學會使用MySQL的Explain執行計劃,SQL效能調優從此不再困難
上篇文章講了MySQL架構體系,瞭解到MySQL Server端的優化器可以生成Explain執行計劃,而執行計劃可以幫助我們分析SQL語句效能瓶頸,優化SQL查詢邏輯,今天就一塊學習Explain執行計劃的具體用法。
1. explain的使用
使用EXPLAIN關鍵字可以模擬優化器執行SQL語句,分析你的查詢語句或是結構的效能瓶頸。
在 select 語句之前增加 explain 關鍵字,MySQL 會在查詢上設定一個標記,執行查詢會返回執行計劃的資訊,並不會執行這條SQL。
就比如下面這個:
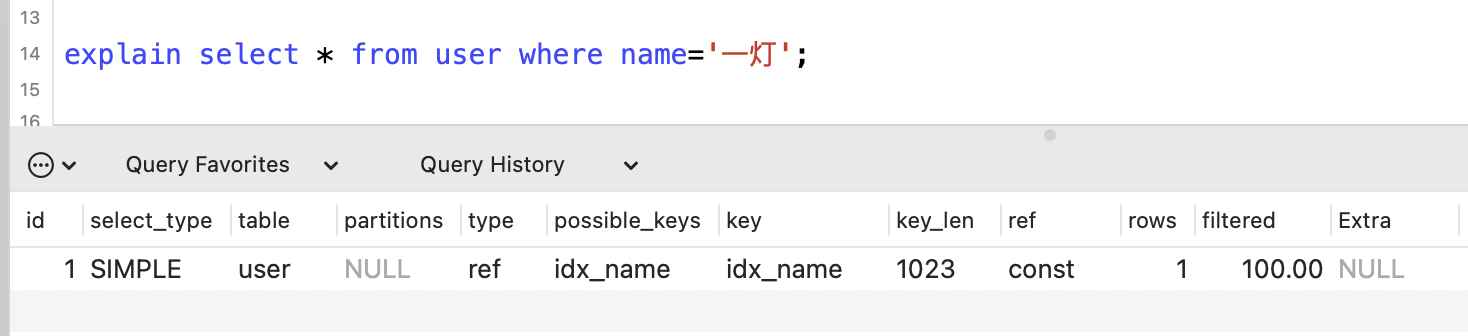
輸出這麼多列都是幹嘛用的?
其實大都是SQL語句的效能統計指標,先簡單總結一下每一列的大致作用,下面詳細講一下:
