【機器學習基礎】無監督學習(5)——生成模型
前面無監督學習主要針對的是一種「降維」的學習任務,將資料降維到另一個能夠表達資料含義的某種空間中,本節主要是無監督學習中的另一個任務——生成進行介紹。
生成模型
0.生成模型介紹
通常生成模型是指學習樣本資料的分佈,可以生成一些新的資料,是相對於判別模型而言的,並不特指有監督學習和無監督學習,比如樸素貝葉斯模型就是一種生成模型。
在這裡生成模型主要指的是無監督學習中的生成模型,在無監督學習中的主要任務是讓機器學習給定的樣本,然後生成一些新的東西出來。比如:

給機器看一些圖片,能夠生成一些新的圖片出來,給機器讀一些詩,然後能夠自己寫詩出來。
在前面所學習的無監督學習主要是針對降維的,成為化繁為簡,那麼在這裡的生成模型則稱之為無中生有。
有三種常見的生成模型:
1、Component-by-Component
2、AutoEncoder
3、Generative Adversarial NetWork(GAN)
下面就對這三種方法進行簡單的介紹,這裡還是主要介紹其大致概念,後面深度學習會具體展開討論。
1.Component-by-Component
這種方法類似於前面說的Predicted-based的方法,即根據前面的來預測後面的。比如一張3*3大小的圖片:
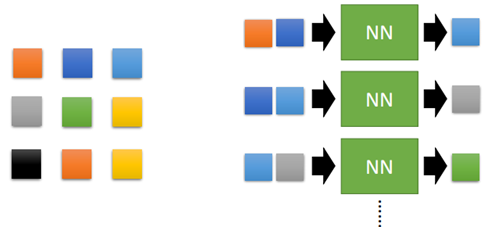
我們希望有一個網路,輸入相鄰的兩個畫素,然後輸出下一個畫素。通過大量的圖片來訓練網路,然後給定一個初始的畫素,就可以生成一張新的圖片出來。
又或者通過閱讀大量的文章,然後輸出一張新的文章出來。
這個任務也稱作Seq2Seq的學習任務,其網路主要用的就是RNN。後面到深度學習部分會對RNN再進行了解。這裡先舉個簡單的例子:讓機器自己創造一些寶可夢出來。
通過大量的寶可夢的圖片訓練一個網路,然後讓這個網路生成一些圖片出來,如圖:

在測試時,首先拿一些真實的寶可夢的圖片,然後蓋住一部分,比如蓋住50%,讓機器生成這50%的圖片,可以得到如右圖所示的結果(並非對應關係)。
2.AutoEncoder
2.1 Review AutoEncoder
在前面說過AutoEncoder的基本概念,即通過encoder對資料的降維,而在生成模型中,decoder則可以用來生成新的資料出來。
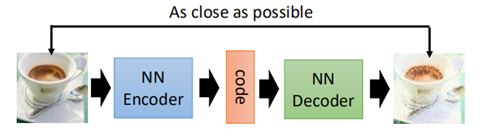
當把AutoEncoder的網路層數增加時,就變成了deep AutoEncoder。通過給定一個code,然後輸入到decoder中,就會產生新的image出來。
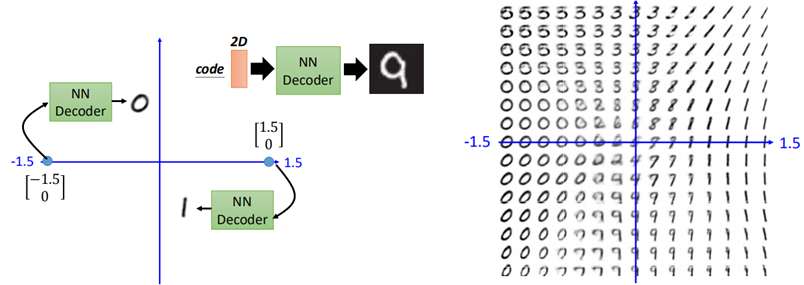
比如在手寫識別中,資料降到2維後,給定一個二維code,則可以生成一張手寫數位出來。
然而在實際中,通常對於未知的code,我們並不能保證所給的code與產生的圖片屬於同一個分佈,這也就可能會導致當給一個code時,所生成的圖片是一個「四不像」,與預期不符。
比如對於月球圖片的學習,將圖片降到1維(中間紅色的線),然後再decode回去,如圖:
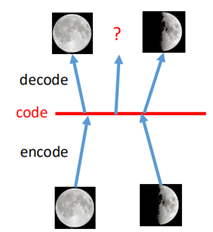
假設兩邊的狀態一個是滿月一個是新月,我們想要中間找個點,得到弦月的圖片,然而當我們在中間的位置任意找一個code輸入到decoder進去時,並不一定能保證得到的是弦月。
也就是說我們無法真正的構造出code,我們並不知道code來自於哪個分佈,因此為解決這一問題,需要變分自編碼器(VAE)。
2.2 VAE簡介
VAE在進行圖片還原時,要保證code與decoder的輸出服從一定的分佈,所以V的意思代表Variational。換句話說,就是在生成code的時候我們限制這些code服從一定的分佈。
