Redis系列5:深入分析Cluster 叢集模式
Redis系列1:深刻理解高效能Redis的本質
Redis系列2:資料持久化提高可用性
Redis系列3:高可用之主從架構
Redis系列4:高可用之Sentinel(哨兵模式)
1 背景
前面我們學習了Redis高可用的兩種架構模式:主從模式、哨兵模式。
解決了我們在Redis範例發生故障時,具備主從自動切換、故障轉移的能力,最終保證服務的高可用。
但是這些其實遠遠不夠,隨著我們業務規模的不斷擴充套件,使用者量膨脹,並行量持續提升。原有的主從架構,已經遠遠達不到我們的需求了,這時候會有一些問題出現,比如:
- 單機的CPU、記憶體、連線數、計算力都是有極限的,不能無限制的承載流量的擴增。
- 超額的請求、大規模的資料計算,導致必然的慢響應。
這時候就需要適當的推進架構的演進,來滿足發展的需要。
2 Cluster 模式介紹
2.1 什麼是Cluster模式
Cluster 即 叢集模式,類似MySQL,Redis 叢集也是一種分散式資料庫方案,叢集通過分片(sharding)模式來對資料進行管理,並具備分片間資料複製、故障轉移和流量排程的能力。這種 分治模式很常見,我們在 微服務系列:拆分策略 和 MySQL系列:分庫分表 中實踐過很多次了。
Redis叢集的做法是 將資料劃分為 16384(2的14次方)個雜湊槽(slots),如果你有多個範例節點,那麼每個範例節點將管理其中一部分的槽位,槽位的資訊會儲存在各自所歸屬的節點中。以下圖為例,該叢集有4個 Redis 節點,每個節點負責叢集中的一部分資料,資料量可以不均勻。比如效能好的範例節點可以多分擔一些壓力。
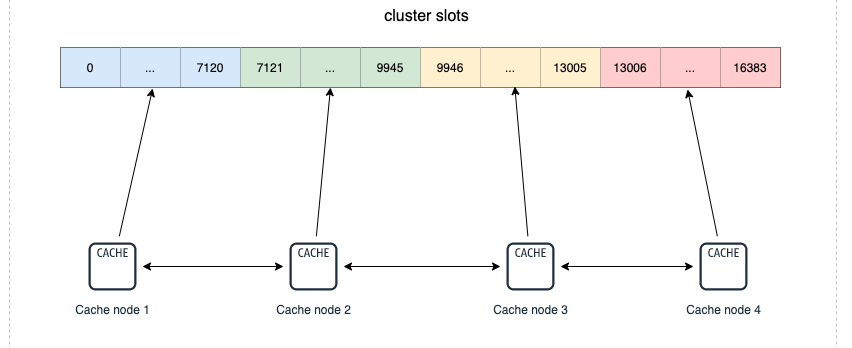
一個Redis叢集一共有16384個雜湊槽,你可以有1 ~ n個節點來分配這些雜湊槽,可以不均勻分配,每個節點可以處理0個 到至多 16384 個槽點。
當16384個雜湊槽都有節點進行管理的時候,叢集處於online 狀態。同樣的,如果有一個雜湊槽沒有被管理到,那麼叢集處於offline狀態。
上面圖中4個範例節點組成了一個叢集,叢集之間的資訊通過 Gossip協定 進行互動,這樣就可以在某一節點記錄其他節點的雜湊槽(slots)的分配情況。
2.2 為什麼需要Cluster模式
