分析 java.util.LinkedHashMap
介紹
該實現與HashMap不同的是它維護一個雙向連結串列,可以使HashMap有序。與HashMap一樣,該類不安全。
結構
和HashMap的結構非常相似,只不過LinkedHashMap是一個雙向連結串列
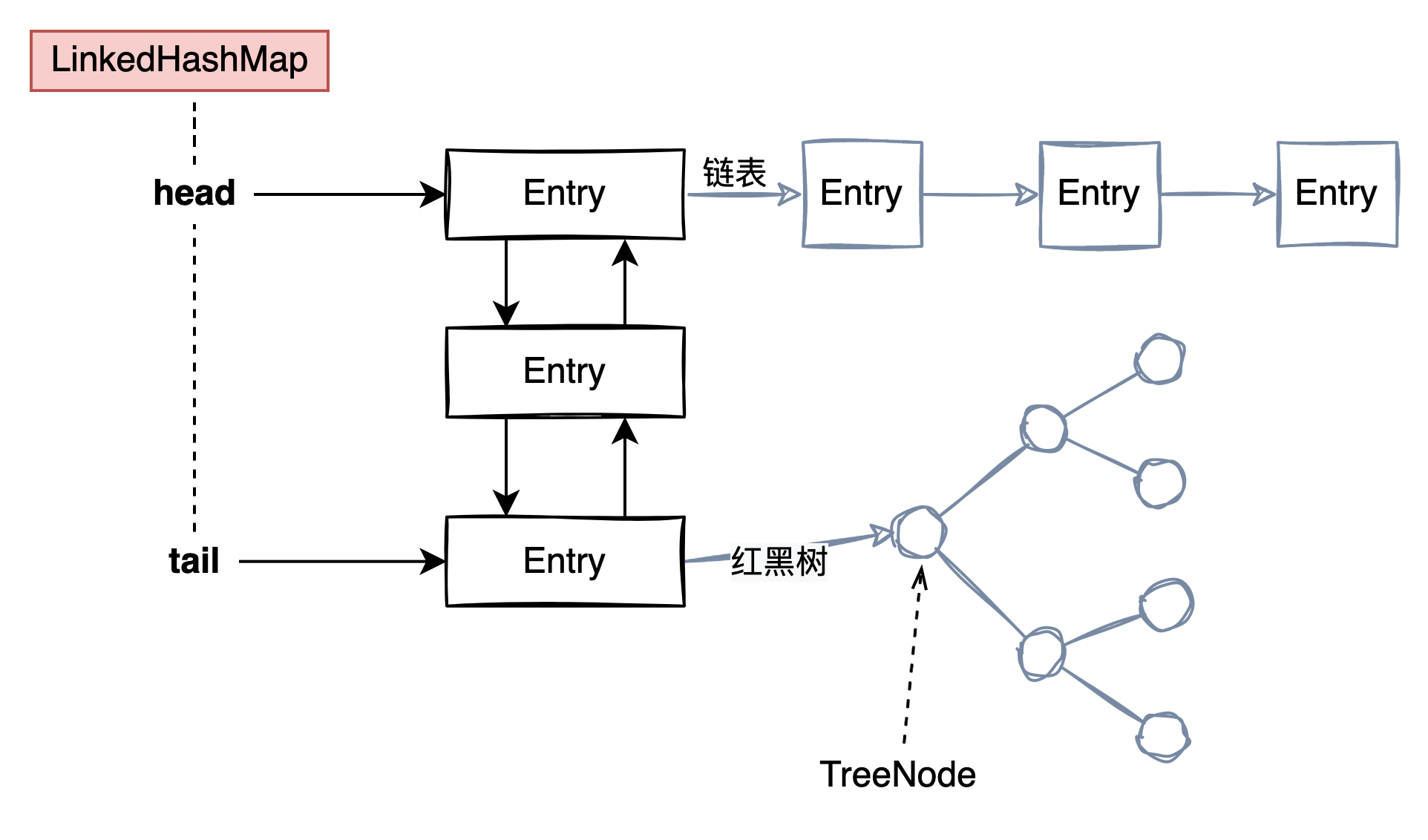
LinkedHashMap 分為兩種節點 Entry和TreeNode節點
Entry節點結構:
class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
before 和 after 是雙向連結串列中的前繼和後繼節點
TreeNode節點和HashMap中的一樣
從這裡能看出LinkedHashMap是一個雙向連結串列
LinkedHashMap 有如下屬性:
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
final boolean accessOrder;
head 和 tail很好理解就是雙向連結串列的頭和尾
HashMap中沒有accessOrder這個欄位,這也是與HashMap最不同的地方,該類有兩種取值分別代表不同的意思 :
- true,按照存取順序排序
- false,按照插入順序排序
HashMap預留的一些方法
HashMap 預留了一些方法提供給 LinkedHashMap 使用
// LinkedHashMap重寫了以下四個方法來保證雙向佇列能夠正常工作
// 建立一個Node節點
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next){...}
// 建立樹節點
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {...}
// 樹節點和普通節點相互轉換
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {...}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {...}
// HashMap未實現,留給LinkedHashMap實現
// 後置處理
// 存取節點後如何處理
void afterNodeAccess(Node<K,V> p) { }
// 插入節點後如何處理
void afterNodeInsertion(boolean evict) { }
// 移除節點後如何處理
void afterNodeRemoval(Node<K,V> p) { }
afterNodeAccess 、afterNodeInsertion、afterNodeRemoval 這三個方法保證了LinkedHashMap有序,分別會在get 、put、remove 後呼叫
put和remove 都對順序沒有影響,因為在操作的時候已經調整好了(put放在)。但是get是對順序有影響的(被存取到了),所以需要重寫該方法:
public V get(Object key) {
Node<K,V> e;
// 獲取節點
if ((e = getNode(hash(key), key)) == null)
return null;
// 改變順序
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
通過afterNodeAccess來改變該節點(P)的順序,該方法分為一下幾步:
- 拆除需要移動的節點P
- 處理前置節點,前置節點有兩種情況
- 前置節點為空,表示P為頭節點
- 前置節點不為空,表示P為中間節點
- 處理後置節點
- 後置節點為空,表示P為尾節點
- 後置節點不為空,表示P為中間節點
- 將該節點移動到
tail處
