不堆概念、換個角度聊多執行緒並行程式設計
大家好,又見面了。
在上一篇檔案《JAVA基於CompletableFuture的流水線並行處理深度實踐,滿滿乾貨》中,我們一起探討了JAVA中並行編碼的相關內容,在文中也一起比較了並行與並行的區別。作為姊妹篇,這裡我們就再展開聊一聊關於並行相關的內容。
俗話說,雙拳難敵四手。
俗話還說,人多力量大。
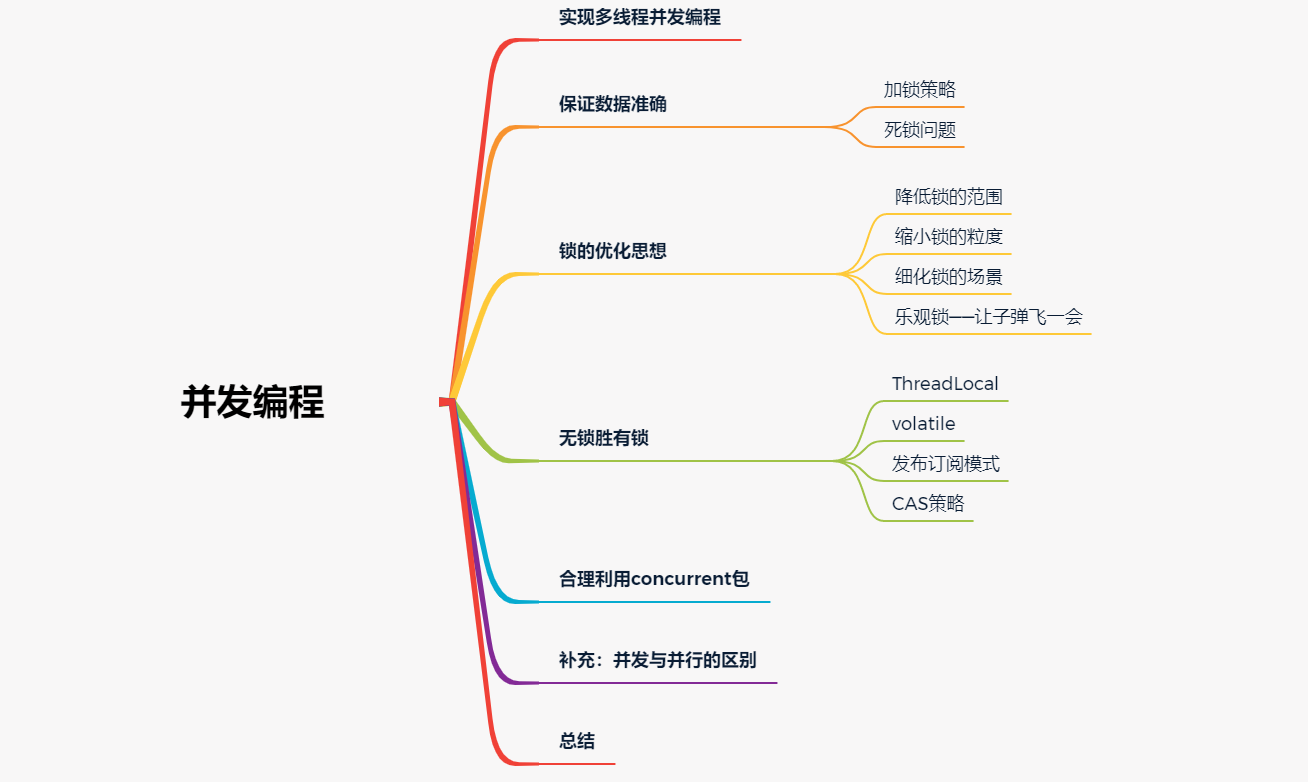
在現實生活中,我們通過團隊化的方式來獲得比單兵作戰更高的單位時間內整體產出速度。同樣,在編碼世界中,為了提升處理效率,並行一直以來都是軟體開發設計場景中無法繞過的話題。不管是微觀層面的單個程序內多執行緒處理模式,還是宏觀層面整個系統叢集化多節點部署策略,為了提升系統的整體並行吞吐量,程式設計師們可謂是煞費苦心。
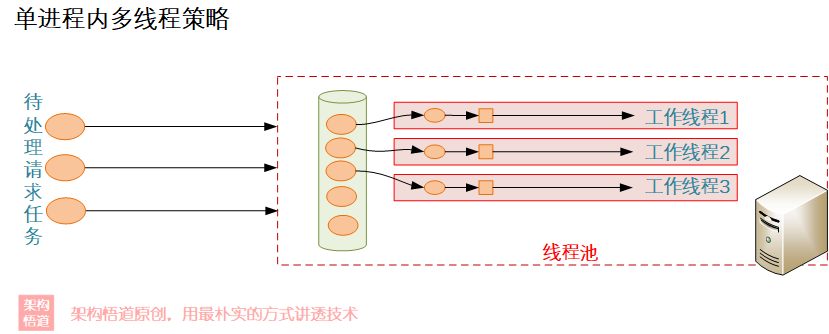

當然,俗話也說,人多眼雜、林子大了什麼鳥都有。在現實中,團隊中多人一起配合工作的時候,一系列的問題又會顯現:
- 同一個事情,老王和小張都以為還沒處理,結果都去處理了,最後造成了成員工作量的浪費、甚至因為重複處理了一遍導致資料錯誤
- 兩個有關聯的事情分別給了老王和翠花,結果老王在等待翠花先給出結果再開始處理自己的事情,翠花也在等待老王先給出結果然後再處理自己的事情,結果兩個人就這麼一致等下去,事情一直沒完成
- 同一個檔案,小張和翠花各自更新的時候,出現相互覆蓋的情況
- ...
編碼源於生活、程式碼世界其實也處處體現著生活中的樸素哲學思維。縱然並行場景存在一些可能的隱患問題,但我們也不必因噎廢食,正所謂先了解它、再掌控它。
作為提升吞吐效能的不二良方,下面我們就一起來嘗試按照問題解決型的思路一步步推進,換個角度探討下多執行緒並行相關的內容,全面瞭解下多執行緒並行世界的各種關聯,進而更從容優雅的讓並行為我們所用,成為我們提升系統效能的神兵利器。
多執行緒——並行第一步
並行探險的第一關,就是如何支援並行。下面大概列舉下常見的幾種方式:
⭐️子執行緒⭐️
一些簡單的場景中,我們為了提升主執行緒的處理效能,會將過程中一些耗時操作放到一個單獨的子執行緒中進行同步處理。在程式碼中可以通過建立臨時子執行緒的方式來執行即可:
public void buyProduct() {
int price = getPrice();
// 子執行緒同步處理部分操作
new Thread(this::printTicket).start();
// 主執行緒繼續處理其它邏輯
doOtherOperations(price);
}
⭐️執行緒池⭐️
頻繁建立執行緒、銷燬執行緒的操作屬於一種消耗效能的操作,而且建立執行緒的數量不可控。所以對於一些固定需要在子執行緒中並行處理的任務場景,我們可以通過建立執行緒池的方式,固定維護著一批可用執行緒,迴圈利用,去處理任務,以實現提升效率與便於管控的訴求:
private ExecutorService threadPool = Executors.newFixedThreadPool(3);
public void testReleaseThreadLocalSafely() {
// 任務直接放到執行緒池中進行處理
threadPool.submit(this::mockServiceOperations);
}
⭐️定時器⭐️
定時器是一種比較特殊的多執行緒並行場景,也是經常可能會被忽視掉的一種情況。定時器也是在子執行緒中執行的,多個定時器之間、定時器執行緒與主執行緒之間、定時器執行緒與業務子執行緒之間都會以多執行緒的形式並行處理。
@Scheduled(cron = "0 0/10 * * * ?")
public void syncBusinessInfo() {
// do something here...
