【萬字長文】使用 LSM-Tree 思想基於.Net 6.0 C# 實現 KV 資料庫(案例版)
文章有點長,耐心看完應該可以懂實際原理到底是啥子。
這是一個KV資料庫的C#實現,目前用.NET 6.0實現的,目前算是屬於雛形,骨架都已經完備,畢竟剛完工不到一星期。
當然,這個其實也算是NoSQL的雛形,有助於深入瞭解相關資料庫的內部原理概念,也有助於實際入門。
適合對資料庫原理以及實現感興趣的朋友們。
整體程式碼,大概1500行,核心程式碼大概500行。
為啥要實現一個資料庫
大概2018年的時候,就萌生了想自己研發一個資料庫的想法了,雖然,造輪子可能不如現有各種產品的強大,但是,能造者寥寥無幾,而且,造資料庫的書更是少的可憐,當然,不僅僅是造資料庫的書少,而是各種各樣高階的產品的創造級的書都少。
雖然,現在有各種各樣的開源,但是,像我這種底子薄的,就不能輕易的瞭解,這些框架的架構設計,以及相關的理念,純看程式碼,沒個長時間,也不容易瞭解其存在的含義。
恰逢其時,前一個月看到【痴者工良】大佬的一篇《【萬字長文】使用 LSM Tree 思想實現一個 KV 資料庫 》文章給我很大觸動,讓我停滯的心,又砰砰跳了起來,雖然大佬是用GO語言實現的 ,但是,對我來講,語言還是個問題麼,只要技術思想一致,我完全可以用C#實現啊,也算是對【痴者工良】大佬的致敬,我這邊緊隨其後。
當然,我自己對資料的研究也是耗時很久,畢竟,研究什麼都要先從原理開始研究,從谷歌三個論文《GFS,MapReduce,BigTable》開始,但是,論文,畢竟是論文,讀不懂啊,又看了網上各種大佬的文章,還是很矇蔽,實現的時候,也沒人交流,導致各種流產。
有時候,自己實現某個產品框架的時候,總是在想,為啥BUG都讓我處理一個遍哦,後來一想,你自己從新做個產品,也不能借鑑技術要點,那還不是從零開始,自然一一遇到BUG。
下圖就是,我在想做資料庫後,自己寫寫畫畫,但是,實際做的時候,邏輯表現總沒有那麼好,當然,這個是關係型資料庫,難度比較高,下面可以看看之前的手稿,都是有想法了就畫一下。

實現難度有點高,現在這個實現是KV資料庫,算是列式資料庫了,大名鼎鼎的HBase,底層資料庫引擎就是LSM-Tree的技術思想。
LSM-Tree 是啥子
LSM-Tree 英文全稱是 Log Structured Merge Tree (中文:紀錄檔結構合併樹),是一種分層,有序,面向磁碟的資料結構,其核心思想是充分了利用了,磁碟批次的順序寫要遠比隨機寫效能高的技術特點,來實現高寫入吞吐量的儲存系統的核心。
具體的說,原理就是針對硬碟,儘量追加資料,而不是隨機寫資料,追加速度要比隨機寫的速度快,這種結構適合寫多讀少的場景,所以,LSM-Tree被設計來提供比傳統的B+樹或者ISAM更好的寫操作吞吐量,通過消去隨機的本地更新操作來達到這個效能目標。
相關技術產品有Hbase、Cassandra、Leveldb、RocksDB、MongoDB、TiDB、Dynamodb、Cassandra 、Bookkeeper、SQLite 等
所以,LSM-Tree的核心就是追加資料,而不是修改資料。
LSM-Tree 架構分析
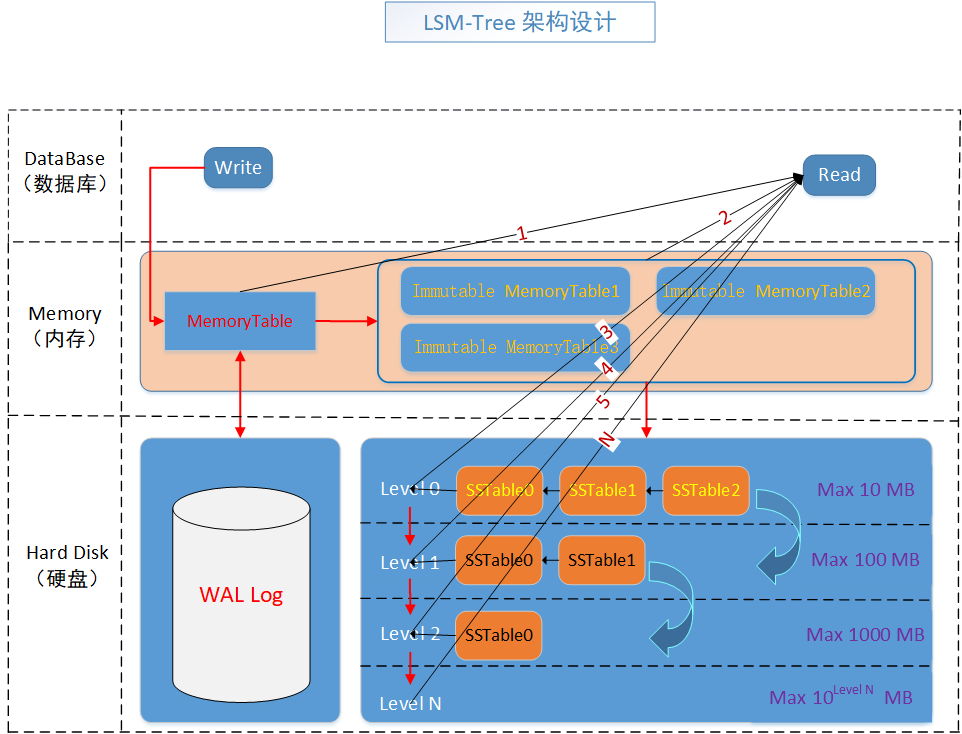
其實這個圖已經表達了整體的設計思想了,主體其實就圍繞著紅色的線與黑色的線,兩部分展開的,其中紅色是寫,黑色是讀,箭頭表示資料的方向,數位表示邏輯順序。
整體包含大致三個部分,資料庫操作部分(主要為讀和寫),記憶體部分(快取表和不變快取表)以及硬碟部分(WAL Log 和 SSTable),這三個部分。
先對關鍵詞解釋一下
MemoryTable
記憶體表,一種臨時快取性質的資料表,可以用 二叉排序樹實現,也可以用字典來實現,我這邊是用字典實現的。
WAL Log
WAL 英文 (Write Ahead LOG) 是一種預寫紀錄檔,用於在系統故障期間提供資料的永續性,這意味著當寫入請求到來時,資料首先新增到 WAL 檔案(有時稱為紀錄檔)並重新整理到更新記憶體資料結構之前的磁碟。
如果用過Mysql,應該就知道BinLog檔案,它們是一個道理,先寫入到WAL Log裡,記錄起來,然後,寫入到記憶體表,如果電腦突然宕機了,記憶體裡的東西肯定丟失了,那麼,下一次重啟,就從WAL Log 記錄表裡,從新恢復資料到當前的資料狀態。
