關於Request複用的那點破事兒。研究明白了,給你彙報一下。
你好呀, 我是歪歪。
之前不是釋出了這篇文章嘛:《千萬不要把Request傳遞到非同步執行緒裡面!有坑!》
說的是由於 Request 在 tomcat 裡面是複用的,所以如果在一個 Request 的生命週期完成之後,在非同步執行緒裡面呼叫了相關的方法,會導致這個 Request 被汙染,然後在下一個請求中觀察到一些匪夷所思的場景。
但是文章的評論區裡面出現了個問題,還一下把我問住了:

由於我那篇文章關注的重點是把 Request 傳遞到非同步執行緒這個騷操作,並沒有特別的關注 Request 到底是怎麼複用的。
我只是通過列印紀錄檔的方式去觀察到了複用的這個現象:
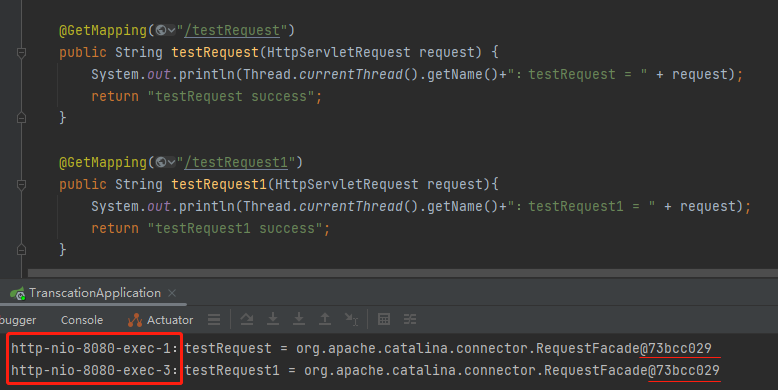
把專案啟動起來之後,分別存取 testRequest 和 testRequest1,從控制檯的輸出來看,Request 物件確實是一個物件。
但是從前面的執行緒名稱來看,這是執行緒池裡面兩個完全不同的執行緒。
所以,雖然我還啥都沒分析呢,基於紀錄檔就至少能看出這個問題的答案:
複用的request是和執行緒繫結的嗎?
不是,沒有繫結關係。
如果不是和執行緒繫結,那麼問題就隨之而來了:
如何決定哪個執行緒每次複用哪個request呢?
這是個好問題,我也不知道答案,所以我決定來盤一盤它。
但是在盤它之前,我們先想個問題:假設 Request 和請求執行緒繫結在一起了,這是一個合理的設計嗎?
肯定不是的。
執行緒就應該是單純的執行緒,不應該給它「繫結」一個 Request。這種繫結讓執行緒不單純了,執行緒和請求耦合在一起了。
好一點的設計應該是 Request 放在一個「池子」裡面,來一個執行緒就從池子裡面去取可以用的 Request。
這樣可以實現執行緒和請求之間解耦的效果。
當然,這也只是我在進行探索之前的一個假設而已,先放在這裡,最後看看這個猜想是否正確。
看這篇文章不需要你對 Tomcat 有多少了解,會用它就行,很多東西都是可以基於原始碼推理出來的。
對了,說一下 Tomcat 原始碼版本:9.0.58。
第一個斷點
要找到問題的答案肯定得去翻原始碼,但是從哪裡開始翻呢?
或者換個問題:第一個斷點打在哪呢?
遇到這個問題我的第一反應還是從紀錄檔裡面看看能不能找到相關的線索,從而找到打第一個斷點的位置。
但是我分別把紀錄檔調整到 DEBUG 級別和 TRACE 級別,均沒有發現有價值的資訊,所以紀錄檔這條路感覺走不通了,怎麼辦?
不慌,這個時候就要冷靜分析一下了。

悄悄的問自己一句:我可以把斷點打在方法入口處嗎?
當然可以了,這也是能想到的一個非常常規的手段:

但是如果把斷點打在這裡,相當於從業務程式碼的第一行反向去推原始碼,把路繞的稍微遠了一點。
那麼還可以把斷點打在哪裡呢?
我這裡不是輸出了 Request 這個物件的全類名嗎:
http-nio-8080-exec-2:testRequest1 = org.apache.catalina.connector.RequestFacade@5db48dd3
RequestFacade,這個類能用,必然有一個 new 它的地方,而要 new 它,必定要呼叫它的構造方法。
那我是不是隻要在其對應的構造方法上打個斷點,當程式建立這個類的時候,不就是我要找的源頭嗎?
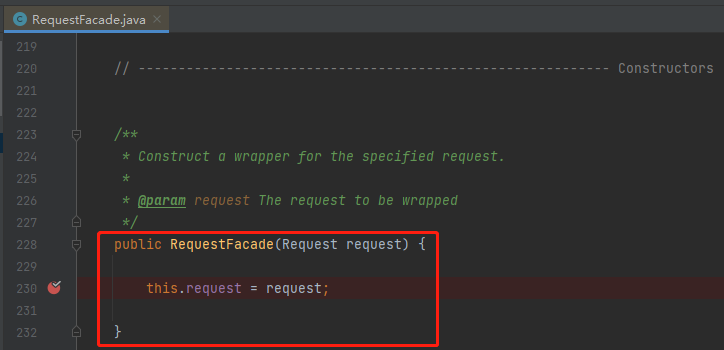
所以,我把第一個斷點打在了 RequestFacade 的構造方法上。
從構造方法入手,這也是我的一個偵錯小技巧,送給你,不客氣。
有的小夥伴就要問了:如果一個類有多個構造方法怎麼辦呢?
很簡單,大力出奇跡,每個構造方法都打上斷點,一定會有一個地方觸發的。

偵錯原始碼
找到第一個斷點的位置了,接下來就是把專案重啟,發起呼叫了。
我連續發起了兩次呼叫,從程式的表現上我就知道這個斷點打對了。
