萬字長文:從計算機本源深入探尋volatile和Java記憶體模型
萬字長文:從計算機本源深入探尋volatile和Java記憶體模型
前言
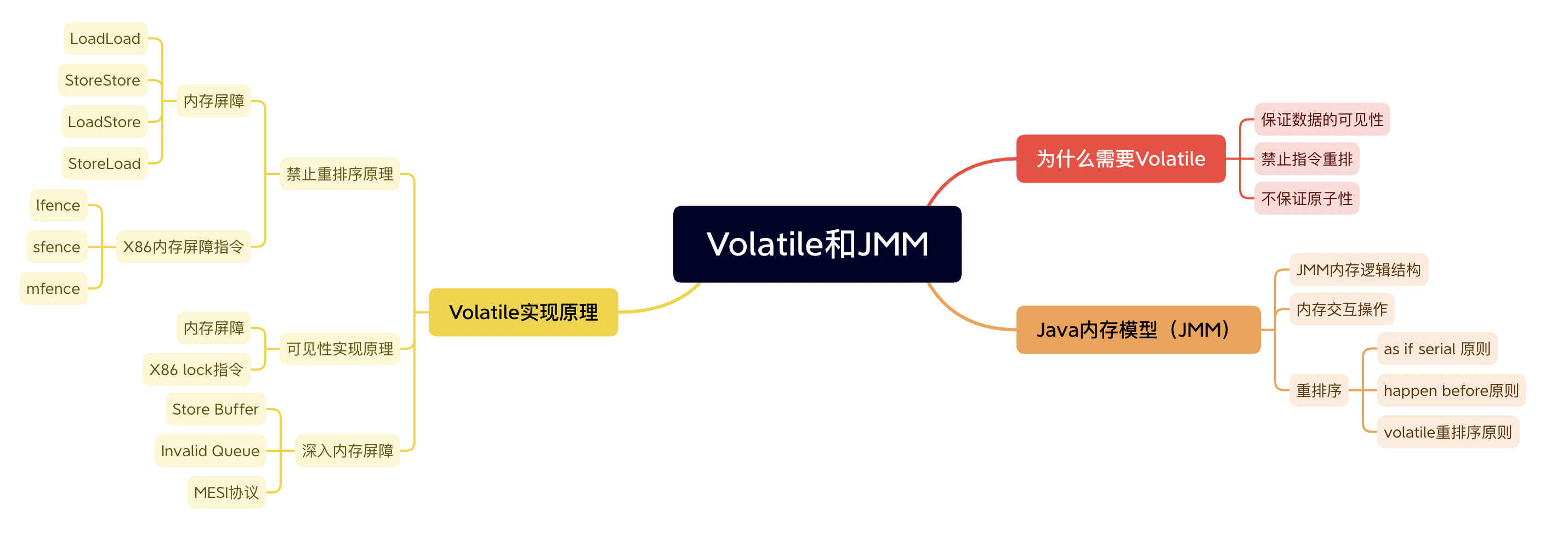
在本篇文章當中,主要給大家深入介紹Volatile關鍵字和Java記憶體模型。在文章當中首先先介紹volatile的作用和Java記憶體模型,然後層層遞進介紹實現這些的具體原理、JVM底層是如何實現volatile的和JVM實現的組合程式碼以及CPU內部結構,深入剖析各種計算機系統底層原理。本篇文章超級幹,請大家坐穩扶好,發車了!!!本文的大致框架如下圖所示:
為什麼我們需要volatile?
保證資料的可見性
假如現在有兩個執行緒分別執行不同的程式碼,但是他們有同一個共用變數flag,其中執行緒updater會執行的程式碼是將flag從false修改成true,而另外一個執行緒reader會進行while迴圈,當flag為true的時候跳出迴圈,程式碼如下:
import java.util.concurrent.TimeUnit;
class Resource {
public boolean flag;
public void update() {
flag = true;
}
}
public class Visibility {
public static void main(String[] args) throws InterruptedException {
Resource resource = new Resource();
Thread thread = new Thread(() -> {
System.out.println(resource.flag);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.update();
}, "updater");
new Thread(() -> {
System.out.println(resource.flag);
while (!resource.flag) {
}
System.out.println("迴圈結束");
}, "reader").start();
thread.start();
}
}
執行上面的程式碼你會發現,reader執行緒始終列印不出迴圈結束,也就是說它一直在進行while迴圈,而進行while迴圈的原因就是resouce.flag=false,但是執行緒updater在經過1秒之後會進行更新啊!為什麼reader執行緒還讀取不到呢?
這實際上就是一種可見性的問題,updater執行緒更新資料之後,reader執行緒看不到,在分析這個問題之間我們首先先來了解一下Java記憶體模型的邏輯佈局:
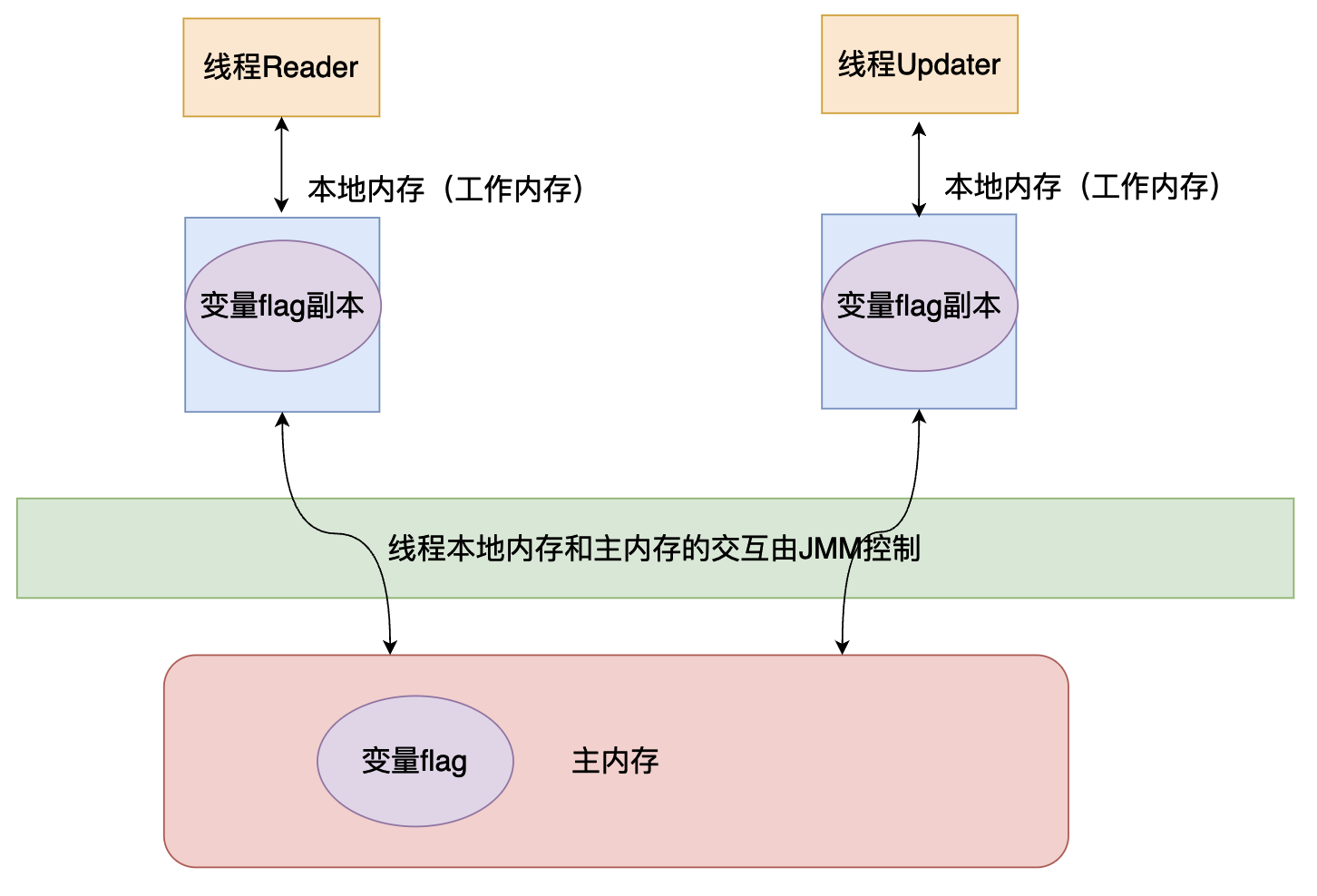
在上面的程式碼執行順序大致如下:
reader執行緒從主記憶體當中拿到flag變數並且儲存到執行緒的本地記憶體當中,進行while迴圈。- 在休眠一秒之後,
Updater執行緒從主記憶體當中拷貝一份flag儲存到本地記憶體當中,然後將flag改成true,將其寫回到主記憶體當中。 - 但是雖然
updater執行緒將flag寫回,但是reader執行緒使用的還是之前從主記憶體當中載入到工作記憶體的flag,也就是說還是false,因此reader執行緒才會一直陷入死迴圈當中。
現在我們稍微修改一下上面的程式碼,先讓reader執行緒休眠一秒,然後再進行while迴圈,讓updater執行緒直接修改。
import java.util.concurrent.TimeUnit;
class Resource {
public boolean flag;
public void update() {
flag = true;
}
}
public class Visibility {
public static void main(String[] args) throws InterruptedException {
Resource resource = new Resource();
Thread thread = new Thread(() -> {
System.out.println(resource.flag);
resource.update();
}, "updater");
new Thread(() -> {
System.out.println(resource.flag);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
while (!resource.flag) {
}
System.out.println("迴圈結束");
