透過Redis原始碼探究Hash表的實現
轉載請宣告出處哦~,本篇文章釋出於luozhiyun的部落格:https://www.luozhiyun.com/archives/667
本文使用的Redis 5.0原始碼
概述
我們在學習 Redis 的 Hash 表的時候難免腦子裡會想起其他 Hash 表的實現,然後進行一番對比。通常我們如果要設計一個 Hash 表,那麼我們需要考慮這幾個問題:
- 有沒有並行操作;
- Hash衝突如何解決;
- 以什麼樣的方式擴容。
對 Redis 來說,首先它是單執行緒的工作模式,所以不需要考慮並行問題,這題 pass。
對於 Hash 衝突的解決,通常來說有,開放定址法、再雜湊法、拉鍊法等。但是大多數的程式語言都用拉鍊法實現雜湊表,它的實現複雜度也不高,並且平均查詢的長度也比較短,各個用於儲存節點的記憶體都是動態申請的,可以節省比較多的儲存空間。
所以對於 Redis 來說也是使用了拉鍊法來解決 hash 衝突,如下所示,通過連結串列的方式把一個個節點串起來:
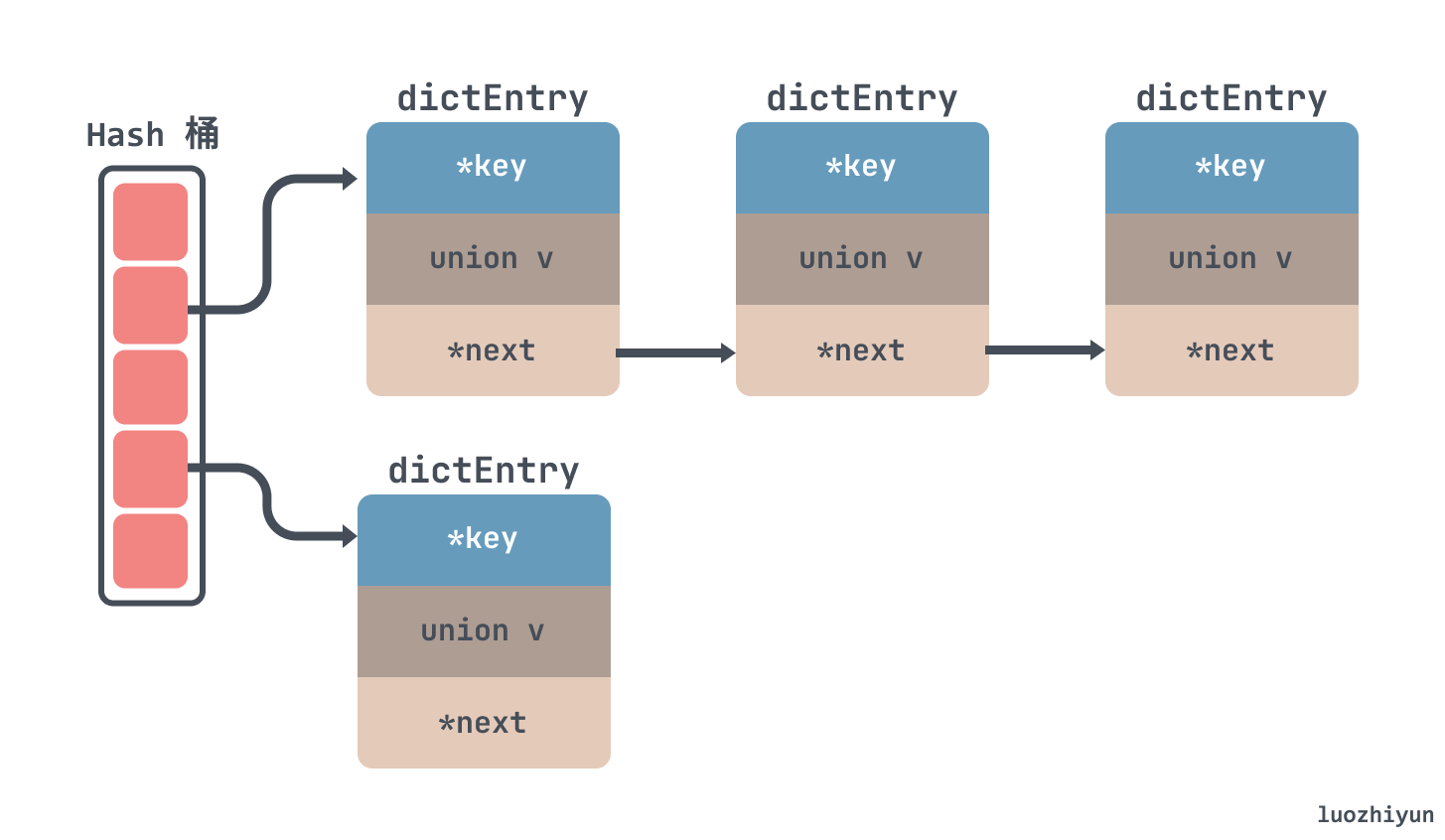
