正規表示式完整入門教學,含線上練習
什麼是正規表示式?
正規表示式是一組由字母和符號組成的特殊文字,它可以用來從文字中找出滿足你想要的格式的句子。
一個正規表示式是一種從左到右匹配主體字串的模式。
「Regular expression」這個詞比較拗口,我們常使用縮寫的術語「regex」或「regexp」。
正規表示式可以從一個基礎字串中根據一定的匹配模式替換文字中的字串、驗證表單、提取字串等等。
想象你正在寫一個應用,然後你想設定一個使用者命名的規則,讓使用者名稱包含字元、數位、下劃線和連字元,以及限制字元的個數,好讓名字看起來沒那麼醜。
我們使用以下正規表示式來驗證一個使用者名稱:
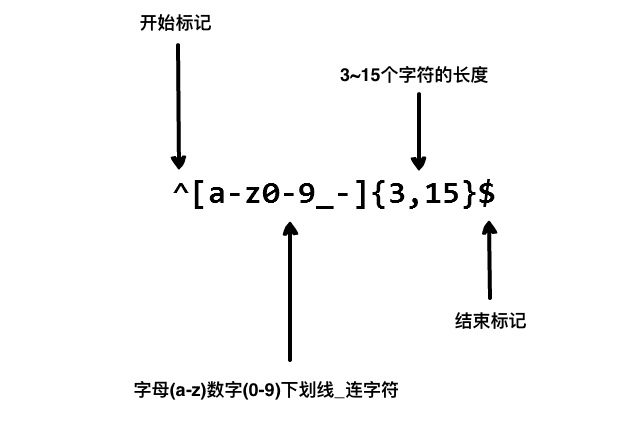
以上的正規表示式可以接受 john_doe、jo-hn_doe、john12_as。
但不匹配Jo,因為它包含了大寫的字母而且太短了。
目錄
1. 基本匹配
正規表示式其實就是在執行搜尋時的格式,它由一些字母和數位組合而成。
例如:一個正規表示式 the,它表示一個規則:由字母t開始,接著是h,再接著是e。
"the" => The fat cat sat on the mat.
"the" => The fat cat sat on the mat.
正規表示式123匹配字串123。它逐個字元的與輸入的正規表示式做比較。
正規表示式是大小寫敏感的,所以The不會匹配the。
"The" => The fat cat sat on the mat.
"The" => The fat cat sat on the mat.
2. 元字元
正規表示式主要依賴於元字元。
元字元不代表他們本身的字面意思,他們都有特殊的含義。一些元字元寫在方括號中的時候有一些特殊的意思。以下是一些元字元的介紹:
| 元字元 | 描述 |
|---|---|
| . | 句號匹配任意單個字元除了換行符。 |
| [ ] | 字元種類。匹配方括號內的任意字元。 |
| [^ ] | 否定的字元種類。匹配除了方括號裡的任意字元 |
| * | 匹配>=0個重複的在*號之前的字元。 |
| + | 匹配>=1個重複的+號前的字元。 |
| ? | 標記?之前的字元為可選. |
| {n,m} | 匹配num個大括號之前的字元或字元集 (n <= num <= m). |
| (xyz) | 字元集,匹配與 xyz 完全相等的字串. |
| | | 或運運算元,匹配符號前或後的字元. |
| \ | 跳脫字元,用於匹配一些保留的字元 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 從開始行開始匹配. |
| $ | 從末端開始匹配. |
2.1 點運運算元 .
.是元字元中最簡單的例子。
.匹配任意單個字元,但不匹配換行符。
例如,表示式.ar匹配一個任意字元后面跟著是a和r的字串。
".ar" => The car parked in the garage.
".ar" => The car parked in the garage.
2.2 字元集
字元集也叫做字元類。
方括號用來指定一個字元集。
在方括號中使用連字元來指定字元集的範圍。
在方括號中的字元集不關心順序。
例如,表示式[Tt]he 匹配 the 和 The。
"[Tt]he" => The car parked in the garage.
"[Tt]he" => The car parked in the garage.
方括號的句號就表示句號。
表示式 ar[.] 匹配 ar.字串
"ar[.]" => A garage is a good place to park a car.
"ar[.]" => A garage is a good place to park a car.
2.2.1 否定字元集
一般來說 ^ 表示一個字串的開頭,但它用在一個方括號的開頭的時候,它表示這個字元集是否定的。
例如,表示式[^c]ar 匹配一個後面跟著ar的除了c的任意字元。
"[^c]ar" => The car parked in the garage.
"[^c]ar" => The car parked in the garage.
2.3 重複次數
後面跟著元字元 +,* or ? 的,用來指定匹配子模式的次數。
這些元字元在不同的情況下有著不同的意思。
2.3.1 * 號
*號匹配 在*之前的字元出現大於等於0次。
例如,表示式 a* 匹配0或更多個以a開頭的字元。表示式[a-z]* 匹配一個行中所有以小寫字母開頭的字串。
"[a-z]*" => The car parked in the garage #21.
