特殊的阻塞佇列
描述
SynchrounousQueue 是一個比較特殊的無界阻塞佇列並支援非公平和公平模式,嚴格意義上來說不算一個佇列,因為它不像其他阻塞佇列一樣能有容量,它僅有一個指向棧頂的地址,棧中的節點由執行緒自己儲存。任意的執行緒都會等待直到獲得資料(消費)或者交付完成(生產)才會返回。
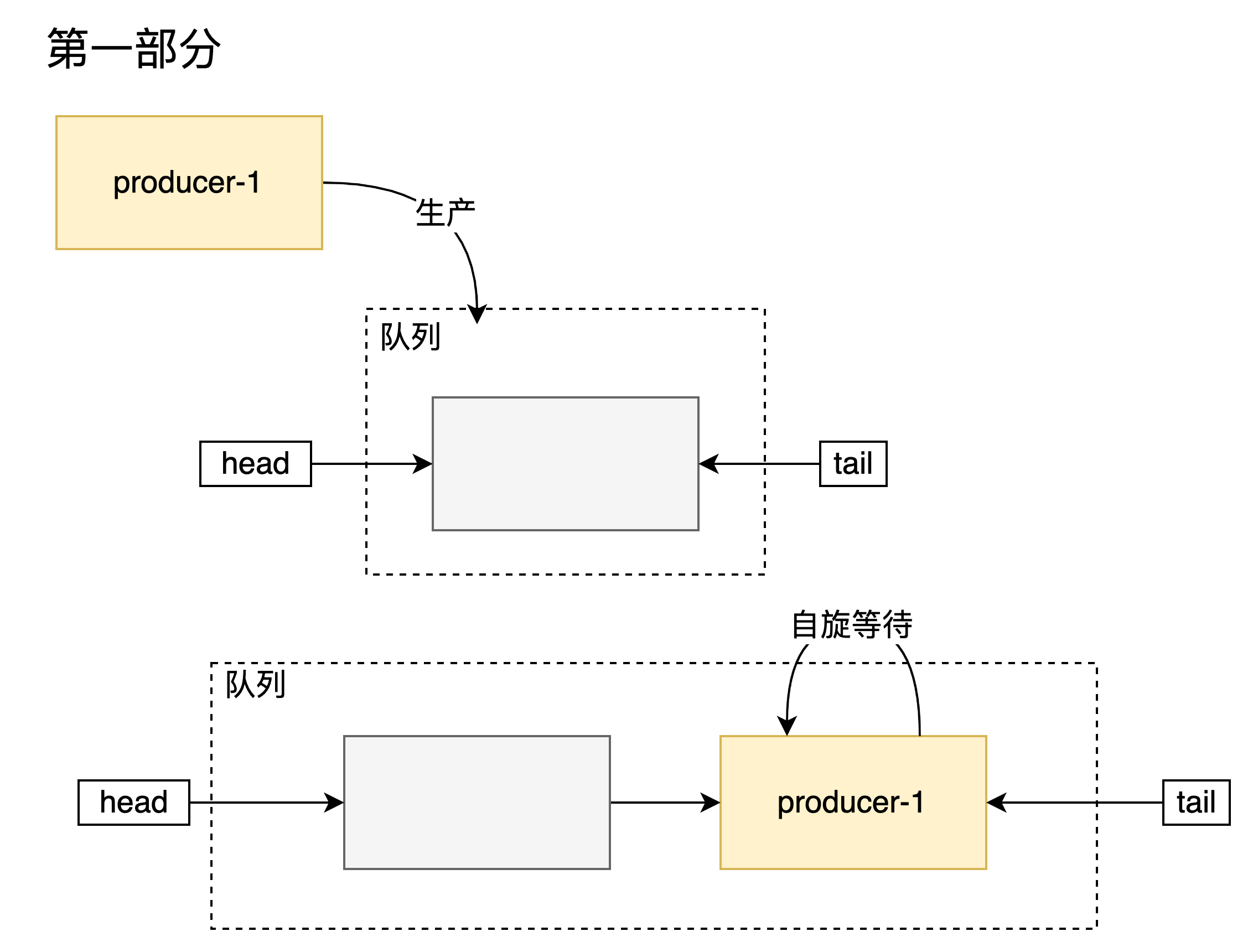
SynchronousQueue 和普通的阻塞佇列的差異類似於下圖所示(非公平模式):
阻塞佇列通常是儲存生產者的生產結果然後消費者去消費,阻塞佇列就類似於一箇中轉站。
SynchronousQueue 則儲存生產結果,只告訴消費者生產者的位置,然後讓其自己去與之交流(反過來一樣),就沒有中轉的一個過程而是直接交付的。

SynchronousQueue 將資料交付的任務交給生產者或消費者自行處理,實現的非常看不懂。
那麼既然是Queue ,就可以通過 offer 和 take 方法來了解
offer:
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
return transferer.transfer(e, true, 0) != null;
}
take:
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
offer 和 take 中都呼叫了 transferer.transfer(...)
