典型相關分析CCA計算過程
本文介紹了CCA解決的問題,CCA原理的推導過程,以及對計算結果物理意義的解釋。並且通過SPSS和R操作演示了一個關於CCA的例子。資料檔案下載參考[8],SPSS輸出結果檔案下載參考[9],R程式碼檔案下載參考[10]。
一.CCA工作原理
1.CCA定義
首先需要搞清楚典型相關分析(Canonical Correlation Analysis)解決了什麼問題,它解決的是一組變數與另外一組變數的相關問題。舉個例子,比如想要量化家庭特徵與家庭消費之間的關係,其中,家庭特徵包括戶主的年齡、家庭的年收入和戶主受教育程式,而家庭消費包括每年去餐廳就餐的頻率、每年外出看電影頻率。
其實,這個是泛化後的問題,先來看一個更加具體的問題,不是一組變數與另外一組變數的相關問題,而是一個變數與另外一個變數的相關問題,比如計算兩個變數\({X}\)和\({Y}\)的相關問題,是如何計算的呢,下面的方程是不是很眼熟:
再進一步的想一下,如果是計算一個變數和一組變數的相關問題呢。當然更深一步的想象就是這篇文章要講的一組變數與另外一組變數的相關問題。先來形式化的定義CCA:假設有一組變數\({X_1}, \cdots ,{X_p}\)與另一組變數\({Y_1}, \cdots ,{Y_q}\),要研究這兩組變數的相關關係,如何給兩組變數之間的相關性以數量的描述,就是CCA。
二.CCA方程推導過程
1.CCA的數學描述
假設\({x_1}\)表示每年去餐館就餐的頻率,\({x_2}\)表示每年外出看電影頻率,\({y_1}\)表示戶主的年齡,\({y_2}\)表示家庭的年收入,\({y_3}\)表示戶主受教育程度。典型相關分析的思想是找出第一對線性組合,使其具有最大相關性:
然後再找第二對線性組合,使其具有次大相關性:
就這樣一直進行計算下去,直到第\(r\)步,這兩組變數的相關性被提取完畢為止,其中\(r \le \min \left( {{\rm{p}},{\rm{q}}} \right)\),即可以得到\(r\)組變數。
2.CCA的推導過程
假設兩組變數的向量\({\bf{Z}} = \left( {{x_1},{x_2},...,{x_p},{y_1},{y_2},...,{y_q}} \right)\),其協方差矩陣如下:
其中,\(\sum\nolimits_{11}\)是第一組變數的協方差矩陣,\(\sum\nolimits_{22}\)是第二組變數的協方差矩陣,\(\sum\nolimits_{12}\)和\(\sum\nolimits_{21}\)是\(X\)和\(Y\)的協方差矩陣,它們之間的關係是轉置相等,即\(\sum\nolimits_{12} = {\sum\nolimits_{21} ^{\rm{T}}}\)。這樣兩組變數的第一對線性組合記為:
其中\({\bf{a}}_1\)和\({\bf{b}}_1\)表示:
接下來推導\({\rho _{{{\bf{u}}_1},{{\bf{v}}_1}}}\)的計算,通過求\({\bf{a}}_1\)和\({\bf{b}}_1\),使\({\rho _{{{\bf{u}}_1},{{\bf{v}}_1}}}\)最大,這個是CCA最核心的思想:
接下來就是典型相關係數的過程。根據高等數學中條件極致的求法,即拉格朗日乘數法,通過引入拉格朗日乘數\(\lambda\)和\(\nu\)來求極值的問題,轉換為求方程1的極大值:
接下來就是求極大值的思路了,各種求偏導,方程2如下所示:
方程3如下所示:
將方程3分別左乘\({\bf{a}}_1^{\rm{T}}\)和\({\bf{b}}_1^{\rm{T}}\),得到方程4:
進一步推導得出方程5:
因此得到方程6:
可見\(\lambda\)和\(v\)是相等的,並且就是要求的\({\rho _{{{\bf{u}}_1},{{\bf{v}}_1}}}\)。
將\(\sum\nolimits_{12} \sum\nolimits_{22}^{ - 1}\)左乘方程3的第二式,得到方程7:
進一步簡化得到方程8:
將方程3的第一式代入方程8,得到方程9:
將方程9左乘\(\sum\nolimits_{11}^{ - 1}\)得到方程10:
在方程10中,\(\sum\nolimits_{11}^{ - 1} \sum\nolimits_{12} \sum\nolimits_{22}^{ - 1} \sum\nolimits_{21}\)的特徵根是\({\lambda ^2}\),相應的特徵向量為\({{\bf{a}}_1}\)。
將\(\sum\nolimits_{12} \sum\nolimits_{11}^{ - 1}\)左乘方程3的第一式,並且將第二式代入得到方程11:
在方程11中,\(\sum\nolimits_{22}^{ - 1} \sum\nolimits_{21} \sum\nolimits_{11}^{ - 1} \sum\nolimits_{12}\)的特徵根是\({\lambda ^2}\),相應的特徵向量為\({{\bf{b}}_1}\)。