單機的吞吐無法承受持續擴增的流量的時候,最好的辦法是從橫向(scale out) 和 縱向(scale up)兩方面進行擴充套件,這個我們在 MySQL系列 和 微服務系列 的時候已經討論過了。
- 縱向擴充套件(scale up):將單個範例的硬體資源做提升,比如 CPU核數量、記憶體容量、SSD容量。
- 橫向擴充套件(scale out):橫向擴增 Redis 範例數,這樣每個節點只負責一部分資料就可以,分擔一下壓力,典型的分治思維。
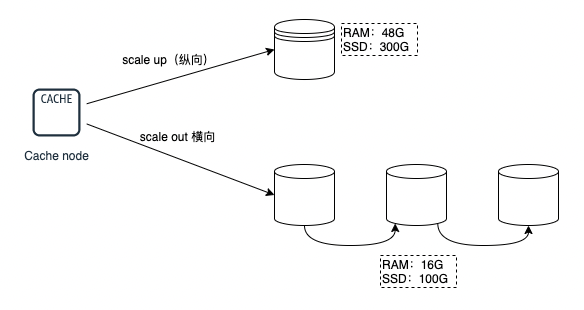
那橫向擴充套件和縱向擴充套件各有什麼優缺點呢? - scale up 雖然操作起來比較簡易。但是沒法解決Redis一些瓶頸問題,比如持久化(如輪式RDB快照還是AOF指令),遇到巨量資料量的時候,照樣效率會很低,響應慢。另外,單臺服務機硬體擴容也是有限制的,不可能無限操作。
- scale out 更容易擴充套件,分片的模式可以解決很多問題,包括單一範例節點的硬體擴容限制、成本限制,還可以分攤壓力,精細化治理,精細化維護。但是同時也要面臨分散式帶來的一些問題
現實情況下,在面對千萬級甚至億級別的流量的時候,很多大廠都是在千百臺的範例節點組成的叢集上進行流量排程、服務治理的。所以,使用Cluster模式,是業內廣泛採用的模式。
3 Cluster 實現原理
3.1 叢集的群組過程
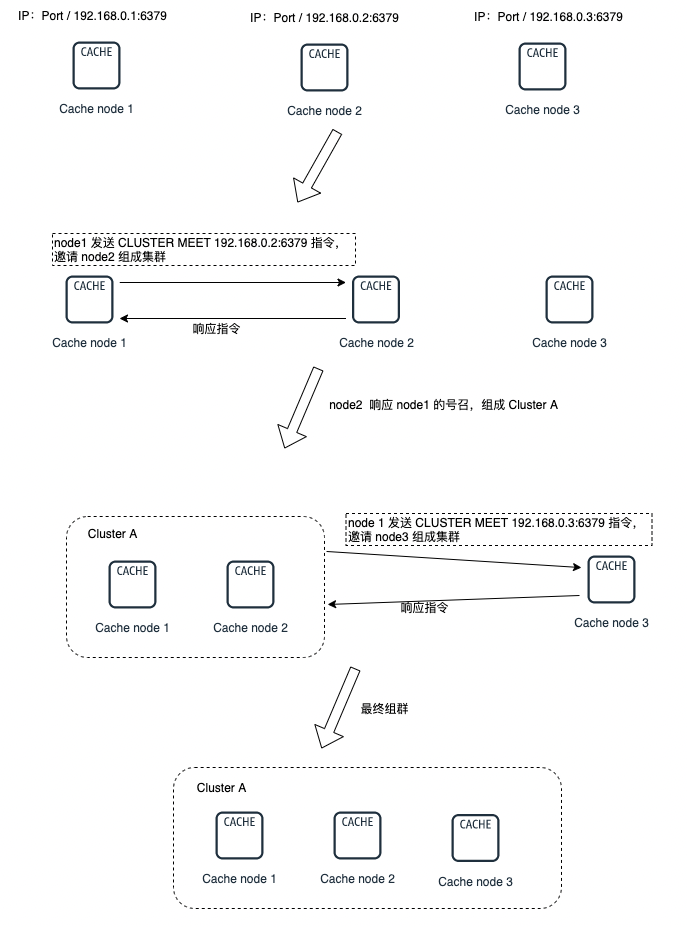
叢集是由一個個互相獨立的節點(readis node)組成的, 所以剛開始的時候,他們都是隔離,毫無聯絡的。我們需要通過一些操作,把他們聚集在一起,最終才能組成真正的可協調工作的叢集。
各個節點的聯通是通過 CLUSTER MEET 命令完成的:CLUSTER MEET <ip> <port> 。
具體的做法是其中一個node向另外一個 node(指定 ip 和 port) 傳送 CLUSTER MEET 命令,這樣就可以讓兩個節點進行握手(handshake操作) ,握手成功之後,node 節點就會將握手另一側的節點新增到當前節點所在的叢集中。
這樣一步步的將需要聚集的節點都圈入同一個叢集中,如下圖:
3.2 叢集資料分片原理
現在的Redis叢集分片的做法,主要是使用了官方提供的 Redis Cluster 方案。這種方案就是的核心就是叢集的範例節點與雜湊槽(slots)之間的劃分、對映與管理。下面我們來看看他具體的步驟。
