ShardingSphere資料庫讀寫分離
碼農在囧途
最近這段時間來經歷了太多東西,無論是個人的壓力還是個人和團隊失誤所帶來的損失,都太多,被罵了很多,也被檢討,甚至一些不方便說的東西都經歷了,不過還好,一切都得到了解決,無論好壞,這對於個人來說也是一種成長吧,事後自己也做了一些深刻的檢討,總結為一句話「挫敗使你難受,使你睡不著覺,使你痛苦,不過最後一定會使你變得成熟,變得認真,變得負責」,每次面臨挫敗,我都會告訴自己,這不算什麼,十年之後,你回過頭來看待這件事的時候,你一定會覺得,這算什麼屁事。
背景
在現在這個資料量與日俱增的時代,傳統的單表,單庫已經無法滿足我們的需求,可能早期資料量不是很大,CRUD都集中在一個庫中,但是當資料量 到達一定的規模的時候,使用單庫可能就無法滿足需求了,在實際場景中,讀的頻率是遠遠大於寫的,所以我們一般會做讀寫分離,主庫一般用於寫,而從庫 用於讀,而主從分離有好幾種模式。
一主多從
一主多從是隻有一臺主機用於寫操作,多臺從機用於讀操作,一主多從是存在風險的,當主機宕機後,那麼寫服務就會癱瘓,本文我們主要說的是ShardingSphere讀寫分離, 而目前ShardingSphere只支援單主庫,所以如果要保證業務的高可用,那麼目前ShardingSphere不是很好的選擇,不過希望ShardingSphere後面支援多主機模式。
多主多從
從上面的一主多從我們看出了它的弊端,所以為了保證高可用,我們可能需要多個主機用於寫操作,這樣當某個主機宕機,其他主機還能繼續工作,ShardingSphere只支援 單主機。
ShardingSphere只需要簡單的設定就能實現資料庫的讀寫的分離,我們甚至感知不到是在操作多個資料庫,極大的簡化了我們的開發,但是ShardingSphere 不支援多主庫,也無法進行主從資料庫的同步。
ShardingSphere整合SpringBoot專案進行主從分離
ShardingSphere和SpringBoot能夠很簡單的進行組合,只需要簡單的設定,ShardingSphere能夠和主流的ORM框架進行整合,ShardingSphere會 從ORM框架中解析出SQL語句,判斷是讀操作還是寫操作,如果是讀操作,則會落到主庫上,如果是讀操作,那麼ShardingSphere會使用對應的負載均衡演演算法負載到 對應的從庫上面。
maven引入ShardingSphere starter
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency>
yml檔案設定
names為資料庫名稱字串,然後需要一個一個的進行設定JDBC連線,對於讀寫分離,我們需要關注rules下面的readwrite-splitting 通過load-balancers設定負載均衡策略,data-sources設定對應的讀寫庫,目前ShardingSphere只支援單主庫,多從庫,如下我們寫 庫使用write-data-source-name,庫為db1,讀庫使用read-data-source-names,庫db2,db3,db4。
spring:
shardingsphere:
datasource:
names: db1,db2,db3,db4
db1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
db2:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
