如何組裝一個註冊中心
hello,大家好呀,我是小樓。今天不寫BUG,來聊一聊註冊中心。
標題本來想叫《如何設計一個註冊中心》,但網上已經有好多類似標題的文章了。所以打算另闢蹊徑,換個角度,如何組裝一個註冊中心。
組裝意味著不必從0開始造輪子,這也比較符合許多公司對待自研基礎元件的態度。
知道如何組裝一個註冊中心有什麼用呢?
第一可以更深入理解註冊中心。以我個人經歷來說,註冊中心的第一印象就是Dubbo的Zookeeper(以下簡稱zk),後來逐漸深入,學會了如何去zk上檢視Dubbo註冊的資料,並能排查一些問題。後來瞭解了Nacos,才發現,原來註冊中心還可以如此簡單,再後來一直從事服務發現相關工作,對一些細枝末節也有了一些新的理解。
第二可以學習技術選型的方法,註冊中心中的每個模組,都會在不同的需求下有不同的選擇,最終的選擇取決於對需求的把握以及技術視野,但這兩項是內功,一時半會練不成,學個選型的方法還是可以的。
本文打算從需求分析開始,一步步拆解各個模組,整個註冊中心以一種如無必要,勿增實體的原則進行組裝,但也不會是個玩具,向生產可用對齊。
當然在實際專案中,不建議重複造輪子,儘量用現成的解決方案,所以本文僅供學習參考。
需求分析
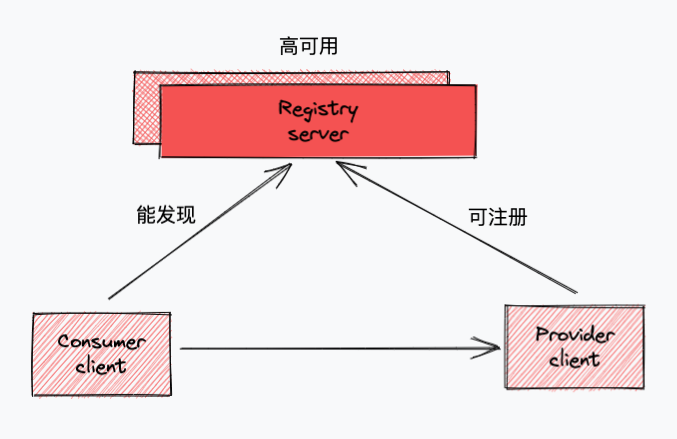
本文的註冊中心需求很簡單,就三點:可註冊、能發現、高可用。
服務的註冊和發現是註冊中心的基本功能,高可用則是生產環境的基本要求,如果高可用不要求,那本文可講解的內容就很少,上圖中的高可用標註只是個示意,高可用在很多方面都有體現。
至於其他花裡胡哨的功能,我們暫且不表。
我們這裡介紹三個角色,後文以此為基礎:
- 提供者(Provider):服務的提供方(被呼叫方)
- 消費者(Consumer):服務的消費方(呼叫方)
- 註冊中心(Registry):本文主角,服務提供列表、消費關係等資料的儲存方
介面定義
註冊中心和使用者端(SDK)的互動介面有三個:
- 註冊(register),將服務提供方註冊到註冊中心
- 登出(unregister),將註冊的服務從註冊中心中刪除
- 訂閱(subscribe),服務消費方訂閱需要的服務,訂閱後提供方有變更將通知到對應的消費方
註冊、登出可以是服務提供方的程序發起,也可以是其他的旁路程式輔助發起,比如釋出系統在釋出一臺機器完成後,可呼叫註冊介面,將其註冊到註冊中心,登出也是類似流程,但這種方式並不多見,而且如果只考慮實現一個註冊中心,必然是可以單獨執行的,所以通常註冊、登出由提供方程序負責。
有了這三個介面,我們該如何去定義介面呢?註冊服務到底有哪些欄位需要註冊?訂閱需要傳什麼欄位?以什麼序列化方式?用什麼協定傳輸?
