用位運算為你的程式加速

前言
最近在持續優化之前編寫的 JSON 解析庫 xjson,主要是兩個方面的優化。
第一個是支援將一個 JSONObject 物件輸出為 JSON 字串。
這點在上個版本中只是利用自帶的 Print 函數列印資料:
func TestJson4(t *testing.T) {
str := `{"people":{"name":{"first":"bob"}}}`
first := xjson.Get(str, "people.name.first")
assert.Equal(t, first.String(), "bob")
get := xjson.Get(str, "people")
fmt.Println(get.String())
//assert.Equal(t, get.String(),`{"name":{"first":"bob"}}`)
}
Output:
map[name:map[first:bob]]
本次優化之後便能直接輸出 JSON 字串了:
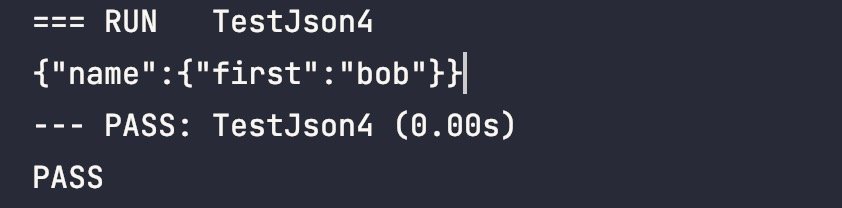
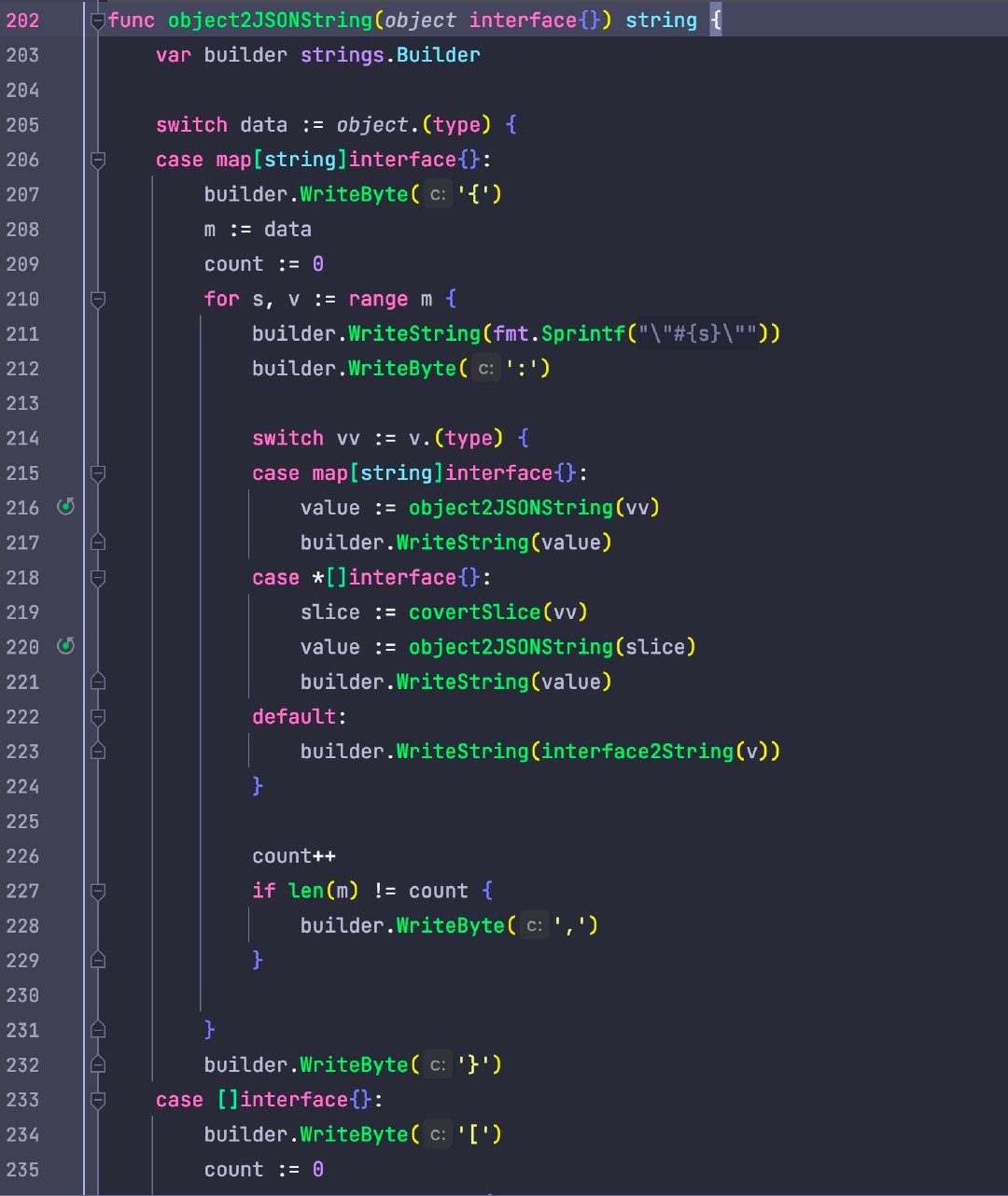
實現過程也很簡單,只需要遞迴遍歷 object 中的資料,然後拼接字串即可,核心程式碼如下:
func (r Result) String() string {
switch r.Token {
case String:
return fmt.Sprint(r.object)
case Bool:
return fmt.Sprint(r.object)
case Number:
i, _ := strconv.Atoi(fmt.Sprint(r.object))
return fmt.Sprintf("%d", i)
case Float:
i, _ := strconv.ParseFloat(fmt.Sprint(r.object), 64)
return fmt.Sprintf("%f", i)
case JSONObject:
return object2JSONString(r.object)
case ArrayObject:
return object2JSONString(r.Array())
default:
return ""
}
}
用位運算優化
第二個優化主要是提高了效能,查詢一個複雜 JSON 資料的時候效能提高了大約 ⏫16%.
# 優化前
BenchmarkDecode-12 90013 66905 ns/op 42512 B/op 1446 allocs/op
# 優化後
BenchmarkDecode-12 104746 59766 ns/op 37749 B/op 1141 allocs/op
這裡擷取了一些重點改動的部分:

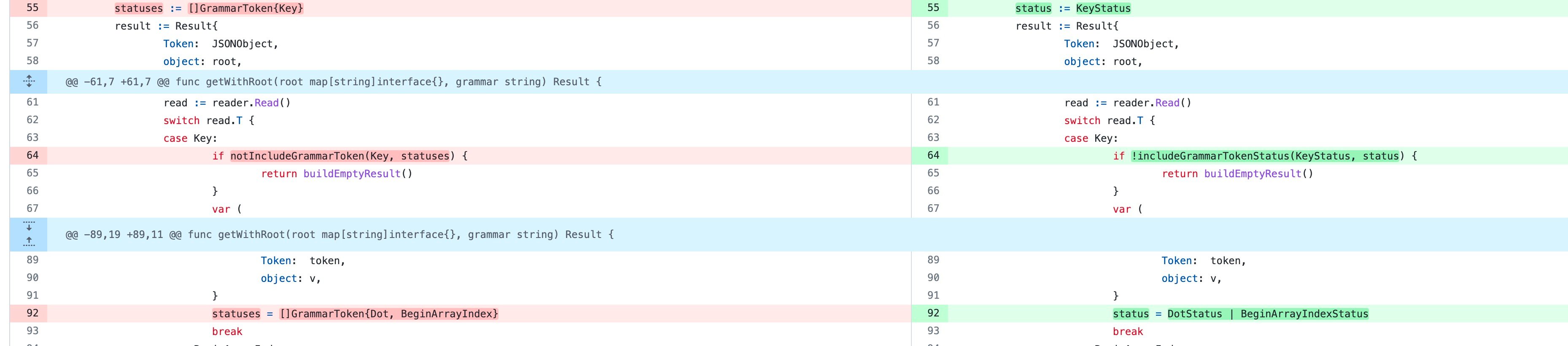
在 JSON 解析過程中會有一個有限狀態機狀態遷移的過程,而遷移的時候可能會出現多個狀態。
比如當前解析到的 token 值為 {,那它接下來的 token 可能會為 ObjectKey:"name",也可能會是 BeginObject:{,當然也可能會是 EndObject:},
所以在優化之前我是將狀態全部存放在一個集合中的,在解析過程中如果發現狀態不滿足預期的列表時則會丟擲語法異常的錯誤。

所以優化之前是遍歷這個集合來進行判斷的,這樣的時間複雜度為 O(N),但當我們換成位運算就不一樣了,時間複雜度直接就變為O(1)了,同時還節省了一個切片的儲存空間。
我們簡單來分析下這個位運算為什麼會達到判斷一個資料是否在一個集合中同樣的效果。
首先以這兩個狀態為例:
StatusObjectKey status = 0x0002
StatusColon status = 0x0004
他們分別對應的二進位制資料為:
StatusObjectKey status = 0x0002 //0010
StatusColon status = 0x0004 //0100
當我們對這兩個資料求 | 運算得到的資料是 0110:
A:0010
B:0100
C:0110
這時候如何我們如果用這兩個原始資料與 C:0110 做 & 運算時就會還原為剛才的兩個資料。
// input:
A:0010
C:0110
// output:
A:0010
----------
// input:
B:0100
C:0110
// output:
B:0100
但我們換一個 D 與 C 求 & 時:
D: 1000 // 0x0008 對應的二進位制為 1000
C: 0110
D':0000
將會得到一個 0 值,只要得出的資料大於 0 我們就能判斷一個資料是否在給定的集合中了。
當然這裡有一個前提條件就是,我們輸入的資料高位永遠都是是 1 才行,也就是2的冪。
同樣的優化在解析查詢語法時也有使用:
其他奇淫巧技
當然位運算還有一些其他技巧,比如判斷奇偶數:
// 偶數
a & 1 == 0
// 奇數
a & 1 == 1
乘法和除法,右移1一位是除以2,左移一位是乘以2.
x := 2
fmt.Println(x>>1) //1
fmt.Println(x<<1) //4
總結
位運算在帶來程式效能提升的同時也降低程式碼可讀性,所以我們得按需選擇是否使用;
再一些底層庫、框架程式碼對效能有極致追求的場景推薦使用,但在業務程式碼中對資料做加減乘除就沒必要用位運算了,只會讓後續的維護者一臉懵逼。
作者: crossoverJie

歡迎關注博主公眾號與我交流。
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出, 如有問題, 可郵件(crossoverJie#gmail.com)諮詢。