}, "reader").start();
thread.start();
}
}
上面的程式碼就不會產生死迴圈了,我們再來分析一下上面的程式碼的執行過程:
reader執行緒先休眠一秒。updater執行緒直接修改flag為true,然後將這個值寫回主記憶體。- 在
updater寫回之後,reader執行緒從主記憶體獲取flag,這個時候的值已經更新了,因此可以跳出while迴圈了,因此上面的程式碼不會出現死迴圈的情況。
像這種多個執行緒共用同一個變數的情況的時候,就會產生資料可見性的問題,如果在我們的程式當中忽略這種問題的話,很容易讓我們的並行程式產生BUG。如果在我們的程式當中需要保持多個執行緒對某一個資料的可見性,即如果一個執行緒修改了共用變數,那麼這個修改的結果要對其他執行緒可見,也就是其他執行緒再次存取這個共用變數的時候,得到的是共用變數最新的值,那麼在Java當中就需要使用關鍵字volatile對變數進行修飾。
現在我們將第一個程式的共用變數flag加上volatile進行修飾:
import java.util.concurrent.TimeUnit;
class Resource {
public volatile boolean flag; // 這裡使用 volatile 進行修飾
public void update() {
flag = true;
}
}
public class Visibility {
public static void main(String[] args) throws InterruptedException {
Resource resource = new Resource();
Thread thread = new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(resource.flag);
resource.update();
}, "updater");
new Thread(() -> {
System.out.println(resource.flag);
while (!resource.flag) {
}
System.out.println("迴圈結束");
}, "reader").start();
thread.start();
}
}
上面的程式碼是可以執行完成的,reader執行緒不會產生死迴圈,因為volatile保證了資料的可見性。即每一個執行緒對volatile修飾的變數的修改,對其他的執行緒是可見的,只要有執行緒修改了值,那麼其他執行緒就可以發現。
禁止指令重排序
指令重排序介紹
首先我們需要了解一下什麼是指令重排序:
int a = 0; int b = 1; int c = 1; a++; b--;比如對於上面的程式碼我們正常的執行流程是:
定義一個變數
a,並且賦值為0。定義一個變數
b,並且賦值為1。定義一個變數
c,並且賦值為1。變數
a進行自增操作。變數
b進行自減操作。而當編譯器去編譯上面的程式時,可能不是安裝上面的流程一步步進行操作的,編譯器可能在編譯優化之後進行如下操作:
定義一個變數
c,並且賦值為1。定義一個變數
a,並且賦值為1。定義一個變數
b,並且賦值為0。從上面來看程式碼的最終結果是沒有發生變化的,但是指令執行的流程和指令的數目是發生變化的,編譯器幫助我們省略了一些操作,這可以讓CPU執行更少的指令,加快程式的執行速度。
上面就是一個比較簡單的在編譯優化當中指令重排和優化的例子。
但是如果我們在語句int c = 1前面加上volatile時,上面的程式碼執行順序就會保證a和b的定義在語句volatile int c = 1;之前,變數a和變數b的操作在語句volatile int c = 1;之後。
int a = 0;
int b = 1;
volatile int c = 1;
a++;
b--;
但是volatile並不限制到底是a先定義還是b先定義,它只保證這兩個變數的定義發生在用volatile修飾的語句之前。
volatile關鍵字會禁止JVM和處理器(CPU)對含有volatile關鍵字修飾的變數的指令進行重排序,但是對於volatile前後沒有依賴關係的指令沒有禁止,也就是說編譯器只需要保證編譯之後的程式碼的順序語意和正常的邏輯一樣,它可以儘可能的對程式碼進行編譯優化和重排序!
Volatile禁止重排序使用——雙重檢查單例模式
在單例模式當中,有一種單例模式的寫法就雙重檢查單例模式,其程式碼如下:
public class DCL {
// 這裡沒有使用 volatile 進行修飾
public static DCL INSTANCE;
public static DCL getInstance() {
// 如果單例還沒有生成
