IM系統-訊息流化一些常見問題
原創不易,求分享、求一鍵三連
之前說過IM系統的一些優化,但是在網路上傳輸資料對於資料的流化和反流化也是處理異常情況的重點環節,不處理好可能會出現一些訊息傳送成功,但是解析失敗的情況,本文就帶大家來一起了解訊息流化中經常遇到的問題以及如何規避。
什麼是流化
我們用到的「流化」這個詞和我們常用的「序列化」類似,序列化指將一個物件的範例轉換成二進位制串或文字串的格式,以方便本地儲存或者異地傳輸。
資訊流化的目的也是為了形成二進位制串的格式方便網路傳輸,可以說「流化」就是「序列化」,兩者沒有本質的區別。
在網路通訊之前,先流化需要傳送的訊息成二進位制,進行網路傳輸,另外節點收到二進位制資料之後,進行反流化解析出訊息內容來進行通訊。
黏包問題
在進行TCP socket通訊時經常會使用自定義位元組流,原因是因為TCP通訊如同水流一樣,沒有明確的拆分規則,TCP粘包、拆包屬於網路底層問題,在資料鏈路層、網路層、傳輸層都可能出現。出現粘包常見的幾點:
- 要傳送的資料大於TCP傳送緩衝區剩餘空間大小,將會發生拆包。
- 待傳送資料大於MSS(最大報文長度),TCP在傳輸前將進行拆包
- 傳送的資料小於TCP傳送緩衝區的大小,TCP將多次寫入緩衝區的資料一次傳送出去,將會發生粘包
- 接收資料端的應用層沒有及時讀取接受緩衝區中的資料,將會發生粘包。
以上的封包傳送的不確定性,為了資料能夠正常解析,在業務層面需要將源源不斷的資料流進行拆分或者合併通常用的方法:
- 傳送資料是先定義本給封包的長度的包頭,然後傳送對應內容,通常自定義位元組流包格式
- 傳送端將每個封包封裝為固定長度(不夠的可以通過補0填充)
- 可以在封包之間設定邊界,如新增特殊符號,將不同的封包拆分開
除了上面說到的問題,資料傳輸中也存在很多不同系統語言和平臺的差異的問題,因為在各種基本的資料型別中,將平臺上的基礎型別轉化為二進位制流,然後將流轉化成接收的機器上的資料型別,如果機器不一樣就會存在位元組排序的差異、資料位元組大小、資料表示和資料對準的方式等問題,經常會遇到的問題:
- 流資料在64位元作業系統與32位元作業系統之間的相容
- 流資料中字串的編解碼方式不同的影響
- 流資料在不同程式語言之間 java 和c 之間的相容問題;我們分別來看這些常見的問題如何處理才能解決
Little Endian與Big Endian
Little Endian 和Big Endian是表示計算機位元組順序的兩種格式,所謂的位元組順序指的是長度跨度多個位元組的資料的存放形式。Little Endian是把低位元組存放在記憶體的低位,而Big Endian將低位元組存放在記憶體的高位。
為什麼會有Little Endian 和Big Endian?要是都統一成一個就好了。
在計算機系統中,我們是以位元組為單位的,每個地址單元都對應著1個位元組,1個位元組為8bit。但是在除了8bit的char之外,還有16bit的short型,32bit的long型等。
另外對於位數大於8位元的處理器,例如16位元或者32位元的處理器,由於暫存器寬度大於1個位元組,那麼必然存在一個如果將多個位元組排列的問題,因此就導致了Little Endian和Big Endian兩種儲存模式。
我們網路傳輸上,TCP/IP協定規定了必須使用網路位元組順序(Big Endian模式),而大多數的PC機上採用了Little Endian模式。所以我們就會注意位元組序列相容的問題 對跨機器通訊有什麼影響呢,最小記憶體單元8位元 一個位元組。
例如:對4位元組的整形資料1247752720 ,其16進位製表示0x4a5f3210,低位是0x10, 最高位0x4a,假設存放這個整形的記憶體單元0x10000100, 終止地址0x10000103,那麼32位元的Little Endian系統中,該整形記憶體儲存如下:

但是32位元的Big Endian體系中,卻存放如下:
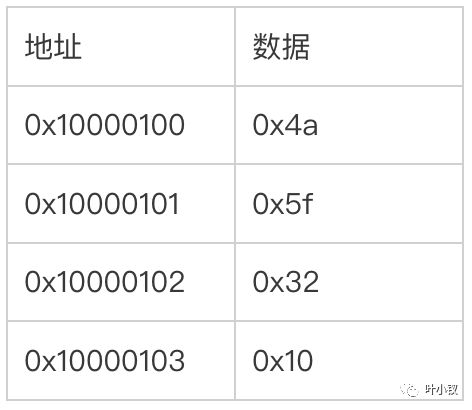
所以,流資料在不同的平臺之間傳輸時,一定要考慮Little Endian和Big Endian的問題,不然傳輸的資料位元組序列就會解析錯誤。
32位元與64位元機器
作業系統相容是流資料傳輸中平臺無關的另一個重要問題。我們知道在32位元和64位元機器上,同一型別的變數的位元組長度可能是不一樣的。比如long 型的變數,在32位元機器上是4位元組,但在64位元機器上卻是8個位元組。
因此,如果一個64位元機器上的long型變數流化後,傳輸到32位元機器上時,採用long型來接收和解釋,必然失敗,並且可能導致整個流資料的解析失敗。
對該類問題的解決方式,一般採用這樣的方法:無論是32位元機器還是64位元機器上,我們都統一規定long型的變數只代表4位元組的整形數,無論傳送、傳輸、接收都嚴格按照這個標準;在語言之間也存在long型差異,c語言中long是4位元組,java的long型是8位元組。這也需要採用同樣的方式來解決。
UTF8 與UTF16的轉換
這個問題來源於不同的程式語言,其對字串的編碼的規則不同。
C/C++ 語言,一般採用UTF-8編碼,比如中文采用UTF-8一般1~3個位元組表示一個字元;如java語言,其內部編碼一般時UTF-16;統一以2個位元組表示一個字元;在Win平臺下的VC++ 採用的wchar來存在一個字元,其實就是UTF-16; 上面已經說過如果出現多個位元組的資料,就會有Little Endian 和Big Endian的問題。
解決這種問題最好的方式統一編碼 要麼統一使用UTF-8 要麼統一使用UTF-16 另外還有種方式來解決編碼的問題也比較常用,使用BASE64 編解碼;
Base64演演算法可以解決中文編碼?
Base64是一種二進位制到文字的編碼方式。它是一種將byte陣列編碼為字串的方法,而且編碼出的字串只包含ASCII基礎字串。基於Base64編碼的文字只包含了64個ASCII碼字元:
- A-Z 26個
- a-z 26個
- 0-9 10個
- 1個
- / 1個 正好64 個字元
使用ASCII碼1個碼一個位元組就能表示,就不存在多個位元組情況,所以經過編碼的中文字串,都是一個單位元組的序列,不存在多個位元組表示一個碼,所以傳輸的過程中就不需要考慮Little Endian 和Big Endian的轉化問題。
總結
無論多複雜的訊息型別最終要做訊息流化都會落到基本的資料型別:數值型、整型、浮點型、雙浮點型資料與長整形數、字串型;做好基礎型別佔用位元組統一和大小端處理,解析訊息就會更流暢。
好了,今天的分享就到這。如果本文對你有幫助的話,歡迎點贊&評論&在看&分享,這對我非常重要,感謝