物無定味適口者珍,Python3並行場景(CPU密集/IO密集)任務的並行方式的場景抉擇(多執行緒threading/多程序multiprocessing/協程asyncio)
原文轉載自「劉悅的技術部落格」https://v3u.cn/a_id_221
一般情況下,大家對Python原生的並行/並行工作方式:程序、執行緒和協程的關係與區別都能講清楚。甚至具體的物件名稱、內建方法都可以如數家珍,這顯然是極好的,但我們其實都忽略了一個問題,就是具體應用場景,三者的使用目的是一樣的,話句話說,使用結果是一樣的,都可以提高程式執行的效率,但到底那種場景用那種方式更好一點?
這就好比,目前主流的汽車發動機變速箱無外乎三種:雙離合、CVT以及傳統AT。主機廠把它們搭載到不同的發動機和車型上,它們都是變速箱,都可以將發動機產生的動力作用到車輪上,但不同使用場景下到底該選擇那種變速箱?這顯然也是一個問題。
所謂「無場景,不功能」,本次我們來討論一下,具體的並行程式設計場景有哪些,並且對應到具體場景,應該怎麼選擇並行手段和方式。
什麼是並行和並行?
在討論場景之前,我們需要將多工執行的方式進行一下分類,那就是並行方式和並行方式。教科書上告訴我們:並行是指兩個或者多個事件在同一時刻發生;而並行是指兩個或多個事件在同一時間間隔內發生。 在多道程式環境下,並行性是指在一段時間內宏觀上有多個程式在同時執行,但在單處理機系統中,每一時刻卻僅能有一道程式執行,故微觀上這些程式只能是分時地交替執行。
好像有那麼一點抽象,好吧,讓我們務實一點,由於GIL全域性直譯器鎖的存在,在Python程式設計領域,我們可以簡單粗暴地將並行和並行用程式通過能否使用多核CPU來區分,能使用多核CPU就是並行,不能使用多核CPU,只能單核處理的,就是並行。就這麼簡單,是的,Python的GIL全域性直譯器鎖幫我們把問題簡化了, 這是Python的大幸?還是不幸?
Python中並行任務實現方式包含:多執行緒threading和協程asyncio,它們的共同點都是交替執行,而區別是多執行緒threading是搶佔式的,而協程asyncio是共同作業式的,原理也很簡單,只有一顆CPU可以用,而一顆CPU一次只能做一件事,所以只能靠不停地切換才能完成並行任務。
Python中並行任務的實現方式是多程序multiprocessing,通過multiprocessing庫,Python可以在程式主程序中建立新的子程序。這裡的一個程序可以被認為是一個幾乎完全不同的程式,儘管從技術上講,它們通常被定義為資源集合,其中資源包括記憶體、檔案控制程式碼等。換一種說法是,每個子程序都擁有自己的Python直譯器,因此,Python中的並行任務可以使用一顆以上的CPU,每一顆CPU都可以跑一個程序,是真正的同時執行,而不需要切換,如此Python就可以完成並行任務。
什麼時候使用並行?IO密集型任務
現在我們搞清楚了,Python裡的並行執行方式就是多執行緒threading和協程asyncio,那麼什麼場景下使用它們?
一般情況下,任務場景,或者說的更準確一些,任務型別,無非兩種:CPU密集型任務和IO密集型任務。
什麼是IO密集型任務?IO就是Input-Output的縮寫,說白了就是程式的輸入和輸出,想一想確實就是這樣,您的電腦,它不就是這兩種功能嗎?用鍵盤、麥克風、攝像頭輸入資料,然後再用螢幕和音箱進行輸出操作。
但輸入和輸出操作要比電腦中的CPU執行速度慢,換句話說,CPU得等著這些比它慢的輸入和輸出操作,說白了就是CPU運算一會,就得等這些IO操作,等IO操作完了,CPU才能繼續運算一會,然後再等著IO操作,如圖所示:

由此可知,並行適合這種IO操作密集和頻繁的工作,因為就算CPU是蘋果最新ARM架構的M2晶片,也沒有用武之地。
另外,如果把IO密集型任務具象化,那就是我們經常操作的:硬碟讀寫(資料庫讀寫)、網路請求、檔案的列印等等。
並行方式的選擇:多執行緒threading還是協程asyncio?
既然涉及硬碟讀寫(資料庫讀寫)、網路請求、檔案列印等任務都算並行任務,那我們就真正地實踐一下,看看不同的並行方式到底能提升多少效率?