if (null == INSTANCE) {
// 進入同步程式碼塊
synchronized (DCL.class) {
// 因為如果兩個執行緒同時進入上一個 if 語句
// 的話,那麼第一個執行緒會 new 一個物件
// 第二個執行緒也會進入這個程式碼塊,因此需要重新
// 判斷是否為 null 如果不判斷的話 第二個執行緒
// 也會 new 一個物件,那麼就破壞單例模式了
if (null == INSTANCE) {
INSTANCE = new DCL();
}
}
}
return INSTANCE;
}
}
上面的程式碼當中INSTANCE是沒有使用volatile進行修飾的,這會導致上面的程式碼存在問題。在分析這其中的問題之前,我們首先需要明白,在Java當中new一個物件會經歷以下三步:
- 步驟1:申請物件所需要的記憶體空間。
- 步驟2:在對應的記憶體空間當中,對物件進行初始化。
- 步驟3:對INSTANCE進行賦值。
但是因為變數INSTANCE沒有使用volatile進行修飾,就可能存在指令重排序,上面的三個步驟的執行順序變成:
- 步驟1。
- 步驟3。
- 步驟2。
假設一個執行緒的執行順序就是上面提到的那樣,如果執行緒在執行完成步驟3之後在執行完步驟2之前,另外一個執行緒進入getInstance,這個時候INSTANCE != null,因此這個執行緒會直接返回這個物件進行使用,但是此時第一個執行緒還在執行步驟2,也就是說物件還沒有初始化完成,這個時候使用物件是不合法的,因此上面的程式碼存在問題,而當我們使用volatile進行修飾就可以禁止這種重排序,從而讓他按照正常的指令去執行。
不保證原子性
原子性:一個操作要麼不做要麼全做,而且在做這個操作的時候其他執行緒不能夠插入破壞這個操作的完整性
public class AtomicTest {
public static volatile int data;
public static void add() {
for (int i = 0; i < 10000; i++) {
data++;
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(AtomicTest::add);
Thread t2 = new Thread(AtomicTest::add);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(data);
}
}
上面的程式碼就是兩個執行緒不斷的進行data++操作,一共會進行20000次,但是我們會發現最終的結果不等於20000,因此這個可以驗證volatile不保證原子性,如果volatile能夠保證原子性,那麼出現的結果會等於20000。
Java記憶體模型(JMM)
JMM下的記憶體邏輯結構
我們都知道Java程式可以跨平臺執行,之所以可以跨平臺,是因為JVM幫助我們遮蔽了這些不同的平臺和作業系統的差異,而記憶體模型也是一樣,各個平臺是不一樣的,Java為了保證程式可以跨平臺使用,Java虛擬機器器規範就定義了「Java記憶體模型」,規定Java應該如何並行的存取記憶體,每一個平臺實現的JVM都需要遵循這個規則,這樣就可以保證程式在不同的平臺執行的結果都是一樣的。
下圖當中的綠色部分就是由JMM進行控制的
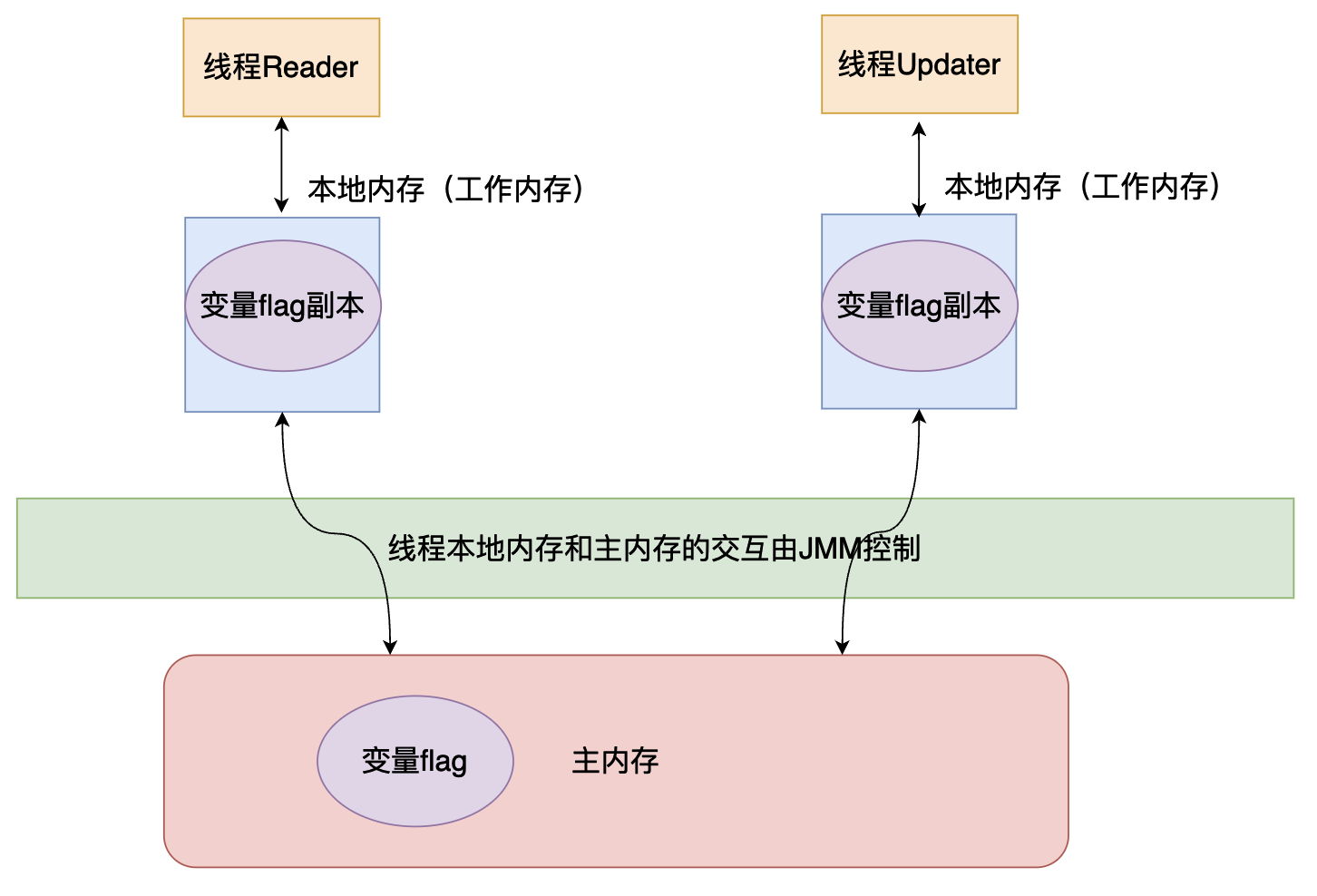
JMM對Java執行緒和執行緒的工作記憶體還有主記憶體的規定如下:
- 共用變數儲存在主記憶體當中,每個執行緒都可以進行存取。
- 每個執行緒都有自己的工作記憶體,叫做執行緒的本地記憶體。
- 執行緒如果想操作共用記憶體必須首先將共用變數拷貝一份到自己的本地記憶體。
- 執行緒不能直接對主記憶體當中的資料進行修改,只能直接修改自己本地記憶體當中的資料,然後通過JMM的控制,將修改後的值寫回到主記憶體當中。
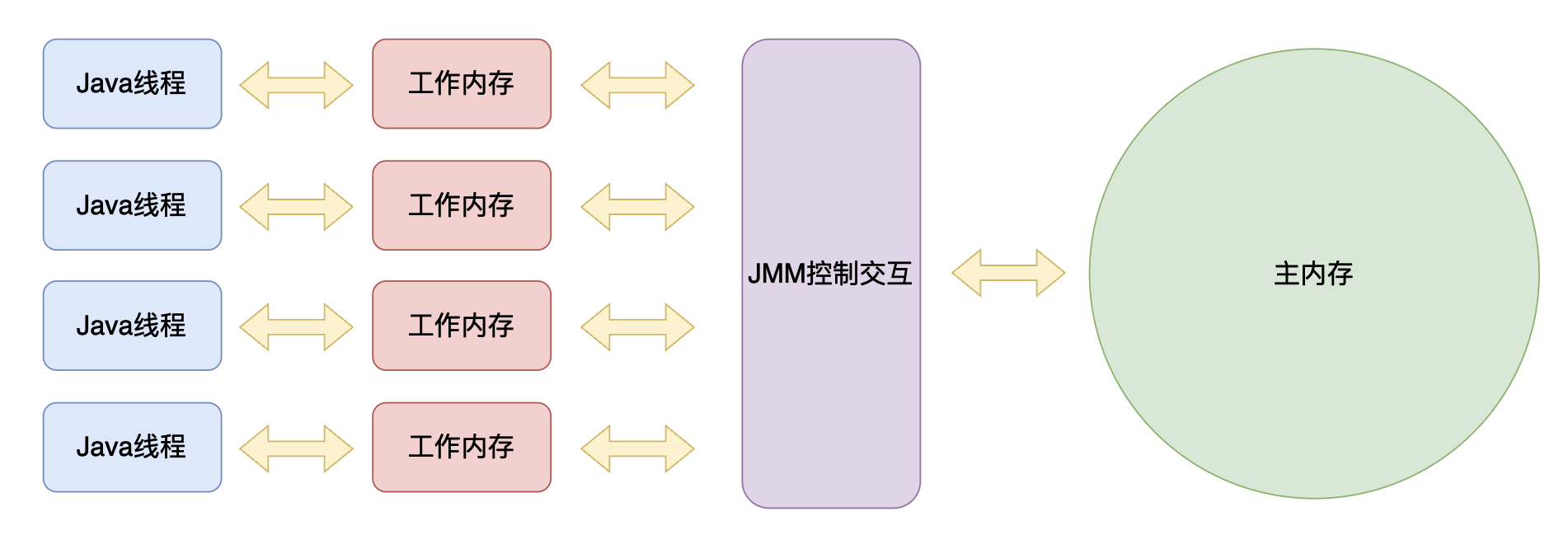
這裡區分一下主記憶體和工作記憶體(執行緒本地記憶體):
- 主記憶體:主要是Java堆當中的物件資料。
- 工作記憶體:Java虛擬機器器棧中儲存資料的某些區域、CPU的快取(Cache)和暫存器。
因此執行緒、執行緒的工作記憶體和主記憶體的互動方式的邏輯結構大致如下圖所示:
記憶體互動的操作
JMM規定了執行緒的工作記憶體應該如何和主記憶體進行互動,即共用變數如何從記憶體拷貝到工作記憶體、工作記憶體如何同步回主記憶體,為了實現這些操作,JMM定義了下面8個操作,而且這8個操作都是原子的、不可再分的,如果下面的操作不是原子的話,程式的執行就會出錯,比如說在鎖定的時候不是原子的,那麼很可能出現兩個執行緒同時鎖定一個變數的情況,這顯然是不對的!!