我先給你上個動圖,你就知道我為什麼這麼說了:
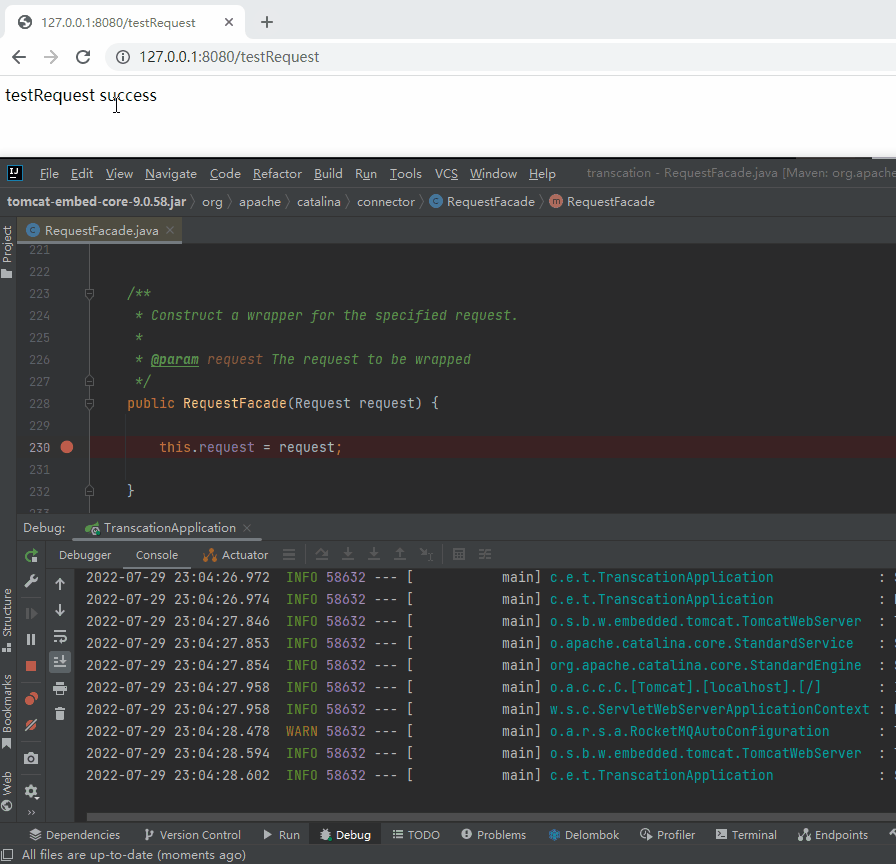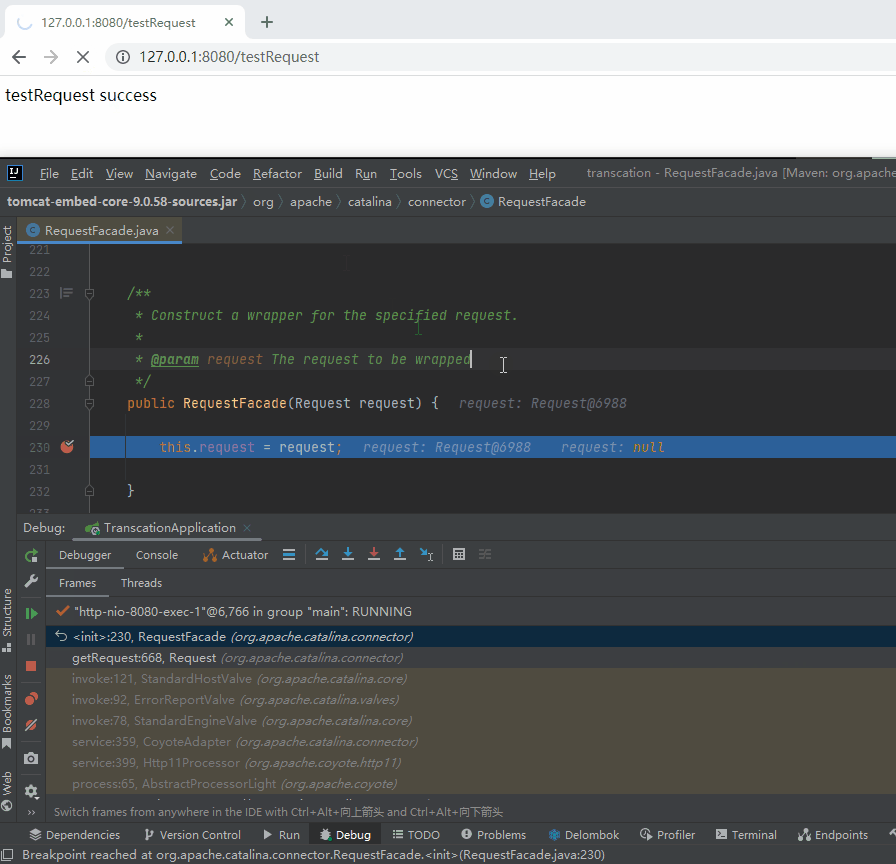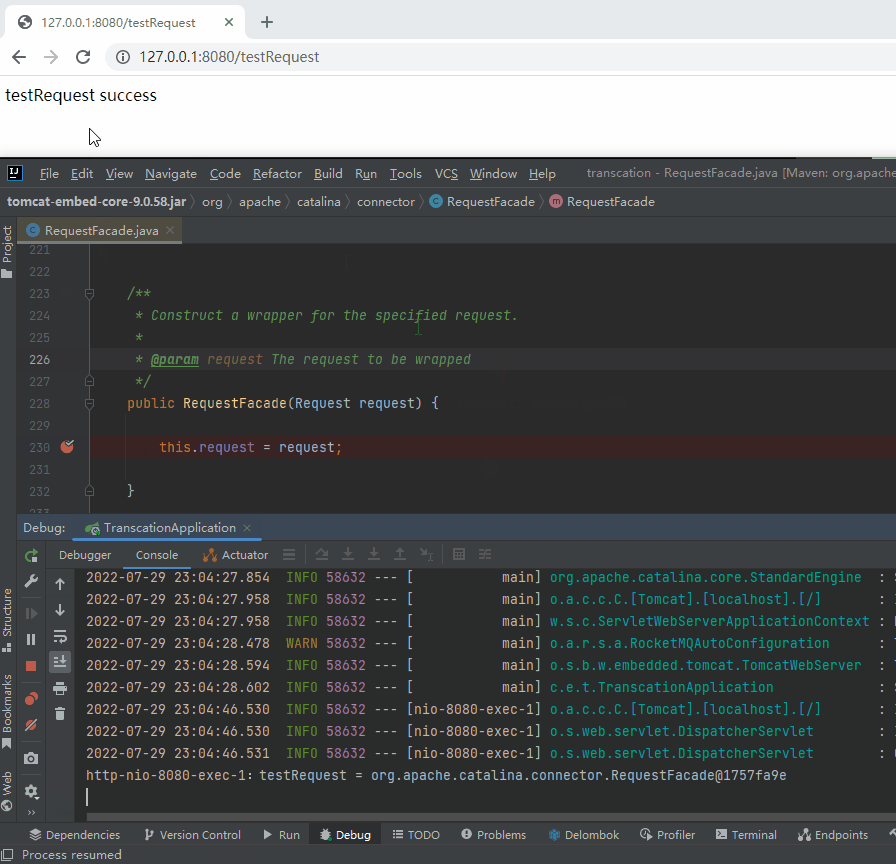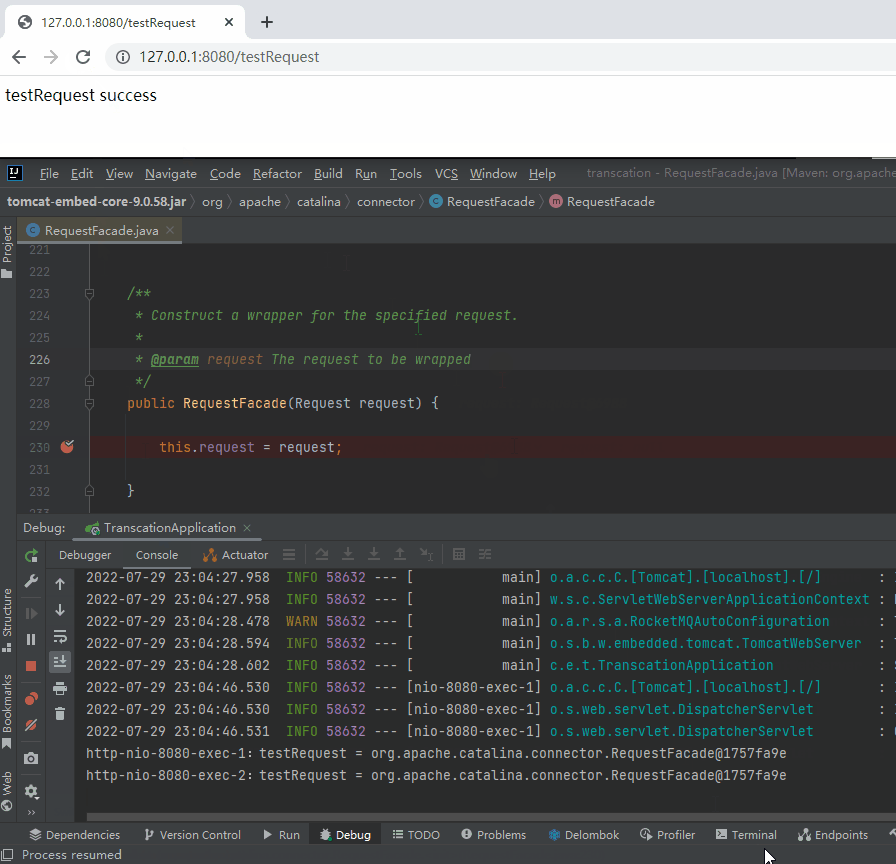
專案啟動之後,第一次呼叫在斷點的地方停下來了,接著第二次呼叫並沒有在斷點的地方停下來。
說明第二次確實沒有新建 RequestFacade 物件,而是複用了第一次呼叫時產生的 RequestFacade 物件。
驗證了斷點打的位置沒毛病之後,就可以開始慢慢的偵錯了。
首先,我們關注一下這個 RequestFacade 物件建立的地方:
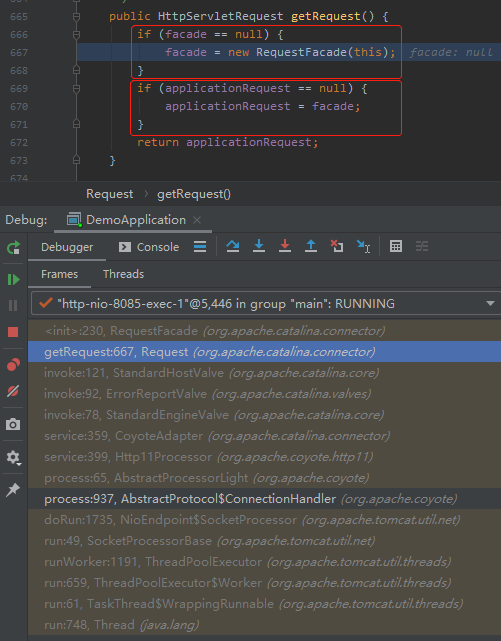
有兩個 if 判斷。
第一個是判斷 facade 是否為 null,不為 null 就 new。
第二個是把 facade 賦值給 applicationRequest 物件,接著返回 applicationRequest 物件。
第二個 if 其實很有意思,你想啊,這裡直接返回 facade 也可以呀,為什麼要用 applicationRequest 來承接一下呢?
這是一個好問題。
這兩個 if 的關鍵在於 facade 和 applicationRequest 是否為空。
第一次存取的時候肯定是空。那麼後續什麼時候又會變為空呢?
就是在一次請求結束,執行 recycle 方法的時候:
org.apache.catalina.connector.Request#recycle
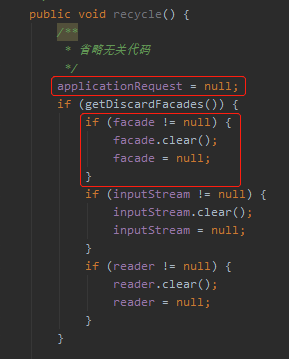
從原始碼中可以看到 applicationRequest 是直接設定為 null 的。
但是這個 facade 設定為 null 有個前提,getDiscardFacades 方法返回為 true。
這是個什麼玩意?
看一眼就知道了:
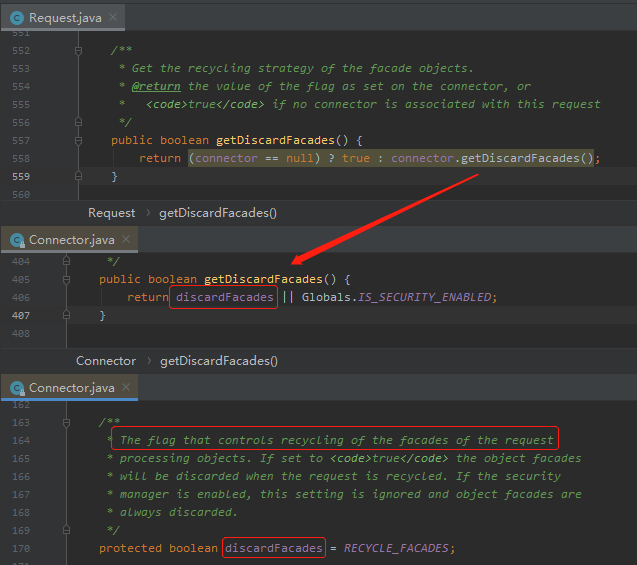
意思是 RECYCLE_FACADES 這個引數控制著是否迴圈使用 facade 這個物件,如果設定為 true 會提高安全性,而這個引數預設是 false。


也就是說我這個地方如果把這個引數修改為 true,facade 物件就會在每次呼叫完成之後進行回收。
可以通過啟動引數JAVA_OPTS來設定:
-Dorg.apache.catalina.connector.RECYCLE_FACADES=true
從前面的原始碼中可以知道,在預設的情況下,applicationRequest 會在每次請求完成之後設定為 null,而 facade 會保留下來。
因此下一次請求過來的時候,facede 並不為空,直接複用 facade。把 facade 賦值給 applicationRequest。
所以我們在紀錄檔裡面觀察到的現象是兩次請求輸出的 facade 物件是一樣的。
接著,我們繼續看呼叫堆疊。
看建立 facade 的這個 getRequest 請求到底是誰在呼叫:
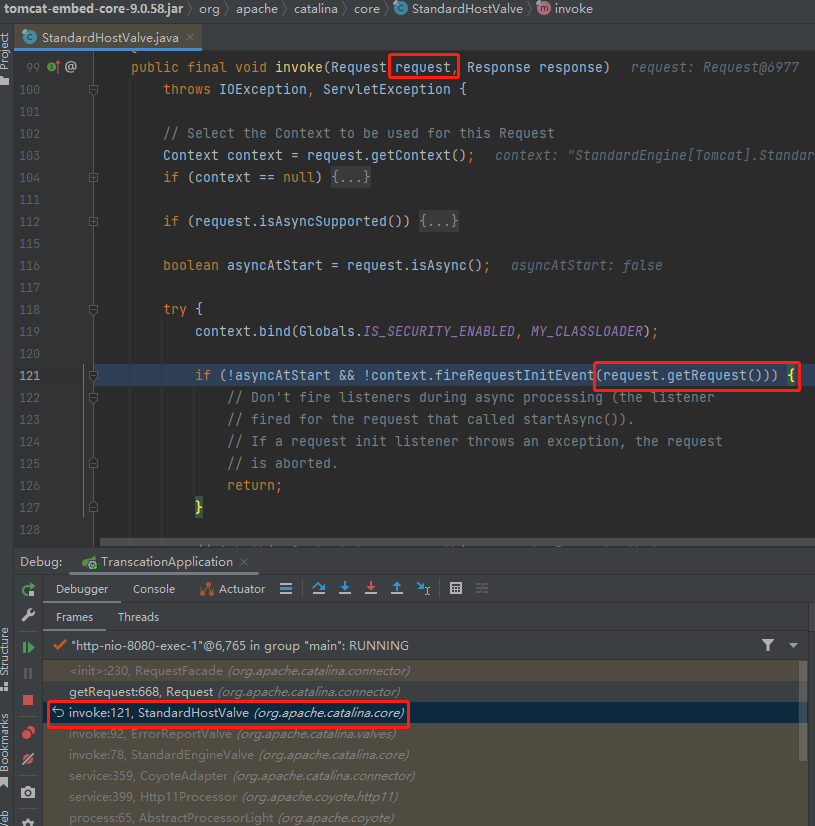
發現是一個 Request 物件在呼叫 getRequest 方法。
所以接下來要找的就是 Request 物件最開始是從哪個方法開始作為入參傳遞的。
順著呼叫堆疊,可以找到下面這個地方:
org.apache.coyote.http11.Http11Processor#service
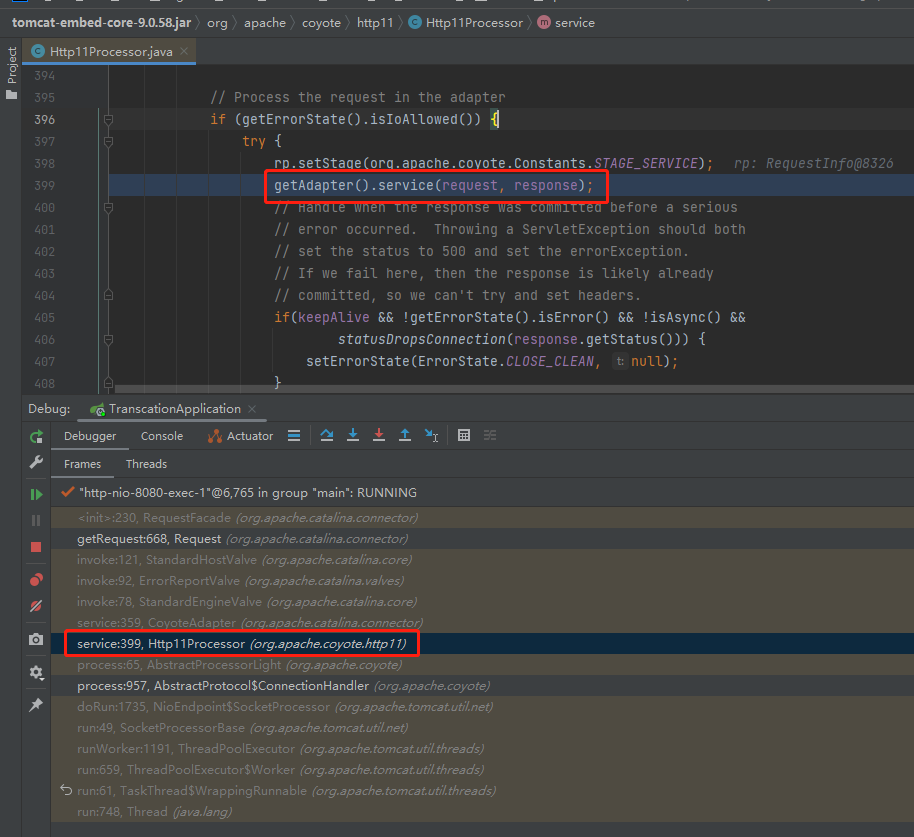
這就是 Request 物件最開始作為入參傳遞的地方。
那麼這個 Request 物件是怎麼產生的呢?
