Flink Window&Time 原理
Flink 中可以使用一套 API 完成對有界資料集以及無界資料的統一處理,而無界資料集的處理一般會伴隨著對某些固定時間間隔的資料聚合處理。比如:每五分鐘統計一次系統活躍使用者、每十秒更新熱搜榜單等等
這些需求在 Flink 中都由 Window 提供支援,Window 本質上就是藉助狀態後端快取著一定時間段內的資料,然後在達到某些條件時觸發對這些快取資料的聚合計算,輸出外部系統。
實際上,有的時候對於一些實時性要求不高的、下游系統無法負載實時輸出的場景,也會通過視窗做一個聚合,然後再輸出下游系統。
Time
時間型別
Flink 是基於事件流的實時處理引擎,那麼流入系統的每一件事件都應該有一個時間,Flink 提供以下四種時間型別來定義你的事件時間:
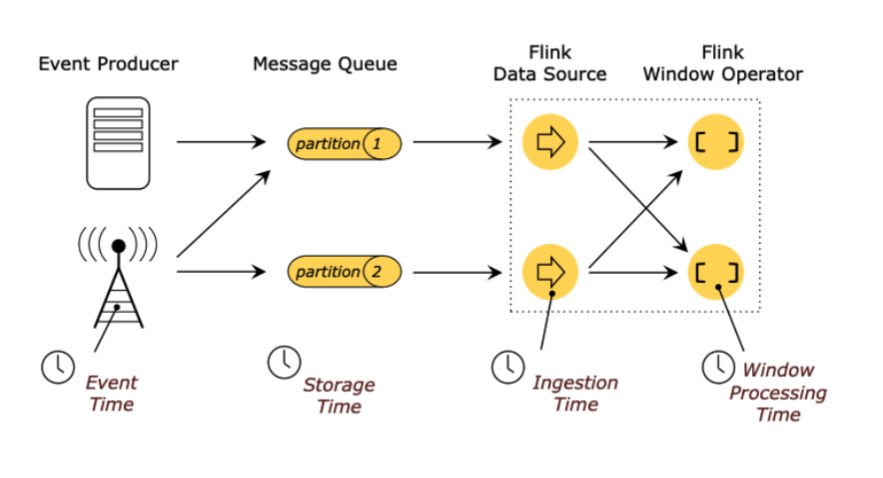
Event Time:這是我們最常用的時間型別,它表示事件真實發生時的時間(比如你點選一個按鈕,就是點選的一瞬間的那個時間) Storage Time:不常用,表示事件以訊息的形式進入佇列時的時間 Ingestion Time:不常用,表示事件進入 Flink Source 的時間 Processing Time:相對常用一些,表示事件實際進入到 window 運算元被處理的時間
以上四種實際上用的最多的還是 EventTime,ProcessingTime 偶爾會用一用。
因為 EventTime 是描述事件真實發生的時間,我們知道事件發生是有順序的,但經過網路傳輸後不一定能保證接收順序。比如:你先買了 A 商品,再買了 B 商品,那麼其實有很大可能 Flink 先收到 B 商品的購買事件,再收到 A 的。通過 EventTime 就可以保證即便 A 事件後到來我也知道它是先發生的。
而 ProcessingTime 描述的是事件被處理時的時間,準確來說並不是事件真實發生的時間,所以它往往在一些不關注事件到達順序的情境中使用。
Watermark 水位線
Watermark 在很多系統中都有應用,可能各個系統的叫法不同,但這種思想還是比較常見的。比如:Kafka 中副本同步機制中的高水位、MySQL 事務隔離機制中可見事務的高低水位等等。
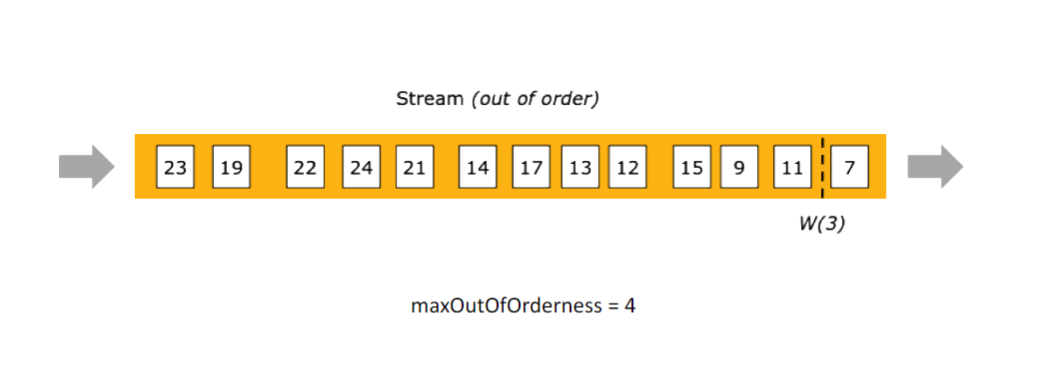
在 Flink 中 Watermark 描述的也是一種水位線的概念,他表示水位線之下的所有資料都已經被 Flink 接收並處理了。
