翟佳:高可用、強一致、低延遲——BookKeeper的儲存實現
分享嘉賓:翟佳 StreamNative 聯合創始人
編輯整理:張曉偉 美團點評
出品平臺:DataFunTalk
導讀:多數讀者們瞭解BookKeeper是通過Pulsar,實際上BookKeeper在資料庫和儲存場景都有著非常廣泛的應用。BookKeeper是Pulsar的底層儲存,Pulsar有著廣泛資料入口,Pulsar跟Kafka及各類MQ(RabbitMQ、ACTIVEMQ)的較大區別是Pulsar是統一的雲原生訊息流平臺,不但是分散式系統,而且做了存算分離,可以讓使用者在雲的環境下,體驗到雲原生的優勢,例如隨意擴縮容、資料靈活遷移複製等。希望通過本文,讓大家對Pulsar底層的BookKeeper有更深入的瞭解。
今天的介紹會圍繞下面四點展開:
- BookKeeper的簡介
- BookKeeper的特性
- BookKeeper儲存媒介的演進
- BookKeeper的社群資源
--
01 BookKeeper的簡介
1. 業務場景需求的統一
Pulsar裡有很重要的概念是「統一」,這個統一的特性是由BookKeeper支援實現的。這裡的統一是指需求的統一,在訊息場景下,使用者場景分兩類:
第一類是線上業務場景,例如1984年誕生的IBM MQ到現在的各類開源MQ解決的是線上業務場景,這些MQ的服務質量會對業務服務質量有著直接的影響,所以這類需求對資料質量,例如對資料永續性、資料延遲、消費模型的靈活性有較強的要求。
第二類是巨量資料場景,例如2010年左右隨著實時計算的廣泛使用,Kafka的這種高頻寬和高吞吐使用需求。
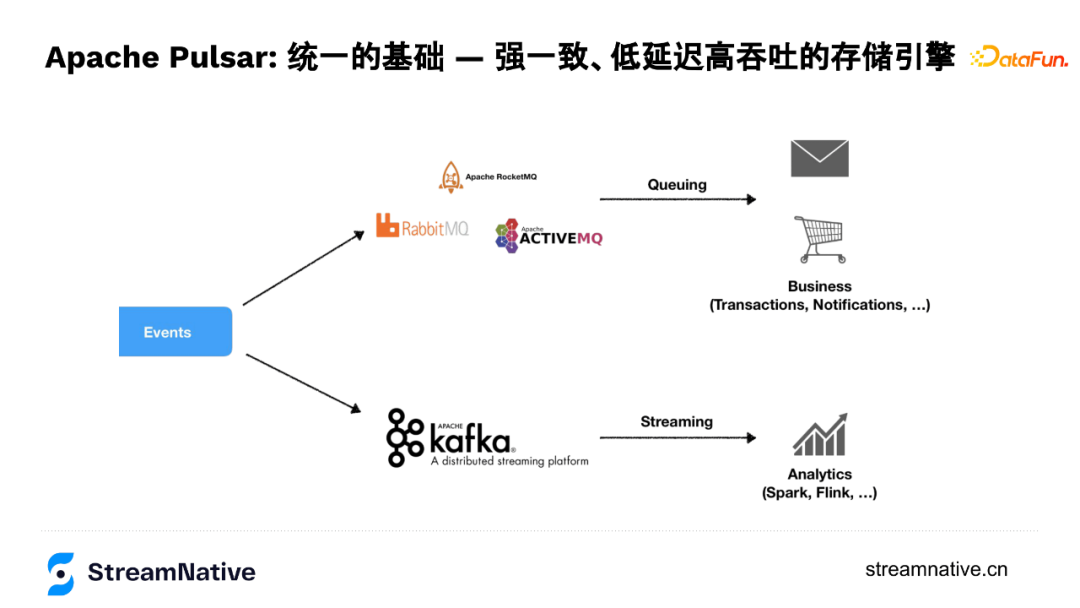