令\({{\bf{M}}_{\rm{1}}} = \sum\nolimits_{11}^{ - 1} {} \sum\nolimits_{12} {} \sum\nolimits_{22}^{ - 1} {} \sum\nolimits_{21} {}\)和\({{\bf{M}}_2}{\rm{ = }}\sum\nolimits_{22}^{ - 1} {} \sum\nolimits_{21} {} \sum\nolimits_{11}^{ - 1} {} \sum\nolimits_{12} {}\),得到方程12:
至此可以得出結論:第一個典型相關係數為\(\lambda_1\)(最大特徵值),其中\(\lambda _1^2\)既是\({\bf{M}}_{\rm{1}}\)又是\({\bf{M}}_{\rm{2}}\)的特徵根,第一對典型變數的係數\({{\bf{a}}_1}\)和\({{\bf{b}}_1}\)是相應於\({\bf{M}}_{\rm{1}}\)和\({\bf{M}}_{\rm{2}}\)的特徵向量。這樣就把典型相關分析的求解轉換成了求\({\bf{M}}_{\rm{1}}\)和\({\bf{M}}_{\rm{2}}\)的特徵根和特徵向量的問題。
說明:第一對典型變數提取了原始變數\(X\)和\(Y\)之間相關的主要部分,如果這部分不能足以解釋原始變數,可以在剩餘的相關中再求出第二對典型變數和它們的典型相關係數。如此反覆,直到這兩組變數的相關性被提取完畢為止。
3.CCA的物理意義
還是以量化家庭特徵與家庭消費之間的關係為例子,假設\({x_1}\)表示每年去餐館就餐的頻率,\({x_2}\)表示每年外出看電影頻率,\({y_1}\)表示戶主的年齡,\({y_2}\)表示家庭的年收入,\({y_3}\)表示戶主受教育程度。如果計算出第一典型相關係數為0.687948,第二典型相關係數為0.186865。第一典型變數和第二典型變數代入方程如下所示:
(1)第一對典型變數
- \({u_1}\)量化的是家庭消費特徵,它與\({x_1}\)和\({x_2}\)的相關係數分別為0.9866和0.8872,這2個值都是比較高的。
- \({v_1}\)量化的是家庭特徵,它與\({y_2}\)的相關係數為0.9822,其它的相關係數較小,因此\({v_1}\)主要代表的就是家庭收入。
- \({u_1}\)和\({v_1}\)的相關係數為0.687948,說明一個家庭的消費和家庭的收入關係密切。