}
⭐️Tomcat等容器⭐️
常見的服務執行容器,比如Tomcat等,都是支援並行請求執行的。而常見的基於SpringBoot實現的服務,其service類都是由Spring進行託管的單例物件。這種場景是比較常見的多執行緒場景。
改為多執行緒並行執行,雖然效率是提升了,但是問題也來了——資料執行結果不準確。
結果不對,顯然是我們無法接受的。所以擺在我們面前的下一難題,就是要保證執行結果資料的準確。
synchronized與lock
在JAVA中提到執行緒同步,使用最簡單、應用頻率最高的非synchronized關鍵字莫屬了。它是 Java 內建的一種同步機制,代表了某種內在鎖定的概念,當一個執行緒對某個共用資源加鎖後,其他想要獲取共用資源的執行緒必須進行等待,synchronized 也具有互斥和排他的語意。具體用法如下:
synchronized修飾實體方法,相當於是對類的範例(this)進行加鎖,進入同步程式碼前需要獲得當前範例的鎖
public synchronized void test() {
//...
}
synchronized修飾程式碼塊,相當於是給物件(syncObject)進行加鎖,在進入程式碼塊前需要先獲得物件的鎖
public void test() {
synchronized(syncObject) {
//允許存取控制的程式碼
}
// 其它操作
}
synchronized修飾靜態方法,相當於是對類(LockTest.class)進行加鎖
public class LockTest {
public synchronized static void test() {
//...
}
}
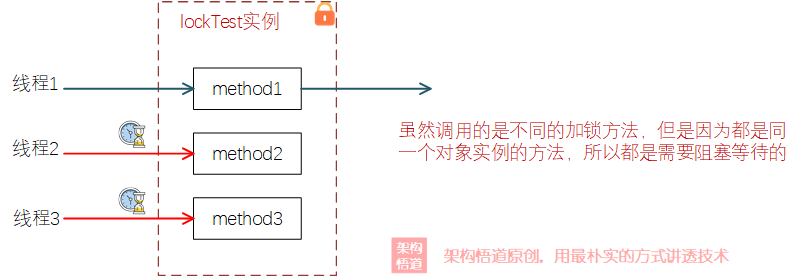
對於被鎖的目標物件而言,鎖是具有排他性的,也就是同一個物件上的多個帶鎖方法,同一時刻只有1個執行緒可以搶到鎖,其餘都會被阻塞住。比如下面的程式碼,執行緒A和執行緒B分別同時請求method1和method2,雖然呼叫的是不同的方法,但是兩個執行緒其實是在爭奪同一把鎖:
public class LockTest {
public synchronized void method1() {
// ...
}
public synchronized void method2() {
// ...
}
}
由於synchronized屬於JVM關鍵字,屬於一種比較重量級的鎖。在JDK中還提供了個Lock類,提供了眾多不同型別的鎖,供各種不同場景訴求使用。
public void test() {
Lock lock = ...;
lock.lock();
try{
// ...
}catch(Exception ex){
// ...
}finally{
// ...
lock.unlock();
}
}
與synchronized不同,使用Lock的時候需要特別注意最後一定要可靠的釋放掉佔用的鎖。
到這裡,再測試會發現,多執行緒並行執行,資料結果也對,似乎是沒什麼問題——但是這樣真的就結束了嗎?
如果並行程式設計僅僅就這麼點內容,那顯然對不上它在編碼界的地位。我們接著往下看。
死鎖——不期而遇的小驚嚇
經過前面的內容,我們知道了使用多執行緒的方式來實現並行處理,也知曉了可以通過加鎖的方式來保證對共用資料編輯的順序性與準確性。而加了鎖之後稍不留神間,也許就會出現死鎖。
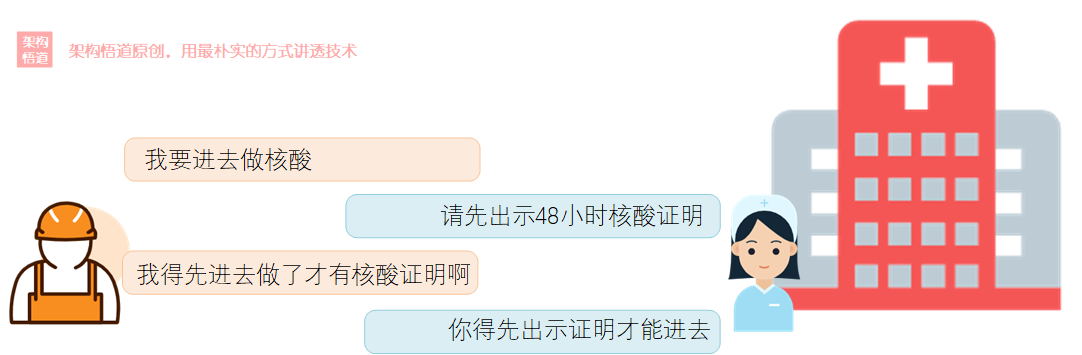
一個執行緒A已經持有一個鎖的情況下同時又去請求呼叫另一個加鎖的物件或者程式碼塊,而這個被請求的物件又被另一個執行緒B所持有,而這個執行緒B,又恰好在等待此時被執行緒A所持有的加鎖資源或程式碼塊,於是兩個執行緒都在沉默中無限等待下去,便會出現死鎖。
看一個實際業務場景:
一個運維管理系統,用於維護虛擬機器器資源以及部署的業務程序資訊,且支援按照虛擬機器器維度和業務程序維度進行分別檢視相關資訊。即:
- 檢視虛擬機器器VM資訊,需要一併獲取到上面部署的Process資訊
- 檢視Process資訊,需要一併獲取其所位於的虛擬機器器的資訊。
假定基於SpringBoot框架進行程式碼實現,DeployedProcessService與VmService範例由Spring框架進行託管,為單例物件,然後彼此自動注入對方範例。假定由於業務邏輯需要,對兩個服務類的執行方法進行了加鎖處理。部署程序管理服務DEMO程式碼如下:
@Service
public class DeployedProcessService {
@Autowired
VmService vmService;
public synchronized void manageDeployedProcessInfo() {
// 獲取程序資訊
collectProcessInfo();
// 獲取程序所在VM資訊
vmService.manageVmInfo(this);
}
}
@Service
public class VmService {
@Autowired
DeployedProcessService deployedProcessService;
public synchronized void manageVmInfo() {
// 獲取此VM基礎資訊
collectVmBasicInfo();
// 獲取此VM上已部署的程序資訊
deployedProcessService.manageDeployedProcessInfo(this);
}
}
我們使用兩個獨立程序同時分別去查詢VM資訊以及Process資訊,模擬並行操作的場景,會發現永遠等不到結果。為啥呀?因為死鎖了!
我們可以通過jstack命令來看下此時的JVM內執行緒堆疊情況,會發現有提示Found one Java-level deadlock,然後可以看到死鎖的堆疊:
Found one Java-level deadlock:
=============================
"ForkJoinPool.commonPool-worker-2":
waiting to lock monitor 0x000000001cf532b8 (object 0x000000076c29bf28, a com.veezean.skills.lock.VmService),
which is held by "ForkJoinPool.commonPool-worker-1"
"ForkJoinPool.commonPool-worker-1":
waiting to lock monitor 0x000000001fce9f88 (object 0x000000076c29f460, a com.veezean.skills.lock.DeployedProcessService),
which is held by "ForkJoinPool.commonPool-worker-2"
Java stack information for the threads listed above:
===================================================
"ForkJoinPool.commonPool-worker-2":
at com.veezean.skills.lock.VmService.manageVmInfo(VmService.java:14)
- waiting to lock <0x000000076c29bf28> (a com.veezean.skills.lock.VmService)
at com.veezean.skills.lock.DeployedProcessService.manageDeployedProcessInfo(DeployedProcessService.java:19)
- locked <0x000000076c29f460> (a com.veezean.skills.lock.DeployedProcessService)
at com.veezean.skills.lock.Main.lambda$main$1(Main.java:19)
"ForkJoinPool.commonPool-worker-1":
at com.veezean.skills.lock.DeployedProcessService.manageDeployedProcessInfo(DeployedProcessService.java:15)
- waiting to lock <0x000000076c29f460> (a com.veezean.skills.lock.DeployedProcessService)
at com.veezean.skills.lock.VmService.manageVmInfo(VmService.java:18)
- locked <0x000000076c29bf28> (a com.veezean.skills.lock.VmService)
at com.veezean.skills.lock.Main.lambda$main$0(Main.java:18)
Found 1 deadlock.