Immutable MemoryTable
Immutable(不變的),相對於記憶體表來講,它是不能寫入新資料,是唯讀的。
SSTable
SSTable 英文 (Sorted Strings Table) ,有序字串表,就是有序的字串列表,使用它的好處是可以實現稀疏索引的效果,而且,合併檔案更為簡單方便,我要查某個Key,但是,它是基於 某個有序Key之間的,可以直接去檔案裡查,而不用都儲存到記憶體裡。
這裡我是用雜湊表實現的,我認為浪費一點記憶體是值得的,畢竟為了快,浪費點空間是值得的,所以,目前是全索引載入到記憶體,而資料儲存在SSTable裡,當然,如果是為了更好的設計,也可以自己去實現有序表來用二分查詢。
我這個方便實現了之後,記憶體會載入大量的索引,相對來講是快的,但是,記憶體會大一些,空間換時間的方案。
下面開始具體的流程分析
LSM-Tree Write 路線分析
看下圖,資料寫入分析
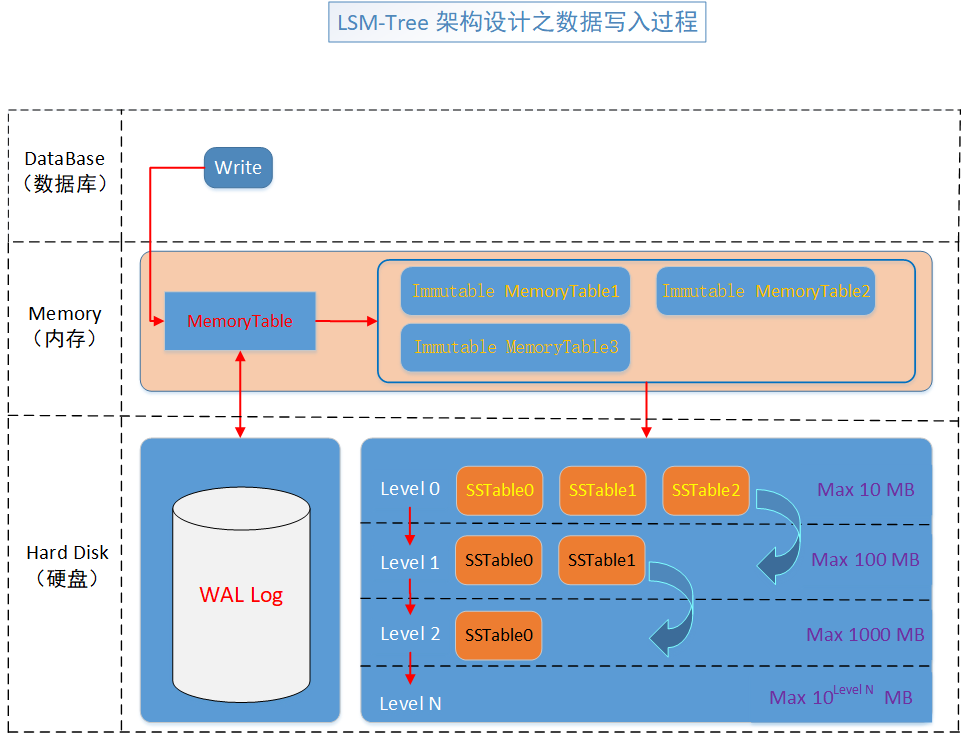
跟著紅色線走,關注我從此不迷路。
LSM-Tree Write 路線分析第一步

第一步,只有兩個部分需要注意的部分,分別是記憶體表和WAL.Log
寫入資料先儲存記憶體表,是為了快速的儲存到資料庫資料。
儲存到WAL.Log,是為了防止異常情況下資料丟失。
正常情況下,寫入到WAL.Log一份,然後,會寫入到記憶體一份。
當程式崩潰了,或者,電腦斷電異常了,重複服務後,就會先載入WAL.Log,按照從頭到尾的順序,恢復資料到記憶體表,直至結束,恢復到WAL.Log最後的狀態,也就是記憶體表資料最後的狀態。
注
這裡要注意的是,當後面的不變表(Immutable MemoryTable)寫入到SSTable的時候,會清空WAL.Log檔案,並同時把記憶體表的資料直接寫入到WAL.log表中。
LSM-Tree Write 路線分析第二步

第二步,比較簡單,就是在記憶體表count大於一定數的時候,就新增一個記憶體表的同時, 把它變為 Immutable MemoryTable (不變表),等待SSTable的落盤操作,這個時候,Immutable MemoryTable會有多個表存在。
LSM-Tree Write 路線分析第三步
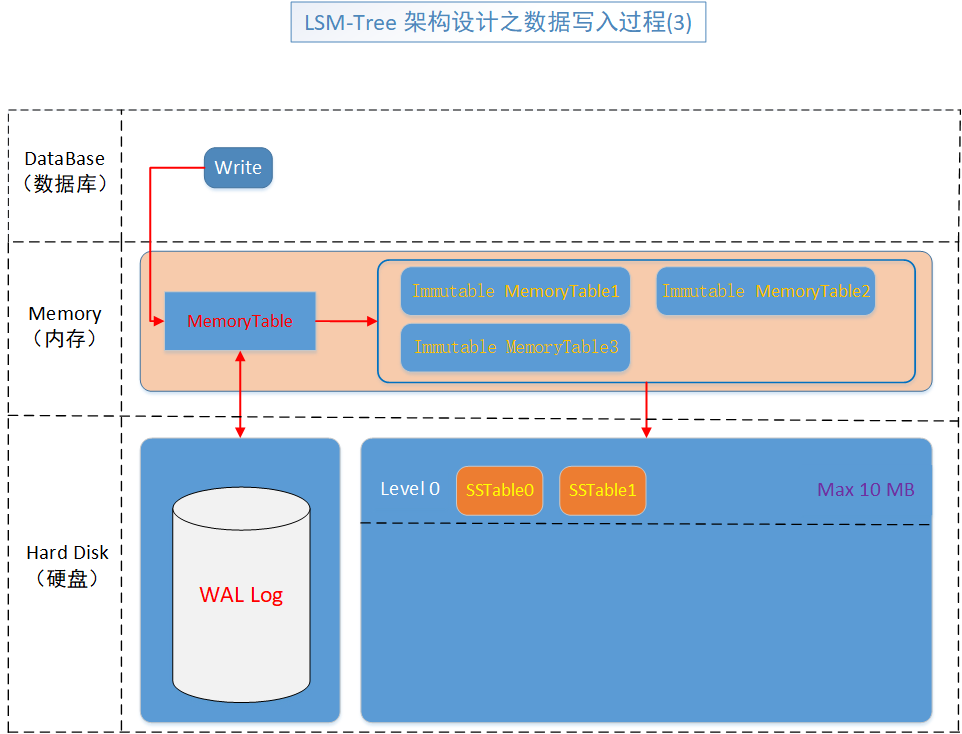
第三步,就是資料庫會定時檢查 Immutable MemoryTable (不變表)不變表是否存在,如果存在,就會直接落盤為SSTable表,不論當前記憶體裡有多少 Immutable MemoryTable (不變表)。
預設從記憶體落盤的第一級SSTable都是 Level 0,然後,內建了當前的時間,所以是兩級排序,先分級別,然後,分時間。
LSM-Tree Write 路線分析第四步
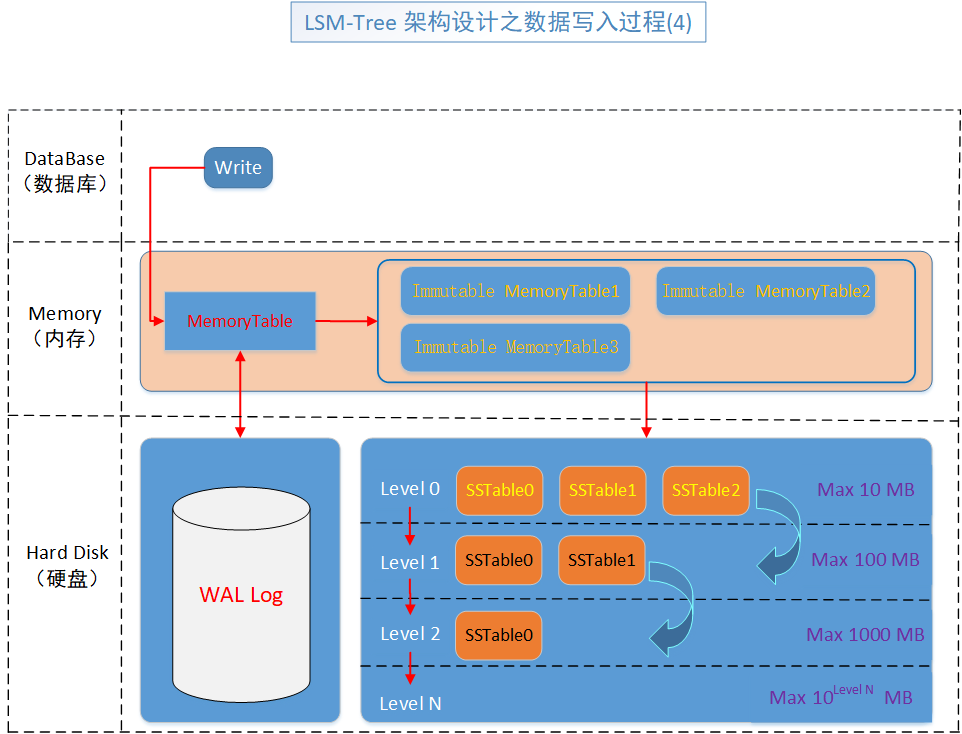
第四步,其實就是段合併或者級合併壓縮,就是判斷 level0 這一個級別的所有 SSTable檔案(SSTable0,SSTable1,SSTable2),判斷它們的總大小或者判斷它們的總個數來判斷,它們需不需要進行合併。
其中 Level 0 的大小如果是10M,那麼 ,Level 1的大小就是 100M,依此類推。
當Level0的所有SSTable檔案超過了10M,或者限定的大小,就會從按照WAL.Log的順序思路,重新合併為一個大檔案,先老資料再新資料這樣遍歷合併,如果已經刪除的,則直接剔除在外,只保留最新狀態。
如果 Level1的(全部SSTable)大小 超過100M,那麼,觸發Level1的收縮動作,執行過程跟Level0一樣的操作,只是級別不同。
這樣壓縮的好處是使資料儘可能讓檔案量儘可能的少,畢竟,檔案多,管理就不是很方便。
至此,寫入路線已經分析完畢
注
查詢的時候,要先新資料,後舊資料,而分段合併壓縮的時候,要先老資料墊底,新資料刷狀態,這個是實現的時候需要注意的點。
LSM-Tree Read 路線分析
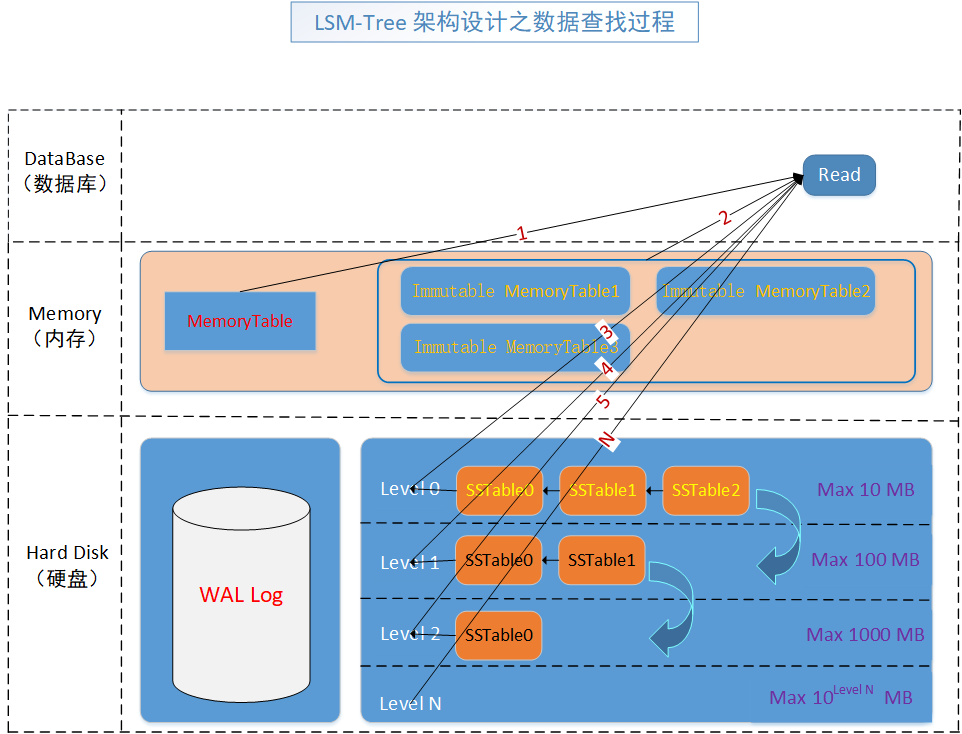
這就是資料的查詢過程,跟著黑線和數位標記,很容易就看到了其存取順序
- MemoryTable (記憶體表)
- Immutable MemoryTable (不變表)