-
lock(鎖定):作用於主記憶體的變數,它把一個變數標識為一條執行緒獨佔的狀態。
-
unlock(解鎖):作用於主記憶體的變數,它把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他執行緒鎖定。
-
read(讀取):作用於主記憶體的變數,它把一個變數的值從主記憶體傳輸到執行緒的工作記憶體中,以便隨後的load動作使用。
-
load(載入):作用於工作記憶體的變數,它把read操作從主記憶體中得到的變數值放入工作記憶體的變數副本中。
-
use(使用):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳遞給執行引擎,每當虛擬機器器遇到一個需要使用變數的值的位元組碼指令時將會執行這個操作。
-
assign(賦值):作用於工作記憶體的變數,它把一個從執行引擎接收的值賦給工作記憶體的變數,每當虛擬機器器遇到一個給變數賦值的位元組碼指令時執行這個操作。
-
store(儲存):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳送到主記憶體中,以便隨後的write操作使用。
-
write(寫入):作用於主記憶體的變數,它把store操作從工作記憶體中得到的變數的值放入主記憶體的變數中。
如果需要將主記憶體的變數拷貝到工作記憶體,就需要順序執行read和load操作,如果需要將工作記憶體的值更新回主記憶體,就需要順序執行store和writer操作。
JMM定義了上述8條規則,但是在使用這8條規則的時候,還需要遵循下面的規則:
-
不允許read和load、store和write操作之一單獨出現,即不允許一個變數從主記憶體讀取了但工作記憶體不接受,或者工作記憶體發起回寫了但主記憶體不接受的情況出現。
-
不允許一個執行緒丟棄它最近的assign操作,即變數在工作記憶體中改變了之後必須把該變化同步回主記憶體。不允許一個執行緒無原因地(沒有發生過任何assign操作)把資料從執行緒的工作記憶體同步回主記憶體 中。·
-
一個新的變數只能在主記憶體中「誕生」,不允許在工作記憶體中直接使用一個未被初始化(load或assign)的變數,換句話說就是對一個變數實施use、store操作之前,必須先執行assign和load操作。
-
一個變數在同一個時刻只允許一條執行緒對其進行lock操作,但lock操作可以被同一條執行緒重複執行多次,多次執行lock後,只有執行相同次數的unlock操作,變數才會被解鎖。
-
如果對一個變數執行lock操作,那將會清空工作記憶體中此變數的值,在執行引擎使用這個變數前,需要重新執行load或assign操作以初始化變數的值。
-
如果一個變數事先沒有被lock操作鎖定,那就不允許對它執行unlock操作,也不允許去unlock一個被其他執行緒鎖定的變數。
-
對一個變數執行unlock操作之前,必須先把此變數同步回主記憶體中(執行store、write操作)。
重排序
重排序介紹
我們在上文當中已經談到了,編譯器為了更好的優化程式的效能,會對程式進行進行編譯優化,在優化的過程當中可能會對指令進行重排序。我們這裡談到的編譯器是JIT(即時編譯器)。它JVM當中的一個元件,它可以通過分析Java程式當中的熱點程式碼(經常執行的程式碼),然後會對這段程式碼進行分析然後進行編譯優化,將其直接編譯成機器程式碼,也就是CPU能夠直接執行的機器碼,然後用這段程式碼代替位元組碼,通過這種方式來優化程式的效能,讓程式執行的更快。
重排序通常有以下幾種重排序方式:
- JIT編譯器對位元組碼進行優化重排序生成機器指令。
- CPU在執行指令的時候,CPU會在保證指令執行時的語意不發生變化的情況下(與單執行緒執行的結果相同),可以通過調整指令之間的順序,讓指令並行執行,加快指令執行的速度。
- 還有一種不是顯式的重排序方式,這種方式就是記憶體系統的重排序。這是由於處理器使用快取和讀/寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行。這並不是顯式的將指令進行重排序,只是因為快取的原因,讓指令的執行看起來像亂序。
as-if-serial規則
as-if-serial語意的意思是:不管怎麼重排序(編譯器和處理器為了提高並行度),(單執行緒)程式的執行結果不能被改變。編譯器、處理器都必須遵守as-if-serial語意,因為如果連這都不遵守,在單執行緒下執行的結果都不正確,那我們寫的程式執行的結果都不是我們想要的,這顯然是不正確的。
1. int a = 1;
2. int b = 2;
3. int c = a + b;
比如上面三條語句,編譯器和處理器可以對第一條和第二條語句進行重排序,但是必須保證第三條語句必須執行在第一和第二條語句之後,因為第三條語句依賴於第一和第二條語句,重排序必須保證這種存在資料依賴關係的語句在重排序之後執行的結果和順序執行的結果是一樣的。
happer-before規則
重排序除了需要遵循as-if-serial規則,還需要遵循下面幾條規則,也就是說不管是編譯優化還是處理器重排序必須遵循下面的原則:
-
程式順序原則 :執行緒當中的每一個操作,happen-before執行緒當中的後續操作。
-
鎖規則 :解鎖(unlock)操作必然發生在後續的同一個鎖的加鎖(lock)之前。
-
volatile規則 :volatile變數的寫,先發生於讀。
-
執行緒啟動規則 :執行緒的start()方法,happen-before它的每一個後續操作。
-