3.2.1 雜湊槽(slots)的劃分
這個前面已經說過了,我們會將整個Redis資料庫劃分為16384個雜湊槽,你的Redis叢集可能有n個範例節點,每個節點可以處理0個 到至多 16384 個槽點,這些節點把 16384個槽位瓜分完成。
而你實際儲存的Redis鍵值資訊也必然歸屬於這 16384 個槽的其中一個。slots 與 Redis Key 的對映是通過以下兩個步驟完成的:
- 使用 CRC16 演演算法計算鍵值對資訊的Key,會得出一個 16 bit 的值。
- 將 第1步中得到的 16 bit 的值對 16384 取模,得到的值會在 0 ~ 16383 之間,對映到對應到雜湊槽中。
當然,可能在一些特殊的情況下,你想把某些key固定到某個slot上面,也就是同一個範例節點上。這時候可以用hash tag能力,強制 key 所歸屬的槽位等於 tag 所在的槽位。
其實現方式為在key中加個{},例如test_key{1}。使用hash tag後用戶端在計算key的crc16時,只計算{}中資料。如果沒使用hash tag,使用者端會對整個key進行crc16計算。下面演示下hash tag使用:
127.0.0.1:6380> cluster keyslot user:case{1}
(integer) 1024
127.0.0.1:6380> cluster keyslot user:favor
(integer) 1023
127.0.0.1:6380> cluster keyslot user:info{1}
(integer) 1024
如上,使用hash tag 後會對應到通一個hash slot:1024中。
3.2.2 雜湊槽(slots)的對映
一種是初始化的時候均勻分配 ,使用 cluster create 建立,會將 16384 個slots 平均分配在我們的叢集範例上,比如你有n個節點,那每個節點的槽位就是 16384 / n 個了 。
另一種是通過 CLUSTER MEET 命令將 node1、node2、ndoe3、node4 4個節點聯通成一個叢集,剛聯通的時候因為還沒分配雜湊槽,還是處於offline狀態。我們使用 cluster addslots 命令來指定。
指定的好處就是效能好的範例節點可以多分擔一些壓力。
