伺服器記憶體故障預測居然可以這樣做!
作者:vivo 網際網路伺服器團隊- Hao Chan
隨著網際網路業務的快速發展,基礎設施的可用性也越來越受到業界的關注。記憶體發生故障的故障率高、頻次多、影響大,這些對於上層業務而言都是不能接受的。
本文主要介紹EDAC(Error Detection And Correction)框架在記憶體預測方面的應用。首先介紹了EDAC應用的背景,接著是EDAC的原理介紹,然後通過EDAC安裝——設定——測試過程詳細地介紹了EDAC在vivo伺服器上的應用,最後提出了記憶體預測使用EDAC的方案總結以及伺服器RAS(Reliability, Availability and Serviceability)應用減小硬體故障對系統的影響的展望。
一、背景介紹
隨著網際網路業務的快速發展,基礎設施的可用性也越來越受到業界的關注。然而硬體故障一直以來都是一種普遍存在的現象,由於硬體故障而造成的損失往往是巨大的。在伺服器各個部件中,除硬碟故障以外,記憶體故障是第二大常見的硬體故障型別。並且伺服器記憶體的數量眾多,vivo的記憶體數量達到40w+條,記憶體故障造成的最嚴重的後果是會直接導致系統崩潰,伺服器宕機,這些對於上層業務而言都是不能接受的。
記憶體故障可分為UCE(Uncorrectable Error)和CE(Correctable Error)。當硬體偵測到一個錯誤,它會通過兩種方式報告給CPU的。其中一種方式是中斷,這種情況如果是UCE也就是不可糾正錯誤,則可能會導致伺服器立馬宕機。如果是CE,即可糾正錯誤,硬體會利用一部分資源對該錯誤進行修復,而當記憶體CE累計過多,無法進行自我修復時,則會產生UCE,造成系統宕機重啟。因此,我們需要儘早地發現CE過多的記憶體條,及時進行更換,避免造成重大的損失。
以往記憶體故障大多是通過MCE(Machine Check Exception)log 和BMC記錄的SEL (System Error Log)紀錄檔結合去發現定位故障的,而這些最大的問題是不能夠提前發現記憶體問題,往往是伺服器宕機重啟後才被動發現的。除此之外還存在以下幾個方面的問題:
MCE紀錄檔很難直接定位到故障記憶體槽位。
沒有直觀的CE/UCE錯誤計數。
無法根據記憶體條上CE/UCE的數量判斷記憶體的健康狀況。
針對以上問題,我們需要尋找別的解決方案。這時EDAC便出現在我們的視野,它能夠完美地解決上面所說的所有問題,並且能夠實現記憶體CE故障的主動發現,提前發現記憶體問題。
本文將主要介紹EDAC的原理以及如何通過它實現的故障預測。
二、EDAC 原理介紹
EDAC(Error Detection And Correction)是Linux系統的錯誤檢測和糾正的框架,它的目的是在linux系統執行過程中,當錯誤發生時能夠發現並且報告出硬體錯誤。EDAC由一個核心(edac_core.ko)和多個記憶體控制器驅動模組組成,它的子系統有edac_mc、edac_device、PCI bus scanning,分別是負責收集記憶體控制器,其他控制器(比如L3 Cache控制器)以及PCI裝置所報告的錯誤。
這裡主要講述EDAC子系統edac_mc是如何收集記憶體控制器的錯誤。記憶體CE以及UCE是edac_mc class獲取的主要錯誤型別,它主要涉及了以下幾個函數:
- 【edac_mc_alloc()】:使用結構體mem_ctl_info來描述記憶體控制器,只有EDAC的核心才能接觸到它,通過edac_mc_alloc()這個函數去分配填充結構體的內容。
- 【edac_device_handle_ce()】:標記CE錯誤。
- 【edac_device_handle_ue()】:標誌UCE錯誤。
- 【edac_mc_handle_error()】:向用戶空間報告記憶體事件,它的引數包括故障點的層次結構以及故障型別,累計的相關UCE/CE錯誤計數統計。
- 【edac_raw_mc_handle_error()】:向用戶空間報告記憶體事件,但是不做任何事情來發現它的位置,只有當硬體錯誤來自BIOS時,才會被edac_mc_handle_error()直接呼叫。
那麼EDAC是如何控制和報告裝置故障的呢?它又是如何將故障定位以及記錄到對應的記憶體條上的呢?