由於面向場景不同、技術棧不同,這兩種場景在業務上又同時存在,給業務帶來不同的基礎設施API、不同的使用方式、不同系統的運維成本等問題。所以Pulsar針對這些問題,做了兩層API的統一:既相容MQ的並行消費模型,提供比較好的服務質量,同時通過底層儲存層抽象,可以提供很高的吞吐和頻寬,這就是我們要介紹的Apache BookKeeper專案。
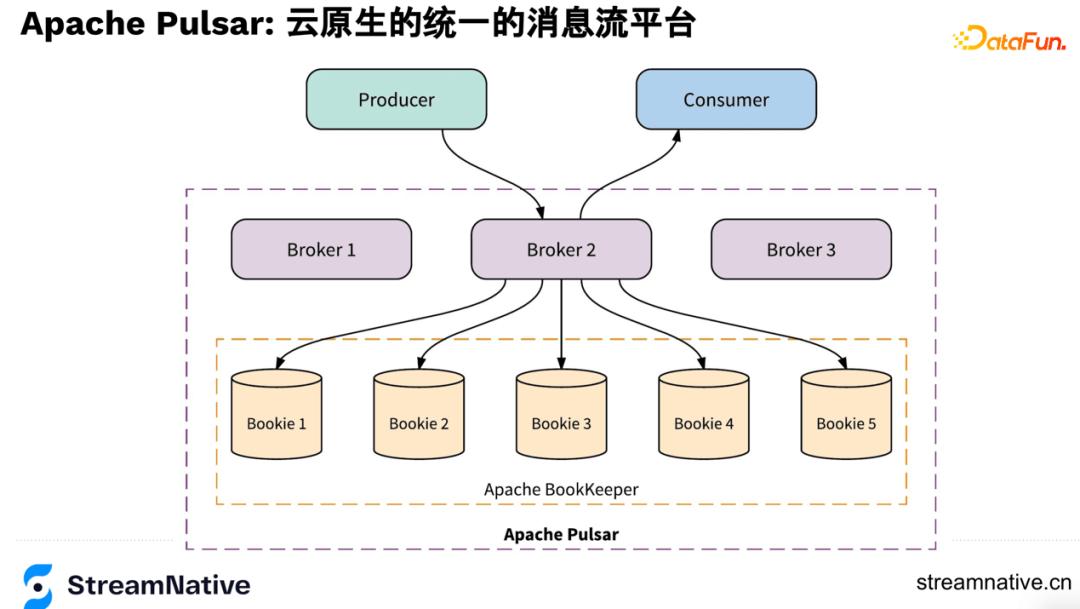
2. Apache BookKeeper簡介
很多服務裡都有紀錄檔,例如MySQL的binlog和HDFS的namenode的editlog,都是對紀錄檔的一個抽象,而BookKeeper就是把這個抽象變成了一個分散式的服務,擺脫了對單機容量瓶頸的限制,把紀錄檔變成了可無限擴充套件的服務。BookKeeper使用packet source協定和ZooKeeper的zap協定,通過log append only的方式實現了低延遲和高吞吐。在APCP裡選擇CP,而availability是通過多副本並行的方式提供高可用,BookKeeper有著低延遲、高吞吐、持久化、資料的強一致性、服務的高可用、單節點可以儲存很多紀錄檔、IO隔離等優勢,針對這些特性在後文會展開介紹。
3. BookKeeper的誕生
BookKeeper也是Apache的一個專案,同樣是由雅虎捐獻誕生,原本是為了應對雅虎開源HDFS裡後設資料儲存的需求。
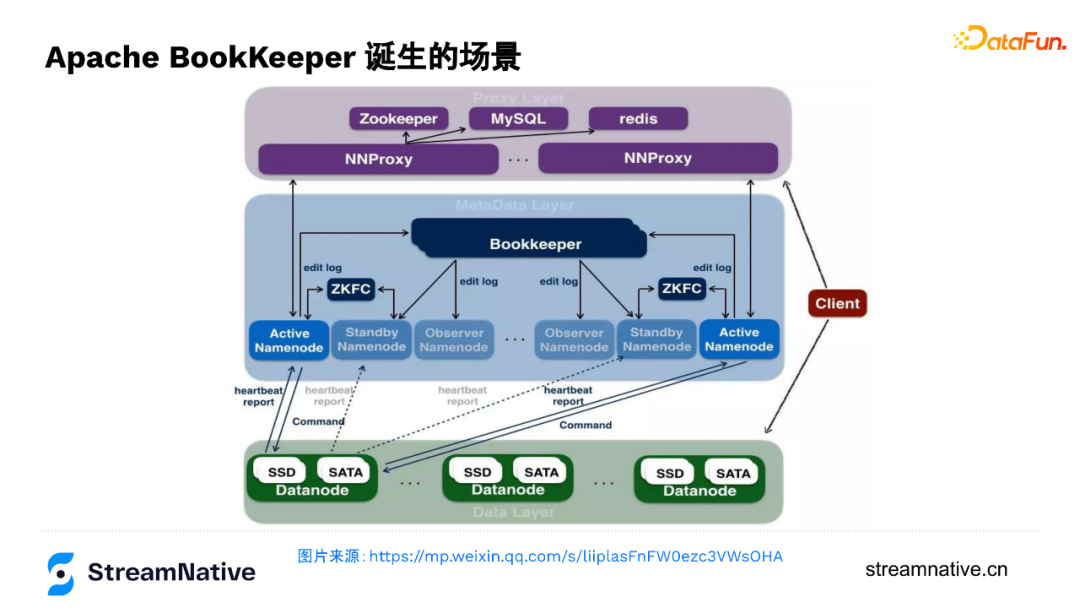
下圖是位元組跳動技術文章的一個圖,主要是呈現在位元組跳動如何用BookKeeper支撐後設資料服務,支撐起EB級別的HDFS叢集。這個叢集DN有好幾萬臺,需要很多NameNode,就需要一個可以保障active/standby/observer NameNode之間強一致性的紀錄檔服務,單機容量瓶頸下很難支撐這麼大的體量時,引入了一個分散式的紀錄檔服務,這就是BookKeeper誕生的場景。