關於死鎖的產生原因,網上或者書中給出的答案無外乎就是說如下四個原因要同時成立,就會死鎖:
- 互斥
- 佔有並等待
- 非搶佔
- 迴圈等待
不知道大家看到上面這個解釋是啥感覺?懂還是不懂?反正我的經歷是:在我懂之後,看這4點中的每一點都很在理;而我不懂時,我依舊不知道啥原因導致的死鎖。其實,用白話解釋死鎖的產生原因,就是兩個或者多個執行緒各自拿到了一個鎖,然後自己依賴別人的鎖,別人依賴自己的鎖,然後彼此都在相互等待,永遠沒有辦法等到。
那麼應該如何解決呢?
還是以上面程式碼為例,一個最簡單的方式,就是兩個Service類的加鎖方法不要相互呼叫,各自Service類中獨立實現所有邏輯即可。
小提示:
一個好的經驗,就是加鎖的方法巢狀呼叫另一個加鎖的方法時,多留個心眼,看看會不會出現相互依賴或者回圈依賴的情況。
鎖優化思想——降低鎖的影響
規避了可能存在的死鎖問題之後,另一個問題又出現在我們面前——效能。我們採用多執行緒並行程式設計的初衷,是為了儘可能的提升整體的處理效能,但是加鎖之後,加鎖的地方反而成為了整個並行處理的一個堵點,導致整個多執行緒並行的效果大打折扣。
所以,如何降低鎖對多執行緒並行處理的影響,成為飄在程式設計師面前的一團新的烏雲。為此也衍生出了多種處理與應對策略,比如_降低鎖的範圍以減少鎖持有時間_、縮小鎖粒度以降低奪鎖競爭、_利用讀寫鎖減少加鎖場景_等等。
降低鎖範圍
這個其實很好理解,因為加鎖範圍越大,意味著持鎖執行的時間就會越久,那麼其他執行緒阻塞等待的時間就會越久,這樣整個系統的堵點就會越發明顯。而如果能夠將一些並不需要放到同步鎖內執行的邏輯放到外部去並行執行,這樣就會降低鎖內邏輯的處理時長,其餘執行緒阻塞等待時間也就會縮短。
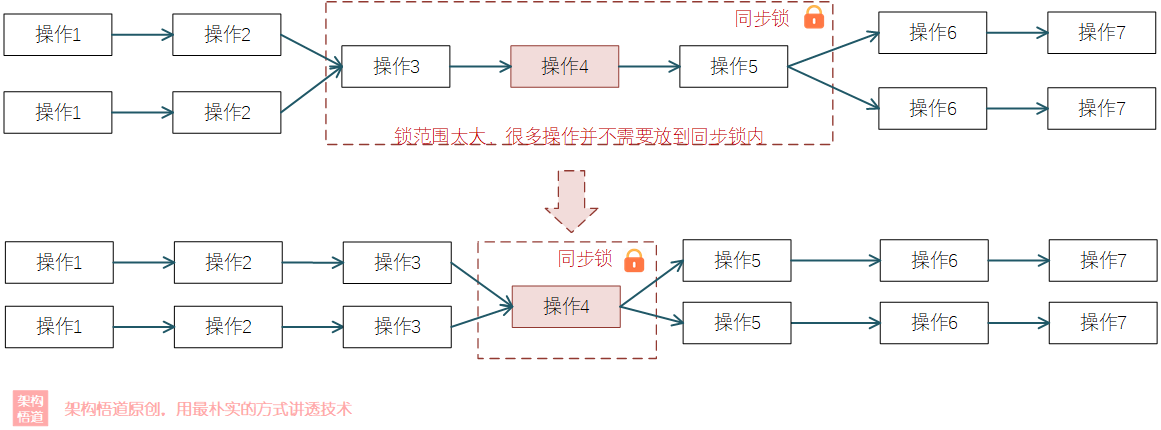
舉個例子。假如現在有個更新文章內容的需求,其處理邏輯如下:
- 校驗當前使用者是否有權更新
- 校驗文章內容重複度
- 檢查文章中是否有違禁詞
- 更新到資料庫中
- 載入到ES中
為了保證並行更新操作的準確性,對方法新增synchronized同步鎖,保證多執行緒順序執行:
public synchronized void updateArticle() {
verifyAuthorInfo();
checkArticleDuplication();
checkBlackWords();
saveToDb();
loadToEs();
}
但是實際分析下,其實幾個操作其實只有一個環節需要做同步鎖處理,其餘的操作其實並不會有任何的同步問題,因此我們按照縮小鎖範圍的優化策略,可以將synchronized鎖範圍縮小:
public void updateArticle() {
verifyAuthorInfo();
checkArticleDuplication();
checkBlackWords();
saveToDb();
loadToEs();
}
private synchronized void saveToDb() {
// ...
}
縮小鎖粒度
鎖的粒度越大,多執行緒請求的時候對鎖的競爭壓力越大,對效能的影響越大。如果將鎖的粒度拆分小一些,這樣同時請求到同一把鎖的概率就會降低,這樣執行緒間爭奪鎖的競爭壓力就會降低。
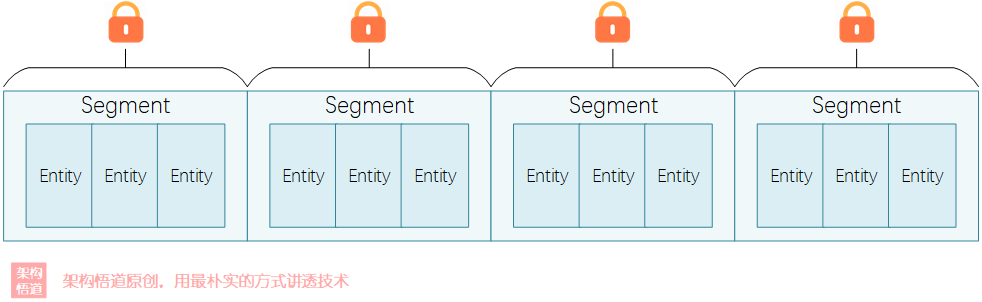
可以看下下面的示意圖,4個執行緒請求同一鎖時,其中1個執行緒可以搶到鎖,其餘三個執行緒將處於等待;而將鎖拆分為3個子鎖的時候,這樣4個執行緒中只有1個執行緒處於等待:
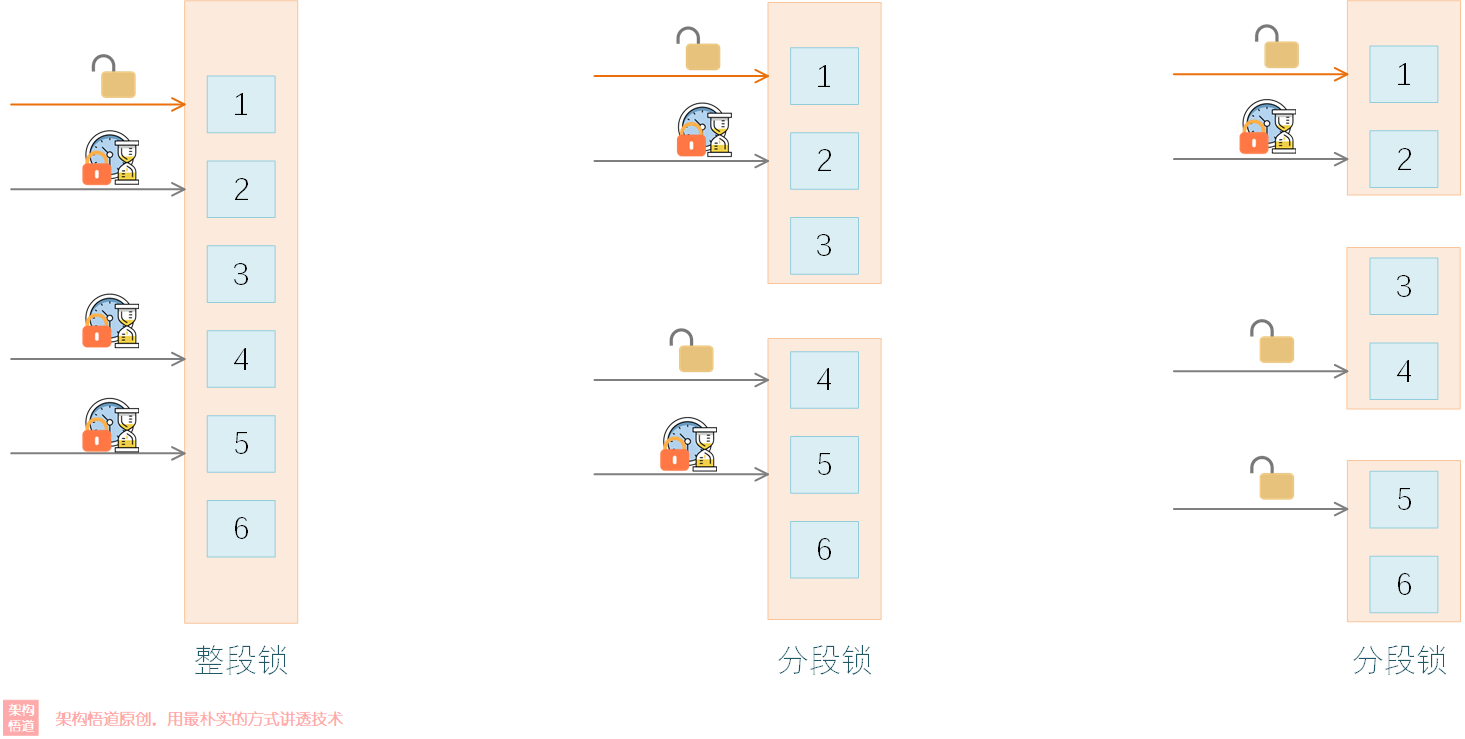
上面演示的就是分段鎖的概念。在JAVA7之前,面試的時候經常會遇到的一個問題就是ConcurrentHashMap與HashTable都是執行緒安全的,為啥ConcurrentHashMap的效能上會更好些呢?其實就是因為ConcurrentHashMap使用了分段鎖(Segment)的方式實現的:
⭐️補充一下⭐️
上面為啥要強調是JAVA7之前呢?因為JAVA7開始,ConcurrentHashMap的執行緒安全策略變了,改為了基於CAS的策略了。
細化鎖場景
對於同一個共用資料的各種操作,很多時候並不是所有多執行緒操作都會出資料錯亂問題,一般情況下只有寫操作才會改變資料的內容,而多個執行緒同時執行讀取操作的時候並不會對資料產生影響,所以這個_讀取的場景其實無需和寫操作使用相同的同步鎖邏輯_。所以為了滿足此場景,出現了讀寫鎖。
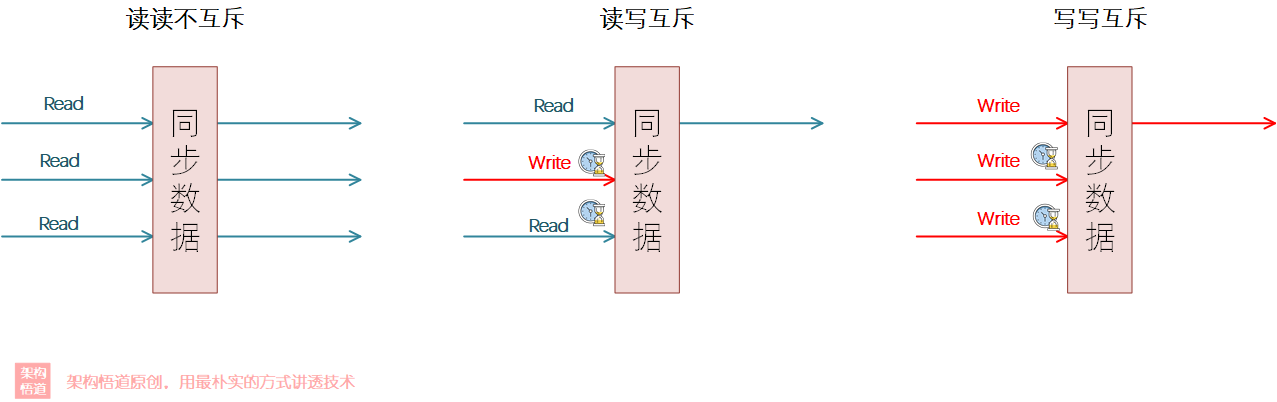
讀寫鎖的特點就是,針對讀操作和寫操作,提供了不同的加鎖同步策略,具體而言:
- 讀讀不互斥
- 讀寫互斥
- 寫寫互斥
在 Java 中,讀寫鎖是使用 ReentrantReadWriteLock 類來實現的,其中:
- **ReentrantReadWriteLock.ReadLock **表示讀鎖,它提供了 lock 方法進行加鎖、unlock 方法進行解鎖。
- **ReentrantReadWriteLock.WriteLock **表示寫鎖,它提供了 lock 方法進行加鎖、unlock 方法進行解鎖。
程式碼範例如下。 建立讀寫鎖,然後通過readLock和writeLock方法,可以分別獲取到讀鎖和寫鎖:
// 建立讀寫鎖
final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
// 獲得讀鎖
final ReentrantReadWriteLock.ReadLock readLock = readWriteLock.readLock();
// 獲得寫鎖
final ReentrantReadWriteLock.WriteLock writeLock = readWriteLock.writeLock();
在讀取操作的場景,直接使用讀鎖,使用完成後需要可靠釋放鎖:
public String readObject() {
// 讀鎖使用
readLock.lock();
try {
// 業務程式碼...
} finally {
readLock.unlock();
}
}
在寫操作的場景使用寫鎖,使用完成後同樣需要可靠釋放鎖:
public void writeObject() {
// 寫鎖使用
writeLock.lock();
try {
// 業務程式碼...
} finally {
writeLock.unlock();
}
}
其它策略
除了上述介紹的各種鎖優化策略,還有很多不同型別的鎖,整體思路大體相同,此處不再展開描述,具體可以參見這篇文章:《不可不說的JAVA「鎖」事》:
無鎖勝有鎖——就是要站著還把錢掙了
為了保證多執行緒的資料安全,我們引入了同步鎖;為了降低同步鎖的影響,我們絞盡腦汁去降低鎖競爭機率。但是勤勞的程式設計師永遠不會滿足眼前的結果、不然頭頂也不會這麼早的鋥光瓦亮。於是,一個靈魂拷問又飄了出來:能不能既使用多執行緒並行處理、又不用加同步鎖?

於是乎,一些無鎖解決方案開始在某些特定的並行場景內嶄露頭角。
ThreadLocal空間換時間
很多時候,編碼世界彙總對程式效能的優化,無外乎是時間與空間的權衡。當系統更關注服務的處理響應時長,就會使用一些快取的策略,降低CPU的重複計算,以此來提升效能。
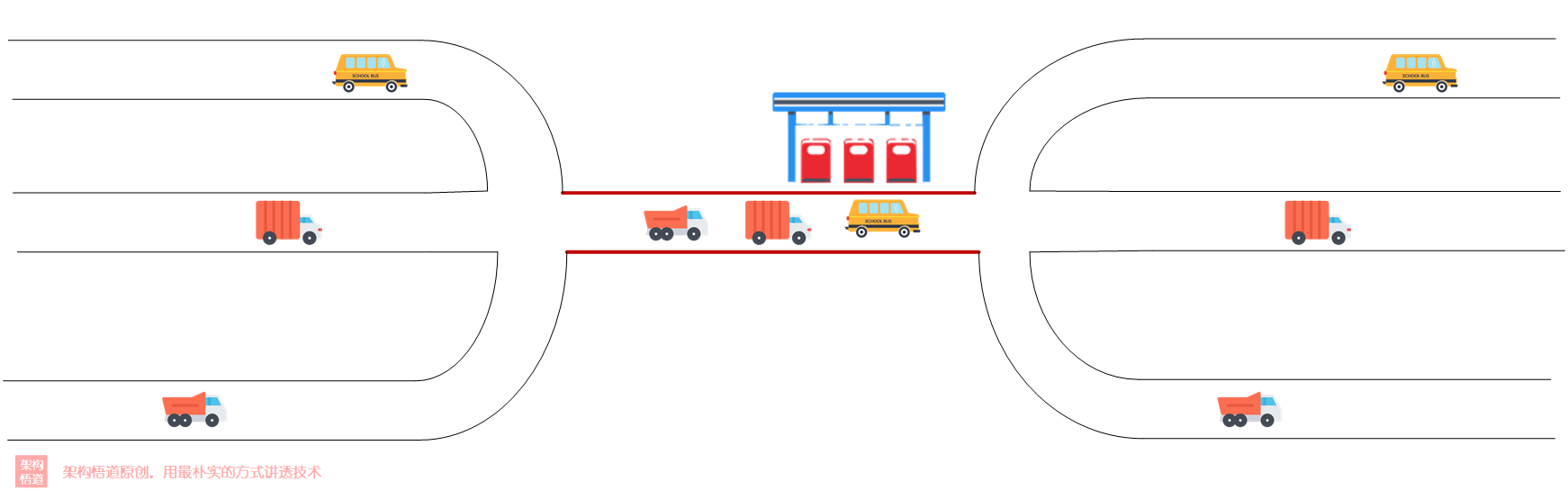
回到我們多執行緒的場景,為了保證多個執行緒對同一個共用記憶體物件的存取安全,所以通過同步鎖的方式來保證序列存取,這樣就會造成CPU的排隊等待,效能受阻。那麼,如果各個記憶體不去存取這個統一的共用物件,而是存取自己獨享的物件,這樣不就互不干擾、無需阻塞等待了嗎?
