移動語意和完美轉發淺析
移動語意和完美轉發淺析
移動語意基礎
為什麼要引入移動語意?
vector<int> v1{1, 2, 3, 4, 5};
vector<int> v2;
v2 = v1;
在移動語意出現前,我們拷貝一個 vector 物件,邏輯上可以分為兩步:
- 在堆上分配一塊空間
- 將 v1 的元素逐個拷貝到 v2 中
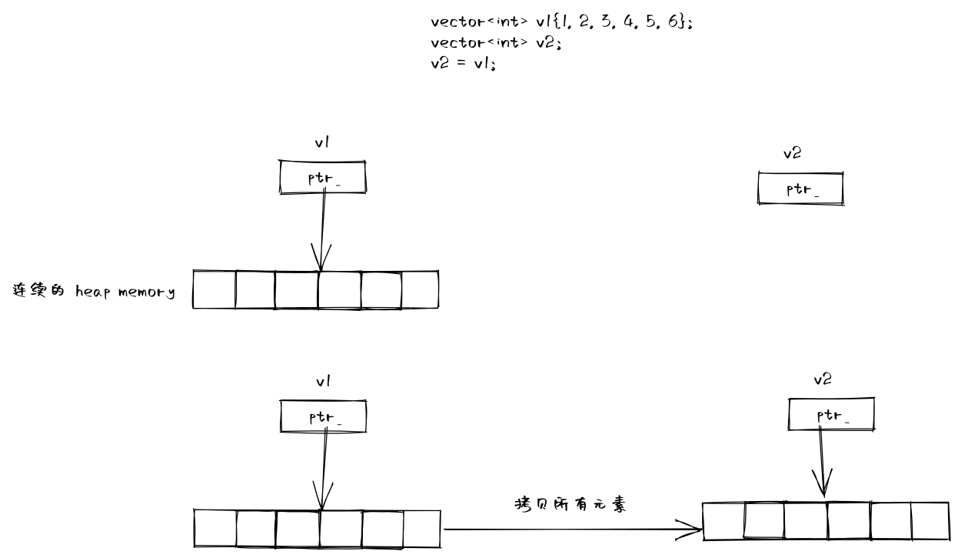
這種行為是完全正確,沒有問題的,但如果 v1 是作為函數的返回值呢?
vector<int> createVector() {
vector<int> v1{1, 2, 3, 4, 5};
return v1;
}
vector<int> v2;
v2 = createVector();
在這種情況下,這種拷貝是否多餘?函數返回後,v1 就要被解構掉了,它堆上的空間卻沒法為 v2 所複用,顯然這裡是有優化空間的。
有移動語意後,這種場景下,移動操作的做法是通過指標操作直接將 v1 的堆上空間移交給 v2,從而實現 v1 堆上空間的複用。
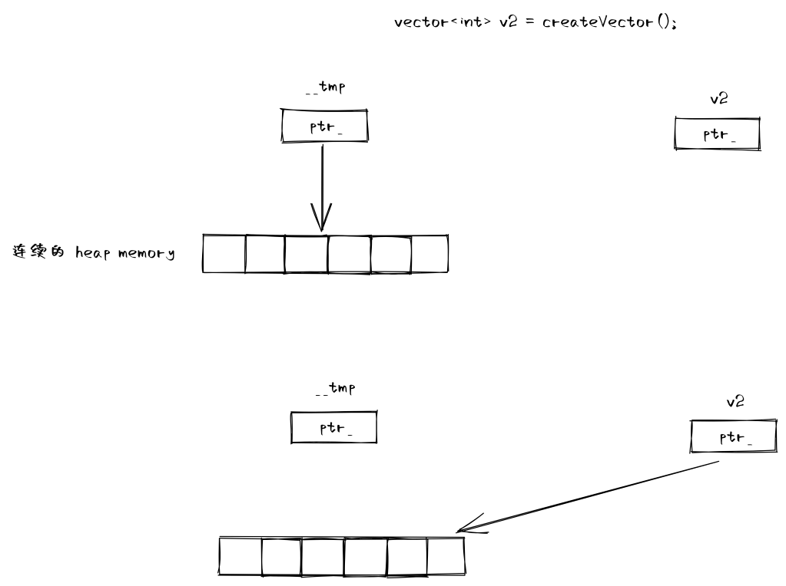
綜上所述,移動語意允許我們以一種更輕量級的(相較於拷貝)形式實現物件資源的複用。
什麼是移動語意?
