便,下面的範例就隱藏構建FileSystem的過程
- 下載檔案
@Test
public void testCopyToLocalFile() throws Exception{
fs.copyToLocalFile(false,new Path("/aa.txt"),new Path("e://cd.txt"),true);
}
- 刪除檔案
@Test
public void testDelete() throws Exception{
fs.delete(new Path("/aa.txt"),true);
}
- 檢視檔名稱、許可權、長度、塊資訊等
public void testList() throws IOException {
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
//檔名稱
System.out.println(status.getPath().getName());
System.out.println(status.getLen());
System.out.println(status.getPermission());
System.out.println(status.getGroup());
BlockLocation[] blockLocations = status.getBlockLocations();
Stream.of(blockLocations).forEach(
block->{
String[] hosts = new String[0];
try {
hosts = block.getHosts();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(Arrays.asList(hosts));
}
);
System.out.println("-----------華麗的分割線----------");
}
}
- 資料夾判斷
@Test
public void testListStatus() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
Stream.of(fileStatuses).forEach(fileStatus -> {
String name = fileStatus.isFile() ? "檔案:" + fileStatus.getPath().getName() : "資料夾:"+fileStatus.getPath().getName();
System.out.println(name);
});
}
- 通過I/O流操作HDFS
- IO流上傳檔案
@Test
public void testIOUpload() throws IOException {
FileInputStream fis = new FileInputStream(new File("e://11.txt"));
FSDataOutputStream fos = fs.create(new Path("/io_upload.txt"));
IOUtils.copyBytes(fis,fos,new Configuration());
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
- IO流下載檔案
@Test
public void testDownload() throws IOException{
FSDataInputStream fis = fs.open(new Path("/io_upload.txt"));
FileOutputStream fos = new FileOutputStream(new File("e://11_copy.txt"));
IOUtils.copyBytes(fis,fos,new Configuration());
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
- seek定位讀取
@Test
public void readFileSeek() throws IOException{
FSDataInputStream fis = fs.open(new Path("/io_upload.txt"));
IOUtils.copyBytes(fis,System.out,1024,false);
//從頭再次讀取
fis.seek(0);
IOUtils.copyBytes(fis,System.out,1024,false);
IOUtils.closeStream(fis);
}
HDFS檔案許可權問題
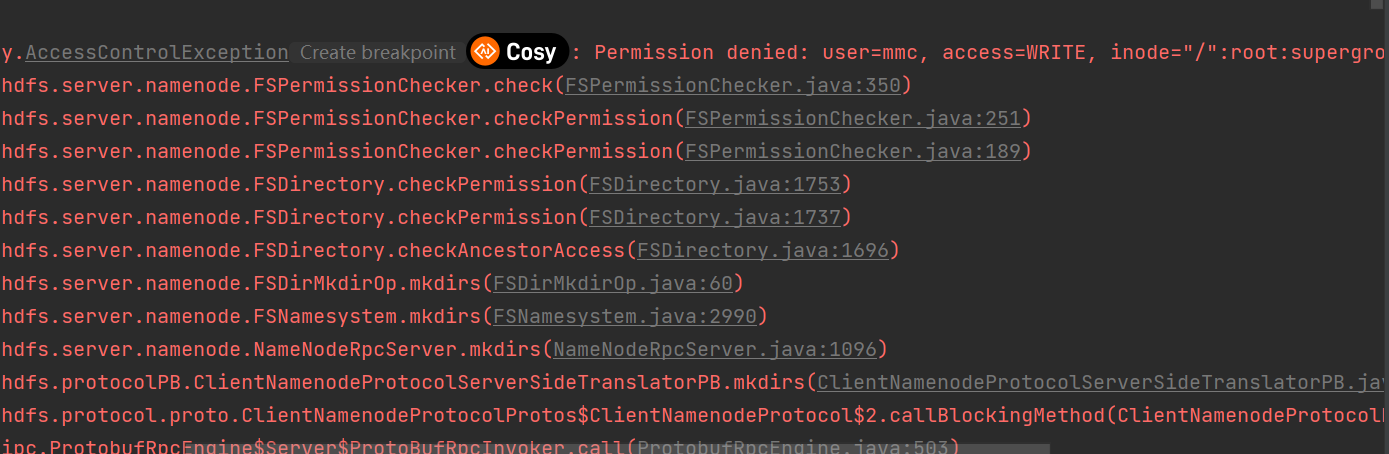
HDFS的檔案許可權和linux系統的檔案許可權機制類似。如果在linux系統中root使用者使用hadoop命令建立了一個檔案,那麼該檔案的owner就是root。
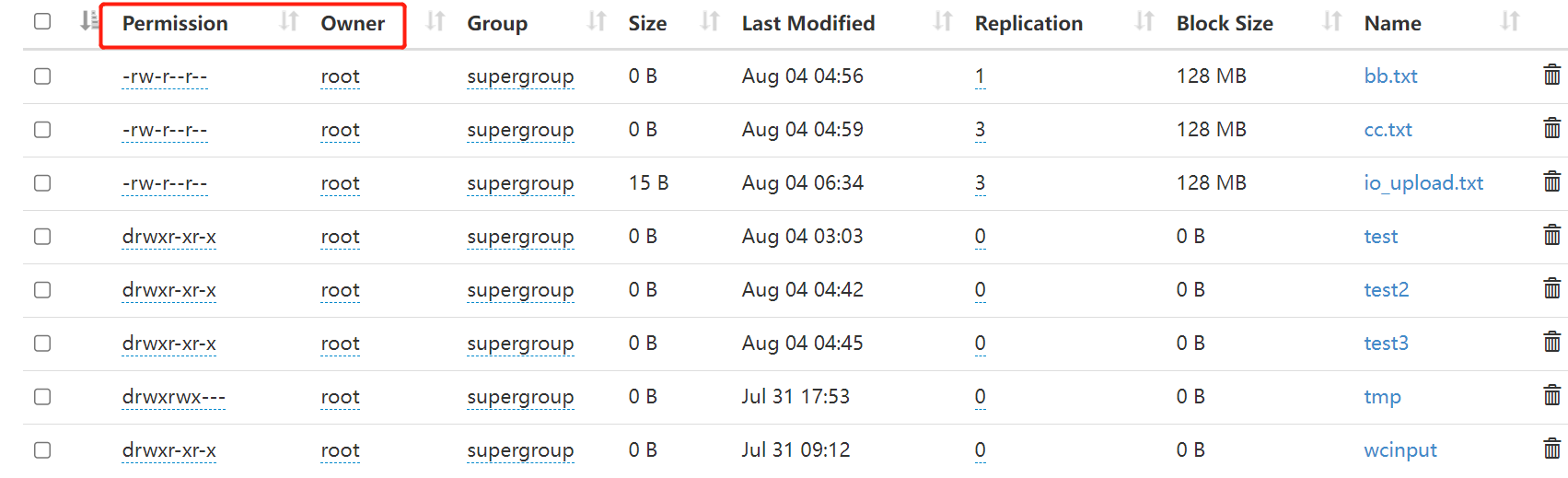
當出現許可權問題時,解決方法有如下幾種:
- 獲取FileSystem物件時指定有許可權的使用者
- 關閉HDFS許可權校驗,修改hdfs-site.xml
#新增如下屬性
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
- 直接修改HDFS的檔案或目錄許可權為777,允許所有使用者操作
hadoop fs -chmod -R 777 /