比如下面圖中的收費站場景,多條路最後需要經由同一個收費站,所以導致收費站這裡會出現堵塞。而如果每條路都建一個自己的收費站,這樣就有效避免了堵塞的狀況。
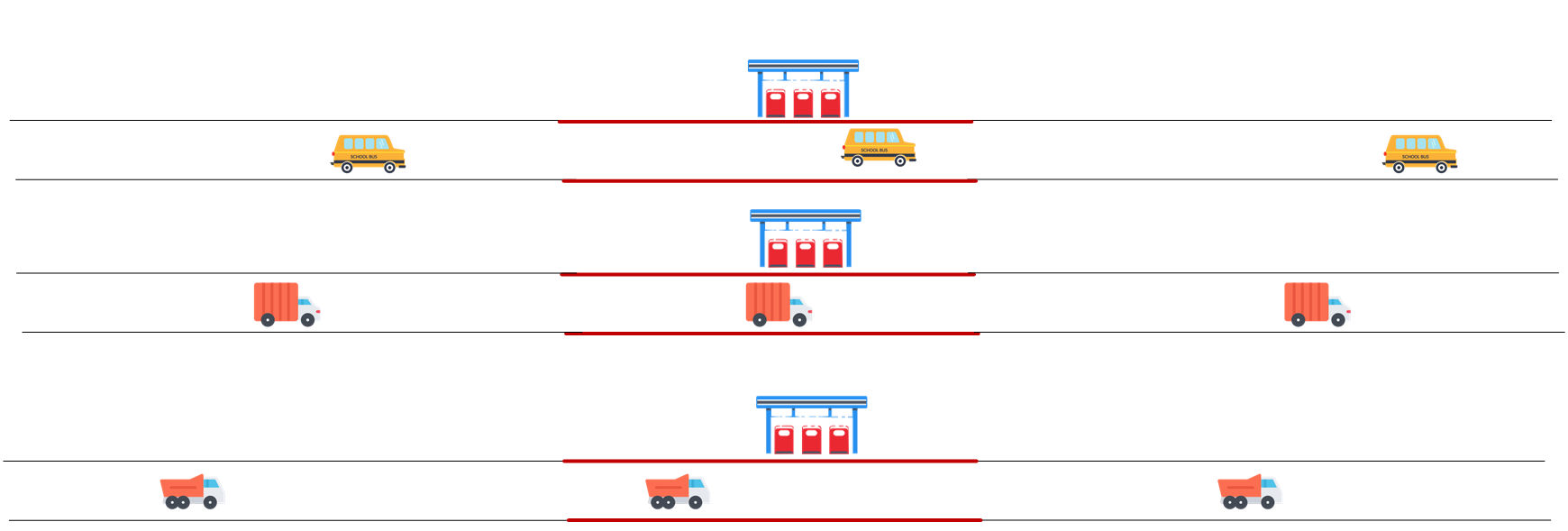
仿照相同的原理,ThreadLocal便出現了。它通過冗餘副本的方式,使得某個記憶體共用物件在各個執行緒上都有自己的拷貝副本。在嘗試去了解ThreadLocal結構與原理前,可以先看下ThreadLocal的set方法實現原始碼:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
翻譯成白話文,先獲取到當前執行緒資訊,然後獲取到當前執行緒對應的ThreadLocalMap物件,然後將當前物件以及要儲存的內容值存到Map中。也就是說:ThreadLocal只是一個方法封裝,具體的資料實際儲存在ThreadLocalMap中,而這個ThreadLocalMap是每個執行緒都有自己專屬副本,裡面儲存著這個執行緒執行過程中使用的所有ThreadLocal物件以及對應數值(程式碼裡面可能會new多個不同的ThreadLocal物件,比如有的用於儲存當前使用者,有的用於儲存當前token資訊之類的)。
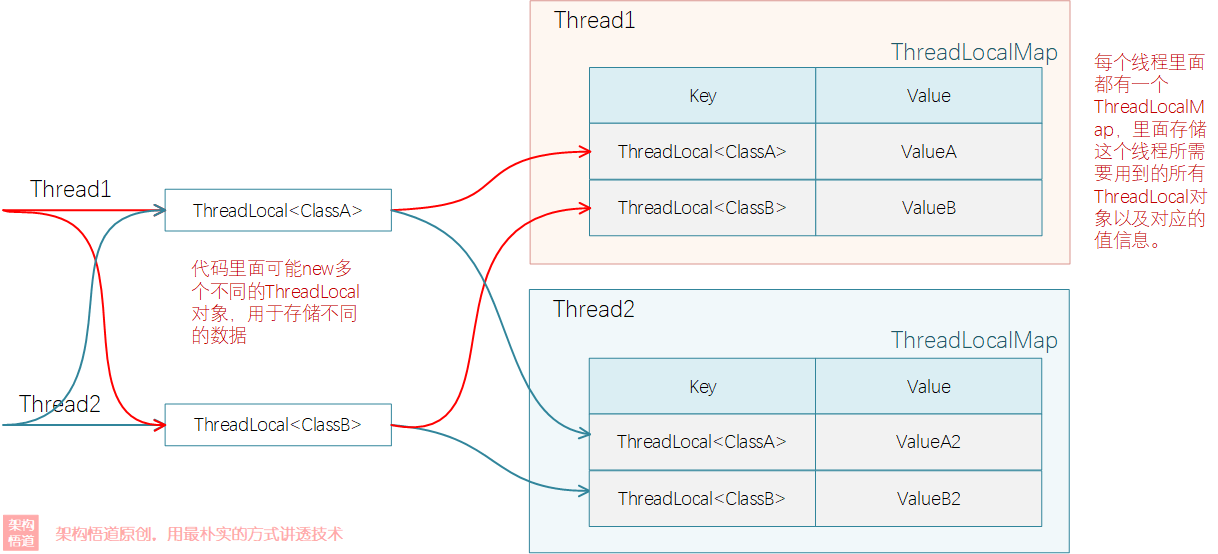
從ThreadLocal的實現原理中,我們可以發現_其適用的場景是有限的_,即只適用於需要在單個執行緒內全域性共用的場景,而不適用於需要在多個執行緒間做資料互動共用的場景。
⭐️適用場景舉例⭐️:
一個SpringBoot構建的後端服務系統,對外以Controller方式提供諸多Restful介面方法供使用者端呼叫。使用者端呼叫的時候會攜帶token資訊,然後鑑權邏輯中根據token獲取到具體使用者資訊並快取到記憶體中,後續的業務處理邏輯中有多處會需要獲取該使用者資訊。
這是ThreadLocal使用的一個典型場景,在通過token鑑權完成後,將使用者資訊設定到ThreadLocal物件中,這樣後續所有需要用的地方,直接從ThreadLocal中獲取就行了。
為了方便後續使用,我們先封裝一個工具類,提供些靜態方法,便於對ThreadLocal進行操作:
public class CurrentUserHolder{
private static final ThreadLocal<UserDetail> CURRENT_USER = ThreadLocal.withInitial(() -> null);
public static void cacheUserDetail(UserDetail userDetail) {
CURRENT_USER.set(userDetail);
}
public static UserDetail getCurrentUser() {
CURRENT_USER.get();
}
public static void clearCache() {
CURRENT_USER.remove();
}
}
在業務處理開始之前先統一設定下使用者的快取資訊。因為是基於SpringBoot專案來講解,所以我們實現一個HandlerInyerceptor的實現類,並在preHandle方法中根據token獲取到使用者詳情並快取到ThreadLocal中:
public class AuthorityInterceptor implements HandlerInterceptor {
private static final ThreadLocal<UserDetail> CURRENT_USER = ThreadLocal.withInitial(() -> null);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
log.info("request IN, url: {}", request.getRequestURI());
try {
UserDetail userDetail = userAuthService.authUser(request.getHeader("token"));
// 校驗通過,快取使用者資訊
CurrentUserHolder.cacheUserDetail(userDetail);
return true;
} catch (Exception e) {
// 校驗沒通過,清理執行緒資料
CurrentUserHolder.clearCache();
return false;
}
}
}
因為鑑權通過之後,會將當前的使用者資訊新增到快取中,並進入到後續的業務實際處理程式碼中,所以業務處理的時候如果需要獲取當前登入使用者資訊的時候,可以直接從CurrentUserHolder中獲取即可。