- Level 0-N (SSTableN-SSTable1-SSTable0) (有序字串表)
基本上來說就這三部分,而級別表是從0級開始往下找的,而每級內部的SSTable是從新到舊開始找的,找到就返回,不論key是刪除還是正常的狀態。
LSM-Tree 架構分析與實現
核心思想:
其實就是一個時間有序的記錄表,會記錄每個操作,相當於是一個訊息佇列,記錄一系列的動作,然後,回放動作,就獲取到了最新的資料狀態,也類似CQRS中的Event Store(事件儲存),概念是相同的,那麼實現的時候,就明白是一個什麼本質。
Wal.log和SSTable,都是為了保證資料能落地持久化不丟失,而MemoryTable,偏向臨時快取的概念,當然,也有為了加速存取的作用。
所以,從這幾個點來看,就分為了以下幾個大的物件
- Database 資料庫( 起到對Wal.log,SSTable和MemoryTable 的管理職責)
- Wal.log(記錄臨時資料紀錄檔)
- MemoryTable(記錄資料到記憶體,同時為資料庫查詢功能提供介面服務)
- SSTable(管理SSTable檔案,並提供SSTable的查詢功能)
所以,針對這幾個物件來設計相關的類介面設計。
KeyValue (具體資料的結構)
設計的時候,要先設計實際資料的結構,我是這樣設計的
主要有三個主要的資訊,key, DataValue,Deleted ,其中DataValue是Object型別的,我這邊寫入到檔案裡的話,是直接寫入的。
/// <summary>
/// 資料資訊 kv
/// </summary>
public class KeyValue
{
public string Key { get; set; }
public byte[] DataValue { get; set; }
public bool Deleted { get; set; }
private object Value;
public KeyValue() { }
public KeyValue(string key, object value, bool Deleted = false)
{
Key = key;
Value = value;
DataValue = value.AsBytes();
this.Deleted = Deleted;
}
public KeyValue(string key, byte[] dataValue, bool deleted)
{
Key = key;
DataValue = dataValue;
Deleted = deleted;
}
/// <summary>
/// 是否存在有效資料,非刪除狀態
/// </summary>
/// <returns></returns>
public bool IsSuccess()
{
return !Deleted || DataValue != null;
}
/// <summary>
/// 值存不存在,無論刪除還是不刪除
/// </summary>
/// <returns></returns>
public bool IsExist()
{
if (DataValue != null && !Deleted || DataValue == null && Deleted)
{
return true;
}
return false;
}
public T Get<T>() where T : class
{
if (Value == null)
{
Value = DataValue.AsObject<T>();
}
return (T)Value;
}
public static KeyValue Null = new KeyValue() { DataValue = null };
}
IDataBase (資料庫介面)
主要對外互動用的主體類,資料庫類,增刪改查介面,都用 get,set,delete 表現。
/// <summary>
/// 資料庫介面
/// </summary>
public interface IDataBase : IDisposable
{
/// <summary>
/// 資料庫設定
/// </summary>