(2)第二對典型變數
- \({u_2}\)和\({x_2}\)的相關係數為0.4614,可見\({u_2}\)主要代表的是每年外出看電影頻率。
- \({v_2}\)和\({y_1}\)的相關係數為0.8464,可見\({v_2}\)主要代表的是家庭成員的年齡特徵。
- \({u_2}\)和\({v_2}\)的相關係數為0.186865,說明一個家庭每年外出看電影頻率和家庭成員的年齡特徵關係密切。
三.CCA程式碼例子
1.SPSS28實現
(1)變數檢視和資料檢視


(2)分析->相關->典型相關分析
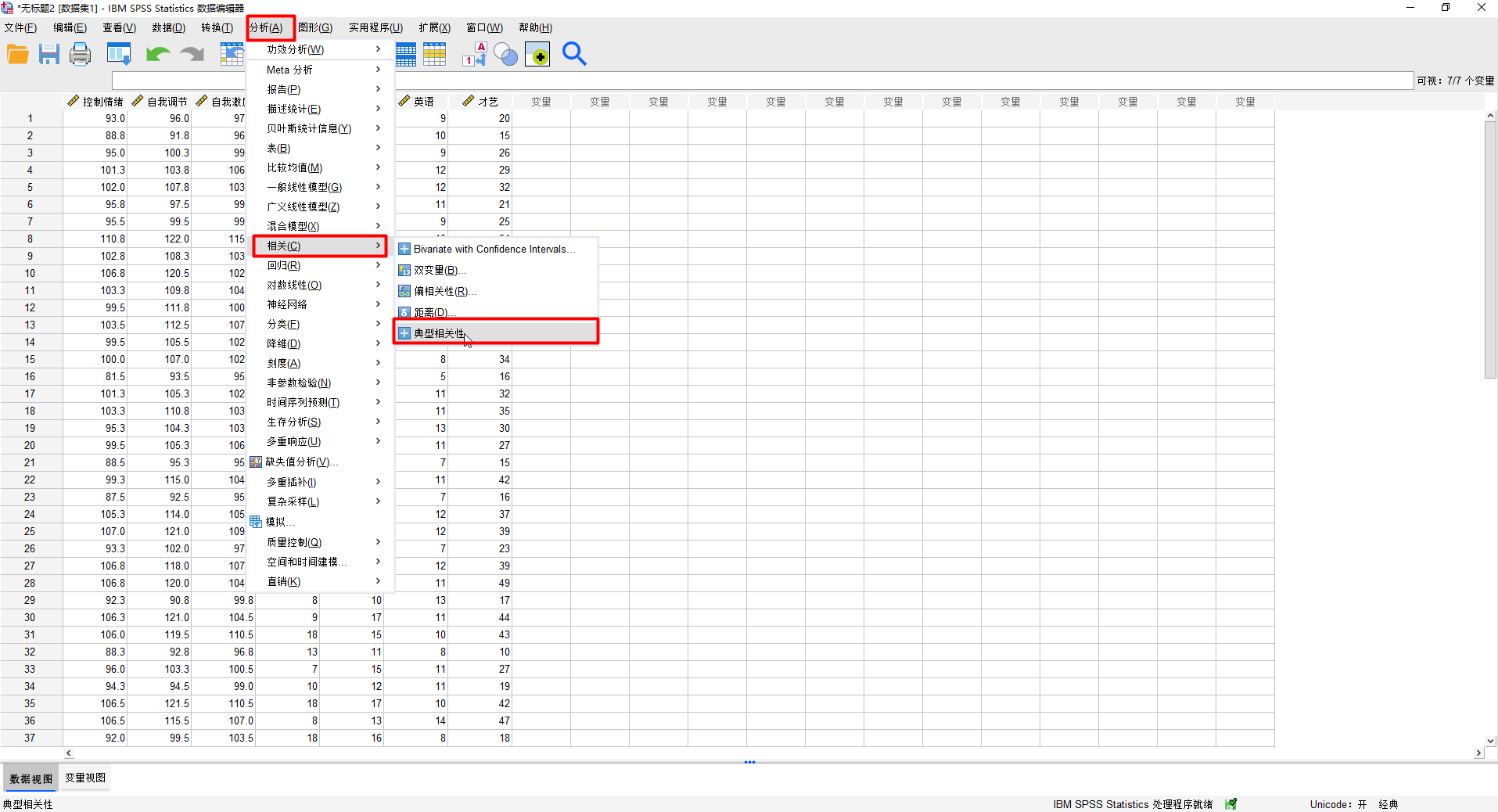
將控制情緒、自我調節、自我激勵作為集合1,將語文、數學、英語和才藝作為集合2:

(3)生成結果

2.R程式設計實現
(1)安裝R包
作業系統使用的Windows10,版本號為20H2,R語言版本使用64位元的R-3.6.3。期初在安裝R包的時候總是報錯,經過查詢資料,需要將Packages頁面中的第2和3個核取方塊去掉,重啟RStudio即可:
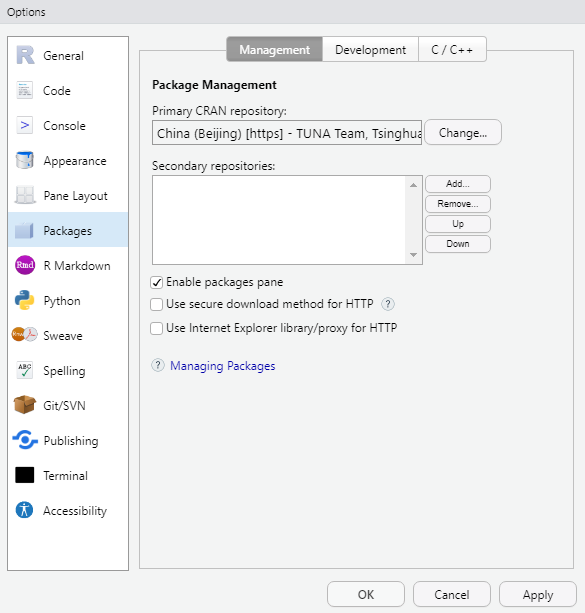
依次安裝openxlsx、CCA和CCP包:
install.packages("openxlsx", dependencies=TRUE)
install.packages("CCA", dependencies=TRUE)
install.packages("CCP", dependencies=TRUE)
(2)R程式碼實現
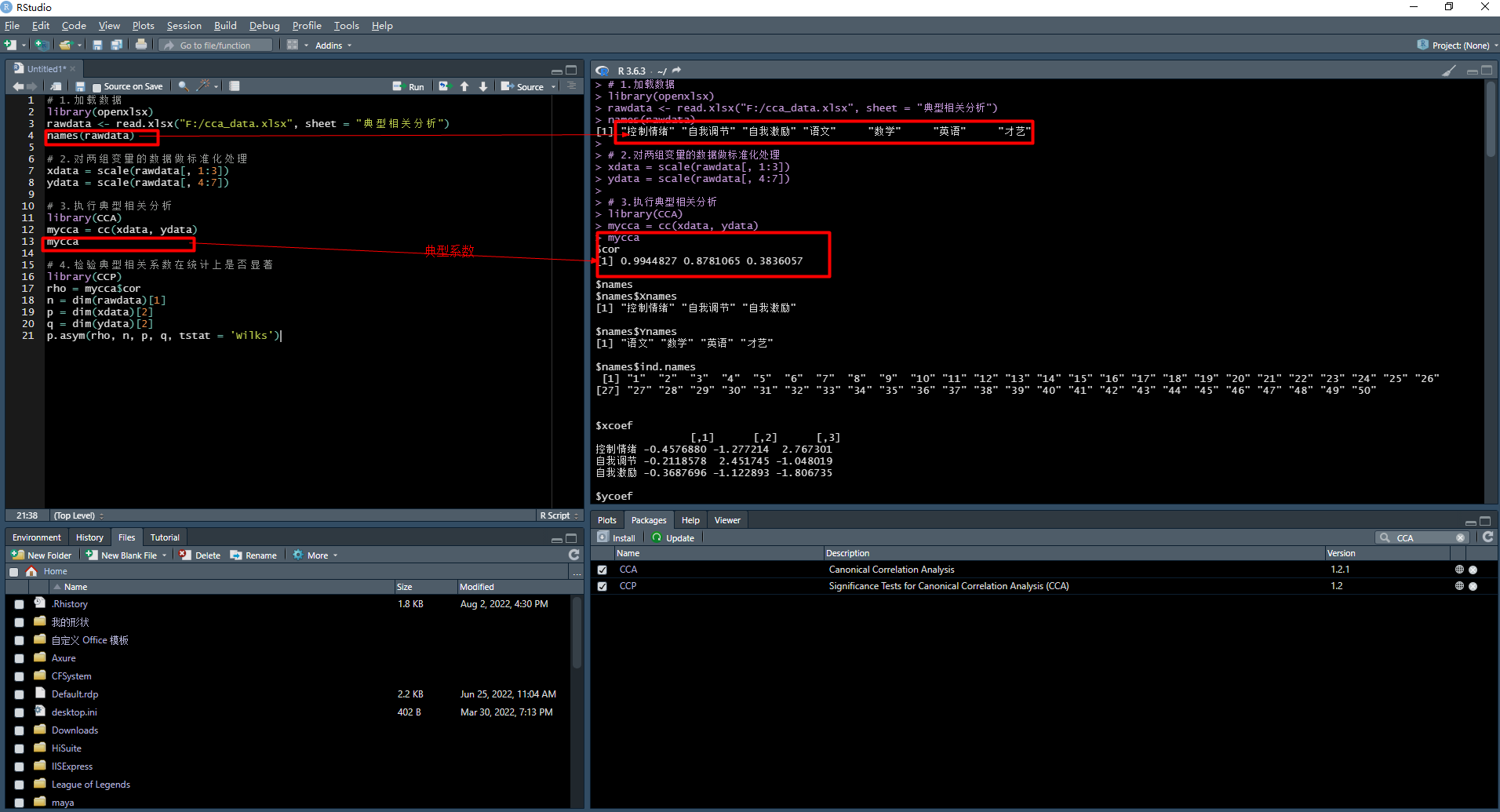
# 1.載入資料
library(openxlsx)
rawdata <- read.xlsx("F:/cca_data.xlsx", sheet = "典型相關分析")
names(rawdata)
# 2.對兩組變數的資料做標準化處理
xdata = scale(rawdata[, 1:3])
ydata = scale(rawdata[, 4:7])
# 3.執行典型相關分析
library(CCA)
mycca = cc(xdata, ydata)
mycca
# 4.檢驗典型相關係數在統計上是否顯著
library(CCP)
rho = mycca$cor
n = dim(rawdata)[1]
p = dim(xdata)[2]
q = dim(ydata)[2]
p.asym(rho, n, p, q, tstat = 'Wilks')