public void collectBookToMySpace(Book book) {
UserDetail user = CurrentUserHolder.getCurrentUser();
// 其他邏輯省略
}
藉助ThreadLocal可以讓我們實現線上程內部共用物件,以此規避多執行緒間的同步等待處理,但是使用完畢之後,還需要保證清除掉當前執行緒的快取資料值。為什麼要這麼做呢?拿執行緒池舉個例子:
既然是為每個執行緒拷貝一份獨立的副本,對於同一個執行緒而言拿到的資料是同一個,那麼對於使用執行緒池來處理多工的場景,執行緒都是重複利用的,這樣會導致同一個執行緒中正在處理的任務可能會拿到上一個任務設定的共用值。對於業務處理而言可能會得到非預期結果。
當然,除了可能會導致業務處理的時候前後任務快取資料錯亂,使用完畢不清除快取,有些時候還容易導致記憶體漏失的問題。所以編碼的時候、尤其涉及記憶體資源使用的時候,用完回收始終會是一個好習慣。
⭐️可靠清除執行緒副本⭐️
既然知道在使用完成之後需要可靠的清理掉當前執行緒的ThreadLocal副本資料,但是對於一些流程比較長、或者邏輯比較複雜的系統,其執行緒任務的退出分支可能有很多條,那麼怎麼樣才能做到可靠清理、避免有分支遺漏呢?
- 如果是自己實現的執行緒池或者執行緒分發操作,在子執行緒的呼叫頂層位置通過
try...finally...包裹呼叫邏輯,並在finally中進行釋放操作。
public void testReleaseThreadLocalSafely() {
threadPool.submit(() -> {
try {
// 設定token資訊
TOKEN.set("123456");
// 執行業務處理操作
mockServiceOperations();
} finally {
// finally分支中可靠清除當前執行緒的ThreadLocal副本
TOKEN.remove();
}
});
}
- 基於一些框架系統實現的場景,比如
SpringBoot專案,可以客製化個Interceptor並在afterCompletion等退出前回撥方法中,新增上對應的清理邏輯。
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) {
CurrentUserHolder.clearCurrentThreadCache();
}
volatile保證可見性
與synchronized保證資料同步處理的原理不一樣,volatile主要解決的是資料在多執行緒之間的可見性問題,但是不保證資料操作的原子性。volatile用於修飾變數,可以保證每個共用此變數資料的執行緒都可以第一時間拿到此值的真實值。
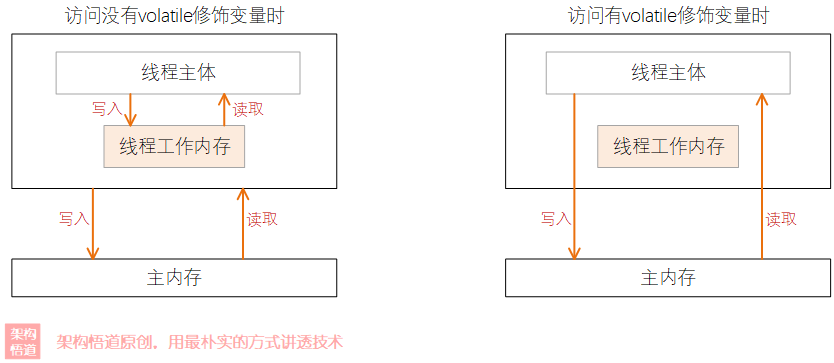
當把變數宣告為volatile型別後,編譯器與執行時都會注意到這個變數是共用的,因此不會將該變數上的操作與其他記憶體操作一起重排序。volatile變數不會被快取在暫存器或者對其他處理器不可見的地方,因此在讀取volatile型別的變數時總會返回最新寫入的值。
但是因為它不保證原子操作,所以如果有多個執行緒同時來修改變數的值時,還是可能會出現問題。所以,volatile適合那種單個執行緒去修改值內容,但是多個執行緒會共用讀取變數結果的場景。
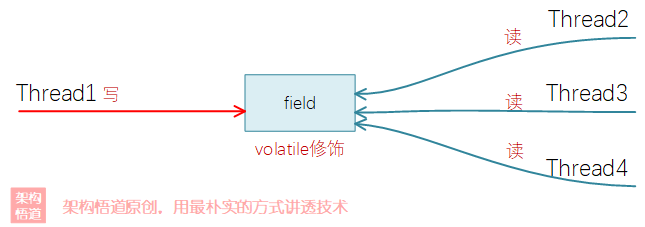
比如專案程式碼中,我們需要支援系統設定屬性的動態變更,我們可以將系統引數使用volatile修飾,然後使用固定一個執行緒進行系統屬性值的維護,其餘業務執行緒負責從記憶體中讀取即可。
釋出訂閱模式
在並行程式設計中使用釋出訂閱模式能夠解決絕大多數並行問題。
多執行緒協同設定的場景下,可以藉助MQ實現釋出訂閱模式,可以保證每個任務都分配給不同的消費者進行處理,這樣就不會出現重複處理的問題、也減少了執行緒或者程序間資源爭奪的風險,正可謂是「無鎖勝有鎖、四兩撥千斤」的典型。
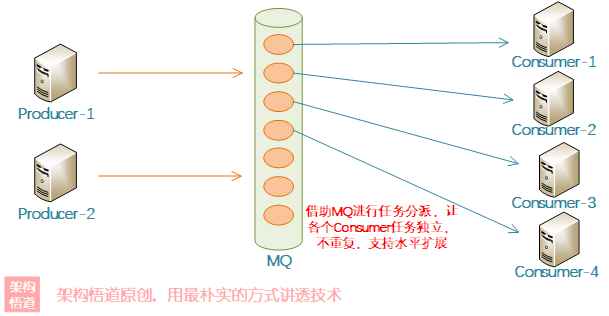
對於MQ的選型,如果是單程序內多執行緒間的使用,可以使用BlockingQueue來實現,而用於分散式系統內時,可以選用一些訊息佇列中介軟體,比如RabbitMQ、Kakfa等。
CAS樂觀鎖策略
所謂CAS,也即Compare And Swap,也即在對資料執行寫操作前,先比較下資料是否有變更,沒有變更的情況下才去執行寫操作,否則重新讀取最新記錄並重新執行計算後,再執行比對操作,直到資料寫入完成。CAS是一種典型的樂觀鎖策略,其與常規的加同步鎖的處理策略有很大的不同,屬於一種比較經典的無鎖機制:
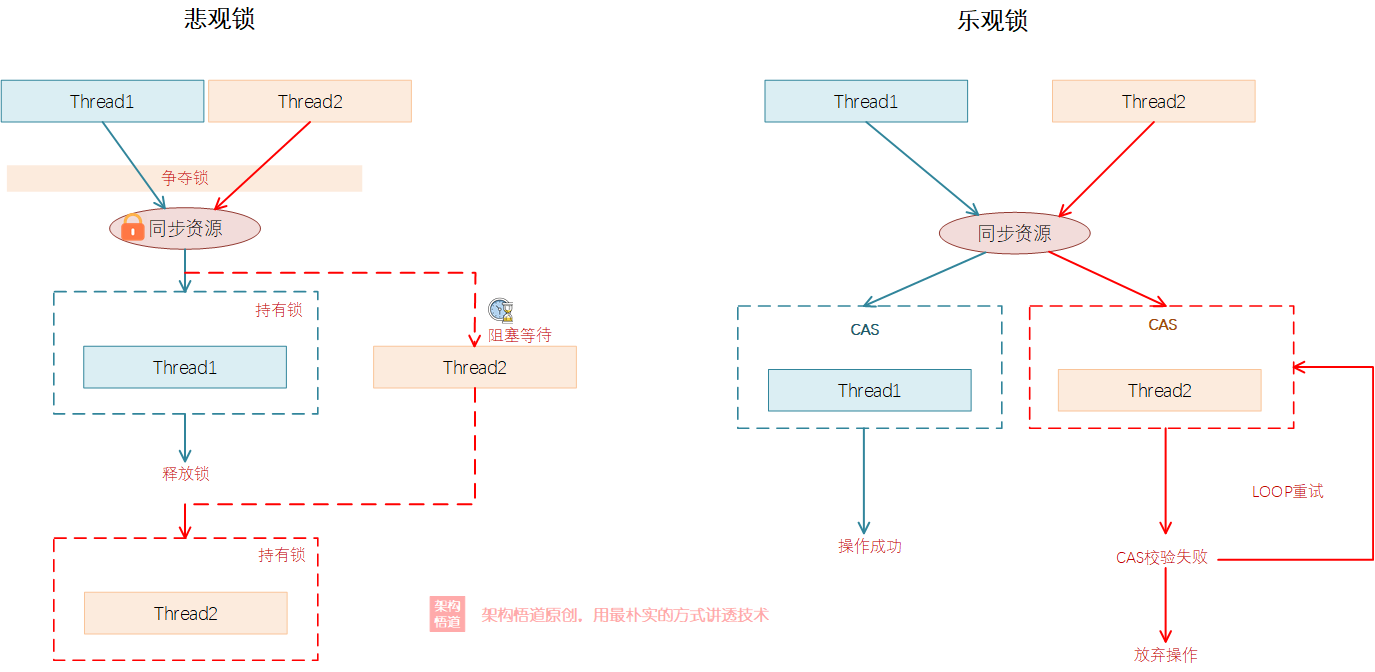
並行場景對公共儲存(比如MySQL)中的資料進行更新的時候,經常會需要考慮並行更新某個記錄的情況,尤其是一些介面編輯更新的場景更是常見。這個場景下使用CAS機制可以有效解決問題。
先看個問題場景:
有個需求任務跟蹤管理系統,團隊內的成員可以編輯團隊內的待辦需求事項的進展描述,如果團隊內有兩個人都開啟了某一個需求頁面進行編輯進展說明,那麼第一個人改動完成儲存的內容,會被第二個人儲存改動時直接覆蓋掉。
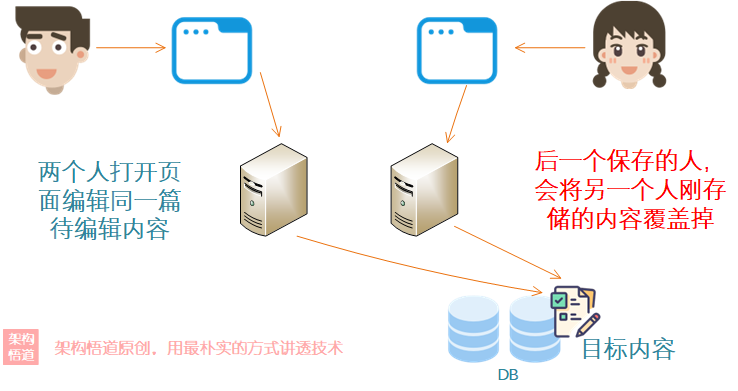
使用CAS的思路來解決上面場景提及的更新覆蓋問題,我們可以對DB中的記錄資料增加一個version欄位,更新的時候必須保證version欄位值與自己最初拿到的version值一致時才能更新成功,同時在每次update的時候更新下version欄位,這樣問題就解決啦,看下過程:
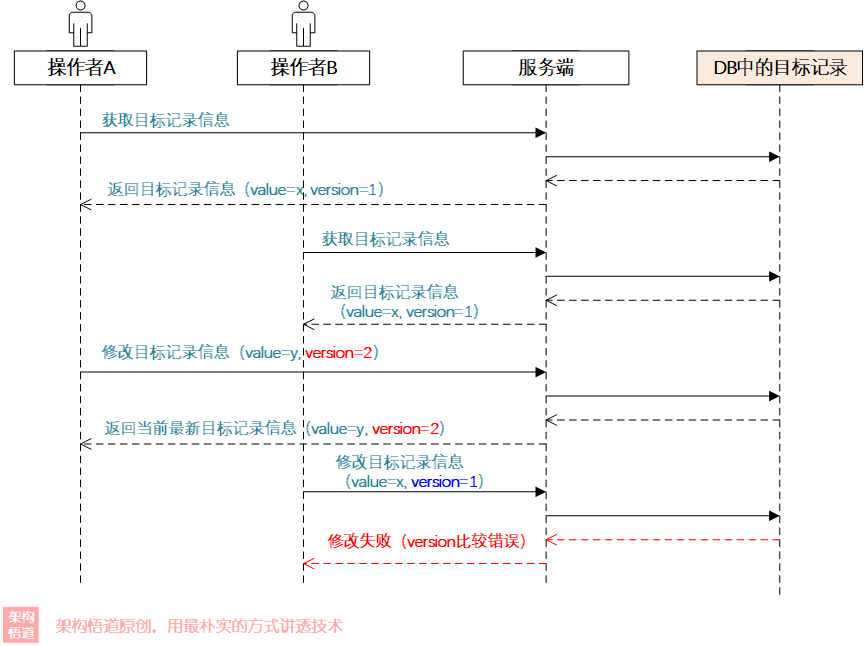
程式碼實現起來也很簡單:
public void updateItem(Item item) {
int updateResult = updateContentByIdAndVersion(item.getContent(), item.getId(), item.getVersion());
if (updateResult == 0) {
// 沒有更新成功任何記錄,說明version比對失敗已經有別人更新了
// 要麼放棄處理,要麼重試
}
}
CAS始終按照無鎖的策略進行資料的處理、處理失敗則重試或放棄。在競爭不是很激烈的並行場景下,可以有效的提升整體的處理效率,因為大部分的場景下都會執行成功,只有在少量的請求出現並行衝突的時候,才會進入自旋重試。但當競爭很激烈的場景下,會導致寫入操作高頻率失敗進入自旋,這要會大大的浪費CPU資源,且因為自旋其實就是執行緒不停的迴圈,所以大量自旋可能會使得CPU的佔用比較高。
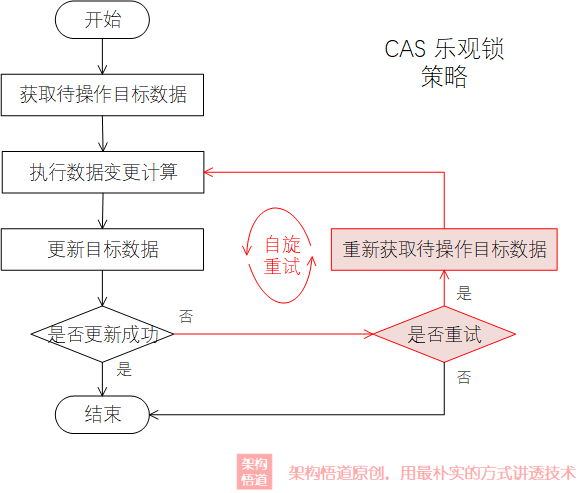
補充說明:
在單程序內的多執行緒間使用CAS機制保證並行的時候,需要結合volatile一起使用,以此來保證原子性與可見性。
另外,我們在前面有提到JAVA7之前ConcurrentHashMap使用的是分段鎖的技術,而從JAVA7之後,ConcurrentHashMap執行緒安全保護的實現邏輯是改為了CAS+synchronized的方式來實現,以此來獲取更好的性表現。
分散式鎖——跨越程序的相逢
前面介紹了單程序內的一些多執行緒高並行場景的應對方案。但高並行的場景,除了單執行緒內的多執行緒間的並行之外,還有分散式系統叢集內的多個程序之間的並行。所以分散式鎖應運而生。
舉個例子:
資料庫有一張「熱議話題」表,表中每條記錄有個「當前熱度」欄位,
熱度計算服務需要每隔5分鐘執行一次計算,然後更新表中每條記錄的熱度欄位。
為了保證系統的高可用,熱度計算服務部署了多個程序節點,由定時器觸發,每隔5分鐘計算一次。
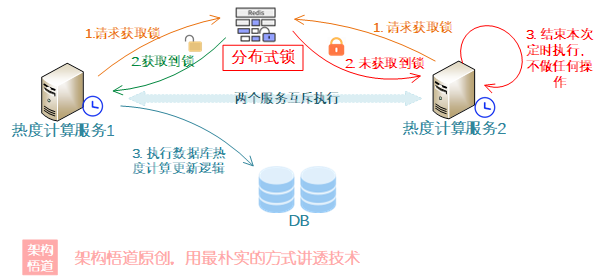
分散式鎖的實現,有多種方式,比較常見的是基於Redis或者MySQL來實現。分散式鎖在實現以及使用的時候,需要關注幾個要點;
- 使用者端請求鎖的整體操作需要是個原子操作,即需要保證鎖分配結果的唯一性
- 使用者端獲取到鎖之後進行自身業務邏輯處理,處理完成之後必須要
主動釋放鎖(需要注意判斷下是否是自己所持有的鎖) - 鎖要有兜底退出機制,防止某個使用者端獲取到鎖之後出現宕機等異常情況,導致鎖被持有後無法釋放,其它使用者端也無法繼續申請
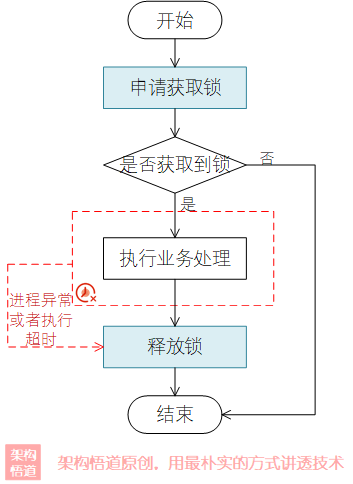
比如基於Redis實現分散式鎖的時候,使用示意如下:
// 獲取鎖
public boolean accuireLock(String lockName) {
return stringRedisTemplate.opsForValue().setIfAbsent(lockName, "", 1L, TimeUnit.MINUTES);
}
// 釋放鎖
public void releaseLock(String lockName) {
stringRedisTemplate.delete(lockName);
}
上面程式碼中,簡單的使用setNx命令來實現分散式鎖的申請,又設定了redis的超時時間,一旦在設定的時間內依舊沒有主動釋放鎖,則redis將主動釋放鎖,供其餘使用者端再來請求。