至於為什麼沒有向 JDK 的 HashMap 一樣紅黑樹來解決衝突,我覺得其實有兩方面,一方面是連結串列轉紅黑數其實也是需要時間成本的,會影響連結串列的操作效率;另一方面就是紅黑樹其實在節點比較少的情況下效率是不如連結串列的。
再來看看擴容,對於擴容來說,一般要新起一塊記憶體,然後將舊資料遷移到新的記憶體塊中,這個過程中因為是單執行緒,所以在擴容的時候,不能阻塞主執行緒很長時間,在 Redis 中採用的是漸進式 rehash + 定時 rehash 。
漸進式 rehash 會在執行增刪查改前,先判斷當前字典是否在執行rehash。如果是,則rehash一個節點。這其實是一種分治的思想,通過通過把大任務劃分成一個個小任務,每個小任務只執行一小部分資料,最終完成整個大任務。
定時 rehash 如果 dict 一直沒有操作,無法漸進式遷移資料,那主執行緒會預設每間隔 100ms 執行一次遷移操作。這裡一次會以 100 個桶為基本單位遷移資料,並限制如果一次操作耗時超時 1ms 就結束本次任務,待下次再次觸發遷移
Redis 在結構體中設定兩個表 ht[0] 和 ht[1],如果當前 ht[0]的容量是 0 ,那麼第一次會直接給4個容量;如果不是 0 ,那麼容量會直接翻倍,然後將新記憶體放入到ht[1]中返回,並設定標記0表示在擴容中。
遷移 hash 桶的操作會在增刪改查雜湊表時每次遷移 1 個雜湊桶從ht[0] 遷移到ht[1],在遷移拷貝完所有桶之後會將ht[0] 空間釋放,然後將ht[1]賦值給ht[0] ,並把ht[1]大小重置為0 ,並將表示設定標記1表示 rehash 結束了。
對於查詢來說,在 rehash 的過程中,因為沒有並行問題,所以查詢 dict 也會依次先查詢 ht[0] 然後再查詢 ht[1]
設計與實現
Redis 的 hash 實現主要在 dict.h 和 dict.c 這兩個檔案中。
hash 表的資料結構大致如下所示,我就不貼出結構體的程式碼了,欄位都標註在圖上了:
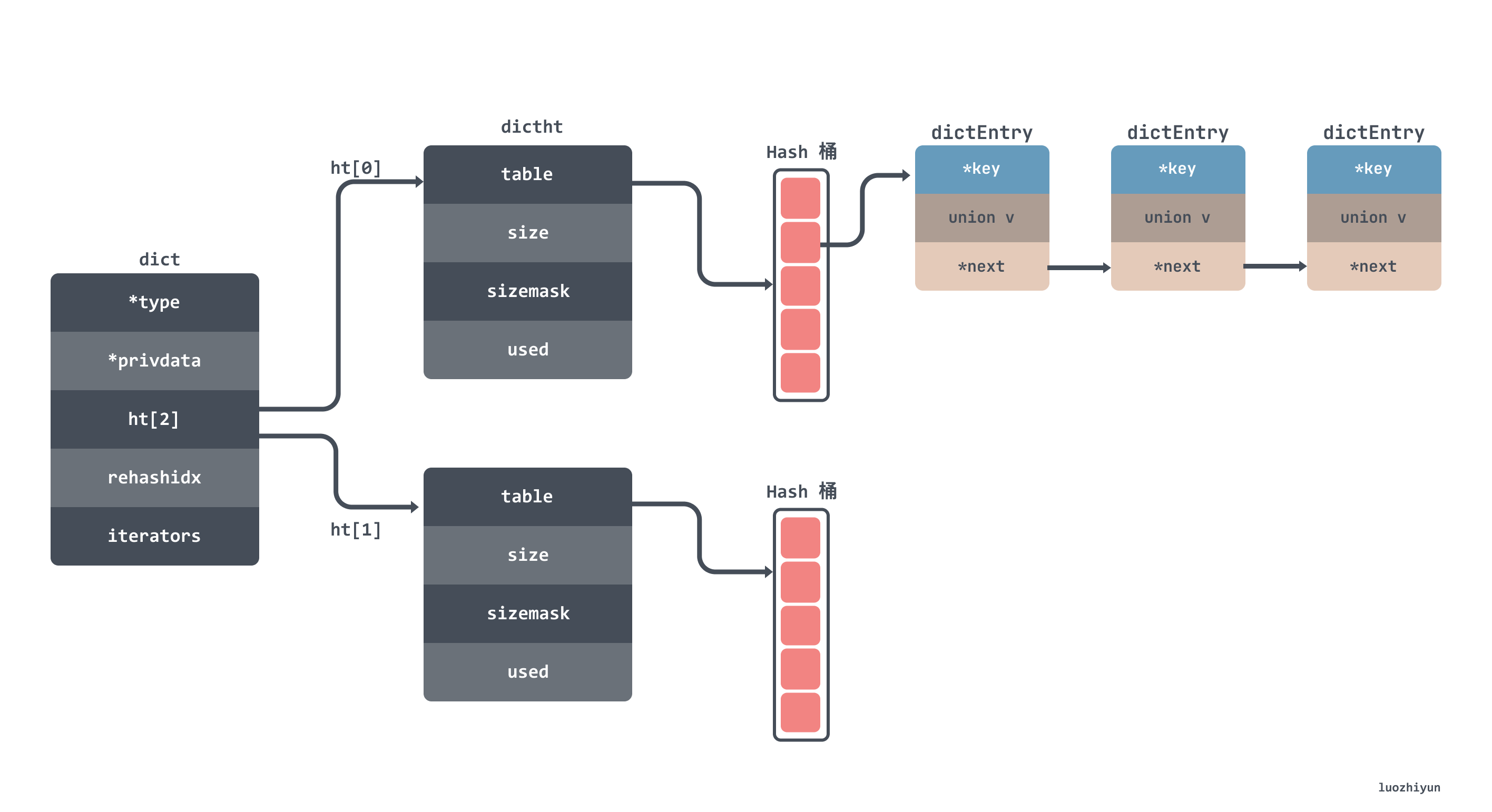
從上面的圖上也可以看到 hash 表中有一個空間為2的 dictht 陣列,這個陣列就是用來做 rehash 時交替儲存資料用的,其中 dict 裡面的 rehashidx 用來表示是否在進行 rehash 。
何時觸發擴縮容?
