LyScript 記憶體交換與差異對比
LyScript 針對記憶體讀寫函數的封裝功能並不多,只提供了記憶體讀取和記憶體寫入函數的封裝,本篇文章將繼續對API進行封裝,實現一些在軟體逆向分析中非常實用的功能,例如記憶體交換,記憶體區域對比,磁碟與記憶體映象比較,特徵碼檢索等功能。
LyScript專案地址:https://github.com/lyshark/LyScript
記憶體區域交換: 實現被載入程式內特定一塊記憶體區域的交換,該方法實現原理就是兩個變數之間的交換,只是在交換時需要逐個位元組進行,呼叫read_memory_byte()函數實現起了很容易。
from LyScript32 import MyDebug
# 交換兩個記憶體區域
def memory_xchage(dbg,memory_ptr_x,memory_ptr_y,bytes):
ref = False
for index in range(0,bytes):
# 讀取兩個記憶體區域
read_byte_x = dbg.read_memory_byte(memory_ptr_x + index)
read_byte_y = dbg.read_memory_byte(memory_ptr_y + index)
# 交換記憶體
ref = dbg.write_memory_byte(memory_ptr_x + index,read_byte_y)
ref = dbg.write_memory_byte(memory_ptr_y + index, read_byte_x)
return ref
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
eip = dbg.get_register("eip")
# 記憶體交換
flag = memory_xchage(dbg, 6815744,6815776,4)
print("記憶體交換狀態: {}".format(flag))
dbg.close()
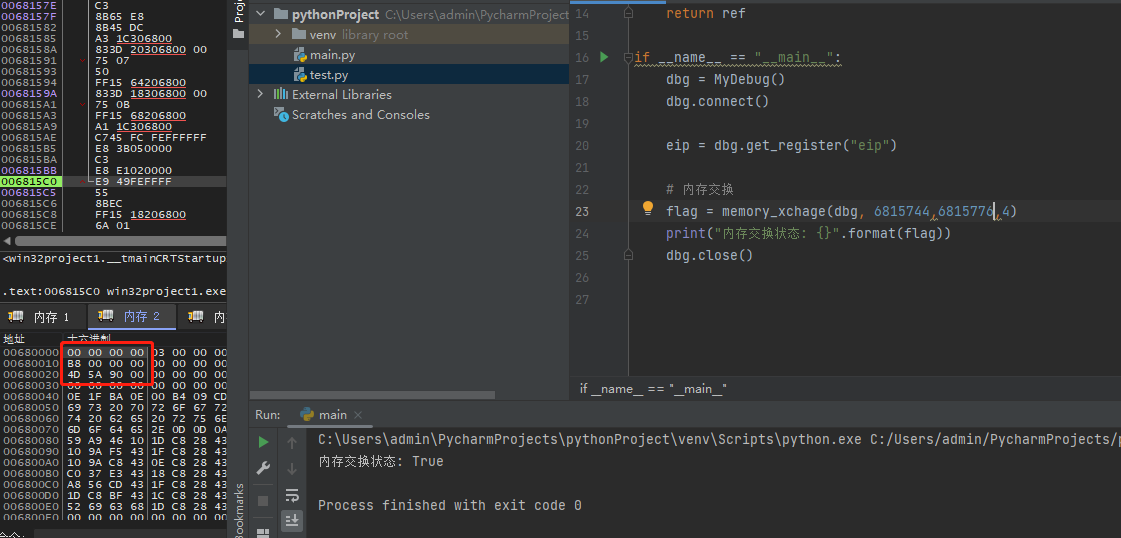
PE檔案頭節點交換後如下:
記憶體區域對比: 可用於對比該程序記憶體中的特定一塊區域的差異,返回是列表中的字典形式,分別傳入對比記憶體x,y以及需要對比的記憶體長度,此處建議不要超過1024位元組。
from LyScript32 import MyDebug
# 對比兩個記憶體區域
def memory_cmp(dbg,memory_ptr_x,memory_ptr_y,bytes):
cmp_memory = []
for index in range(0,bytes):
item = {"addr":0, "x": 0, "y": 0}
# 讀取兩個記憶體區域
read_byte_x = dbg.read_memory_byte(memory_ptr_x + index)
read_byte_y = dbg.read_memory_byte(memory_ptr_y + index)
if read_byte_x != read_byte_y:
item["addr"] = memory_ptr_x + index
item["x"] = read_byte_x
item["y"] = read_byte_y
cmp_memory.append(item)
return cmp_memory
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
eip = dbg.get_register("eip")
# 記憶體對比
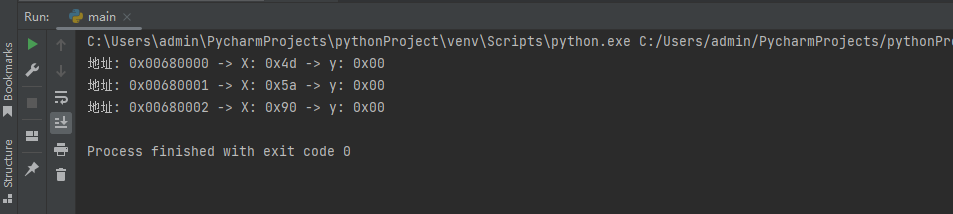
cmp_ref = memory_cmp(dbg, 6815744,6815776,4)
for index in range(0,len(cmp_ref)):
print("地址: 0x{:08X} -> X: 0x{:02x} -> y: 0x{:02x}".format(cmp_ref[index].get("addr"),cmp_ref[index].get("x"),cmp_ref[index].get("y")))
dbg.close()
對位元定記憶體區域,返回差異位元組地址:
記憶體與磁碟機器碼比較: 通過呼叫read_memory_byte()函數,或者open()開啟檔案,等就可以得到程式磁碟與記憶體中特定位置的機器碼引數,然後通過對每一個列表中的位元組進行比較,就可得到特定位置下磁碟與記憶體中的資料是否一致的判斷。