(3)輸出結果
> # 1.載入資料
> library(openxlsx)
> rawdata <- read.xlsx("F:/cca_data.xlsx", sheet = "典型相關分析")
> names(rawdata)
[1] "控制情緒" "自我調節" "自我激勵" "語文" "數學" "英語" "才藝"
>
> # 2.對兩組變數的資料做標準化處理
> xdata = scale(rawdata[, 1:3])
> ydata = scale(rawdata[, 4:7])
>
> # 3.執行典型相關分析
> library(CCA)
> mycca = cc(xdata, ydata)
> mycca
$cor
[1] 0.9944827 0.8781065 0.3836057
$names
$names$Xnames
[1] "控制情緒" "自我調節" "自我激勵"
$names$Ynames
[1] "語文" "數學" "英語" "才藝"
$names$ind.names
[1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22" "23" "24" "25" "26"
[27] "27" "28" "29" "30" "31" "32" "33" "34" "35" "36" "37" "38" "39" "40" "41" "42" "43" "44" "45" "46" "47" "48" "49" "50"
$xcoef
[,1] [,2] [,3]
控制情緒 -0.4576880 -1.277214 2.767301
自我調節 -0.2118578 2.451745 -1.048019
自我激勵 -0.3687696 -1.122893 -1.806735
$ycoef
[,1] [,2] [,3]
語文 -0.2755155 -0.7599743 -0.9739351
數學 -0.1040424 0.6822849 0.4802843
英語 -0.1916330 -1.0607433 0.5995720
才藝 -0.6620838 0.7198947 -0.1194195
$scores
$scores$xscores
[,1] [,2] [,3]
1 0.97838292 -0.362539552 0.81938141
2 1.40651588 -0.410239408 0.05351720
......
