千萬級別的表分頁查詢非常慢,怎麼辦?
一、問題復現
在實際的軟體系統開發過程中,隨著使用的使用者群體越來越多,表資料也會隨著時間的推移,單表的資料量會越來越大。
以訂單表為例,假如每天的訂單量在 4 萬左右,那麼一個月的訂單量就是 120 多萬,一年就是 1400 多萬,隨著年數的增加和單日下單量的增加,訂單表的資料量會越來越龐大,訂單資料的查詢不會像最初那樣簡單快速,如果查詢關鍵欄位沒有走索引,會直接影響到使用者體驗,甚至會影響到服務是否能正常執行!
下面我以某個電商系統的客戶表為例,資料庫是 Mysql,資料體量在 100 萬以上,詳細介紹分頁查詢下,不同階段的查詢效率情況(訂單表的情況也是類似的,只不過它的資料體量比客戶表更大)。

下面我們一起來測試一下,每次查詢客戶表時最多返回 100 條資料,不同的起始下,資料庫查詢效能的差異。
- 當起點位置在 0 的時候,僅耗時:18 ms

- 當起點位置在 1000 的時候,僅耗時:23 ms
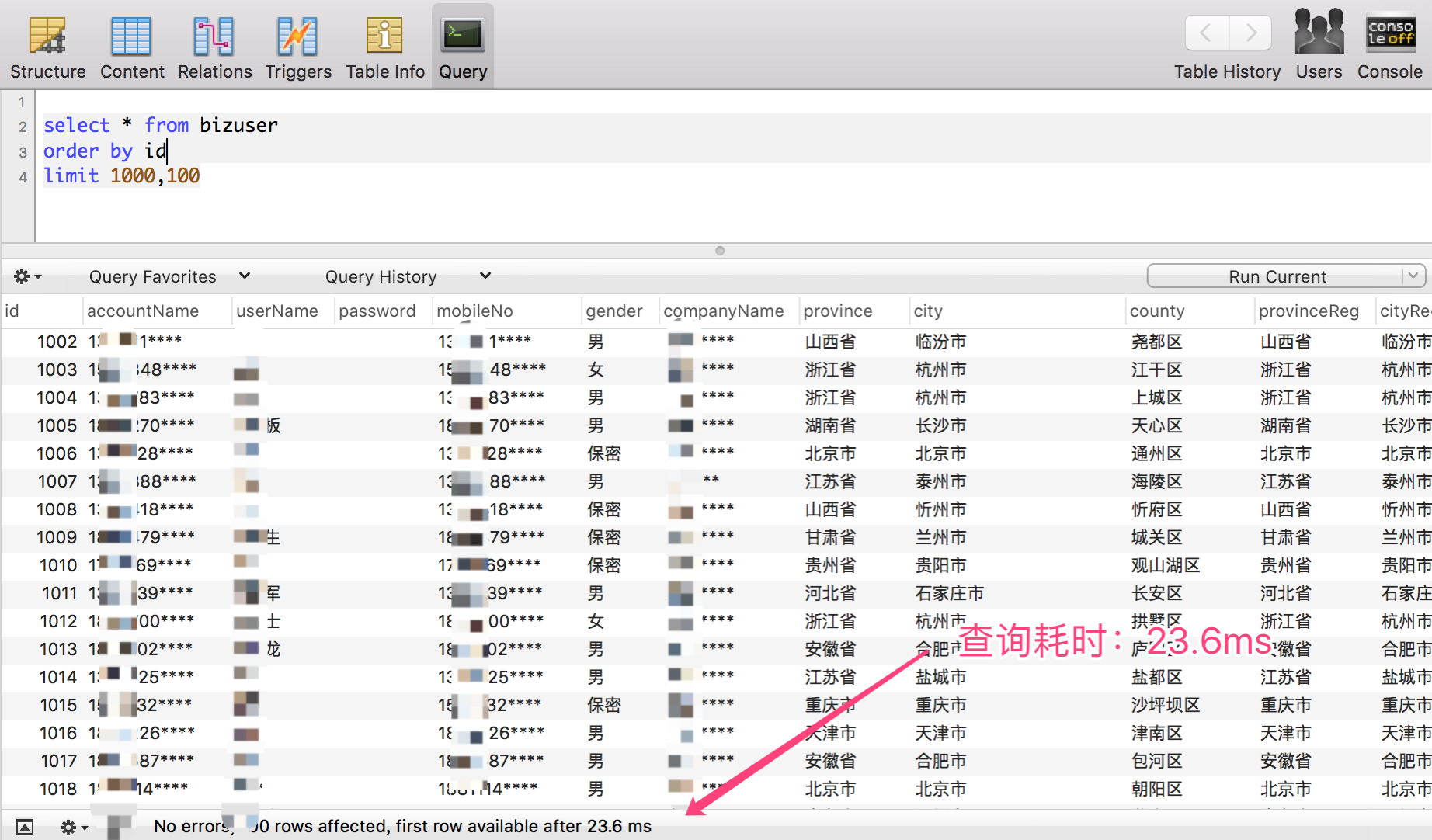
- 當起點位置在 10000 的時候,僅耗時:54 ms