IDataBaseConfig DataBaseConfig { get; }
/// <summary>
/// 獲取資料
/// </summary>
KeyValue Get(string key);
/// <summary>
/// 儲存資料(或者更新資料)
/// </summary>
bool Set(KeyValue keyValue);
/// <summary>
/// 儲存資料(或者更新資料)
/// </summary>
bool Set(string key, object value);
/// <summary>
/// 獲取全部key
/// </summary>
List<string> GetKeys();
/// <summary>
/// 刪除指定資料,並返回存在的資料
/// </summary>
KeyValue DeleteAndGet(string key);
/// <summary>
/// 刪除資料
/// </summary>
void Delete(string key);
/// <summary>
/// 定時檢查
/// </summary>
void Check(object state);
/// <summary>
/// 清除資料庫所有資料
/// </summary>
void Clear();
}
IDataBase.Check (定期檢查)
這個是定期檢查Immutable MemoryTable(不變表)的定時操作,主要依賴IDataBaseConfig.CheckInterval 引數設定其觸發間隔。
它的職責是檢查記憶體表和檢查SSTable 是否觸發分段合併壓縮的操作。
public void Check(object state)
{
//Log.Info($"定時心跳檢查!");
if (IsProcess)
{
return;
}
if (ClearState)
{
return;
}
try
{
Stopwatch stopwatch = Stopwatch.StartNew();
IsProcess = true;
checkMemory();
TableManage.Check();
stopwatch.Stop();
GC.Collect();
Log.Info($"定時心跳處理耗時:{stopwatch.ElapsedMilliseconds}毫秒");
}
finally
{
IsProcess = false;
}
}
IDataBaseConfig (資料庫組態檔)
資料庫的組態檔,資料庫儲存在哪裡,以及生成SSTable時的閾值設定,還有檢測間隔時間設定。
/// <summary>
/// 資料庫相關設定
/// </summary>
public interface IDataBaseConfig
{
/// <summary>
/// 資料庫資料目錄
/// </summary>
public string DataDir { get; set; }
/// <summary>
/// 0 層的 所有 SsTable 檔案大小總和的最大值,單位 MB,超過此值,該層 SsTable 將會被壓縮到下一層
/// 每層資料大小是上層的N倍
/// </summary>
public int Level0Size { get; set; }
/// <summary>
/// 層與層之間的倍數
/// </summary>
public int LevelMultiple { get; set; }
/// <summary>
/// 每層數量閾值
/// </summary>
public int LevelCount { get; set; }
/// <summary>
/// 記憶體表的 kv 最大數量,超出這個閾值,記憶體表將會被儲存到 SsTable 中
/// </summary>
public int MemoryTableCount { get; set; }
/// <summary>
/// 壓縮記憶體、檔案的時間間隔,多久進行一次檢查工作
/// </summary>
public int CheckInterval { get; set; }
}
IMemoryTable (記憶體表)