從上面的例子可以看出,事實上移動操作移動的並不是物件,移動結束後,v1 仍然存在於 createVector() 的棧上,它並沒有被 「移動」 到呼叫者的棧上去(可以和 NRVO 優化做比較),被移動的是堆上的空間,也就是 v1 所持有的資源。因此,移動語意移動的是物件所持有的資源,而不是物件本身。
如果你有看過 unique_ptr 和 auto_ptr 的實現,就會發現用拷貝去模擬資源的移交是非常困難的,auto_ptr 正是標準庫在這方面的失敗嘗試,而 unique_ptr 改為用移動操作去模擬資源移交,實現的就比較正確和優雅。
什麼樣的物件是可以被移動的?
瞭解了移動語意的基本概念,那麼擺在我們面前的一個問題就是:什麼樣的物件是可以被移動的?總的來說,一個物件要被移動,要滿足如下要求:
- 該物件將要被銷燬;
- 該物件沒有任何使用者;
- 可以自由接管該物件所持有的資源
為了表達這種概念,C++ 修改了左值和右值的定義,在 C 語言中,左值和右值即字面意思,左值是表示式左邊的值,而右值是表示式右邊的值。而 C++ 為了支撐移動語意,對值的型別做了新的劃分。
區分左值和右值
C++ 中值有兩個獨立的屬性:
- 有身份(has identity)
- 或者說,有地址,有指向它的指標
- 有身份的值統稱為 glvalue ("generalized" lvalue)
- 可以被移動(can be moved from)
- 可以移動的值統稱為 rvalue
glvalue 和 rvalue 就是我們一般說的左值和右值。
根據是否有這兩種屬性,我們可以對 C++ 中的值做如下劃分(i 表示有身份,m 表示可以被移動,大寫字母表示沒有這種屬性,第四種型別 IM 在 C++中沒有被使用):
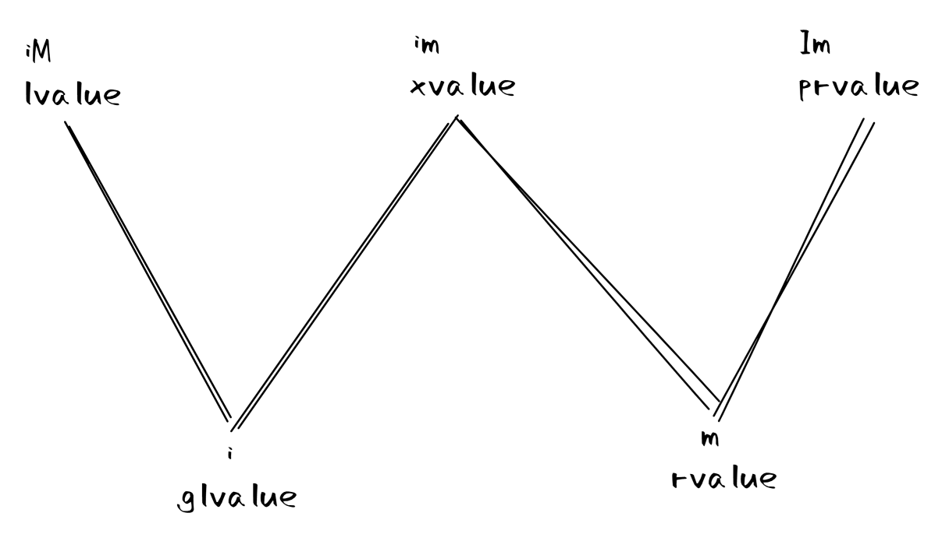
- lvalue( iM )
- 有身份,且不能被移動
- 包括
- 變數、函數或資料成員的名字
- 返回左值參照的表示式,比如
++x、x = 1 - 字串字面量,如
"hello world"
- prvalue("pure" rvalue, Im)
- 一般譯作純右值
- 沒有身份,可以被移動,也就是所謂的「臨時物件」
- 包括
- 返回非參照型別的表示式,比如
x++、x + 1 - 除字串字面量之外的字面量,比如
42、true
- 返回非參照型別的表示式,比如
- 有趣的是 this 指標是 prvalue,你會發現沒法對 this 指標求地址
- xvalue(an "eXpiring" value, im)
- 一般譯作將亡值
- 有身份,且可以被移動
- 包括
- 右值參照型別的返回值,比如
std::move(x)
- 右值參照型別的返回值,比如
雖然說,C++ 對值做了很細粒度的劃分,但事實上,大多數時候只需要區分一個值是左值還是右值即可,因此,這裡給出一個實踐上可以用來區分左右值的法則:
- 如果你可以對某個表示式取地址,那麼它是左值
- 如果一個表示式的型別是左值參照( T& 或 const T& 等),那麼它是左值