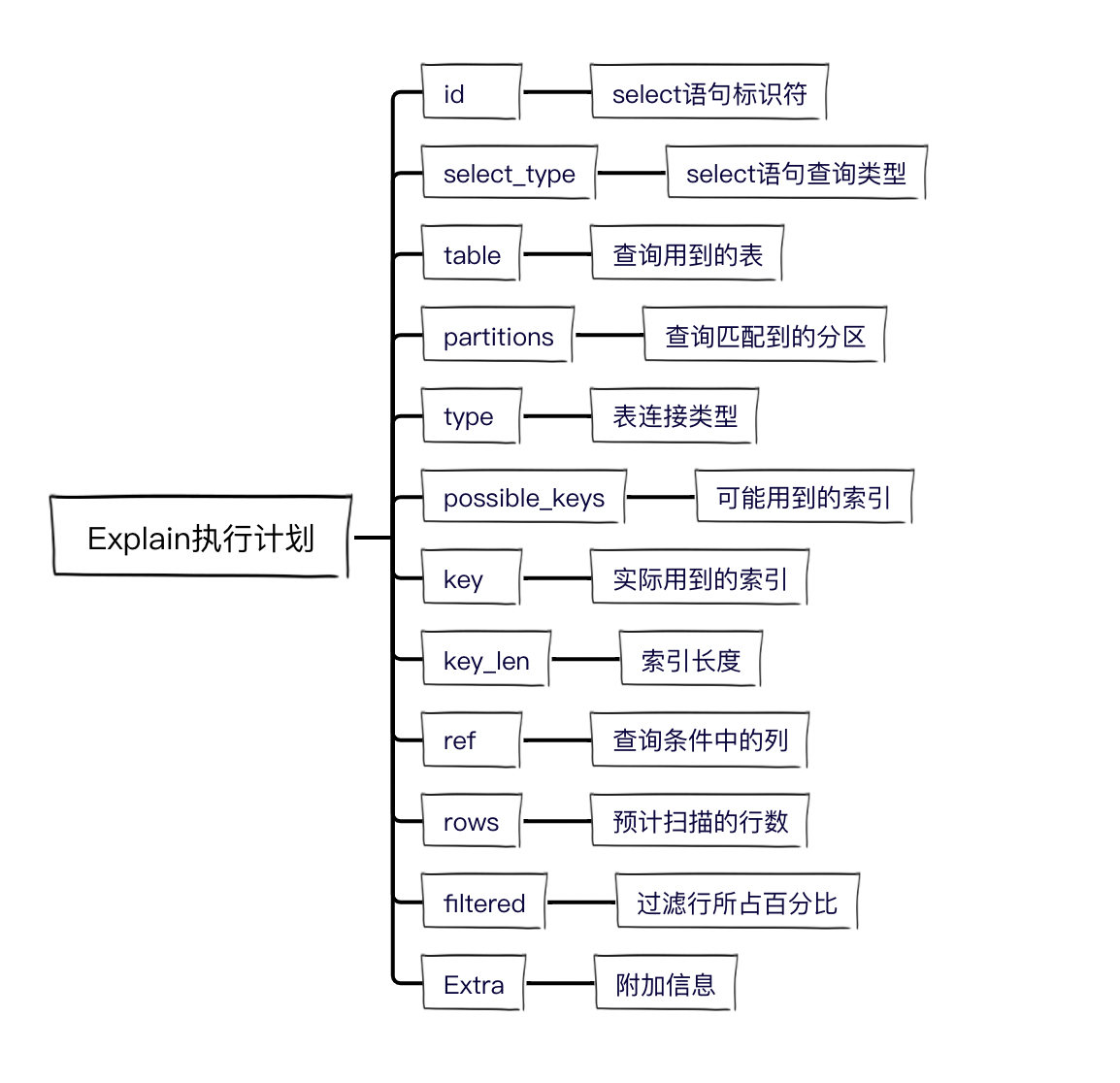
2. explain欄位詳解
下面就詳細講一下每一列的具體作用。
1. id列
id表示查詢語句的序號,自動分配,順序遞增,值越大,執行優先順序越高。
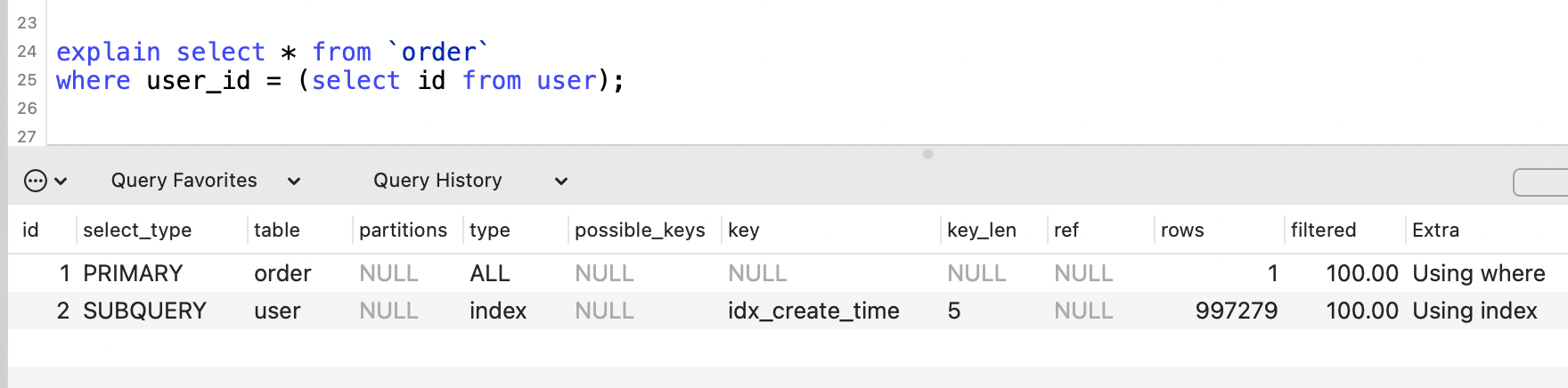
id相同時,優先順序由上而下。
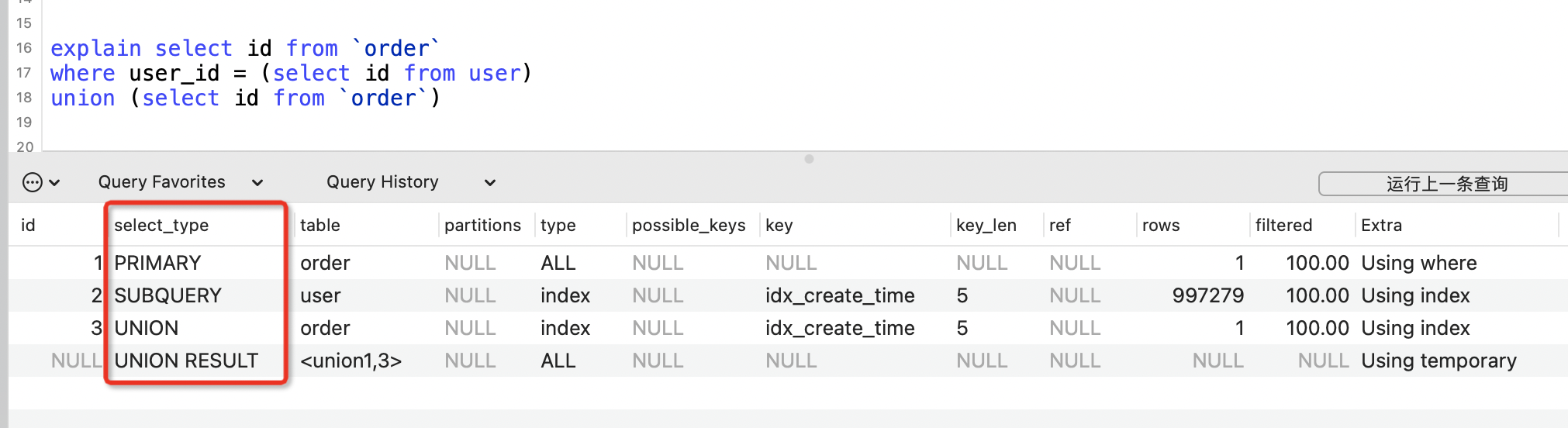
2. select_type列
select_type表示查詢型別,常見的有SIMPLE簡單查詢、PRIMARY主查詢、SUBQUERY子查詢、UNION聯合查詢、UNION RESULT聯合臨時表結果等。
3. table列
table表示SQL語句查詢的表名、表別名、臨時表名。