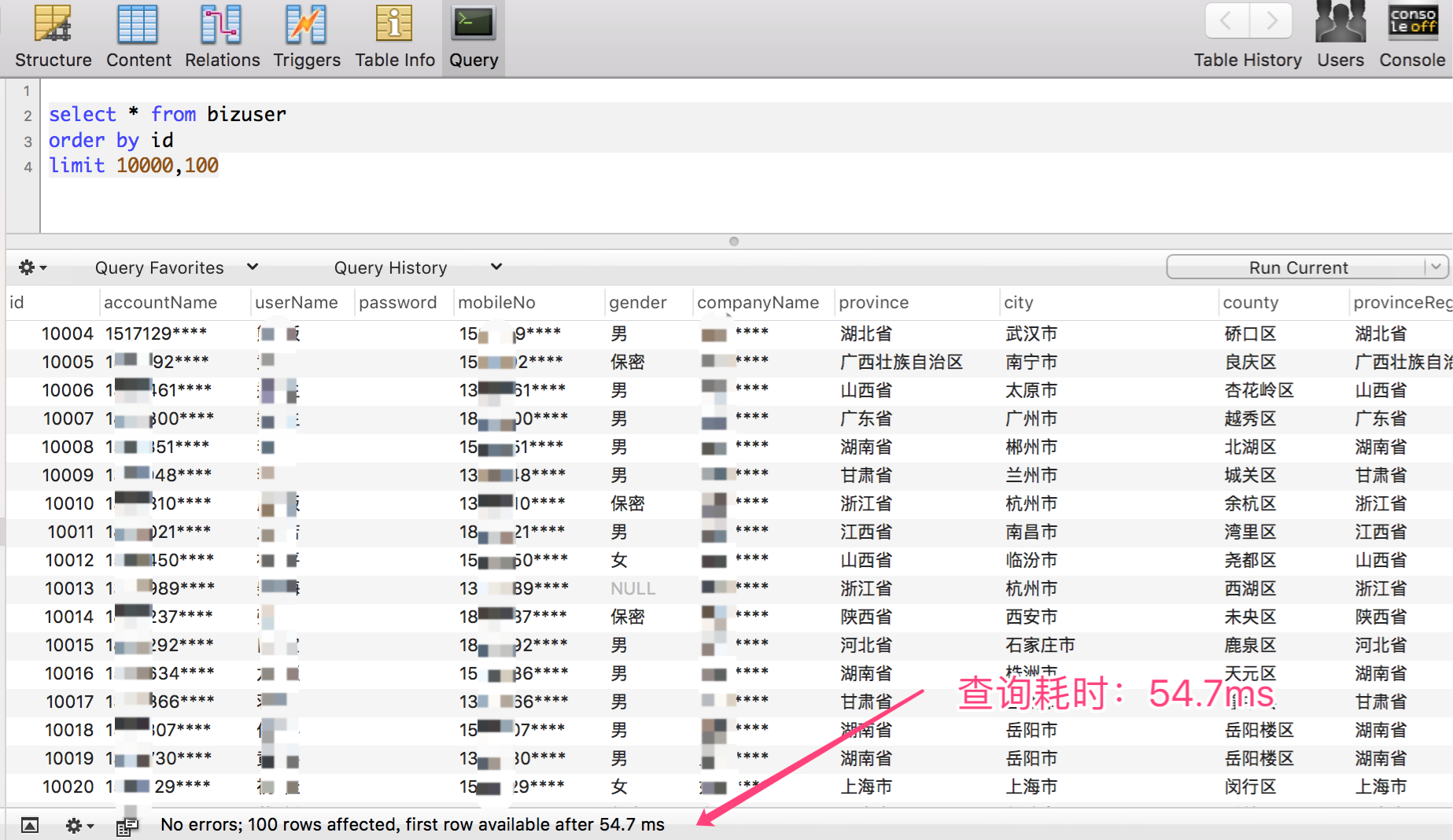
- 當起點位置在 100000 的時候,僅耗時:268 ms
- 當起點位置在 500000 的時候,僅耗時:1.16 s
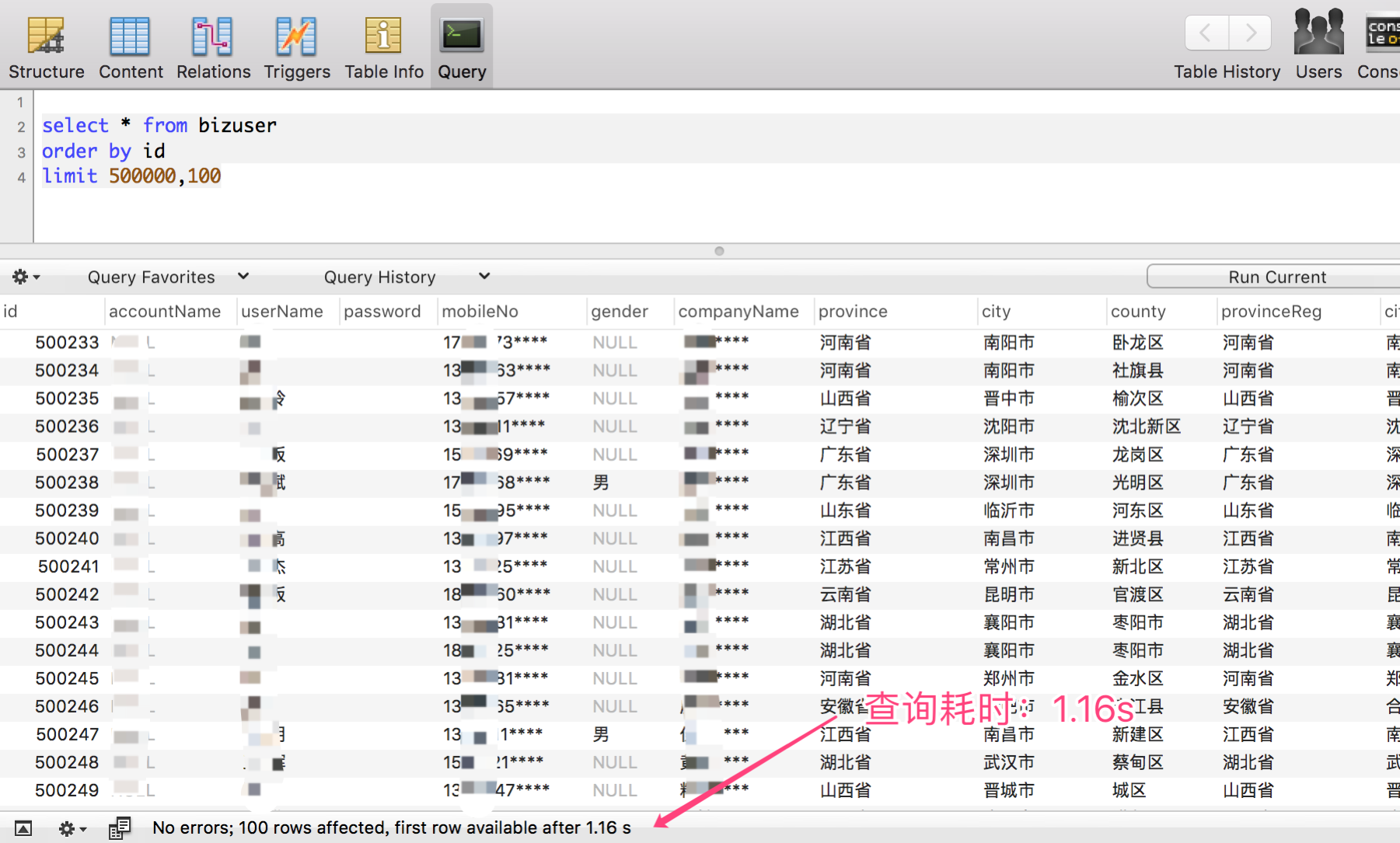
- 當起點位置在 1000000 的時候,僅耗時:2.35 s
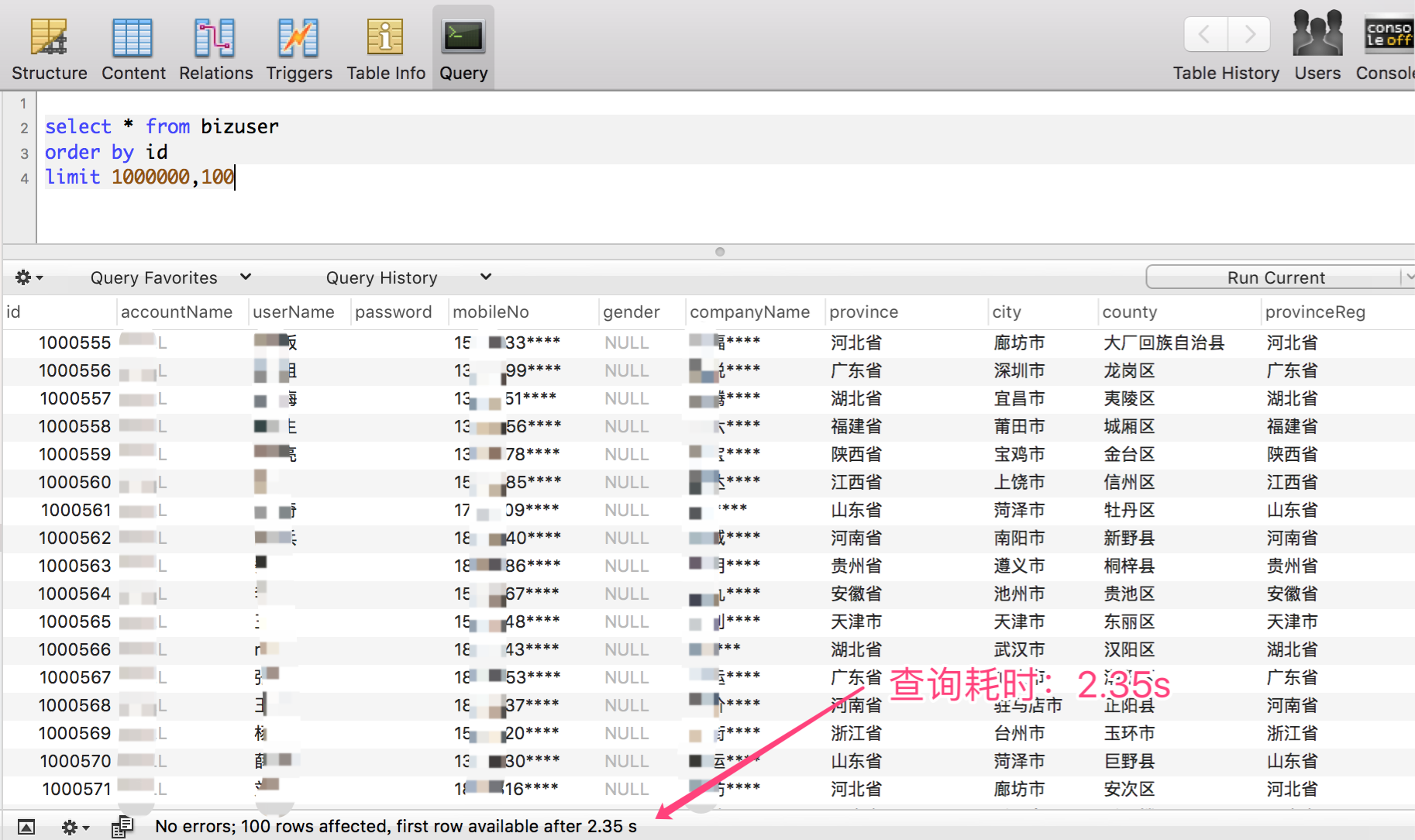
可以非常清晰的看出,隨著起點位置越大,分頁查詢效率成倍的下降,當起點位置在 1000000 以上的時候,對於百萬級資料體量的單表,查詢耗時基本上以秒為單位。
而事實上,一般查詢耗時超過 1 秒的 SQL 都被稱為慢 SQL,有的公司運維組要求的可能更加嚴格,比如小編我所在的公司,如果 SQL 的執行耗時超過 0.2s,也被稱為慢 SQL,必須在限定的時間內儘快優化,不然可能會影響服務的正常執行和使用者體驗。
對於千萬級的單表資料查詢,小編我剛剛也使用了一下分頁查詢,起點位置在 10000000,也截圖給大家看看,查詢耗時結果:39 秒!
