聯邦學習:聯邦場景下的多源知識圖譜嵌入
1 導引
目前,知識圖譜(Knowlege Graph)在醫療、金融等領域都取得了廣泛的應用。我們將知識圖譜定義為\(\mathcal{g}=\{\mathcal{E}, \mathcal{R}, \mathcal{T}\}\),這裡\(\mathcal{E}=\left\{e_{i}\right\}_{i=1}^{n}\)是由\(n\)個實體(entity)組成的集合,\(\mathcal{R}=\left\{r_{i}\right\}_{i=1}^{m}\)是由\(m\)個關係(relation)組成的集合。元組集合\(\mathcal{T}=\{(h, r, t) \in \mathcal{E} \times \mathcal{R} \times \mathcal{E}\}\)則建模了不同實體之間的關係。知識圖譜嵌入是知識圖譜在應用中非常重要的一步。我們先通過知識圖譜嵌入將知識圖譜中的實體和關係嵌入到embeddings向量,然後再在下游進行實體分類或者知識圖譜補全的任務。
對於知識圖譜嵌入任務我們常採用基於負取樣的交叉熵函數[1]:
這裡\((h,r,t)\)即知識圖譜中存在的元組,其對應的負樣本\((h,r,t^{-})\)即圖譜中不存在的元組;\(\sigma\)為sigmoid函數;\(P_{h}^{-}(\mathcal{E})\)為實體集\(\mathcal{E}\)的負取樣分佈(可能是關於\(h\)的),最簡單的設定為均勻分佈(不過易造成「假陰性結果」,即取樣實際上存在於圖譜中的負樣本,一種改進方法參見[2]);超引數\(\gamma>0\)。
這裡\(f_r(h, t)\)稱為Score function。適用於常見經典知識圖譜的Score function \(f_r(h, t)\)可以參見下圖。

這裡\(\textbf{h}, \textbf{r}, \textbf{t}\)是\(h, r, t\)對應的embeddings。\(\text{Re}(\cdot)\)表示復值向量的實值部分。\(\circ\)表示逐項乘積(即Hadamard乘積)。
在實際應用中我們常常面臨一系列來自不同資料持有方的知識圖譜,我們將其稱為多源知識圖譜(Multi-Source KG)。我們將來自\(K\)個不同資料持有方的知識圖譜集合記為\(\mathcal{G}=\left\{g_{k}\right\}_{k=1}^{K}=\left\{\left\{\mathcal{E}_{k}, \mathcal{R}_{k}, \mathcal{T}_{k}\right\}\right\}_{k=1}^{K}\),按照資料異構程度可分為以下兩種形式:
多源同領域
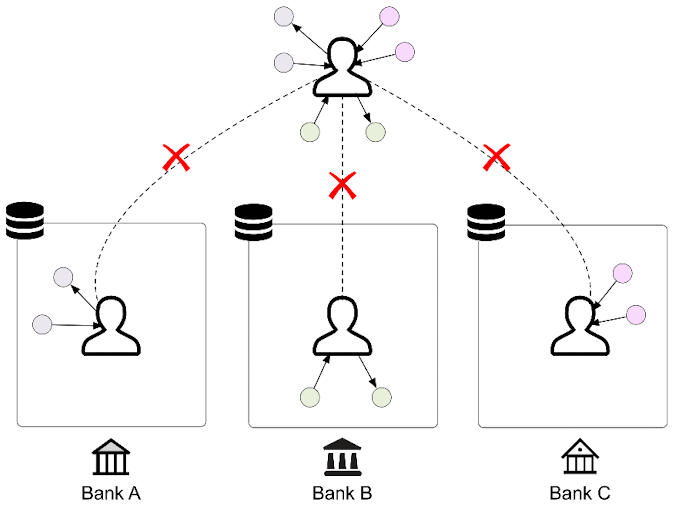
這種型別中各知識圖譜的領域(domain)相同,比如都是來自不同銀行的使用者知識圖譜。這些知識圖譜中也可能有實體重疊(overlapped),因為在日常生活中,一個使用者很可能在不同銀行都產生有相關的資料(元組)[2]。
多源跨領域
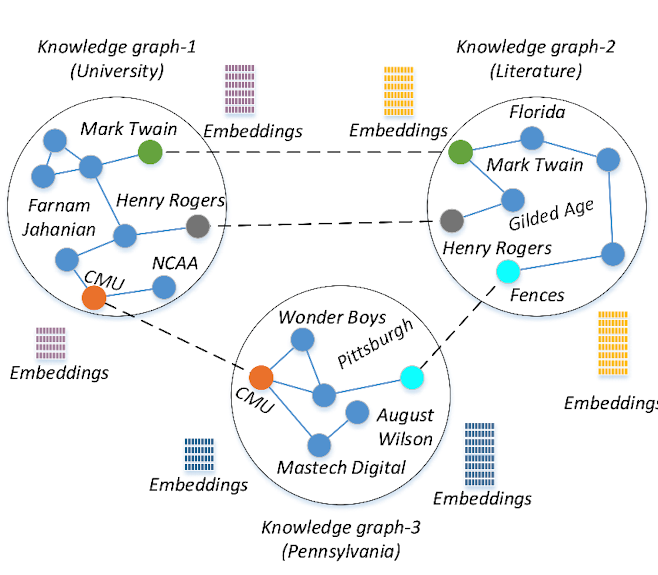
這種情況下資料更具有異構性,各個知識圖譜之間是跨領域(cross domain)的 ,如下圖中所示的大學(university)、文學(literature)和賓夕法尼亞州(pennsylvania)這三個不同領域的知識圖譜[3]。這種知識圖譜中也有可能出現實體重疊,比如CMU實體在大學知識圖譜和賓夕法尼亞州知識圖譜中就同時出現(當然在兩個知識圖譜中的嵌入向量是不同的)。
如果能讓在多個知識圖譜間進行知識共用,那麼很可能提高實體的嵌入質量與下游任務的表現。目前多源知識圖譜融合(cross source knowlege graph fusion)領域的工作大都是需要先將多個知識圖譜集中起來的。然而,在現實場景中,不同部門之間由於資料隱私的問題,共用資料是很困難的,那麼聯邦學習在這裡就成為了一個很好的解決方案。
在聯邦場景下,對於多源且同領域的情況,我們可以採用傳統FedAvg的思想,訓練一個讓多方共用的嵌入模型;然而對於多源且不同領域的情況,不同的知識圖譜就應當使用不同的嵌入模型。不過不論是在同領域和不同領域的情況下,都需要涉及對某些知識圖譜間重疊(也稱為對齊的,aligned)實體的embeddings進行統一(unify),以提高整體的學習效果,類似於分散式優化演演算法中聚合的意思。
2 聯邦多源知識圖譜嵌入論文閱讀
2.1 IJCKG 2021:《FedE: Embedding Knowledge Graphs in Federated Setting》[3]
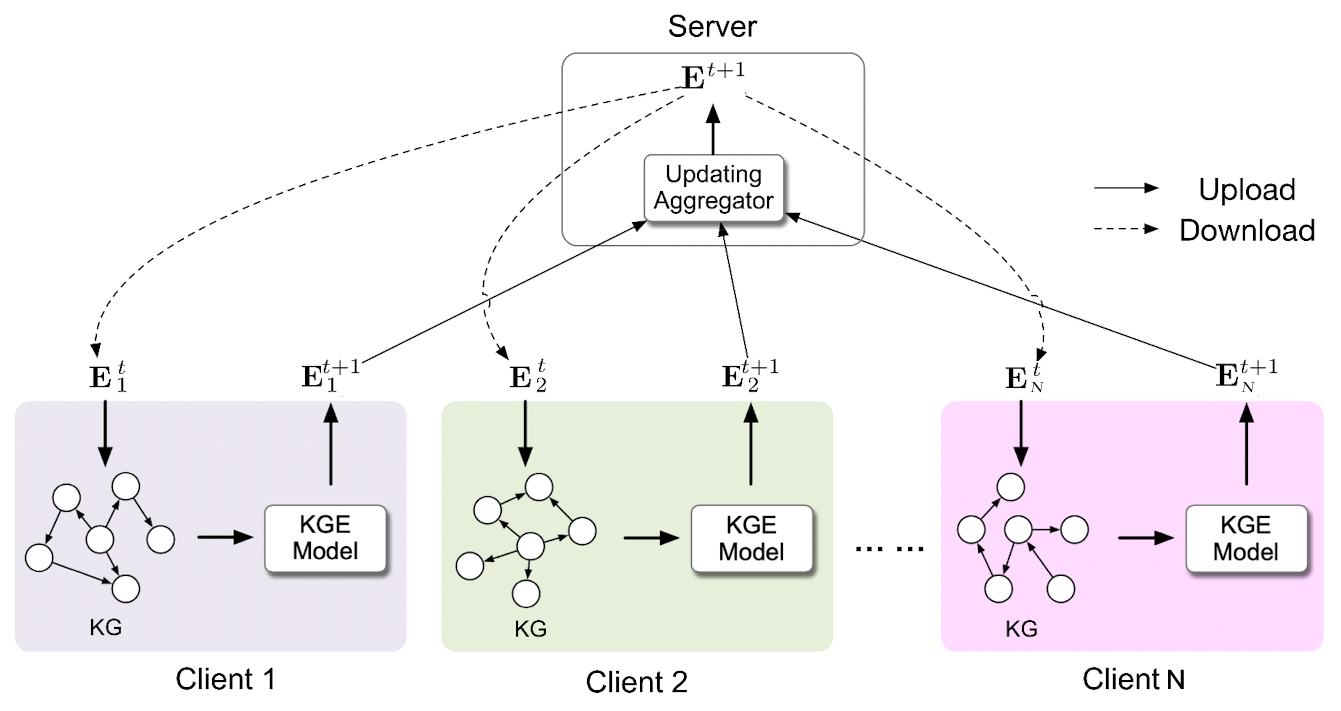
這篇論文屬於多源同領域的型別。該問題的靚點在於首次採用FedAvg的框架對知識圖譜嵌入模型進行訓練,其解決方案非常直接:所有client共用一份所有實體和關係的嵌入,然後在本地進行優化時通過查表的方式獲得元組\((h, r, t)\)對應的嵌入向量。
本篇論文演演算法的每輪通訊描述如下:
(1) 第\(k\)個client節點執行
- 從server接收所有實體的嵌入矩陣\(\textbf{E}\),令本地嵌入矩陣\(\textbf{E}_k=\textbf{P}_k^T \textbf{E}\)。
- 執行\(E\)個區域性epoch的SGD:\[\textbf{E}_k = \textbf{E}_k - \eta \nabla \mathcal{L}(\textbf{E}_k; \mathcal{b}) \](此處將區域性元組資料\(\mathcal{T}_k\)劃分為多個批次\(\mathcal{b}\))
- 將\(\textbf{P}_k \textbf{E}_k\)發往server。
(2) server節點執行
-
從\(N\)個client接收\(\{\textbf{P}_k \textbf{E}_k\}_{k=1}^N\)。
-
進行引數聚合:
- 將嵌入矩陣\(\textbf{E}\)發往對應的client。
上面只展示了實體embeddings的更新流程,關係embeddings的更新同理,此處從簡省略掉。這裡\(\textbf{E}_k\in \mathbb{R}^{n_k\times d_e}\)表示本地實體的embeddings,\(d_e\)為實體嵌入維度;\(\textbf{P}_k\in \{0, 1\}^{n\times n_k}\)用於將使用者端\(k\)的本地embeddings對映到伺服器端的全域性embeddings中,\((\textbf{P}_k)_{ij}=1\)意為全域性embeddings中的第\(i\)個實體對應client中的第\(j\)個實體;\((\textbf{v}_k)_{i}=1\)意為第\(i\)個實體在client \(k\)中存在,\(\oslash\)表示逐元素除,\(\left(\mathbb{1} \oslash \sum \mathbf{v}_k\right)\)表示給聚合結果的加權,在所有client中出現多的實體權重小;\(\otimes\)表示帶廣播的逐元素乘,\([\textbf{v} \otimes \textbf{M}]_{i,j}=\textbf{v}_i \times \textbf{M}_{i,j}\)。
整個演演算法流程如下圖所示:
該演演算法本地優化採用的損失函數為論文[2]中提出的標準損失函數的變種,寫為如下形式(考慮本地資料集\(\mathcal{T}_k\)的一個批次\(b\)):