很多 hash 表都只有擴容,但是 dict 在 Redis 中是既有擴容,也有縮容。
擴容
擴容其實就是一般是在 add 元素的時候校驗一下是否達到某個閾值,然後決定要不要進行擴容。所以經過搜尋可以看到新增元素會呼叫 dictAddRaw 這個函數,我們通過函數的註釋也可以知道它是 add 或查詢的底層的函數。
Low level add or find:
This function adds the entry but instead of setting a value returns the dictEntry structure to the user, that will make sure to fill the value field as he wishes.
dicAddRaw 函數會呼叫到 _dictKeyIndex 函數,這個函數會呼叫 _dictExpandIfNeeded 判斷是否需要擴容。
┌─────────────┐ ┌─────────┐ ┌─────────────┐ ┌─────────────────────┐
│ add or find ├────►│dicAddRaw├─────►│_dictKeyIndex├─────►│ _dictExpandIfNeeded │
└─────────────┘ └─────────┘ └─────────────┘ └─────────────────────┘
_dictExpandIfNeeded 函數判斷了大致有三種情況會進行擴容:
- 如果 hash 表的size為0,那麼建立一個容量為4的hash表;
- 伺服器目前沒有在執行 rdb 或者 aof 操作, 並且雜湊表的負載因子大於等於
1; - 伺服器目前正在執行 rdb 或者 aof 操作, 並且雜湊表的負載因子大於等於
5;
其中雜湊表的負載因子可以通過公式:
// load ratio = the number of elements / the buckets
load_ratio = ht[0].used / ht[0].size
比如說, 對於一個大小為 4 , 包含 4 個鍵值對的雜湊表來說, 這個雜湊表的負載因子為:
load_ratio = 4 / 4 = 1
又比如說, 對於一個大小為 512 , 包含 256 個鍵值對的雜湊表來說, 這個雜湊表的負載因子為:
load_ratio = 256 / 512 = 0.5
為什麼要根據 rdb 或者 aof 操作聯合負載因子來判斷是否應該擴容呢?其實原始碼的註釋中也有提到:
as we use copy-on-write and don't want to move too much memory around when there is a child performing saving operations.
也就是說在 copy-on-write 時提高執行擴充套件操作所需的負載因子, 可以儘可能地避免在子程序存在期間進行雜湊表擴充套件操作, 這可以避免不必要的記憶體寫入操作, 最大限度地節約記憶體,提高子程序的操作的效能。
邏輯我們說完了, 下面我們看看原始碼:
static int _dictExpandIfNeeded(dict *d)
{
// 正在擴容中
if (dictIsRehashing(d)) return DICT_OK;
// 如果 hash 表的size為0,那麼建立一個容量為4的hash表
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// hash表中元素的個數已經大於hash表桶的數量
if (d->ht[0].used >= d->ht[0].size &&
//dict_can_resize 表示是否可以擴容
(dict_can_resize ||
// hash表中元素的個數已經除以hash表桶的數量是否大於5
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); // 容量擴大兩倍
}
return DICT_OK;
}
通過上面的原始碼我們可以知道,如果當前表的已用空間大小為 size,那麼就將表擴容到 size*2 的大小。新的 dict hash 表是通過 dictExpand 來進行建立的。
int dictExpand(dict *d, unsigned long size)
{
//正在擴容,直接返回
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n;
// _dictNextPower會返回 size 最接近的2的指數值
// 也就是size是10,那麼返回 16,size是20,那麼返回32
unsigned long realsize = _dictNextPower(size);
// 校驗擴容之後的值是否和當前一樣
if (realsize == d->ht[0].size) return DICT_ERR;
// 初始化 dictht 成員變數
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*)); // 申請空間是 size * Entry的大小
n.used = 0;
//校驗hash 表是否初始化過,沒有初始化不應該進行rehash
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//將新的hash表賦值給 ht[1]
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
這一段程式碼還是比較清晰的,可以跟著上面的註釋稍微看一下就好了。
縮容
講完了擴容,那麼來看一下縮容。熟悉 Redis 的同學都知道,在 Redis 裡面對於清理過期資料一個是惰性刪除,另一個是定期刪除,縮容其實也是在定期刪除裡面做的。
Redis 的定時器會每100ms呼叫一次 databasesCron 函數,它會呼叫到 dictResize 函數進行縮容:
┌─────────────┐ ┌──────────────────┐ ┌──────────┐ ┌──────────┐
│databasesCron├──►│tryResizeHashTable├──►│dictResize├──►│dictExpand│
└─────────────┘ └──────────────────┘ └──────────┘ └──────────┘
同樣的 dictResize 函數中也會判斷一下是否正在執行 rehash 以及校驗 dict_can_resize 是否在進行 copy on write操作。然後將 hash 表的 bucket 大小縮小為和被鍵值對同樣大小:
int dictResize(dict *d)
{
int minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; // 將bucket 縮小為和被鍵值對同樣大小
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
最後同樣呼叫 dictExpand 建立新的空間賦值給 ht[1]。
資料遷移如何進行?