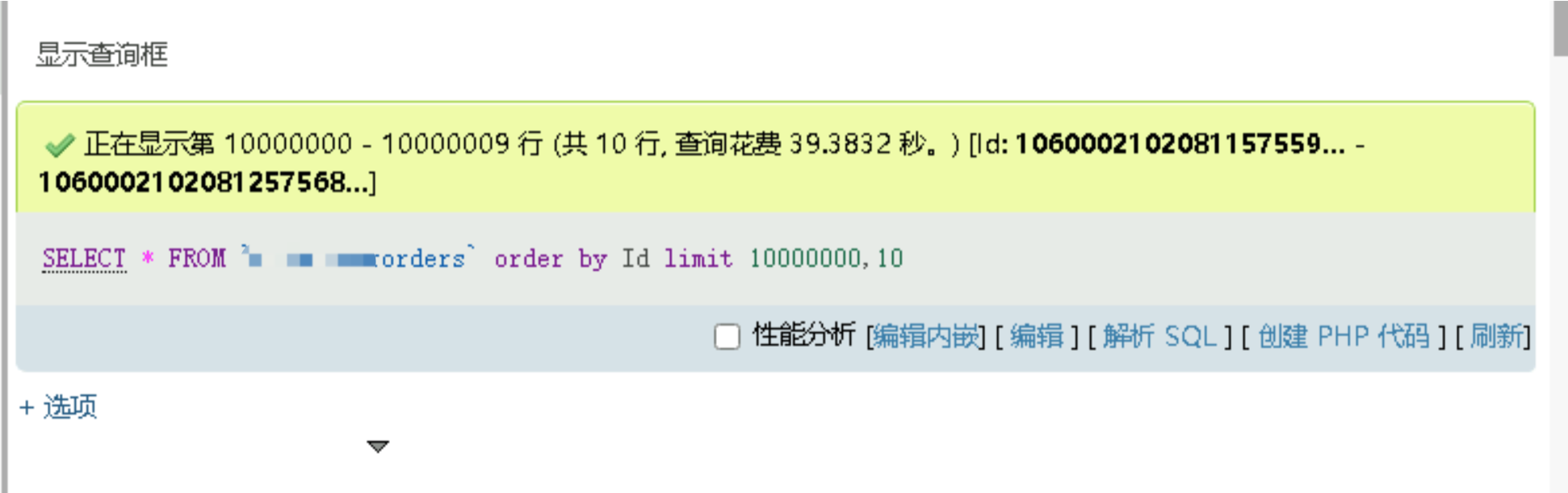
沒有接觸過這麼巨量資料體量的同學,可能多少對這種查詢結果會感到吃驚,事實上,這還只是資料庫層面的耗時,還沒有算後端服務的處理鏈路時間,以及返回給前端的資料渲染時間,以百萬級的單表查詢為例,如果資料庫查詢耗時 1 秒,再經過後端的資料封裝處理,前端的資料渲染處理,以及網路傳輸時間,沒有異常的情況下,差不多在 3~4 秒之間,可能有些同學對這個請求時長數值還不太敏感。
據網際網路軟體使用者體驗報告,當平均請求耗時在1秒之內,使用者體驗是最佳的,此時的軟體也是使用者留存度最高的;2 秒之內,還勉強過的去,使用者能接受;當超過 3 秒,體驗會稍差;超過 5 秒,基本上會解除安裝當前軟體。
有的公司為了提升使用者體驗,會嚴格控制請求時長,當請求時長超過 3 秒,自動放棄請求,從而倒逼技術優化調整 SQL 語句查詢邏輯,甚至調整後端整體架構,比如引入快取中介軟體 redis,搜尋引擎 elasticSearch 等等。
繼續回到我們本文所需要探討的問題,當單表資料量到達百萬級的時候,查詢效率急劇下降,如何優化提升呢?
二、解決方案
下面我們一起來看看具體的解決辦法。