49 -0.68982939 -1.133476875 0.34804581
50 -0.86681530 1.107521445 0.63269334
$scores$yscores
[,1] [,2] [,3]
1 0.97479103 0.09430244 -0.08851950
2 1.40034960 -0.76140727 0.45769014
......
49 -0.64792179 -1.26188686 -0.66195176
50 -0.73030445 0.62990478 0.08452069
$scores$corr.X.xscores
[,1] [,2] [,3]
控制情緒 -0.9798776 0.0006477883 0.199598477
自我調節 -0.9464085 0.3228847489 -0.007504408
自我激勵 -0.9518620 -0.1863009724 -0.243414776
$scores$corr.Y.xscores
[,1] [,2] [,3]
語文 -0.6348095 -0.1894059 -0.24988439
數學 -0.7171837 0.2086069 0.02598458
英語 -0.6436782 -0.4402237 0.22027544
才藝 -0.9388771 0.1734549 0.03614570
$scores$corr.X.yscores
[,1] [,2] [,3]
控制情緒 -0.9744713 0.0005688272 0.076567107
自我調節 -0.9411869 0.2835272081 -0.002878734
自我激勵 -0.9466102 -0.1635921013 -0.093375287
$scores$corr.Y.yscores
[,1] [,2] [,3]
語文 -0.6383313 -0.2156981 -0.65140953
數學 -0.7211626 0.2375644 0.06773775
英語 -0.6472493 -0.5013329 0.57422365
才藝 -0.9440859 0.1975329 0.09422619
> # 4.檢驗典型相關係數在統計上是否顯著
> library(CCP)
> rho = mycca$cor
> n = dim(rawdata)[1]
> p = dim(xdata)[2]
> q = dim(ydata)[2]
> p.asym(rho, n, p, q, tstat = 'Wilks')
Wilks' Lambda, using F-approximation (Rao's F):
stat approx df1 df2 p.value
1 to 3: 0.002148472 87.391525 12 114.0588 0.000000e+00
2 to 3: 0.195241267 18.526265 6 88.0000 8.248957e-14
3 to 3: 0.852846693 3.882233 2 45.0000 2.783536e-02
從結果上來看,無論是SPSS還是R,計算的結果都是完全相同的。
參考文獻:
[1]典型相關分析:https://www.bilibili.com/video/BV1LZ4y1S7Vd
[2]sklearn.cross_decomposition.CCA:https://scikit-learn.org/stable/modules/generated/sklearn.cross_decomposition.CCA.html
[3]協方差矩陣:https://baike.baidu.com/item/協方差矩陣/9822183
[4]典型相關分析(CCA)原理及Python實現:https://developer.aliyun.com/article/839949
[5]CCA典型關聯分析原理與Python案例:https://cloud.tencent.com/developer/article/1652998
[6]典型關聯分析(CCA)原理總結:https://www.cnblogs.com/pinard/p/6288716.html
[7]典型相關分析:https://www.docin.com/p-212673286.html
[8]資料檔案cca_data.xlsx:https://url39.ctfile.com/f/2501739-631515818-1a4a0d?p=2096 (存取密碼: 2096)
[9]SPSS輸出結果檔案:https://url39.ctfile.com/f/2501739-631515819-214c93?p=2096 (存取密碼: 2096)
[10]R程式碼檔案:https://url39.ctfile.com/f/2501739-631515820-50502e?p=2096 (存取密碼: 2096)