"[a-z]*" => The car parked in the garage #21.
*字元和.字元搭配可以匹配所有的字元.*。
*和表示匹配空格的符號\s連起來用,如表示式\s*cat\s*匹配0或更多個空格開頭和0或更多個空格結尾的cat字串。
"\s*cat\s*" => The fat cat sat on the concatenation.
"\s*cat\s*" => The fat cat sat on the concatenation.
2.3.2 + 號
+號匹配+號之前的字元出現 >=1 次。
例如表示式c.+t 匹配以首字母c開頭以t結尾,中間跟著至少一個字元的字串。
"c.+t" => The fat cat sat on the mat.
"c.+t" => The fat cat sat on the mat.
2.3.3 ? 號
在正規表示式中元字元 ? 標記在符號前面的字元為可選,即出現 0 或 1 次。
例如,表示式 [T]?he 匹配字串 he 和 The。
"[T]he" => The car is parked in the garage.
"[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
2.4 {} 號
在正規表示式中 {} 是一個量詞,常用來限定一個或一組字元可以重複出現的次數。
例如, 表示式 [0-9]{2,3} 匹配最少 2 位最多 3 位 0~9 的數位。
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
我們可以省略第二個引數。
例如,[0-9]{2,} 匹配至少兩位 0~9 的數位。
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
如果逗號也省略掉則表示重複固定的次數。
例如,[0-9]{3} 匹配3位數位
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
2.5 (...) 特徵標群
特徵標群是一組寫在 (...) 中的子模式。(...) 中包含的內容將會被看成一個整體,和數學中小括號( )的作用相同。例如, 表示式 (ab)* 匹配連續出現 0 或更多個 ab。如果沒有使用 (...) ,那麼表示式 ab* 將匹配連續出現 0 或更多個 b 。再比如之前說的 {} 是用來表示前面一個字元出現指定次數。但如果在 {} 前加上特徵標群 (...) 則表示整個標群內的字元重複 N 次。
我們還可以在 () 中用或字元 | 表示或。例如,(c|g|p)ar 匹配 car 或 gar 或 par.
"(c|g|p)ar" => The car is parked in the garage.
"(c|g|p)ar" => The car is parked in the garage.
2.6 | 或運運算元
或運運算元就表示或,用作判斷條件。
例如 (T|t)he|car 匹配 (T|t)he 或 car。
"(T|t)he|car" => The car is parked in the garage.
"(T|t)he|car" => The car is parked in the garage.
2.7 轉碼特殊字元
反斜線 \ 在表示式中用於轉碼緊跟其後的字元。用於指定 { } [ ] / \ + * . $ ^ | ? 這些特殊字元。如果想要匹配這些特殊字元則要在其前面加上反斜線 \。
例如 . 是用來匹配除換行符外的所有字元的。如果想要匹配句子中的 . 則要寫成 \. 以下這個例子 \.?是選擇性匹配.
"(f|c|m)at\.?" => The fat cat sat on the mat.
"(f|c|m)at\.?" => The fat cat sat on the mat.
2.8 錨點
在正規表示式中,想要匹配指定開頭或結尾的字串就要使用到錨點。^ 指定開頭,$ 指定結尾。
2.8.1 ^ 號
^ 用來檢查匹配的字串是否在所匹配字串的開頭。
例如,在 abc 中使用表示式 ^a 會得到結果 a。但如果使用 ^b 將匹配不到任何結果。因為在字串 abc 中並不是以 b 開頭。
例如,^(T|t)he 匹配以 The 或 the 開頭的字串。
"(T|t)he" => The car is parked in the garage.
"(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
2.8.2 $ 號
同理於 ^ 號,$ 號用來匹配字元是否是最後一個。
例如,(at\.)$ 匹配以 at. 結尾的字串。
"(at\.)" => The fat cat. sat. on the mat.
"(at\.)" => The fat cat. sat. on the mat.
"(at\.)$" => The fat cat. sat. on the mat.
"(at\.)$" => The fat cat. sat. on the mat.