視窗的觸發一般就會基於 Watermark 來實現,水位線動態更新,當達到某某條件就觸發哪些視窗的計算。
關於 Watermark 如何更新,Flink 是開放給你實現的,當然它也提供了一些預設實現。
Timestamp 的抽取
如果你指定 Flink 需要使用 EventTime,那麼你就需要在 WatermarkStrategy 策略中通過 withTimestampAssigner 指定如何從你的事件中抽取出 Timestamp 作為 EventTime。比如:

Watermark 的生成
Watermark 的生成方式本質上是有兩種:週期性生成和標記生成。
/**
* {@code WatermarkGenerator} 可以基於事件或者週期性的生成 watermark。
*
* <p><b>注意:</b> WatermarkGenerator 將以前互相獨立的 {@code AssignerWithPunctuatedWatermarks}
* 和 {@code AssignerWithPeriodicWatermarks} 一同包含了進來。
*/
@Public
public interface WatermarkGenerator<T> {
/**
* 每來一條事件資料呼叫一次,可以檢查或者記錄事件的時間戳,或者也可以基於事件資料本身去生成 watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 週期性的呼叫,也許會生成新的 watermark,也許不會。
*
* <p>呼叫此方法生成 watermark 的間隔時間由 {@link ExecutionConfig#getAutoWatermarkInterval()} 決定。
*/
void onPeriodicEmit(WatermarkOutput output);
}
週期性生成器通常通過 onEvent() 觀察傳入的事件資料,然後在框架呼叫 onPeriodicEmit() 時更新 Watermark。
標記生成器將檢視 onEvent() 中的事件資料,然後根據你自定義的邏輯是否需要更新 Watermark。
比如這是一個官網給出的例子:
/**
* 該 watermark 生成器可以覆蓋的場景是:資料來源在一定程度上亂序。
* 即某個最新到達的時間戳為 t 的元素將在最早到達的時間戳為 t 的元素之後最多 n 毫秒到達。
*/
public class BoundedOutOfOrdernessGenerator implements WatermarkGenerator<MyEvent> {