- 否則,這個表示式是右值
- 函數的返回值(非參照型別的或右值參照型別的)
- 通過隱式型別轉換建立的值
- 除字串以外的字面量(比如 10 和 5.3)
我們來看一些例子,看看如何實踐上述的法則以區分左值右值:
Widget&& var1 = someWidget;
auto&& var2 = var1;
可以對 var1 取地址,所以 var1 是左值,這點其實比較反直覺,雖然 var1 是右值參照,但其實它是左值。
std::vector<int> v;
auto&& val = v[0];
由於v[0]是左值參照,因此它是左值。
template<typename T>
void f(T&& param);
f(10);
非字串字面量 10 是右值。
右值參照
伴隨著新的右值定義,C++11 也引入了一種新的參照型別——右值參照,比如 int &&,右值參照的特點是它只能繫結到右值上,因此 C++11 中也就有了三種參照型別:
- 右值參照只能繫結到右值上,比如
int && - 非 const 的左值參照只能繫結到左值上,比如
int & - const 的左值參照可以繫結到左值或右值上,比如
const int &
新的特殊成員函數
為了支援移動語意,C++11 參照兩個新的特殊成員函數,它們是移動建構函式和移動賦值運運算元,想要支援移動操作的類必須定義它們。
class Widget {
private:
int i{0};
string s{};
unique_ptr<int> pi{};
public:
// Move constructor
Widget(Widget &&w) = default;
// Move assignment operator
Widget &operator=(Widget &&w) = default;
};
移動建構函式
移動建構函式的任務
- 完成資源移動
- 資源的所有權移交給新建立的物件
- 確保移動操作完成後,銷燬源物件是無害的
- 不再指向被移動的資源
- 確保移動操作完成後,源物件依然是有效的
- 可以賦予它一個新值
- 對留下的值沒有任何要求
也就是說移動操作完成後,可以銷燬移後源物件,也可以賦予它一個新值,但不能使用移後源物件的值。
移動操作和異常安全
- 移動操作一般不分配新資源,因此不會丟擲異常
- 如果移動操作不拋異常,必須註明
noexcept
如果你的移動操作不註明 noexcept ,標準庫就不敢呼叫你的移動建構函式,這是由於標準庫的某些介面會做出異常安全的保障,比如 vector 的 push_back 介面做出的保證為:
If an exception is thrown (which can be due to Allocator::allocate() or element copy/move constructor/assignment), this function has no effect (strong exception guarantee).