可以通過 addslots 命令指定雜湊槽範圍,比如下圖中,我們雜湊槽是這麼分配的:範例 1 管理 0 ~ 7120 雜湊槽,範例 2 管理 7121~9945 雜湊槽,範例 3 管理 9946 ~ 13005 雜湊槽,範例 4 管理 13006 ~ 16383 雜湊槽。
redis-cli -h 192.168.0.1 –p 6379 cluster addslots 0,7120
redis-cli -h 192.168.0.2 –p 6379 cluster addslots 7121,9945
redis-cli -h 192.168.0.3 –p 6379 cluster addslots 9946,13005
redis-cli -h 192.168.0.4 –p 6379 cluster addslots 13006,16383
slots 和 Redis 範例之間的對映關係如下:
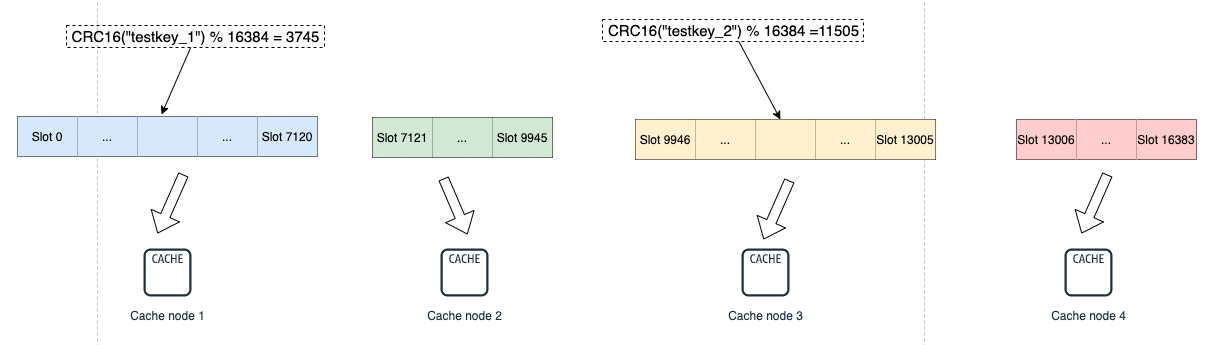
key testkey_1 和 testkey_2 經過 CRC16 計算後再對slots的總個數 16384 取模,結果分別匹配到了 cache1 和 cache3 上。
3.3 資料複製過程和故障轉移
3.3.1 資料複製
Cluster 是具備Master 和 Slave模式,Redis 叢集中的每個範例節點都負責一些槽位,比如上圖中的四個節點分管了不同的槽位區間。而每個Master至少需要一個Slave節點,Slave 節點是通過《Redis系列3:高可用之主從架構》方式同步主節點資料。 節點之間保持TCP通訊,當Master發生了宕機, Redis Cluster自動會將對應的Slave節點選為Master,來繼續提供服務。與純主從模式不同的是,主從節點之間並沒有讀寫分離, Slave 只用作 Master 宕機的高可用備份,所以更合理來說應該是主備模式。
如果主節點沒有從節點,那麼一旦發生故障時,叢集將完全處於不可用狀態。 但也允許設定 cluster-require-full-coverage引數,及時部分節點不可用,其他節點正常提供服務,這是為了避免全盤宕機。
主從切換之後,故障恢復的主節點,會轉化成新主節點的從節點。這種自愈模式對提高可用性非常有幫助。
3.3.2 故障檢測
