Docker部署kafka|Go操作實踐
前言
寫作本文的背景是由於位元組的暑期青訓營中,某個專案要求編寫一個簡易的流處理引擎(flink),開發語言不限,推薦Java,本著好奇心的驅使,我打算使用Go語言進行部分嘗試。
既然是流處理引擎,那麼首先需要有流式的資料來源,一般而言,flink會配合從kafka中獲取資料流,先不考慮後續編寫引擎的部分,本文將著重於kafka的部署,並且後半段將給出使用Go語言編寫kafka的生產者和消費者。
如果你只是希望完成kafka的部署,而不想侷限於Go語言,只需要著重閱讀文章的前半部分,後文的Go語言操作部分可以給你提供一些思路,你只需要找尋適合語言如Java的kafka client庫去完成生產者和消費者的編寫即可。
部署kafka
docker前置知識
下文的實踐需要你擁有基本的docker操作能力,如果未曾掌握docker知識點,推薦閱讀這兩篇文章:
docker | jenkins 實現自動化部署專案,後端躺著把運維的錢掙了!(上)
docker | jenkins 自動化CI/CD,後端躺著把運維的錢掙了!(下)
docker-compose
編寫docker-compose.yml,通過docker容器部署單節點kafka
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper:3.4.6
volumes:
- ./zookeeper_data:/opt/zookeeper-3.4.6/data
container_name: zookeeper
ports:
- "10002:2181"
- "10003:2182"
restart: always
kafka:
image: wurstmeister/kafka
container_name: kafka_01
depends_on:
- zookeeper
ports:
- "10004:9092"
volumes:
- ./kafka_log:/kafka
environment:
- KAFKA_BROKER_NO=0
- KAFKA_BROKER_ID=0
- KAFKA_LISTENERS=PLAINTEXT://kafka_01:9092 # kafka tcp 偵聽的ip
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://伺服器ip:10004 # kafka broker偵聽的ip
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_HEAP_OPTS=-Xmx512M -Xms16M
restart: always
# kafka叢集管理面板
kafka_manager:
image: sheepkiller/kafka-manager
ports:
- "10005:9000"
environment:
- ZK_HOSTS=zookeeper:2181
depends_on:
- zookeeper
- kafka
restart: always
後臺執行
docker-compose up -d
docker ps命令檢視容器是否啟動成功

通過上述docker-compose.yml部署會執行三個容器,選擇進入kafka容器

docker exec -it kafka容器id /bin/bash
# 進入kafka目錄
cd /opt/kafka_2.13-2.8.1/
在容器內建立topic,topic是kafka中資料管理的基本單位,或者說集合,每一個topic可以管理多個partition,編碼操作時:你可以往對應kafka伺服器ip+port+topic+partition去傳送和讀取資料。
bin/kafka-topics.sh --create --zookeeper 伺服器ip:2181 --replication-factor 1 -partitions 1 --topic test
業務編寫
Go語言中連線kafka使用第三方庫: github.com/Shopify/sarama
go get github.com/segmentio/kafka-go
sarama庫的簡易操作可以參照檔案(消費者的編寫檔案中有坑):檔案地址
如下使用kafka client庫進行編碼所涉及的API操作比較簡單,流程上或許不夠規範,請酌情參考。
producer
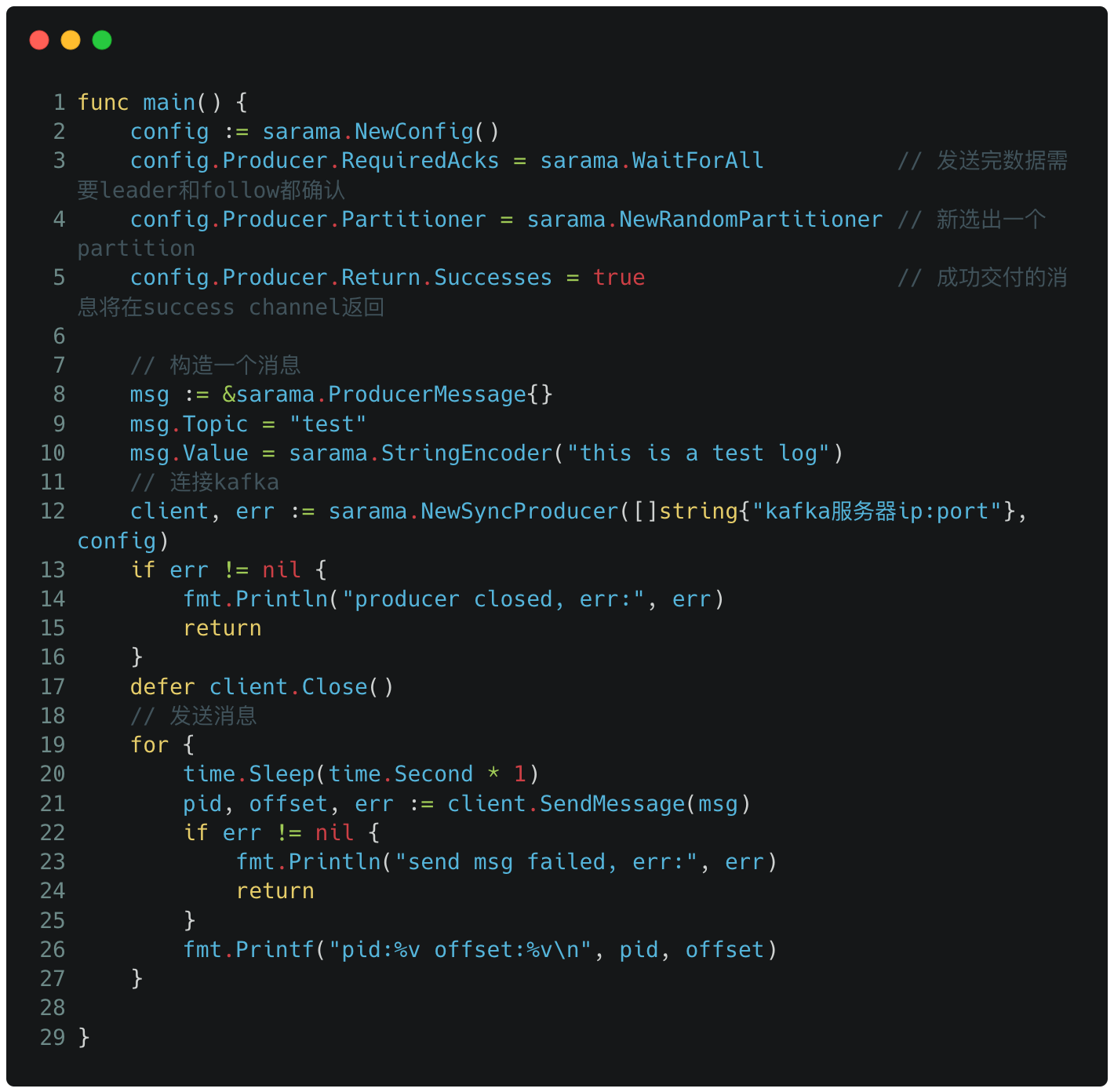
檔案中生產者只傳送了一條資料後就會關閉,這裡我改成了每秒鐘傳送一次。
consumer
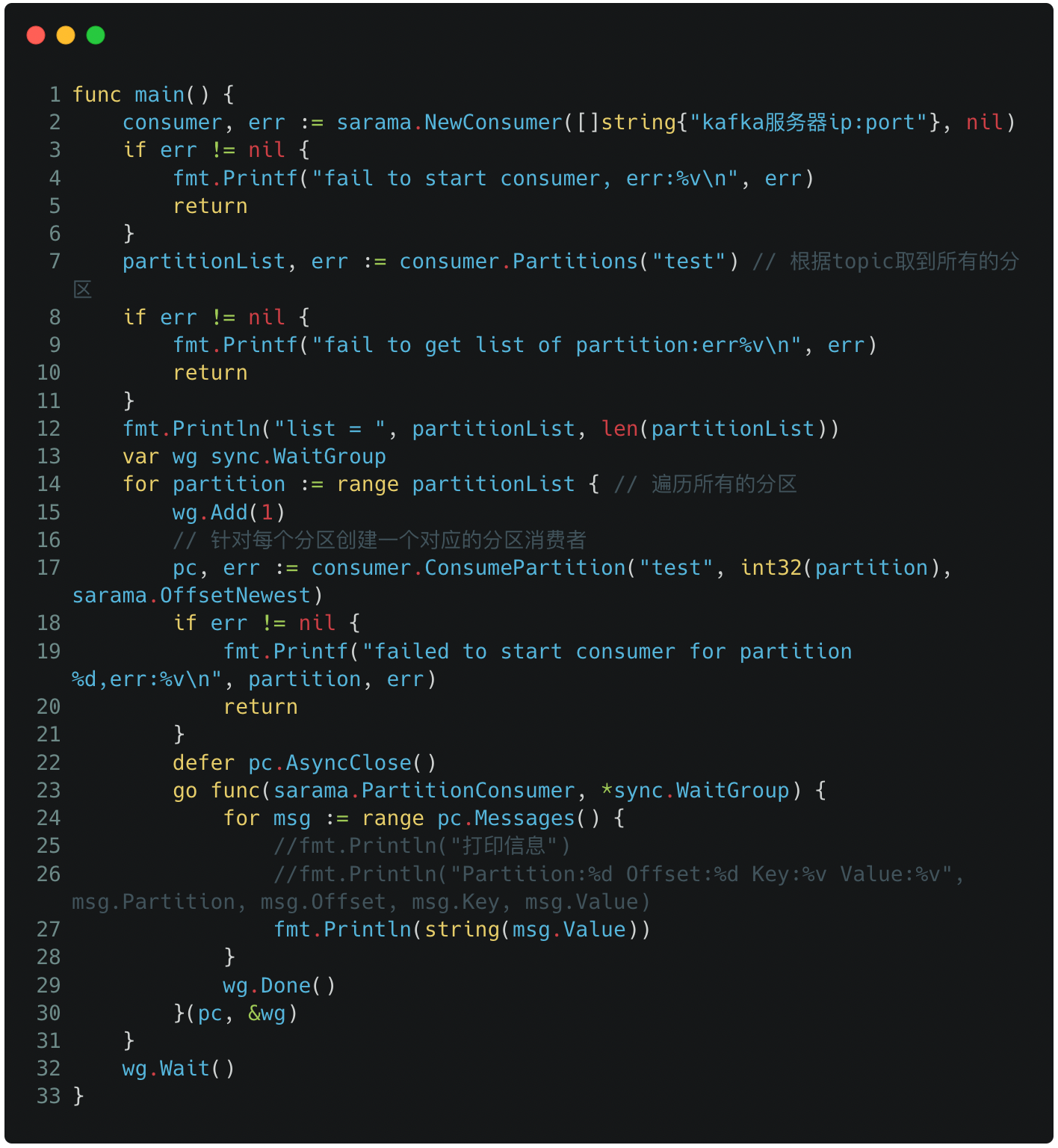
檔案中消費者雖然開啟了Go協程(類比於Java的執行緒)去讀取kafka的資料,但是由於主程式執行順序執行完畢後,子協程也會終止,導致子協程還沒有讀取成功/列印資料,整個程式就已經關閉執行了。
因此我做了一些改動,在子協程退出之前,保持主程式不會退出(使用Go語言的WaitGroup),如果簡單粗暴在main函數末尾設定一個很長的程式sleep時間,也是可以實現列印輸出的。
生產&消費
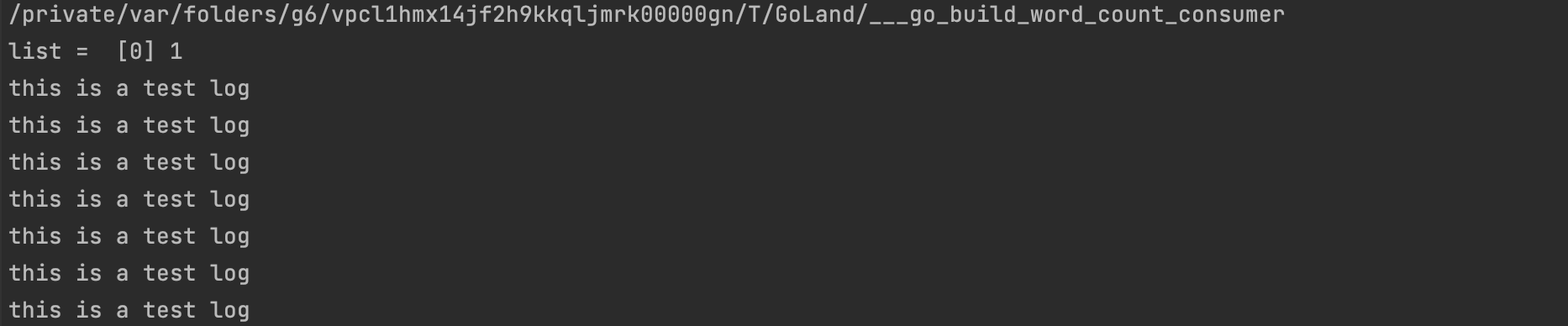
確保kafka容器正常執行,kafka伺服器防火牆埠正常開放,執行消費者程式,執行生產者程式。這個生產者每秒向kafka傳送一條測試資料:this is a test log,你也可以新增上程式執行時間進行測試。
事實上被使用者端消費後的資料並沒有馬上從kafka刪除,這裡不多做介紹,各位自行了解~
小結
本文講解了使用docker-compose部署單節點kafka的流程,後續通過修改docker-compose.yml的內容也可以實現kafka叢集的部署,並且,在較新版本的kafka中,叢集的部署可以脫離zookeeper,但是經過了解,由於功能並不完善,這裡還是選擇了基於zookeeper的部署。