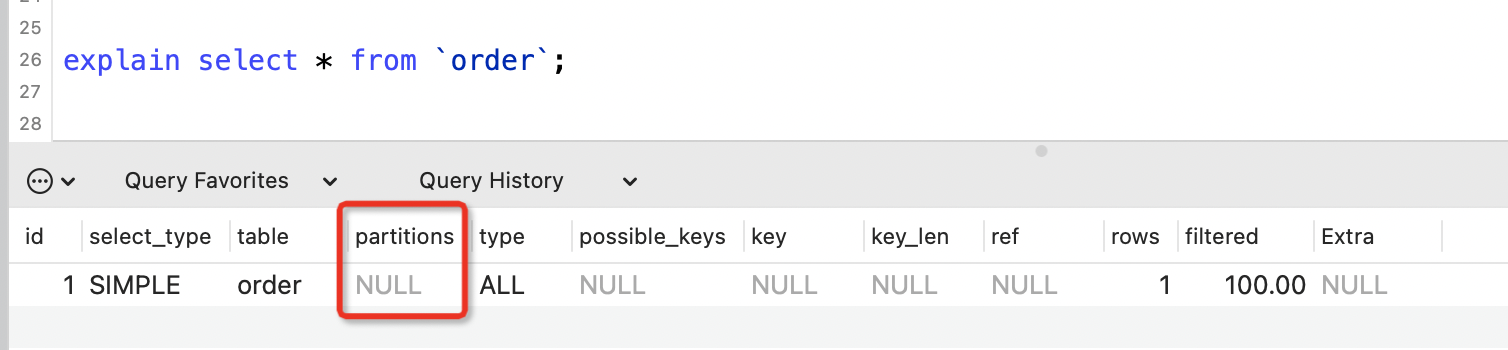
4. partitions列
partitions表示SQL查詢匹配到的分割區,沒有分割區的話顯示NULL。
5. type列
type表示表連線型別或者資料存取型別,就是表之間通過什麼方式建立連線的,或者通過什麼方式存取到資料的。
具體有以下值,效能由好到差依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system
當表中只有一行記錄,也就是系統表,是 const 型別的特列。

const
表示使用主鍵或者唯一性索引進行等值查詢,最多返回一條記錄。效能較好,推薦使用。

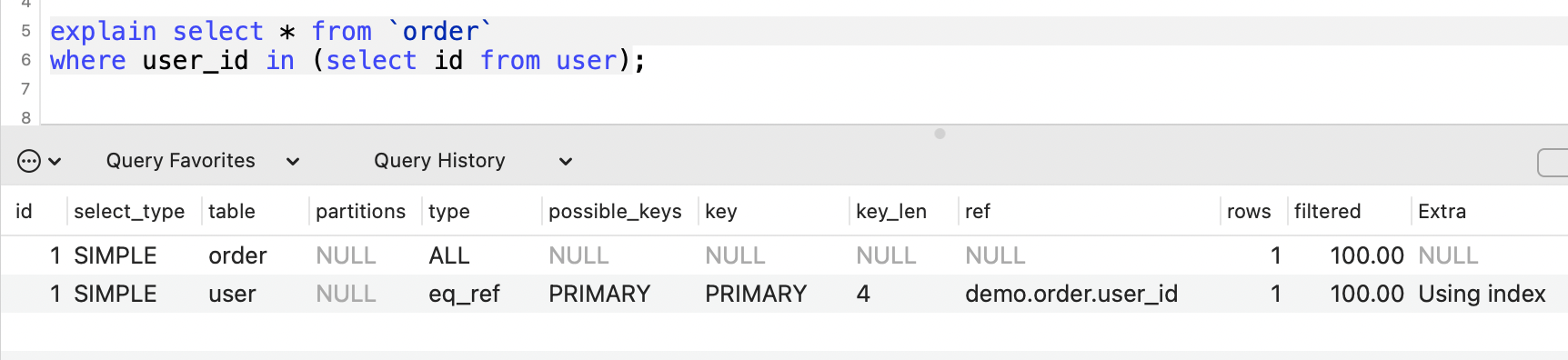
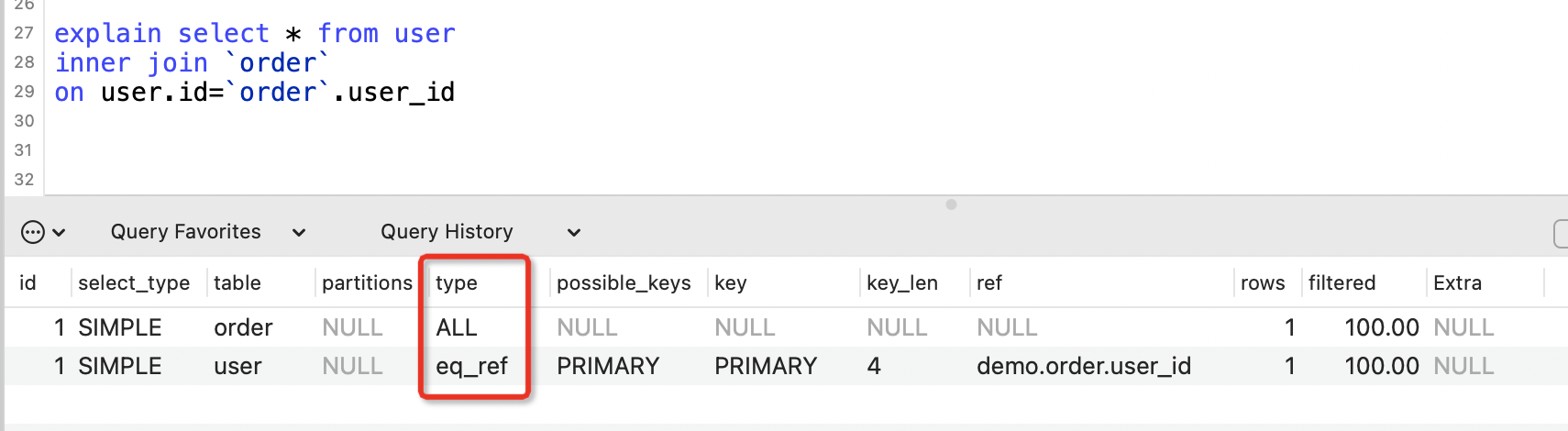