上面我們也提到了,無論是擴容還是縮容,建立的新的空間都會賦值給 ht[1] 以便進行資料遷移。然後在兩個地方分別執行資料遷移,一個是增刪改查雜湊表時觸發,另一個是定時觸發
增刪改查雜湊表時觸發
增刪改查操作的時候都會檢查 rehashidx 引數,校驗是否正在遷移,如果正在遷移那麼會呼叫 _dictRehashStep 函數,然後會呼叫到 dictRehash 函數。
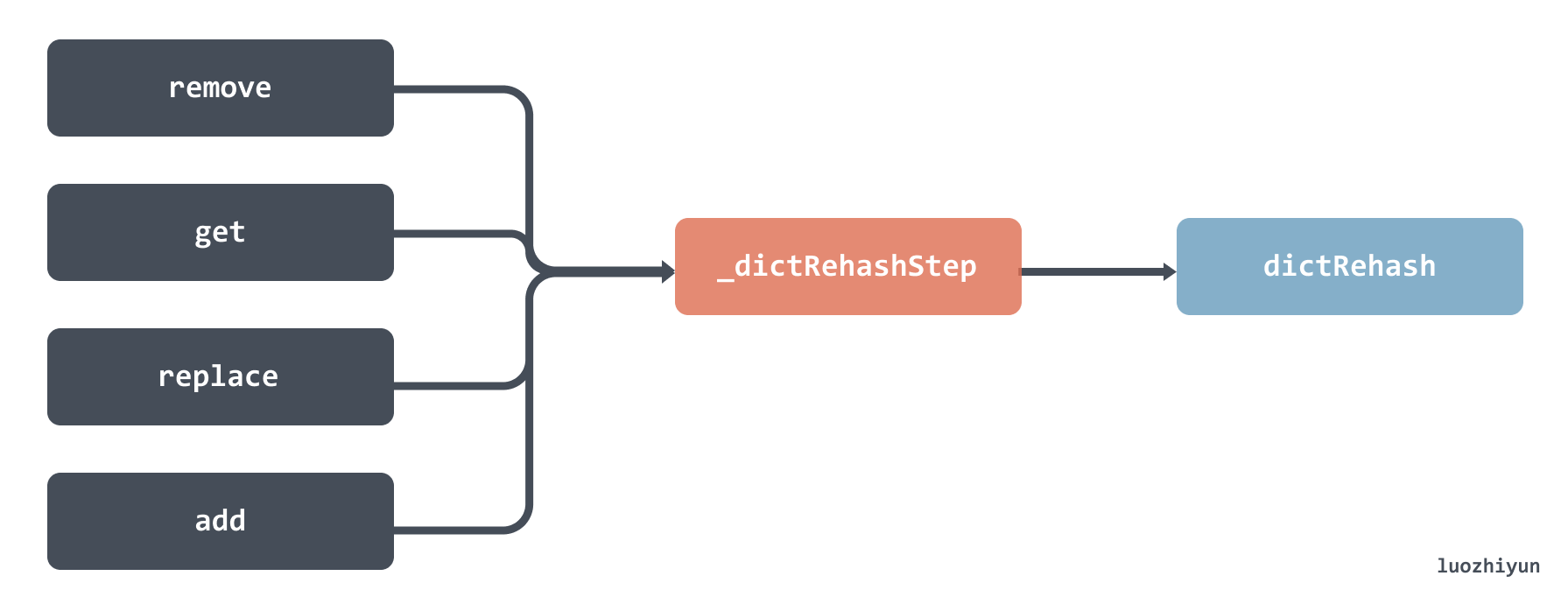
但是需要注意的是,這裡呼叫 dictRehash 函數傳入的大小是 1 ,也就意味著每次只遷移 1 個 bucket。下面我們來看看 dictRehash 函數,這是整個遷移過程中最重要的函數。這個函數主要做了以下幾件事:
- 校驗當前遷移的bucket數量是否已達上線,並且ht[0]是否還有元素;
- 判斷當前的遷移的bucket槽位是否為空,最大存取的空槽數量不能超過 n*10,n是本次遷移bucket數量;
- 獲取到非空槽位裡面 entry 連結串列進行迴圈遷移;
- 首先獲取ht[1]新槽位的index;
- 一個個節點放置到新bucket的頭部;
- 直到全部遷移完畢;
- 遷移完了將舊的hash表ht[0]對應的bucket置空;
- 檢查如果已經rehash完了,那麼需要free掉記憶體佔用,並將ht[1]賦值給ht[0];
感興趣的可以看看下面原始碼,已標註好註釋:
int dictRehash(dict *d, int n) {
// 最大的空bucket存取次數
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
// 校驗當前遷移的bucket數量是否已達上線,並且ht[0]是否還有元素;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx);
// 判斷當前的遷移的bucket槽位是否為空
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
// 獲取到槽位裡面 entry 連結串列
de = d->ht[0].table[d->rehashidx];
// 從老的bucket遷移資料到新的bucket中
while(de) {
uint64_t h;
nextde = de->next;
// hash之後獲取新hash表的bucket槽位
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 一個個節點放置到新bucket的頭部
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
// 遷移完了將舊的hash表對應的bucket置空