private final long maxOutOfOrderness = 3000; // 3 秒
private long currentMaxTimestamp;
@Override
public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {
currentMaxTimestamp = Math.max(currentMaxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 發出的 watermark = 當前最大時間戳 - 最大亂序時間
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
它實現的邏輯就是:每個事件到來會根據自身攜帶的 EventTime 和當前已到達的最大時間戳進行對比,保留兩者較大的時間戳用以描述當前已到達的最大事件。
然後 onPeriodicEmit 週期性的更新 WaterMark:最多接收 3s 的延遲資料,也就是 "2022 07-24 10:10:20" 的事件到達就會生成一個 "2022 07-24 10:10:17" 的 WaterMark 表示在此水位線之前的資料全部收到並且不再接收此水位線之前的事件。(這部分不再被接收的資料實際上會被叫做遲到資料)
Flink 中內建的一個用的比較多的生成器就是:
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3));
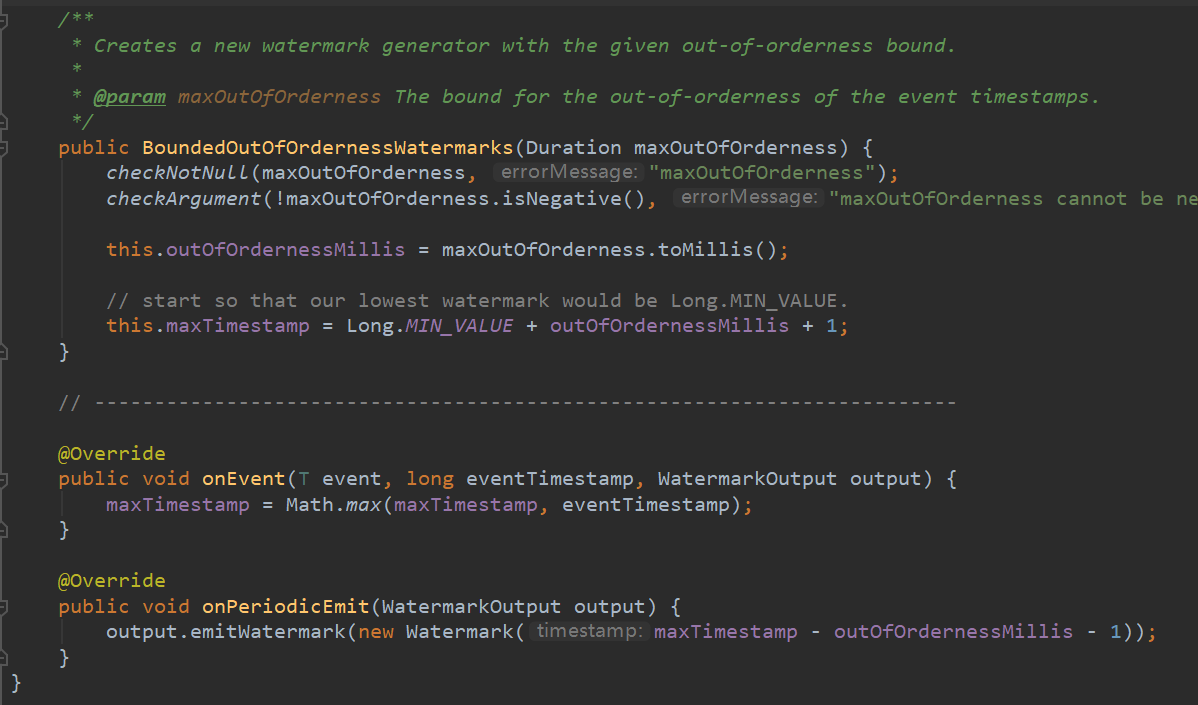
這個其實就是我們上面的範例封裝,它的內部實現就是這樣:
Watermark 的傳播
在多並行度下,Watermark 具有木桶效應,取最小的。比如下圖中
map1 和 map2 會 keyby 把部分資料流到 window1,map1 產生的 w(29) 和 map2 產生的 w(14),最終 window1 會以 w(14) 往下游運算元傳播。
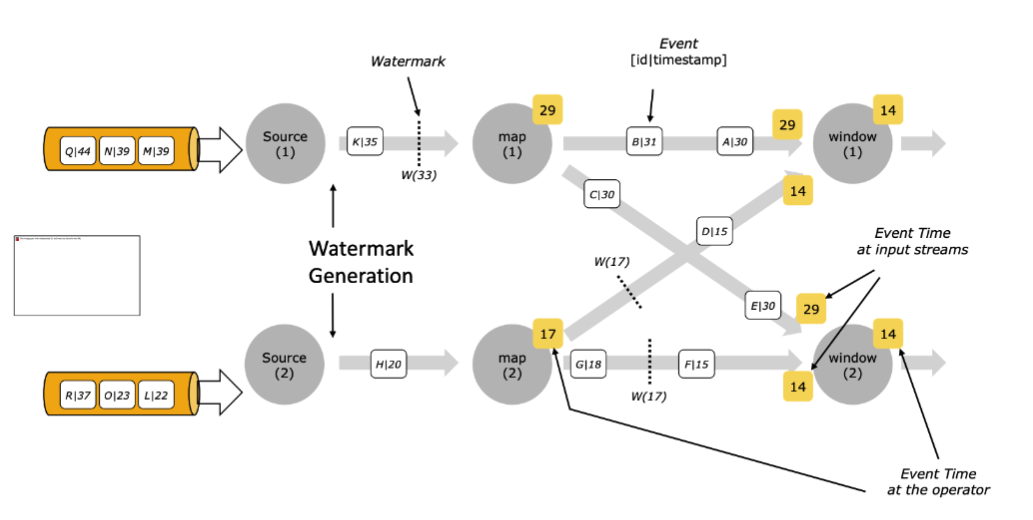
傳小不傳大應該是比較好理解的,如果傳大的就會讓進度慢的 map2 後續的資料全部被認為遲到資料而被丟棄。
這裡其實會存在一個問題,如果 map2 突然沒資料了,也就是不再更新 Watermark 往下游傳播了,那麼是不是就整個資料流再也不會推進 Watermark 了?