eq_ref
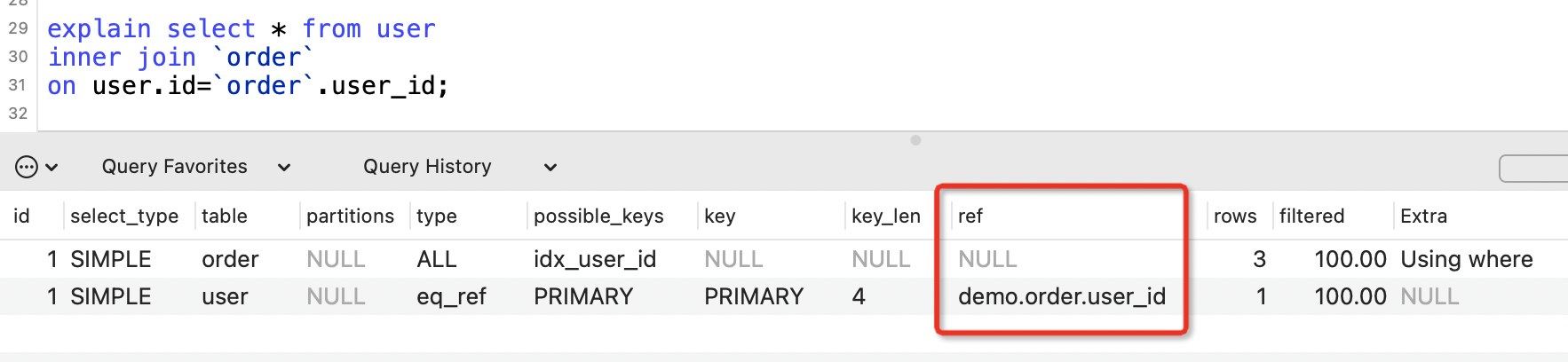
表示表連線使用到了主鍵或者唯一性索引,下面的SQL就用到了user表主鍵id。
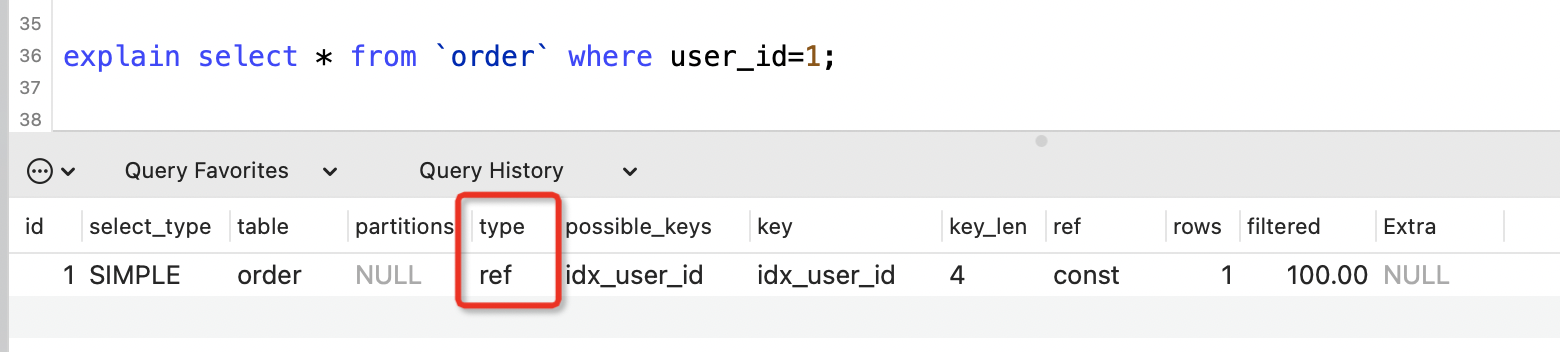
ref
表示使用非唯一性索引進行等值查詢。
ref_or_null
表示使用非唯一性索引進行等值查詢,並且包含了null值的行。

index_merge
表示用到索引合併的優化邏輯,即用到的多個索引。

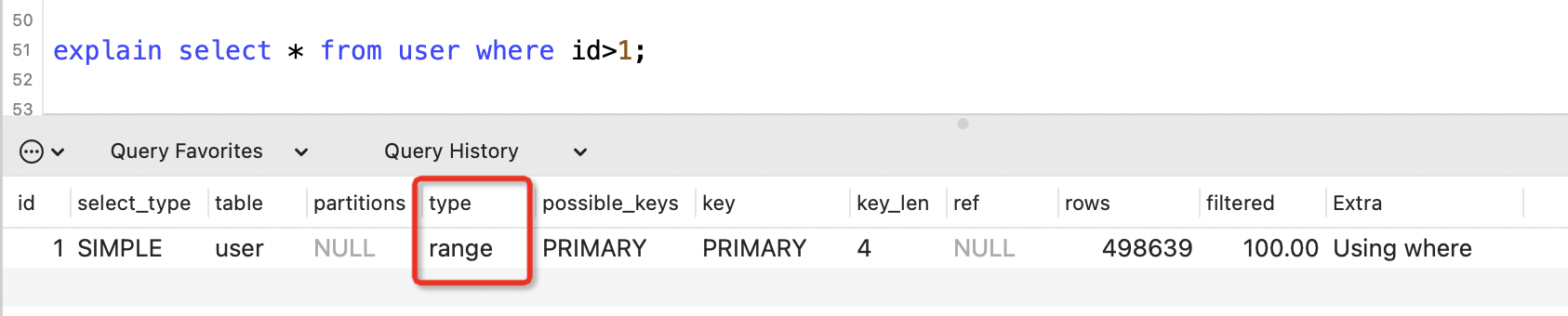
range
表示用到了索引範圍查詢。
index
表示使用索引進行全表掃描。

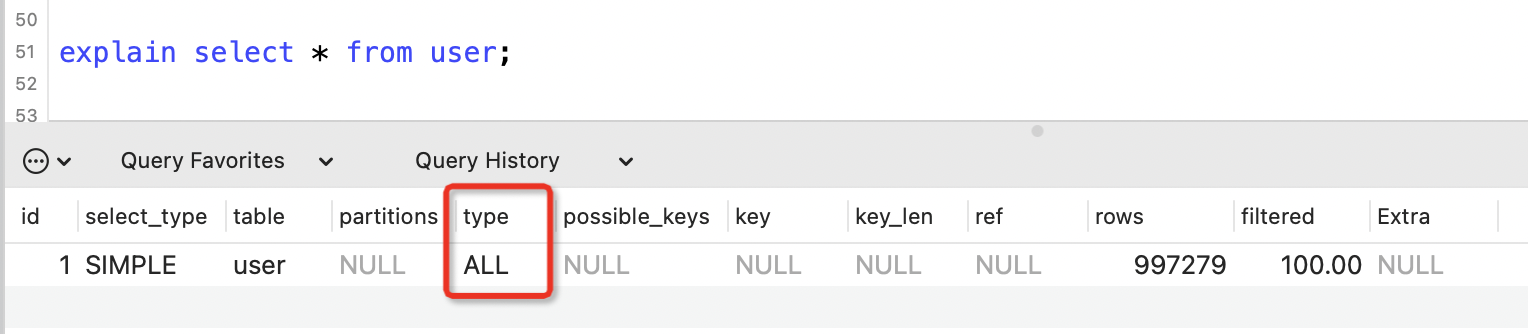