這裡\(\gamma\)是一個間隔超引數;\((h, r, t_i^{-})\)是\((h, r, t)\)對應的負樣本,\((h, r, t_i^{-})\notin \mathcal{T}_k\);\(n^{-}\)為負樣本的數量。\(p\left(h, r, t_{i}^{-}\right)\)為對應負樣本的權重,這種非均勻的負取樣叫做自對抗負取樣(self-adversarial negative sampling),權重定義如下:
這裡\(\alpha\)是溫度。
2.2 CIKM 2021:《Differentially Private Federated Knowledge Graphs Embedding》[4]
這篇論文考慮的是各知識圖譜之間跨領域的情況。這種情況下因為資料更加異構,就不能單純地對重疊實體及關係的embeddings進行平均了。本文的靚點在於提出了一種隱私保護的對抗轉換網路(privacy-preserving adversarial translation, PPAT),可以在隱私保護的前提下完成兩兩知識圖譜間重疊實體及關係embeddings的統一。
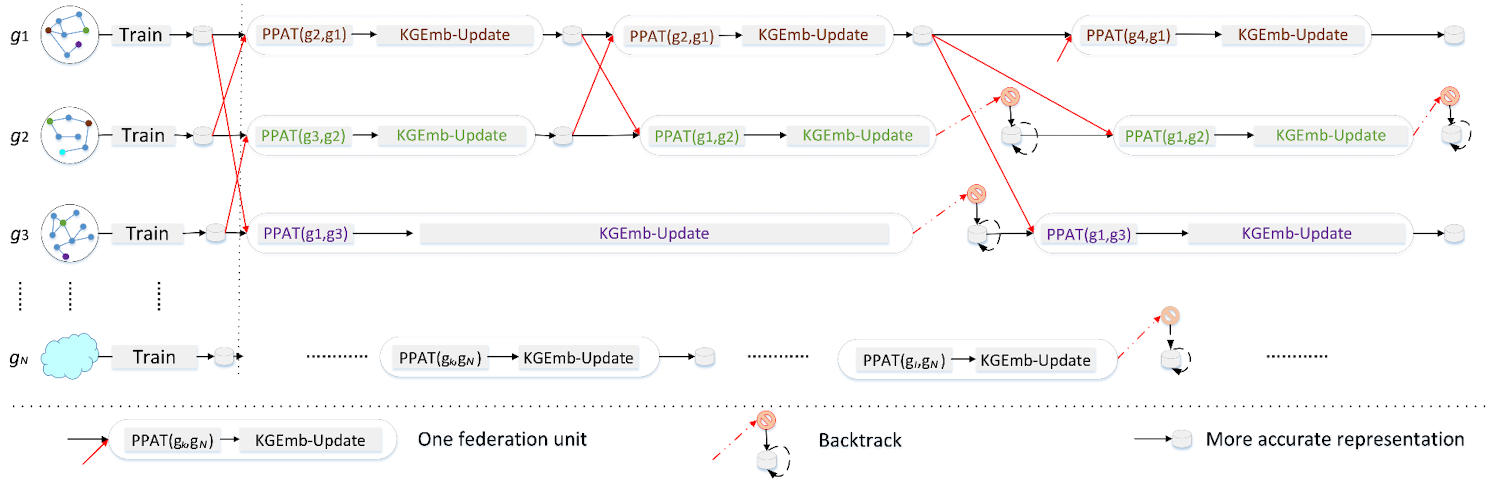
如上圖就展示了使用了論文提出的PPAT網路後的整個去中心化非同步訓練流程。圖中\(\text{Train}\)表示本地訓練知識圖譜嵌入模型;\(\text{PPAT}(g_k, g_l)\)表示用PAPAT網路生成的\(g_k\)和\(g_l\)之間重疊部分的embeddings;\(\text{KGEmb-Update}\)表示更新之前PAPAT網路所生產的embeddings並再對client中所有embeddings進行訓練(同\(\text{Train}\))。如果在\(\text{KGEmb-Update}\)之後的本地評估結果沒有提升,則會對client進行回退(backtrack),也即捨棄新訓練得到的embeddings並使用訓練前的舊版本。
接下來我們來看PPAT網路是怎麼實現的。該網路利用GAN結構來輔助重疊實體embeddings的統一。給定任意兩個圖\((g_k,g_l)\),論文將生成器設定於client \(k\)上,判別器設定與client \(j\)上。生成器的目標是將\(g_k\)中重疊實體的embeddings轉換到\(g_l\)的嵌入空間;判別器負責區分生成器生成的人工embeddings和\(g_l\)中的基準embeddings。在GAN訓練完畢後,生成器產生的人工embeddings能夠學得兩個知識圖譜的特徵,因此可以做為\(\mathcal{E}_{k} \cap \mathcal{E}_{l}\)與\(R_{k} \cap R_{l}\)的原始embeddings的有效替代(此時即完成了對embeddings的統一)。