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
// 如果已經rehash完了,那麼需要free掉記憶體佔用,並將ht[1]賦值給ht[0]
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;// 返回0表示遷移已完成
}
return 1; // 返回1表示遷移未完成
}
定時觸發
定時觸發是由 databasesCron 函數進行定時觸發,這個函數會每100ms 執行一次,最終會通過 dictRehashMilliseconds 函數呼叫到我們上面提到的 dictRehash 函數。
┌─────────────┐ ┌───────────────────┐ ┌──────────────────────┐ ┌──────────┐
│databasesCron├──►│incrementallyRehash├──►│dictRehashMilliseconds├──►│dictRehash│
└─────────────┘ └───────────────────┘ └──────────────────────┘ └──────────┘
dictRehashMilliseconds 函數傳入的 ms 參數列示可以執行多長時間,預設傳入的是1,也就是執行1ms就會退出這個函數:
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
// 每次會遷移 100 個 bucket
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
呼叫 dictRehash 函數的時候每次會遷移 100 個 bucket。
總結
之所有要講 hash 表的實現是因為 Redis 中凡是需要 O(1) 時間獲取 kv 資料的場景,都使用了 dict 這個資料結構,而 Redis 用的最多的也就是這種 kv 獲取的場景,所以通過這篇文章我們可以清楚的瞭解到 Redis 的 kv 儲存是怎麼存放資料的,何時擴容,以及擴容是如何遷移資料的。
看這篇文章的時候不妨對比一下自己所使用的語言中 hash 表是如何實現的。
Reference
https://tech.meituan.com/2018/07/27/redis-rehash-practice-optimization.html
http://redisbook.com/preview/dict/rehashing.html
https://juejin.cn/post/6986102133649063972
https://tech.youzan.com/redisyuan-ma-jie-xi/
https://time.geekbang.org/column/article/400379
