怎樣解決mysql深分頁問題

推薦學習:
日常需求開發過程中,相信大家對於limit一定不會陌生,但是使用limit時,當偏移量(offset)非常大時,會發現查詢效率越來越慢。一開始limit 2000時,可能200ms,就能查詢出需要的到資料,但是當limit 4000 offset 100000時,會發現它的查詢效率已經需要1S左右,那要是更大的時候呢,只會越來越慢。
概括
本文將會討論當mysql表巨量資料量的情況,如何優化深分頁問題,並附上最近的優化慢sql問題的案例虛擬碼。
1、limit深分頁問題描述
先看看錶結構(隨便舉了個例子,表結構不全,無用欄位就不進行展示了)
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主鍵', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上報數量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上報時間', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '會議id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '開始時間', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '應答時間', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '結束時間', `duration` int NOT NULL DEFAULT '0' COMMENT '持續時間', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通話記錄詳情表';
假設我們要查詢的深分頁SQL長這樣
select * from p2p_detail_record ppdr where ppdr .start_time_stamp >1656666798000 limit 0,2000

查詢效率是94ms,是不是很快?那如果我們limit 100000,2000呢,查詢效率是1.5S,已經非常慢,那如果更多呢?

2、sql慢原因分析
讓我們來看看這條sql的執行計劃

也走到了索引,那為什麼還是慢呢?我們先來回顧一下mysql 的相關知識點。
聚簇索引和非聚簇索引
聚簇索引: 葉子節點儲存的是整行的資料。
非聚簇索引: 葉子節點儲存的是整行的資料對應的主鍵值。
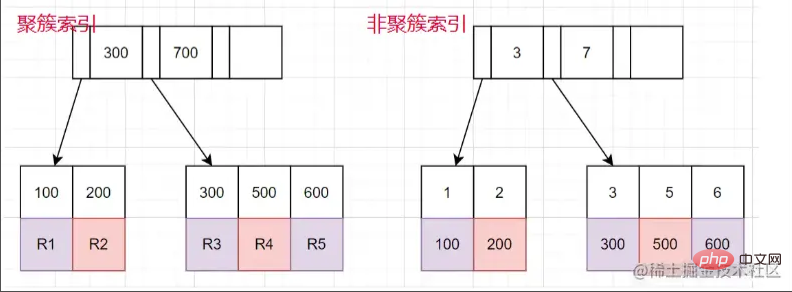
使用非聚簇索引查詢的流程
- 通過非聚簇索引樹,找到對應的葉子節點,獲取到主鍵的值。
- 再通過取到主鍵的值,回到聚簇索引樹,找到對應的整行資料。(整個過程稱為回表)
回到這條sql為什麼慢的問題上,原因如下
1、limit語句會先掃描offset+n行,然後再丟棄掉前offset行,返回後n行資料。也就是說limit 100000,10,就會掃描100010行,而limit 0,10,只掃描10行。這裡需要回表100010次,大量的時間都在回表這個上面。
方案核心思路: 能不能事先知道要從哪個主鍵ID開始,減少回表的次數
常見解決方案
通過子查詢優化
select * from p2p_detail_record ppdr where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1) limit 2000
相同的查詢結果,也是10W條開始的第2000條,查詢效率為200ms,是不是快了不少。
標籤記錄法
標籤記錄法: 其實標記一下上次查詢到哪一條了,下次再來查的時候,從該條開始往下掃描。類似書籤的作用
select * from p2p_detail_record ppdr where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4' order by id limit 2000 備註:bb9d67ee6eac4cab9909bad7c98f54d4是上次查詢結果的最後一條ID
使用標籤記錄法,效能都會不錯的,因為命中了id索引。但是這種方式有幾個缺點。
- 1、只能連續頁查詢,不能跨頁查詢。
- 2、需要一種類似連續自增的欄位(可以使用orber by id的方式)。
方案對比
- 使用通過子查詢優化的方式
優點: 可跨頁查詢,想查哪一頁的資料就查哪一頁的資料。
缺點: 效率不如標籤記錄法。原因: 比如需要查10W條資料後,第1000條,也需要先查詢出非聚簇索引對應的10W1000條資料,在取第10W開始的ID,進行查詢。
- 使用 標籤記錄法 的方式
優點: 查詢效率很穩定,非常快。
缺點:
- 不跨頁查詢,
- 需要一種類似連續自增的欄位
關於第二點的說明: 該點一般都好解決,可使用任意不重複的欄位進行排序即可。若使用可能重複的欄位進行排序的欄位,由於mysql對於相同值的欄位排序是無序,導致如果正好在分頁時,上下頁中可能存在相同的資料。
實戰案例
需求: 需要查詢查詢某一時間段的資料量,假設有幾十萬的資料量需要查詢出來,進行某些操作。
需求分析 1、分批查詢(分頁查詢),設計深分頁問題,導致效率較慢。
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主鍵', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上報數量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上報時間', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '會議id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '開始時間', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '應答時間', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '結束時間', `duration` int NOT NULL DEFAULT '0' COMMENT '持續時間', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通話記錄詳情表';
虛擬碼實現:
//最小ID
String lastId = null;
//一頁的條數
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //標籤記錄法,記錄上次查詢過的Id
lastId = list.get(list.size()-1).getId(); //獲取上一次查詢資料最後的ID,用於記錄
//對資料的操作邏輯
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>這裡有個小優化點: 可能有的人會先對所有資料排序一遍,拿到最小ID,但是這樣對所有資料排序,然後去min(id),耗時也蠻長的,其實第一次查詢,可不帶lastId進行查詢,查詢結果也是一樣。速度更快。
總結
1、當業務需要從表中查出巨量資料量時,而又專案架構沒上ES時,可考慮使用標籤記錄法的方式,對查詢效率進行優化。
2、從需求上也應該儘可能避免,在巨量資料量的情況下,分頁查詢最後一頁的功能。或者限制成只能一頁一頁往後劃的場景。
推薦學習:
以上就是怎樣解決mysql深分頁問題的詳細內容,更多請關注TW511.COM其它相關文章!