VAE的直觀理解是,在生成的code上加上一些「噪音」,如圖:
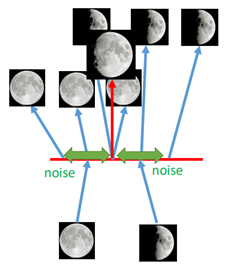
在生成的code上面加上噪音,例如滿月的圖片生成code之後,在其周圍加上噪音之後,那麼在噪音範圍內所生成的圖片都是滿月的圖片,同理新月也是。
當我們在滿月和新月的code的中間取一點時(紅色的箭頭),此時相當於對新月和滿月進行一個加權,從而生成了弦月。
上面就是VAE的直觀的解釋,那麼通常這個code的「噪聲」是如何加呢?又為什麼這麼加,下面就是VAE的網路結構和原理:
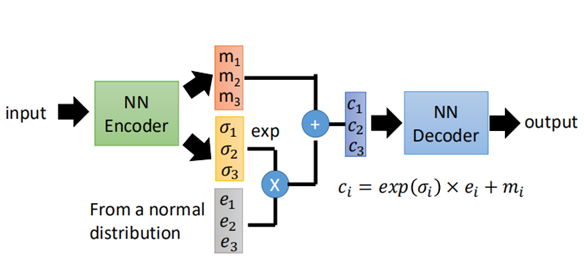
可以看到code的部分變成了ci的樣子,其中m是原來的code,σ是噪音分佈的方差,是自己學出來的,取exp是為了保證學習的時候是一個正值,e是一個正態分佈,從而得到新的code。
然而僅僅在code上加noise是不夠的,在訓練時,我們希望recontruction error越小越好,那麼在訓練時,會偏向於將σ學成0,因為當σ=0時,損失就越小。
因此在訓練時要加上一項:
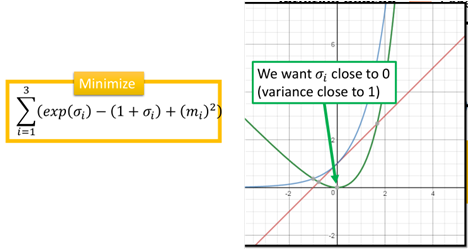
exp(σ)為藍色的線,(1+σ)為紅色的線,二者相減則為綠色的線,最小化這一項,則使得σi在0附近,再取exp,那麼varaice則趨向於1,最後一項m的平方則可以看做是L2正則化。
因此VAE在訓練時是重構誤差加上上邊那一項。
上邊是VAE的做法和直觀的理解,對於VAE的原理和推導稍微有點複雜,這裡簡單總結一下:
首先在高斯混合模型中,樣本x的分佈可以用有限個高斯分佈組合而成的:
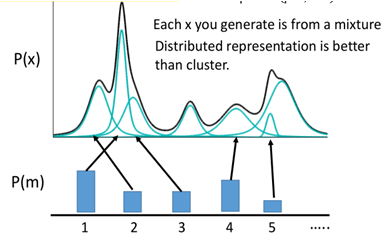
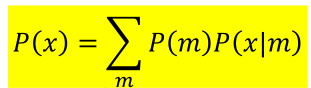
假設樣本由M個混合高斯模型所組成的,x從其中一個高斯分佈m而來,那麼產生x的概率p(x) =p(m)*p(x|m),總體的分佈則為:
那麼現在我們在訓練時限制住x降維後所產生的code服從一定的標準正態分佈z~N(0,I),那麼:
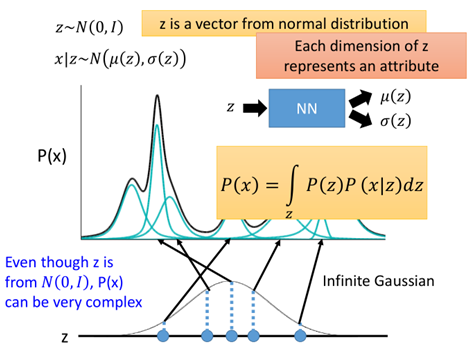
這裡z就是降維後的code,其每一維代表一個屬性,不同的是這裡的高斯混合模型相當於有無限個高斯模型,因此是積分的形式。
隨機出來一個z,得到z的均值和方差,就可以得到一個x,我們希望有這樣一個function,輸入z,輸出為z的均值和方差:
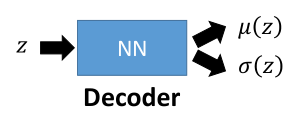
這也就是decoder,同樣,需要藉助一個分佈q(z|x),其含義是給一個x,其在z這個空間中的分佈,也就是給一個x,在z空間中的均值和方差,從而sample出一個z。其做的事剛好是跟上面的相反的。

這就是encoder。
根據所給定的樣本x,根據極大似然估計:
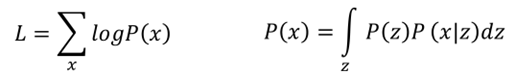
我們需要最大化上面的式子L,接下來就是一系列的推導:

然後就變成了最大化Lower bound,進一步:
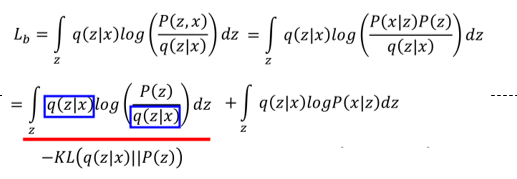
至此訓練變成了最大化這兩項,其中前一項可以表示為P(z)和q(z|x)的散度的負數,最大化這一項即是最小化二者的KL散度。
這一項的含義就是保證z(也就是降維的code)的分佈要儘量與x在z空間中的分佈保持一致。這也就限制了在降維後要保持一定的分佈,那麼在sample時我們可以從該分佈中來生成一些樣本。這也是VAE的精神所在。
而後一項就是使得z生成的x要與原來的x越接近越好,這與原來的autoencoder是一致的。