ALL
表示全表掃描,效能最差。
6. possible_keys列
表示可能用到的索引列,實際查詢並不一定能用到。

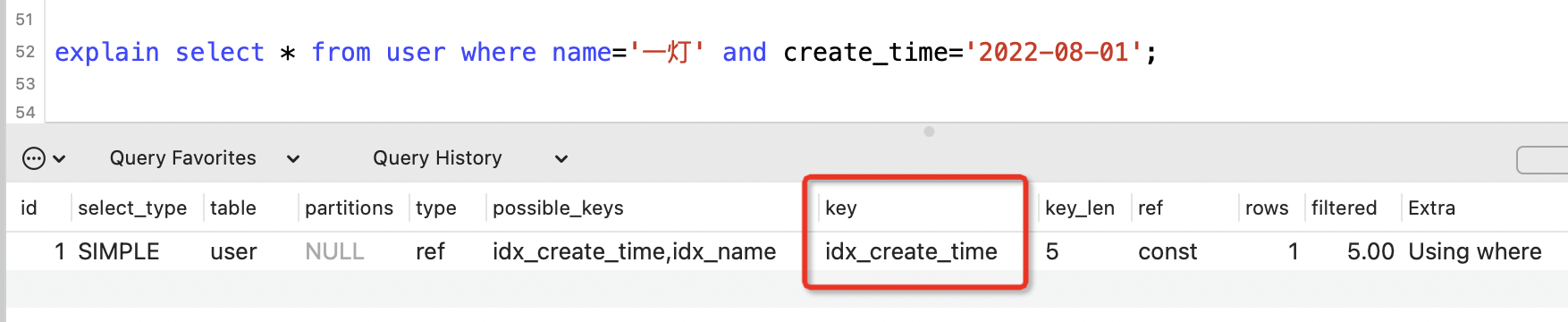
7. key列
表示實際查詢用到索引列。
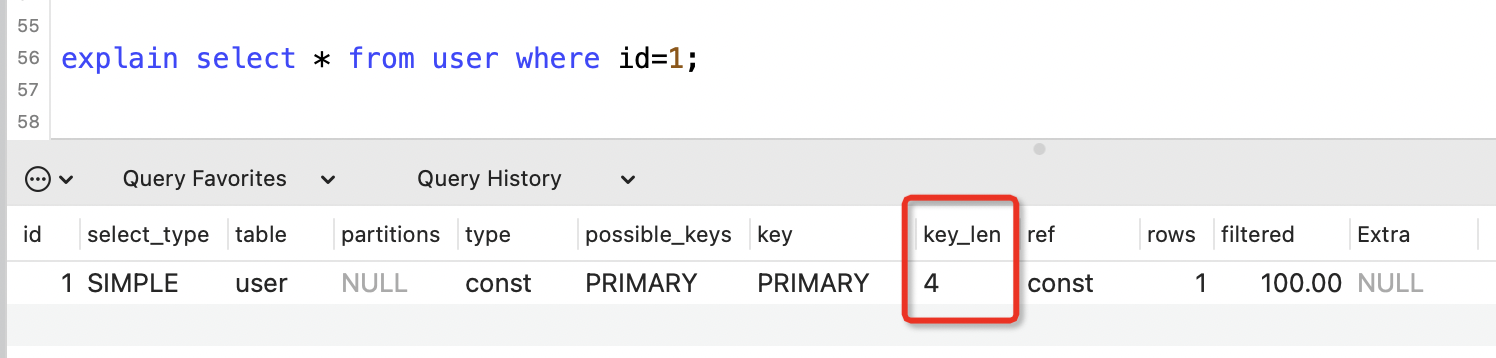
8. key_len列
表示索引所佔的位元組數。
每種型別所佔的位元組數如下:
| 型別 | 佔用空間 |
|---|---|
| char(n) | n個位元組 |
| varchar(n) | 2個位元組儲存變長字串,如果是utf-8,則長度 3n + 2 |
| tinyint | 1個位元組 |
| smallint | 2個位元組 |
| int | 4個位元組 |
| bigint | 8個位元組 |