執行緒終止規則 :執行緒的所有操作先於執行緒的終結,Thread.join()方法的作用是等待 當前執行的執行緒終止。假設線上程B終止之前,修改了共用變數,執行緒A從執行緒B的 join方法成功返回後,執行緒B對共用變數的修改將對執行緒A可見。
-
執行緒中斷規則 :對執行緒 interrupt()方法的呼叫先行發生於被中斷執行緒的程式碼檢測到中斷事件的發生,可以通Thread.interrupted()方法檢測執行緒是否中斷。
-
物件終結規則 :物件的建構函式執行,需要先於finalize()方法的執行。
-
傳遞性 :A先於B ,B先於C 那麼A必然先於C。
總而言之,重排序必須遵循下面兩條基本規則:
- 對於會改變程式執行結果的重排序,JMM要求編譯器和處理器必須禁止這種重排序。
- 對於不會改變程式執行結果的重排序,JMM對編譯器和處理器不做要求(JMM允許這種重排序)。
Volatile重排序規則
下表是JMM為了實現volatile的記憶體語意制定的volatile重排序規則,列表示第一個操作,行表示第二個操作:
| 是否可以重排序 | 第二個操作 | 第二個操作 | 第二個操作 |
|---|---|---|---|
| 第一個操作 | 普通讀/寫 | volatile讀 | volatile寫 |
| 普通讀/寫 | Yes | Yes | No |
| volatile讀 | No | No | No |
| volatile寫 | Yes | No | No |
說明:
- 比如在上表當中說明,當第二個操作是volatile寫的時候,那麼這個指令不能和前面的普通讀寫和volatile讀寫進行重排序。
- 當第一個操作是volatile讀的時候,這個指令不能和後面的普通讀寫和volatile讀寫重排序。
Volatile實現原理
禁止重排序實現原理
記憶體屏障
在瞭解禁止重排序如何實現的之前,我們首先需要了解一下記憶體屏障。所謂記憶體屏障就是為了保證記憶體的可見性而設計的,因為重排序的存在可能會造成記憶體的不可見,因此Java編譯器(JIT編譯器)在生成指令的時候為了禁止指令重排序就會在生成的指令當中插入一些記憶體屏障指令,禁止指令重排序,從而保證記憶體的可見性。
| 屏障型別 | 指令例子 | 解釋 |
|---|---|---|
| LoadLoad Barrier | Load1;LoadLoad;Load2 | 確保Load1資料的載入先於Load2和後面的Load指令 |
| StoreStore Barrier | Store1;StoreStore;Store2 | 確保Store1操作的資料對其他處理器可見(將Cache重新整理到記憶體),即這個指令的執行要先於Store2和後面的儲存指令 |
| LoadStore Barrier | Load1;LoadStore;Store2 | 確保Load1資料載入先於Store2以及後面所有儲存指令 |
| StoreLoad Barrier | Store1;StoreLoad;Load2 | 確保Store1資料對其他處理器可見,也就是將這個資料從CPU的Cache重新整理到記憶體當中,這個記憶體屏障會讓StoreLoad前面的所有的記憶體存取指令(不管是Store還是Load)全部完成之後,才執行Store Load後面的Load指令 |
X86當中記憶體屏障指令
現在處理器一般可能不會支援上面屏障指令當中的所有指令,但是一般都會支援Store Load屏障指令,因為這個指令可以達到其他三個指令的效果,因此在實際的機器指令當中如果想達到上面的四種指令的效果,可能不需要四個指令,像在X86當中就主要有三個記憶體屏障指令:
lfence,這是一種Load Barrier,一種讀屏障指令,這個指令可以讓快取記憶體(CPU的Cache)失效,如果需要載入資料,那麼就需要從記憶體當中重新載入(這樣可以載入最新的資料,因為如果其他處理器修改了快取當中的資料的時候,這個快取當中的值已經不對了,去記憶體當中重新載入就可以拿到最新的資料),這個指令其實可以達到上面指令當中LoadLoad和指令的效果。同時這條指令不會讓這條指令之後讀操作被排程到lfence指令之前執行。sfence,這是一種Store Barrier,一種寫屏障指令,這個指令可以將寫入快取記憶體的資料重新整理到記憶體當中,這樣記憶體當中的資料就是最新的了,資料就可以全域性可見了,其他處理器就可以載入記憶體當中最新的資料。這條指令有StoreStore的效果。同時這條指令不會讓在其之後的寫操作排程到其之前執行。- 關於以上兩點的描述是稍微有點不夠準確的,在下文我們在討論Store Buffer和Invalid Queue時我們會重新修正,這裡這麼寫是為了能夠幫助大家理解。
mfence,這是一種全能型的屏障,相當於上面lfence和sfence兩個指令的效果,除此之外這條指令可以達到StoreLoad指令的效果,這條指令可以保證mfence操作之前的寫操作對mfence之後的操作全域性可見。
Volatile需要的記憶體屏障
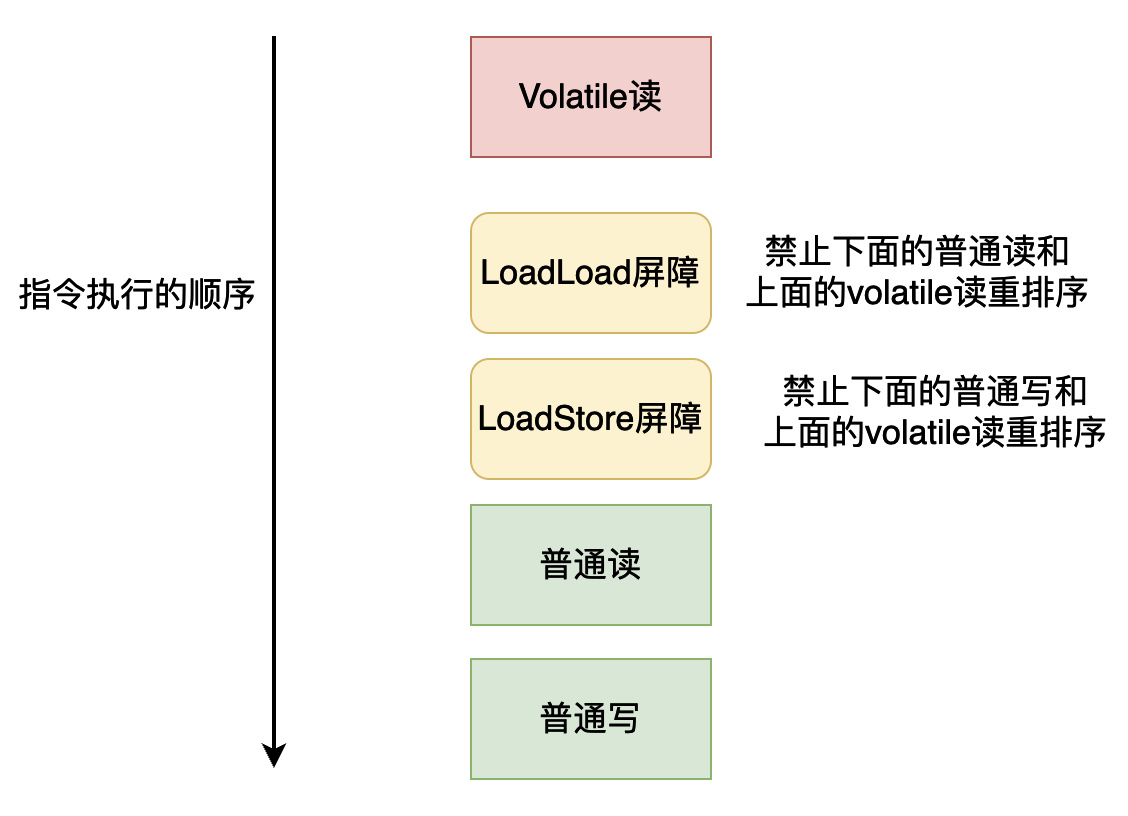
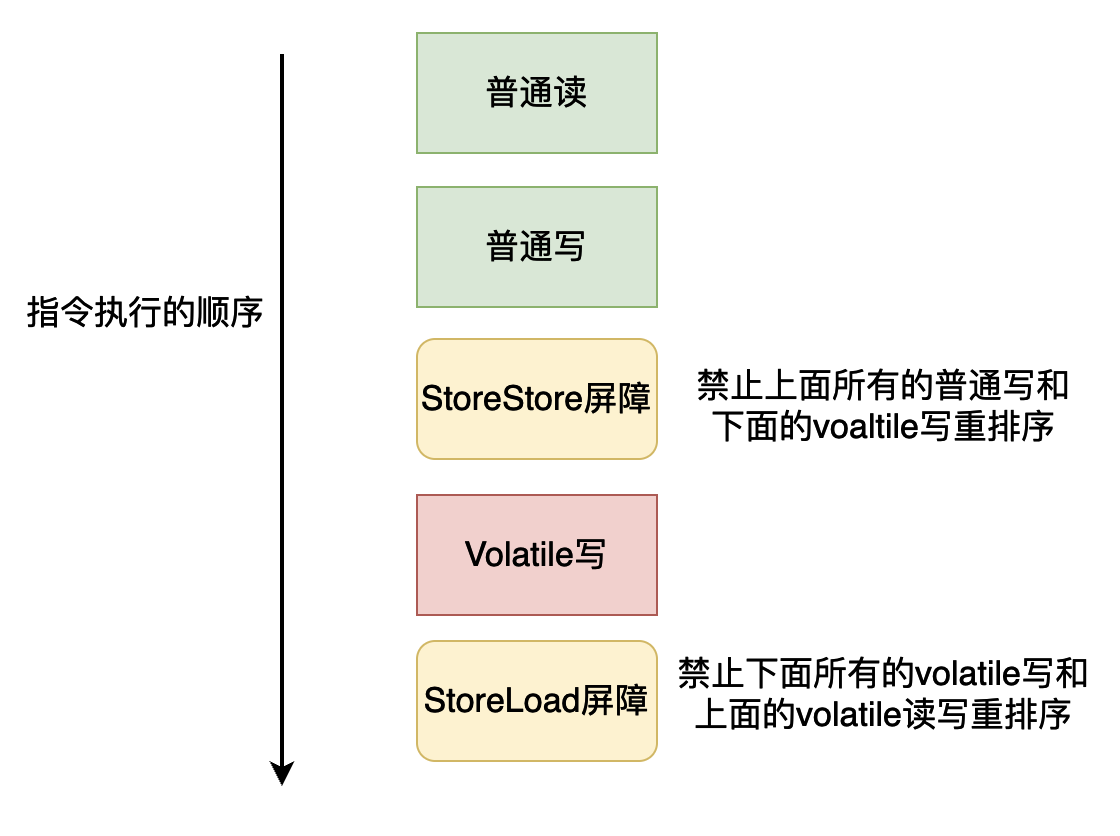
為了實現Volatile的記憶體語意,Java編譯器(JIT編譯器)在進行編譯的時候,會進行如下指令的插入操作(這裡你可以對照前面的volatile重排序規則,然後你就理解為什麼要插入下面的記憶體屏障了):
-
在每個volatile寫操作的前面插入一個StoreStore屏障。
-
在每個volatile寫操作的後面插入一個StoreLoad屏障。
-
在每個volatile讀操作的後面插入一個LoadLoad屏障。
-