我也不知道。
所以,要知道這個問題的答案,第二個斷點打的位置也就呼之欲出了:
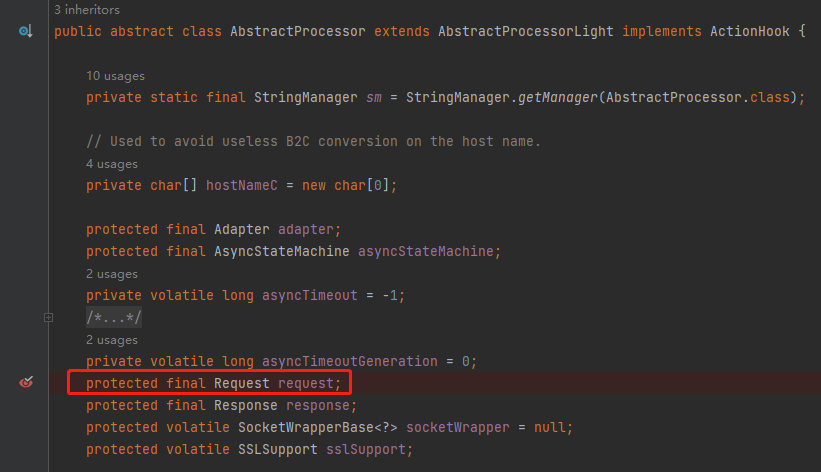
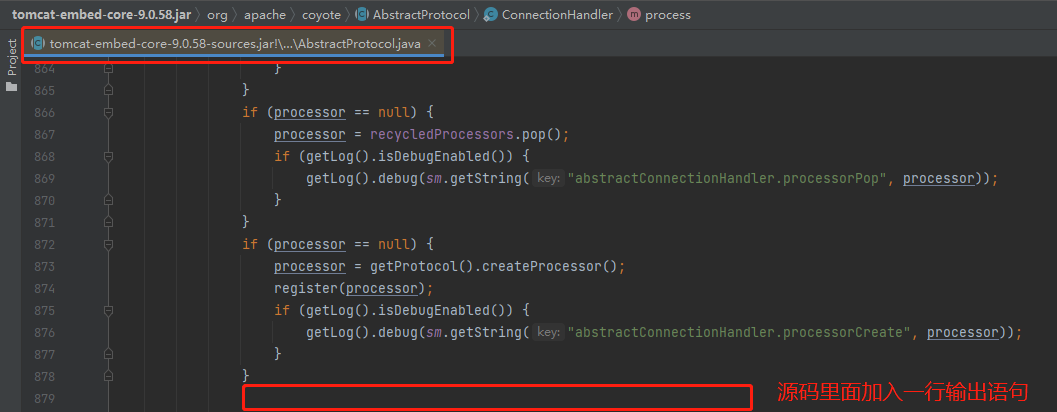
重啟專案,發起請求,發現 Debug 停在了 AbstractProcessor 類的構造方法,這就是 request 最開始產生的地方,同時我們又收穫了一個呼叫堆疊:
org.apache.coyote.AbstractProcessor#AbstractProcessor(org.apache.coyote.Adapter, org.apache.coyote.Request, org.apache.coyote.Response)
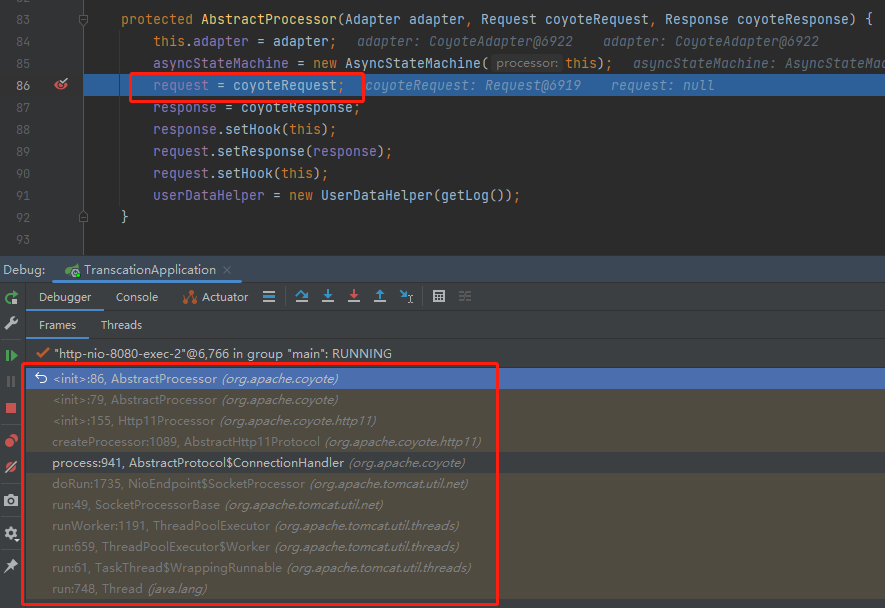
這個 Request 是怎麼來的呢?
new 出來的:
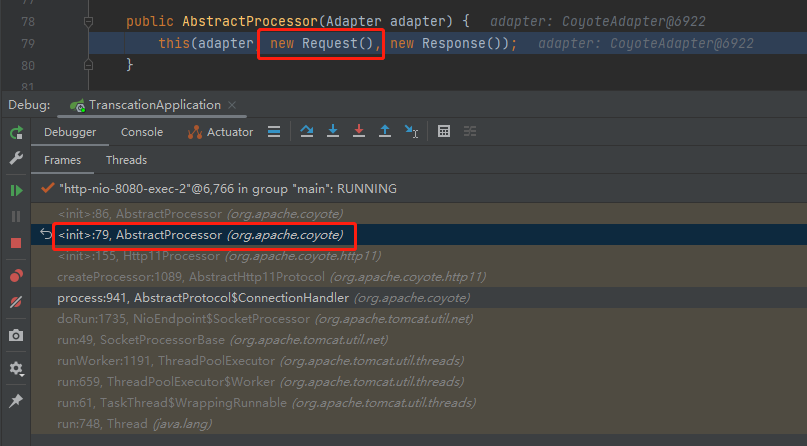
為什麼要執行這個 new 方法呢?
因為這個地方在 createProcessor:
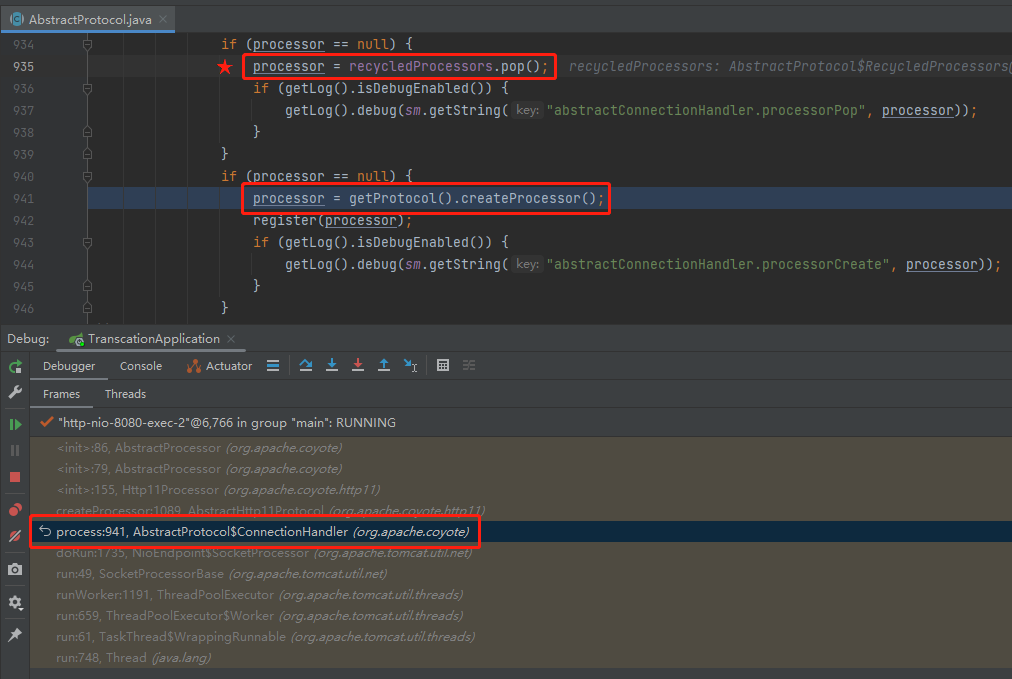
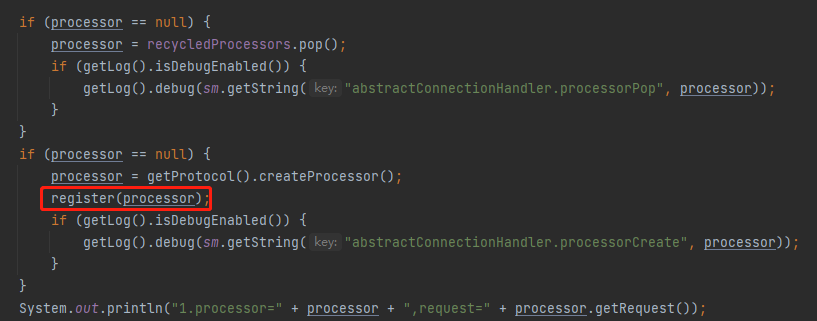
而我們要尋找的問題的答案,就藏在上面這個截圖中。
準確的說,就藏在上面截圖中,標記了五角星的地方:
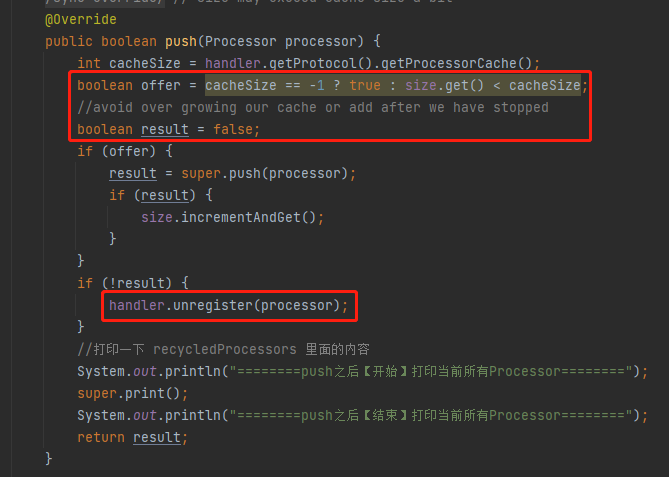
processor = recycledProcessors.pop();
從程式碼的片段看,如果從 recycledProcessors 裡面 pop 出的 processor 物件不為空,則不會呼叫 createProcessor 方法。
而從偵錯的角度看,不呼叫 createProcessor 方法,也就不會建立 RequestFacade 物件。
所以,recycledProcessors,這個玩意是華點、是真正的突破口。

這一小節,主要是分享一下我找到這個突破口的一個過程,兩個關鍵的斷點是基於上面考慮設定的。
其實你回想一下,這是一個非常順其自然的事情,帶著問題去偵錯原始碼是一件比較簡單的事情。
不要慫,就是翻。
recycledProcessors
你看這個物件的名稱,recycled + Processors,一看就知道里面有故事,有關於物件複用的故事。
org.apache.coyote.AbstractProtocol.RecycledProcessors
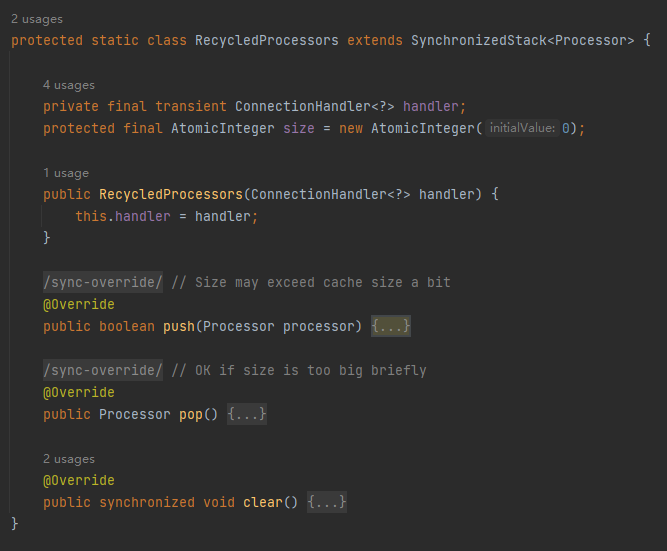
這個類的方法也特別簡單,就三個方法:push、pop、clear。
繼承至 SynchronizedStack 物件,就是一個標標準準的棧結構,只不過是用 Synchronized 修改了對應的方法:
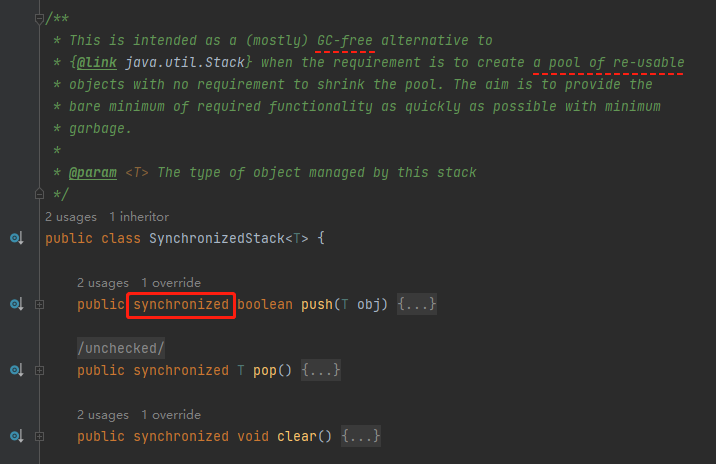
在 SynchronizedStack 類的註釋上提到了這是一個物件池、這個物件池不需要縮容、目的是為了減少垃圾物件,釋放 GC 壓力。
現在我們找到了這個物件池,也找到了呼叫這個物件池 pop 的地方。
那麼什麼時候往這個物件池 push 呢?