這個表其實算是對記憶體資料的管理表了,主要是管理 MemoryTableValue 物件,這個物件是通過雜湊字典來實現的,當然,你也可以選擇其他結構,比如有序二元樹等。
/// <summary>
/// 記憶體表(排序樹,二元樹)
/// </summary>
public interface IMemoryTable : IDisposable
{
IDataBaseConfig DataBaseConfig { get; }
/// <summary>
/// 獲取總數
/// </summary>
int GetCount();
/// <summary>
/// 搜尋(從新到舊,從大到小)
/// </summary>
KeyValue Search(string key);
/// <summary>
/// 設定新值
/// </summary>
void Set(KeyValue keyValue);
/// <summary>
/// 刪除key
/// </summary>
void Delete(KeyValue keyValue);
/// <summary>
/// 獲取所有 key 資料列表
/// </summary>
/// <returns></returns>
IList<string> GetKeys();
/// <summary>
/// 獲取所有資料
/// </summary>
/// <returns></returns>
(List<KeyValue> keyValues, List<long> times) GetKeyValues(bool Immutable);
/// <summary>
/// 獲取不變表的數量
/// </summary>
/// <returns></returns>
int GetImmutableTableCount();
/// <summary>
/// 開始交換
/// </summary>
void Swap(List<long> times);
/// <summary>
/// 清空全部資料
/// </summary>
void Clear();
}
MemoryTableValue (物件的實現)
主要是通過 Immutable 這個屬性實現了對不可變記憶體表的標記,具體實現是通過判斷 IDataBaseConfig.MemoryTableCount (記憶體表的 kv 最大數量)來實現標記的。
public class MemoryTableValue : IDisposable
{
public long Time { get; set; } = IDHelper.MarkID();
/// <summary>
/// 是否是不可變
/// </summary>
public bool Immutable { get; set; } = false;
/// <summary>
/// 資料
/// </summary>
public Dictionary<string, KeyValue> Dic { get; set; } = new();
public void Dispose()
{
Dic.Clear();
}
public override string ToString()
{
return $"Time {Time} Immutable:{Immutable}";
}
}
什麼時機表狀態轉換為 Immutable MemoryTable(不變表)的
我這裡實現的是從Set的入口處實現的,如果數目大於IDataBaseConfig.MemoryTableCount (記憶體表的 kv 最大數量)就改變其狀態
public void Check()
{
if (CurrentMemoryTable.Dic.Count() >= DataBaseConfig.MemoryTableCount)
{
var value = new MemoryTableValue();
dics.Add(value.Time, value);
CurrentMemoryTable.Immutable = true;
}
}
IWalLog
wallog,就簡單許多,就直接把KeyValue 寫入到檔案即可,為了保證WalLog的持續寫,所以,物件內部保留了此檔案的控制程式碼。而SSTable,就沒有必要了,隨時讀。