2.3 VAE的問題
VAE雖然能夠比較容易地產生一些資料,但其實VAE並沒有學會如何真正的去生成一些新的事物,而是一直在模仿,希望儘可能地接近已知樣本。比如:
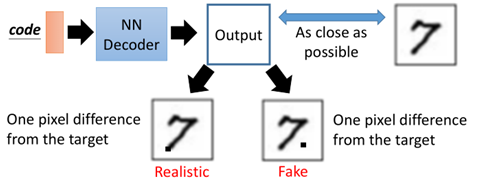
對於生成的兩張圖片「7」,第一張顯然對於我們來說是可以接受的,而第二種是不可接受的,然而對於VAE來說,二者具有相同的損失(重構誤差)。同時通過實驗可以看出,VAE生成的圖片一般比較「糊」,這是因為autoencoder在生成圖片時,每一個pixel是獨立的,它並沒有考慮相互之間的關係(大局觀)。
這時就需要另一個生成模型登場了——GAN。
2.4 VAE的實現
在介紹GAN之前,先來做個VAE的demo,前面簡單對autoencoder進行了簡單的實現,這裡順便就做一下VAE,程式碼沒有封裝,只是VAE的實現過程,便於理解本部分內容,以手寫數位識別為例。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
# 讀取資料
mnist = input_data.read_data_sets('/MNIST_data', one_hot=True)
# 輸入預留位置,因為是無監督學習,所以只需要x
x = tf.placeholder(tf.float32, [None, 784])
# 定義變數從輸入層到隱藏層的w,b,隱藏層假設有100個節點
encode_w = tf.Variable(tf.truncated_normal([784, 100], stddev=0.01))
encode_b = tf.Variable(tf.zeros([100]))
# 定義隱藏層到輸出m那一層的權重w,假設降維到128維
encode_mean_w = tf.Variable(tf.truncated_normal([100, 128], stddev=0.01))
# 定義隱藏層到輸出的variance的權重
encode_var_w = tf.Variable(tf.truncated_normal([100, 128], stddev=0.01))
# code到輸出層的w和b
decode_w = tf.Variable(tf.truncated_normal([128, 784], stddev=0.01))
decode_b = tf.Variable(tf.zeros([784]))
# 隱藏層輸出
encode_output = tf.nn.relu(tf.matmul(x, encode_w) + encode_b)
# 求解mean和variance
encode_mean = tf.matmul(encode_output, encode_mean_w)
encode_var = tf.matmul(encode_output, encode_var_w)
# 加上一個random normal
E = tf.random_normal([1, 128])
# 降維後的資料 m + exp(var) * E
code = tf.add(tf.exp(encode_var)*E, encode_mean)
# decoder,把code解回原資料784維
decode_output = tf.nn.relu(tf.matmul(code, decode_w) + decode_b)
# loss,原來的重構誤差
decode_loss = tf.reduce_mean((decode_output - x) ** 2)
# 加上另一項誤差
encode_loss = tf.reduce_mean(tf.exp(encode_var) - (1 + encode_var) + encode_mean ** 2)