我也不知道。
所以第三個斷點就來了,可以打在 push 方法上:
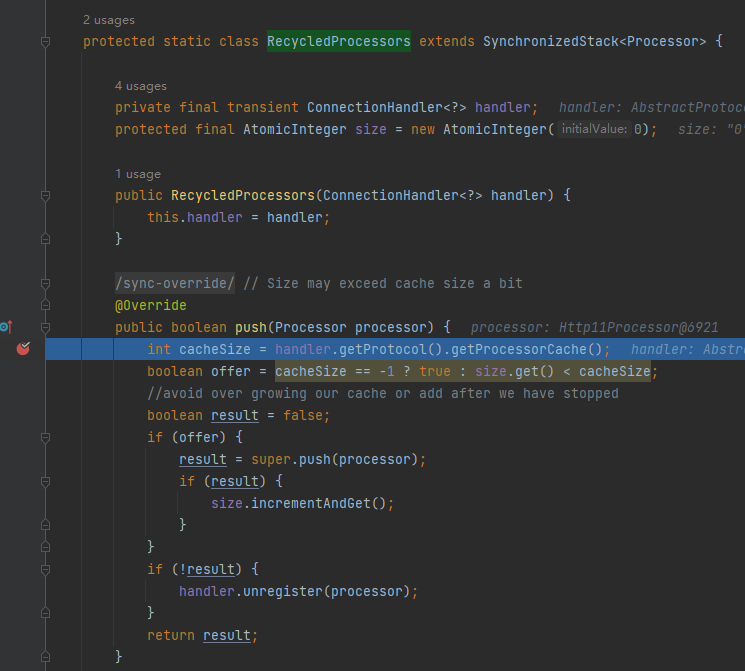
然後發起呼叫,發現是在請求處理完成,release 當前 processor 的時候,就把這個 processor 放到 recycledProcessors 裡面去,等著下一次請求使用:
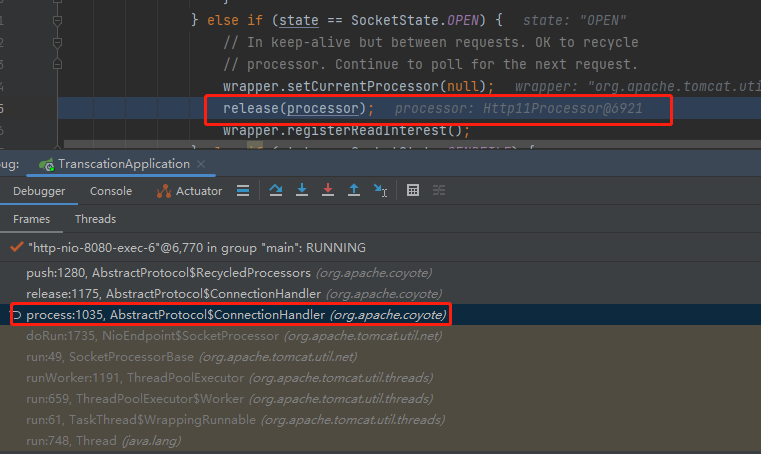
此時我們已經掌握了這樣的一個閉環:
當請求來了之後,先看 recycledProcessors 這個棧結構裡面有沒有可用的 processor,沒有則呼叫 createProcessor 方法建立一個新的,接著在請求結束之後,將其放入到棧結構裡面。
而在呼叫 createProcessor 方法的時候,會構建一個新的 Request 物件,最終這個 Request 物件會封裝為 RequestFacade 物件。
所以我現在想要驗證 Processor、Request 和 RequestFacade 三者之間有這樣的一個對應關係。
怎麼驗證呢?
列印紀錄檔。
注意,接下來又是一個偵錯小技巧了。

我想要在選定 processor 之後,加入一行輸出語句:
怎麼加呢?
在自己的專案裡面建立一個和原始碼一樣的包路徑,然後把對應的類直接貼上過來:
因為是在自己的專案裡面,你想怎麼改都行:
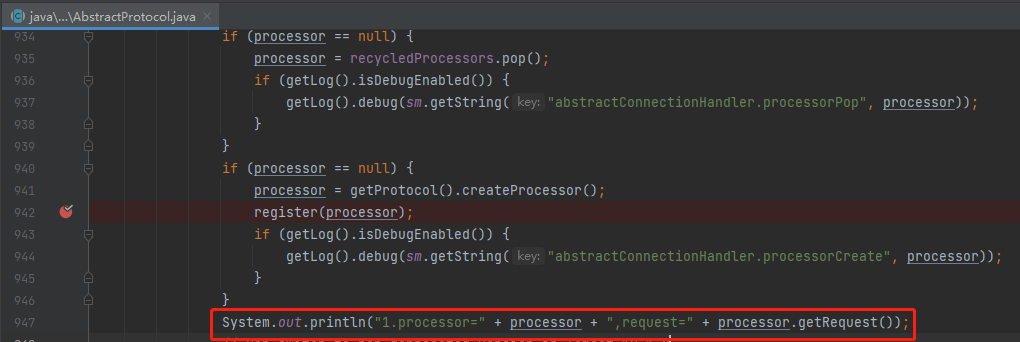
比如我加入這個輸出語句,列印出 processor 和裡面的 request。
發起請求之後你會發現確實生效了,但是 reuqest 的輸出是這樣的:
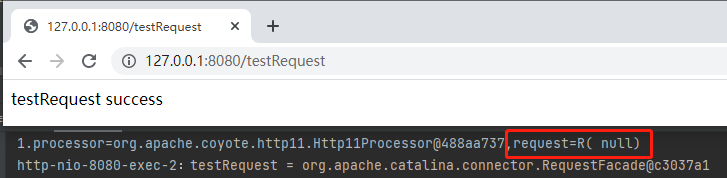
為什麼呢?
因為在原始碼裡面,這個類的 toString 方法被重寫了:
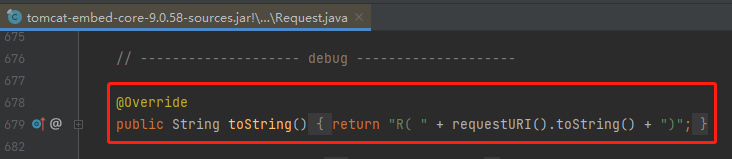
怎麼辦?