在每個volatile讀操作的後面插入一個LoadStore屏障。
Volatile讀記憶體屏障指令插入情況如下:
Volatile寫記憶體屏障指令插入情況如下:
其實上面插入記憶體屏障只是理論上所需要的,但是因為不同的處理器重排序的規則不一樣,因此在插入記憶體屏障指令的時候需要具體問題具體分析。比如X86處理器只會對讀-寫這樣的操作進行重排序,不會對讀-讀、讀-寫和寫-寫這樣的操作進行重排序,因此在X86處理器進行記憶體屏障指令的插入的時候可以省略這三種情況。
根據volatile重排序的規則表,我們可以發現在寫-讀的情況下,只禁止了volatile寫-volatile讀的情況:

而X86僅僅只會對寫-讀的情況進行重排序,因此我們在插入記憶體屏障的時候只需要關心volatile寫-volatile讀這一種情況,這種情況下我們需要使用的記憶體屏障指令為StoreLoad,即volatile寫-StoreLoad-volatile讀,因此在X86當中我們只需要在volatile寫後面加入StoreLoad記憶體屏障指令即可,在X86當中Store Load對應的具體的指令為mfence。
Java虛擬機器器原始碼實現Volatile語意
在Java虛擬機器器當中,當對一個被volatile修飾的變數進行寫操作的時候,在操作進行完成之後,在X86體系結構下,JVM會執行下面一段程式碼,從而保證volatile的記憶體語意:(下面程式碼來自於:hotspot/src/os_cpu/linux_x86/vm/orderAccess_linux_x86.inline.hpp)
inline void OrderAccess::fence() {
// 這裡判斷是不是多處理器的機器,如果是執行下面的程式碼
if (os::is_MP()) {
// 這裡說明了使用 lock 指令的原因 有時候使用 mfence 代價很高
// 相比起 lock 指令來說會降低程式的效能
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64 // 這個表示如果是 64 位機器
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else // 如果不是64位元機器 s
// 32位元和64位元主要區別就是 暫存器不同 在64 位當中是 rsp 在32位元機器當中是 esp
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
上面程式碼主要是通過內聯組合程式碼去執行指令lock,如果你不熟悉C語言和內聯組合的形式也沒有關係,你只需要知道JVM會執行lock指令,lock指令有mfence相同的作用,它可以實現StoreLoad記憶體屏障的作用,可以保證執行執行的順序,在前文當中我們說mfence是用於實現StoreLoad記憶體屏障,因為lock指令也可以實現同樣的效果,而且有時候mfence的指令可能對程式的效能影響比較大,因此JVM使用lock指令,這樣可以提高程式的效能。如果你對X86的lock指令有所瞭解的話,你可能知道lock還可以保證使用lock的指令具有原子性,在X86的體系結構下就可以使用lock實現自旋鎖(CAS)。
可見性實現原理
可見性存在的根本原因是一個執行緒讀,一個執行緒寫,一個執行緒寫操作對另外一個執行緒的讀不可見,因此我們主要分析volatile的寫操作就行,因為如果都是進行讀操作的話,資料就不會發生變化了,也就不存在可見性的問題了。
在上文當中我們已經談到了Java虛擬機器器在執行volatile變數的寫操作時候,會執行lock指令,而這個指令有mfence的效果:
- 將執行
lock指令的處理器的快取行寫回到記憶體當中,因為我們進行了volatile資料的更新,因此我們需要將這個更新的資料寫回記憶體,好讓其他處理器在存取記憶體的時候,能夠看見被修改後的值。 - 寫回記憶體的操作會使在其他CPU裡快取了該記憶體地址的資料無效,這些處理器如果想使用這些資料的話,就需要從記憶體當中重新載入。因為修改了volatile變數的值,但是現在其他處理器中的快取(Cache)還是舊值,因此我們需要讓其他處理器快取了這個用volatile修飾的變數的快取行失效,那麼其他處理器想要再使用這個資料的話就需要重新去記憶體當中載入,而最新的資料已經更新到記憶體當中了。
深入記憶體屏障——Store Buffer和Invalid Queue
在前面我們提到了lock指令,lock指令可保證其他CPU當中快取了volatile變數的快取行無效。這是因為當處理器修改資料之後會在匯流排上傳送訊息說改動了這個資料,而其他處理器會通過匯流排嗅探的方式在匯流排上發現這個改動訊息,然後將對應的快取行置為無效。
這其實是處理器在處理共用資料時保證快取資料一致性(Cache coherence)的協定,比如說Intel的MESI協定,在這個協定之下快取行有以下四種狀態:
-
已修改Modified (M) 快取行是髒的(dirty),與主記憶體的值不同。如果別的CPU核心要讀主記憶體這塊資料,該快取行必須回寫到主記憶體,狀態變為共用(S).
-
獨佔Exclusive (E)快取行只在當前快取中,但是乾淨的(clean)快取資料和主記憶體資料相同。當別的快取讀取它時,狀態變為共用;當寫資料時,變為已修改狀態。
-
共用Shared (S)快取行也存在於其它快取中且是乾淨的。快取行可以在任意時刻拋棄。
-
無效Invalid (I)快取行是無效的。
-
因為MESI協定涉及的內容還是比較多的,如果你想仔細瞭解MESI協定,請看文末,這裡就不詳細說明了!