loss = tf.add(decode_loss, encode_loss)
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# tf.reset_default_graph()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(10000):
# total_num = int(mnist.train.num_examples/100)
# for i in range(total_num):
xs, ys = mnist.train.next_batch(100)
_, loss_ = sess.run([optimizer, loss], feed_dict={x: xs})
if epoch % 100 == 0:
print('epoch:', epoch, 'loss:', loss_)
# test
I_test = tf.truncated_normal(shape=[1, 128], stddev=0.00001)
decode_output_test = tf.nn.relu(tf.matmul(I_test, decode_w) + decode_b)
decode_output_test_data = sess.run([decode_output_test])
test_img = np.reshape(decode_output_test_data, [28, 28])
plt.imshow(test_img, cmap='gray')
plt.pause(0.1)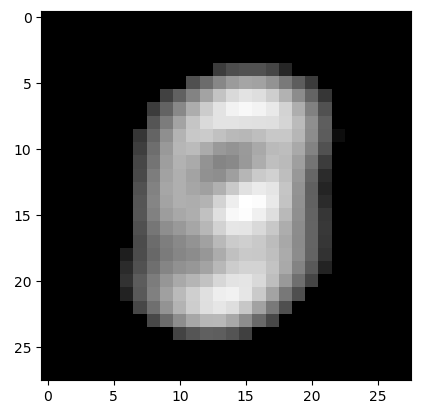
可以看到隨著訓練的次數增加,生成的圖片也越來越「清晰」,隱約可以看到「9」的形狀,一方面是因為沒有對模型中的引數進行調節,加上模型較為簡單,特徵提取不完整。另一方面也是前面說的VAE本身的問題。
接下來結合CNN,經過折積之後再對圖片進行降維,利用VAE進行降維和還原:
# 這裡首先定義一個max_pool函數,返回的經過max_pool之後的圖片和所對應的索引
def max_pool_with_argmax(net, stride):
_, mask = tf.nn.max_pool_with_argmax(net, ksize=[1, stride, stride, 1], strides=[1, stride, stride, 1], padding='SAME')
mask = tf.stop_gradient(mask)
net = tf.nn.max_pool(net, ksize=[1, stride, stride, 1], strides=[1, stride, stride, 1], padding='SAME')
return net, mask
# 根據max_pool的索引進行反池化的操作,原理在前面CNN部分已經說過
def unpool(net, mask, stride):
ksize = [1, stride, stride, 1]
input_shape = net.get_shape().as_list()
output_shape = (input_shape[0], input_shape[1] * ksize[1], input_shape[2] * ksize[2], input_shape[3])
one_like_mask = tf.ones_like(mask)
batch_range = tf.reshape(tf.range(output_shape[0], dtype=tf.int64), shape=[input_shape[0], 1, 1, 1])