改原始碼啊,剛剛才教你了的:
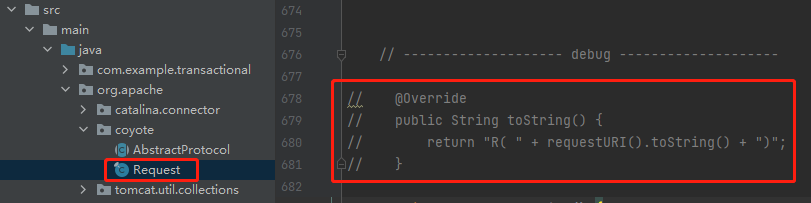
修改之後發起呼叫,就可以在控制檯看到對應的預期的輸出了:
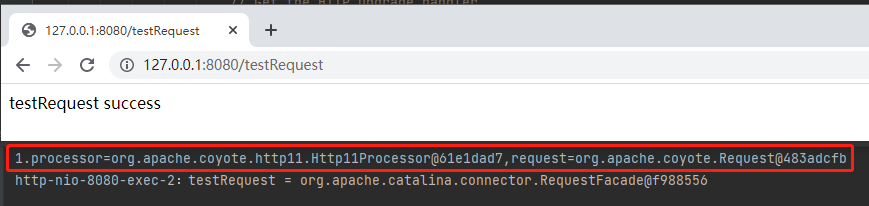
你看,processor 裡面有個 request。現在我要找的是 request 和 RequestFacade 之間的關係。
很簡單,在 getRequest 方法這裡也輸出一行:
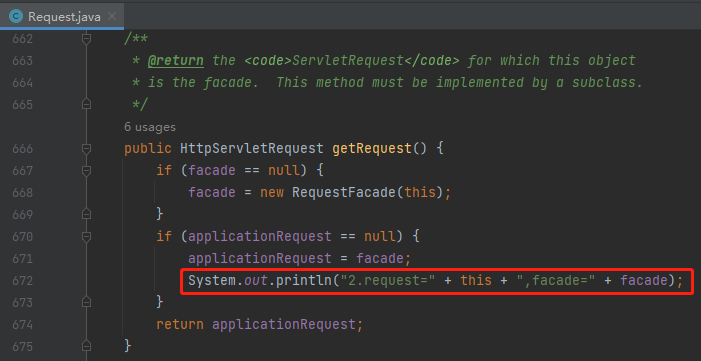
發起呼叫之後,發現,完犢子了:

這兩個 Request 根本就不是同一個玩意啊:
org.apache.coyote.Request@667cbb30
org.apache.catalina.connector.Request@9ffc697
不要慌,冷靜下來細嗦一下,雖然這是兩個不同的 Request,但是它們之間一定有著千絲萬縷的聯絡。
先看一下 org.apache.catalina.connector.Request 是怎麼來的,老規矩,構造方法上打斷點:
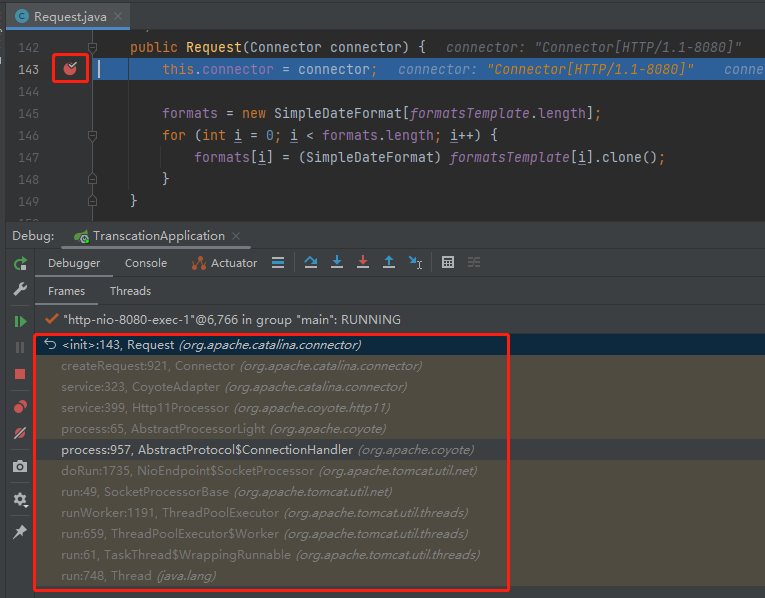
基於這個呼叫堆疊,往前找一點點,就能看到一個值得注意的地方:
org.apache.catalina.connector.CoyoteAdapter#service
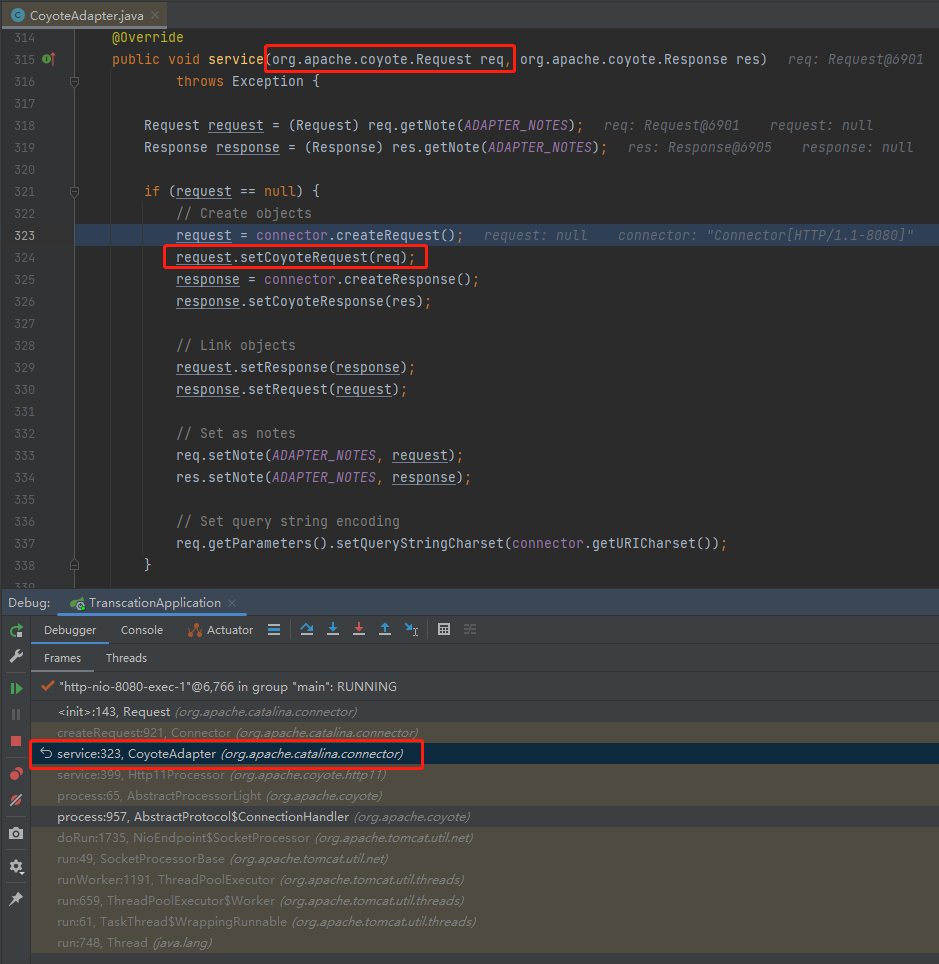
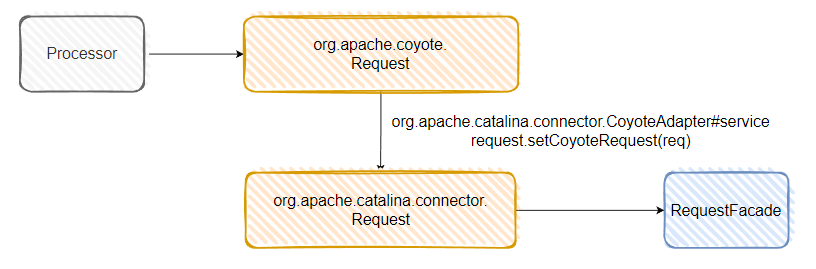
在上面截圖的這個方法中,有一行這樣的程式碼:
request.setCoyoteRequest(req);
其中 request 是 org.apache.catalina.connector.Request 物件。
而 req 是 org.apache.coyote.Request 物件。
也就是說,我這裡的這個輸出語句應該是這樣的才對:
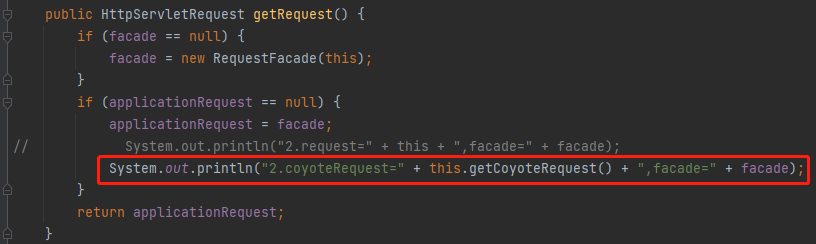
修改之後,再次發起呼叫,輸出紀錄檔是這樣的:

如果你還沒看出點什麼的話,我給你加工一下:
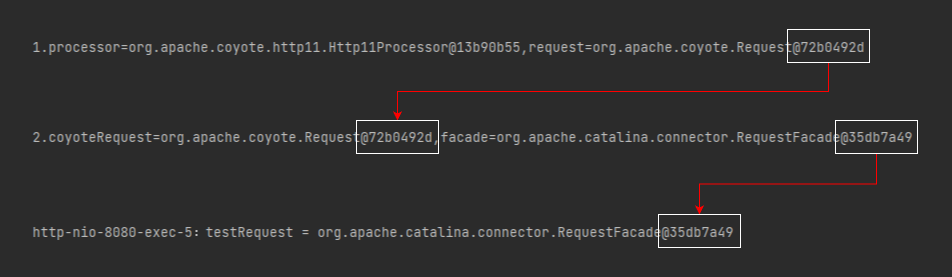
意思就是 Processor 和 RequestFacade 確實是一一對應的。
回到文章最開始的這個截圖,為什麼我發起兩次請求,RequestFacade 物件是同一個呢?
因為兩次請求用的是同一個 Processor 呀。
你看我再發起兩次請求,都是 Http11Processor@26807016 在處理:

所以,表面上看是同一個 RequestFacade,實質上是用的同一個 Processor。
換句話說:要是兩個請求用的是不同的 Processor,就不會存在複用的情況。
怎麼驗證一下呢?
我想到了下面的這個驗證方式:
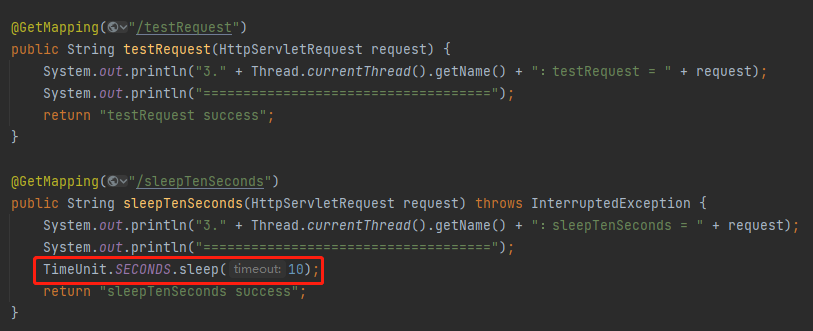
我可以先請求 sleepTenSeconds,然後在 10s 內請求 testRequest。這樣,我就能觀察到兩個不同的 Processor:
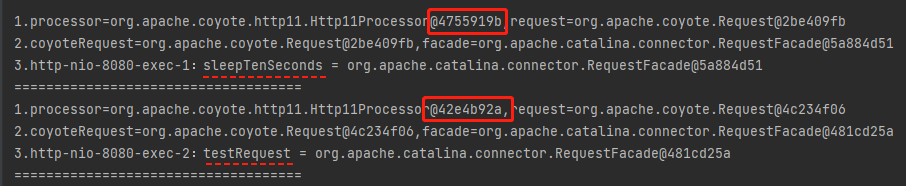
為了更加直觀的看到這個現象。
我決定在操作 recycledProcessors 的 pop 方法之前和 push 方法之後,輸出一下 recycledProcessors 裡面的內容:
org.apache.coyote.AbstractProtocol.RecycledProcessors
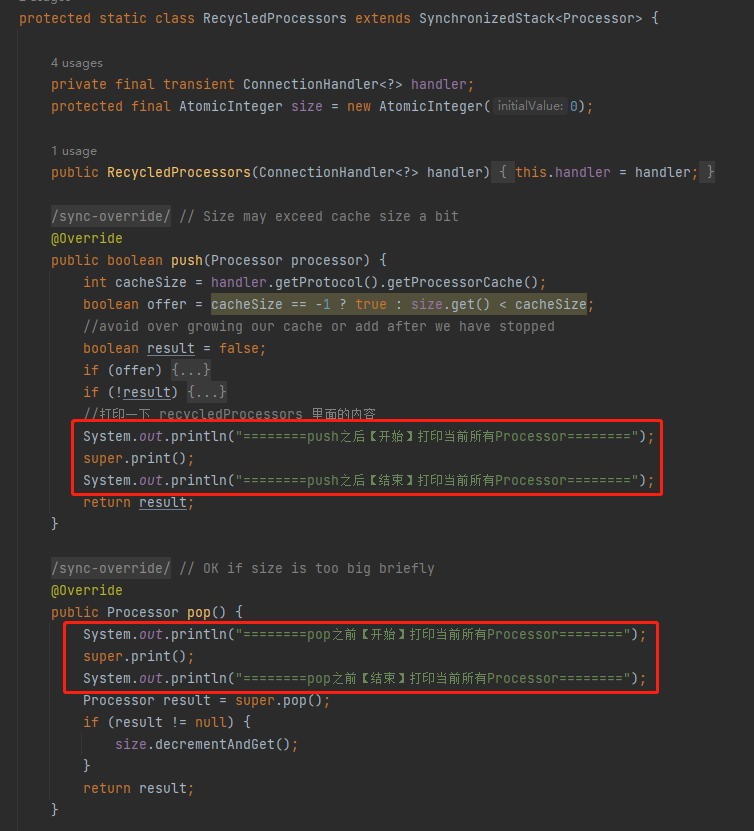
但是你按照我這樣寫的時候會發現: RecycledProcessors 的父類別,也就是 SynchronizedStack 類並沒有提供 print 方法,怎麼辦呢?
很簡單嘛,原始碼我都可以拿到,加一個方法,還不是手到擒來的事情?