在上面歸納的分散式鎖實現與使用的注意要點中,在提及業務處理完成之後要主動釋放鎖的時候,有特別補充了一個要求:需要判斷下是否是自己的鎖,只能釋放自己的鎖!為什麼一定要強調這一點呢?以上述程式碼為例,看一種可能的情況:
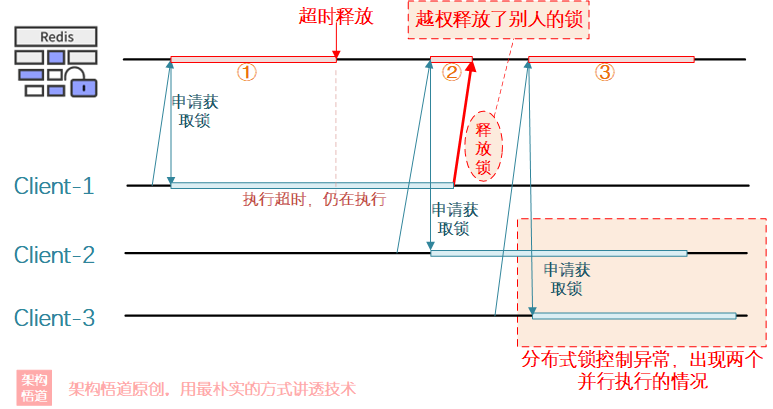
從上圖可以看出,Client-1申請到了_鎖1_,但是Client-1執行超時導致_鎖1_被強制釋放掉了,而Client-2隨後獲取到了_鎖2_並開始執行處理邏輯。此時Client-1的任務終於執行完成了,然後去釋放了鎖(Client-1自己不知道自己超時,還是按照正常邏輯去釋放鎖),結果_Client-3_此時又申請到了_鎖3_,然後開始執行自己的任務。這個時候就會出現了Client-2和Client-3同時執行的異常情況了。
整個問題出現的原因就是釋放鎖的時候沒有校驗是否是自己的鎖,所以出現了越權釋放了別人的鎖的情況。為了避免此情況的發生,我們對前面的分散式鎖實現使用邏輯稍加改動即可:
首先是申請分散式鎖的時候,可以生成個隨機UUID作為鎖的value值,如果申請成功,則直接返回此鎖的UUID唯一標識:
/**
* 獲取鎖,如果獲取成功,則返回鎖的value值(UUID隨機)
*/
public String accuireLock(String lockName) {
String uuid = UUID.randomUUID().toString();
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockName, uuid, 1L,
TimeUnit.MINUTES);
if (result == null || !result) {
throw new RuntimeException("獲取鎖失敗");
}
return uuid;
}
鎖釋放的時候,需要同時提供鎖名稱與鎖的唯一UUID標識值,先根據鎖名稱嘗試獲取下已存在的鎖,然後比對下鎖value值是否一致,如果一致,則表名當前的鎖是自己鎖持有的這把鎖,然後將其釋放即可:
/**
* 釋放鎖,先比對鎖value一致,才會釋放
*/
public void releaseLock(String lockName, String lockUuid) {
String lockValue = stringRedisTemplate.opsForValue().get(lockName);
if (!StringUtils.equals(lockValue, lockUuid)) {
throw new RuntimeException("鎖釋放失敗,鎖不存在");
}
stringRedisTemplate.delete(lockName);
}
當然啦,我們這裡舉例是使用的Redis的setNx命令來實現的,此實現可以輕鬆的應對大部分的使用場景。但是,上述的釋放鎖實現程式碼中可以看出,由於獲取鎖內容、比對鎖內容、釋放鎖內容三個操作是獨立分開的,存在無法保證操作原子性的弊端。如果專案的要求級別較高,可以考慮使用LUA指令碼封裝為原子命令操作來解決,或者使用redis官方提供的redission來實現。
補充:並行與並行
本文主要討論了多執行緒並行程式設計相關的內容,提到並行,往往還有個容易混淆的概念,叫並行。關於並行的具體介紹與實現策略,以及並行與並行的詳細區別,可以參見我的另一個檔案《JAVA基於CompletableFuture的流水線並行處理深度實踐,滿滿乾貨》,此處不述。
綜合而言:
- 如果業務處理邏輯是CPU密集型的操作,優先使用基於執行緒池實現並行處理方案(可以避免執行緒間切換導致的系統效能浪費)。
- 如果業務處理邏輯中存在較多需要阻塞等待的耗時場景、且相互之間沒有依賴,比如本地IO操作、網路IO請求等等,這種情況優先選擇使用並行處理策略(可以避免寶貴的執行緒資源被阻塞等待)。
總結
好啦,關於多執行緒並行場景常見問題的相關應對策略,這裡就探討到這裡啦。那麼看到這裡,相信您應該有所收穫吧?那麼你是否有實際應對過多執行緒並行場景的開發呢?那你是如何處理的呢?是否有發現過什麼問題呢?評論區一起討論下吧、我會認真對待您的每一個評論~~
此外:
- 關於本文中涉及的演示程式碼的完整範例,我已經整理並提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點贊 + 關注讓我感受到您的支援。也可以關注下我的公眾號【架構悟道】,獲取更及時的更新。
期待與你一起探討,一起成長為更好的自己。

本文來自部落格園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多幹貨,轉載請註明原文連結:https://www.cnblogs.com/softwarearch/p/16529688.html