b = one_like_mask * batch_range
y = mask // (output_shape[2] * output_shape[3])
x = mask % (output_shape[2] * output_shape[3]) // output_shape[3]
feature_range = tf.range(output_shape[3], dtype=tf.int64)
f = one_like_mask * feature_range
updates_size = tf.size(net)
indices = tf.transpose(tf.reshape(tf.stack([b, y, x, f]), [4, updates_size]))
values = tf.reshape(net, [updates_size])
ret = tf.scatter_nd(indices, values, output_shape)
return ret
x = tf.placeholder(tf.float32, [100, 28, 28, 1])
w_conv1 = tf.Variable(tf.truncated_normal([3, 3, 1, 64], stddev=0.01))
b_conv1 = tf.constant(0.1, shape=[64])
conv1 = tf.nn.relu(tf.nn.conv2d(x, w_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1)
pool1, mask1 = max_pool_with_argmax(conv1, 2)
w_conv2 = tf.Variable(tf.truncated_normal([3, 3, 64, 10], stddev=0.01))
b_conv2 = tf.constant(0.1, shape=[10])
conv2 = tf.nn.relu(tf.nn.conv2d(pool1, w_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
pool2, mask2 = max_pool_with_argmax(conv2, 2)
# pool2 = tf.nn.max_pool2d(conv2, ksize=[1, 3, 3, 1], strides=[1, 3, 3, 1], padding='SAME')
conv_out = tf.reshape(pool2, [-1, 490])
encode_w = tf.Variable(tf.truncated_normal([490, 100]))
encode_b = tf.Variable(tf.constant(0.1, shape=[100]))
encode_output = tf.add(tf.matmul(conv_out, encode_w), encode_b)
encode_mean_w = tf.Variable(tf.truncated_normal([100, 128], stddev=0.01))
encode_var_w = tf.Variable(tf.truncated_normal([100, 128], stddev=0.01))
encode_mean = tf.matmul(encode_output, encode_mean_w)
encode_var = tf.matmul(encode_output, encode_var_w)
E = tf.random_normal([1, 128])