一個簡單的小需求,對本站資料進行重複抓取操作,並計算首頁資料文字的行數:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"下載了{len(response.content)}行資料")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下載了 {len(sites)}次,執行了{duration}秒")
在不使用任何並行手段的前提下,程式返回:
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了76347行資料
下載了 50 次資料,執行了8.781155824661255秒
[Finished in 9.6s]
這裡程式的每一步都是同步操作,也就是說當第一次抓取網站首頁時,剩下的49次都在等待。
接著使用多執行緒threading來改造程式:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"下載了{len(response.content)}行資料")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下載了 {len(sites)}次,執行了{duration}秒")
這裡通過with關鍵詞開啟執行緒池上下文管理器,並行8個執行緒進行下載,程式返回:
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76161行資料
下載了76424行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了 50次,執行了7.680492877960205秒
很明顯,效率上有所提升,事實上,每個執行緒其實是在不停「切換」著執行,這就節省了單執行緒每次等待爬取結果的時間:
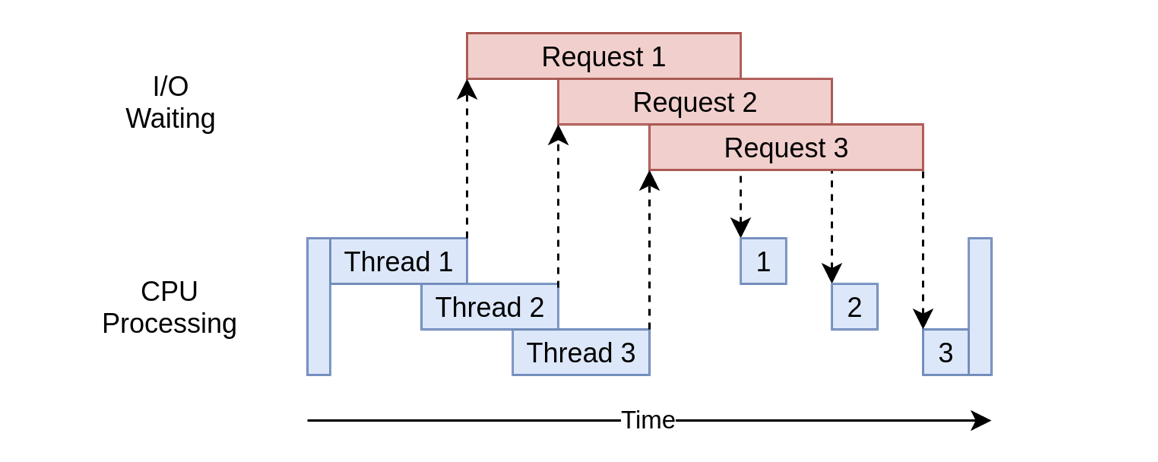
由此帶來了另外一個問題:上下文切換的時間開銷。
讓我們繼續改造,用協程來一試鋒芒,首先安裝非同步web請求庫aiohttp:
pip3 install aiohttp
改寫邏輯:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print(f"下載了{response.content_length}行資料")
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
asyncio.run(download_all_sites(sites))
duration = time.time() - start_time
print(f"下載了 {len(sites)}次,執行了{duration}秒")
程式返回:
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76424行資料
下載了76161行資料
下載了76424行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了76161行資料
下載了 50次,執行了6.893810987472534秒
效率上百尺竿頭更進一步,同樣的使用with關鍵字操作上下文管理器,協程使用asyncio.ensure_future()建立任務列表,該列表還負責啟動它們。建立所有任務後,使用asyncio.gather()來保持對談上下文的範例,直到所有爬取任務完成。和多執行緒threading的區別是,協程並不需要切換上下文,因此每個任務所需的資源和建立時間要少得多,因此建立和執行更多的任務效率更高:
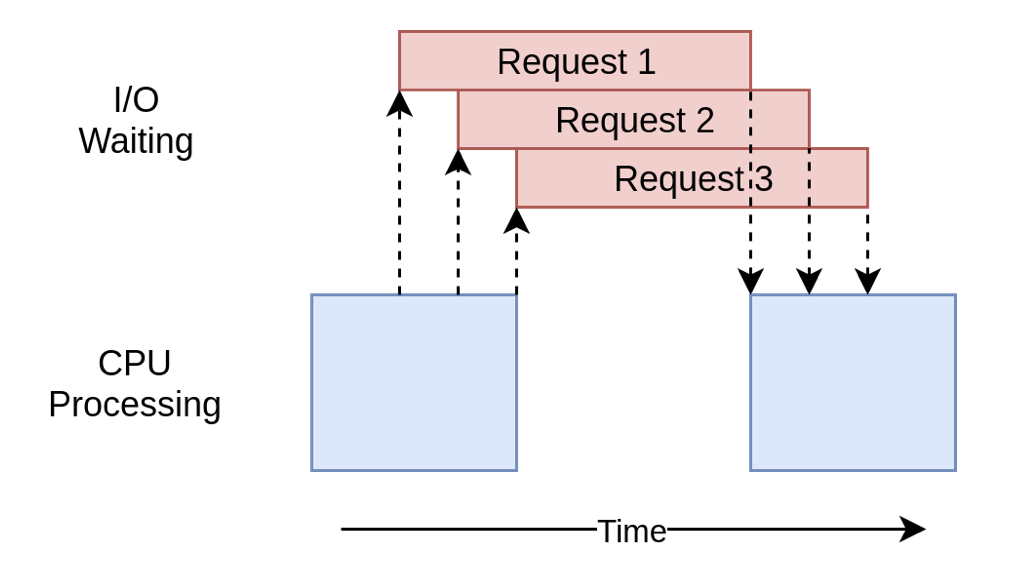
綜上,並行邏輯歸根結底是減少CPU等待的時間,也就是讓CPU少等一會兒,而協程的工作方式顯然讓CPU等待的時間最少。
並行方式:多程序multiprocessing
再來試試多程序multiprocessing,並行能不能幹並行的事?