實際上,這種情況是存在的,Flink 中提供如下設定可以將某個源標記為空閒,即將它刨除 Watermark 的計算列表中。比如一分鐘沒有資料流出即標記為空閒資料來源。
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
Window
Window 本質上就是藉助狀態後端快取著一定時間段內的資料,然後在達到某些條件時觸發對這些快取資料的聚合計算,輸出外部系統。
Flink 中會根據當前資料流是否經過 keyby 運算元分為「Keyed 和 Non-Keyed Windows」
KeyedWindow 實際上就是每個 key 都對應一個視窗,而 Non-KeyedWindow 實際上是全域性並行度為1的視窗(即便你手動指定多並行度也是無效的)
一個完整的 WindowStream 的處理流程大概是這樣的,資料經過 assigner 的挑選進入對應的視窗,經過 trigger 的邏輯觸發視窗,再經過 evictor 的剔除邏輯,然後由 WindowFuction 完成處理邏輯,最終輸出結果。
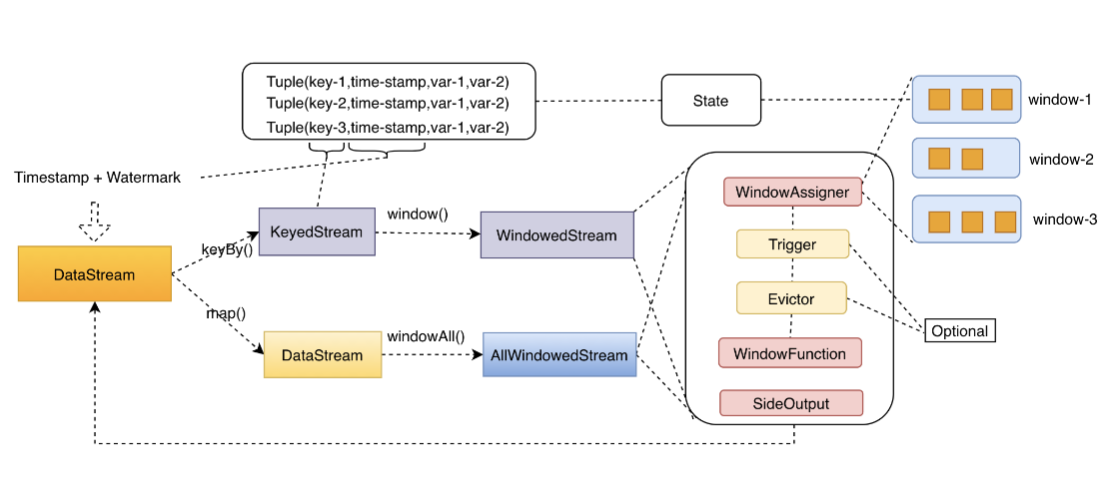
Window Assigners
Window assigner 定義了 stream 中的元素如何被分發到各個視窗。換句話說,每一個事件資料到來,Flink 通過 assigner 的邏輯來確定當前事件資料應該發往哪個或者哪幾個視窗。
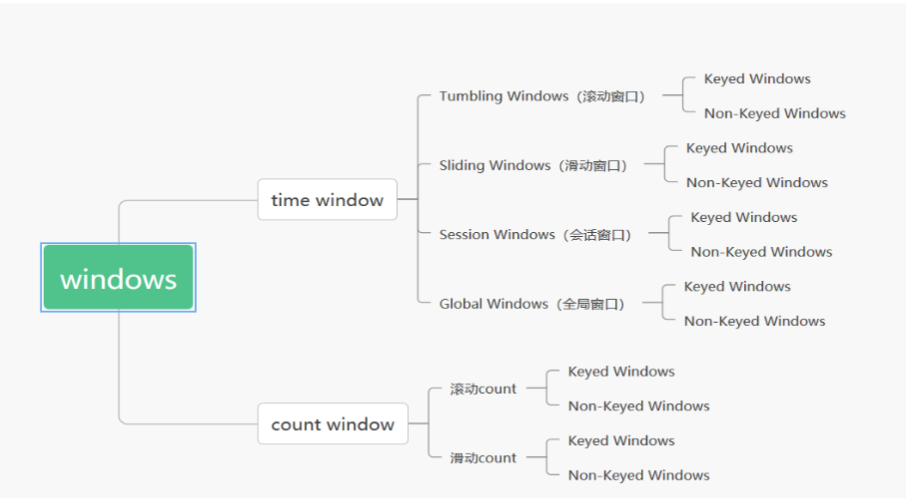
內建的 WindowAssigners
Flink 中預定義好了四款 WindowAssigner,幾乎可以滿足日常百分之八九十的場景需求。
捲動視窗(Tumbling Windows)
捲動視窗的 assigner 分發元素到指定大小的視窗。捲動視窗的大小是固定的,且各自範圍之間不重疊。
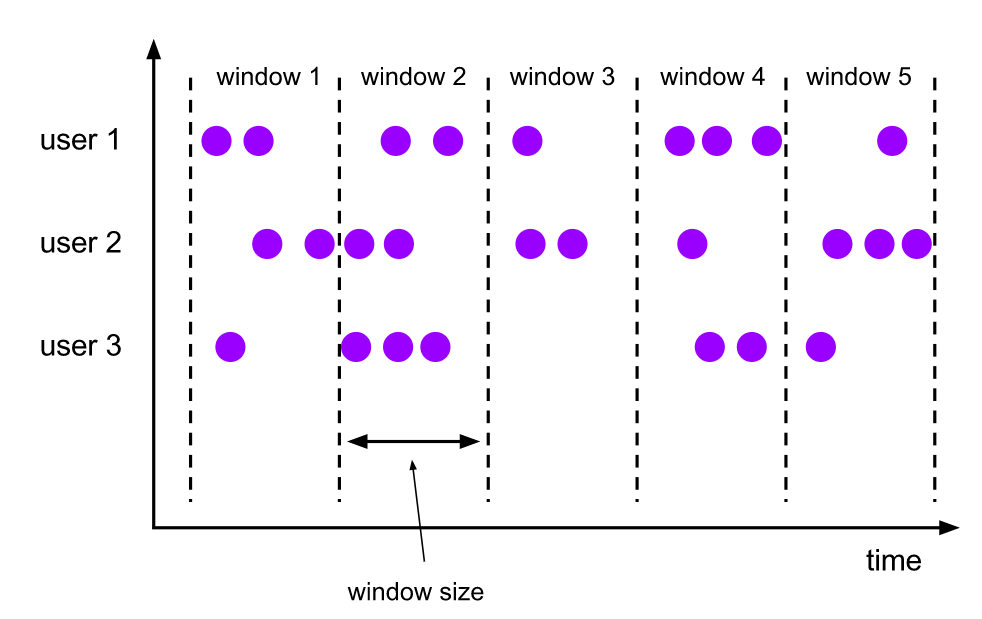
通過使用 TumblingEventTimeWindows 或者 TumblingProcessingTimeWindows 來指定使用捲動視窗。
除此之外,捲動視窗還實現好了一個預設的 Trigger 觸發器 EventTimeTrigger,也就是說使用捲動視窗預設不需要再指定觸發器了,至於觸發器是什麼待會兒會介紹,這裡只是需要知道它是有預設觸發器實現的。