transferer 是一個介面 SynchrounousQueue 有兩個實現類:
- TransferQueue: 用於公平交付
- TransferStack:用於不公平交付
這兩個的作用可以通過SynchrounousQueue的構造方法得知:
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
如果啟用公平交付則建立 TransferQueue 否則使用 TransferStack
首先先分析 TransferStack.transfer
非公平的TransferStack
通過類名得知,是使用堆疊實現的,是一個LIFO的序列。
每個請求的執行緒都會被包裝成一個 SNode,具有以下屬性:
class SNode {
volatile SNode next; // 連結的下一個SNode
volatile SNode match; // 與該執行緒匹配的另外一個執行緒SNode節點
volatile Thread waiter; // 當前請求的執行緒
Object item;
int mode; //該節點的型別(模式)
}
很顯然,是一個連結串列結構,使用一個mode來標識該節點的型別,具有以下值:
// 代表一個消費者
int REQUEST = 0;
// 代表一個生產者
int DATA = 1;
// 代表已經和另外一個節點匹配
int FULFILLING = 2;
通過原始碼註釋得知,整個TransferStack.transfer可以分為以下幾步:
- 如果當前的棧是空的,或者棧頂與請求的節點模式相同,那麼就將該節點作為棧頂並等待下一個與之相匹配的請求節點,最後返回匹配節點的資料(take或offer)或者null(被取消/中斷)
- 如果棧不為空,請求節點與棧頂節點相匹配(一個是REQUEST一個是DATA)那麼當前節點模式變為FULFILLING,然後將其壓入棧中和互補的節點進行匹配,完成交付後同時彈出棧並返回交易的資料,如果匹配失敗則與其他節點解除關係等帶回收。
- 如果棧頂已經存在一個FULFILLING的節點,說明正在交付,那麼就幫助這個棧頂節點快速完成交易。
下面用圖來描述先生產後消費的例子
當棧為空將其封裝為SNode節點後入棧,自旋等待其他節點與自己匹配
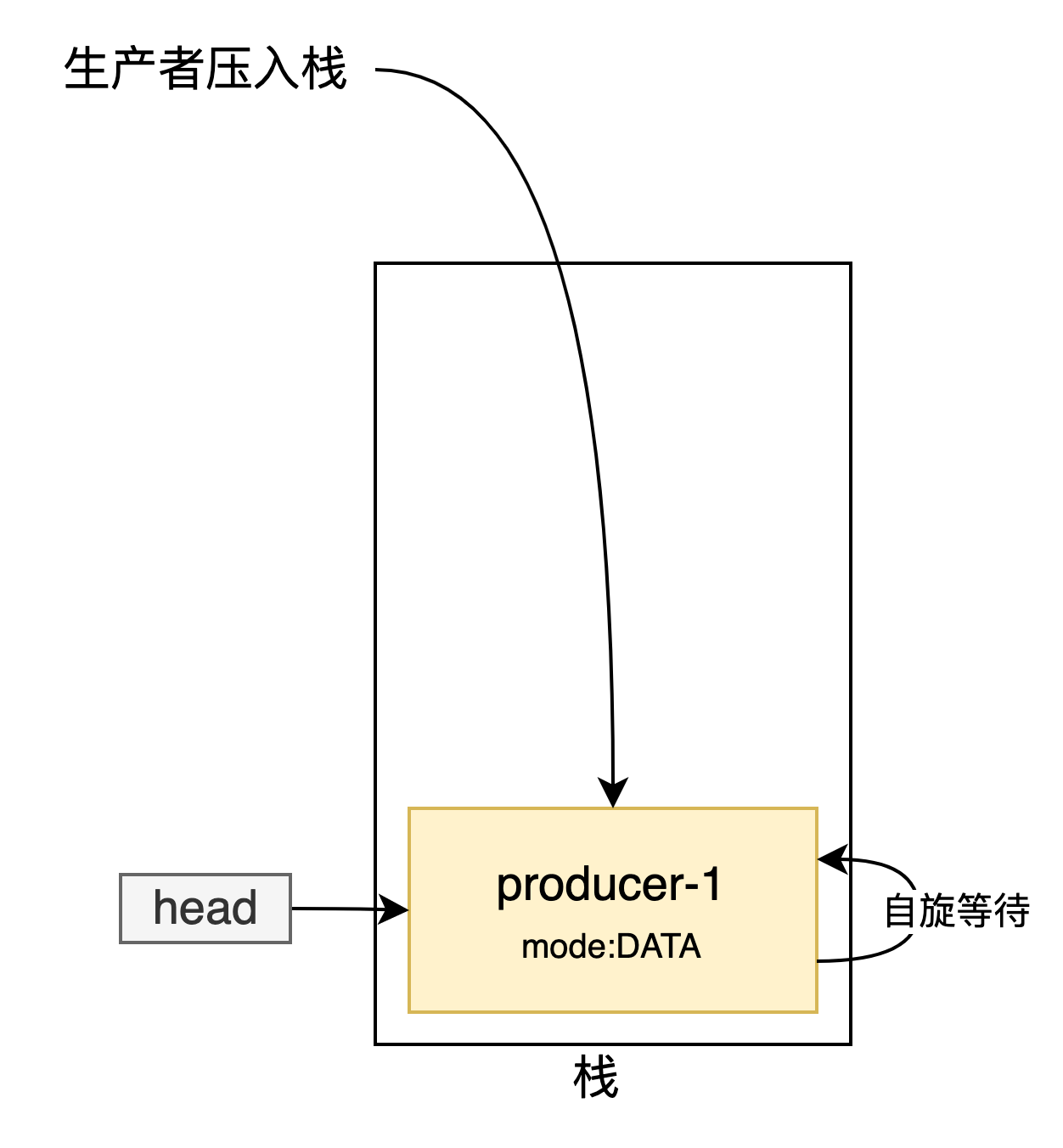
這是TransferStack.transfer的第一個部分,用來處理棧為空或者是多個生產者/消費者的情況,使得都自旋等待匹配。
if (h == null || h.mode == mode) { // empty or same-mode
// 生產者/消費者不願意等待則直接返回
if (timed && nanos <= 0L) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
// 建立一個節點並將該節點作為棧頂
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 自旋等待下一個與之匹配的節點
SNode m = awaitFulfill(s, timed, nanos);
// 如果該節點已經取消等待