2.1、方案一:查詢的時候,只返回主鍵 ID
我們繼續回到上文給大家介紹的客戶表查詢,將select *改成select id,簡化返回的欄位,我們再來觀察一下查詢耗時。
- 當起點位置在 100000 的時候,僅耗時:73 ms

- 當起點位置在 500000 的時候,僅耗時:274 ms
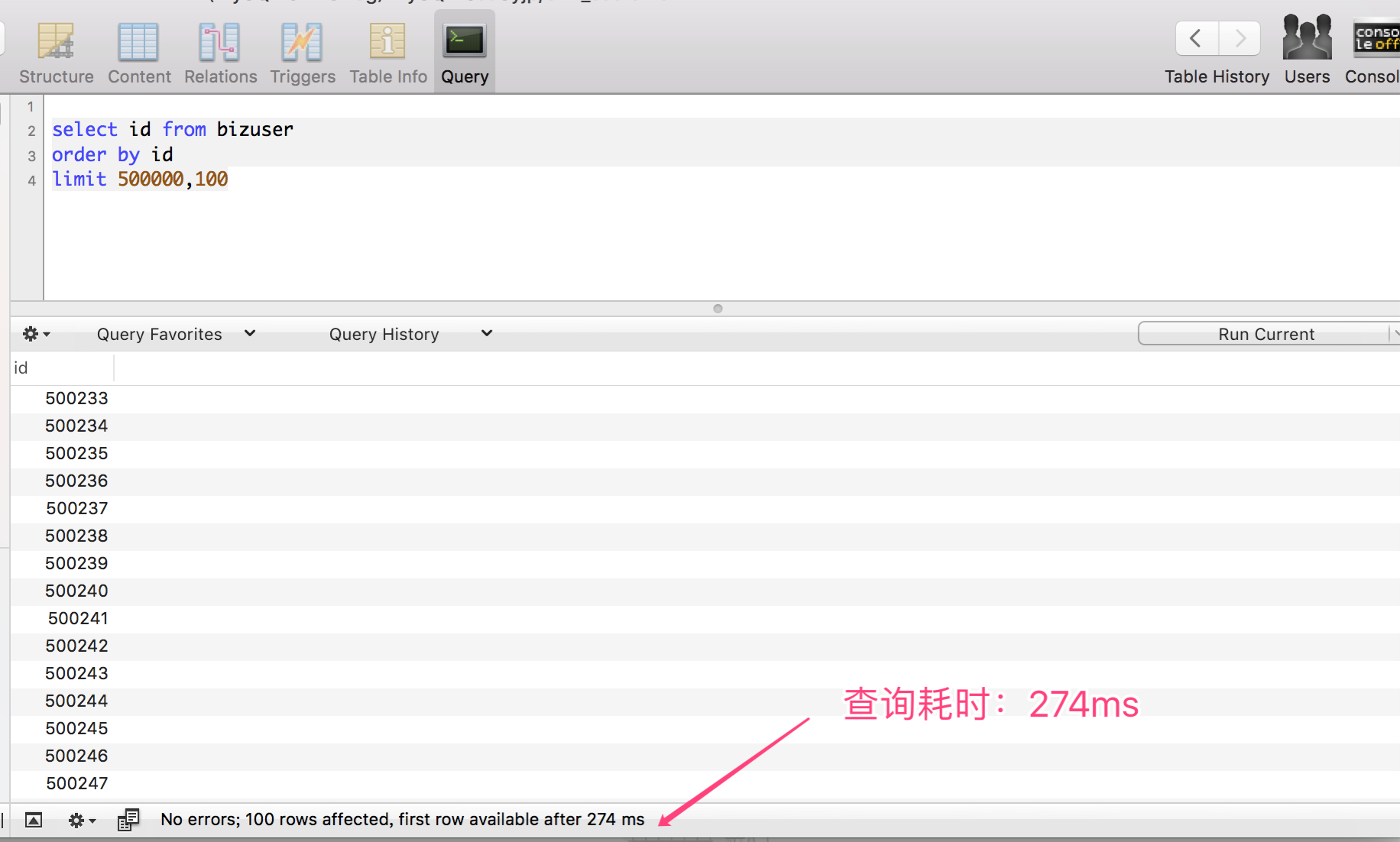
- 當起點位置在 1000000 的時候,僅耗時:471 ms

可以很清晰的看到,通過簡化返回的欄位,可以很顯著的成倍提升查詢效率。
實際的操作思路就是先通過分頁查詢滿足條件的主鍵 ID,然後通過主鍵 ID 查詢部分資料,可以顯著提升查詢效果。
-- 先分頁查詢滿足條件的主鍵ID
select id from bizuser order by id limit 100000,10;
-- 再通過分頁查詢返回的ID,批次查詢資料
select * from bizuser where id in (1,2,3,4,.....);
2.2、方案二:查詢的時候,通過主鍵 ID 過濾
這種方案有一個要求就是主鍵ID,必須是數位型別,實踐的思路就是取上一次查詢結果的 ID 最大值,作為過濾條件,而且排序欄位必須是主鍵 ID,不然分頁排序順序會錯亂。