#coding: utf-8
import binascii,os,sys
from LyScript32 import MyDebug
# 得到程式的記憶體映象中的機器碼
def get_memory_hex_ascii(address,offset,len):
count = 0
ref_memory_list = []
for index in range(offset,len):
# 讀出資料
char = dbg.read_memory_byte(address + index)
count = count + 1
if count % 16 == 0:
if (char) < 16:
print("0" + hex((char))[2:])
ref_memory_list.append("0" + hex((char))[2:])
else:
print(hex((char))[2:])
ref_memory_list.append(hex((char))[2:])
else:
if (char) < 16:
print("0" + hex((char))[2:] + " ",end="")
ref_memory_list.append("0" + hex((char))[2:])
else:
print(hex((char))[2:] + " ",end="")
ref_memory_list.append(hex((char))[2:])
return ref_memory_list
# 讀取程式中的磁碟映象中的機器碼
def get_file_hex_ascii(path,offset,len):
count = 0
ref_file_list = []
with open(path, "rb") as fp:
# file_size = os.path.getsize(path)
fp.seek(offset)
for item in range(offset,offset + len):
char = fp.read(1)
count = count + 1
if count % 16 == 0:
if ord(char) < 16:
print("0" + hex(ord(char))[2:])
ref_file_list.append("0" + hex(ord(char))[2:])
else:
print(hex(ord(char))[2:])
ref_file_list.append(hex(ord(char))[2:])
else:
if ord(char) < 16:
print("0" + hex(ord(char))[2:] + " ", end="")
ref_file_list.append("0" + hex(ord(char))[2:])
else:
print(hex(ord(char))[2:] + " ", end="")
ref_file_list.append(hex(ord(char))[2:])
return ref_file_list
if __name__ == "__main__":
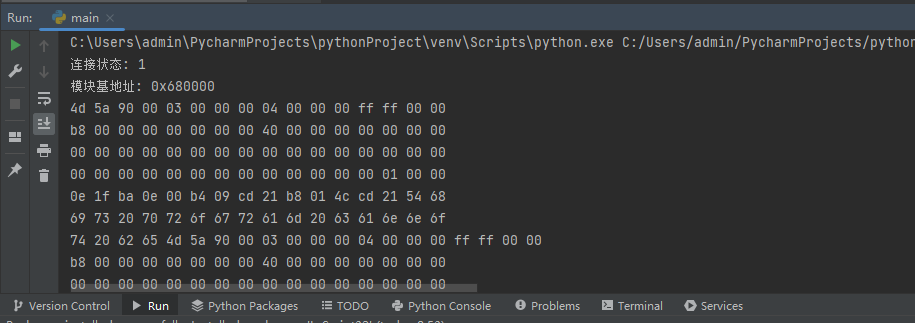
dbg = MyDebug()
connect_flag = dbg.connect()
print("連線狀態: {}".format(connect_flag))
module_base = dbg.get_base_from_address(dbg.get_local_base())
print("模組基地址: {}".format(hex(module_base)))
# 得到記憶體機器碼
memory_hex_byte = get_memory_hex_ascii(module_base,0,100)
# 得到磁碟機器碼
file_hex_byte = get_file_hex_ascii("d://Win32Project1.exe",0,100)
# 輸出機器碼
print("\n記憶體機器碼: ",memory_hex_byte)
print("\n磁碟機器碼: ",file_hex_byte)
dbg.close()
讀取後輸出時會預設十六個字元一次換行,輸出效果如下。
我們繼續增加磁碟與記憶體對比過程,然後就能實現對特定記憶體區域與磁碟區域位元組碼一致性的判斷。