這些問題接踵而來,我覺得我們先不急著去做選擇,先看看這個領域有沒有相關標準,如果有就參考或者直接按照標準實現,如果沒有,再來分析每一點的選擇。
服務發現還真有一套標準,但又不完全有。它叫OpenSergo,它其實是服務治理的一套標準,包含了服務發現:
OpenSergo 是一套開放、通用的、面向分散式服務架構、覆蓋全鏈路異構化生態的服務治理標準,基於業界服務治理場景與實踐形成通用標準規範。OpenSergo 的最大特點就是以統一的一套設定/DSL/協定定義服務治理規則,面向多語言異構化架構,做到全鏈路生態覆蓋。無論微服務的語言是 Java, Go, Node.js 還是其它語言,無論是標準微服務還是 Mesh 接入,從閘道器到微服務,從資料庫到快取,從服務註冊發現到設定,開發者都可以通過同一套 OpenSergo CRD 標準設定針對每一層進行統一的治理管控,而無需關注各框架、語言的差異點,降低異構化、全鏈路服務治理管控的複雜度。
我們需要的服務註冊與發現也被納入其中:
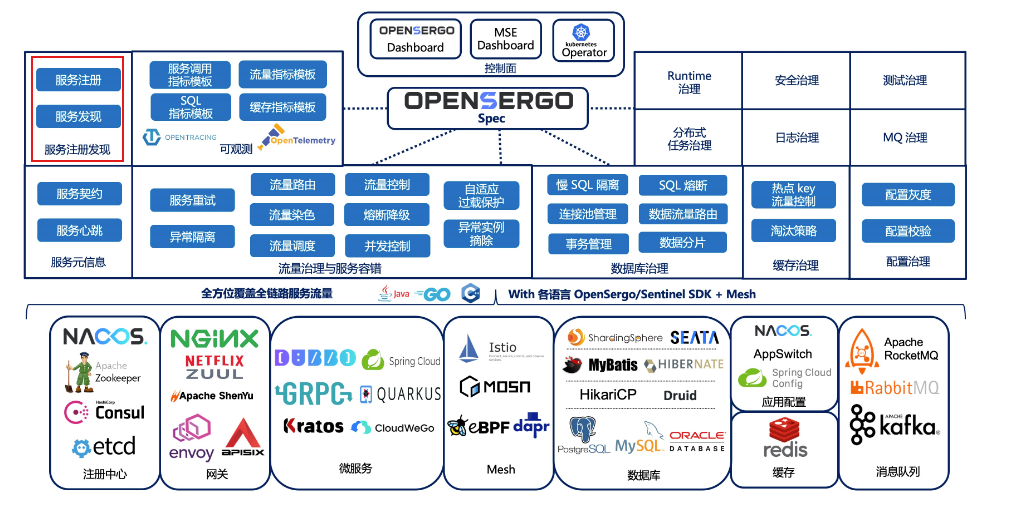
說有但也不是完全有是因為這個標準還在建設中,服務發現相關的標準在寫這篇文章的時候還沒有給出。
既然沒有標準,可以結合現有的系統以及經驗來定義,這裡我用json的序列化方式給出,以下為筆者的總結,不能囊括所有情形,需要時根據業務適當做一些調整:
- 服務註冊入參
{
"application":"provider_test", // 應用名
"protocol":"http", // 協定
"addr":"127.0.0.1:8080", // 提供方的地址
"meta":{ // 攜帶的後設資料,以下三個為範例
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
}
- 服務訂閱入參
{
"subscribes":[
{
"provider":"test_provider1", // 訂閱的應用名
"protocol":"http", // 訂閱的協定
"meta":{ // 攜帶的後設資料,以下為範例
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
},
{
"provider":"test_provider2",
"protocol":"http",
"meta":{
"cluster":"small",
"tag":"read"
}
}
]
}
- 服務發現出參
{
"version":"23des4f", // 版本
"endpoints":[ // 範例
{
"application":"provider_test",
"protocol":"http",
"addr":"127.0.0.1:8080",
"meta":{
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
},
{
"application":"provider_test",
"protocol":"http",
"addr":"127.0.0.2:8080",
"meta":{
"cluster":"small",
"idc":"shanghai",
"tag":"read"
}
}
]
}
變更推播 & 服務健康檢查
有了定義,我們如何選擇序列化方式?選擇序列化方式有兩個重要參考點:
- 語言的適配程度,比如 json 幾乎所有程式語言都能適配。除非能非常確定5-10年內不會有多語言的需求,否則我還是非常建議你選擇一個跨語言的序列化協定
- 效能,序列化的效能包含了兩層意思,序列化的速度(cpu消耗)與序列化後的體積,設想一個場景,一個服務被非常多的應用訂閱,如果此時該服務釋出,則會觸發非常龐大的推播事件,此時註冊中心的cpu和網路則有可能被打滿,導致服務不可用