接著,我還是按照先存取 sleepTenSeconds 再存取 testRequest 方法的順序發起請求,紀錄檔是這樣的:
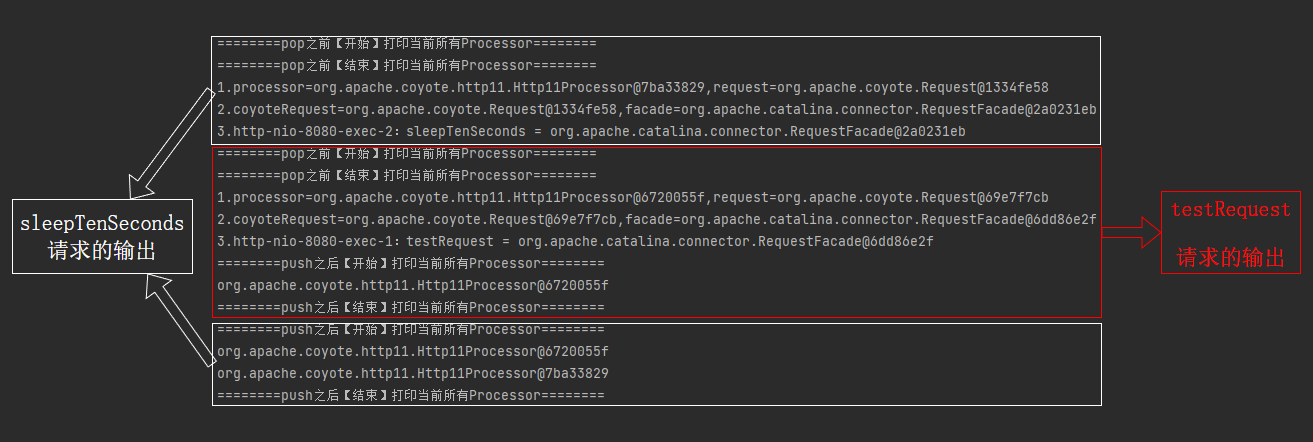
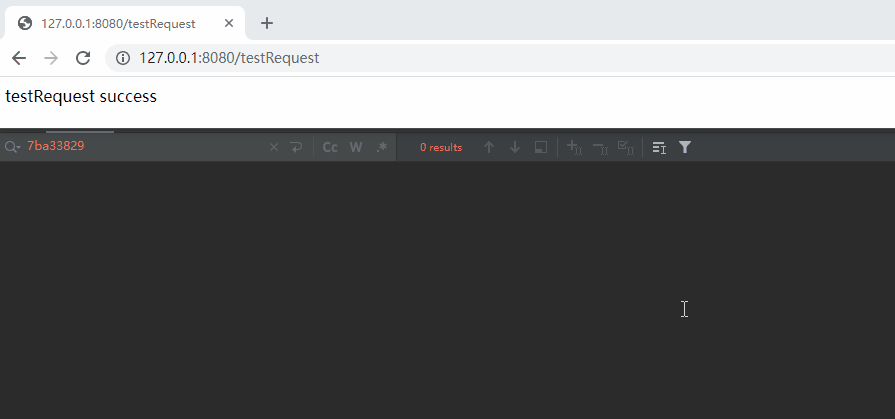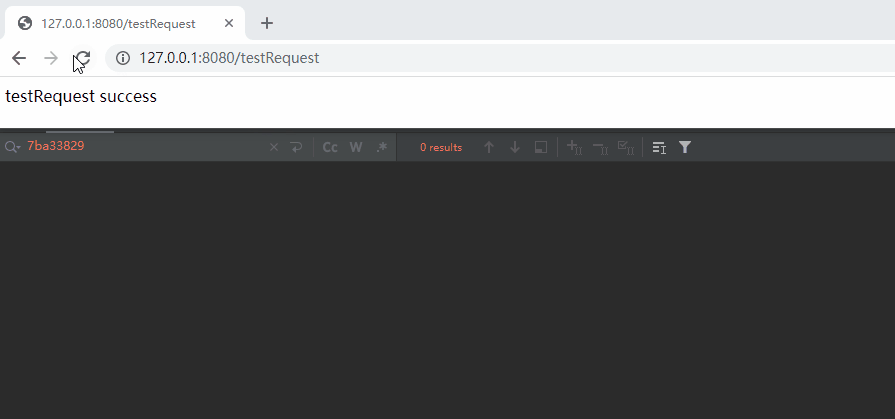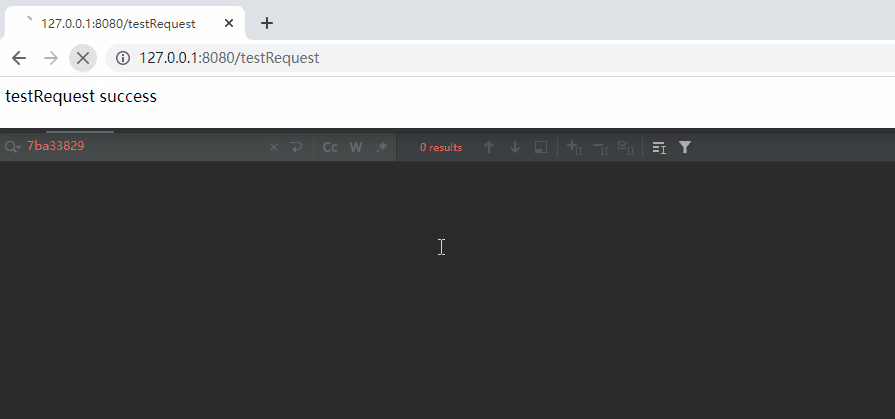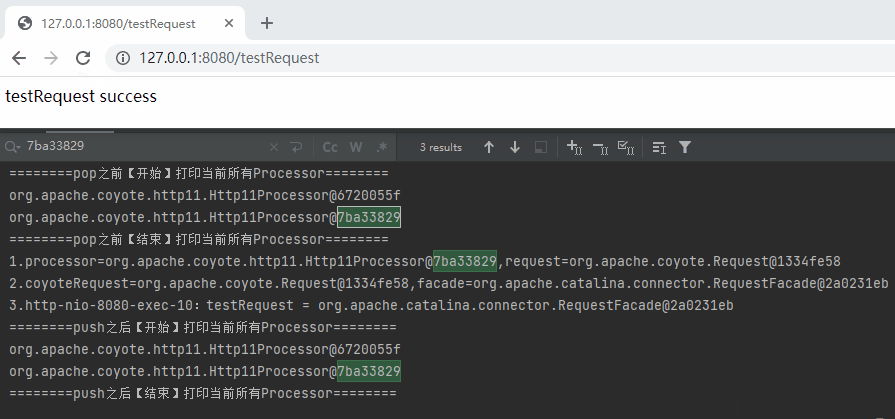
單獨拿出來,testRequest 整個請求完成之後,對應的紀錄檔是這樣的,
========pop之前【開始】列印當前所有Processor========
========pop之前【結束】列印當前所有Processor========
1.processor=org.apache.coyote.http11.Http11Processor@6720055f,request=org.apache.coyote.Request@69e7f7cb
2.coyoteRequest=org.apache.coyote.Request@69e7f7cb,facade=org.apache.catalina.connector.RequestFacade@6dd86e2f
3.http-nio-8080-exec-1:testRequest = org.apache.catalina.connector.RequestFacade@6dd86e2f
========push之後【開始】列印當前所有Processor========
org.apache.coyote.http11.Http11Processor@6720055f
========push之後【結束】列印當前所有Processor========
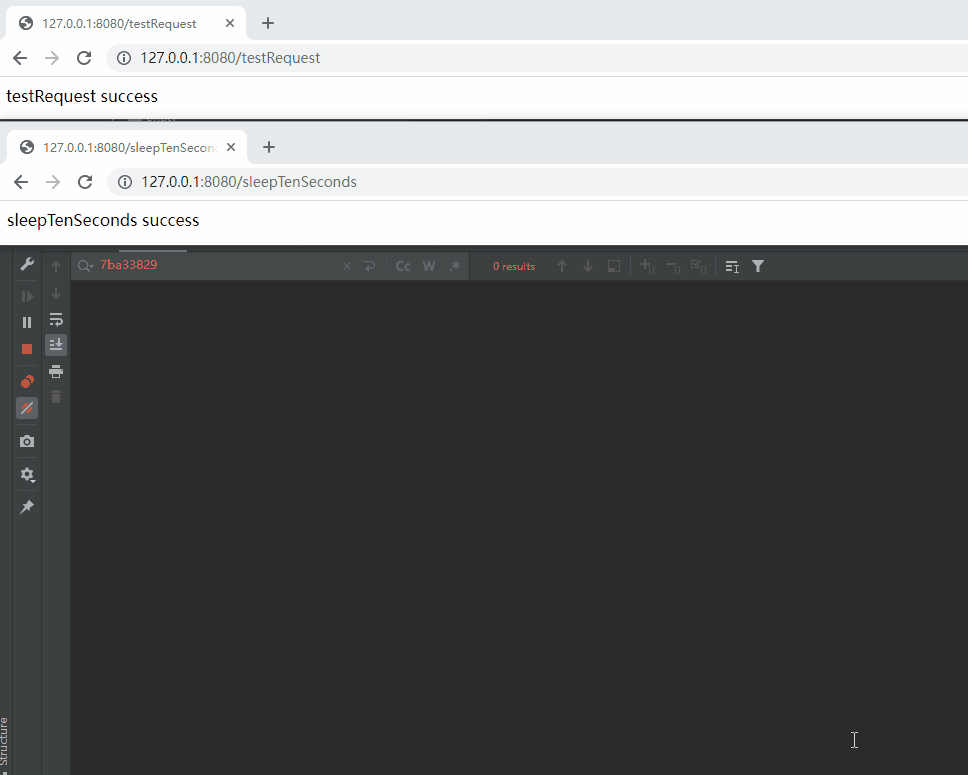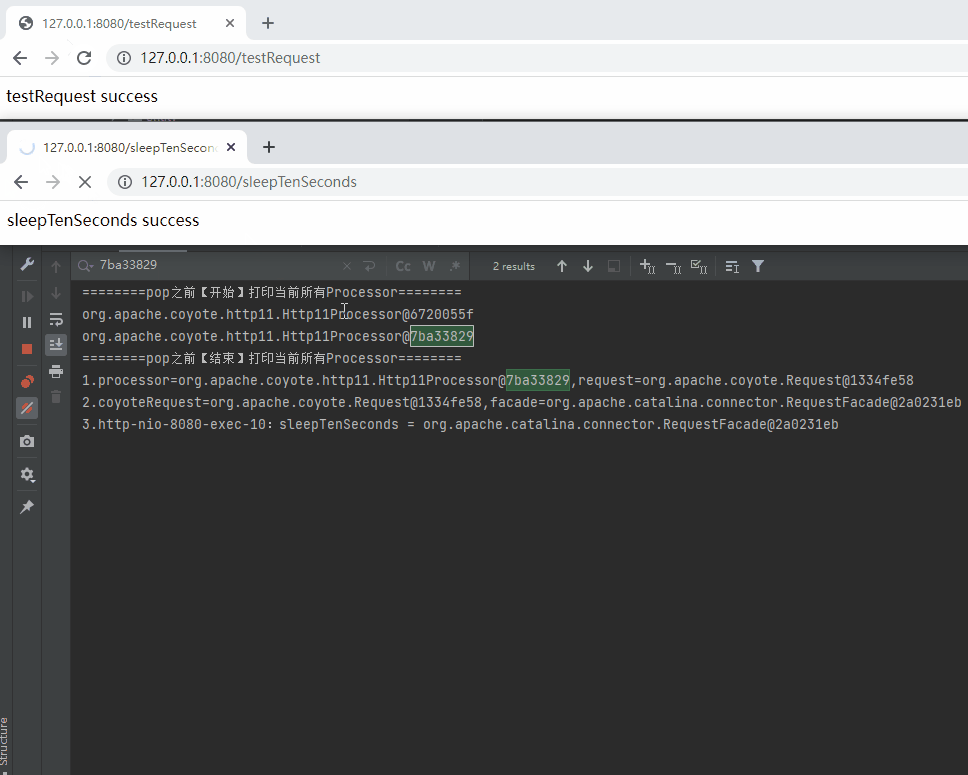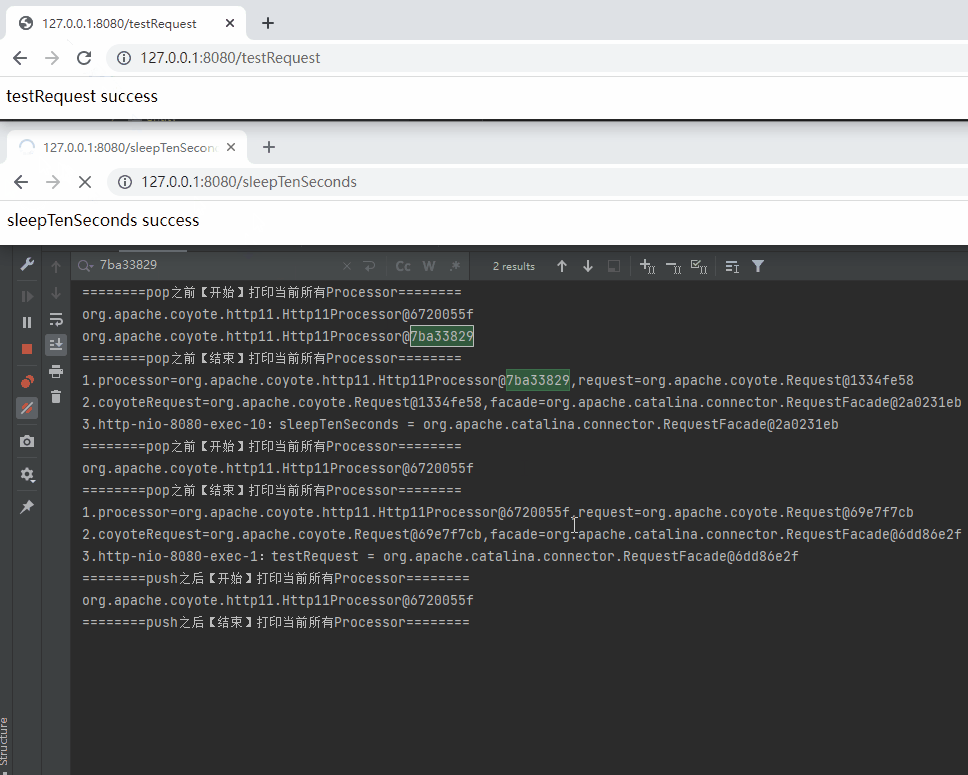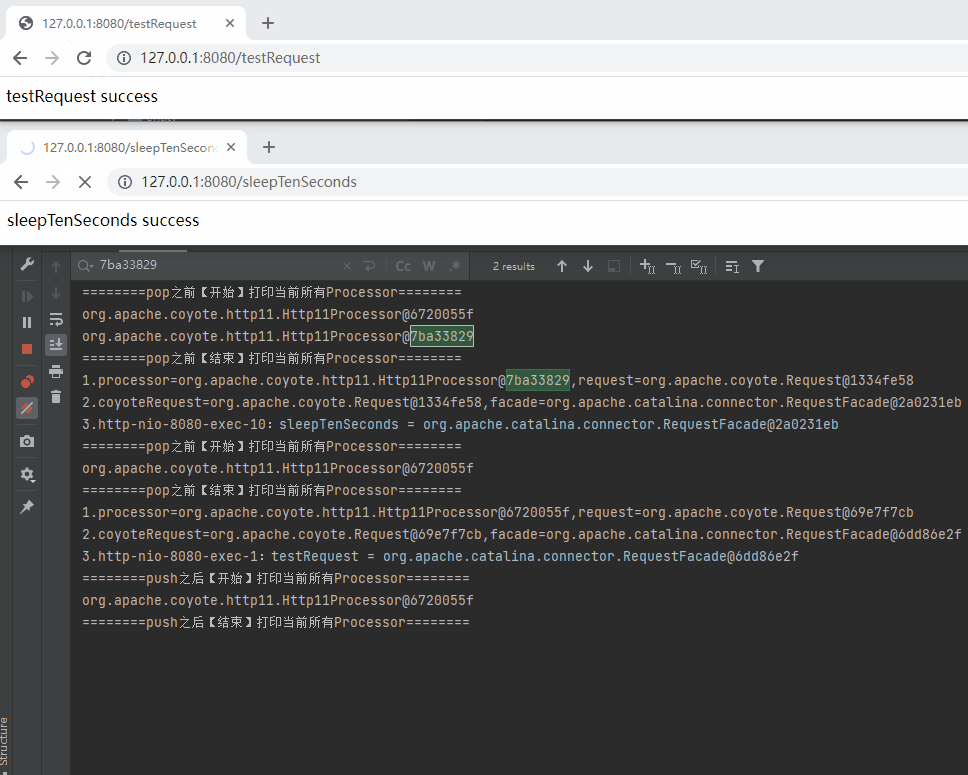
而 sleepTenSeconds 整個請求完成之後,對應的紀錄檔是這樣的:
========pop之前【開始】列印當前所有Processor========
========pop之前【結束】列印當前所有Processor========
1.processor=org.apache.coyote.http11.Http11Processor@7ba33829,request=org.apache.coyote.Request@1334fe58
2.coyoteRequest=org.apache.coyote.Request@1334fe58,facade=org.apache.catalina.connector.RequestFacade@2a0231eb
3.http-nio-8080-exec-2:sleepTenSeconds = org.apache.catalina.connector.RequestFacade@2a0231eb
========push之後【開始】列印當前所有Processor========
org.apache.coyote.http11.Http11Processor@6720055f
org.apache.coyote.http11.Http11Processor@7ba33829
========push之後【結束】列印當前所有Processor========