- 查詢 100000~1000100 區間段的資料,僅耗時:18 ms

- 查詢 500000~5000100 區間段的資料,僅耗時:18 ms
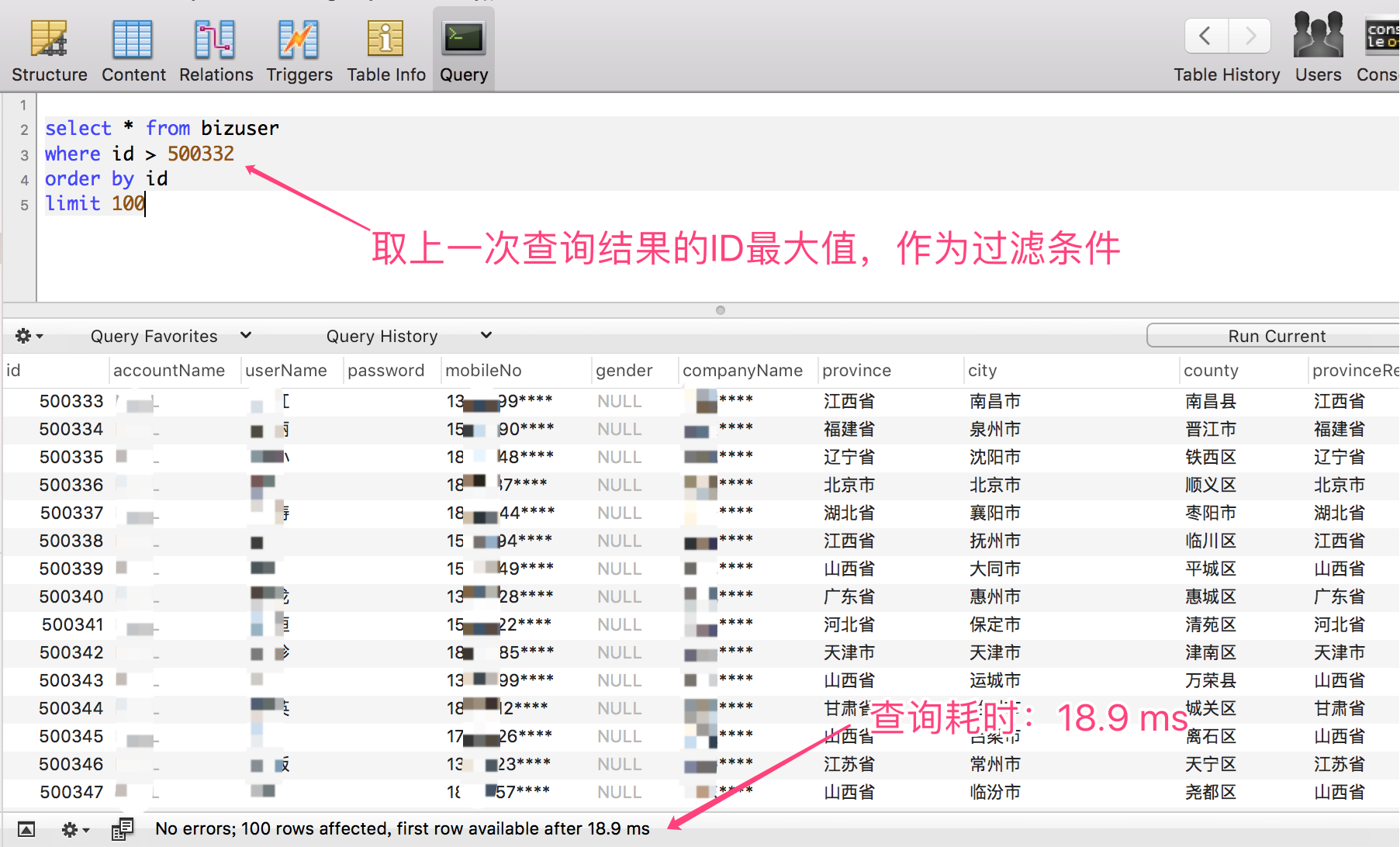
- 查詢 1000000~1000100 區間段的資料,僅耗時:18 ms
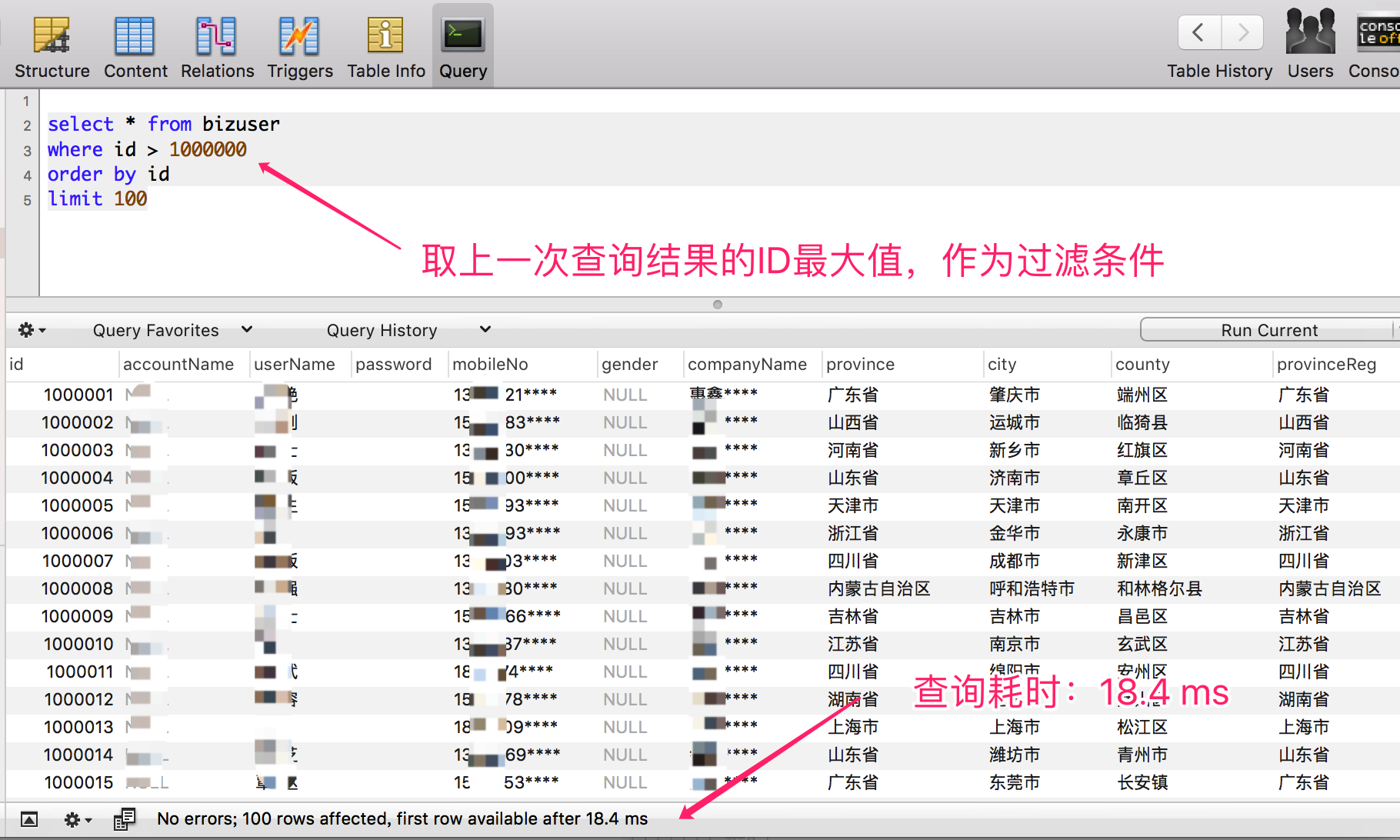
可以很清晰的看到,帶上主鍵 ID 作為過濾條件,查詢效能非常的穩定,基本上在20 ms內可以返回。
這種方案還是非常可行的,如果當前業務對排序要求不多,可以採用這種方案,效能也非常槓!
但是如果當前業務對排序有要求,比如通過客戶最後修改時間、客戶最後下單時間、客戶最後下單金額等欄位來排序,那麼上面介紹的【方案一】,比【方案二】查詢效率更高!
2.3、方案三:採用 elasticSearch 作為搜尋引擎
當資料量越來越大的時候,尤其是出現分庫分表的資料庫,以上通過主鍵 ID 進行過濾查詢,效果可能會不盡人意,例如訂單資料的查詢,這個時候比較好的解決辦法就是將訂單資料儲存到 elasticSearch 中,通過 elasticSearch 實現快速分頁和搜尋,效果提升也是非常明顯。