至於程式語言的選擇,我覺得應該更加偏向團隊對語言的掌握,以能hold住為最主要,這點沒什麼好說的,一般也只會在 Java / Go 中去選,很少見用其他語言實現的註冊中心。
對於註冊、訂閱介面,無論是基於TCP的自定義私有協定,還是用HTTP協定,甚至基於HTTP2的gRPC我覺得都可以。
但變更推播這個技術點的實現,有多種實現方式:
- 定時輪詢,每隔一段時間向註冊中心請求查詢訂閱的服務提供列表
- 長輪詢,向註冊中心查詢訂閱的服務提供列表,如果列表較上次沒有變化,則伺服器端hold住請求,等待有變化或者超時(較長時間)才返回
- UDP推播,服務列表有變化時通過UDP將事件通知給使用者端,但UDP推播不一定可靠,可能會丟失、亂序,故要配合定時輪詢(較長時間間隔)來作為一個兜底
- TCP長連線推播,使用者端與註冊中心建立一個TCP長連線,有變更時推播給使用者端
從實現的難易、實時性、資源消耗三個方面來比較這四種實現方式:
| 實現難易 | 實時性 | 資源消耗 | 備註 | |
|---|---|---|---|---|
| 定時輪詢 | 簡單 | 低 | 高 | 實時性越高,資源消耗越多 |
| 長輪詢 | 中等 | 高 | 中等 | 伺服器端hold住很多請求 |
| UDP推播 | 中等 | 高 | 低 | 推播可能丟失,需要配合定時輪詢(間隔較長) |
| TCP長連線推播 | 中等 | 高 | 中等 | 伺服器端需要保持很多長連線 |
似乎我們不好抉擇到底使用哪種方式來做推播,但以我自己的經驗來看,定時輪詢應該首先被排除,因為即便是一個初具規模的公司,定時輪詢的消耗也是巨大的,更何況這種消耗隨著實時性以及服務的規模日漸龐大,最後變得不可維護。
剩下三種方案都可以選擇,我們可以繼續結合服務節點的健康檢查來綜合判斷。
服務啟動時註冊到註冊中心,當服務停止時,從註冊中心摘除,通常摘除會藉助劫持kill訊號實現,如果是Java則有封裝好的ShutdownHook,當程序被 kill 時,觸發劫持邏輯,從註冊中心摘除,實現優雅退出。
但事情不總是如預期,如果有人執行了kill -9強制殺死程序,或者機器出現硬體故障,會導致提供者還在註冊中心,但已無法提供服務。
此時需要一種健康檢查機制來確保服務宕機時,消費者能正常感知,從而切走流量,保證線上服務的穩定性。
關於健康檢查機制,在之前的文章《服務探活的五種方式》中有專門的總結,這裡也列舉一下,以便做出正確的選擇:
| 優點 | 缺點 | |
|---|---|---|
| 消費者被動探活 | 不依賴註冊中心 | 需在服務呼叫處實現邏輯;用真實流量探測,可能會有滯後性 |
| 消費者主動探活 | 不依賴註冊中心 | 需在服務呼叫處實現邏輯 |
| 提供者上報心跳 | 對呼叫無入侵 | 需消費者服務發現模組實現邏輯,伺服器端處理心跳消耗資源大 |
| 註冊中心主動探測 | 對使用者端無要求 | 資源消耗大,實時性不高 |
| 提供者與註冊中心對談保持 | 實時性好,資源消耗少 | 與註冊中心需保持TCP長連線 |
我們暫時無法控制呼叫動作,故而前2項依賴消費者的方案排除,提供者上報心跳如果規模較小還好,上點規模也會不堪重任,這點在Nacos中就體現了,Nacos 1.x版本使用提供者上報心跳的方式保持服務健康狀態,由於每次上報健康狀態都需要寫入資料(最後健康檢查時間),故對資源的消耗是非常大的,所以Nacos 2.0版本後就改為了長連線對談保持健康狀態。
所以健康檢查我個人比較傾向最後兩種方案:註冊中心主動探測與提供者與註冊中心對談保持的方式。
結合上述變更推播,我們發現如果實現了長連線,好處將很多,很多情況下,一個服務既是消費者,又是提供者,此時一條TCP長連線可以解決推播和健康檢查,甚至在註冊登出介面的實現,我們也可以複用這條連線,可謂是一石三鳥。
長連線技術選型