滑動視窗(Sliding Windows)
滑動視窗和捲動視窗的區別在於,多了一個滑動維度,也就是說視窗仍然是固定長度,但是視窗會以一個固定步長進行滑動。
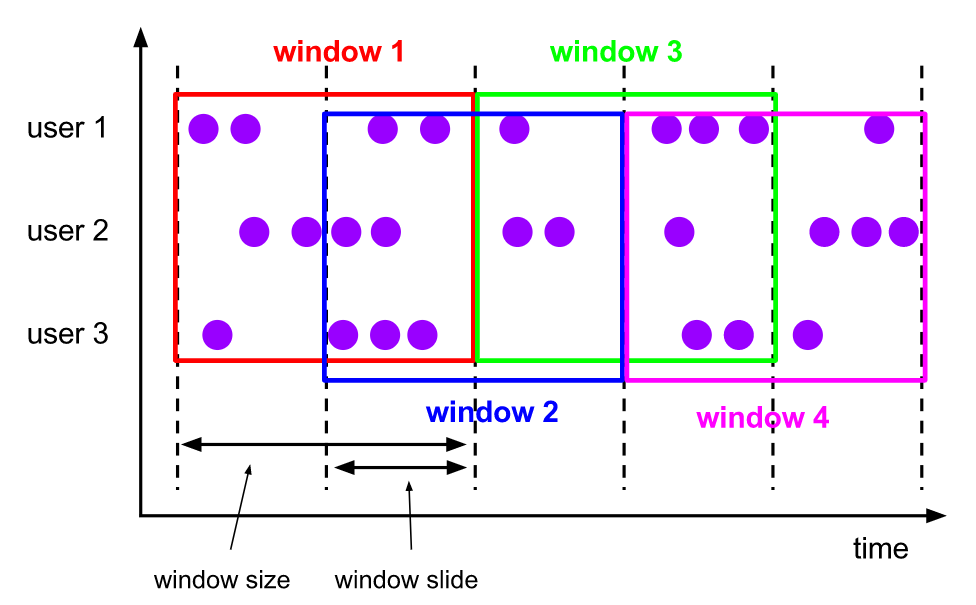
比如視窗是 10m,滑動步長是 5m,那麼 window1 後 5m 的資料其實也是 window2 前 5m 的資料,這種視窗的特點就是存在資料重複。
這種視窗的資料場景還是比較多的,比如:每隔 5 分鐘輸出最近一小時內點選量最多的前 N 個商品。(windowsize=1h,slide=5m,每間隔 5m 會有一個視窗產生,而每個視窗包含 1h 的資料)
通過 SlidingEventTimeWindows 和 SlidingProcessingTimeWindows 來指定使用滑動視窗。區別的是,滑動視窗對於一個事件可能返回多個視窗,以表示該資料同時存在於多個視窗之中。
滑動視窗和捲動視窗使用的是同一個觸發器 EventTimeTrigger。
對談視窗(Session Windows)
對談視窗的 assigner 會把資料按活躍的對談分組。對談視窗沒有固定的開始和結束時間,我們唯一需要指定的 sessionGap,表示如果兩條資料之間差距查過這個時間間隔即切分兩個視窗。
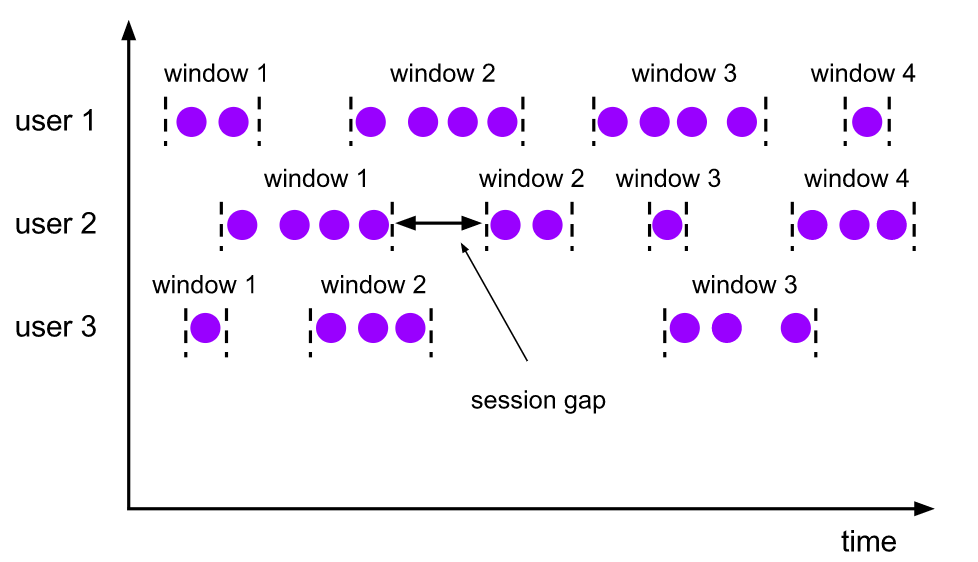
其實從 Flink 原始碼的角度看對談視窗的實現就是:每條資料過來都會建立一個視窗(timestamp, timestamp+sessionGap),然後會對重合的視窗集進行不斷的 merge 輸出成一個視窗。這樣,視窗的截止就是最後一個活躍事件加上 sessionGap。非常巧妙的實現了 gap 這個語意。
預設的視窗觸發器依然是 EventTimeTrigger。
全域性視窗(Global Windows)
全域性視窗就是會將所有的資料 Shuffle 到一個範例上,單並行度收集所有資料。

通過使用 GlobalWindows 來指定使用全域性視窗,需要注意的是:全域性視窗沒有預設的觸發器,也就是資料預設永遠不會觸發。
所以,如果需要用到全域性視窗,一定記得指定視窗觸發器。實際上 countWindow 本質上就是一個全域性視窗,全域性計數的視窗。