| date | 3個位元組 |
| timestamp | 4個位元組 |
| datetime | 8個位元組 |
| 欄位允許為NULL | 額外增加1個位元組 |
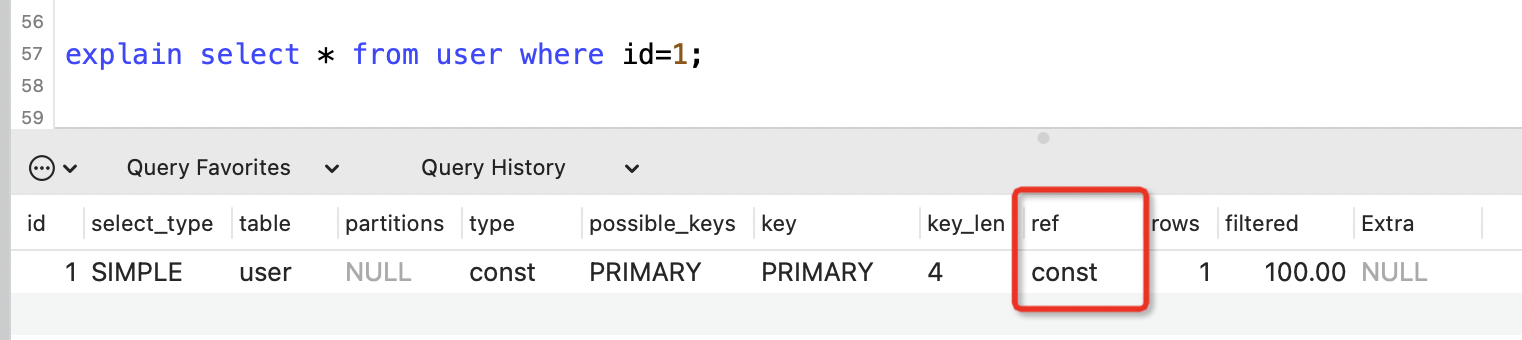
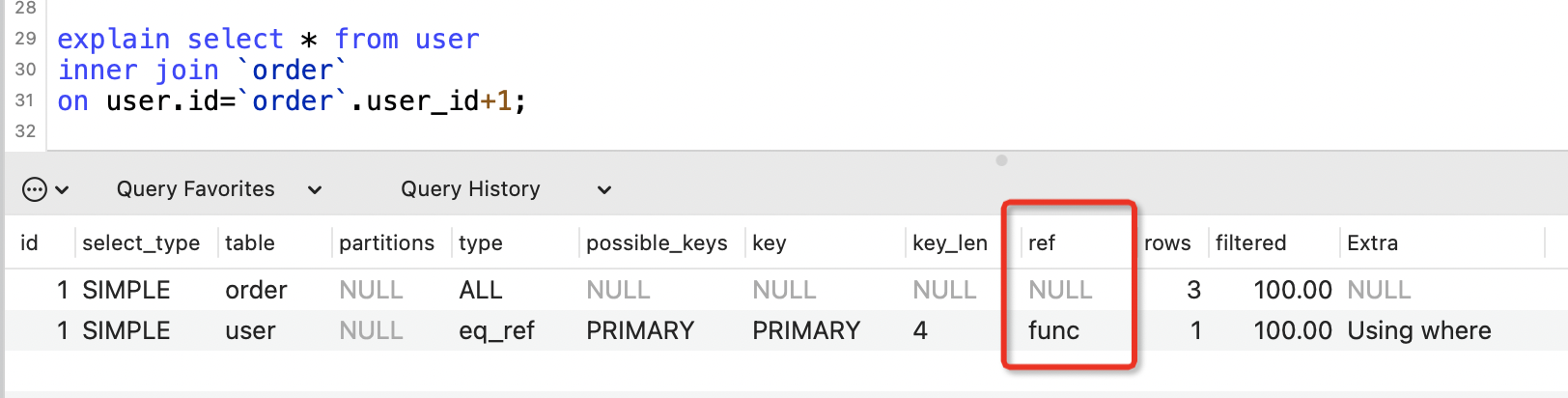
9. ref列
表示where語句或者表連線中與索引比較的引數,常見的有const(常數)、func(函數)、欄位名。
如果沒用到索引,則顯示為NULL。
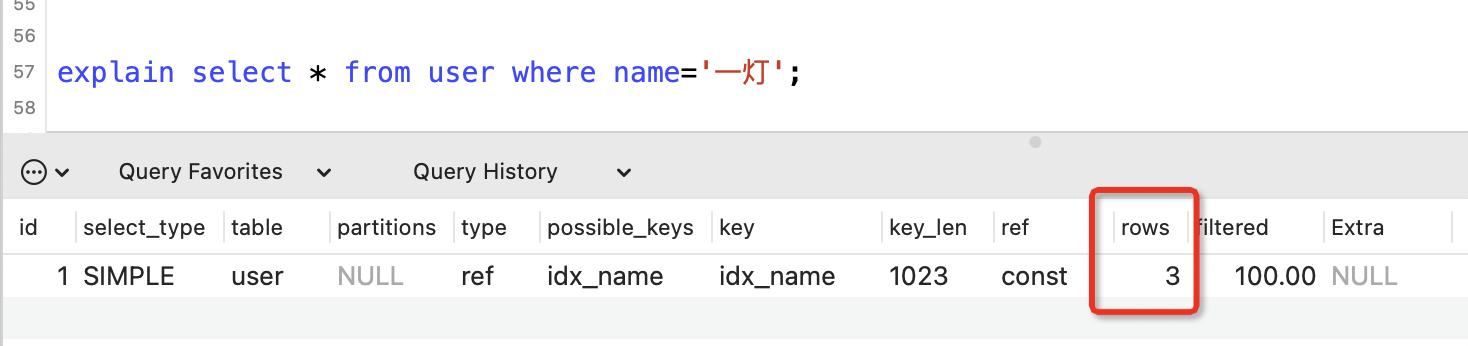
10. rows列
表示執行SQL語句所掃描的行數。
11. filtered列
表示按條件過濾的錶行的百分比。
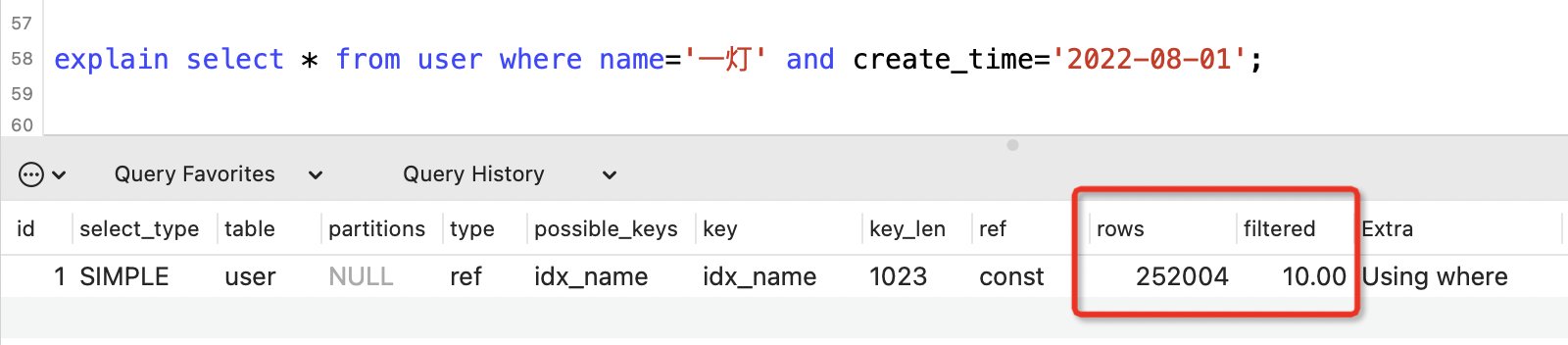