3. 簡寫字元集
正規表示式提供一些常用的字元集簡寫。如下:
| 簡寫 | 描述 |
|---|---|
| . | 除換行符外的所有字元 |
| \w | 匹配所有字母數位,等同於 [a-zA-Z0-9_] |
| \W | 匹配所有非字母數位,即符號,等同於: [^\w] |
| \d | 匹配數位: [0-9] |
| \D | 匹配非數位: [^\d] |
| \s | 匹配所有空格字元,等同於: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字元: [^\s] |
| \f | 匹配一個換頁符 |
| \n | 匹配一個換行符 |
| \r | 匹配一個回車符 |
| \t | 匹配一個製表符 |
| \v | 匹配一個垂直製表符 |
| \p | 匹配 CR/LF(等同於 \r\n),用來匹配 DOS 行終止符 |
4. 零寬度斷言(前後預查)
先行斷言和後發斷言(合稱 lookaround)都屬於非捕獲組(用於匹配模式,但不包括在匹配列表中)。當我們需要一個模式的前面或後面有另一個特定的模式時,就可以使用它們。
例如,我們希望從下面的輸入字串 $4.44 和 $10.88 中獲得所有以 $ 字元開頭的數位,我們將使用以下的正規表示式 (?<=\$)[0-9\.]*。意思是:獲取所有包含 . 並且前面是 $ 的數位。
零寬度斷言如下:
| 符號 | 描述 |
|---|---|
| ?= | 正先行斷言-存在 |
| ?! | 負先行斷言-排除 |
| ?<= | 正後發斷言-存在 |
| ?<! | 負後發斷言-排除 |
4.1 ?=... 正先行斷言
?=... 正先行斷言,表示第一部分表示式之後必須跟著 ?=...定義的表示式。
返回結果只包含滿足匹配條件的第一部分表示式。
定義一個正先行斷言要使用 ()。在括號內部使用一個問號和等號: (?=...)。
正先行斷言的內容寫在括號中的等號後面。
例如,表示式 (T|t)he(?=\sfat) 匹配 The 和 the,在括號中我們又定義了正先行斷言 (?=\sfat) ,即 The 和 the 後面緊跟著 (空格)fat。
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
4.2 ?!... 負先行斷言
負先行斷言 ?! 用於篩選所有匹配結果,篩選條件為 其後不跟隨著斷言中定義的格式。
正先行斷言 定義和 負先行斷言 一樣,區別就是 = 替換成 ! 也就是 (?!...)。
表示式 (T|t)he(?!\sfat) 匹配 The 和 the,且其後不跟著 (空格)fat。
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
4.3 ?<= ... 正後發斷言
正後發斷言 記作(?<=...) 用於篩選所有匹配結果,篩選條件為 其前跟隨著斷言中定義的格式。
例如,表示式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat,且其前跟著 The 或 the。
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.
4.4 ?<!... 負後發斷言
負後發斷言 記作 (?<!...) 用於篩選所有匹配結果,篩選條件為 其前不跟隨著斷言中定義的格式。
例如,表示式 (?<!(T|t)he\s)(cat) 匹配 cat,且其前不跟著 The 或 the。
"(?<!(T|t)he\s)(cat)" => The cat sat on cat.
"(?<!(T|t)he\s)(cat)" => The cat sat on cat.
5. 標誌
標誌也叫模式修正符,因為它可以用來修改表示式的搜尋結果。
這些標誌可以任意的組合使用,它也是整個正規表示式的一部分。
| 標誌 | 描述 |
|---|---|
| i | 忽略大小寫。 |
| g | 全域性搜尋。 |
| m | 多行修飾符:錨點元字元 ^ $ 工作範圍在每行的起始。 |
5.1 忽略大小寫 (Case Insensitive)
修飾語 i 用於忽略大小寫。
例如,表示式 /The/gi 表示在全域性搜尋 The,在後面的 i 將其條件修改為忽略大小寫,則變成搜尋 the 和 The,g 表示全域性搜尋。
"The" => The fat cat sat on the mat.
"The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
5.2 全域性搜尋 (Global search)
修飾符 g 常用於執行一個全域性搜尋匹配,即(不僅僅返回第一個匹配的,而是返回全部)。
例如,表示式 /.(at)/g 表示搜尋 任意字元(除了換行)+ at,並返回全部結果。
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
5.3 多行修飾符 (Multiline)
多行修飾符 m 常用於執行一個多行匹配。
像之前介紹的 (^,$) 用於檢查格式是否是在待檢測字串的開頭或結尾。但我們如果想要它在每行的開頭和結尾生效,我們需要用到多行修飾符 m。
例如,表示式 /at(.)?$/gm 表示小寫字元 a 後跟小寫字元 t ,末尾可選除換行符外任意字元。根據 m 修飾符,現在表示式匹配每行的結尾。
"/.at(.)?$/" => The fat
cat sat
on the mat.
"/.at(.)?$/" => The fat
cat sat
on the mat.
"/.at(.)?$/gm" => The fat
cat sat
on the mat.
"/.at(.)?$/gm" => The fat cat sat on the mat.
6. 貪婪匹配與惰性匹配 (Greedy vs lazy matching)
正規表示式預設採用貪婪匹配模式,在該模式下意味著會匹配儘可能長的子串。我們可以使用 ? 將貪婪匹配模式轉化為惰性匹配模式。
"/(.*at)/" => The fat cat sat on the mat.
"/(.*at)/" => The fat cat sat on the mat.
"/(.*?at)/" => The fat cat sat on the mat.
"/(.*?at)/" => The fat cat sat on the mat.