code = tf.add(tf.exp(encode_var) * E, encode_mean)
# decoder
decode_w = tf.Variable(tf.truncated_normal([128, 490], stddev=0.01))
decode_b = tf.Variable(tf.constant(0.1, shape=[490]))
decode_output = tf.nn.relu(tf.add(tf.matmul(code, decode_w), decode_b))
decode_output = tf.reshape(decode_output, [-1, 7, 7, 10])
t_conv2 = unpool(decode_output, mask2, 2)
t_pool1 = tf.nn.conv2d_transpose(t_conv2 - b_conv2, w_conv2, pool1.shape, [1, 1, 1, 1])
t_conv1 = unpool(t_pool1, mask1, 2)
pre_output = tf.nn.conv2d_transpose(t_conv1-b_conv1, w_conv1, x.shape, [1, 1, 1, 1])
decode_loss = tf.reduce_mean((pre_output - x) ** 2)
encode_loss = tf.reduce_mean(tf.exp(encode_var) - (1 + encode_var) + encode_mean ** 2)
loss = tf.add(decode_loss, encode_loss)
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(10000):
# total_num = int(mnist.train.num_examples/100)
# for i in range(total_num):
xs, ys = mnist.train.next_batch(100)
xs = np.reshape(xs, [-1, 28, 28, 1])
_, loss_ = sess.run([optimizer, loss], feed_dict={x: xs})
if epoch % 100 == 0:
print('epoch:', epoch, 'loss:', loss_)
# test
# 這裡就有一個問題,在隨機給定一個code時,在進行反池化操作時mask的選擇不能用原來的訓練的mask了。
I_test = tf.truncated_normal(shape=[1, 128], stddev=0.01)
decode_output_test = tf.nn.relu(tf.add(tf.matmul(I_test, decode_w), decode_b))
decode_output_test = tf.reshape(decode_output_test, [-1, 7, 7, 10])
mask2_test = tf.reshape(mask2[0], [-1, 7, 7, 10])
t_conv2_test = unpool(decode_output_test, mask2_test, 2)
t_pool1_test = tf.nn.conv2d_transpose(t_conv2_test - b_conv2, w_conv2, [1, 14, 14, 64], [1, 1, 1, 1])
mask1_test = tf.reshape(mask1[0], [-1, 14, 14, 64])