/// <summary>
/// 紀錄檔
/// </summary>
public interface IWalLog : IDisposable
{
/// <summary>
/// 資料庫設定
/// </summary>
IDataBaseConfig DataBaseConfig { get; }
/// <summary>
/// 載入Wal紀錄檔到記憶體表
/// </summary>
/// <returns></returns>
IMemoryTable LoadToMemory();
/// <summary>
/// 寫紀錄檔
/// </summary>
void Write(KeyValue data);
/// <summary>
/// 寫紀錄檔
/// </summary>
void Write(List<KeyValue> data);
/// <summary>
/// 重置紀錄檔檔案
/// </summary>
void Reset();
}
ITableManage (SSTable表的管理)
為了更好的管理SSTable,需要有一個管理層,這個介面就是它的管理層,其中SSTable會有多層,每次用 Level+時間戳+db 作為檔名,用作外部識別。
/// <summary>
/// 表管理項
/// </summary>
public interface ITableManage : IDisposable
{
IDataBaseConfig DataBaseConfig { get; }
/// <summary>
/// 搜尋(從新到老,從大到小)
/// </summary>
KeyValue Search(string key);
/// <summary>
/// 獲取全部key
/// </summary>
List<string> GetKeys();
/// <summary>
/// 檢查資料庫檔案,如果檔案無效資料太多,就會觸發整合檔案
/// </summary>
void Check();
/// <summary>
/// 建立一個新Table
/// </summary>
void CreateNewTable(List<KeyValue> values, int Level = 0);
/// <summary>
/// 清理某個級別的資料
/// </summary>
/// <param name="Level"></param>
public void Remove(int Level);
/// <summary>
/// 清除資料
/// </summary>
public void Clear();
}
ISSTable(SSTable 檔案)
SSTable的內容管理,應該就是LSM-Tree的核心了,資料的合併,以及資料的查詢,寫入,載入,都是偏底層的操作,需要一丟丟的資料庫知識。
/// <summary>
/// 檔案資訊表 (儲存在IO中)
/// 後設資料 | 索引列表 | 資料區(資料修改只會新增,並修改索引列表資料)
/// </summary>
public interface ISSTable : IDisposable
{
/// <summary>
/// 資料地址
/// </summary>
public string TableFilePath();
/// <summary>
/// 重寫檔案
/// </summary>
public void Write(List<KeyValue> values, int Level = 0);
/// <summary>
/// 資料位置
/// </summary>
public Dictionary<string, DataPosition> DataPositions { get; }
/// <summary>
/// 獲取總數
/// </summary>
/// <returns></returns>
public int Count { get; }
/// <summary>
/// 後設資料
/// </summary>
public ITableMetaInfo FileTableMetaInfo { get; }
