基於MIndSpore框架的道路場景語意分割方法研究
基於MIndSpore框架的道路場景語意分割方法研究
概述
本文以華為最新國產深度學習框架Mindspore為基礎,將城市道路下的實況圖片解析作為任務背景,以複雜城市道路進行高精度的語意分割為任務目標,對上述難處進行探究並提出相應方案,成功地在Cityscapes資料集上完成了語意分割任務。
整體的技術方案見圖:
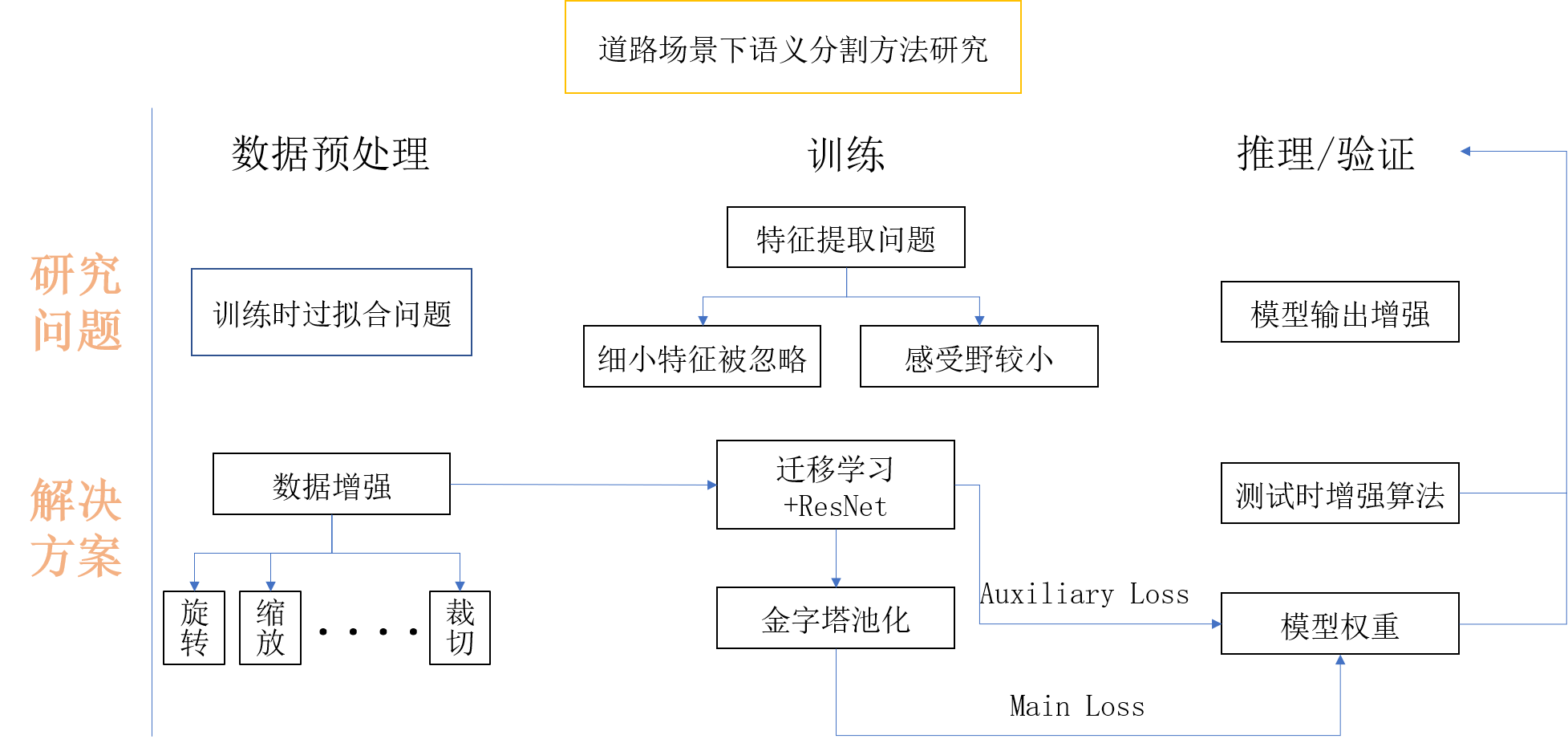
本帖僅對程式碼上的更改以及專案進行介紹。
專案地址
https://gitee.com/xujinminghahaha/mindspore_model
相關設定
硬體設定
| 作業系統 | Ubuntu 18.04 | 硬體架構 | X86_64 |
|---|---|---|---|
| CPU | Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz | GPU | NVIDIA-A100(40G) |
| 深度學習框架 | Mindspore 1.6.0 | Batch_sizes | 7 |
Cityscapes資料集:
Cityscapes資料集提供了3475張細粒度分割標籤圖,以及20 000張粗略分割的影象,本文使用了細粒度標註的train/val集進行訓練和驗證,此資料集與之前的CamVid,Leuven,Daimler 城市資料集不同,Cityscapes更多的捕捉到了真實世界的城市道路場景的多樣性與複雜性,尤其是為城市環境中的自動駕駛量身客製化,涉及範圍更廣的高度複雜的市中心街道場景,並且這些場景分別在50個不同城市採集。

資料集下載地址:https://www.cityscapes-dataset.com/
實現流程記錄