if (m == s) {
//清理該節點
clean(s);
return null;
}
// 如果有節點與自己匹配那麼就返回交換的元素
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
// 如果當前模式為DATA就表示是 消費者等待生產者生產
// 如果當前模式為REQUEST就表示是 生產者等待消費者消費
return (E) ((mode == REQUEST) ? m.item : s.item);
}
}
棧不為空,消費者壓入棧頂,消費者與生產者進行匹配,消費者改變頭節點(也就是本身)的狀態為FuLFILLING
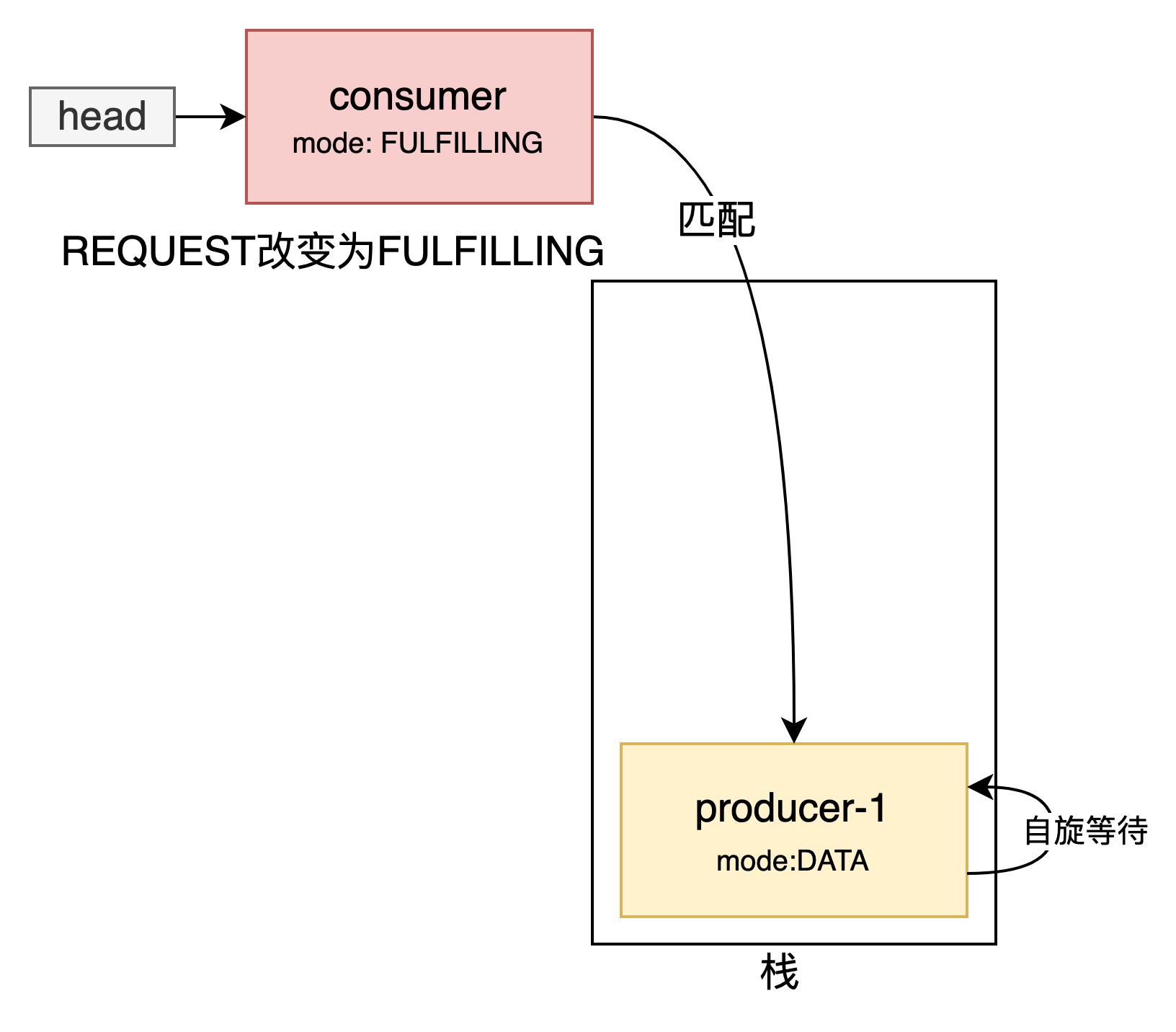
這是TransferStack.transfer的第二個部分,新節點和已經存在的節點進行匹配
else if (!isFulfilling(h.mode)) { // try to fulfill
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
// m 為與當前插入的節點相匹配的節點,也就是之前head指向的節點
SNode m = s.next; // m is s's match
// 如果m取消了則清空整個棧,這裡不用擔心後面的節點,因為clean會將已經取消的節點彈出。m為空就代表沒有節點和該節點匹配了
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
SNode mn = m.next;
// 嘗試匹配
if (m.tryMatch(s)) {
// 匹配成功並彈出
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
// 匹配失敗
s.casNext(m, mn); // help unlink
}
}
}
匹配完成之後將這兩個節點彈出並返回交換的元素
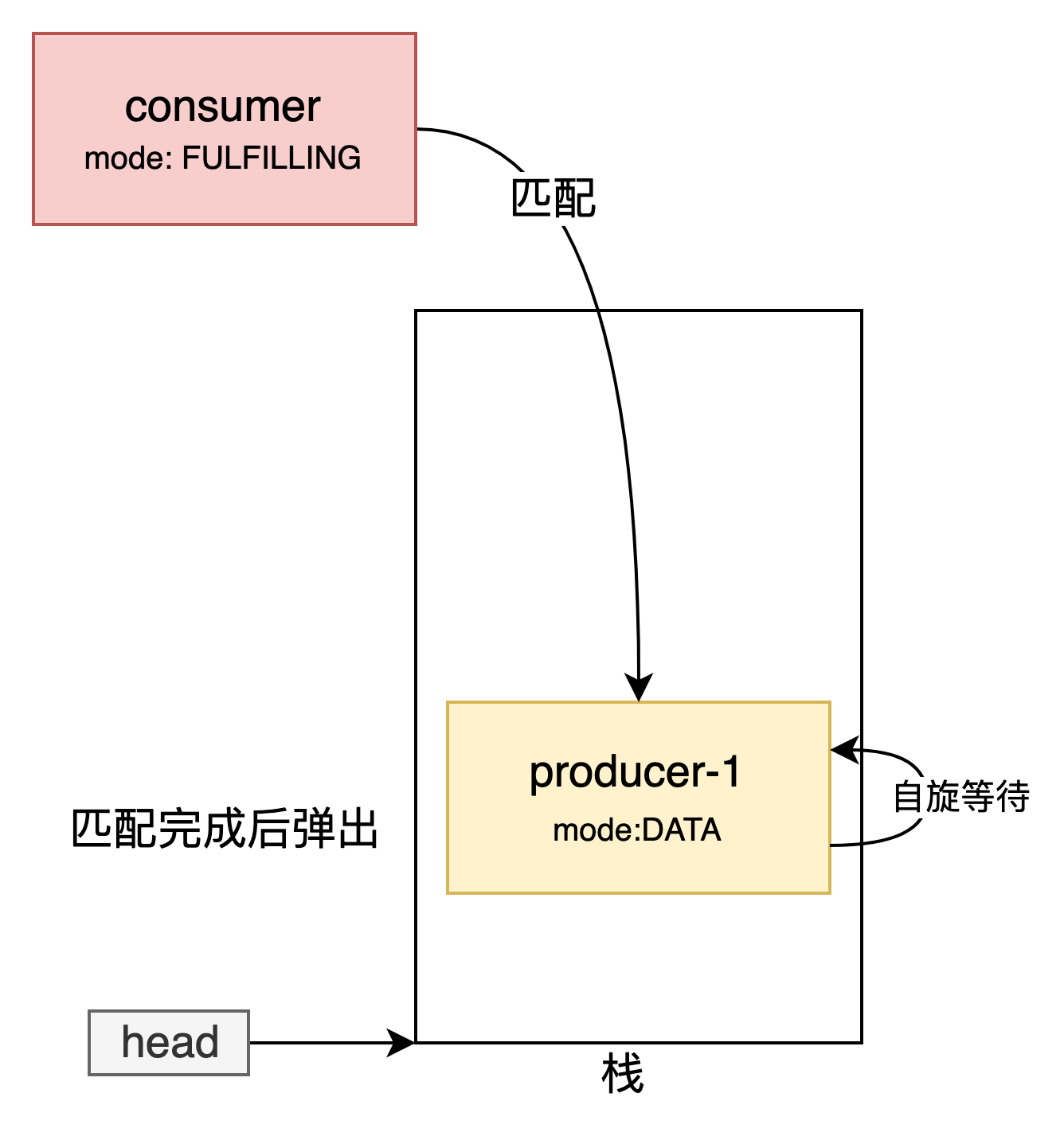
使其他節點可以輔助其他節點完成任務
else {
// 棧頂節點正在進行匹配,幫助棧頂節點完成匹配
SNode m = h.next; // m is h's match
//
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}
先消費者後生產者也是同理
有幾個關鍵方法需要額外注意的:
casHead 是一個通過CAS更新頭節點的方法,J9 之後就不使用 Unsafe 了,改為使用handle
boolean casHead(SNode h, SNode nh) {
return h == head &&
SHEAD.compareAndSet(this, h, nh);
}
awaitFulfill 使使節點自旋等待的一個方法,如果該節點位於頭節點或者是在等待其他節點與自己匹配都會自旋。自旋期間會監測自己的中斷狀態、匹配狀態。如果超過了自旋次數或者該節點不允許等待都會通過LockSupport.park 來使執行緒阻塞。
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = shouldSpin(s)