假設在某個時刻,CPU的多個核心共用一個記憶體資料,其中一個一個核心想要修改這個資料,那麼他就會通過匯流排給其他核心傳送訊息表示想要修改這個資料,然後其他核心將這個資料修改為Invalid狀態,再給修改資料的核心傳送一個訊息,表示已經收到這個訊息,然後這個修改資料的核心就會將這個資料的狀態設定為Modified。
在上面的例子當中當一個核心給其他CPU傳送訊息時需要等待其他CPU給他返回確認訊息,這顯然會降低CPU的效能,為了能夠提高CPU處理資料的效能,硬體工程師做了一層優化,在CPU當中加了一個部分,叫做「Store Buffer」,當CPU寫資料之後,需要等待其他處理器返回確認訊息,因此處理器先不將資料寫入快取(Cache)當中,而時寫入到Store Buffer當中,然後繼續執行指令不進行等待,當其他處理器返回確認訊息之後,再將Store Buffer當中的訊息寫入快取,以後如果CPU需要資料就會先從Store Buffer當中去查詢,如果找不到才回去快取當中找,這個過程也叫做Store Forwarding。
處理器在接受到其他處理器發來的修改資料的訊息的時候,需要將被修改的資料對應的快取行進行失效處理,然後再返回確認訊息,為了提高處理器的效能,CPU會在接到訊息之後立即返回,然後將這個Invalid的訊息放入到Invalid Queue當中,這就可以降低處理器響應Invalid訊息的時間。其實這樣做還有一個好處,因為處理器的Store Buffer是有限的,如果發出Invalid訊息的處理器遲遲接受不到響應資訊的話,那麼Store Buffer就可以寫滿,這個時候處理器還會卡住,然後等待其他處理器的響應訊息,因此處理器在接受到Invalid的訊息的時候立馬返回也可以提升發出Invalid訊息的處理器的效能,會減少處理器卡住的時間,從而提升處理器的效能。
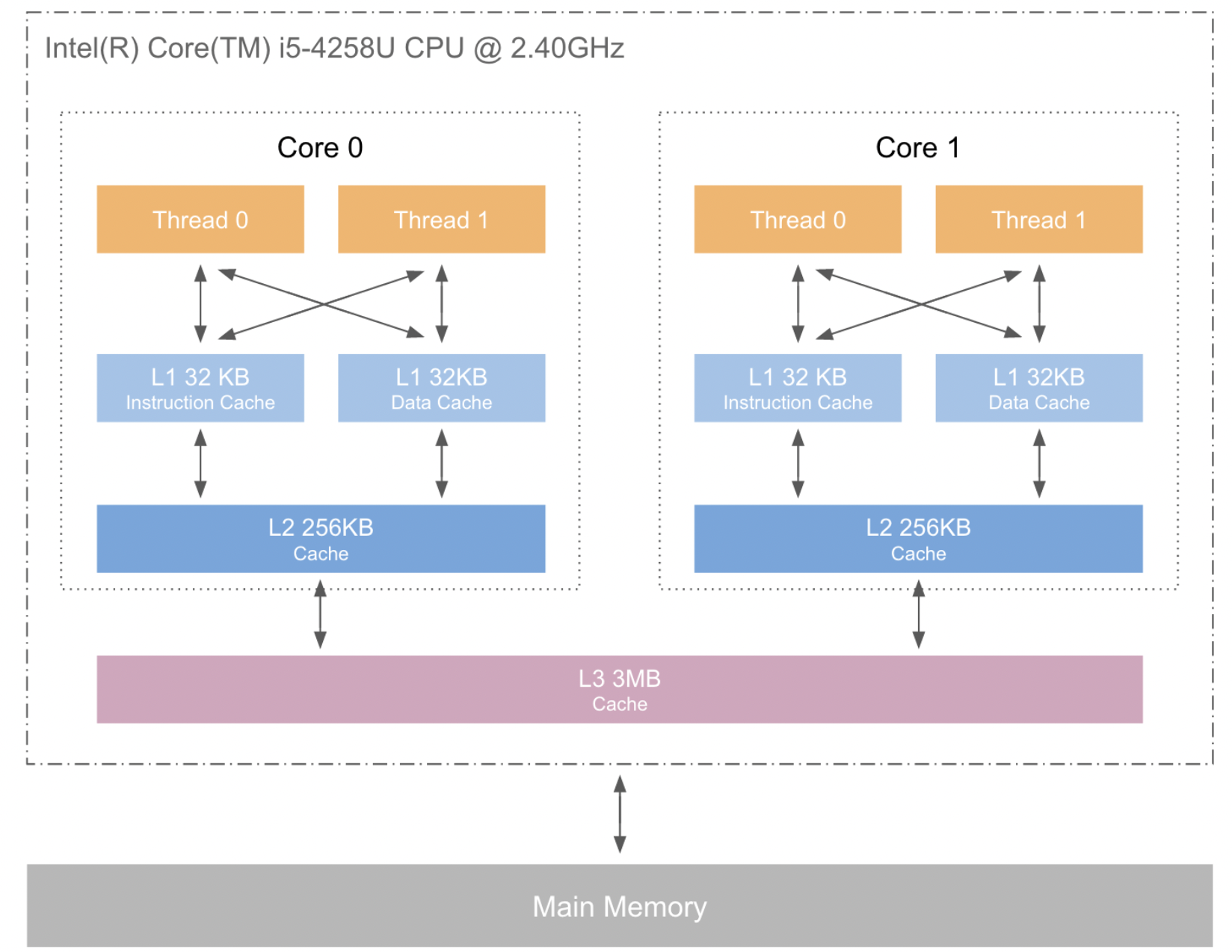
Store Buffer、Valid Queue、CPU、CPU快取以及記憶體的邏輯結構大致如下:

還記得前面的兩條指令lfence和sfence嗎,現在我們重新回顧一下這兩條指令:
lfence,在前面的內容當中,這個屏障能夠讓快取記憶體失效,事實上是,它掃描Invalid Queue中的訊息,然後讓對應資料的快取行失效,這樣的話就可以更新到記憶體當中最新的資料了。這裡的失效並不是L1快取失效,而是L2和L3中的快取行失效,讀取資料也不一定從記憶體當中讀取,因為L1Cache當中可能有最新的資料,如果有的話就可以從L1Cache當中讀取。sfence,在前面的內容當中,我們談到這個屏障時,說它可以將寫入快取記憶體的資料重新整理到記憶體當中,這樣記憶體當中的資料就是最新的了,資料就可以全域性可見了。事實上這個記憶體屏障是將StoreBuffer當中的資料刷行到L1Cache當中,這樣其他的處理器就可以看到變化了,因為多個處理器是共用同一個L1Cache的,比如下圖當中的CPU結構。當然它也是可以被重新整理到記憶體當中的。
(下面圖片來源於網路)
MESI協定
在前面的文章當中我們已經提到了在MESI協定當中快取行的四種狀態:
-
已修改Modified (M) 快取行是髒的(dirty),與主記憶體的值不同。如果別的CPU核心要讀主記憶體這塊資料,該快取行必須回寫到主記憶體,狀態變為共用(S).