db3:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db3?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
db4:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db4?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
rules:
sharding:
readwrite-splitting:
load-balancers:
round_robin:
type: ROUND_ROBIN
data-sources:
read_write_db:
type: Static
props:
write-data-source-name: db1
read-data-source-names: db2,db3,db4
load-balancer-name: round_robin
props:
sql-show: true
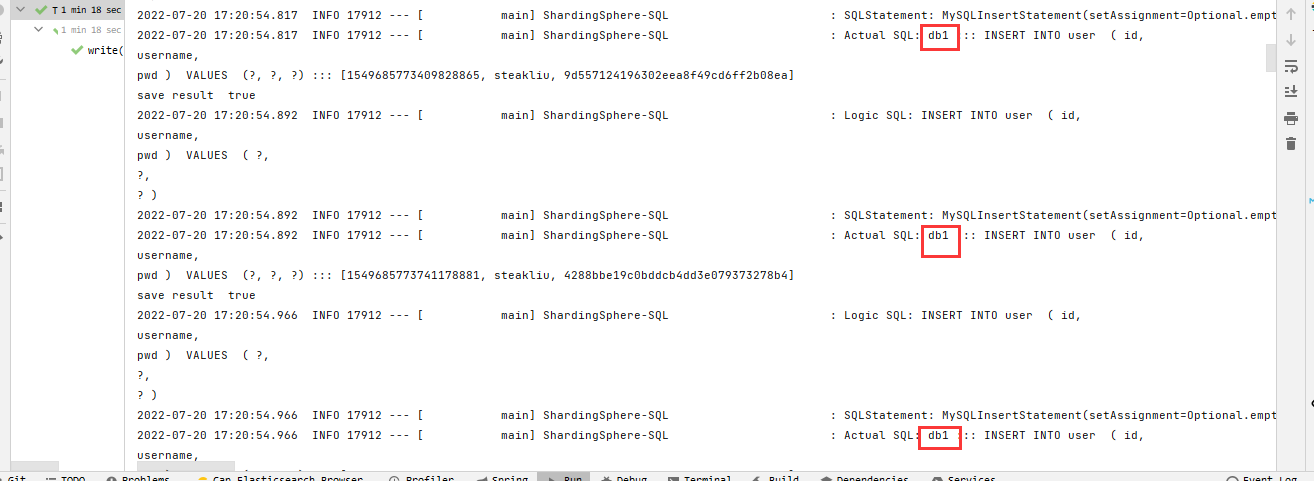
測試寫操作。
因為寫操作設定的資料庫是db1,所以所有寫操作都應該進入db1,如下圖所示,解析出來的ShardingSphere-SQL中顯示的都是db1。
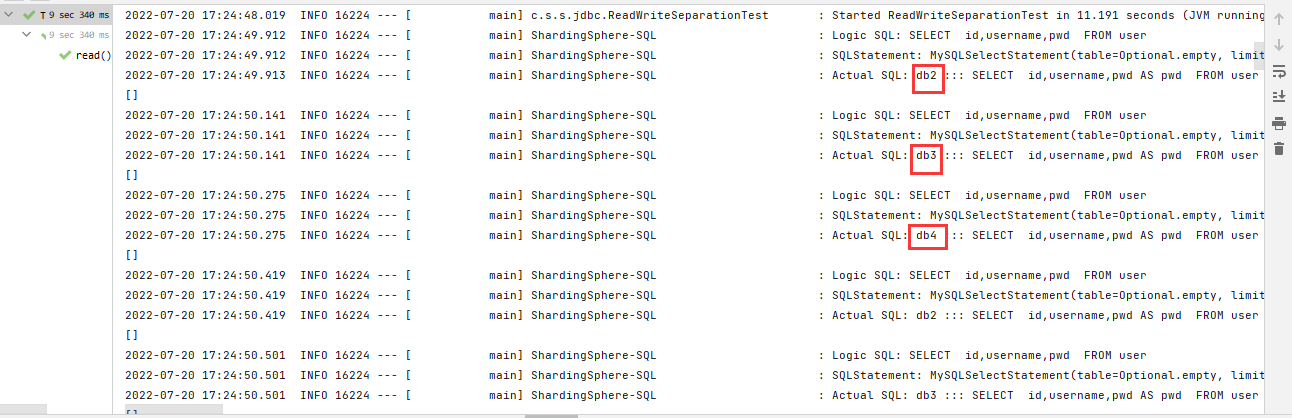
測試讀操作
讀操作設定的資料庫是db2,db3,db4,設定的負載均衡演演算法是ROUND_ROBIN(輪詢演演算法),所以查詢請求會在三個庫順序查詢。
ShardingSphere負載均衡演演算法
因為從庫有多個,所以我們需要根據一定的策略將請求分發到不同的資料庫上,防止單節點的壓力過大或者空閒,ShardingSphere內建了多種負載均衡演演算法,如果我們想實現自己的 演演算法,那麼可以實現ReadQueryLoadBalanceAlgorithm介面,下面我們列舉幾種來看下。
ROUND_ROBIN 輪詢演演算法
設定負載均衡演演算法為輪詢演演算法,那麼所有請求都會均勻的分發到對應的資料庫,這樣,每臺資料庫所承受的壓力都是一樣的,輪詢演演算法對應的實現類是RoundRobinReplicaLoadBalanceAlgorithm。
public final class RoundRobinReplicaLoadBalanceAlgorithm implements ReadQueryLoadBalanceAlgorithm {
private final AtomicInteger count = new AtomicInteger(0);
@Getter
private Properties props;
@Override
public void init(final Properties props) {
this.props = props;
}
@Override
public String getDataSource(final String name, final String writeDataSourceName, final List<String> readDataSourceNames) {
if (TransactionHolder.isTransaction()) {
return writeDataSourceName;
}