用來估算與其他表連線時掃描的行數,row x filtered = 252004 x 10% = 25萬行
12. Extra列
表示一些額外的擴充套件資訊,不適合在其他列展示,卻又十分重要。
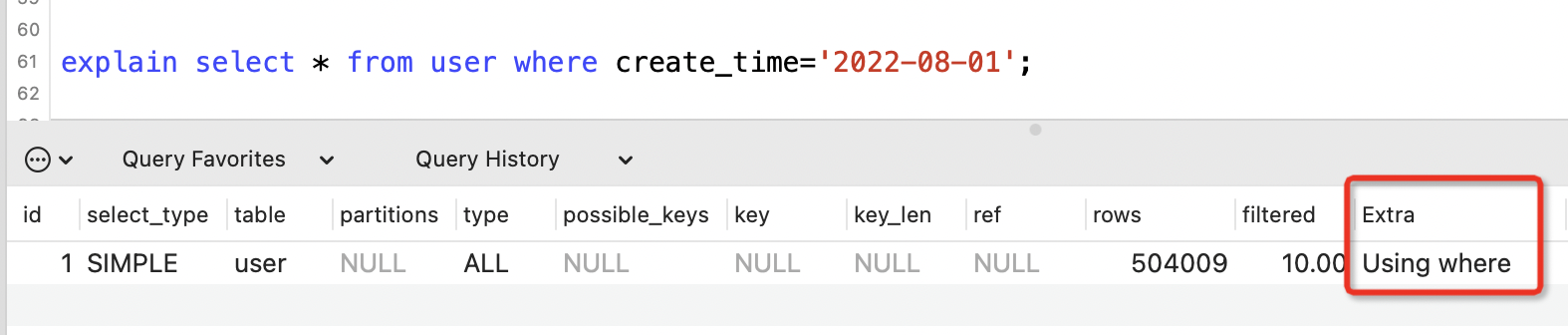
Using where
表示使用了where條件搜尋,但沒有使用索引。
Using index
表示用到了覆蓋索引,即在索引上就查到了所需資料,無需二次回表查詢,效能較好。

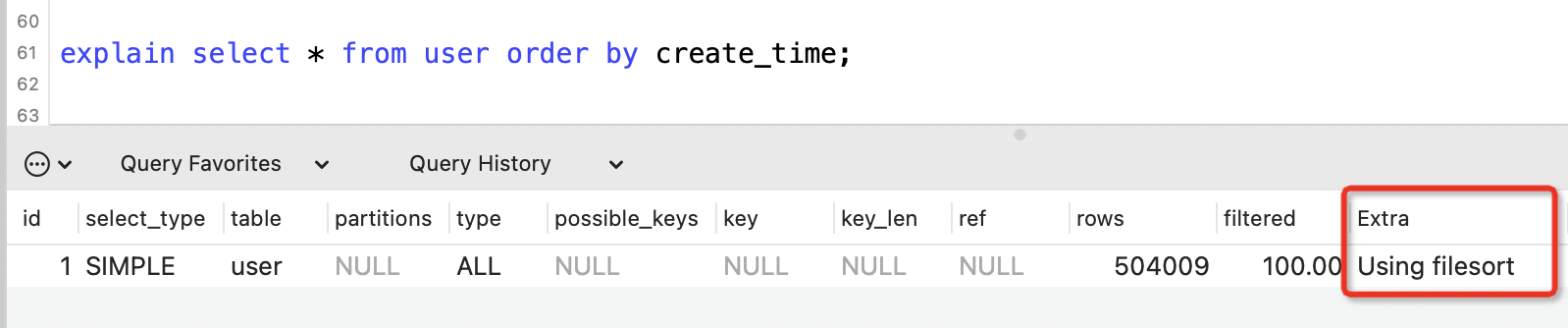
Using filesort
表示使用了外部排序,即排序欄位沒有用到索引。
Using temporary
表示用到了臨時表,下面的範例中就是用到臨時表來儲存查詢結果。