長連線的技術選型,在《Nacos架構與原理》這本電子書中有有詳細的介紹,我覺得這部分堪稱技術選型的典範,我們參考下,本節內容大量參考《Nacos架構與原理》,如有雷同,那便是真是雷同。
首先是長連線的核心訴求:
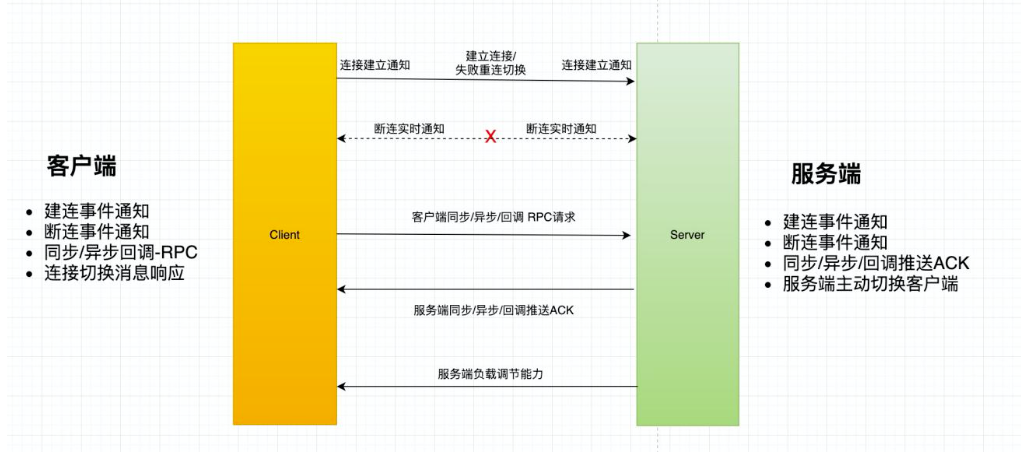
圖來自《Nacos架構與原理》
- 低成本快速感知:使用者端需要在伺服器端不可用時儘快地切換到新的服務節點,降低不可用時間
- 使用者端正常重啟:使用者端主動關閉連線,伺服器端實時感知
- 伺服器端正常重啟 : 伺服器端主動關閉連線,使用者端實時感知
- 防抖:網路短暫不可用,使用者端需要能接受短暫網路抖動,需要一定重試機制,防止叢集抖動,超過閾值後需要自動切換 server,但要防止請求風暴
- 斷網:斷網場景下,以合理的頻率進行重試,斷網結束時可以快速重連恢復
- 低成本多語言實現:在使用者端層面要儘可能多的支援多語言,降低多 語言實現成本
- 開源社群:檔案,開源社群活躍度,使用使用者數等,面向未來是否有足夠的支援度
據此,我們可選的輪子有:
| gRPC | Rsocket | Netty | Mina | |
|---|---|---|---|---|
| 使用者端感知斷連 | 基於 stream 流 error complete 事件可實現 | 支援 | 支援 | 支援 |
| 伺服器端感知斷連 | 支援 | 支援 | 支援 | 支援 |
| 心跳保活 | 應用層自定義,ping-pong 訊息 | 自定義 kee palive frame | TCP+ 自定義 | 自定義 kee palive filter |
| 多語言支援 | 強 | 一般 | 只Java | 只Java |
我比較傾向gRPC,而且gRPC的社群活躍度要強於Rsocket。
資料儲存
註冊中心資料儲存方案,大致可分為2類:
- 利用第三方元件完成,如Mysql、Redis等,好處是有現成的水平擴容方案,穩定性強;壞處是架構變得複雜
- 利用註冊中心本身來儲存資料,好處是無需引入額外元件;壞處是需要解決穩定性問題
第一種方案我們不必多說,第二種方案中最關鍵的就是解決資料在註冊中心各節點之間的同步,因為在資料儲存在註冊中心本身節點上,如果是單機,機器故障或者掛掉,資料存在丟失風險,所以必須得有副本。
資料不能丟失,這點必須要保證,否則穩定性就無從談起了。保證資料不丟失怎麼理解?在使用者端向註冊中心發起註冊請求後,收到正常的響應,這就意味著資料儲存了起來,除非所有註冊中心節點故障,否則資料就一定要存在。
如下圖,比如提供者往一個節點註冊資料後,正常響應,但是資料同步是非同步的,在同步完成前,nodeA節點就掛掉,則這條註冊資料就丟失了。
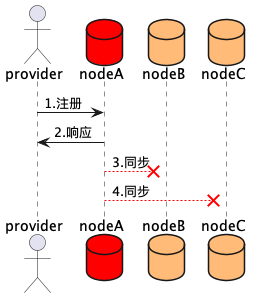
所以,我們要極力避免這種情況。
而一致性演演算法(如raft)就解決了這個問題,一致性演演算法能保證大部分節點是正常的情況下,能對外提供一致的資料服務,但犧牲了效能和可用性,raft演演算法在選主時便不能對外提供服務。
有沒有退而求其次的演演算法呢?還真有,像Nacos、Eureka提供的AP模型,他們的核心點在於使用者端可以recover資料,也就是註冊中心追求最終一致性,如果某些資料丟失,服務提供方是可以重新將資料註冊上來。
比如我們將提供方與註冊中心之間設計為長連線,提供方註冊服務後,連線的節點還沒來得及將資料同步到其他節點就掛了,此時提供方的連線也會斷開,當連線重新建立時,服務提供方可以重新註冊,恢復註冊中心的資料。
對於註冊中心選用AP、還是CP模型,業界早有爭論,但也基本達成了共識,AP要優於CP,因為資料不一致總比不可用要好吧?你說是不是。
高可用
其實高可用的設計散落在各個細節點,如上文提到的資料儲存,其基本要求就是高可用。除此之外,我們的設計也都必須是面向失敗的設計。
假設我們的伺服器會全部掛掉,怎樣才能保持服務間的呼叫不受影響?