一個節點認為某個節點宕機不能說明這個節點真的掛起了,無法提供服務了。只有佔據多數的範例節點都認為某個節點掛起了,這時候cluster才進行下線和主從切換的工作。
Redis 叢集的節點採用 Gossip 協定來廣播資訊,每個節點都會定期向其他節點傳送ping命令,如果接受ping訊息的節點在指定時間內沒有回覆pong,則會認為該節點失聯了(PFail),則傳送ping的節點就把接受ping的節點標記為主觀下線。
如果叢集半數以上的主節點都將主節點 xxx 標記為主觀下線,則節點 xxx 將被標記為客觀下線,然後向整個叢集廣播,讓其它節點也知道該節點已經下線,並立即對下線的節點進行主從切換。
3.3.3 主從故障轉移
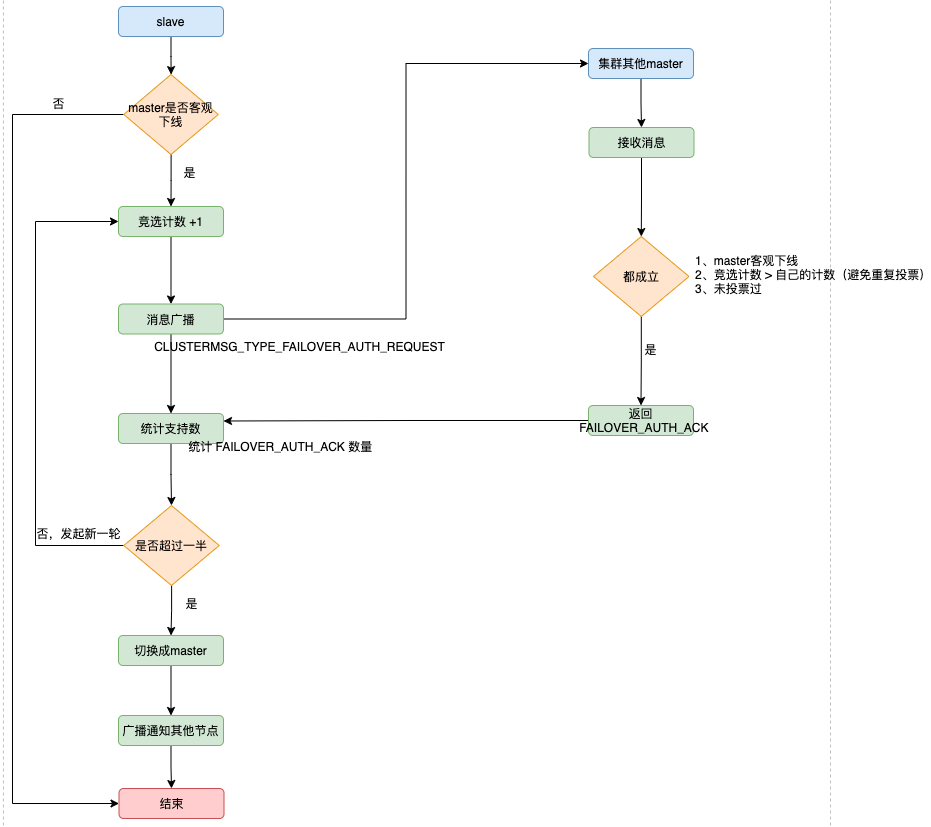
當一個從節點發現自己正在複製的主節點進入了已下線,則開始對下線主節點進行故障轉移,故障轉移的步驟如下:
-
如果只有一個slave節點,則從節點會執行SLAVEOF no one命令,成為新的主節點。
-
如果是多個slave節點,則採用選舉模式進行,競選出新的Master
- 叢集中設立一個自增計數器,初始值為 0 ,每次執行故障轉移選舉,計數就會+1。
- 檢測到主節點下線的從節點向叢集所有master廣播一條CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息,所有收到訊息、並具備投票權的主節點都向這個從節點投票。
- 如果收到訊息、並具備投票權的主節點未投票給其他從節點(只能投一票哦,所以投過了不行),則返回一條CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息,表示支援。
- 參與選舉的從節點都會接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息,如果收集到的選票 大於等於 (n/2) + 1 支援,n代表所有具備選舉權的master,那麼這個從節點就被選舉為新主節點。
- 如果這一輪從節點都沒能爭取到足夠多的票數,則發起再一輪選舉(自增計數器+1),直至選出新的master。
-
新的主節點會復原所有對已下線主節點的slots指派,並將這些slots全部指派給自己。
-
新的主節點向叢集廣播一條PONG訊息,這條PONG訊息可以讓叢集中的其他節點立即知道這個節點已經由從節點變成了主節點,並且這個主節點已經接管了原本由已下線節點負責處理的槽。