隨著HDFS大規模的問題開始出現之後,BookKeeper成為了HDFS在HA上的剛需需求,例如在EMC內部的HDFS叢集,也是用的BookKeeper來做NameNode的editlog服務。BookKeeper是一種分散式場景下很常見的複製狀態機的實現(通過複製log,保持各個節點狀態機的同步,A節點持久化log後,把log同步到B節點,在B節點進行log的一個重放,讓B節點達到跟A節點一樣的一個狀態)。由於在HDFS場景中,儲存的只是NN的變更紀錄檔,所以算是後設資料的後設資料,對資料一致性、對吞吐、對時延的要求自然極高。
4. BookKeeper使用案例
BookKeeper也有侷限性,是append only的一個抽象變成了分散式服務,相對而言比較底層。所以使用者多是一些比較大的網際網路公司或其他有巨量資料量的需求的使用者,這些使用者會在BookKeeper之上做一些二次開發,例如Pulsar在BookKeeper之上做了一層broker服務,對BookKeeper的每個分片做一些管理然後將其作為資料的儲存服務。
類似的還有Twitter和Salesforce。Twitter的技術棧是構建在實時計算上的,在Twitter內部,BookKeeper是作為很重要的基礎設施,不但有類似Pulsar的服務eventbus,還有其他使用場景例如搜尋、廣告、Stream computing, 以及作為類似KV儲存的Manhattan Database的後設資料服務,這些場景都用到了BookKeeper。在規模上,Twitter BookKeeper有兩個叢集,每個叢集約有1500個節點,每天有17PB的資料,每秒1.5萬億的records。