這裡需要注意的是,論文將原始GAN的判別器改為了多個學生判別器和一個教師判別器。論文在多個教師判別器的投票表決結果上加以Laplace噪聲,得到帶噪聲的標籤來訓練學生判別器,這樣學生判別器具有差分隱私性。而生成器又由學生判別器訓練,則同樣具有了差分隱私性。最終促使生成器產生帶有差分隱私保護的embeddings。設生成器為\(G\)(引數為\(\theta_G\)),學生判別器為\(S\)(引數為\(\theta_S\)),多個教師判別器為\(T=\{ T_1,T_2,\cdots, T_{|T|}\}\)(引數為\(\theta_{T}^{1}, \theta_{T}^{2}, \ldots, \theta_{T}^{|T|}\)。這裡使用\(X=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}\)來表示\(g_k\)中\(\mathcal{E}_{k} \cap \mathcal{E}_{l}\)與\(R_{k} \cap R_{l}\)的embeddings,用\(Y=\left\{y_{1}, y_{2}, \ldots, y_{n}\right\}\)來表示\(g_l\)中\(\mathcal{E}_{k} \cap \mathcal{E}_{l}\)與\(R_{k} \cap R_{l}\)的embeddings,則整個PPAT網路流程可描述如下:
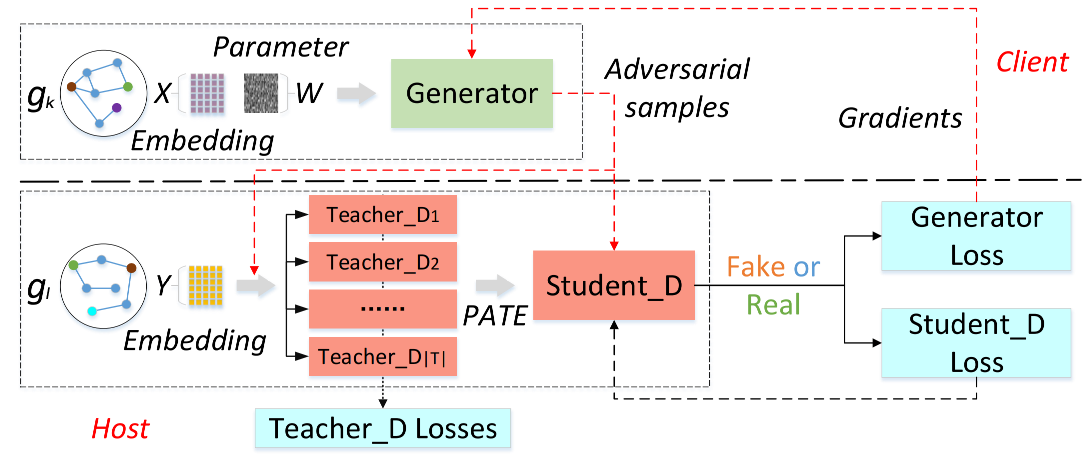
如上圖所示,生成器\(G\)的目標是產生與\(Y\)相似的對抗樣本\(G(X)\),以求學生判別器\(S\)不能夠識別它們。下面這個式子是生成器的損失函數:
這裡\(G(X)=WX\);\(S\)是一個引數為\(\theta_S\)的學生判別器,它同時將\(G(X)\)和\(Y\)做為輸入。
教師判別器\(T=\{ T_1,T_2,\cdots, T_{|T|}\}\)的學習目標和原始GAN中判別器相似,也即區分偽造樣本\(G(X)\)與真樣本\(Y\)。唯一的不同是各個教師判別器會使用劃分好的資料集來訓練,第\(t\)個教師判別器的損失函數如下:
這裡\(D^t\)是\(T^t\)對應的資料集\(X\)和\(Y\)的子集,滿足\(|D_t|=\frac{n}{T}\)且子集之間無交集。