Linux 是通過sysfs檔案系統來展示核心裝置的層次關係,EDAC則通過它來控制和報告裝置故障。EDAC是通過抽象出來的記憶體控制器模型,將故障定位到對應的記憶體條上,這主要也是與記憶體在系統中的排列結構相關。CPU對應的每個MC(memory controller)裝置控制著一組DIMM記憶體模組,這些模組通以片選行(Chip-Select Row,csrowX)和通道(Channel,chX)的方式排布,在系統中可以有多個csrow和多個通道。
通過下列路徑可以檢視相關檔案:
# ls /sys/devices/system/edac/mc/mc0/csrow0/
ce_count ch0_ce_count ch0_dimm_label ch1_ce_count ch1_dimm_label dev_type edac_mode mem_type power size_mb subsystem ue_count uevent
部分檔案的用途如下表所示:
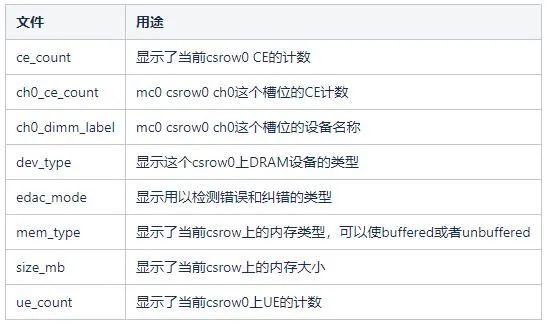
EDAC如果發現硬體裝置控制器報告的是UE事件,並且控制器要求UE即停機,則會重啟系統。控制器檢查到CE事件後,可以看作對未來UCE事件的預測。我們可以通過一些遮蔽手段或者更換記憶體條減少UE事件以及系統宕機的可能性。
三、EDAC 的應用
EDAC在vivo 現網中的應用過程主要分為以下幾步:
(1)EDAC在Linux系統中的支援
EDAC在Linux 2.6.16以上的核心中以及系統發行版都已經得到了支援,但是核心中edac的驅動模組卻有很多,不同的系統版本支援的驅動模組卻不盡相同,可以通過以下方式檢視系統支援哪些驅動模組。
# ls /lib/modules/3.10.0-693.el7.x86_64/kernel/drivers/edac/
amd64_edac_mod.ko.xz edac_core.ko.xz i3000_edac.ko.xz i5000_edac.ko.xz i5400_edac.ko.xz i7core_edac.ko.xz ie31200_edac.ko.xz skx_edac.ko.xz
e752x_edac.ko.xz edac_mce_amd.ko.xz i3200_edac.ko.xz i5100_edac.ko.xz i7300_edac.ko.xz i82975x_edac.ko.xz sb_edac.ko.xz x38_edac.ko.xz
那麼這些驅動模組之間有什麼區別?我們又應該怎樣選擇呢?拿sb_edac與skx_edac進行說明,我們先來看一下它們描述。
# modinfo sb_edac
filename: /lib/modules/3.10.0-693.el7.x86_64/kernel/drivers/edac/sb_edac.ko.xz
description: MC Driver for Intel Sandy Bridge and Ivy Bridge memory controllers - Ver: 1.1.1
...
# modinfo skx_edac
filename: /lib/modules/3.10.0-693.el7.x86_64/kernel/drivers/edac/skx_edac.ko.xz
description: MC Driver for Intel Skylake server processors
...
通過檢視描述我們發現,原來驅動模組是和CPU的產品架構有關,安裝不匹配的模組會出現 edac-util: Error: No memory controller data found 這樣的報錯。經過我們測試發現,一般而言,如果CPU的產品架構支援的驅動模組存在的話,系統會預設安裝支援的驅動。
(2)設定記憶體槽位與物理槽位對應關係
通過sysfs檔案系統我們可以看到哪個CPU的哪個記憶體控制下的哪個通道的哪條記憶體的CE計數,但是它對應的系統下的哪一個記憶體呢,畢竟我們伺服器日常的運維,經常看到的是系統槽位名稱,那麼它們的關係是怎樣的呢?