而在Salesforce的使用背景,是Salesforce想去掉對Oracle的依賴,所以自研了類似Amazon Aurora的NewSQL Database,其內部很多跟後設資料相關或有一致性要求的服務都是通過BookKeeper來滿足的,並且也有部分後端場景將BookKeeper作為儲存服務去用。
--
02 BookKeeper的特性
1. BookKeeper基本概念
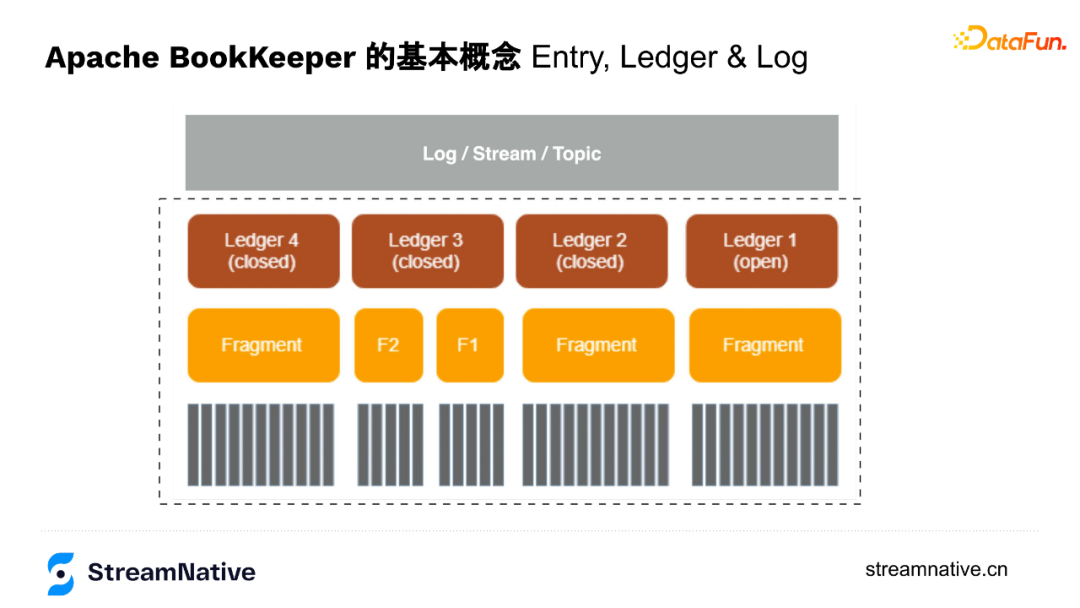
- Ledger
可以理解為BookKeeper是會計,Ledger是賬本,每個賬本是記錄資訊的一個單元,寫完之後轉為closed狀態(唯讀),最新的賬本是開啟狀態(openLedger),以append only的方式持續儲存資料。
- Fragment
可以理解為BookKeeper內部維護的一個以append only的方式新增的資料組。
Fragment之下就是使用者以append only的方式追加的一條條資料。
2. BookKeeper的節點對等架構
openLedger時有3個引數:Ensemble選擇幾個節點儲存這個賬本,Write Quorum控制資料寫幾個副本(並行寫,不同於Kafka或HDFS,BookKeeper沒有資料節點之間主從同步的關係,把資料同步的協調者從伺服器端移到了使用者端),Ack Quorum控制等幾個副本返回ack。
以下圖為例openLedger(5,3,2),在儲存這個賬本時,選擇了5個節點,但是隻寫3個副本,等2個副本來返回ack。第一個引數一般可用於調整並行度,因為寫3個副本是通過輪轉的方式寫入,例如第1個record是寫1-3節點,第2個record寫2-4節點,第3個record寫3-5節點,第4個record寫4-5和1節點這樣輪轉。這種方式即便3個副本,也可以把5個節點都用起來。