/// <summary>
/// 查詢資料
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
public KeyValue Search(string key);
/// <summary>
/// 有序的key列表
/// </summary>
/// <returns></returns>
public List<string> SortIndexs();
/// <summary>
/// 獲取位置
/// </summary>
DataPosition GetDataPosition(string key);
/// <summary>
/// 讀取某個位置的值
/// </summary>
public object ReadValue(DataPosition position);
/// <summary>
/// 載入所有資料
/// </summary>
/// <returns></returns>
public List<KeyValue> ReadAll(bool incloudDeleted = true);
/// <summary>
/// 獲取所有keys
/// </summary>
/// <returns></returns>
public List<string> GetKeys();
/// <summary>
/// 獲取表名
/// </summary>
/// <returns></returns>
public long FileTableName();
/// <summary>
/// 檔案的大小
/// </summary>
/// <returns></returns>
public long FileBytes { get; }
/// <summary>
/// 獲取級別
/// </summary>
public int GetLevel();
}
IDataPosition(資料稀疏索引算是)
方便資料查詢方便和方便從SSTable裡讀取到實際的資料內容。
/// <summary>
/// 資料的位置
/// </summary>
public interface IDataPosition
{
/// <summary>
/// 索引起始位置
/// </summary>
public long IndexStart { get; set; }
/// <summary>
/// 開始地址
/// </summary>
public long Start { get; set; }
/// <summary>
/// 資料長度
/// </summary>
public long Length { get; set; }
/// <summary>
/// key的長度
/// </summary>
public long KeyLength { get; set; }
/// <summary>
/// 是否已經刪除
/// </summary>
public bool Deleted { get; set; }
public byte[] GetBytes();
}
資料結構分析
內部表的結構就不用說了,很簡單,就是一個雜湊字典,而有兩個結構是要具體分析的,那就是 WALLog和SSTable檔案。
WALLog 結構分析
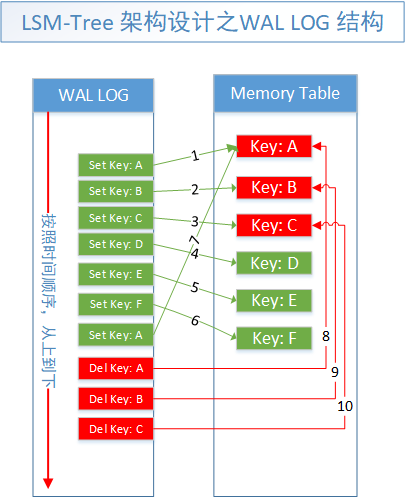
這個圖橫向不好畫,我畫成豎向了,WalLog裡面儲存的就是時間序的KeyValue資料,當它載入到Memory Table的時候,其實就是按照我所標的數位順序依次疊加到最後的狀態的。
同理,SSTable 資料分段合併壓縮的時候,其實是跟這個一個原理的。
SSTable 結構分析
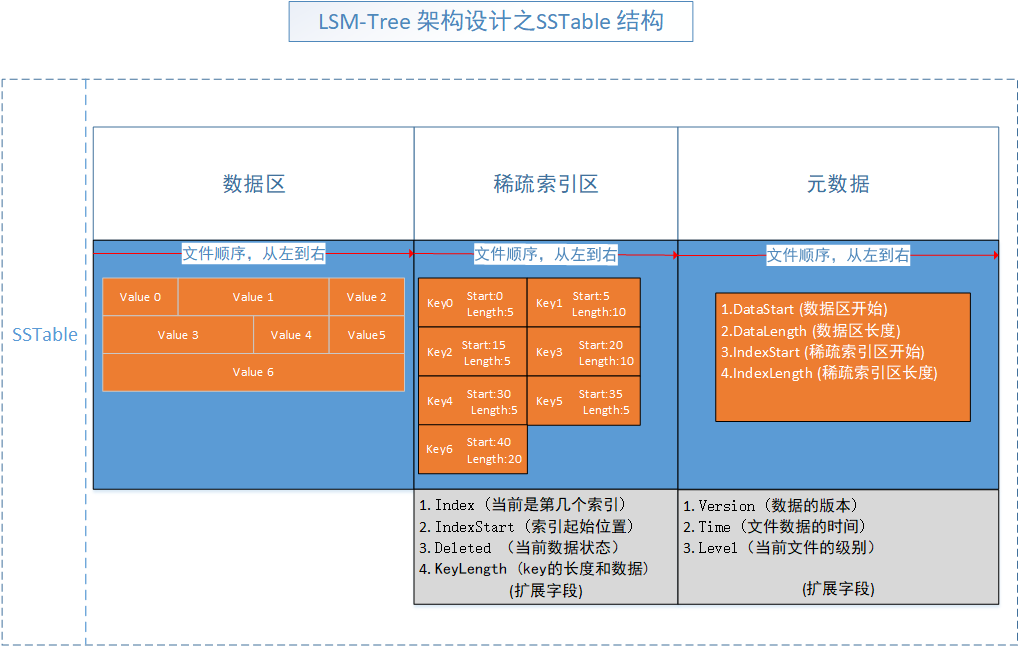
SSTable,它本身是一個檔案 名字大致如下:
0_16586442986880000.db
格式為 層級_時間戳.db 這樣的方式搞的命名規則,為此我還搞了一個生成時間序不重複 ID的簡單演演算法。
SSTable 資料區

資料區就很簡單,把KeyValue.DataValue直接ToJson 就可以了,然後,直接寫檔案。