自定義 WindowAssigners
上面說的四種 WindowAssigners 是 Flink 內建的預設的實現,應該可以滿足大家平常百分之八九十的需求。除此之外的是,Flink 也允許你自定義實現 WindowAssigner,以下是它的一些核心方法:
assignWindows getDefaultTrigger isEventTime getWindowSerializer
其中 assignWindows 方法它將返回一個 window 用以表示當前事件處於哪個視窗中。
getDefaultTrigger 方法返回一個預設實現的觸發器,這個觸發器預設和當前 WindowAssigner 繫結,當然你也可以外部再顯式指定替換。
isEventTime 用於標記當前 WindowAssigner 是否是基於 EventTime 實現的,getWindowSerializer 方法將告訴 Flink 應該如何序列化當前視窗。
總之,重點重寫 assignWindows 的邏輯即可,你也可以去開啟 Flink 內建的四種 WindowAssigner 的原始碼實現進行參考。
視窗函數(Window Functions)
WindowFunction 就是定義了視窗在觸發後應該如何計算的邏輯。
視窗函數有三種:ReduceFunction、AggregateFunction 或 ProcessWindowFunction。
ReduceFunction 指定兩條輸入資料如何合併起來產生一條輸出資料,輸入和輸出資料的型別必須相同。 AggregateFunction 會在每條資料到達視窗後 進行增量聚合,相對效能較好。 ProcessWindowFunction 只會在觸發器生效時將視窗中所有的資料全部發到 ProcessWindowFunction 進行計算,更靈活但效能更差。
Triggers
顧名思義,觸發器用於決定視窗是否觸發,Flink 中內建了一些觸發器,如圖:

其中,EventTimeTrigger 已經在上文中多次出現,它的邏輯也比較簡單,就是當每個事件過來時判斷當前 Watermark 是否越過視窗邊界,如果是則觸發視窗,Flink 也將呼叫你的 ProcessFunction 傳入視窗中所有資料進行計算。
Trigger 介面中有如下一下核心方法需要關注:
onElement onEventTime onProcessingTime
其中,onElement 會在每個事件到來被呼叫,onEventTime 和 onProcessingTime 都將在 Flink timer 的定時器中被呼叫。
其餘的一些 Triggers 相對不是特別常用,不過也沒有特別複雜,你可以直接檢視它的原始碼實現。
比如:ContinuousEventTimeTrigger,它就是在 EventTimeTrigger 的基礎上增加了固定時間間隔觸發,每個事件過來如果沒有達到觸發條件,會通過 ReducingState 記錄下 "time+interval" 也就是下一次觸發的時間並註冊一個 timer,最終會在 timer 的排程下執行 onEventTime 完成視窗觸發。
Evictors
Flink 的視窗模型允許在 WindowAssigner 和 Trigger 之外指定可選的 Evictor,在 trigger 觸發後、呼叫視窗函數之前或之後從視窗中刪除元素,我們也稱它為剔除器。
用法也比較簡單,就是在 windowStream 後呼叫 evictor()方法,並提供 Evictor 實現類,Evictor 類中有兩個方法需要實現,evictBefore() 包含在呼叫視窗函數前的邏輯,而 evictAfter() 包含在視窗函數呼叫之後的邏輯。
Flink 中也提供了內建的一些剔除器:
CountEvictor:僅記錄使用者指定數量的元素,一旦視窗中的元素超過這個數量,多餘的元素會從視窗快取的開頭移除 DeltaEvictor:接收 DeltaFunction 和 threshold 引數,計算最後一個元素與視窗快取中所有元素的差值, 並移除差值大於或等於 threshold 的元素 TimeEvictor:接收 interval 引數,以毫秒錶示。 它會找到視窗中元素的最大 timestamp max_ts 並移除比 max_ts - interval 小的所有元素
最後說一下關於遲到資料,沒有被視窗包含的資料在 Flink 中可以不被丟棄,Flink 中有 Allowed Lateness 策略,即通過 allowedLateness 方法指定一個最大可接受的延遲時間,那麼這部分遲到的資料將可以通過旁路輸出(sideOutputLateData)獲取到。