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"讀了{len(response.content)}行")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下載了 {len(sites)}次,執行了{duration}秒")
這裡我們依然使用上下文管理器開啟程序池,預設程序數匹配當前計算機的CPU核心數,也就是有幾核就開啟幾個程序,程式返回:
讀了76000行
讀了76241行
讀了76044行
讀了75894行
讀了76290行
讀了76312行
讀了76419行
讀了76753行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
讀了76290行
下載了 50次,執行了8.195281982421875秒
雖然比同步程式要快,但無疑的,效率上要低於多執行緒和協程。為什麼?因為多程序不適合IO密集型任務,雖然可以利用多核資源,但沒有任何意義:
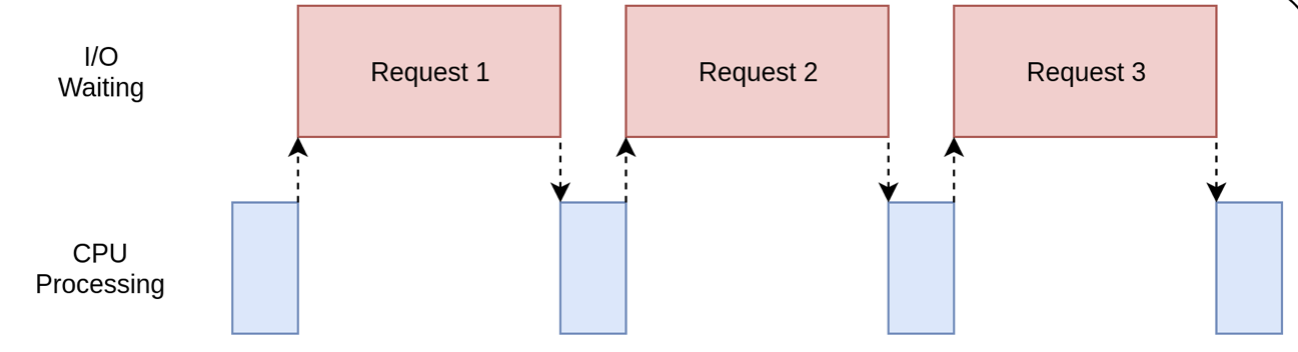
無論開多少程序,CPU都沒有用武之地,多數情況下CPU都在等待IO操作,也就是說,多核反而拖累了IO程式的執行。
並行方式的選擇:CPU密集型任務
什麼是CPU密集型任務?這裡我們可以使用逆定理:所有不涉及硬碟讀寫(資料庫讀寫)、網路請求、檔案列印等任務都算CPU密集型任務任務,說白了就是,計算型任務。
以求平方和為例子:
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
同步執行20次,需要花費多少時間?
4.466595888137817秒
再來試試並行方式:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
八核處理器,開八個程序開始跑:
1.1755797863006592秒
不言而喻,並行方式有效提高了計算效率。
最後,既然之前用並行方式執行了IO密集型任務,我們就再來試試用並行的方式執行CPU密集型任務:
import concurrent.futures
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
executor.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
單程序開8個執行緒,走起:
4.452666759490967秒
如何?和並行方式執行IO密集型任務一樣,可以執行,但是沒有任何意義。為什麼?因為沒有任何IO操作了,CPU不需要等待了,CPU只要全力運算即可,所以你上多執行緒或者協程,無非就是畫蛇添足、多此一舉。
結語
有經驗的汽修師傅會告訴你,想省油就選CVT和雙離合,想質量穩定就選AT,經常高速上激烈駕駛就選雙離合,經常市區內堵車就選CVT;同樣地,作為經驗豐富的後臺研發,你也可以告訴汽修師傅,任何不需要CPU等待的任務就選擇並行(multiprocessing)的處理方式,而需要CPU等待時間過長的任務,選擇並行(threading/asyncio)。反過來,我就想用CVT在高速上飆車,用雙離合在市區堵車,行不行?行,但沒有意義,或者說的更準確一些,沒有任何額外的收益;而用並行方式執行CPU密集型任務,用並行方式執行IO密集型任務行不行?也行,但依然沒有任何額外的收益, 無他,唯物無定味,適口者珍矣。
原文轉載自「劉悅的技術部落格」 https://v3u.cn/a_id_221