也就是說有異常丟擲時(可能是由於記憶體分配或元素拷貝/移動),這個呼叫不產生任何效果。
push_back 可能會導致 vector 擴容,也就是說會申請一塊新的記憶體空間,將現有的元素拷貝/移動到這塊新的空間裡。
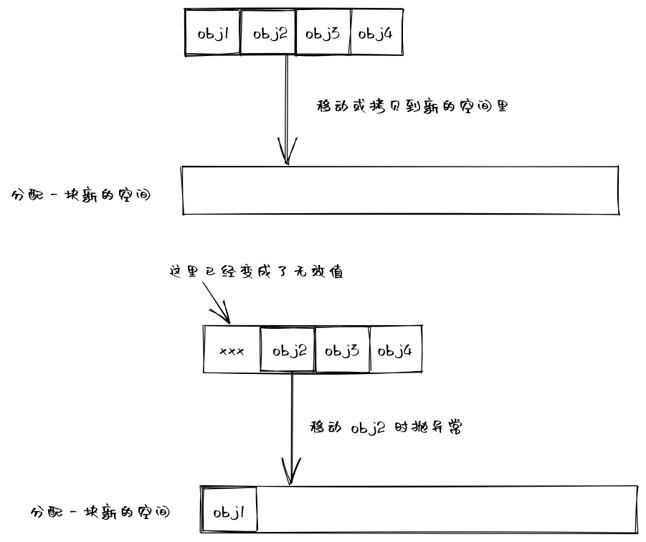
如果我們的移動建構函式會拋異常,假設擴容的過程中,只有部分元素被移動到了新的空間裡,這時候有異常丟擲,不僅擴容操作沒完成,而且原有空間裡的部分元素還被已執行的移動操作破壞掉了,不符合 push_back 做出的異常保障。因此,這種情況下,vector 只會使用拷貝操作來完成擴容操作。
移動操作和函數匹配
- 移動右值,拷貝左值
- 移動建構函式只能用於實參是右值的情況下,其他情況下,都會發生拷貝
- 但如果沒有移動建構函式,則右值也被拷貝
- 拷貝建構函式的引數是 const 的左值參照,既能接受左值也能接受右值
移動賦值運運算元
定義移動賦值運運算元最簡單的方法就是定義一個「拷貝並交換」的拷貝賦值運運算元(如果你在疑惑該怎樣自定義 swap 操作,請看 Effective C++ Item 25):
ClassA& ClassA::operator=(ClassA rhs)
{
swap(*this, rhs);
return *this;
}
「拷貝並交換」賦值運運算元的引數不再是參照,而是傳值
- rhs 將是右側運算物件的一個副本;
- 將
*this與這個副本交換,也就是將右側運算物件的值賦給了左側運算物件; - 函數返回時,rhs 被銷燬,解構函式銷燬 rhs 現在指向的記憶體,即左側運算物件原來的記憶體。
「拷貝並交換」的優勢是正確處理了自賦值而且是異常安全的。
賦值運運算元的異常安全問題主要來自於拷貝時可能申請記憶體,如果 new 拋異常了,要確保左側運算物件原本的資料結構還沒有被破壞(顯然, rhs 做拷貝的時候,左側運算物件原有資料結構還沒有做任何修改)。
如果你定義了移動建構函式,那麼這個拷貝賦值運運算元同時也是移動賦值運運算元:
- 如果實參是右值,就會用移動建構函式來初始化 rhs;
- 相反,如果實參是左值,就會用拷貝建構函式來初始化 rhs
何時該定義移動構造/賦值
the rule of zero
C.20: If you can avoid defining default operations, do
也就是說,如果預設行為夠用,就不要再去定義自己的特殊成員函數。
struct Named_map {
public:
// ... no default operations declared ...
private:
string name;
map<int, int> rep;
};
Named_map nm; // default construct
Named_map nm2 {nm}; // copy construct
map 和 string 定義了所有的特殊成員函數,編譯器生成的預設實現就已經夠用了。
the rule of five
C.21: If you define or =delete any copy, move, or destructor function, define or =delete them all
如果定義拷貝、移動或解構中的任意一個,或將任意一個宣告為 =delete 的;那麼就需要將它們都定義出來或全部宣告為 =delete 的。
實踐 the rule of five 時,最簡單的判斷方法就是看解構函式,如果你解構函式裡要做事,不管是釋放資源還是關閉資料庫連線,那麼你就應該把解構函式的這些好兄弟都定義出來。
定義這些特殊成員時,如果你想要預設實現,就將它宣告為 =default;如果你想要禁用某個特殊成員,就將它宣告為 =delete(這兩種情況都被編譯器認為是使用者定義的)。
the rule of five 背後的邏輯是這些特殊成員函數的語意是息息相關的:
- 規則 1:如果某個類有自定義拷貝建構函式、拷貝賦值運運算元或者解構函式,編譯器就不會為它合成移動建構函式和移動賦值運運算元了
- 根據函數匹配規則,這種情況下會呼叫拷貝操作來處理右值
- 規則 2:如果某個類定義了移動建構函式,沒有定義拷貝建構函式,那麼後者被編譯器定義為刪除的(對於賦值運運算元也是一樣的)
如果定義了這些操作中的某一個,就應該把其他的操作都定義出來,以避免所有(潛在的)可移動的場景都變成昂貴的拷貝(對應規則 1)或者使得型別變成僅能移動的(對應規則 2)。
struct M2 { // bad: incomplete set of copy/move/destructor operations
public:
// ...