#coding: utf-8
import binascii,os,sys
from LyScript32 import MyDebug
# 得到程式的記憶體映象中的機器碼
def get_memory_hex_ascii(address,offset,len):
count = 0
ref_memory_list = []
for index in range(offset,len):
# 讀出資料
char = dbg.read_memory_byte(address + index)
count = count + 1
if count % 16 == 0:
if (char) < 16:
print("0" + hex((char))[2:])
ref_memory_list.append("0" + hex((char))[2:])
else:
print(hex((char))[2:])
ref_memory_list.append(hex((char))[2:])
else:
if (char) < 16:
print("0" + hex((char))[2:] + " ",end="")
ref_memory_list.append("0" + hex((char))[2:])
else:
print(hex((char))[2:] + " ",end="")
ref_memory_list.append(hex((char))[2:])
return ref_memory_list
# 讀取程式中的磁碟映象中的機器碼
def get_file_hex_ascii(path,offset,len):
count = 0
ref_file_list = []
with open(path, "rb") as fp:
# file_size = os.path.getsize(path)
fp.seek(offset)
for item in range(offset,offset + len):
char = fp.read(1)
count = count + 1
if count % 16 == 0:
if ord(char) < 16:
print("0" + hex(ord(char))[2:])
ref_file_list.append("0" + hex(ord(char))[2:])
else:
print(hex(ord(char))[2:])
ref_file_list.append(hex(ord(char))[2:])
else:
if ord(char) < 16:
print("0" + hex(ord(char))[2:] + " ", end="")
ref_file_list.append("0" + hex(ord(char))[2:])
else:
print(hex(ord(char))[2:] + " ", end="")
ref_file_list.append(hex(ord(char))[2:])
return ref_file_list
if __name__ == "__main__":
dbg = MyDebug()
connect_flag = dbg.connect()
print("連線狀態: {}".format(connect_flag))
module_base = dbg.get_base_from_address(dbg.get_local_base())
print("模組基地址: {}".format(hex(module_base)))
# 得到記憶體機器碼
memory_hex_byte = get_memory_hex_ascii(module_base,0,1024)
# 得到磁碟機器碼
file_hex_byte = get_file_hex_ascii("d://Win32Project1.exe",0,1024)
# 輸出機器碼
for index in range(0,len(memory_hex_byte)):
# 比較磁碟與記憶體是否存在差異
if memory_hex_byte[index] != file_hex_byte[index]:
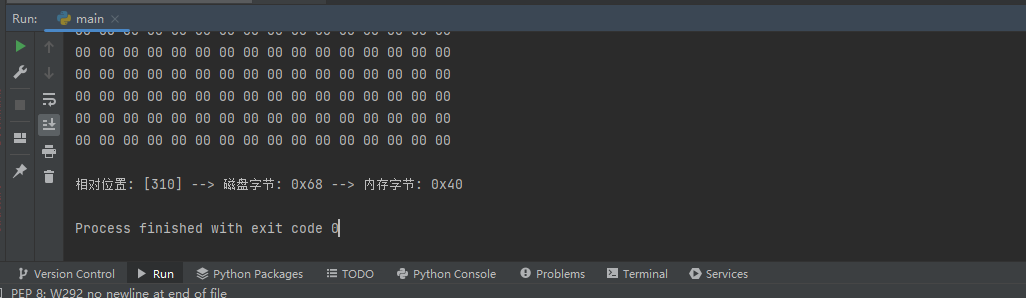
# 存在差異則輸出
print("\n相對位置: [{}] --> 磁碟位元組: 0x{} --> 記憶體位元組: 0x{}".