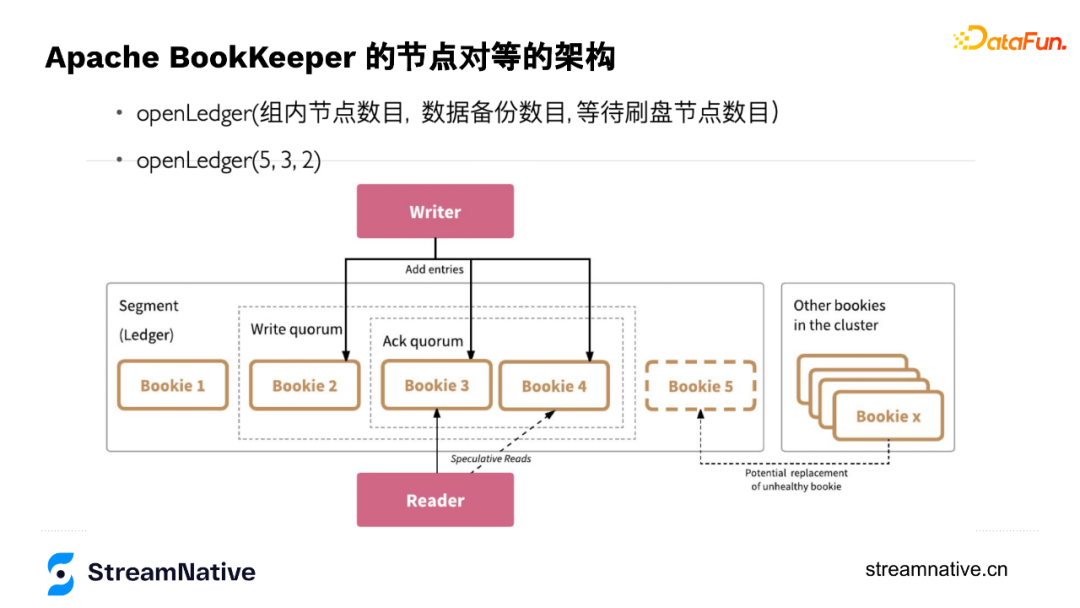
這幾個引數便捷的特性可讓使用者通過機架感知、機房感知、resource感知等各種方式進行靈活設定。當選好節點後節點之間的排序就已完成,每個record會帶個index,index和節點已有繫結關係,例如index為1的,都放在123上,為2的都放在234上。通過這種方式可以讓我們知道每個節點存了哪些訊息,當某個節點宕機,根據這個節點的位置資訊,把對應record還在哪些節點上有副本的資訊找出來進行多對多的恢復。這麼做的另一個好處是不用再維護後設資料資訊,只需要有每個節點記錄index資訊,在openLedger時記錄好每個節點的順序即可。
openLedger(5,3,2)資料儲存結構就是下圖中右邊的結構,如果選擇Ensemble=3,Write Quorum=3,資料儲存結構就是下圖左邊的結構:
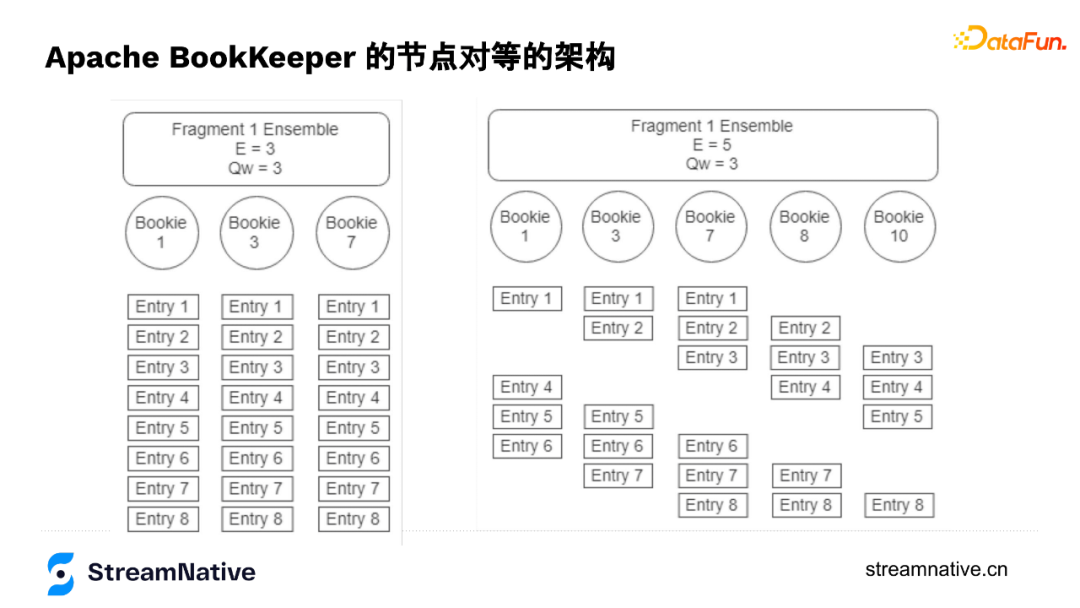
綜上,使用者可以通過Ensemble來調整讀寫頻寬,通過Write Quorum調整強一致性的控制,通過Ack Quorum權衡在有較多副本時也可以有較低的長尾時延(但一致性就可能有一定的損失)。
3. BookKeeper可用性
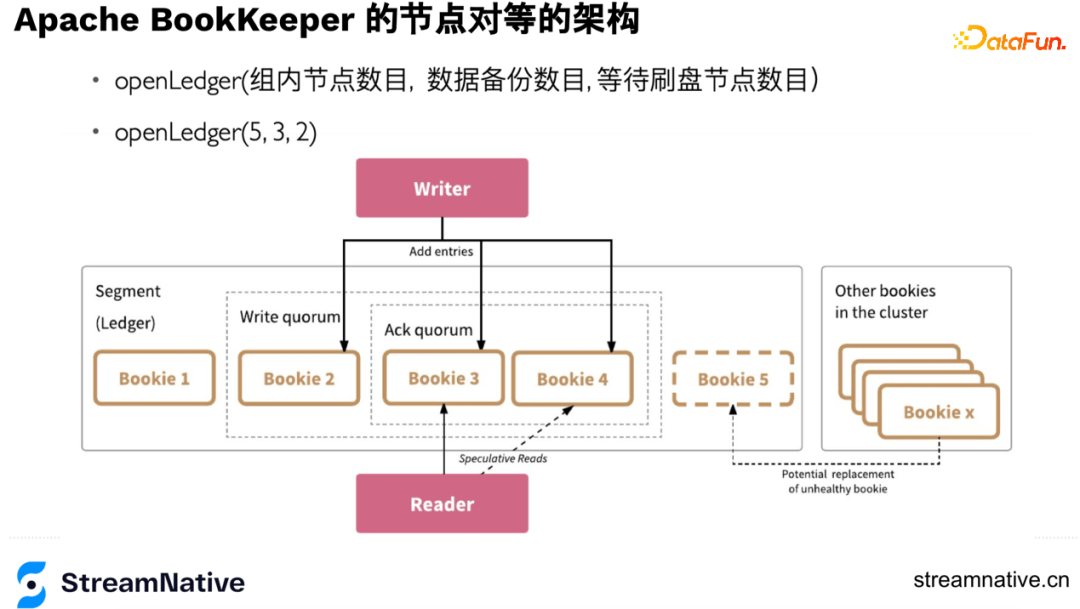
- 讀的高可用
讀的存取是對等的,任意一個節點返回就算讀成功。這個特性可以把延遲固定在一個閾值內,當遇到網路抖動或壞節點,通過延遲的引數避障。例如讀的延遲時間2ms,讀節點3超過2ms,就會並行地讀節點4,任意一個節點返回就算讀成功,如下圖Reader部分。
- 寫的高可用