// ... no copy or move operations ...
~M2() { delete[] rep; }
private:
pair<int, int>* rep; // zero-terminated set of pairs
};
void use()
{
M2 x;
M2 y;
// ...
x = y; // the default assignment
// ...
}
這段程式碼沒能遵循 the rule of five,造成的後果是 rep 被 double free。
std::move 和 std::forward
本章的內容涉及通用參照,可以看我的部落格通用參照,裡面有這方面的介紹。
雖然這兩個函數的名字很有迷惑性,但事實上,從它們所做的事情上來看:move 不移動;forward 不轉發,它們只是執行了型別轉換操作罷了:
- std::move 無條件地將實參轉換為右值;
- std::forward 在部分條件下將實參轉換為右值
熟悉 C++ 型別轉換的朋友應該知道 static_cast 事實上在執行時什麼也不做,因此這倆函數也並不會在執行時做什麼事情。
std::move
一個簡化的 move 實現是這樣的:
template <typename T> typename remove_reference<T>::type &&move(T &¶m) {
using ReturnType = typename remove_reference<T>::type &&;
return static_cast<ReturnType>(param);
}
T&& 是通用參照,因此這個函數幾乎可以接收任何型別的引數。
通過 remove_reference 去掉 T 的參照性質(並不會去掉 cv 限定符),然後給它加上 &&,形成 ReturnType 型別,由於右值參照型別的返回值是右值,因此結果是實參被無條件地轉換為右值。
為什麼要使用 std::move?
既然 std::move 只是無條件地做 static_cast,那為什麼不直接做型別轉換,而要呼叫 std::move 呢?
std::move 允許我們截斷左值,也就是說不再使用該左值,可以自由移動它所擁有的資源;這是非常特殊的型別操作,通過使用 std::move 方便我們確定在哪裡對左值做了截斷,語意上更加清晰。
使用 std::move 並不代表移動操作一定會發生
- 可能這個型別根本沒有定義移動操作
- std::move 並不會去除實參的 const 性質,因此把 const 的物件傳給它,得到的返回值型別也是 const 的,對它的操作會變為拷貝操作
- 因為移動操作往往會修改源物件,所以我們不希望在 const 物件上觸發移動操作
std::forward 和完美轉發
某些函數需要將其一個或多個實參連同型別不變地轉發給其他函數,轉發後需要保持被轉發實參的所有性質,包括
- 實參是否是 const 的;
- 實參是左值還是右值
這種場景我們往往稱之為完美轉發,C++11 可以通過 std::forward 來實現。
比如工廠函數需要將初始化引數傳遞給建構函式。一個常見的例子就是 make_unique C++14 才支援,如果我們想自己寫一個 make_unique 應該怎麼寫呢?