t_conv1_test = unpool(t_pool1_test, mask1_test, 2)
pre_output_test = tf.nn.conv2d_transpose(t_conv1_test - b_conv1, w_conv1, [1, 28, 28, 1], [1, 1, 1, 1])
decode_output_test_data = sess.run([pre_output_test], feed_dict={x: xs})
test_img = np.reshape(decode_output_test_data, [28, 28])
plt.imshow(test_img, cmap='gray')
plt.pause(0.1)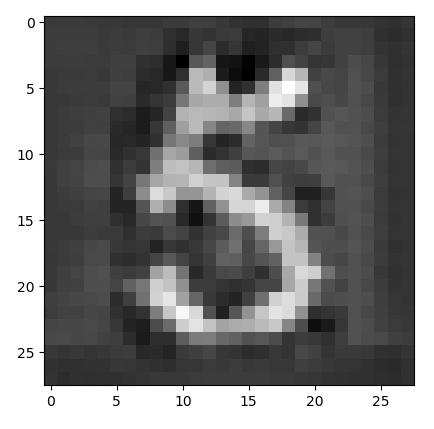
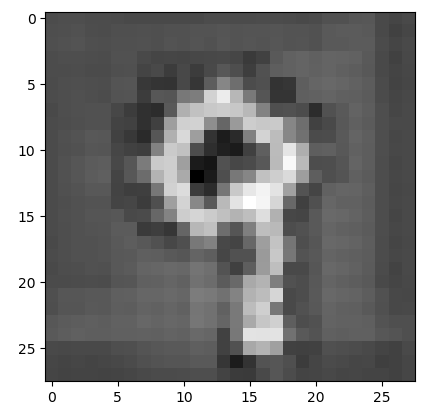
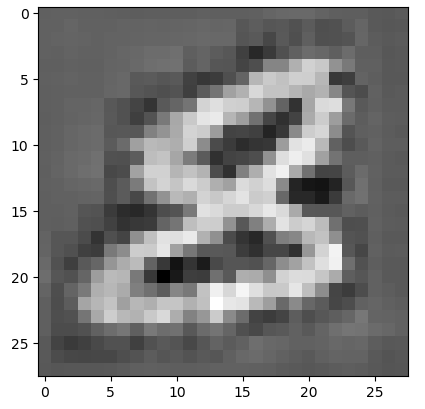
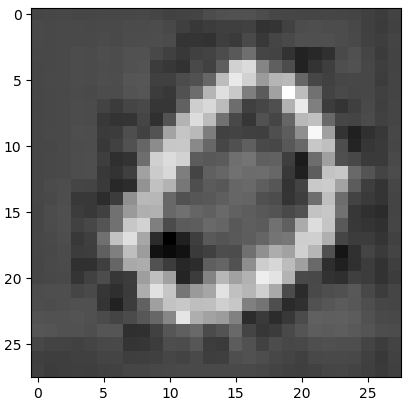
可以看出上面生成的一些圖片相比於之前的VAE更加清晰了,也比較像數位了,但其中有個問題就是程式碼中註釋的那樣,有的一般只做折積,不做池化,關於池化後再test時如何生成,下去再思考。
3. GAN簡介
Genrative Advesarial Networl(GAN)是機器學習中一個耳熟能詳的演演算法,隨著時間的發展,GAN也從原始的演演算法進化了更多的版本,這裡就先對GAN進行簡要的介紹,後面會單獨開一節來介紹GAN及其變種演演算法。
GAN全名叫做生成對抗網路,顧名思義,就是在不斷地生成和對抗中進行成長學習。舉一個例子:
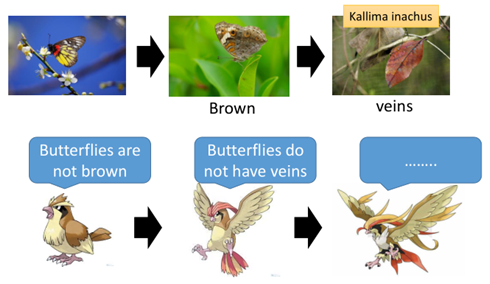
圖中是枯葉蝶,其天敵是一種鳥類,在最開始時,枯葉蝶可能就是普通的蝴蝶,而這種鳥靠捕食蝴蝶為食,這種鳥認為蝴蝶不是棕色的,因此,蝴蝶進化成棕色的騙過第一代的鳥,而鳥類也在進化,進化成第二代,可以辨別蝴蝶是沒有葉脈的,因此蝴蝶進一步進化成枯葉蝶。這其實就是一種對抗生成。
那麼在實際的機器學中,對抗生成網路有兩個部分組成,一個是Generator,另一個是Discriminator,二者在不斷進行生成與對抗,稱為亦師亦友的關係。在圖片生成中:
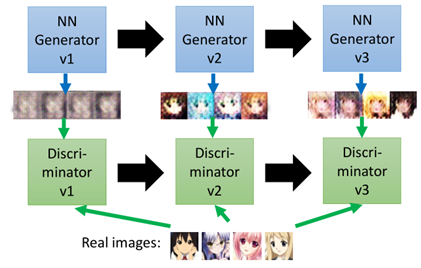
第一代的Generator所及生成一些圖片,給到第一代的Discriminator識別,其認為都是假的圖片,
然後Generator進化到第二代,此時第二代所產生的的圖片能夠騙過第一代的Discriminator,單後Discriminator進化到第二代,發現第二代Generator產生的也是假的,
如此反覆不斷進化和迭代,直到Discriminator無法分辨Generator所產生的圖片是假的。
上面是GAN的基本概念,對於GAN的原理可以解釋如下:
對於實際的樣本圖片的資料分佈我們用Pdata(x)來表示,假設它的分佈是下面這樣的:
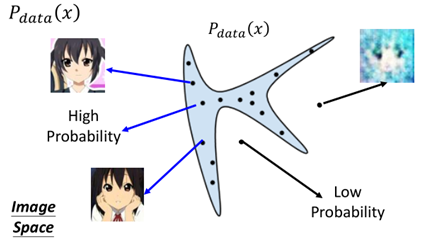
在藍色的區域是實際的圖片,區域以外則產生的圖片不像是真的圖片,那麼我們想要通過訓練得到Pdata(x)的分佈,假設Generator所產生的分佈為PG(x):
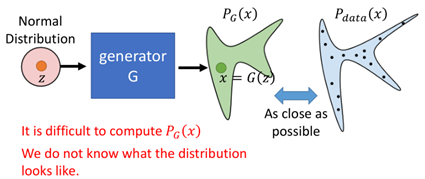
我們訓練時希望G所產生的圖片的分佈於原來的圖片的資料分佈越接近越好。然而在實際中,我們其實並不知道PG(x)長什麼樣,因此這樣也變得困難。
但是在GAN中,Discriminator則可以為解決這一問題提供方法,具體做法如下:
首先Generator產生一下圖片資料,同時從樣本中sample出一些資料
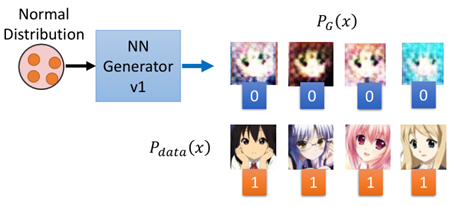
然後把這些資料Generator所產生的圖片標記為0,從原資料中產生的圖片標記為1,然後訓練Discriminator:
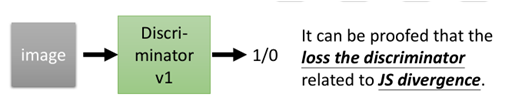
那麼Discriminator最終訓練完成的loss則與PG(x)和Pdata(x)的JS divergence有關,也就說loss可以用來衡量兩個分佈有多相似。
然後Generator則可以根據這個loss進行進化成為第二代Generator。那麼引數是如何更新的呢?下面舉個例子:
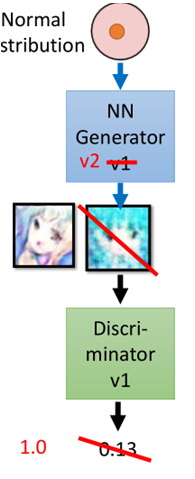
訓練完成Discriminator後,隨機sample一個資料,丟進Generator中,然後產生一張圖片,圖片經過Discriminator,假設此時Discriminator給的分數是0.13,那麼此時Generator開始調整引數(注意此時Discriminator的引數是固定不變的),使得所產生的圖片丟給Discriminator讓其輸出值為1,然後完成進化成為Generator V2。
以上就是GAN的基本思想以及其演演算法的較為通俗的解釋。下面給出文獻中GAN的演演算法:
"""
Generator:G,Discriminator: D
-
- Initialize G θg, D θd(初始化Generator和Discriminator的引數)
- for each training
- sample m examples{x1, x2, .....,xm} from datanse;(從樣本集中sample出一些資料)
- sample m noise samples {z1, z2, .....,zm} from a distribution;(從一種分佈中sample出一些資料)
- Obtaining generated data {x'1,x'2,......x'm},x'i=G(zi);(然後把z丟進G中產生一些圖片)
- Fix G, update θd to maximize , (固定住Generator的引數,調整Discriminator的引數,這裡並不一定使用這種方法更新,還有其他方法也就衍生了其他演演算法)
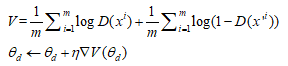
-
-
- sample m noise samples{z1,z2,......,zm} from a distribution;(再另外從某種分佈中sample出一些資料)
- Fix D, update to maximize;(固定住Discriminator,調整Generator的引數,使得sample出來的那些資料讓Discriminator的分數越高越好)
-
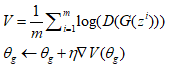
"""
以上就是GAN的基本概念和演演算法,這裡就暫時對這部分內容介紹到這裡,後邊會單獨開一節GAN有關其他的衍生演演算法及其實現。
4 總結
至此有關無監督學習的內容到這裡就基本完結了,總結一些,無監督學習可以概況為兩種「化繁為簡」和「無中生有」兩類,所謂化繁為簡就是資料的降維,將資料從高維空間對映到另一個空間,又能保持原資料的特徵,主要方法有PCA、LLE、TSNE、AutoEncoder,無中生有主要是生成模型,主要方法有Seq2Seq、AutoEncoder、VAE、GAN。
後面有關機器學習的概念和內容快完結了,後面還有一些前面的提到沒有補充的,後面會再進行補充。