在openLedger時會記錄每個節點的順序,假如寫到5節點宕機,會做一次後設資料的變更,從這個時間開始,先進行資料恢復,同時新的index中會把5節點變為6節點,如下圖x節點替換5節點:
4. BookKeeper一致性
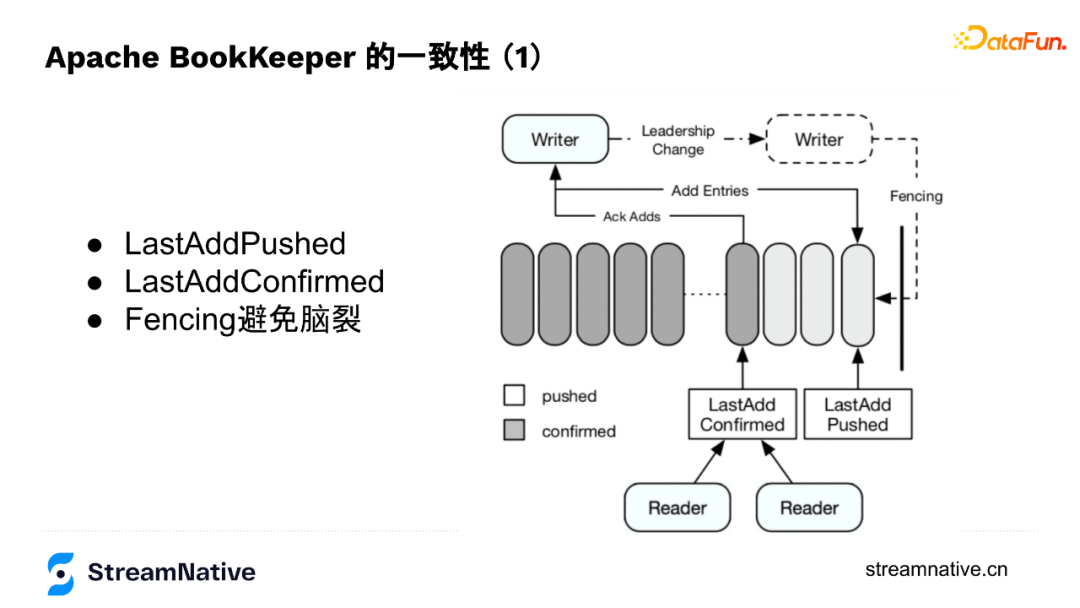
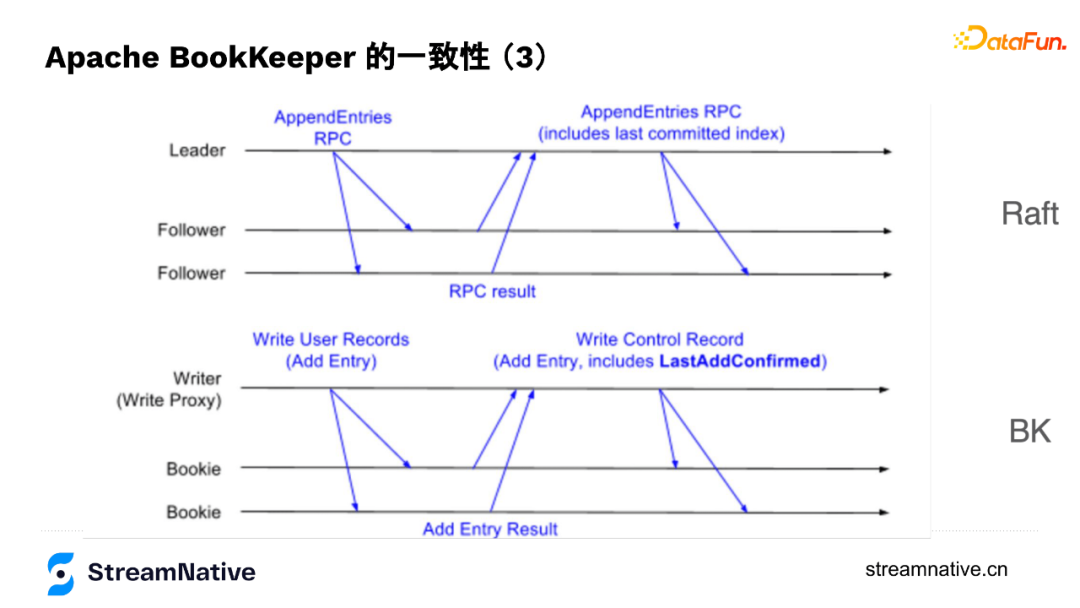
BookKeeper底層節點對等設計讓寫入資料的Writer成為了協調者,Writer來儲存資料是否儲存成功的狀態,例如節點是否出現問題、副本夠不夠、切換Fragment時要不要做資料恢復、在寫入過程中出現宕機時,通過fencing的方式防止腦裂等。所以,Writer維護了2個index:LastAddPushed和LastAddConfirmed。
LastAddPushed會隨訊息ID遞增,LastAddConfirmed則記錄最後一個連續的訊息成功寫入了(例如Ack Quorum為2,有2個成功返回了即為成功),但因為返回順序不一定與訊息順序一致,例如123個訊息,3的訊息先返回了,2的還未返回,按連續的規則就是2不是3。
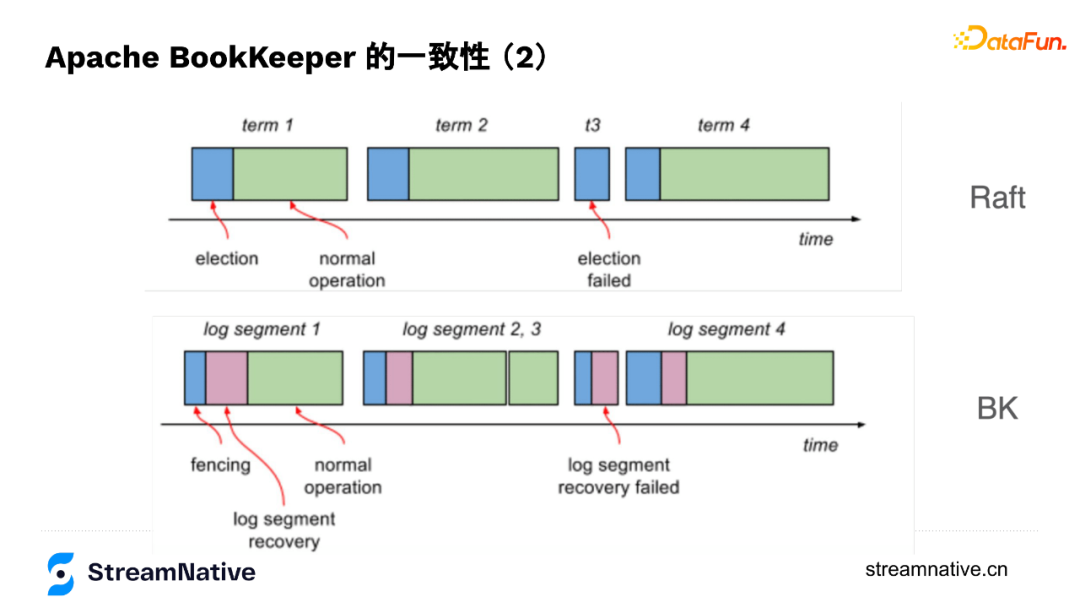
5. BookKeeper與Raft的對比
在底層原理上,Raft與BookKeeper有很多類似的地方,Raft每個資料寫入的組織形式是term,跟BookKeeper的segment類似,每個term也會選擇一組節點儲存資料,然後不斷往後追加資料,通過資料節點之間的協同保證資料一致性。
在資料結構上,Raft在儲存資料時有Entry,Entry除了帶本身的index還會帶上last committed index,與BookKeeper中的LastAddConfirmed較為類似,只是BK是通過Writer來協調資料在不同節點的一致性,Raft有leader來協調資料在不同節點的一致性。