return readDataSourceNames.get(Math.abs(count.getAndIncrement()) % readDataSourceNames.size());
}
@Override
public String getType() {
return "ROUND_ROBIN";
}
@Override
public boolean isDefault() {
return true;
}
}
RANDOM 隨機演演算法
如果使用隨機演演算法,那麼請求過來以後就會隨機的分發到其中的一個資料庫上面,使用隨機演演算法可能會導致請求的分發不均勻,可能某一臺 接受到了大量的請求,某一臺接受到的請求相對來說較少。
WEIGHT 基於權重的演演算法
基於權重的演演算法需要做相應的設定,我們可以將某一臺資料庫的權重加大,某一臺資料庫的權重減小,這樣,權重大的資料庫 就會接收到更多的請求,權重小的接收到的請求就會比較少。
在ShardingSphere中自定義負載均衡演演算法
ShardingSphere中使用了大量的SPI,所以我們開發者可以自由的實現自己的規則,然後無縫的切換到自己的規則,我們可以實現自己的一套負載均衡演演算法,其實ShardingSphere內建的集中負載均衡演演算法完全能滿足資料庫負載均衡,只不過為了更加深入的學習ShardingSphere,所以我們很有必要自己簡單的實現一下。
下面我們簡單的實現一下,我們就不去實現一些複雜的了,為了演示,我們將所有請求全部都負載到db2。
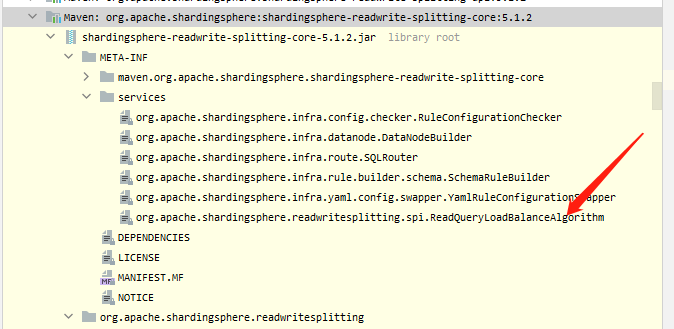
定義SPI
我們從ShardingSphere的讀寫分離模組shardingspere-readwrite-spliltting-core中的META-INF/services下面看到了負載均衡的SPI。
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.RoundRobinReplicaLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.RandomReplicaLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.WeightReplicaLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedPrimaryLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedReplicaRandomLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedReplicaRoundRobinLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedReplicaWeightLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.TransactionRandomReplicaLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.TransactionRoundRobinReplicaLoadBalanceAlgorithm
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.TransactionWeightReplicaLoadBalanceAlgorithm