? (timed ? MAX_TIMED_SPINS : MAX_UNTIMED_SPINS)
: 0;
for (;;) {
if (w.isInterrupted())
s.tryCancel();
SNode m = s.match;
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
if (spins > 0) {
Thread.onSpinWait();
spins = shouldSpin(s) ? (spins - 1) : 0;
}
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
LockSupport.park(this);
else if (nanos > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanos);
}
}
clean 將一個節點移除,用來清理已經中斷(取消)的節點。
最壞的情況下需要遍歷整個棧來移除s。可能會存在多個執行緒並行的刪除其他節點。
該方法從頭部開始尋找所有被取消的節點然後將其刪除
void clean(SNode s) {
s.item = null; // forget item
s.waiter = null; // forget thread
SNode past = s.next;
if (past != null && past.isCancelled())
past = past.next;
// Absorb cancelled nodes at head
SNode p;
// 從頭部開始遇到被取消的節點就出棧
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next);
// Unsplice embedded nodes
// 繼續尋找
while (p != null && p != past) {
SNode n = p.next;
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}
tryMatch 使兩個執行緒相互匹配,並使在等待的執行緒解鎖
boolean tryMatch(SNode s) {
if (match == null &&
// 修改被匹配節點的match狀態,使得該節點能夠了解到自己已經和其他節點匹配了
SMATCH.compareAndSet(this, null, s)) {
// 如果被匹配的節點已經阻塞了,那麼將該節點的執行緒unpark
Thread w = waiter;
if (w != null) { // waiters need at most one unpark
waiter = null;
LockSupport.unpark(w);
}
// 匹配成功
return true;
}
return match == s;
}
從這裡也能看出兩個執行緒是直接交付的,沒有中間商。速度相對來說就會快一點。
下面是該方法的完成程式碼:
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