也就是說,此時 recycledProcessors 裡面有兩個 Processor:
========push之後【開始】列印當前所有Processor========
org.apache.coyote.http11.Http11Processor@6720055f
org.apache.coyote.http11.Http11Processor@7ba33829
========push之後【結束】列印當前所有Processor========
那麼問題就來了:你說我接下來再次發起一個請求,哪個 Processor 會來承接這個請求呢?
雖然我還沒有發起請求,但是我知道,一定是 Http11Processor@7ba33829 來進行處理。
因為我知道它將是下一個被 pop 出來的 Processor 物件。
不信,你就看這個動圖:
在上面的動圖中,我先是 testRequest 這個請求。
如果我先存取 sleepTenSeconds,再存取 testRequest 呢?
雖然我還沒有發起請求,但是我知道,一定是這樣的對應關係來處理這兩次請求:
sleepTenSeconds->Http11Processor@7ba33829
testRequest->Http11Processor@6720055f
因為 sleepTenSeconds 請求來的時候,recycledProcessors 裡面會 pop 出 Processor@7ba33829 這個物件,來處理這個請求。
所以在 10 秒內,也就是 sleepTenSeconds 請求未完成的時候,存取 testRequest 請求,recycledProcessors 裡面接著 pop 出來的 就是 Http11Processor@6720055f 這個物件。
不信的話,你再看這個動圖:
所以,現在我們是不是找到這個問題的答案了:
如何決定哪個執行緒每次複用那個request呢?
請求執行緒和 request 之間沒有關聯關係。每次請求使用哪個 request 取決於使用哪個 Processor。而每次請求使用哪個 Processor,取決於 recycledProcessors 類裡面快取了哪些 Processor。請求過來的時候,pop 出來哪個,就是哪個。
recycledProcessors 既然是一個快取,它的大小,一定程度上決定了專案的效能。
而它的預設值是 200:
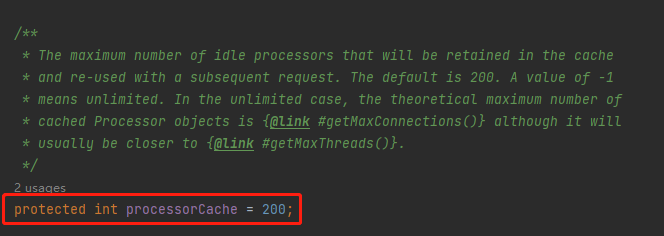
為什麼是 200 呢?
因為 tomcat 執行緒池的最大執行緒數預設就是 200:
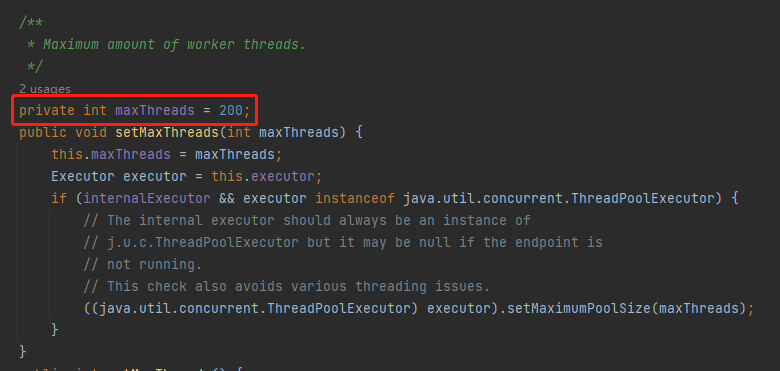
這個能想明白吧?
雖然執行緒和 Processor 之間沒有繫結關係,但是從邏輯上講一個執行緒對應一個 Processor。因此,好一點的做法是讓執行緒數和 Processor 的數量保持一致。
如果我把 processorCache 這個引數修改為 1:
server.tomcat.processor-cache=1
你說高並行的時候會發生什麼事情呢?
很多請求 push 的時候會 push 不進去,從而走到 handler.unregister(processor) 的邏輯裡面去:
而這個 unregister 方法,對應的還有一個 register 方法,我一起給你看看:
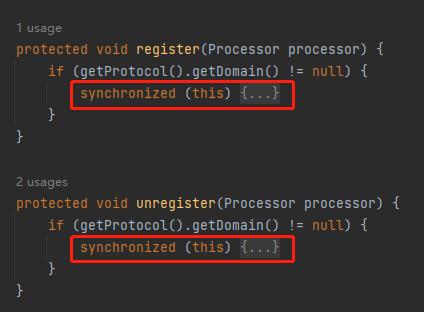
它們持有的是同一筆 synchronized 鎖,說明它們之間有競爭。
我們知道,一個請求結束之後會呼叫 RecycledProcessors 的 push 方法,而 push 的時候會呼叫 unregister 方法。
那麼問題就來了:register 什麼時候呼叫呢?