-
獨佔Exclusive (E)快取行只在當前快取中,但是乾淨的(clean)快取資料和主記憶體資料相同。當別的快取讀取它時,狀態變為共用;當寫資料時,變為已修改狀態。
-
共用Shared (S)快取行也存在於其它快取中且是乾淨的。快取行可以在任意時刻拋棄。
-
無效Invalid (I)快取行是無效的。
下圖表示不同處理器快取同一個資料的快取行的狀態是否相容:
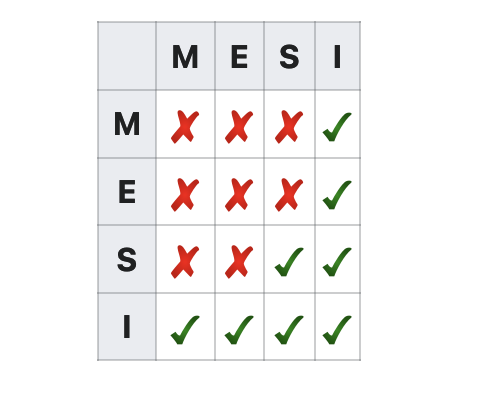
-
比如說「I」那一行,處理器A的快取行H包含資料
data,而且這個快取行的狀態是Invalid,那麼其他處理器包含資料data的快取行的狀態可以是「M、E、S、I」當中的任意一個。 -
再比如說包含資料
data的快取行是「Shared」的狀態,說明這個資料是各個處理器共用的,因此其他的快取行不可能是「Exclusive」狀態,因為不可能既共用也獨佔。當然肯定也不是「Modified」,如果是「Modified」狀態,那麼其他快取行只能是「Invalid」的狀態,而不會是「Shared」狀態
在介紹MESI協定之前,我們先介紹一些基本操作:
處理器對快取的請求:
- PrRd: 處理器請求讀一個快取塊。
- PrWr: 處理器請求寫一個快取塊。
匯流排對快取的請求:
- BusRd: 匯流排上有一個訊息:其他處理器請求讀一個快取塊。
- BusRdX: 匯流排上有一個訊息:其他處理器請求寫一個自己不擁有的快取塊。
- BusUpgr: 匯流排上有一個訊息:其他處理器請求寫一個自己擁有的快取塊。
- Flush:匯流排上有一個訊息:請求回寫整個快取到主記憶體。
- FlushOpt: 匯流排上有一個訊息:整個快取塊被髮到匯流排,然後通過匯流排送給另外一個處理器(快取到快取的複製)。
下圖是MESI這四種狀態在不同的操作之下的轉換圖(紅色表示匯流排事務,黑色表示處理器事務):(圖片來自維基百科)
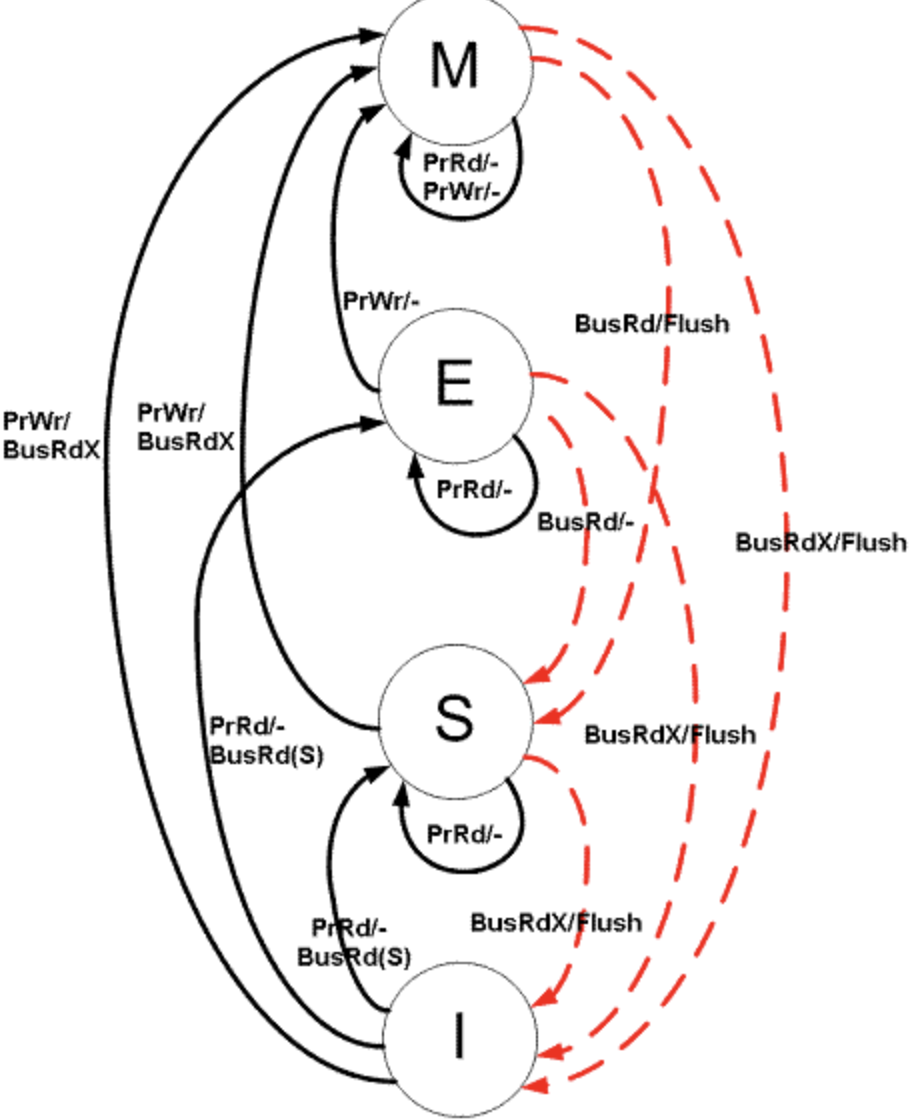
- 假如現在是「M」狀態,現在如果有其他處理器想要讀資料(BusRd)或者處理器想要將這個資料寫回記憶體(flush),那麼這個「M」狀態就轉變成「S」狀態了。
- 假如現在是「E」狀態,如果有匯流排請求讀(BusRd),那麼這個狀態就需要從獨佔(E)變成共用(S)。
不同的初始狀態在不同的處理器操作下的狀態變化:
| 初始狀態 | 操作 | 響應 |
|---|---|---|
| Invalid(I) | PrRd | 給匯流排發BusRd訊號 其他處理器看到BusRd,檢查自己是否有有效的資料副本,通知發出請求的快取 狀態轉換為(S)Shared, 如果其他快取有有效的副本 狀態轉換為(E)Exclusive, 如果其他快取都沒有有效的副本 如果其他快取有有效的副本, 其中一個快取發出資料;否則從主記憶體獲得資料 |
| Exclusive(E) | PrRd | 無匯流排事務生成 狀態保持不變 讀操作為快取命中 |
| Shared(S) | PrRd | 無匯流排事務生成 狀態保持不變 讀操作為快取命中 |
| Modified(M) | PrRd | 無匯流排事務生成 狀態保持不變 讀操作為快取命中 |
| Invalid(I) | PrWr | 給匯流排發BusRdX訊號 狀態轉換為(M)Modified 如果其他快取有有效的副本, 其中一個快取發出資料;否則從主記憶體獲得資料 如果其他快取有有效的副本, 見到BusRdX訊號後無效其副本 向快取塊中寫入修改後的值 |
| Exclusive(E) | PrWr | 無匯流排事務生成 狀態轉換為(M)Modified 向快取塊中寫入修改後的值 |
| Shared(S) | PrWr | 發出匯流排事務BusUpgr訊號 狀態轉換為(M)Modified 其他快取看到BusUpgr匯流排訊號,標記其副本為(I)Invalid. |
| Modified(M) | PrWr | 無匯流排事務生成 狀態保持不變 寫操作為快取命中 |
不同的初始狀態在不同的匯流排訊息下的狀態變化:
| 初始狀態 | 操作 | 響應 |
|---|---|---|
| Invalid(I) | BusRd | 狀態保持不變,訊號忽略 |
| Exclusive(E) | BusRd | 狀態變為共用 發出匯流排FlushOpt訊號並行出塊的內容 |
| Shared(S) | BusRd | 狀態變為共用 可能發出匯流排FlushOpt訊號並行出塊的內容(設計時決定那個共用的快取發出資料) |
| Modified(M) | BusRd | 狀態變為共用 發出匯流排FlushOpt訊號並行出塊的內容,接收者為最初發出BusRd的快取與主記憶體控制器(回寫主記憶體) |
| Exclusive(E) | BusRdX | 狀態變為無效 發出匯流排FlushOpt訊號並行出塊的內容 |
| Shared(S) | BusRdX | 狀態變為無效 可能發出匯流排FlushOpt訊號並行出塊的內容(設計時決定那個共用的快取發出資料) |
| Modified(M) | BusRdX | 狀態變為無效 發出匯流排FlushOpt訊號並行出塊的內容,接收者為最初發出BusRd的快取與主記憶體控制器(回寫主記憶體) |
| Invalid(I) | BusRdX/BusUpgr | 狀態保持不變,訊號忽略 |
總結
在本篇文章當中主要是介紹了volatile和JMM的具體作用和規則,然後仔細介紹了實現這些的底層原理,尤其是記憶體屏障以及它在X86當中的具體實現,這一部分的內容比較抽象,可能難以理解本篇文章涉及的內容比較多,可能需要大家慢慢的仔細思考才能理解。
以上就是本文所有的內容了,希望大家有所收穫,我是LeHung,我們下期再見!!!(記得點贊收藏哦!)
更多精彩內容合集可存取專案:https://github.com/Chang-LeHung/CSCore
關注公眾號:一無是處的研究僧,瞭解更多計算機(Java、Python、計算機系統基礎、演演算法與資料結構)知識。
參考書籍和資料
《Java並行程式設計的藝術》
《深入理解Java虛擬機器器》
《Java高並行程式設計詳解》
《JSR-133: Java™ Memory Model and Thread Specifification》
https://blog.the-pans.com/std-atomic-from-bottom-up/
https://en.wikipedia.org/wiki/MESI_protocol
https://www.felixcloutier.com/x86/index.html