1、 參考華為官方gitee倉庫的modelzoo克隆至本地,找到research/cv/PSPNet目錄,在此程式碼基礎上進行修改。
本專案基於GPU平臺,對modelzoo中原有的昇騰檔案已清除。程式碼中shell_command提供了訓練指令碼和驗證指令碼的啟動命令,同時附帶linux伺服器一鍵下載Cityscapes下載方式。
2、由於選題是道路場景,所以需要更改資料集為Cityscapes,由於modelzoo上的資料集僅支援VOC2012和ADE20K,所以需要增加對資料集的適配和標籤資訊轉換。
在程式碼中已經新增了對於cityscapes的畫素點和label的轉換程式碼,可以直接使用,其中顏色和類別的對映關係請見:config/cityscapes_colors.txt以及config/cityscapes_names.txt
3、網路架構選用可插拔的殘差網路,以及金字塔池化模組解碼。相關程式碼實現在src/model目錄下。
ResNet論文地址:https://arxiv.org/abs/1512.03385
PSPNet論文地址:https://arxiv.org/abs/1612.01105
網路結構圖:
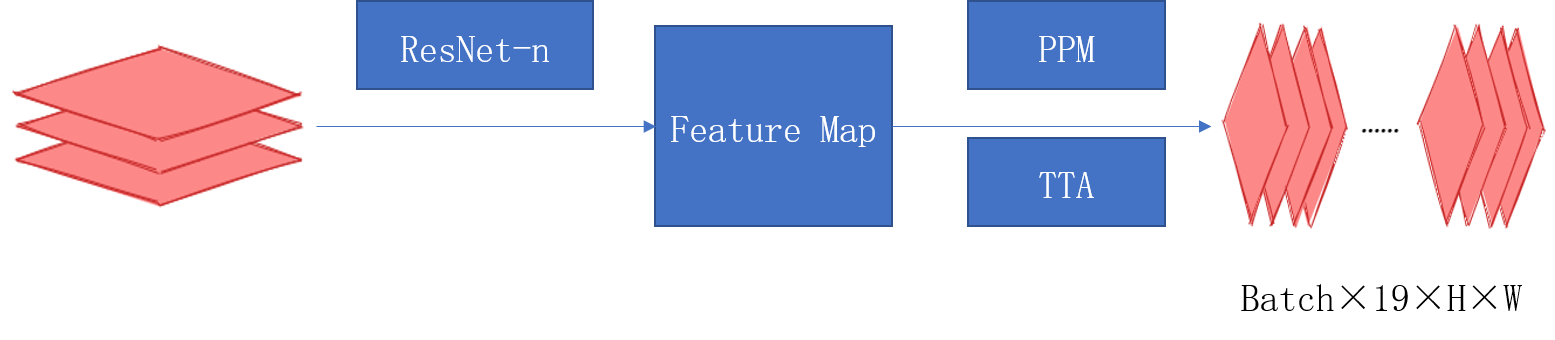
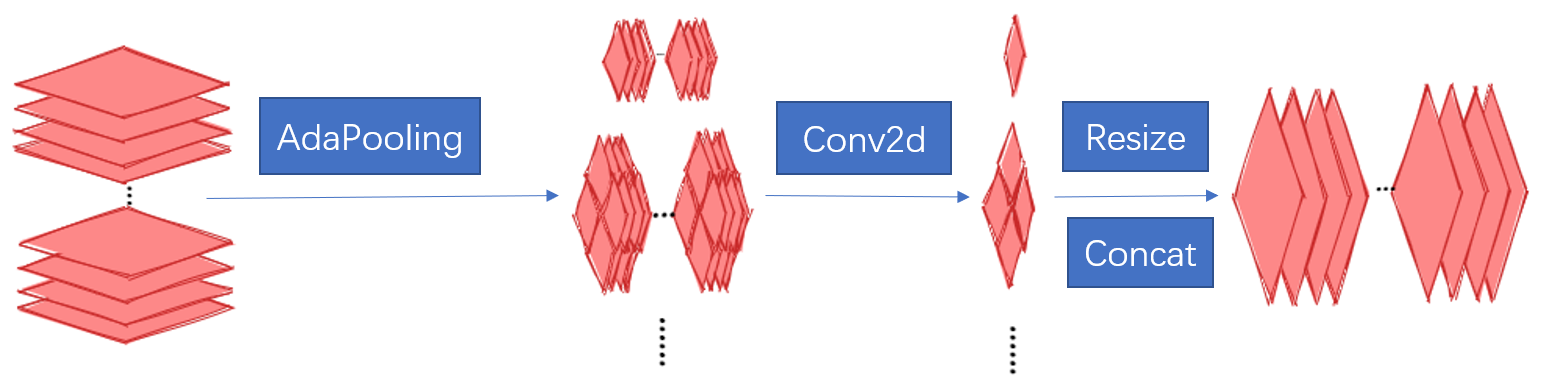
金字塔池化模組:
loss函數的設計:
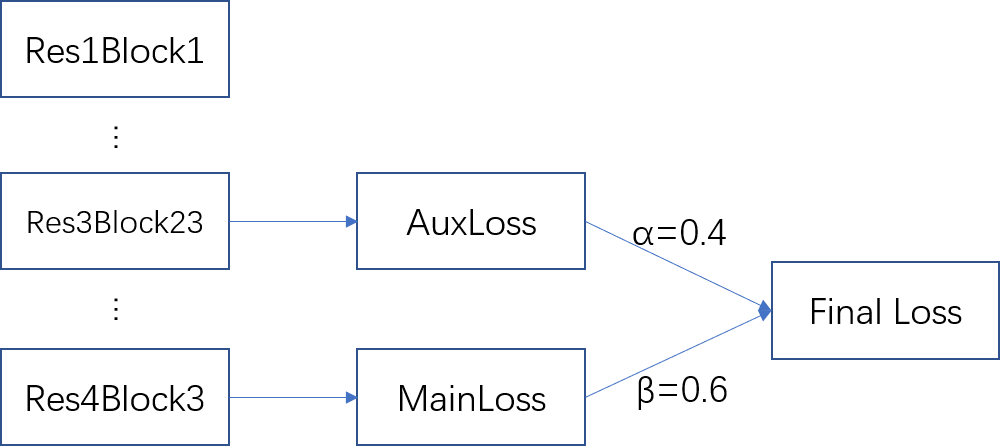
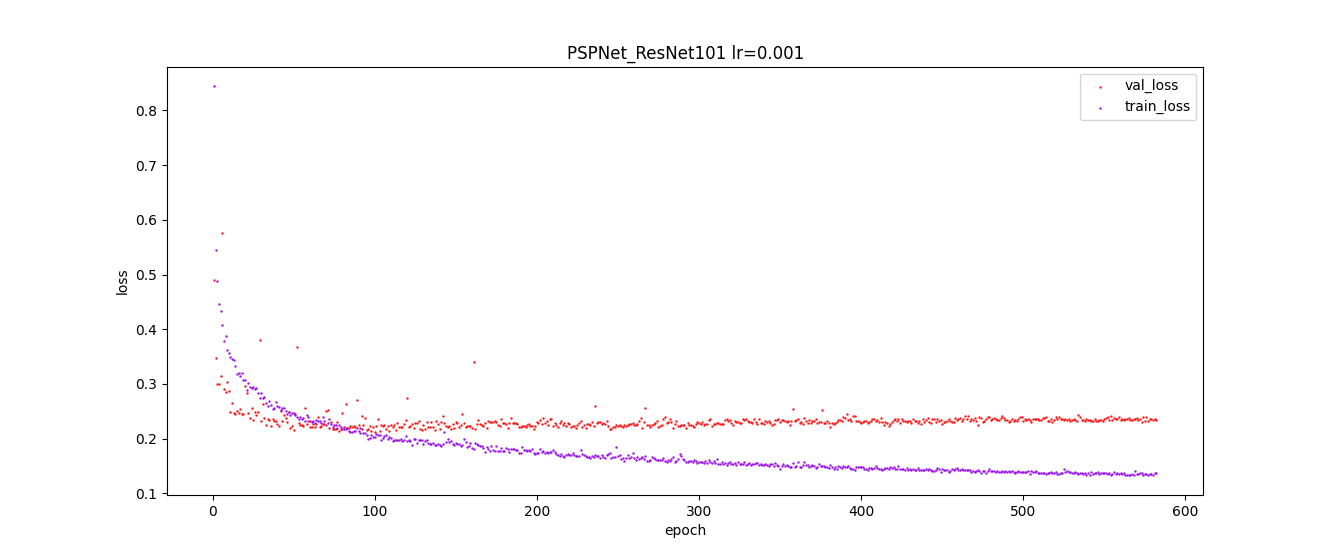
實際訓練時的loss值變化趨勢:
特色功能
4、測試時增強(TTA, Test Time Augmentation),通過多尺度推理最後取平均的方法獲得更好的效果:
以下給出方法偽碼,供大家參考,具體實現請結合程式碼倉庫查閱。