// 棧頂節點為空或者與棧頂節點模式匹配
if (h == null || h.mode == mode) { // empty or same-mode
if (timed && nanos <= 0L) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
// 建立一個節點並將該節點作為棧頂
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 自旋等待下一個與之匹配的節點
SNode m = awaitFulfill(s, timed, nanos);
// 該節點已經取消等待
if (m == s) {
//清理該節點
clean(s);
return null;
}
// 已經匹配,
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
// 如果當前匹配模式是 REQUEST 那麼就說明在消費,需要返回被匹配的節點
// 如果不是當前模式就是 DATA 說明在生產,需要返回S(是一個生產者)它的item不為
return (E) ((mode == REQUEST) ? m.item : s.item);
}
} else if (!isFulfilling(h.mode)) { // try to fulfill
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
// m 為與當前插入的節點相匹配的節點,也就是之前head指向的節點
SNode m = s.next; // m is s's match
// 如果m取消了則清空整個棧,這裡不用擔心後面的節點,因為clean會將已經取消的節點彈出。m為空就代表沒有節點和該節點匹配了
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
SNode mn = m.next;
// 嘗試匹配
if (m.tryMatch(s)) {
// 匹配成功並彈出
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
// 匹配失敗
s.casNext(m, mn); // help unlink
}
}
} else {
// 棧頂節點正在進行匹配,幫助棧頂節點完成匹配
SNode m = h.next; // m is h's match
//
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}
}
}
公平的TransferQueue
SynchronousQueue通過TransferQueue來實現
QNode 是TransferQueue用來包裝每一個請求的。
final class QNode {
volatile QNode next;  // 該節點指向的下一個節點
volatile Object item; //
volatile Thread waiter; // 用來控制執行緒的狀態 unpark 或 park
final boolean isData; // 用來標記該節點為生產者還是消費者
....