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeInsertion 則在putVal中呼叫
基本邏輯是如果引數為true則嘗試刪除頭節點,但是還需要滿足頭節點是最'老'的,具體的與removeEldestEntry配合使用,可以繼承LinkedHashMap並客製化, LinkedHashMap是恆為false的。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
如果所有條件都滿足則刪除頭節點
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
afterNodeRemoval則在removeNode成功刪除節點之後呼叫:
用來保證在雙向連結串列中刪除一個節點仍然能夠使結構不被破壞
為被刪除節點的頭和尾節點建立聯絡:
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
應用
實現LRU
LRU是一種快取置換機制,LRU (Least Recently Used)將最近最少使用的內容替換掉。實現非常簡單,每次存取某個元素,就將這個元素浮動到棧頂。這樣最靠近棧頂的頁面就是最近經常存取的,而被壓在棧底的就是最近最少使用的,只需要刪除棧底的元素。
LinkedHashMap非常方便實現LRU,LinkedHashMap在put操作時同時會判斷是否需要刪除最'老'的元素。只需要重寫removeEldestEntry方法,使得超過容量就刪除最'老'的元素。
下面是具體實現:
public class LRU<K, V> extends LinkedHashMap<K, V> {
/**
* 最大容量
* <p>
* Note: 用位運算就不需要將十進位制轉換為二進位制,直接就為二進位制。
*/
private final int MAX_CAPACITY = 1 << 30;
/**
* 快取的容量
*/
private int capacity;
public LRU(int capacity) {
this(true, capacity);
}
public LRU(boolean accessOrder, int capacity) {
this(1 << 4, 0.75f, accessOrder, capacity);
}
public LRU(int initialCapacity, float loadFactor, boolean accessOrder, int capacity) {
super(initialCapacity, loadFactor, accessOrder);
this.capacity = capacity;
}
}
測試:
LRU<Integer, Integer> lru = new LRU<Integer, Integer>(10);
for (int i = 0; i < 10; i++) {
lru.put(i, i * i);
System.out.println("put: (" + i + "," + i * i + ")");
int randomKey = (int) (Math.random() * i);
System.out.println("get "+randomKey+": " + lru.get(randomKey));
System.out.println("head->"+lru+"<-tail");
}
結果:
put: (0,0)
get 0: 0
head->{0=0}<-tail
---------------
put: (1,1)
get 0: 0
head->{1=1, 0=0}<-tail
---------------
put: (2,4)
get 1: 1
head->{0=0, 2=4, 1=1}<-tail
---------------