為了實現自己的負載均衡演演算法,我們需要在自己的模組中定義SPI,如下,在自己專案的META-INF/services目錄下編寫負載均衡SPI介面,裡面內容為我們自定義的負載均衡演演算法的類檔案的位置。
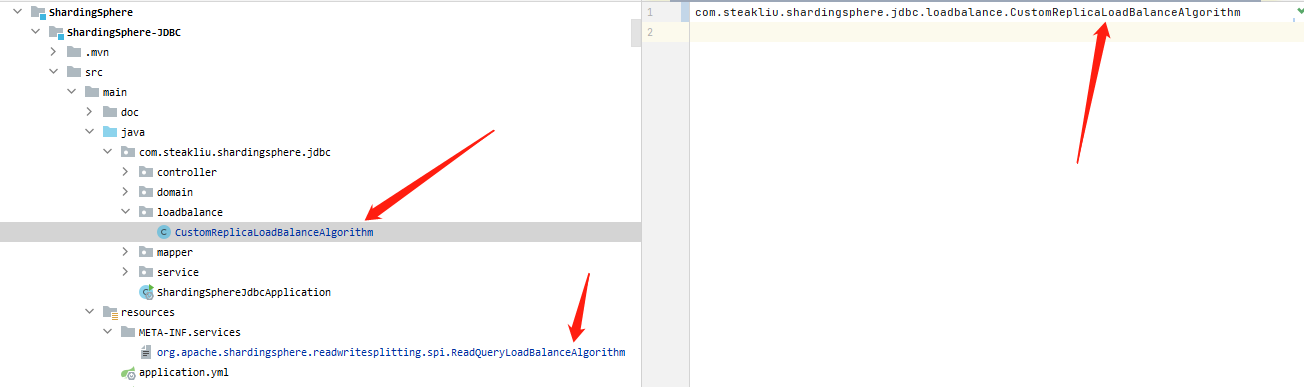
編寫負載均衡演演算法核心程式碼
自定義負載均衡演演算法需要實現ReadQueryLoadBalanceAlgorithm介面,裡面核心的兩個方法是getDataSource和getType,getDataSource是演演算法的邏輯實現部分,其目的是選出一個目標資料庫,此方法會傳入readDataSourceNames,它是讀庫的集合,我們此處直接返回db2,那麼會一直讀db2,getType是返回負載均衡演演算法的名稱。
/**
* 功能說明: 自定義負載均衡演演算法
* <p>
* Original @Author: steakliu-劉牌, 2022-07-20 18:05
* <p>
* Copyright (C)2020-2022 steakliu All rights reserved.
*/
public class CustomReplicaLoadBalanceAlgorithm implements ReadQueryLoadBalanceAlgorithm {
@Getter
private Properties props;
@Override
public String getDataSource(final String name, final String writeDataSourceName, final List<String> readDataSourceNames) {
return "db2";
}
@Override
public String getType() {
return "CUSTOM";
}
@Override
public void init(Properties props) {
this.props = props;
}
@Override
public boolean isDefault() {
return false;
}
}
在yml中使用自己實現的負載均衡演演算法
rules:
sharding:
readwrite-splitting:
load-balancers:
custom:
type: CUSTOM
data-sources:
read_write_db:
type: Static
props:
write-data-source-name: db1
read-data-source-names: db2,db3,db4
load-balancer-name: custom
發起大量的查詢操作
從紀錄檔輸出來看,所有的請求全部落在了db2上面,於是證明我們自定義的負載均衡演演算法成功了。

讀寫分離的中介軟體其實有很多,ShardingSphere旨在構建異構資料庫上層的標準和生態,使用它我們基本上能解決資料庫中的大部分問題,但是ShardingSphere也並不是萬能的,還有一些東西沒有實現,我們期待ShardingSphere能夠實現更多強大,好用的功能。
關於ShardingSphere讀寫分離的分享,我們今天就先說到這裡,後面我們會繼續探索ShardingSphere的更多強大的功能,比如資料分片,高可用,資料加密,影子庫等,今天的分享就到這裡,感謝你的觀看,我們下期見。