}
一些屬性值
// 佇列頭
transient volatile QNode head;
// 佇列尾
transient volatile QNode tail;
// 一個標誌,用來輔助刪除節點
transient volatile QNode cleanMe;
和TransferStack一樣,都是通過transfer方法來實現交付的,邏輯相對TransferStack.transfer更加簡單一點,主要分為以下兩種情況:
- 佇列為空或者與頭節點型別相同,將該節點新增到佇列中,改變頭的狀態並自旋等待其他節點與自己匹配,匹配成功後返回互動的元素。
- 如果當前佇列包含正在等待的節點並與頭節點相匹配(消費者-生產者或者生產者-消費者),嘗試去匹配頭節點,匹配成功則出隊,返回互動的元素。
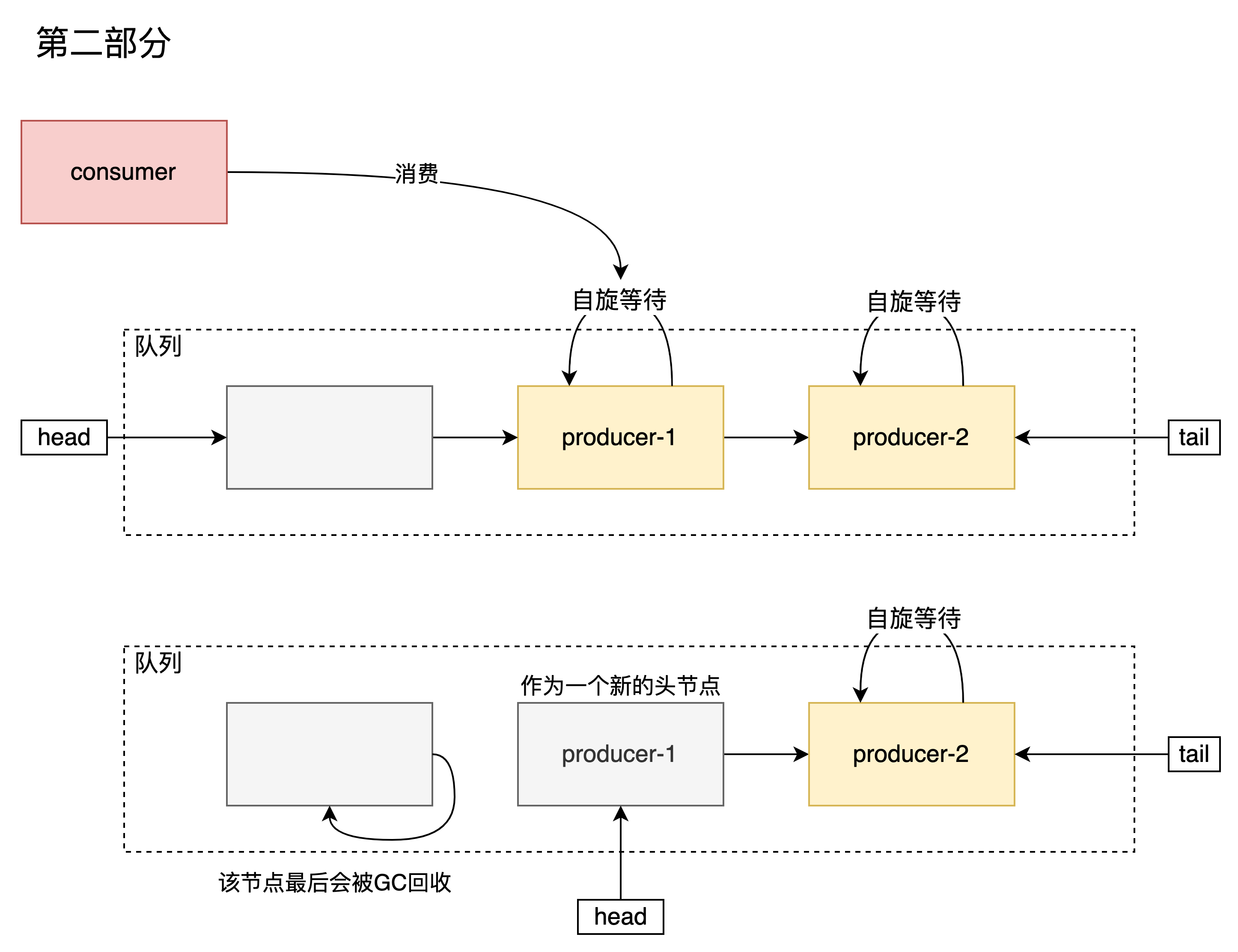
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // saw uninitialized value
continue; // spin
// 情況一:入隊
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
// 尾節點被修改,其他節點操作還未完成。迴圈等待
if (t != tail) // inconsistent read
continue;
// 尾節點後還連結了其他的節點說明當前尾節點不是尾節點,需要更新
if (tn != null) { // lagging tail
advanceTail(t, tn);
continue;
}
// 如果當前節點不允許等待,則退出
if (timed && nanos <= 0L) // can't wait
return null;
// 建立節點
if (s == null)
s = new QNode(e, isData);
// 放到隊尾,如果失敗則重新嘗試
if (!t.casNext(null, s)) // failed to link in
continue;
// 當前節點為尾節點,更新t指標
advanceTail(t, s); // swing tail and wait
// 自旋等待其他節點匹配
Object x = awaitFulfill(s, e, timed, nanos);
// 說明當前節點被取消
if (x == s) { // wait was cancelled
// 清除該節點
clean(t, s);
return null;
}
// 該節點可能未從佇列中移除,需要處理s為隊尾的情況
if (!s.isOffList()) { // not already unlinked
// 更新頭節點
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
// 情況二:出隊
} else { // complementary-mode
QNode m = h.next; // node to fulfill
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
// 在並行的情況下m已經和其他節點匹配或者是m已經取消了
// 當前節點為生產者(型別相同)