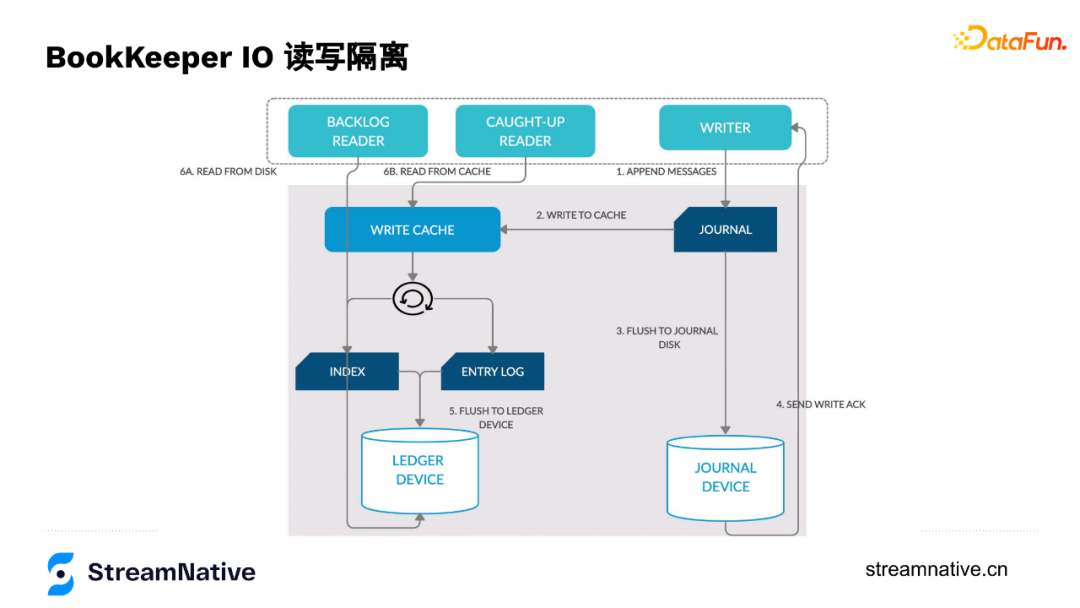
6. BookKeeper的IO讀寫分離
下圖是每個資料節點的資料流轉過程,資料寫入時,Writer通過append only方式寫入到Journal,Journal在把資料寫到記憶體的同時會按一定頻率(預設1ms或500 byte)把資料持久化到Journal Device裡,寫完後會告訴Writer這個節點寫入成功了(持久化到磁碟是預設設定)。
Journal在資料寫入時有寫到記憶體中,接下來在記憶體中做排序(用於解決如果按寫的順序讀會導致分割區隨機性強的問題),然後把資料刷到資料盤中。讀的時候,如果讀最新的資料,可以直接從記憶體裡返回,如果讀歷史資料,也只去讀資料盤,不會對Journal Device寫入有影響。這樣針對有讀瓶頸或寫瓶頸的使用者,可以把Journal Disk或Ledger Disk換成SSD槽,提升效能,並且防止讀寫的互相干擾。
--
03 BookKeeper的儲存媒介演變
1. BookKeeper的Disk演進
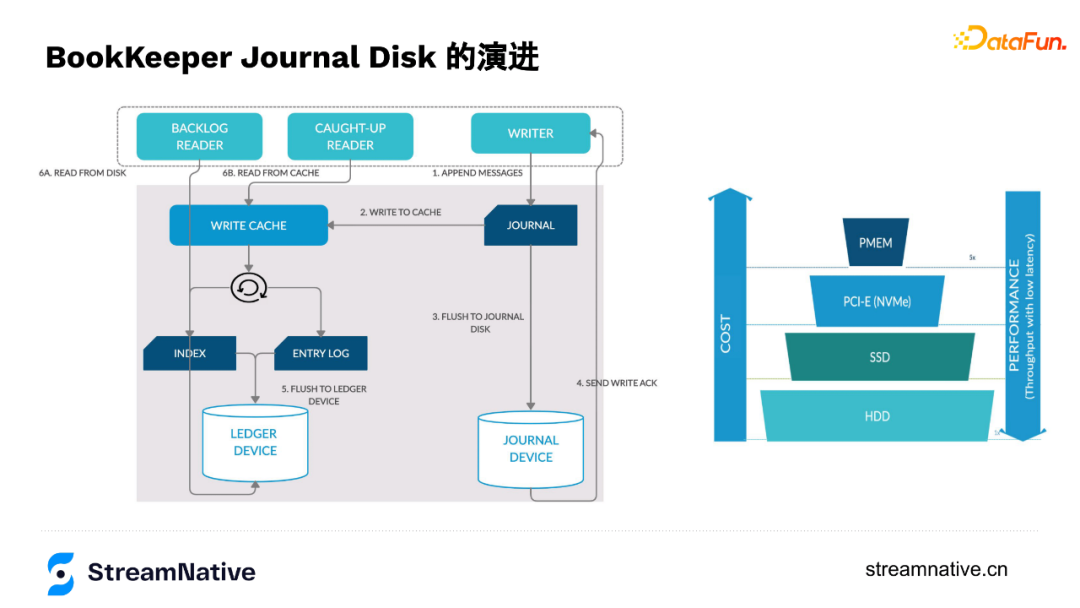
在演進過程中,因為順序讀的情況比較多,所以讀的部分變化不大,但在寫的這部分經歷了HDD到SSD再到NVMe SSD,再到現在部分使用者換成了Intel的PMem的過程(如下圖所示)。在換到NVMe SSD時,部分使用者通過多目錄的方式可以把SSD的IO頻寬打的很滿。
2. PMEM在BookKeeper上的應用
PMem的特性非常匹配Journal Disk,單塊PMem可以達到3-4GB的頻寬,不但能提供高頻寬吞吐而且可持久化。PMem容量相比SSD比較小、相比記憶體又比較大,在剛推出時單條128GB,有著GB級別的吞吐和ns級別的延遲。