經過檢視edac-util的原始碼結構發現,它提供了labels.db這個組態檔,去儲存伺服器記憶體的系統槽位與物理槽位對應關係。
# cat /etc/edac/labels.db
# EDAC Motherboard DIMM labels Database file.
#
# $Id: labels.db 102 2008-09-25 15:52:07Z grondo $
#
# Vendor-name and model-name are found from the program 'dmidecode'
# labels are found from the silk screen on the motherboard.
#
#Vendor: <vendor-name>
# Model: <model-name>
# <label>: <mc>.<row>.<channel>
編寫這個檔案的時候,我們需要知道記憶體是如何在伺服器上是怎麼插,並且知道它對應的是系統中的槽位名稱,不同伺服器型號系統槽位的名稱不同。一般能使記憶體效能發揮最大的插法,總結起來就是對稱插法,並且先插離CPU遠的通道,每個通道里面先插離CPU遠的槽位。
設定完成後,如何去檢查是否設定正確呢,主要分為兩步:
① 使用edac-ctl檢視SYSFS CONTETS條數是否正確
② 用dmidecode -t memory檢視記憶體的名稱是否一致
這裡我們還遇到一個rpm包的問題:對於廠商的主機板的model name前後有多個空格的情況,edac-ctl無法識別到主機板的model name,lables.db無法註冊成功。最後我們修改了edac-utils包的原始碼,重新進行了打包。
(3)測試與驗證
安裝設定完成後,就到了測試驗證環節了,要怎樣去驗證EDAC的正確性,保證CE錯誤記錄到了對應的記憶體條上呢?我們可以使用APEI Error inject做一些錯誤注入的測試。
APEI Error inject 它的原理是依賴APEI(ACPI Platform Error Interface),它的結構中有四張表:
- BERT(Boot Error Record Table):主要用來記錄在啟動過程中出現的錯誤
- **ERST(Error Record Serialization Table) **:用來永久儲存錯誤的抽象介面,儲存各種硬體或平臺的相關錯誤,錯誤型別包括 Corrected Error(CE),Uncorrected Recoverable Error(UCR),以及 Uncorrected Non-Recoverable Error,或者說Fatal Error。
- EINJ(Error Injection Table):主要作用是用來注入錯誤並觸發錯誤,是一個用來測試的表
- HEST(Hardware Error Source Table):定義了很多錯誤源和錯誤型別。定義這些硬體錯誤源的目的在於標準化軟硬體錯誤介面的實現。
這裡是通過debugfs向核心APEI結構中的EINJ表注入記憶體錯誤來進行測試,debugfs是一種用於核心偵錯的虛擬檔案系統,簡單來說就是可以通過debugfs對映核心資料到使用者空間,使使用者能夠修改一些資料進行偵錯。
方法步驟如下:
# 檢視是否存在EINJ表
# ls /sys/firmware/acpi/tables/EINJ
# grep <以下欄位> /boot/config-3.10.0-693.el7.x86_64
CONFIG_DEBUG_FS=y
CONFIG_ACPI_APEI=y
CONFIG_ACPI_APEI_EINJ=m
# 安裝einj
# modprobe einj
# 檢視記憶體地址範圍,這一步是因為/proc/iomem這個檔案記錄的是實體地址的分配情況,有些記憶體地址是系統預留存放以及其他裝置所佔用的,無法進行錯誤注入。
# cat /proc/iomem | grep "System RAM"
00001000-000997ff
00100000-69f79fff
6c867000-6c9e6fff
6f345000-6f7fffff
100000000-407fffffff
# 檢視記憶體頁大小
# getconf PAGESIZE
4096 即4KB
# 進入edac錯誤注入目錄
# cat /proc/mounts | grep debugfs
debugfs /sys/kernel/debug debugfs rw,relatime 0 0
# cd /sys/kernel/debug/apei/einj/
# 檢視支援注入的錯誤型別
# cat available_error_type
0x00000008 Memory Correctable
0x00000010 Memory Uncorrectable non-fatal
0x00000020 Memory Uncorrectable fatal
# 寫入要注入的錯誤的型別
echo 0x8 > error_type
# 寫入記憶體地址掩碼
echo 0xfffffffffffff000 > param2
# 寫入記憶體地址
echo 0x32dec000 > param1
# 寫入0x0,若為1,則會跳過觸發環節
echo 0x0 > notrigger
# 寫入任何整數觸發錯誤注入,這是錯誤注入的最後一步
echo 1 > error_inject
# 檢視紀錄檔
# tail /var/log/message
xxxxxx xxxxxxxx kernel: [2258720.203422] EDAC MC0: 1 CE memory read error on CPU_SrcID#0_MC#0_Chan#0_DIMM#1 (channel:0 slot:1 page:0x32dec offset:0x0 grain:32 syndrome:0x0 - err_code:0101:0090 socket:0 imc:0 rank:0 bg:0 ba:3 row:327 col:300)
# 使用edac-util -v檢視,可以看到對應的記憶體條上新增了CE計數
四、 總結與展望
-
EDAC可以明確的獲取到伺服器的每條記憶體上的CE計數,我們可以通過CE計數去設定閾值,分析CE計數曲線等,結合其他MCE log 、SEL等對記憶體進行健康狀況評估,進行記憶體預測。EDAC在vivo伺服器全量上線過程以來,累計提前發現450+ case的記憶體CE問題,伺服器的宕機數量明顯減少。對滿足報修標準伺服器業務進行遷移,並更換相應的記憶體條,避免因伺服器突然宕機導致業務的不穩定,甚至因此造成的損失。
-
EDAC是伺服器RAS(Reliability, Availability and Serviceability)在記憶體方面應用的一小部分。RAS是指通過一些技術手段,軟硬體結合去保證伺服器的這三個能力。RAS在記憶體方面的優化還有很多,例如MCA(Machine Check Architecture)recovery等等。未來我們也將引入RAS去緩解硬體故障對系統的影響。
參考資料:
- https://www.kernel.org/doc/html/latest/driver-api/edac.html
- https://www.kernel.org/doc/html/latest/admin-guide/ras.html
- https://www.kernel.org/doc/html/latest/firmware-guide/acpi/apei/einj.html
- https://github.com/grondo/edac-utils/
- https://uefi.org/specs/ACPI/6.4/18_ACPI_Platform_Error_Interfaces/ACPI_PLatform_Error_Interfaces.html