SSTable 稀疏索引區

這個區是按照與資料區對應的key的順序寫入的,主要是把DataValue對應的開始地址和結束地址放入到這個資料區了,另外把key也寫入進去了。
好處是為了,當此SSTable載入索引(IDataPosition)到記憶體,省的把資料區的內容也載入進去,查詢就方便許多,這也是索引的作用。
後設資料區

這個按照協定來講,屬於協定頭,但是為啥放最後面呢,其實是為了計算方便,這也算是一個小妙招。
其中不僅包含了資料區的開始和結束,稀疏索引區的開始和結束,還包含了,此SSTable的版本和建立時間,以及當前SSTable所在的級別。
SSTable 分段合併壓縮
剛看這段功能邏輯的時候,腦子是懵的,使勁看了好久,分析了好久,還是把它寫出來了,剛開始不理解,後來理解了,寫著就容易許多了。
看下圖:
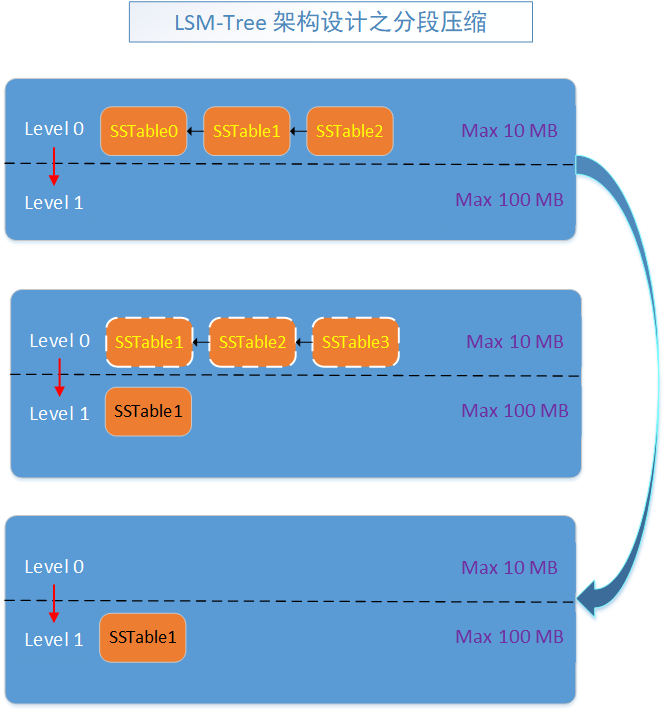
其實合併是有狀態的,這個就是中間態,我把他放到了圖中間,然後,用白色的虛框表示。
整體邏輯就是,先從記憶體中定時把不變表生成為0級的SSTable,然後,0級就會有許多檔案,如果這些檔案大小超過了閾值,就合併此級的檔案為一個大檔案,按照WalLog的合併原理,然後把資訊重新寫入到本地為1級SSTable即可。
以此類推。
下面一個動圖說明其合併效果。
這個動圖也說明一些事情,有此圖,估計對原理就會多懂一些。
LSMDatabase 效能測試
目前我這邊測試用例都挺簡單,如果有bug,就直接改了。
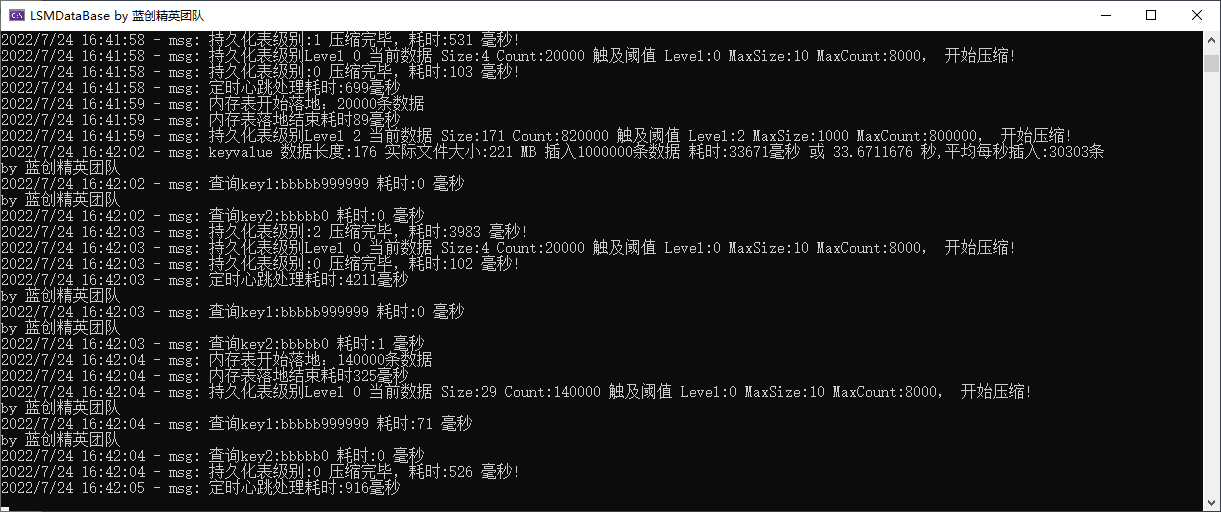
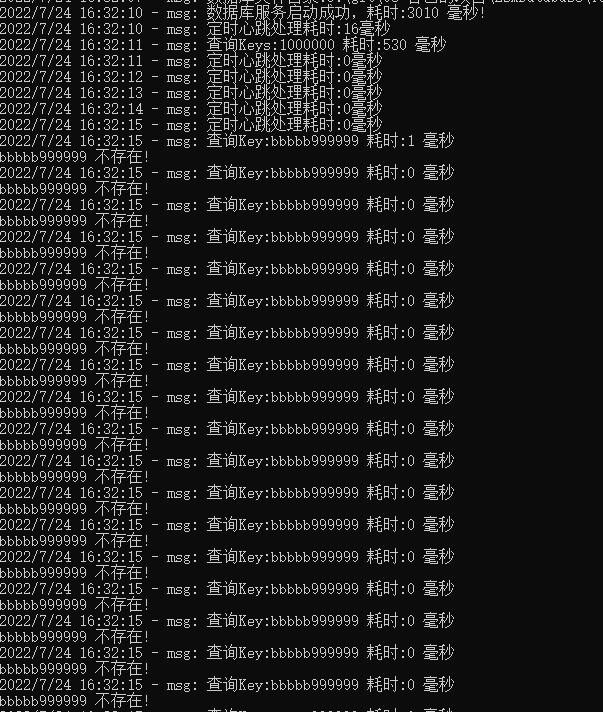
我這邊測試是,直接寫入一百萬條資料,測試結果如下:
keyvalue 資料長度:151 實際檔案大小:217 MB 插入1000000條資料 耗時:79320毫秒 或79.3207623秒,平均每秒插入:52631條
keyvalue 資料長度:151 實際檔案大小:221 MB 插入1000000條資料 耗時:27561毫秒 或 27.5616519 秒,平均每秒插入:37037條
- keyvalue 資料長度:176
- 實際檔案大小:215 MB
- 插入1000000條資料 耗時:29545毫秒 或 29.5457999 秒,
- 平均每秒插入:34482條 或 30373 等( 設定不一樣,環境不一樣,會有不同,但是大致差不多)
- 多次插入資料長度不同,設定不同,插入速度都會受到影響
載入215 MB 1000000條資料條資料 耗時:2322 毫秒,也就是2秒(載入SSTable)
記憶體穩定後佔用500MB左右。
穩定查詢耗時: 百條查詢平均每條查詢耗時: 0毫秒。可能是因為用了字典的緣故,查詢速度會快點,但是,特別點查詢會有0.300左右的耗時個別現象。
查詢keys,一百萬條耗時3秒,這個有點耗時,應該是資料量太大了。

至此,此專案已經結束,雖然,還沒有經歷過壓力測試,但是,整體骨架和內容已經完備,可以根據具體情況修復完善。目前我這邊是沒啥子問題的。
總結
任何事情的開始都是艱難的,跨越時間的長河,一步一步的學習,才有了今天它的誕生,會了就是會了,那麼,應對下一個相關問題就會容易許多,我對這樣的壁壘稱之為,知識的屏障。
一葉障目,還真是存在,如何突破,唯有好奇心,堅持下去,一點點挖掘。
參考資料
【萬字長文】使用 LSM Tree 思想實現一個 KV 資料庫
肖漢鬆:《從0開始:500行程式碼實現 LSM 資料庫》
cstack : 讓我們建立一個簡單的資料庫
資料庫核心雜談 - 一小時實現一個基本功能的資料庫
谷歌三大論文 GFS,MapReduce,BigTable 中的GFS和BigTable
致謝名單
- 痴者工良
- 陶德
雖然與以上大佬沒有太過深入的交流,畢竟咖位還是有點高的,但是,通過文章以及簡單的交流中,讓我對資料庫的研究更深一步,甚至真實的搞出來了,再次感謝。
程式碼地址
https://github.com/kesshei/LSMDatabaseDemo.git
https://gitee.com/kesshei/LSMDatabaseDemo.git
閱
一鍵三連呦!,感謝大佬的支援,您的支援就是我的動力!
版權
藍創精英團隊(公眾號同名,CSDN同名)