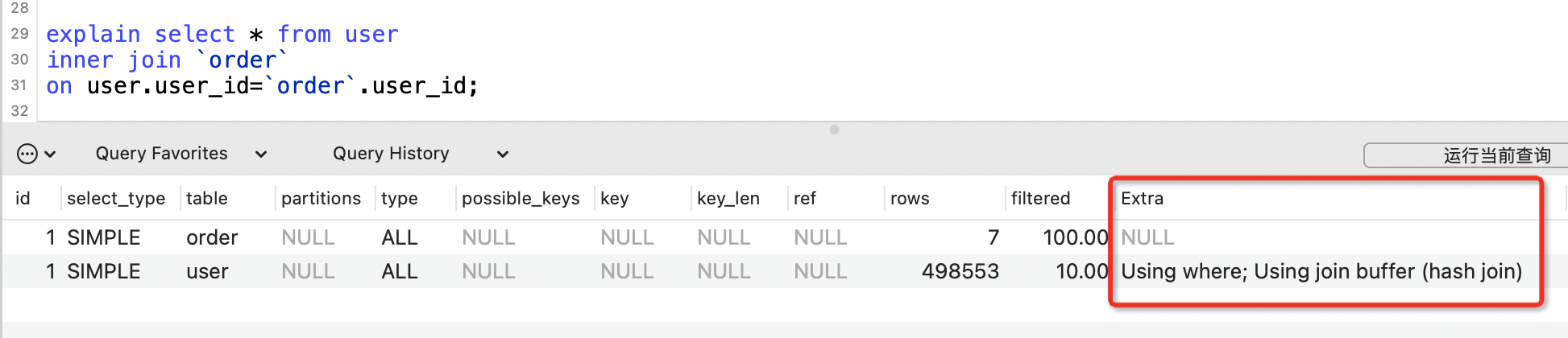
Using join buffer
表示在進行表關聯的時候,沒有用到索引,使用了連線快取區儲存臨時結果。
下面的範例中user_id在兩張表中都沒有建索引。
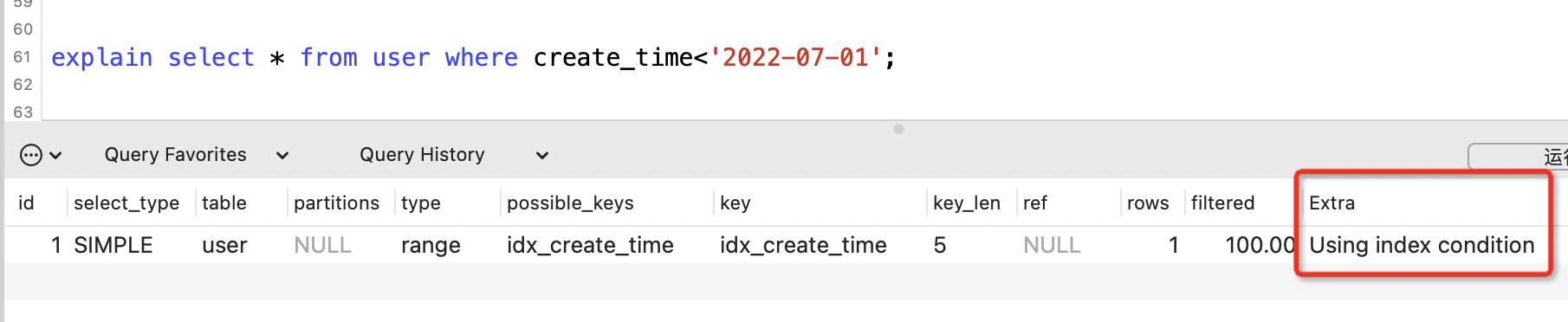
Using index condition
表示用到索引下推的優化特性。
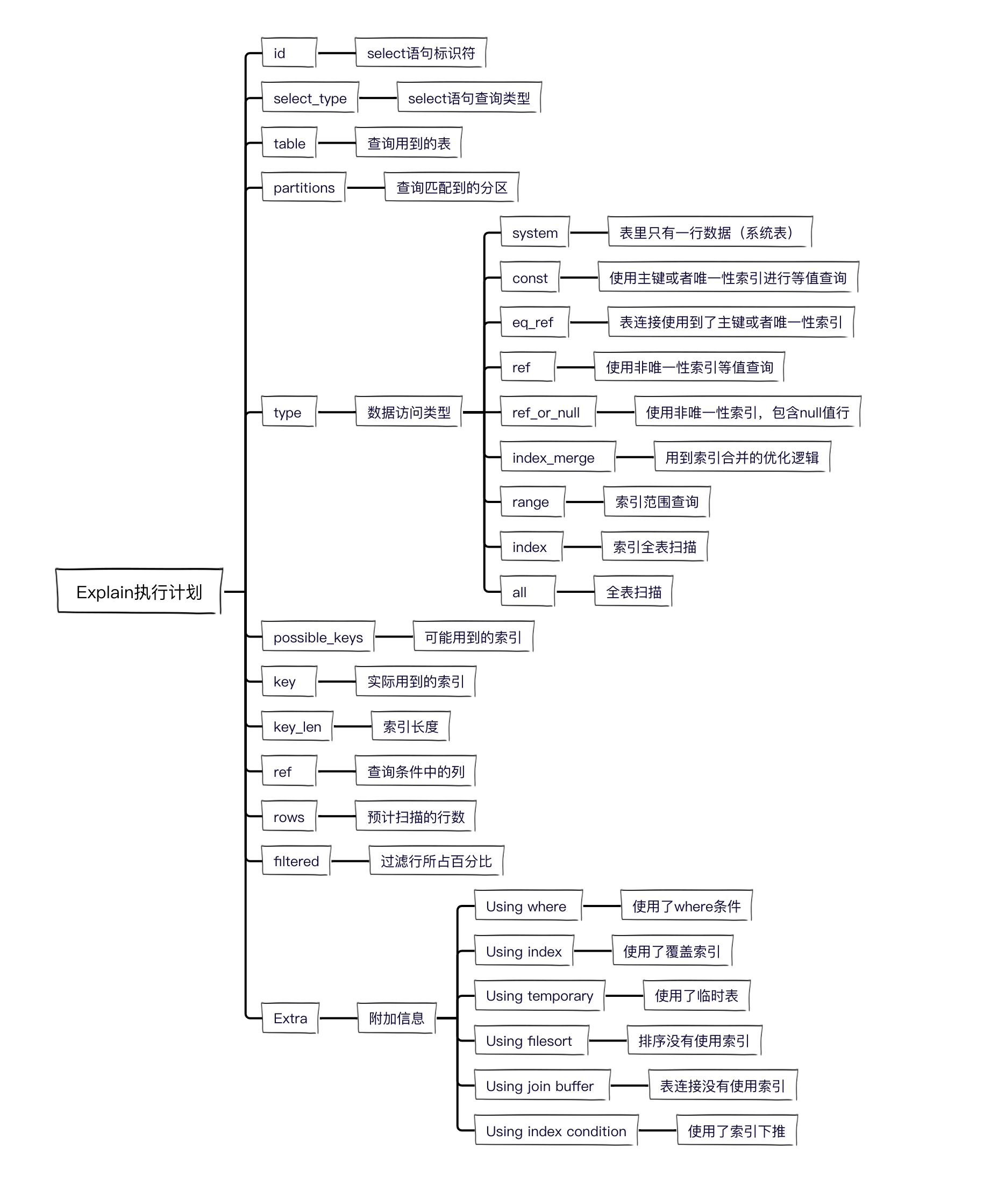
知識點總結:
本文詳細介紹了Explain使用方式,以及每種引數所代表的含義。無論是工作還是面試,使用Explain優化SQL查詢,都是必備的技能,一定要牢記。
下篇再一塊學習一下SQL查詢的其他優化方式,敬請期待。
文章持續更新,可以微信搜一搜「 一燈架構 」第一時間閱讀更多技術乾貨。