-
新的主節點開始接收和自己負責處理的槽有關的命令請求,故障轉移完成。
跟哨兵類似,兩者都是基於 Raft 演演算法來實現的,流程如圖所示:
3.4 client 存取 資料叢集的過程
3.4.1 定位資料所在節點
我們前面說過了,Redis 中的每個範例節點會將自己負責的雜湊槽資訊 通過 Gossip 協定廣播給叢集中其他的範例,實現了slots分配資訊的擴散。這樣的話,每個範例都知道整個叢集的雜湊槽分配情況以及對映資訊。
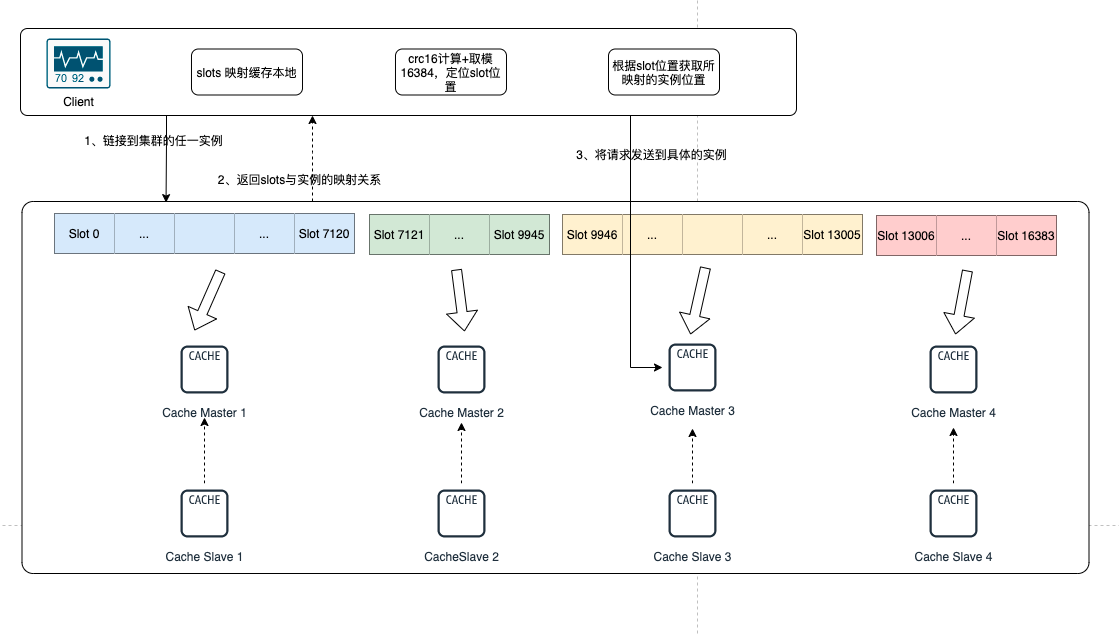
所以使用者端想要快捷的連線到伺服器端,並對某個redis資料進行快捷存取,一般是經過以下步驟:
- 使用者端連線任一範例,獲取到slots與範例節點的對映關係,並將該對映關係的資訊快取在本地。
- 將需要存取的redis資訊的key,經過CRC16計算後,再對16384 取模得到對應的 Slot 索引。
- 通過slot的位置進一步定位到具體所在的範例,再將請求傳送到對應的範例上。
下圖展示了 Redis 使用者端如何定位資料所在節點:
4 總結
- 哨兵模式已經實現了故障自動轉移的能力,但業務規模的不斷擴充套件,使用者量膨脹,並行量持續提升,會出現了 Redis 響應慢的情況。
- 使用 Redis Cluster 叢集,主要解決了巨量資料量儲存導致的各種慢問題,同時也便於橫向拓展。在面對千萬級甚至億級別的流量的時候,很多大廠的做法是在千百臺的範例節點組成的叢集上進行流量排程、服務治理的。
- 整個Redis資料庫劃分為16384個雜湊槽,Redis叢集可能有n個範例節點,每個節點可以處理0個 到至多 16384 個槽點,這些節點把 16384個槽位瓜分完成。
- Cluster 是具備Master 和 Slave模式,Redis 叢集中的每個範例節點都負責一些槽位,節點之間保持TCP通訊,當Master發生了宕機, Redis Cluster自動會將對應的Slave節點選為Master,來繼續提供服務。
- 使用者端能夠快捷的連線到伺服器端,主要是將slots與範例節點的對映關係儲存在本地,當需要存取的時候,對key進行CRC16計算後,再對16384 取模得到對應的 Slot 索引,再定位到相應的範例上。實現高效的連線。