關於 elasticSearch 的玩法,之前有給大家介紹過具體的實踐,這裡不在過多撰書。
三、小結
不知道大家有沒有發現,上文中介紹的表主鍵 ID 都是數值型別的,之所以採用數位型別作為主鍵,是因為數位型別的欄位能很好的進行排序。
但如果當前表的主鍵 ID 是字串型別,比如 uuid 這種,就沒辦法實現這種排序特性,而且搜尋效能也非常差,因此不建議大家採用 uuid 作為主鍵ID,具體的數值型別主鍵 ID 的生成方案有很多種,比如自增、雪花演演算法等等,都能很好的滿足我們的需求。
本文主要圍繞大表分頁查詢效能問題,以及對應的解決方案做了簡單的介紹,如果有異議的地方,歡迎網友留言,一起討論學習!
如果想獲取更多的巨量資料庫相關的資料,可以關注下方二維條碼,後臺回覆 【cccc】有我準備的一執行緒序必備計算機書籍、大廠面試資料和免費電子書,希望可以幫助大家提升技術和能力。
作者:程式設計師志哥
出處:www.pzblog.cn
資源:微信搜【Java極客技術】關注我,回覆 【cccc】有我準備的一執行緒序必備計算機書籍、大廠面試資料和免費電子書。 希望可以幫助大家提升技術和能力。