format(index,memory_hex_byte[index],file_hex_byte[index]))
dbg.close()
程式碼執行後即可輸出,存在差異的相對位置:
記憶體ASCII碼解析: 通過封裝的get_memory_hex_ascii得到記憶體機器碼,然後再使用如下過程實現輸出該記憶體中的機器碼所對應的ASCII碼。
from LyScript32 import MyDebug
import os,sys
# 轉為ascii
def to_ascii(h):
list_s = []
for i in range(0, len(h), 2):
list_s.append(chr(int(h[i:i+2], 16)))
return ''.join(list_s)
# 轉為16進位制
def to_hex(s):
list_h = []
for c in s:
list_h.append(hex(ord(c))[2:])
return ''.join(list_h)
# 得到程式的記憶體映象中的機器碼
def get_memory_hex_ascii(address,offset,len):
count = 0
ref_memory_list = []
for index in range(offset,len):
# 讀出資料
char = dbg.read_memory_byte(address + index)
count = count + 1
if count % 16 == 0:
if (char) < 16:
ref_memory_list.append("0" + hex((char))[2:])
else:
ref_memory_list.append(hex((char))[2:])
else:
if (char) < 16:
ref_memory_list.append("0" + hex((char))[2:])
else:
ref_memory_list.append(hex((char))[2:])
return ref_memory_list
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
eip = dbg.get_register("eip")
# 得到模組基地址
module_base = dbg.get_base_from_address(dbg.get_local_base())
# 得到指定區域記憶體機器碼
ref_memory_list = get_memory_hex_ascii(module_base,0,1024)
# 解析ascii碼
break_count = 1
for index in ref_memory_list:
if break_count %32 == 0:
print(to_ascii(hex(int(index, 16))[2:]))
else:
print(to_ascii(hex(int(index, 16))[2:]),end="")
break_count = break_count + 1
dbg.close()
輸出效果如下,如果換成中文,那就是一箇中文搜尋引擎了。
記憶體特徵碼匹配: 通過二次封裝get_memory_hex_ascii()實現掃描記憶體特徵碼功能,如果存在則返回True否則返回False。
from LyScript32 import MyDebug
import os,sys
# 得到程式的記憶體映象中的機器碼
def get_memory_hex_ascii(address,offset,len):
count = 0
ref_memory_list = []
for index in range(offset,len):
# 讀出資料
char = dbg.read_memory_byte(address + index)
count = count + 1
if count % 16 == 0:
if (char) < 16:
ref_memory_list.append("0" + hex((char))[2:])
else:
ref_memory_list.append(hex((char))[2:])
else:
if (char) < 16:
ref_memory_list.append("0" + hex((char))[2:])
else:
ref_memory_list.append(hex((char))[2:])
return ref_memory_list
# 在指定區域內搜尋特定的機器碼,如果完全匹配則返回
def search_hex_ascii(address,offset,len,hex_array):
# 得到指定區域記憶體機器碼
ref_memory_list = get_memory_hex_ascii(address,offset,len)
array = []
# 迴圈輸出位元組
for index in range(0,len + len(hex_array)):
# 如果有則繼續裝
if len(hex_array) != len(array):
array.append(ref_memory_list[offset + index])
else:
for y in range(0,len(array)):
if array[y] != ref_memory_list[offset + index + y]:
return False
array.clear()
return False
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
eip = dbg.get_register("eip")
# 得到模組基地址
module_base = dbg.get_base_from_address(dbg.get_local_base())
re = search_hex_ascii(module_base,0,100,hex_array=["0x4d","0x5a"])
dbg.close()
特徵碼掃描一般不需要自己寫,自己寫的麻煩,而且不支援萬用字元,可以直接呼叫我們API中封裝好的scan_memory_one()它可以支援??萬用字元模糊匹配,且效率要高許多。
版權宣告:本部落格文章與程式碼均為學習時整理的筆記,文章 [均為原創] 作品,轉載請 [新增出處] ,您新增出處是我創作的動力!