if (isData == (x != null) || // m already fulfilled
// m已經取消
x == m || // m cancelled
// 更新m的值,標識m已經和自己匹配,如果更新失敗則m已經匹配或者是取消了
!m.casItem(x, e)) { // lost CAS
// 如果m不能和自己匹配
advanceHead(h, m); // dequeue and retry
continue;
}
// 成功匹配並出隊
advanceHead(h, m); // successfully fulfilled
// 停止阻塞被匹配的節點
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
如果消費者或生產者被取消了,那麼需要將其從佇列中刪除,完成這個操作的是clean
分為三種情況:
- 如果該節點不是尾節點則直接刪除
- 如果該節點是尾節點,但是cleanMe為空,則將cleanMe置為當前節點的前繼節點(意思就是一會再刪,應該該節點現在不能被刪除)
- 如果cleanMe不為空,則根據cleanMe刪除需要刪除的節點。如果當前節點的前繼節點不為cleanMe則對應步驟2,否則置為空。
尾節點如果直接刪除會導致一些並行問題
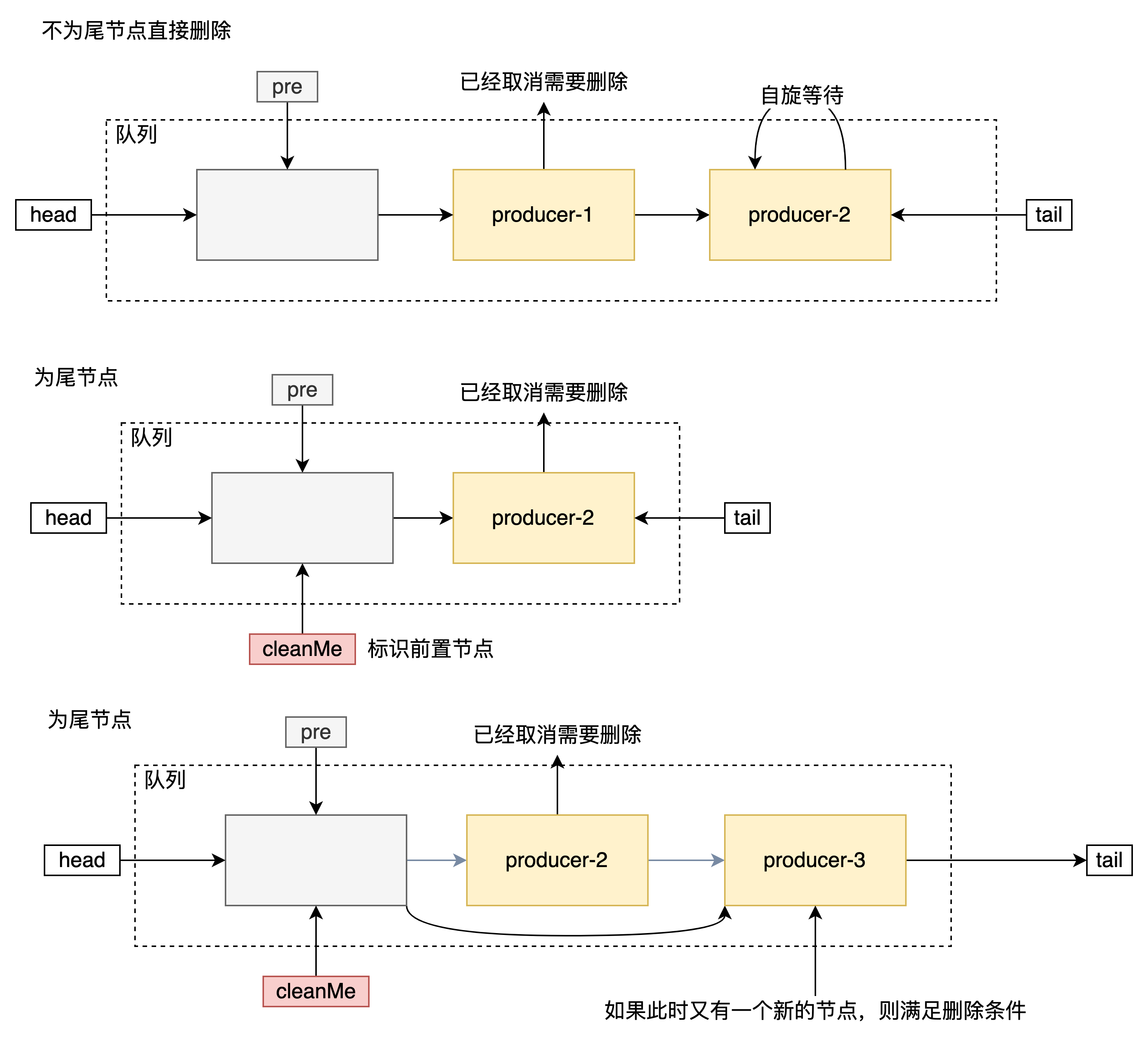
void clean(QNode pred, QNode s) {
s.waiter = null; // forget thread
while (pred.next == s) { // Return early if already unlinked
QNode h = head;
QNode hn = h.next; // Absorb cancelled first node as head
// 從頭開始,如果有被取消的節點則跳過該節點
if (hn != null && hn.isCancelled()) {
advanceHead(h, hn);
continue;
}
// 確保尾節點的讀一致性
QNode t = tail; // Ensure consistent read for tail
if (t == h)
return;
QNode tn = t.next
// 尾節點不一致,重新開始
if (t != tail)
continue;
// 又有新節點插入,更新尾節點
if (tn != null) {
advanceTail(t, tn);
continue;
}
// s 不為尾節點直接刪除s
if (s != t) { // If not tail, try to unsplice
QNode sn = s.next;
if (sn == s || pred.casNext(s, sn))
return;
}
// 這裡說明s目前還不能刪除,只能刪除上一次需要刪除的節點。
// cleanMe儲存著上一次需要刪除節點的前繼節點
QNode dp = cleanMe;
if (dp != null) { // Try unlinking previous cancelled node
// d 為待刪除節點
QNode d = dp.next;
QNode dn;
// 檢查d的狀態
// d 已經為空則說明已經被刪除,所以要刪除d,d不能被刪除
if (d == null || // d is gone or