template <typename T, typename... Ts>
std::unique_ptr<T> make_unique(Ts &&... params) {
return std::unique_ptr<T>(new T(std::forward<Ts>(params)...));
}
std::forward 的實現
template< class T >
T&& forward( typename std::remove_reference<T>::type& t ) noexcept {
return static_cast<T&&>(param);
}
template< class T >
T&& forward( typename std::remove_reference<T>::type&& t ) noexcept {
return static_cast<T&&>(param);
}
std::forward 的模板引數是沒法推導的,稱為無法推導的上下文(nondeduced context)。
理解這個實現的重點在於它的返回值型別是 T&&,我們看一個例子:
void g(int &&i, int& j);
template <typename F, typename T1, typename T2>
void flip3(F f, T1 &&t1, T2 &&t2)
{
f(std::forward<T2>(t2), std::forward<T1>(t1));
}
flip3(g, i, 42);
flip3 接受一個可呼叫物件,以及兩個額外實參,將引數逆序傳遞給可呼叫物件。
- 如果實參是 int 變數 i
- T1 的型別為
int&,std::forward 的返回型別為int& &&,根據參照摺疊,結果是int& - t1 的型別為
int& - 引數的型別和返回值的型別相同,所以轉換不會做任何事
- T1 的型別為
- 而如果實參是 42
- T2 的型別為
int,std::forward 的返回型別是int && - t2 的型別為
int && - 從函數返回的右值參照是右值,所以 t2 會被轉換為右值
- T2 的型別為
就此,我們也理解了為什麼說 forward 是有條件地將實參轉換為右值。
怎麼判斷該用 move 還是 forward?
- 對右值參照 move
- 右值參照只能繫結到右值上,所以可以無條件地將它轉換為右值
- 對通用參照 forward
- 通用參照既能繫結到左值上,也能繫結到右值上,在後一種情況下,我們希望能將它轉換為右值
在右值參照上呼叫 std::forward 表現出的行為是正確的,但由於 std::forward 沒法自動做型別推導,寫出來的程式碼會比較繁瑣;但如果在通用參照上呼叫 std::move,可能會導致左值被錯誤地修改,導致異常的行為。
什麼時候用 move 和 forward?
你可能需要在函數中多次使用某個右值參照或通用參照,那麼只有在最後一次使用它的時候,才可以對它調 std::move 或 std::forward,因為將它轉為右值後,它的內容就不能再被使用了。
void sink(X&& x); // sink takes ownership of x
void user()
{
X x;
// error: cannot bind an lvalue to a rvalue reference
sink(x);
// OK: sink takes the contents of x, x must now be assumed to be empty
sink(std::move(x));
// ...
// probably a mistake
use(x);
}
名字查詢和 move、forward
std::move 和 std::forward 的形參都是通用參照,它們幾乎可以匹配任何型別的引數。
因此如果我們定義了自己的 move 或 forward 函數,如果它接受單一形參,不管型別如何,都將與標準庫的版本衝突。
同時,move 和 forward 執行的是非常特殊的型別操作,使用者特意去修改函數原有行為的概率非常小,因此最好使用帶限定語的版本 std::move 和 std::forward 來明確指出使用標準庫的版本。
移動和返回值優化
RVO
如果 return 語句的運算元是 prvalue ,且它和返回值的型別相同。
T f() {
return T();
}
f(); // only one call to default constructor of T
此時,編譯器可以實施 copy elision(拷貝省略、拷貝消除),將物件直接構造到呼叫者的棧上去。
return 語句所在的地方,T 的解構函式必須是可存取的且沒有被刪除,儘管此處並沒有 T 物件被解構掉。
C++17 強制編譯器做 RVO,RVO 不再是一項可選的編譯器優化,而是 C++ 對 prvalue 的新規定,即返回和使用 prvalue 時不再去實體化一個臨時物件
NRVO
X bar()
{
X xx;
// process xx ...
return xx;
}
對於上面的函數 bar,如果直接用引數 __result 代替命名的返回值 xx,即改寫為:
void
bar( X &__result )
{
// default constructor invocation
// Pseudo C++ Code
__result.X::X();
// ... process in __result directly
return;
}
也就是說返回值會被直接構造在呼叫者的棧上,少了一次拷貝操作,這種優化被稱為 Named Return Value Optimization(NRVO)。
移動和 NRVO
C++11 開始,NRVO 仍可以發生,但在沒有 NRVO 的情況下,編譯器將試圖把本地物件移動出去,而不是拷貝出去。
這一移動行為不需要程式設計師手工用 std::move 進行干預,使用 std::move 對於移動行為沒有幫助,反而會影響返回值優化,因為這種情況下,你返回的並不是區域性物件,而是區域性物件的參照。
參考資料
本文來自部落格園,作者:路過的摸魚俠,轉載請註明原文連結:https://www.cnblogs.com/ljx-null/p/16512384.html