其實前面已經出現過了:
一個請求來了,建立完 processor 之後。
所以,當我把 processorCache 設定為 1,高並行的情況下,在不停的呼叫 register 和 unregister,鎖競爭頻繁,效能下降。
這個結論,就是我通過翻閱原始碼得出來的結論,而不是在其他的某個書上或者視訊裡面得到的一個現成的結論。
這就是翻閱原始碼的快樂和意義。

回手掏
寫到這裡的時候,我不由的想起了我在《千萬不要把Request傳遞到非同步執行緒裡面!有坑!》這篇文章中踩到的坑。
再看一下這個動圖,主要關注兩次呼叫的時候控制檯對應的輸出:
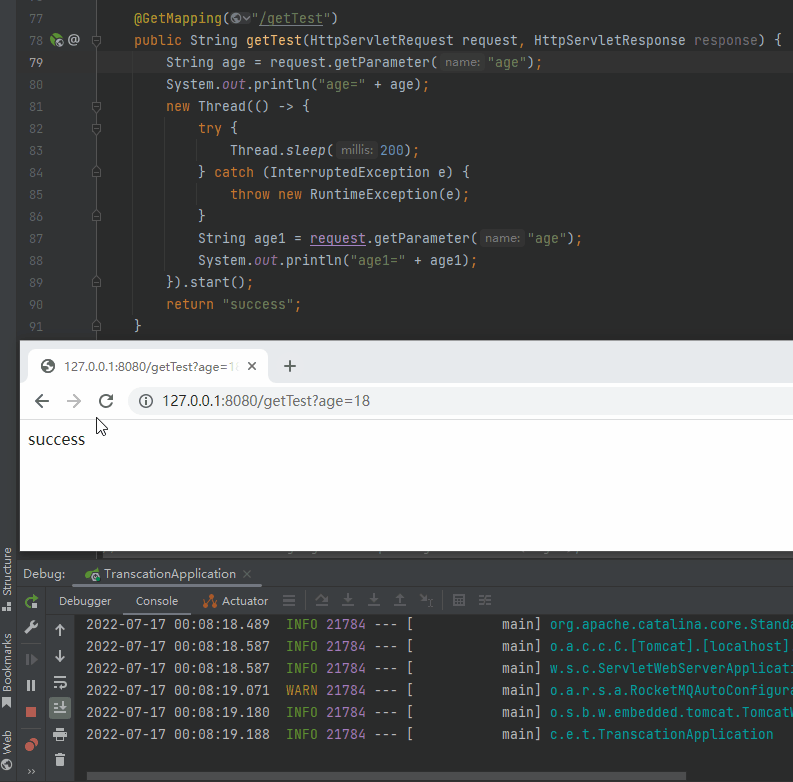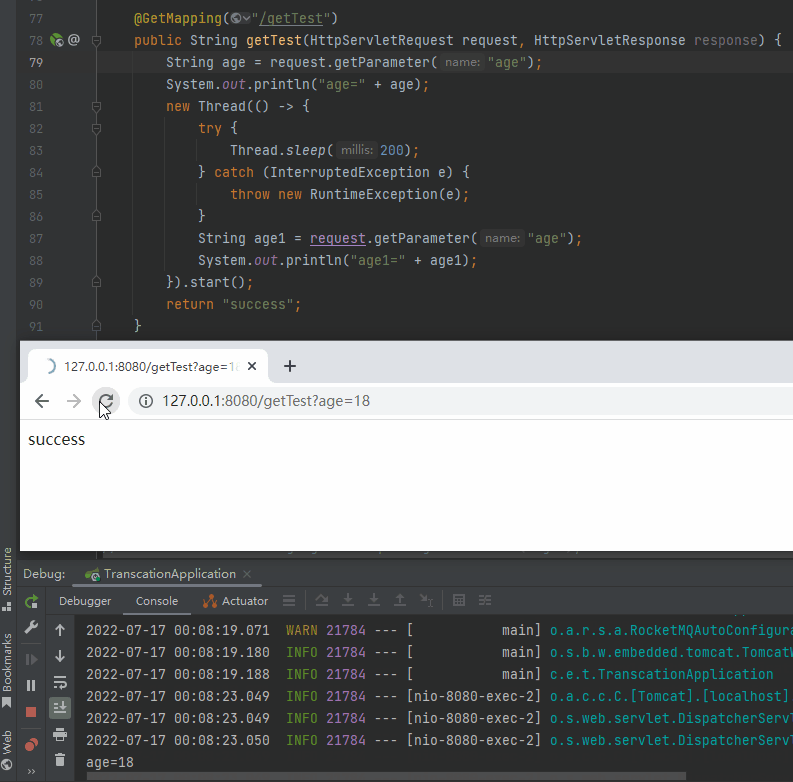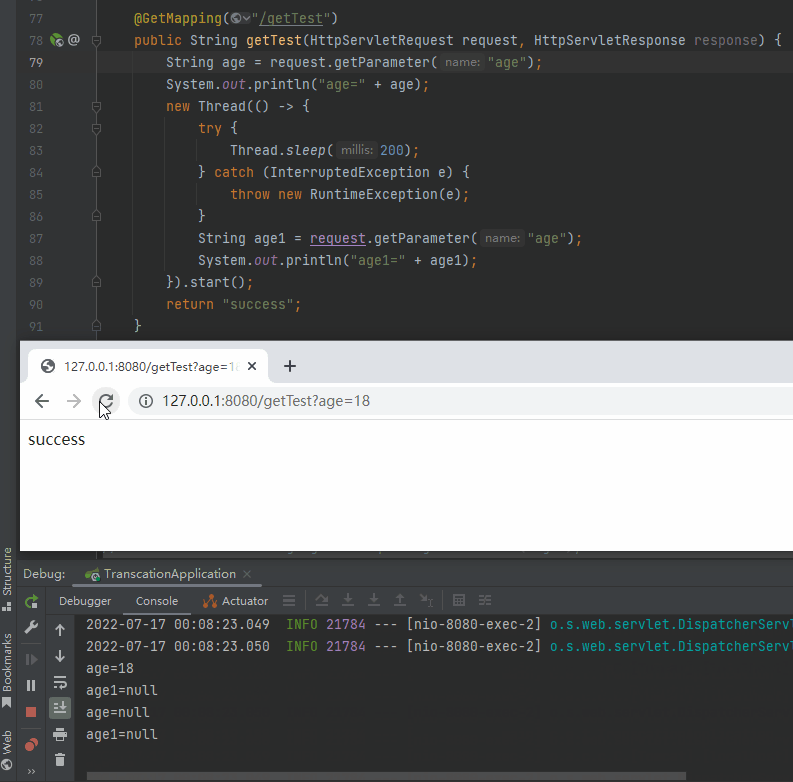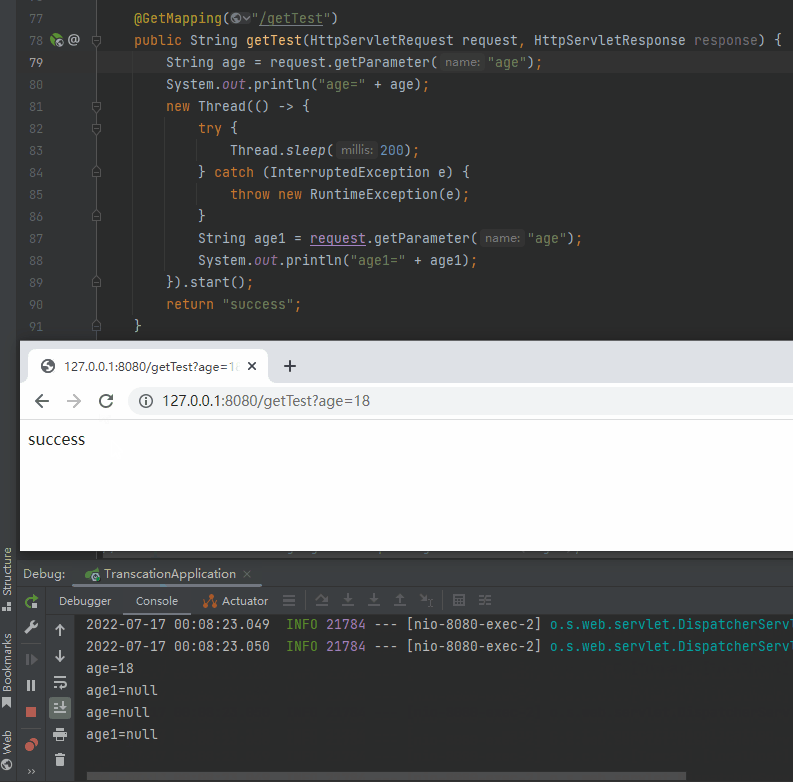
就是因為在 Request 的生命週期之外使用了它,導致複用的時候出現了問題。
當時我給出的正確方案是使用 Request 的非同步程式設計,也就是 startAsync 和 AsyncContext.complete 方法那一套。
但是這篇文章寫完之後,我又想到了兩個騷操作。
第一個方法,就藏在我前面說的 RECYCLE_FACADES 這個設定中。
從官方檔案上的描述來看這個引數如果設定為 true 會提高安全性,但是它預設是 false。
它怎麼提高安全性呢?
就是每次把 RequestFacade 也給回收了。
那我把它改成 true 試一試,看看啥效果:
-Dorg.apache.catalina.connector.RECYCLE_FACADES=true
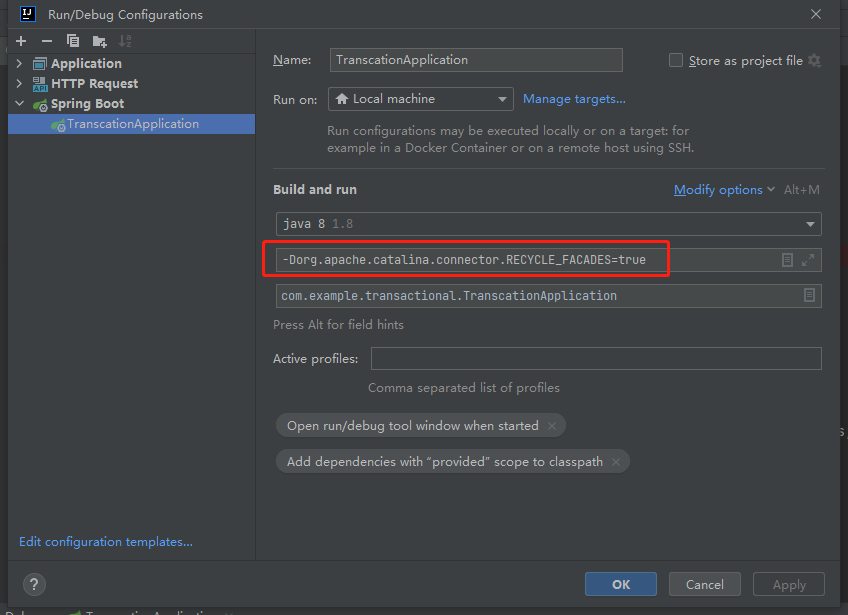
啟動專案,發起呼叫:
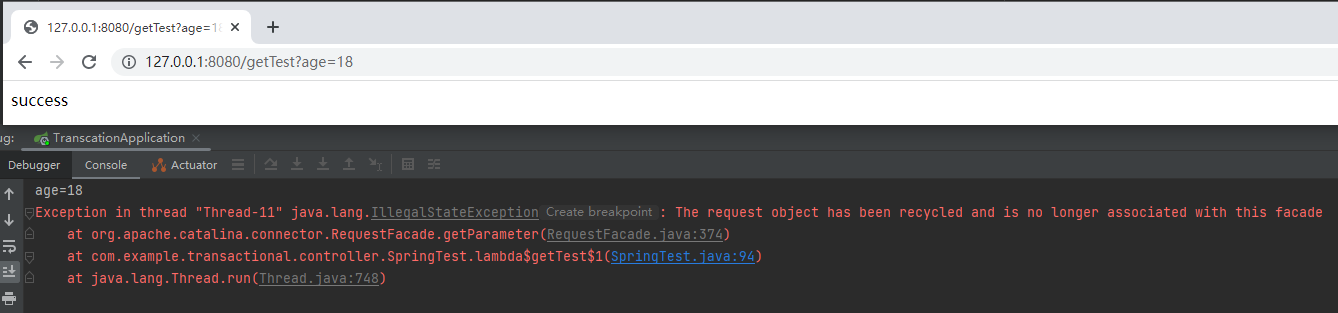
丟擲了一個異常。
看到這個異常的時候,我一下就明白了官方檔案裡面說的「安全性」是什麼意思了:你的用法錯誤了,我給你拋個異常,給你提醒一下,這裡需要進行修改,提升安全性。
而第二個是這樣的:
server.tomcat.processor-cache=0
你明白我意思吧?
我直接不讓你複用了,每次都用新的,繞過複用這個「坑」:
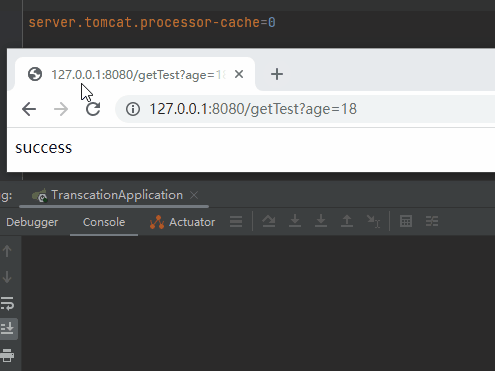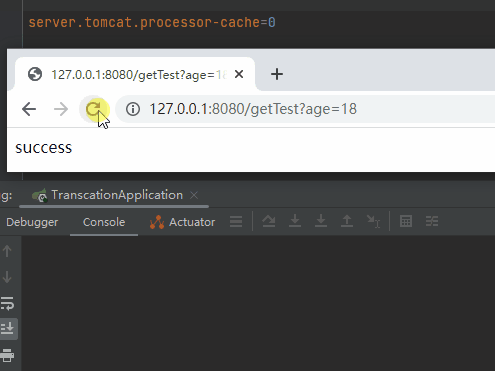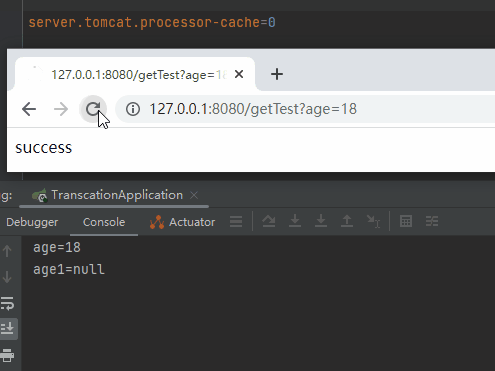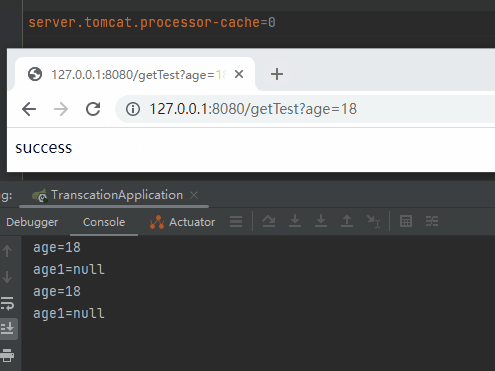
先別管它好不好用,有沒有效能問題,你就說在徹底理解了底層邏輯之後,這個操作騷不騷吧。