作業系統之虛擬記憶體總結
前言
作業系統為每個程序提供了一個假象:它擁有屬於自己的大量的私有記憶體,可以有巨大的連續地址空間放入自己的程式碼和資料。使用者程式中存取的地址都是虛擬地址,需要經過作業系統和硬體的協同工作將這個虛擬地址翻譯為實體地址,找到想要的資訊。之所以提供這樣的假象,是為了隔離和保護,沒有人會希望一個惡意程序隨意修改別的程序的程式碼和資料。
地址轉換
動態重定位
在介紹現代作業系統使用的地址轉換機制之前,我們先來看一個簡單的地址轉換方法——動態重定位。這個簡單的方法建立在一些假設之上:
- 使用者的地址空間必須連續地放在實體記憶體中
- 地址空間不是很大,具體來說,小於實體記憶體的大小
- 每個地址空間的大小完全一樣
後面會逐步放寬這些假設,不過為了讓動態重定向工作起來,我們先勉為其難地接受這些假設。
動態重定位也稱為基址加界限機制,這麼叫的原因是,每個 CPU 需要兩個硬體暫存器(放在記憶體管理單元 MMU 中):基址暫存器和界限暫存器,讓我們能夠將地址空間放在實體記憶體的任何位置,同時又能確保程序只能存取自己的地址空間。我們編譯出來的程式虛擬地址空間從 0 開始,但是當程式跑起來的時候,作業系統會將程式的地址空間加上由基址暫存器所儲存的偏移量,比如基址暫存器的值為 32KB,程式存取的虛擬地址為 1KB,那麼實際存取的實體地址會是 33KB。我們接著假設實體記憶體為 64KB,每個程序的虛擬記憶體大小為 16KB,那麼界限暫存器既可以存虛擬記憶體的大小 16KB,也可以存程序在實體地址空間的結束位置,如下圖所示的 48KB。當程式中存取的虛擬記憶體超過界限暫存器規定的範圍時,會引發越界錯誤,作業系統可以殺死該程序。

現在站在一個高層次來觀察動態重定位,它其實就是將實體記憶體進行 N 等分出 N 個大小為虛擬記憶體大小的槽,每個程序會對應一個槽。這種方法的優點很明顯,就是簡單且快速。但是缺點也很明顯,如果我們程式實際只佔用了 4KB 的空間(堆和棧之間有一大段空間沒被使用),你卻給他分配了 16KB,這就造成內部碎片,有 12KB 的實體記憶體被白白浪費了,而別的程序卻無法使用。
分段
為了解決動態重定位中的內部碎片問題,我們放寬第一個假設,不再要求使用者的地址空間必須連續地放在實體記憶體中。我們對虛擬地址空間進行分段,比如程式碼、堆和棧各一段,如下圖所示,每個段只佔用了 2KB,程序只佔用了 6KB 的實體記憶體:
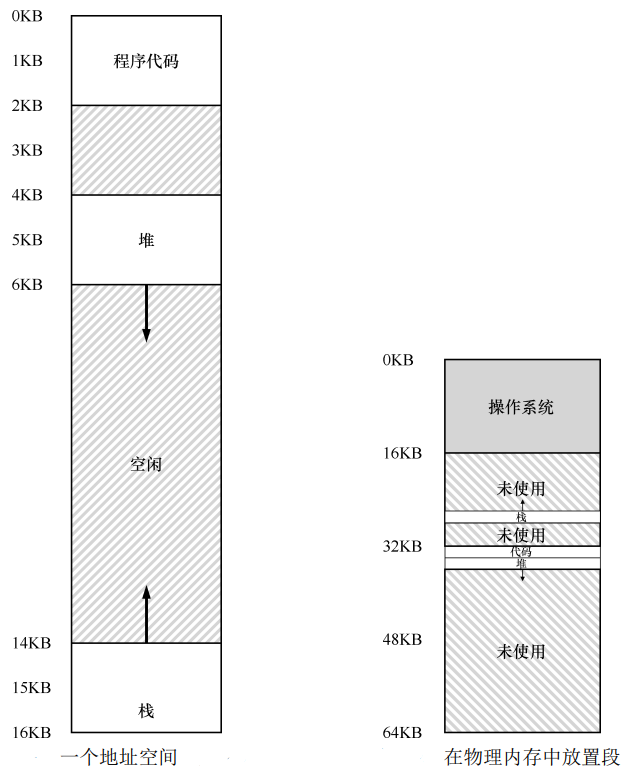
為了支援分段,MMU 中現在不止一對基址加界限暫存器,而是需要三組。這種分段方法帶來了一個問題:給定一個虛擬地址,如何判斷該地址所屬的段?如果我們不知道所屬的段,就無法存取正確的基址暫存器和界限暫存器。一種可行的判斷方法,是對虛擬地址進行切分,比如虛擬地址 4200,它處於堆中,我們將地址的高二位解釋為地址所屬段的編號(00 為程式碼,01 為堆,10 為棧),剩下的位就是在段內的位元組偏移量:

分段方法比較好地解決了內部碎片的問題,卻又帶來了一個新問題:每個程序的各個段大小可以不同,隨著實體記憶體的不斷切分,可能會出現許多較小的空閒空間,這些空間太小以至於無法被別的段所使用,即使所有空閒空間的總和大於段大小,也無法被利用,這種問題稱為外部碎片。
分頁
分段中外部碎片的起因就是各個段的大小不一,如果我們同樣對地址空間進行分割,分割出來的每個頁(或者稱為塊)固定大小,比如 4KB,這樣就不會有外部碎片的問題了。然後我們在虛擬記憶體頁和實體記憶體頁之間建立一個對映關係,比如下圖中(虛擬頁 0→物理幀 3)、(VP 1→PF 7)、(VP 2→PF 5)和(VP 3→PF 2),我們將每個程序的這種對映關係儲存在一個資料結構中,稱為頁表。

有了頁表之後,每次要想知道虛擬記憶體在哪,只要去記憶體中查下表就行了(頁表地址由 CR3 暫存器給出),聽起來貌似很簡單,但是和分段類似,為了知道虛擬頁對應的物理幀的編號記錄在頁表的哪個條目上,我們需要對虛擬地址進行切分。
如下圖所示,虛擬記憶體大小為 64B(6 位),實體記憶體大小為 128B(7 位),每個虛擬頁的大小為 16B,所以我們可以將虛擬記憶體分為 4 頁,對每個虛擬頁進行編號需要 2位,每個頁 16B 需要 4 位的偏移量來描述,加起來正好 6 位。所以我們將虛擬地址的高二位解釋為虛擬頁號(VPN),剩下 4 位解釋為頁內偏移量。
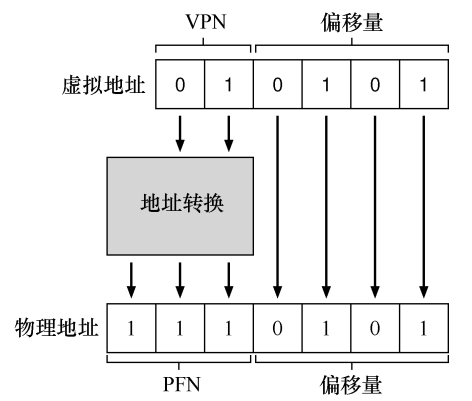
現在假設我們的頁表只是一個線性陣列,我們使用 VPN 對該陣列進行索引,得到一個頁表條目(PTE),一個 32 位 x86 頁表條目結構如下圖所示:

每個條目會有幾位對應物理頁號(PPN 或 PFN),回到我們的例子中就是會有 3 位對應物理頁號(0b111),將 0b111 和偏移量 0101 進行拼接就得到了實體地址 0b1110101。
分頁機制雖然好用,但是也存在著一些問題。
第一個問題就是頁表大小。假設我們虛擬地址 32 位,頁大小為 4KB,我們就需要將虛擬記憶體切為 \(2^{32}/2^{12}=2^{20}\) 個虛擬頁,為了儲存這些頁的對映關係,我們的頁表的長度也得是 \(2^{20}\),如果每個 PTE 的大小是 4B,光是儲存一個程序的頁表就得佔用 \(2^{22}\) 位元組(4MB),如果有 100 個程序就得佔用 400MB 的實體記憶體,這顯然是無法接受的。
第二個問題就是翻譯速度。由於頁表儲存在記憶體中,每次對虛擬地址的轉換(包括指令獲取、資料載入和儲存)都得進行一次記憶體存取,程式執行速度變成了原來的一半。
TLB
先來解決第二個問題,參考快取的思想,我們可以將經常存取的對映關係放在一個特殊的快取硬體中,每次進行地址轉換的時候都先去查詢 VPN 對應的 PFN 在不在快取硬體裡面,在的話就皆大歡喜,不在就得老老實實去找頁表要了。
這樣的一個硬體稱為地址轉換旁路緩衝記憶體,簡稱 TLB。TLB 中儲存的每個條目結構為 VPN | PFN | 其他位,其他位中可以包括有效位、保護位、髒位和地址空間識別符號,各個位的含義這裡不再贅述。
多級頁表
接著解決第一個問題,頁表太大的原因,在於我們將所有對映關係儲存在一個頁表中,即使有的對映關係並不存在,也得在頁表中佔一個位置。如果我們能對一個頁表進行拆分,拆成一個頁目錄和多個實際儲存對映關係的頁表,頁目錄中的每一個條目指向一個頁表,不存在實際對映關係的頁表可以不被分配記憶體,這樣就能節省很多空間,如下圖右側所示。

為了支援二級頁表,我們需要對虛擬地址的 VPN 部分進行細分。假設我們的虛擬地址空間為 16KB(14 位),頁大小為 64B,PTE 大小為 4B,為了完成對映,線性頁表中需要有 \(2^{14}/2^6=256\) 個 PTE,共佔用 1KB 空間。現在每個頁可以容納 \(64/4=16\) 個 PTE,如果將頁表拆成 \(256/16=16\) 個小頁表,對這些小頁表進行編號需要 4 位,每個小頁表中儲存的 PTE 編號也需要 4 位,剩下 6 位作為頁內偏移量。

假設虛擬地址為 0b11111110000000,由於前四位為 0b1111,所以對應的頁表編號為 15(最後一個頁表),接下來四位為 0b1110,說明 PTE 在此頁表的倒數第二個,假設這個 PTE 告訴我們 PFN 為 55(0b110111),由於偏移量數 0,那麼實體地址就是 0b00110111000000。
交換空間
現在來思考一個問題:如果系統有許多個程序,他們把實體記憶體給榨乾了,這時候又來了一個新的程序,它要求系統給它分配幾個頁來儲存程式碼,但是現在記憶體滿了,該怎麼辦?
解決這個問題的思路,就是在硬碟上開闢一部分空間,稱為交換空間,用於物理頁的移入和移出。需要從物理頁中挑出一個受害者,把它暫時儲存到交換空間中,這樣才能騰出空間給新程序。等到程序要用到這個被換出的頁時,就從硬碟中重新載入它。挑選受害者的方法有很多,比如先入先出、隨機挑選和 LRU 演演算法,由於 LRU 演演算法需要維護的資訊比較多,所以可以採用時鐘替換演演算法來近似,這裡不再贅述。
後記
虛擬記憶體還有許多知識點這裡沒有寫到,大家可以閱讀《作業系統導論》中的相關章節來自行學習。《作業系統導論》採用循序漸進的寫法,由易到難,將虛擬記憶體的面紗一層層解開,比起《深入理解計算機系統》中直接丟擲一大堆虛擬記憶體概念而言,《作業系統導論》的寫法更符合人類的認知過程,因此牆裂推薦這本書,以上~~