通常註冊中心不侵入服務呼叫,而是在記憶體(或磁碟)中快取一份服務列表,當註冊中心完全掛了,大不了這份快取不再更新,但也不影響現有的服務呼叫,但新應用啟動就會受到影響。
總結
本文內容略多,用一幅圖來總結:
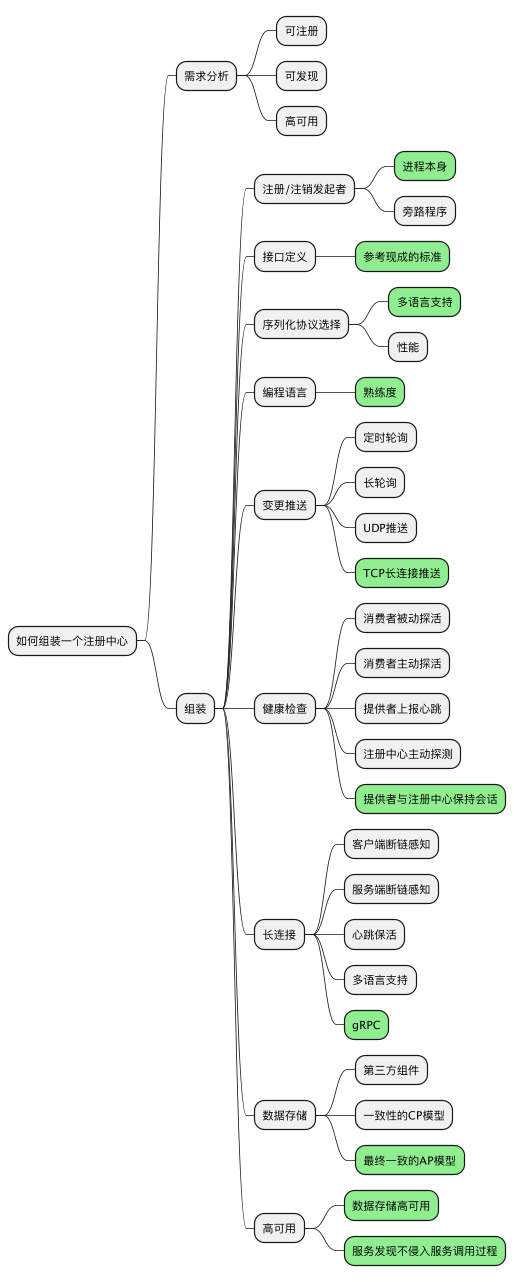
組裝一個線上可用的註冊中心最小集,從需求分析出發,每一步都有許多選擇,本文通過一些核心的技術選型來描繪出一個大致藍圖,剩下的工作就是用程式碼將這些組裝起來。
其中有些細節,我在之前的文章中有提及,這裡也一併推薦,感謝大家的閱讀,如果稍有收穫,麻煩點個贊和在看,你的支援是我創作的最大動力~
- 《服務探活的五種方式》
- 《我在組內的Nacos分享》
- 《Nacos註冊中心之概要設計》
- 《當我們談註冊中心時談什麼?》
- 《zookeeper到nacos的遷移實踐》
- 《nacos的一致性協定distro介紹》
搜尋關注微信公眾號"捉蟲大師",後端技術分享,架構設計、效能優化、原始碼閱讀、問題排查、踩坑實踐。