# Algorithm 1: TTA(Test Time Augmentation)
# Input:Image,Scales,Crop_size,Net
# OutPut:Image with Label
batch, _,ori_height, ori_width = image.shape #獲取影象shape
stride_h ,stride_w = crop_size #步長,cropsize為訓練時設定的crop引數
final_pred = Tensor(np.zeros([1, dataset.num_classes, ori_height, ori_width])) #初始化結果
for scales:
image = dataset.multi_scale_aug(image,scale)
height, width = image.shape[:-1]
new_h, new_w = image.shape[:-1]
rows, cols = GetParam(new_h, new_w) #一張圖片分為row行和col列分塊推理
preds = np.zeros([1, dataset.num_classes, new_h, new_w]).astype(np.float32)#初始化
count = np.zeros([1, 1, new_h, new_w]).astype(np.float32)#記錄影素點推理次數
for rows,cols:
h0 , w0, h1, w1 = GetIndex(rows,cols,stride_h,strid_w) #獲得格點座標
crop_img = new_img[h0:h1, w0:w1, :]
crop_img = crop_img.transpose((2, 0, 1))
crop_img = np.expand_dims(crop_img, axis=0)
pred = dataset.inference(model, crop_img, flip)
preds[:, :, h0:h1, w0:w1] += pred.asnumpy()[:, :, 0:h1 - h0, 0:w1 - w0]
count[:, :, h0:h1, w0:w1] += 1 #將推理矩陣相加,再把標記矩陣相加
preds = preds / count #求得平均推理畫素值
preds = preds[:, :, :height, :width]
preds = P.ResizeBilinear((ori_height, ori_width))(preds) #恢復原始大小
final_pred = P.Add()(final_pred, preds)
return final_pred
在config/pspnet_resnet_cityscapes_gpu.yaml下scales那一行,可以輸入一個陣列,該陣列中每一個Value對應一個Scale,inference將會在此scale下輸出一次。
5、 結果展示:
| road | traffic light | rider | bicycle | sidewalk | traffic sign | car | pole |
|---|---|---|---|---|---|---|---|
| 97.81% | 63.08% | 56.61% | 74.33% | 83.69% | 69.24% | 92.79% | 45.66% |
| building | vegetation | truck | person | fence | sky | train | mIoU |
| 90.71% | 90.43% | 71.73% | 75.35% | 55.50% | 92.89% | 43.63% | 74.874% |