而學生判別器\(S\)的學習目標則是在給定帶噪聲標籤的情況下,對生成器產生的真假樣本進行分類。這裡所謂的帶噪聲標籤是在教師判別器的投票結果的基礎上,加以隨機的Laplace噪聲來生成。下面的式子描述了在帶噪聲標籤的生成機制(即所謂PATE機制):
這裡\(V_0, V_1\)為用於引入噪聲的IID的Laplace分佈隨機變數。\(n_j(x)\)表示對於輸入\(x\)預測類別為\(c\)的教師數量:
(此處符號不嚴謹,\(T_t(x)\)應該是個概率值,但意會意思即可)
學生判別器則利用帶有上述標籤的生成樣本來訓練自身。學生判別器的損失函數定義如下:
這裡\(\gamma_{i}=P A T E_{\lambda}\left(x_{i}\right)\)即生成的帶噪聲標籤。
這樣學生判別器\(S\)由帶噪聲的標籤訓練,則具有差分隱私性。而生成器又由學生判別器訓練,則同樣具有了差分隱私性。最終促使生成器產生帶有差分隱私保護的embeddings。
參考
- [1] Hamilton W L. Graph representation learning[J]. Synthesis Lectures on Artifical Intelligence and Machine Learning, 2020, 14(3): 1-159.
- [2] Sun Z, Deng Z H, Nie J Y, et al. Rotate: Knowledge graph embedding by relational rotation in complex space[J]. arXiv preprint arXiv:1902.10197, 2019.
- [3] Chen M, Zhang W, Yuan Z, et al. Fede: Embedding knowledge graphs in federated setting[C]//The 10th International Joint Conference on Knowledge Graphs. 2021: 80-88.
- [4] Peng H, Li H, Song Y, et al. Differentially private federated knowledge graphs embedding[C]//Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021: 1416-1425.