高吞吐低容量的PMem非常適合Journal持久話刷盤的需求,例如宕機後,需要對沒刷到磁碟的這部分資料做恢復,需要Journal做replay log重放,由於只是增量紀錄檔而非全量資料,所以並不需要很大的容量,正好和PMem容量不大相匹配。而且,PMem的壽命會比SSD的壽命長一些,例如在每天同樣寫入量下SSD可能只能用1年而PMem預計可以使用4-5年。
雅虎(現在是Verizon Media)有實際通過PMEem優化BookKeeper的案例,在只增加5%的單機成本情況下提升了5倍的頻寬吞吐和低於5ms的時延保障(BookKeeper社群與Intel正在合作做效能測試,預計未來會產出白皮書說明)。
在雅虎案例中用10臺Pulsar(底層是用PMem做Journal Disk的BookKeeper)替換了33臺Kafka,比原Kafka方案成本降低了一半,產出的對比結果如下:

--
04 社群資源
- 團隊構成
由Apache Pulsar核心研發團隊創立,同時有Apache Pulsar和Apache BookKeeper專案管理委員會(PMC)主席,有6名Apache Pulsar PMC成員和3名Apache BookKeeper PMC成員,有約20名 Apache Committer。
- 里程碑
公司成立於2019年,2020年釋出商業化產品StreamNative Cloud,目前有50+付費客戶,覆蓋金融、IoT、網際網路、製造多個行業。
- 優勢
是社群和程式碼的構建維護者,有全球最專業的Pulsar設計開發、運維、管理團隊的7*24小時服務,提供開箱即用的雲服務和諮詢培訓服務。

今天的分享就到這裡,謝謝大家。
分享嘉賓:

本文首發於微信公眾號「DataFunTalk」。