// d 不能離開佇列
d == dp || // d is off list or
// d 節點不能被取消
!d.isCancelled() || // d not cancelled or
// d 不能為尾節點
(d != t && // d not tail and
// d 有後繼節點
(dn = d.next) != null && // has successor
dn != d && // that is on list
// 刪除d
dp.casNext(d, dn))) // d unspliced
// 清除cleanMe的狀態
casCleanMe(dp, null);
// cleanMe 已經儲存了 s 的狀態,但是s不滿足刪除的條件
if (dp == pred)
return; // s is already saved node
// 將cleanMe
} else if (casCleanMe(null, pred))
return; // Postpone cleaning s
}
}
如果佇列中沒有出現能與之相匹配的節點,則該節點就自旋等待,完成這個操作的是awaitFulfill,和TransferStack中的差不太多
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread ();
// 自旋次數
int spins = (head.next == s)
? (timed ? MAX_TIMED_SPINS : MAX_UNTIMED_SPINS)
: 0;
for (;;) {
// 當前執行緒是否阻塞
if (w.isInterrupted())
s.tryCancel (e);
// 匹配項,用於檢測是否被匹配
Object x = s.item;
if (x != e)
return x;
// 是否超時
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
// 用來控制自旋次數
if (spins > 0) {
--spins;
Thread.onSpinWait();
}
else if (s.waiter == null)
s.waiter = w;
// 該執行緒不允許等待,則阻塞
else if (!timed)
LockSupport.park (this);
// 過一定時間阻塞
else if (nanos > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanos);
}
}
總結
SynchrounousQueue 和常見的阻塞佇列比起來處理方式不一樣,也比較難理解。
對於不公平和不公平分為了兩種實現方式,利用了FIFO(公平)和LIFO(不公平)的特性來實現。
相比於可儲存的佇列,SynchronousQueue導致其他執行緒就必須自旋等待交付,所以如果交付佔用了大量時間就導致其他執行緒就需要等待特別久的時間,但好處是不需要儲存而且是直接交付的。
SynchronousQueue還有一些理解不到位的地方,以上僅供參考。
參考
Java 阻塞佇列 SynchronousQueue 詳解
【JUC】JDK1.8原始碼分析之SynchronousQueue(九)
深入淺出SynchronousQueue佇列(二)